基于感知偏序模型的图标视觉复杂度研究
2023-02-28陆宏菊
陆宏菊,崔 嘉
(1 广州城市理工学院管理学院,广州 510850; 2 华南理工大学设计学院,广州 510006)
0 引 言
视觉复杂度计算作为重要依据用来检索和评价图像和图案,如可视化检索、分类、审美评估等[1]。当前复杂度评估主要包括三方面研究: 描述程度、创造程度和组织程度[2]。 然而,由于获取和处理困难,缺少感知特征的考虑导致其预测结果与人工评价仍有较大的差异。
对视觉复杂度的排序方法可以分为两大类: 基于偏好和基于过程的排序[3]。 前者主要对用户数据采用概率模型进行统计分析,但统计结果往往会覆盖用户数据的敏感性; 后者采用特定的评价指标产生评估序列,却无法体现视觉复杂度的动态波动特点。 近年来,戴凌宸等学者[4]通过计算4 种客观评价参数,采用回归模型对图标形状复杂度进行评价,获得了较为准确的结果(接近80%的人工评价)。 基于学习策略的不同评估模型也随之出现,例如基于结构分裂Patch[5]、Inferring Human Attention 模型[6]和深度学习算法[7]。 然而,当对比图像具有高度相似性时,由于用户的感知因素常优于客观特征起主导作用,上述方法的评价效果往往波动较大。 因此,具有冲突性、动荡性和不稳定性的用户感知数据[8]的表示和建模便成为了解决该问题的关键。
针对上述问题,提出新的视觉复杂度评估模型,与文献[4]所不同,本文面向具有丰富语义和符号含义的图标图案进行研究。 研究假设存在目标复杂度序列,既对用户数据具有敏感性,又能够发掘复杂度逻辑。 用户数据的敏感性能够保证在统计数据相同的前提下,不同的用户数据可以产生不同的感知特征表示,从而提高预测的精准度; 发掘复杂度逻辑是主观感知模型建立的基础,能够使得模型更加符合用户评价方式。 与传统统计概率模型不同,研究提出基于比较的偏序关系(A >B) 表示用户感知信息。 偏序对的形式能够有效保持用户数据的敏感度。 针对用户数据普遍存在的矛盾冲突现象,本文提出可信度预处理,根据用户数据得到可信度阈值,从而使得冲突程度为最终预测结果做出积极贡献。 对于偏序关系采用对象相异距离最大化地改进SVM 模型进行训练,获得用户感知模型。 本文首次在视觉复杂度模型预测中引入用户感知因素以提高预测的准确度。
本文主要贡献包括:
(1)提出基于二比较偏序关系的用户感知特征表示方法。 主观数据的表示对于用户感知模型的建立至关重要,本文提出”偏序对”的方式能够融合比较双方的多模态特征。 用户的偏序关系可以通过启发式算法进行训练生成用户感知模型。
(2)基于群体智能的用户感知计算模型的提出可以广泛应用于视觉比较和智能设计领域。 用户感知评价在设计、生成领域的决策过程中一直占有重要地位,但由于难于获取和表示无法在优化过程中进行计算。 本文针对具有感知特点的视觉自动评估机制提出的评估框架适用于领域其他研究,具有较好的推广性和普适性。
1 相关工作
2017年,Zhang 等学者[4,9]提出通过回归算法构建形状复杂性的计算模型,是近年来该领域的代表作之一。 其中,文献[6]提出了对复杂度表示的4个特征:香浓信息熵、加权旋转角度熵、非圆性和邻角平均差。 训练标签来自于用户数据的统计结果。通过采用Pearson 和Kendall 相关性系数,模型能够解释80%的用户评价行为。 但该方法仅用简单(相似度不高)的图标图案进行验证,因而在决策过程中用户感知因素并没有明确的体现。
