面向图像篡改检测的双流卷积注意力网络
2023-02-28张玉金张立军
孙 冉,张玉金,张立军,郭 静
(上海工程技术大学电子电气工程学院,上海 201620)
0 引 言
随着图像编辑技术的发展,图像篡改成为了低成本的操作,不同的人群篡改图片的目的不同,但都会使图像内容的真实性得不到保障。 已有的研究工作表明,图像篡改类型主要包括:复制-粘贴篡改[1]、拼接篡改[2]和修复篡改[3]。 其中,复制-粘贴篡改是指在同一幅图像上,把某一部分区域复制后粘贴到该图像的另一个位置,从而达到以假乱真的目的;拼接篡改是指将一幅图像的某个部分复制下来粘贴到其他图像中以合成一幅伪造图像;修复篡改是指基于图像原有信息还原缺失部分或移除原图某一区域。 目前,主流的图像篡改检测方法可以分为主动检测和被动检测(盲检测)[4],二者的主要区别在于是否在图像中预先嵌入附加信息,如数字水印等。
图像拼接使用的源图像一般来自两幅或多幅不同图片,人们在对图像进行篡改时,往往只关注RGB 域的逼真程度,而忽略图像噪声域的统计特性变化。 图像噪声是指存在于图像数据中的干扰信息,图像成像过程中,CCD 和CMOS 传感器采集数据时一般会受到传感器材料属性、工作环境和电路结构等影响而引入各种噪声[5]。 由于拼接篡改使用的图像通常来源于不同成像设备,而这些设备的噪声分布往往具有一定的差异,因此,噪声的不一致性对图像拼接篡改的分析与鉴定具有较好的辅助作用。
2012年,以Alex-Net[6]为代表的卷积神经网络(Convolutional Neural Network,CNN)在特征提取方面表现优异,随后一些学者开始使用深度学习技术来解决图像篡改检测问题。 Yuan 等学者[7]首次将卷积神经网络用于数字图像篡改检测,该方法从RGB 彩色图像自动学习特征层次表示,并采用特征融合技术得到最终判别特征。 Johnson 等学者[8]提出了全卷积网络并应用于语义分割任务,实现了像素级别的分类。 Salloum 等学者[9]对此网络结构稍作修改,提出一种基于边缘强化的多任务图像被动取证框架用于像素级别的篡改区域分割,该算法采用VGG16 网络提取图像篡改特征,并利用篡改区域掩码对篡改区域进行修正。 Bondi 等学者[10]结合图像成像设备属性的特点,提出利用相机指纹进行图像篡改检测和定位,该算法采用神经网络从图像块中提取相机模型特征,对拼接篡改具有良好的检测效果,但不适用于复制-粘贴的篡改类型。 Bappy 等学者[11]采用了一个混合的CNN-LSTM 模型来捕捉篡改区域和非篡改区域之间的区分特征,LSTM(Long Short Term Memory)[12]是长短期记忆模型,能够记录图像上下文信息,并将LSTM 和CNN 中的卷积层相结合来理解篡改区域和相邻非篡改区域共享边界上像素间的空间结构差异。 Zhou 等学者[13]基于Faster R-CNN 网络[14]提出一种双流网络,并对其进行端到端的训练,以检测可疑的篡改区域。
