一种巡逻执勤目标检测算法研究 *
2023-03-06岳磊袁建虎杨柳吕婷婷
岳磊,袁建虎,杨柳,吕婷婷
(陆军工程大学 野战工程学院,江苏 南京 210001)
0 引言
巡逻执勤目标与所处环境背景高度融合,检测目标种类多样,传统方法检测难度大、检测精度低、实时性差等问题十分突出。随着任务复杂程度加深,行动范围扩大,对巡逻执勤目标的检测要求逐渐提高,研究巡逻执勤目标检测在军事侦察、边境治理、引导打击和反恐维稳等领域具有重要意义。
目前国内外众多学者利用计算机视觉对无人机航拍目标、伪装目标进行检测,并已取得了一定成果。侯文迪[1]等提出了一种基于图像金字塔光流计算与灰度、HOG(histograms of oriented gradents)特征匹配的综合跟踪算法,该方法证明对边缘纹理较为丰富的伪装色移动目标具有良好的跟踪效果。苏昂[2]提出了一种基于梯度方向直方图特征和在线级联Boosting 的检测算法用于无人机图像的车辆检测,提升了无人机视角下车辆检测性能。
传统目标检测方法主要依赖人工提取特征[3],但由于当前巡逻执勤任务形式复杂多样,涉及行人、车辆、牲畜等多种类型目标,且机动性、实时性要求高,传统目标检测算法已经难以满足当前巡逻执勤任务的需要。此外,巡逻执勤目标在实际采集过程中,大都属于运动目标,且采集环境多样,这些因素容易造成图像模糊等问题。因此,在这样的情况下使用人工提取特征的方式进行目标检测,效果较差。
当前,采用深度学习的方式进行目标检测是重要的研究方向[4],在军事侦察、安防管控、维稳治安方面的应用也是研究重点[5]。通过深度学习的方法能够有效解决传统检测方法只利用浅层特征信息、易受自然环境因素影响、检测方法泛化性差的问题,同时提升巡逻执勤目标检测精度,提高检测效率,为相关任务执行提供帮助。当前,根据算法结构设计方式,将基于深度学习的目标检测算法分为2 类:
第1 类是基于区域的两阶段(two-stage)检测算 法,代 表 算 法 有Fast R-CNN[6](region-based convolutional neural network),Faster R-CNN[7]等;两阶段算法主要是依据图像中被检测目标实际位置,提前选取候选区的方式进行训练。
第2 类是一阶段(one-stage)检测算法,该类算法采用端到端检测网络,代表算法有YOLO[8-9](you only look once),SSD[10](single shot multibox detector)等。一阶段算法对图像进行检测采用回归方式,以这种方式找到检测框类别及偏移量,得到最接近真实值的检测框。