相对于分类任务,能够得到目标序列的排序模型[10]更加接近真实的视觉复杂度评价。 SVMRank 算法[11]能够基于图像数据训练模型对于类内/间物体的可视化属性进行排序,例如:鞋子、自然风景和人脸表情。 类内物体的属性表示为S集,类间物体的属性表示为O集。 优化过程的损失函数实现类间物体差距大,且类内物体差距小的约束。 SVMRank 算法及其改进的DeepRank 算法[12]虽然对于类间排序能够获得较好的准确度,但对高度相似的类内数据的排序效果仍旧有待提升。 这主要因为在相似的类内数据排序过程中,感知因素将占据主导地位。
受以上方法的启发,本文提出能够模拟人类决策过程的视觉复杂度计算模型。
2 感知特征表示
主/客观特征都能够对视觉复杂度进行表示。 对于差异明显的图标复杂度评估,客观因素占据主导地位[1,3],如图1(a)所示。 本文的主要研究对象是面向具有高度相似性图标在评估过程中起到关键作用的感知因素。 中国大学图标具有丰富的视觉元素和隐含的符号化语义:在有限的设计空间内,不同的图形、颜色及其组合表达了不同的设计理念和语义传达,既具有相似性,又具有辨别度,非常适合用来进行主观因素占主导的决策研究,如图1(b)所示。 如何对具有感知特征和高度相似的图形图像进行视觉复杂度评估是当前计算机视觉和机器学习研究领域的挑战。本文提出二元组偏序关系表示用户的感知评价结果;可信度预处理函数能有效地提高训练模型的鲁棒性,如图2 所示。 尤其是在主观评价存在冲突的时候,通过引入多模态特征组对目标物体进行客观描述,能够尽可能全面地获取比较对象的感知特征。 根据收集到的数据量,本文采用基于改进SVM 模型模拟用户主观感知进行复杂度预测。

图1 不同相似度的图标Fig. 1 Logos with different similarities
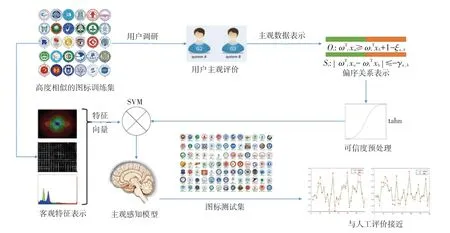
图2 本文算法框架Fig. 2 Research framework
2.1 偏序关系表示感知特征
对于人工智能最大的收获在于将人类智慧和机器智能相结合而产生的群智能[13]。 传统研究中,当需要用户感知数据时,用户调研成为最常采用的研究手段。 传统的用户数据通过基于累积得分的概率统计模型进行表示。 这种模型在启发式学习过程中具有数据不敏感的问题,例如,根据众数原理,A数据得9 分和得5.5 分,都表示统计优势结果。 由于感知判断的不稳定性和难以对所有采样进行完整测试(工作量大),统计概率模型仅能表示部分的通用概率分布且不能体现其中个体的相似度关系。 例如,如果A(强烈喜欢,+2),B(普通喜欢,+1),C(不喜欢,+0),那么对于ACC和BBC的统计模型会得到相同的结果,而A所代表的强烈偏好的感知因素无法在数据模型中得到体现。 数据的敏感性对于智能算法至关重要,因此提出具有数据敏感的用户感知表示法成为需要解决的首要问题。
在小数据量(n≤30) 情况下,对用户进行全面的测试得到基于用户数据的目标序列仍是具有挑战的。 根据心理学原理[14],人们在进行选择时,二选择往往会比多选择更容易做出决策。 因此本文采用二选择的方式进行用户感知数据的收集,即用户只需要在2 个图标中根据感受进行相应选择。 其比较的结果通过偏序关系进行表示:大于关系O集(A >B) 和近似关系U集(A ~B)。 用户测试界面如图3所示。

图3 用户数据收集界面Fig. 3 User interface for data collection
对于偏序对A >B和A ~B,可以通过式(1)和式(2) 进行表示:
其中,xi和xj表示2 个目标图标的特征向量;ƒ(·) 为主观评价函数;‘>’ 和‘=’ 为用户根据感知指定的偏序关系。
这样,通过用户调研收集到的用户感知数据可以表示为N不等式关系。 本文提出目标函数可以表示为:
且满足如下约束:
2.2 数据可信度处理
在相似的视觉复杂度评价中,用户的感知因素将起主导作用。 但是,由于主观感知的不确定性,不可避免地将会产生一定的冲突结论。 例如,对于图标A和B,有人认为A比B复杂,有人认为B比A复杂,还有人会认为A与B的复杂度差不多。 在传统的统计概率模型下,只需要对评价数值进行叠加而无需关注结论的冲突程度,即,最终用户数据统计结果为0-1 分类。 但本文研究引入用户的感知差异的考虑,在训练过程中加入感知数据的冲突现象建模过程。 研究假设,感知因素的不稳定性会导致偏序关系存在多样性,而每一对偏序关系都将对最终模型的建立做出相应的贡献。 为了表示数据的多样性,本文提出可信度约束函数,将用户的主观数据根据冲突情况映射到连续区间[0,1]中。 经过多次实验,本文选取tahn 函数作为可信度约束,计算公式如下:
当结论相对统一时,可信度函数将会趋向于0或1; 当结论冲突现象严重时,可信度函数将会计算相应可信度阈值平衡矛盾冲突现象。
由于偏序关系中的U集表示2 个目标的相似关系,不存在偏序的比较关系(A ~B⇔B ~A),因此U集不需要可信度约束。 偏序关系中的O集可以表示为
2.3 主观感知模型
训练数据I ={i1,…,in}可以表示为在n维特征空间内的特征向量xi。 根据式(5) 和式(7) 可知,该问题进行优化仍旧属NP 难问题。 本文通过引入松弛变量ζij和γi j对问题近似寻优[15],则偏序关系O集和U集可以表示为不等式(8):
该优化问题可以通过支持向量机SVM 模型进行求解:
其中,C为平衡系数常量。 式(9) 中第一项用来最大化目标物体间的距离,第二项用来满足松弛约束。 通过计算二次惩罚训练误差,其梯度可以表示为:
其Hessian矩阵可以通过式(11) 计算:
当相邻目标间的距离变大时,由于数据比较稀疏,Hessian矩阵无法进行显式的构建。 因此,可以通过共轭梯度法[16]求解线性系统H-1∇。
本文提出的改进SVM 模型能够使得训练数据遵循式(8)的约束。 保证序列中相邻目标物体间的投影距离尽可能地大,也就是说将序列中相邻2 个图标间的差异最大化。 系数w可以学习到偏序关系O集和U集所表示的用户感知数据。 具体算法如下。
Algorithm 主观感知模型算法
输入用户主观偏序对
输出权重向量Wij
Step 1输入用户主观偏序对O集和U集
Step 2按照式(6)计算可信度约束confij
Step 3O′ =confij∗O
Step 4按照式(10)~(11)计算∇和H
Step 5按照式(9)进行优化
Step 6计算Wij
3 实验与分析
3.1 实验设置
实验环境为Win10 操作系统,16 G 内存,GTX1070 图形卡和Matlab R2015b。 多模态特征能够在不同尺度和流形对目标物体进行描述[17],本文从不同角度选取3 个特征对目标物体进行客观特征描述: 全局特征Gist、局部特征HOG 和颜色特征Color histogram。 总共进行了3 组实验对本文方法进行验证。 第一组:在自建的中国大学图标数据库中进行视觉复杂度定性排序实验;第二组:与最新的算法进行主观感知准确率对比实验;第三组:与人工打分进行相关性系数对比实验。
3.2 图标数据集