在上述双流网络中,RGB 流能够有效地反映图像篡改特性,噪声流则能更好地体现不同设备源图像进行拼接后的差异,故RGB 流和噪声流对于图像篡改检测具有一定的互补性,但由于Faster R-CNN最优性能的限制,该网络仍存在提升空间。 因此,本文在前人工作基础上改进了卷积注意力机制(Convolutional Block Attention Module,CBAM)[15]加入到特征提取网络,并在RPN 模块引入Soft-NMS算法[16],构建了一种面向图像篡改检测的双流卷积注意力网络。 改进的卷积注意力机制可有效抑制图片中冗余信息,达到对有效信息的专注检测,Soft-NMS 算法可以有效地降低漏检概率。 本文所提的双流网络可以学习更丰富的图像特征,以提高图像篡改检测准确度。
1 网络总体框架
本文所提双流卷积注意力网络的整体流程如图1 所示。 RGB 流将原图输入网络中,通过加入改进卷积注意力机制的特征提取网络从RGB 图像中提取特征,捕捉RGB 域中的边缘异常、颜色反差等篡改痕迹;噪声流首先利用SRM 模型[17]提取噪声信息,再通过特征提取网络分析图像真实区域和被篡改区域噪声间的不一致性;最后,将2 个支流中提取到的特征信息在双线性池化层[18]融合得到最终的特征图,送入最后的全连接层进行分类和位置精修。

图1 网络整体框架Fig. 1 The framework of the network
1.1 改进的卷积注意力模块
注意力机制是提升网络性能的一种方式,在传统的卷积池化过程中,默认特征图的每个通道的重要性是相同的,而实际并非如此,SE block[19]即是为了解决该问题而研发的。 一个SE 模块分为压缩(Squeeze)和激发(Excitation)两个步骤,通过对前一个卷积层输出的特征图进行全局平均池化操作得到1∗1∗C的压缩特征量,再经过2 个全连接层,先对特征压缩量进行降维、再升维,增加了更多的非线性处理,更好地拟合通道之间复杂的相关性。 最后与原始的特征图进行矩阵的对应元素相乘得到不同通道权重的特征图。
CBAM 是轻量级的卷积注意力模型,是对SE block 的一种改进,由通道注意力机制和空间注意力机制级联而成,CBAM 对特征图进行操作,使提取到的特征更加精炼。 其中,通道注意力和SE block 类似,只是多了一个并行的全局最大池化的操作,研究认为不同的池化意味着提取到的高层次特征更丰富。 图2 展示了通道注意力的过程。
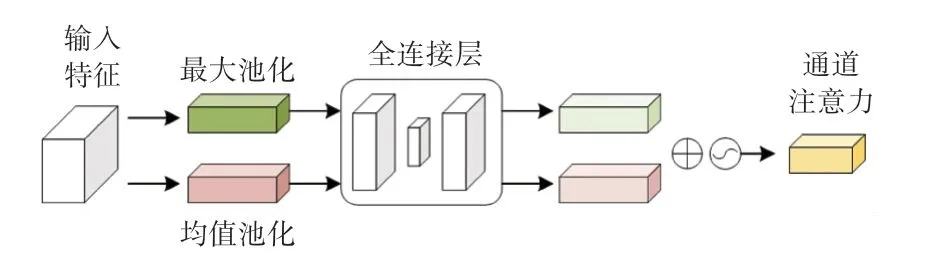
图2 通道注意力Fig. 2 Channel attention
空间注意力关注的是同一通道间不同位置像素的重要性,该模块的输入是上一个通道注意力的输出。 图3 为空间注意力过程。
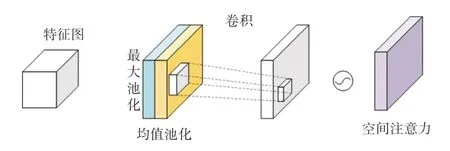
图3 空间注意力Fig. 3 Spatial attention
文献[20]中实验表明,SE block 中的2 个全连接层中的降维操作会给通道注意力预测带来副作用,并且所捕获到通道之间的依存关系效率不高,研究提出一种有效的通道注意力机制(Efficient Channel Attention,ECA)模块,在不降维的情况下进行逐通道全局平均池化后,考虑每个通道及其k个近邻来捕获本地跨通道交互。 受这种做法的启发,本文给出了改进的CBAM 注意力模型(Improved CBAM,ICBAM),将2 个全连接层换成大小为k的快速一维卷积生成权值,k值的大小通过学习自适应确定,结构如图4 所示。 整个过程可以用公式(1)表示:
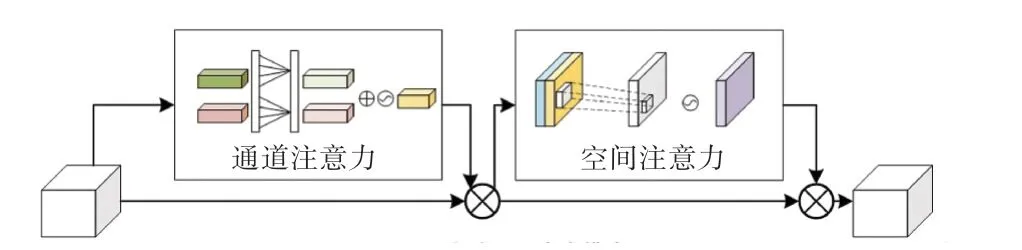