赵晓枫[11]等对SSD 算法网络添加残差窗口模块,并将优化后数据集的检测结果作为评价指标,实验证明评估效果较好。邓小桐[12]等在RetinaNet 的骨干网络(backbone)的残差块中嵌入注意力机制,有效实现了迷彩伪装人员的检测。SONG[13]等提出了一种改进的注意模块I-ECANet(improved-efficient channel attention net),并在YOLOv3 网络中的最后一层残差层和每组残差层卷积到I-ECANet 注意力模块中,最后实验证明对检测反导遥感图像检测精度有较大提升,有广泛应用价值。
然而,对于巡逻执勤任务具有较强实时性、复杂性、任务环境多样、干扰因素多的情况,上述检测算法性能就有所欠缺。为此本文针对复杂环境背景下巡逻执勤目标检测图像模糊、自然环境干扰造成检测困难的问题,提出了一种多层注意力机制和多尺度特征融合的巡逻执勤目标检测智能算法。本文主要贡献点和创新点如下:①对有限的图像数据进行扩充,使用自适应均衡处理、翻转、旋转、噪声添加等增强处理。②搭建YOLOv5 检测网络,并在骨干网络中引入ECA-Net 注意力机制模块,以解决巡逻执勤图像中背景对被检测目标的干扰问题。③引入BiFPN(bi-directional feature pyramid network)结构,替换原始算法中的颈部网络(neck)中的FPN+PAN (feature pyramid network+path aggregation network)结构,用以改善网络结构,解决巡逻执勤目标尺度多样问题。
1 YOLOv5 算法原理
YOLOV5 检测模型主要组成为Input,Backbone,Neck,Prediction 共4 部分,其结构图如图1 所示。

图1 YOLOv5 网络划分流程图Fig. 1 Network partition flow chart of the YOLOv5
Input:将输入图像调整为640×640 的大小,然后进行数据增强、自适应锚框计算和缩放。
Backbone:相较 于YOLOv4 模型,YOLOv5 增 加了Focus 层、CSPNet[14](cross stage partial network)层。Focus 对图像进行切片处理,如图2 所示;CSP结构改进了网络结构设计方式,将推理过程中的计算量降低;SPP[15](spatial pyramid pooling)层将特征层进行卷积;然后进行最大池化(maxpool),增大了网络的感受野,同时也使非线性表达能力得到提升。
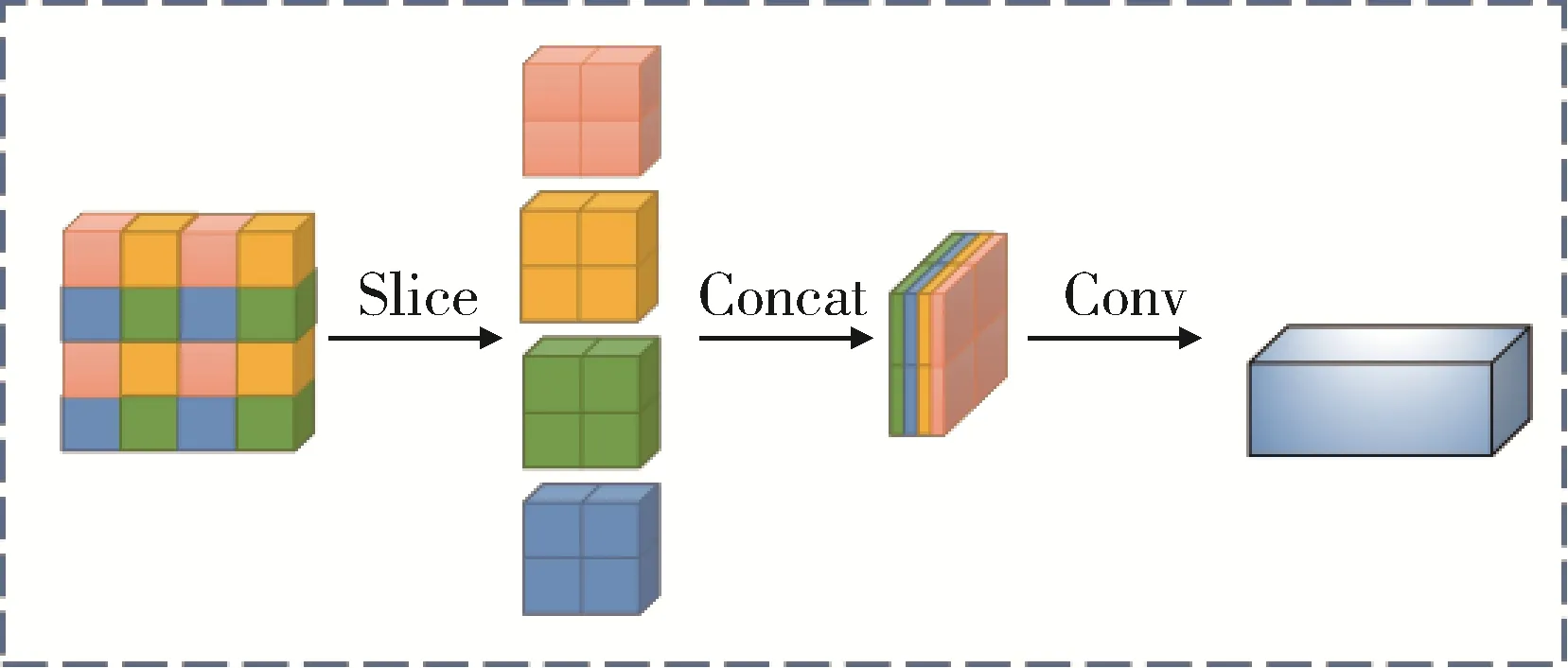