研究搜集了815 个大学图标,并建立主观评价数据集。 考虑用户调查的可行性,60 个图标一组对整个数据库进行可重复分组。 邀请40 位年龄在18~25 岁的用户(12 男,28 女)进行感知数据采集。一组图标分为训练集和测试集(30 个图标作为训练集,30 个图标作为测试集)。 图标复杂用户评估属于高强度脑力劳动,不易进行大规模、长时间测试。同时,为了避免用户仓促选择导致的数据不准确,设定每一次选择时间不小于5 s。 用户可以根据自己的主观感受,通过点击鼠标在2 个图标中选择认为复杂的一个,或者复杂度相同的选项。 并且规定每人每天只能进行一组实验,每组实验不超过100 对比较,连续5 天为一个周期,训练和测试部分数据如图4 所示。

图4 中国大学图标库Fig. 4 Chinese university logo dataset
研究选择其中一组用户数据进行分析,见表1。表1 中,total_test_pairs 表示一共进行了6300 对图标对比实验; effective_test_pairs 表示除去重复实验外,总共进行的实验组数。 在一组训练集和测试集中各有30 个图标,最多的有效对数(不重复的测试对)为870 组。 测试覆盖度达到了99.46%。 其中,经统计共有812 组出现了结果冲突的情况,只有53组没有冲突,冲突率达到了93.95%。 以上数据的分析从侧面证实了本文提出的假设:在高度相似的数据集中,可视复杂度的判断起主导作用的是感知因素; 且感知数据特征具有不稳定和矛盾冲突的特点。 该数据分析也证实了在进行视觉评价时感知模型建立的必要性。

表1 数据库用户数据分析Tab. 1 Database user data analysis
由于具有较高的数据冲突,因此对比了数据预处理之前和之后的状态,见图5。 通过采用传统的统计概率模型进行分析发现,数据经过可信度预处理后,虽然数据数值发生了变化,但数据分布和变化趋势并未改变,也没有破坏偏序关系本身的特征。
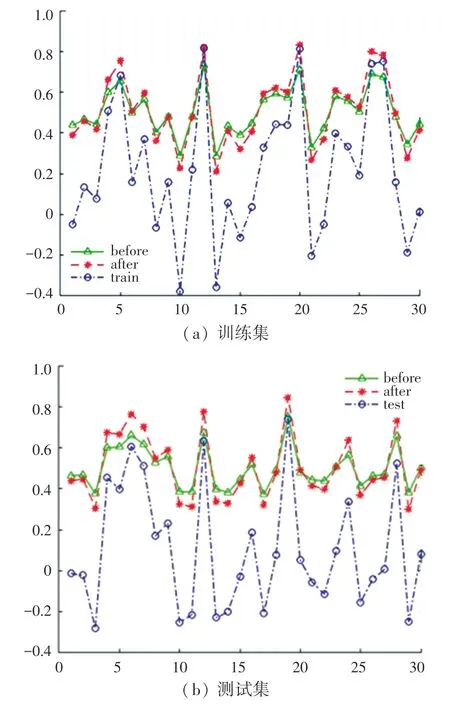
图5 主观数据分布Fig. 5 Subjective data distribution
3.3 图标复杂度对比实验
本节包括2 个实验:首先,是用户感知模型在训练集上预测结果与人工打分结果的定性对比实验;其次,是与其他经典复杂度评估的对比实验,例如:LogoComplexity[4,9]、SVMrank[11]和Deeprank[12]。
通过用户调研,对图标复杂度的用户数据通过统计概率模型进行分析得到在训练集和测试集上的排序情况,如图6 所示。 训练好的用户感知模型也分别在训练集上进行验证,在测试集上进行推理。经过对比发现:在训练集上,对于复杂度前5 名来说模型预测和用户评分获得了相同的结论,如图6(a);复杂度后5 名模型预测和用户评分虽然排序略有不同,但是都集中在相同的5 个图标上。 从视觉角度分析,前5 名复杂的图标都具有精细的线条和复杂的图案; 后5 名复杂的图标图案都比较简单。 在测试集上可以得到类似的结论,除了2 个例外(见图6)。 前5 名的用户评分第4 个在模型预测序列中只能排到第15 名。 经过分析原始主观数据发现该图标总共出现了15 次冲突数据,因此其可信度系数不高导致预测排名靠后。 后5 名的用户评分第4 个也是类似的情况。 第一组实验结论证实本文提出的用户主观感知模型基本可以真实地反映用户的主观特征,可信度系数的提出也进一步的提高了模型对于数据的鲁棒性。