图4 改进的卷积注意力模块Fig. 4 Advanced CBAM block
其中,F为输入特征;Mc为通道注意力特征;Ms为空间注意力特征;“ ⊗”表示逐项元素相乘。
在通道注意力模块,输入特征F经过并行的平均池化和最大池化得到2 个通道描述子,分别通过卷积核大小为k的一维卷积计算权重,将得到的特征元素逐项求和,经由sigmoid函数得到权重系数Mc,和输入特征F相乘得到新的特征。 见式(2):
其中,σ表示激活函数,Ek表示一维卷积后的权重。
在空间注意力模块,输入是上一个通道注意力的输出,把带权重的通道特征送入2 个大小为列通道维度的池化(最大池化和平均池化)得到H∗W∗2 大小的特征图,对该特征图进行卷积操作和sigmoid激活之后,和该模块带权重的输入对应元素相乘得到最后的结果。 研究推得的计算公式为:
其中,σ表示激活函数,f7∗7表示7∗7 卷积操作。
本文采用通道注意力机制在前、空间注意力机制在后的级联形式,将卷积注意力机制加到ResNet[21]第一个卷积层和最后一个卷积层之后。ResBlock+ICBAM 结构如图5 所示。
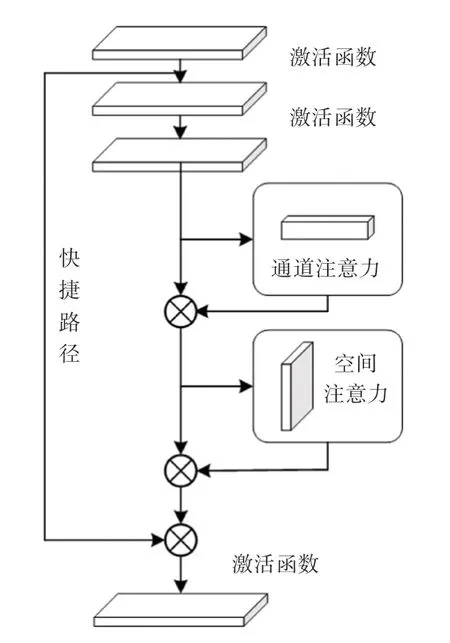
图5 Resblock+ICBAM 结构Fig. 5 Resblock with ICBAM
1.2 Faster R-CNN
Faster R-CNN 是一种两阶段目标检测算法,在目标检测领域取得优异成绩,该算法主要由4 个部分组成:特征提取网络、区域推荐网络(Region Proposal Network,RPN)、RoI(Region of Interest)池化层、分类和回归。 其中,特征提取网络提取图像的特征图送到RPN,RPN 用于生成多个建议框,RoI 池化层综合特征图和RPN 的建议框信息送入全连接层和softmax层进行分类,同时进行bounding box 回归得到最终预测的目标位置。 结构流程如图6 所示。
1.3 RGB 流
RGB 流是一个基础Faster R-CNN 网络,在特征提取模块,采用带卷积注意力机制的ResNet 网络学习RGB 图像中篡改的特征。 RGB 流中的RPN(region proposal network)模块用来推荐可能存在篡改的区域,这一层使用softmax层分类器判断建议框是正、还是负,RPN 模块的损失函数如下:
其中,gi表示候选框i可能被篡改的概率;表示候选框i为正样本标签;fi和是候选框的四维标签;Lcls表示RPN 网络的交叉熵损失;Lreg表示建议边框的L1回归损失;Ncls表示RPN 网络中批量的大小;Nreg表示建议边框的数量;λ表示用于平衡2 个损失的超参数,本文选取λ=10。
1.4 噪声流
RGB 流对篡改图像进行检测和定位精度和准确度有限,尤其是当篡改图像经过一些后处理操作、如滤波等,导致拼接区域的边缘不一致信息被隐藏,因此需要引入噪声流辅助检测和定位。
噪声流的设计是为了更关注噪声而不是图像的语义信息,富隐写分析模型(Steganalysis Rich Model,SRM)在图像隐写任务中表现优异,该模型主要从相邻像素中提取局部噪声。 本文同样使用SRM 模型来提取噪声输入到噪声流。 在SRM 的30个基础滤波器中,只使用3 个滤波器也可以达到与30 个滤波器近似的效果,另外的27 个滤波器对噪声提取效果并没有明显的提升,因此本文采用3 个滤波器,滤波器的权重如图7 所示。