图2 Focus 流程 示意 图Fig. 2 Focus schematic of the process
Neck:将不同次的特征图进行融合,减少语义信息的丢失,获得更多的特征信息。在YOLOv5 算法中,使用FPN+PAN 的特征金字塔结构。FPN 将语义特征从顶部特征映射传递到较低的特征映射。同时,PAN[16]结构将定位特征从较低的特征图传递到较高的特征图中。这2 种结构共同加强了颈部网络的特征融合能力。
Prediction:在YOLOv5 的预测端采用的是GIOU_Loss (generalized intersection over union loss)作为bounding box 损失函数,类概率分类采用交叉熵损失函数。函数定义式为
式中:IOU(intersection over union)为预测框和标记框的交并比;B为标注框;Bgt为预测框;C为预测框与标注框的最小外接矩形面积;B∪Bgt为两个框的并集。
2 改进YOLOv5 巡逻执勤目标检测算法
在网络中添加注意力机制模块对于提升算法检测性能具有较好的作用,同时为保持特征信息提取性能和算法检测速率,加入了多尺度特征融合模块。本文所提出的多层注意力机制和跨尺度特征融合的巡逻执勤目标检测智能算法检测框架如图3所示。

图3 改进检测算法框架Fig. 3 Improved detection algorithm framework
数据集进行标注、转换格式、划分测试集和验证集,输入到网络中进行训练,并获得模型权重,然后使用改进算法进行检测。
2.1 ECA-Net 注意力机制模型
为了解决巡逻执勤目标显著度低的问题,在YOLOv5 模型的骨干网络中添加ECA-Net(efficient channel attention)注意力机制模块[17-18],如图4 所示。ECA-Net 在SENet 的基础上进行了改进,采用不降低维的方式产生权重,能够在实现复杂注意力模块的同时,降低算法的复杂程度。
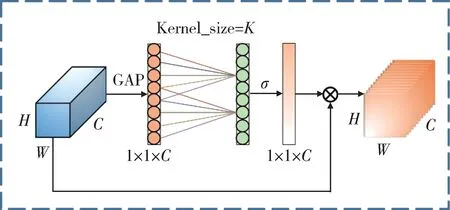
图4 ECA-Net 注意力机制模块Fig. 4 Efficient channel attention mechanism module
首先对特征通道进行全局平均池化,执行1×1卷积,然后产生通道权重系数,其中的卷积K(kernel size)代表了交互概率,采用如式(2)所示的自适应方法来确定K的方法。
式中:C为通道维 度;|t|为距离t最近的奇数;b和γ为线性函数关系,在这里本文将b设置为1;γ设置为2。