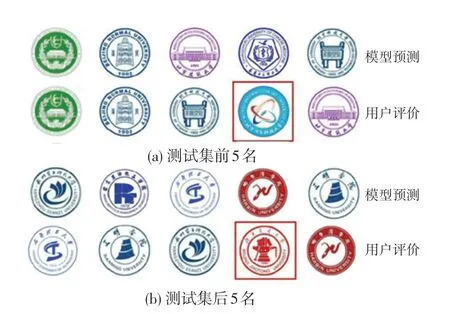
图6 测试集图标分析Fig. 6 Logo rank analysis on test set
第二组实验对比本文算法与其他3 个经典算法,以及与未经过可信度预处理模型的对比结果。预测准确率为预测准确的组数与总预测组数的比率,如式(12)所示:
对此结果见表2。 在表2 中,由于图标图案在形状和结构方面具有高度相似性,LogoComplexity 只对4 个客观特征训练的预测准确率约有70%。 无论RankSVM、还是Deeprank 算法,仅依靠客观特征、不考虑主观因素,都无法准确地预测评价结果。RankSVM 的准确率大约在80%,而采用了深度学习框架Deeprank 的准确率在85%。 本文提出的用户主观感知模型由于引入了用户主观数据,因此能够获得较好地预测准确率。 同时,因为RankSVM 和本文方法皆采用了基于回归SVM 模型、且都包含用户感知数据,还进一步对比了可信度预处理之前和之后的效果。 经过实验显示,置信度预处理能够在一定程度提高预测准确率(3%,3%,8%,12%)。

表2 图标复杂度定量对比Tab. 2 Quantitative comparison of icon complexity
3.4 用户相关性实验
本文提出的模型引入了感知特征,因此与用户的主观判断更加接近。 研究采用统计学中的三大相关性系数:Pearson、Kendall 和Spearman 进行模型推理结论与用户评价数据的相关性实验。 其中,Pearson 系数用来衡量2 组数据在线性关系中的相关性和方向性; Kendall 系数用来衡量2 组数据的部分匹配度; Spearman 系数用来衡量2 组变量的依赖性程度。 主观感知模型相关性,对此实验结果见表3。 由于LogoComplexity 仅计算了图标的客观特征,因此与人工评价的相关性都比较低。 RankSVM和Deeprank 算法通过计算用户评价感知特征的统计信息进行排序而没有考虑相似个体的差异,因此得到的相关性也不令人满意。 本文方法采用偏序关系对用户感知数据进行表示。 由于主观数据具有冲突的因素,在进行可信度预处理前,三大系数均在70%~85%之间。 经过可信度预处理后,相关性系数均在90%左右。 因此,研究认为本文提出的主观感知模型可以解释达到90%的用户行为特征。
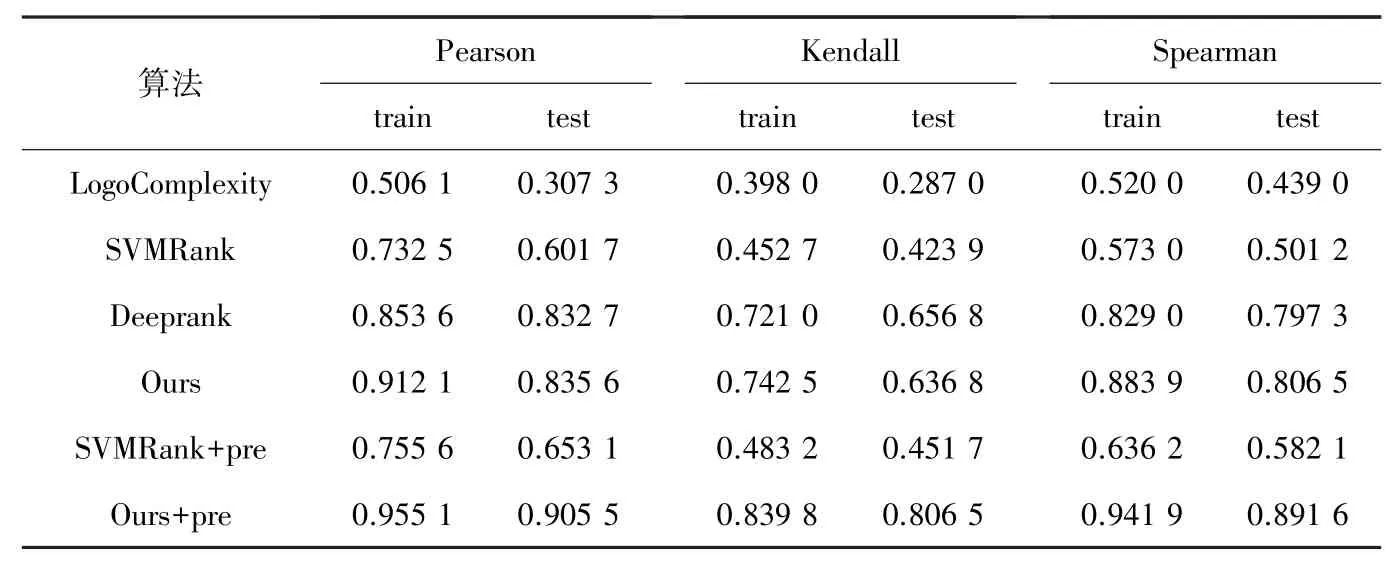
表3 主观感知模型相关性对比实验Tab. 3 Comparison experiment subjective perceptual model correlation
4 结束语
本文提出通过基于偏序关系的感知特征表示视觉复杂度。 针对用户调查数据存在冲突的现象,本文首先进行可信度函数预处理,然后通过共轭梯度法,采用改进的SVM 模型对主观偏序关系进行优化得到用户感知模型。 经过与最新算法的定性对比、准确率对比验证了本文方法的有效性。 通过相关性系数的计算,证实了本文方法能够较高地(90%)接近用户的评价结果。
在训练过程中本文仍旧采用手工设计的特征对目标物体进行表示,特征表达具有局限性。 采用预训练的深度框架提取目标特征,从而提高预测准确率和模型鲁棒性是接下来的研究方向。 另外,本文工作仅在小数据集进行了实验和对比,存在过拟合和数据不均衡的可能性,无法全面、客观地反映用户感知数据特点。 收集更大规模的用户数据能够有效解决这一问题,这也将是下一步工作方向。