如图5 所示,添加注意力机制模块能够提升图像中被检测目标的显著性,减少其他干扰因素对图像检测带来的影响,为模型性能的进一步提升发挥作用。
2.2 BiFPN 特征融合结构
YOLOv5 算法中在Neck 部 分 采用FPN+PAN 结构,在多尺度融合方面取得了良好的效果。但其计算较复杂,且针对当前任务图像容易受环境因素影响,且尺度多样,该结构存在特征提取利用不充分,造成损失误差较大的情况。因此在Neck 部分引入双向特征融合结构BiFPN[19],如图6 所示。
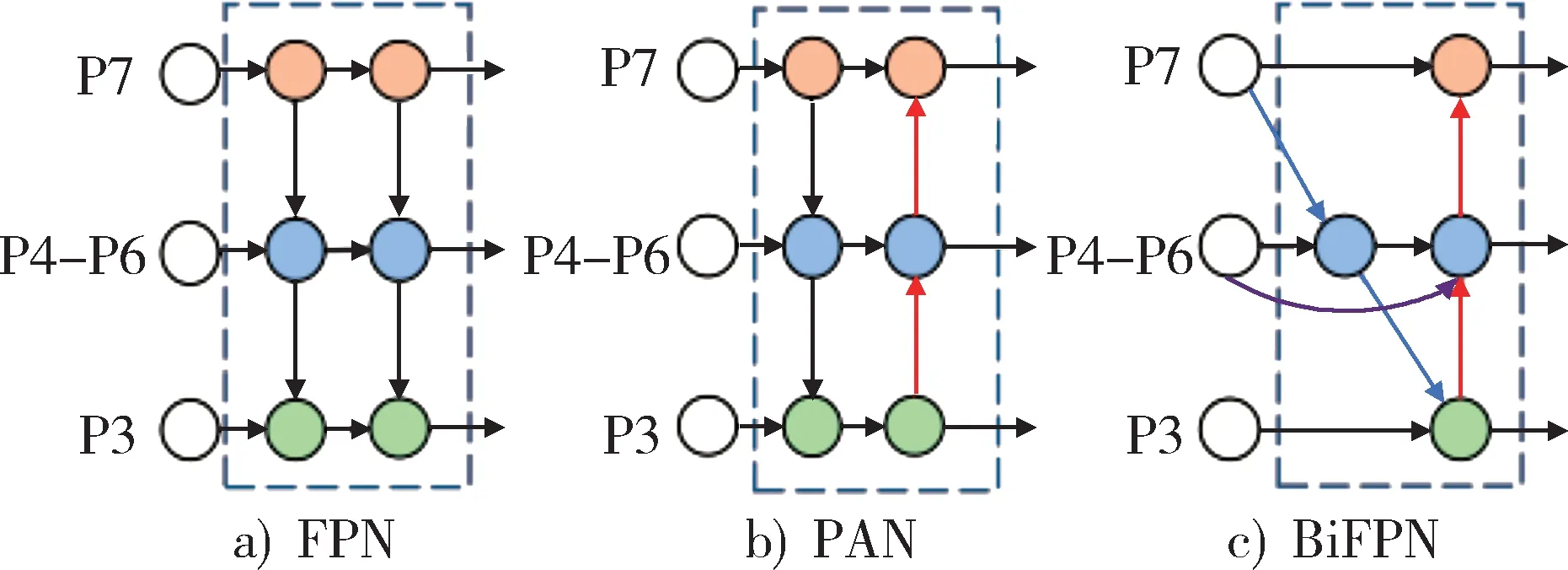
图6 3 种特征网络结构Fig. 6 Three feature network structure
相较于原来的Neck 结构,BiFPN 结构有4 点不同:①采用跨尺度连接以去除PAN 中对特征融合贡献率低的部分,并在同一级别的输入输出之间添加更多的节点。②删除对融合特征网络贡献较小的节点,简化双向网络。③BiFPN 结构在原始输入节点和输出节点之间增加了额外的边,尽可能多地提取特征。④该结果将每个双向路径作为特征层处理,并多次循环同一层。
3 模型训练及结果分析
本文实验使用PyTorch 框架,实验中所使用的软硬件环境如表1 所示。

表1 实验环境配置Table 1 Experimental environment configuration
本文所用部分数据集是从巡逻执勤的视频中截取,并结合国内外公开的图像、视频资料进行收集,共有样本2 600 余张。将数据集进行了划分,随机选取600 张图像作为测试集,其余图像作为训练样本。
3.1 模型训练
模型训练过程:将图像调整为640×640 大小,为防止过拟合和跳过最优解,将动量因子设置为0.93,并采用随机下降法进行训练。batch_size 为32。共训练500 轮次,前300 轮训练学习率为0.01,后200 轮训练学习率为0.001。待损失函数和精度都逐渐稳定时,得到算法最优权重。
3.2 实验过程
为验证改进算法的有效性,使用AP(average precision)来对每一类检测结果进行评估,并利用mAP(mean AP),即所有目标类AP 的平均值来衡量整个模型的性能。对于主观评价结果,可以通过对比改进和未改进网络处理后的图片来评估模型的性能:
式中:TP,FP和FN分别为正确检测数、误检数、漏检数;AP为P-R曲线积分;N为检测种类数量。为了检测本文改进算法与YOLO 标准算法的优势,进行了对比实验。结果如图7 所示。
IOU取0.5 时mAP为mAP@0.5,IOU取 不 同 值的mAP为mAP@0.5∶0.95。从图7 中可以看出,改进算法和原始算法都具有较高的检测精度。相较而言,本文算法在训练迭代到200 轮次左右的时候,准确率上升至0.68 左右,并最终在300 轮左右时稳定至0.77 左右;改进Neck 部分能够提前收敛,标准YOLOv5 算法训练迭代到180 轮次左右时,准确率仅上升至0.55 左右,最终稳定至0.73 左右。
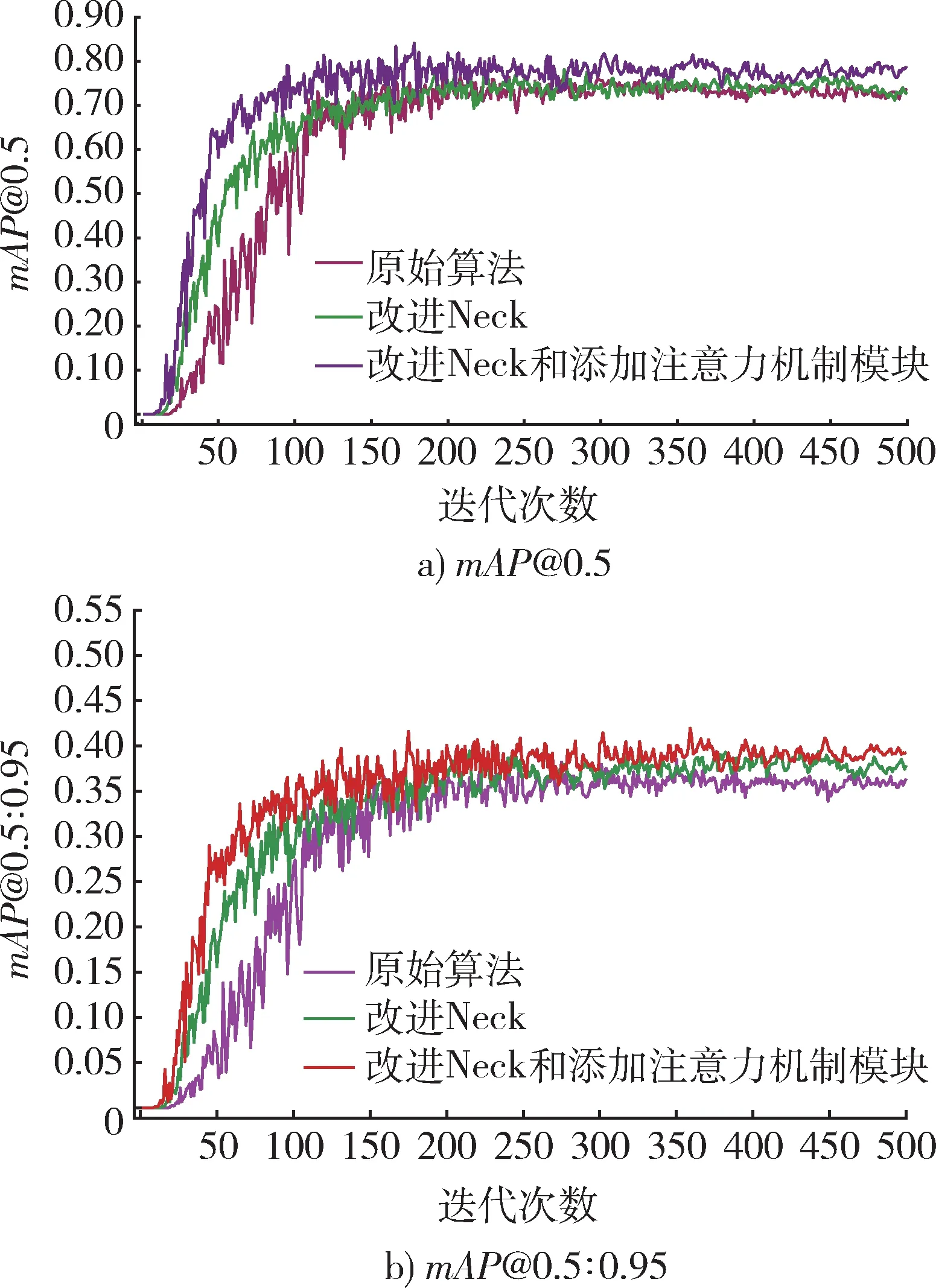
图7 mAP@0.5 与 mAP@0.5:0.95 训练变化曲线Fig. 7 mAP@0.5 and mAP@0.5:0.95 training change curves
3.3 结果分析
为了验证本文引入的数据增强、ECA-Net、改进Neck 等部分的作用,进行了消融实验进行验证,相关结果如表2 所示。

表2 消融实验结果对比Table 2 Comparison of ablation experiment results
表2 中第1 行为标准YOLOv5 网络模型的实验结果。
第2 行为训练样本进行旋转、平移、自适应均衡处理及马赛克增强等处理后送入模型进行训练,精度提高了1.04 %。
第3 行、第4 行为引入ECA-Net 后,使用数据增强和不使用数据增强后的结果。从实验结果可知,被检测目标在复杂背景下的特征表达能力增强,模型检测精度分别提高了2.97%和2.07%。
第5 行为综合本文方法改进后的算法检测结果,检测精度达到了77.18%,相较于原始算法有一定提升,且具有较高的实际应用性。
为了进一步验证改进算法的性能,将本算法与常见的One-stage 和Two-stage 算法进行对比,对比实验结果如表3 和图8 所示。

表3 各检测网络对比实验数据Table 3 Comparative experiments with each detection network
从表中数据可知道,本文算法在检测精度上略低于两阶段算法Faster R-CNN,在检测速度上略低于YOLOv5,但也保持了较好的实时性[20](FPS≥25即满足实时性)和准确性。综合来看,相较于其他检测模型,本文改进模型能更好地满足于巡逻执勤任务的实际需要。
第1 组被检测目标为无人机视角下的行人目标,有2 种姿态存在,且身体有部分遮掩。实验表示,虽然被检测目标小,且存在遮掩、模糊的情况,但本文算法能以较高准确率、较少的损失值,更接近于真实框。
第2 组被检测目标大小不一致,且随着网络的不断加深,特征语义信息会由低维转换成高维,每层网络都会产生一定程度的丢失。本文算法引入BiFPN 后,减少了低价值特征的融合,缩短了底层特征和顶层特征之间的信息路径,在一定程度上减少了被检测目标因为目标小、被遮挡等原因带来的误检、漏检情况。
第3 组被检测图像存在检测背景相似造成检测困难、漏检误检的情况。从检测结果来看,各类检测算法均存在漏检的情况。SSD 检测算法效果最差,仅检测出1 个目标;Faster R-CNN 算法效果最好,检测出4 个目标;YOLOv4 算法检测出3 个目标;YOLOv5 和本文算法检测出2 个目标,与原始YOLOv5 算法相比,本文算法检测精度更好。由实验结果分析得出:本文算法加入ECA-Net 后,利用该模块将特征通道进行全局平均池化,产生通道权重系数,并通过不同的权重系数强化目标特征,提高了检测精度。再结合BiFPN 结构,对于小尺度目标的特征信息挖掘能力更强,特别是对无人机俯拍目标的检测效果更好。但对于大尺度背景相似目标的特征信息提取能力提升有限,并且因训练样本中,这一类样本数量较少,不利于模型的优化训练,从而导致本文算法与YOLOv4 和Faster R-CNN 相比,在这一类目标上的检测性能略低。
第4 组被检测图像中含多个小目标,且背景干扰因素较多。实验结果表明SSD 和Faster R-CNN 算法出现了漏检的情况,而YOLOv4,YOLOv5 和本文算法均未出现漏检,且本文算法更加接近于真实框。
4 结束语
为解决巡逻目标检测效果差的问题,本文引入较为先进的单阶段目标检测算法YOLOv5,并基于该算法进行了针对性改进。虽然相较于其他检测算法,YOLOv5 在平衡准确性和检测效率上表现出较大的优势,满足实时性、高效性的要求。但在结合实际任务的需要进行分析时,指出了原始YOLOv5 算法检测巡逻执勤目标时,存在因检测目标尺度不一、所处背景复杂、自然因素较多等问题影响,导致漏检、误检、部分目标检测精度较低的情况。针对这些问题,在YOLOv5 算法模型的基础上提出了一种基于多尺度特征融合和通道注意力机制的巡逻执勤目标检测算法。首先通过图像增强,扩充数据集的同时增强了算法的鲁棒性;在Backbone 中引入ECA-Net 通道注意机制模块,提高了被检测目标在自然环境等复杂背景图像的显著性,进而提高了检测精度;通过将Neck 替换为BiFPN,使被检测目标的特征能够得到更好的表达,降低了因巡逻执勤目标多样、遮挡等情况造成的漏检率和误检率。实验结果表明,相较于原始算法,本文算法在多种复杂环境下的测试,具有较好的精度及实时性。
本文算法还存在一定的局限性及较大的提升空间,数据集还需进一步扩充。当利用本文算法检测背景高度相似、阴影区域时,漏检情况较严重;同时针对具体巡逻执勤任务,还需进一步结合任务情况进行实际应用,后期将对上述问题持续开展研究。