图7 SRM 滤波器Fig. 7 SRM filter
本文将提取出来的噪声特征直接输入到噪声流,噪声流的网络也采用Faster R-CNN,并且和RGB 流共用RoI 池化层的权重。
1.5 双线性池化
图像分别经过RGB 流和噪声流的特征提取网络后,需要将2 个特征图融合后再进行篡改的检测和定位操作。 双线性池化主要用于特征融合,对于从同一个样本提取出来的特征X和特征Y,将2 个特征相乘得到矩阵b,对所有位置进行求和池化操作得到矩阵ξ,最后把矩阵ξ张成一个张量,记为双线性向量x,对x进行归一化操作之后,就得到融合后的特征。 为了加速计算和节省内存,本文采用文献[22] 提出的紧凑双线性池化。 池化层之后的输出是:
其中,fRGB是RGB 流的RoI 特征,fN是噪声流的RoI 特征。
1.6 Soft-NMS 算法
非极大值抑制算法[23]( Non - maximum suppression,NMS)是目标检测框架中的重要组成部分,主要用于去除冗余的建议框,找到最佳的目标检测位置。 具体做法是将RPN 推荐的建议框按照置信度得分排序,将得分最高的建议框作为候选框,删除与该框重叠面积比例大于设定阈值的其他建议框。 为了解决在预设的重叠阈值之内篡改区域检测不到的问题,本文采用Soft-NMS[16]算法,该算法改良了传统NMS 算法,对非最大得分的建议框检测分数进行衰减,降低了目标区域被漏检的概率。
传统的NMS 的分数重置函数如下:
其中,si表示置信度分数;M表示当前得分最高的候选框;bi表示建议框;iou(Intersection over Union)表示交并比;Nt表示iou阈值。
在Soft-NMS 算法中,建议框bi与候选框M重叠区域比例越大,出现漏检的可能性就越高,相应的分数衰减应该更严重,于是Soft-NMS 中的分数衰减函数设计如下:
当2 个建议框的iou大于设定的阈值时,si的值就会相应减小,降低了因彻底移除而造成漏检的概率,从而达到检测精度的提升。
1.7 损失函数
图像经过特征提取网络的全连接层和softmax层之后得到了RoI 区域,还需要对这些RoI 区域做分类和边框回归。 总的损失函数如下:
其中,Ltotal表示总损失;LRPN表示RPN 网络中的RPN 损失;Ltamper表示基于双线性池化特征的交叉熵分类损失;Lbbox表示bounding box 回归损失;fRGB和fN是来自RGB 和噪声流的RoI 特征。
网络的训练是端到端的,输入的图像和提取的噪声特征的宽度调整为600 像素。 2 个支流RoI 池化后的特征维度均为7∗7∗1 024。 双线性池化之后的特征尺寸为16 384。 训练过程中RPN 推荐的batch size是64,测试时设为300。 算法一共训练110 000 次,初始学习率设置为0.001,从第40 000步开始减小为0.000 1,Soft-NMS 的阈值设为0.2。
2 实验结果和分析
为了验证双流卷积注意力网络算法的有效性,本文在CASIA[24-25]、COVER[26]和Columbia[27]三个主流图像数据集上评估算法的性能。 CASIA 数据集提供了多种物体的拼接和复制-粘贴操作,该数据集有CASIA 1.0 和CASIA 2.0 两个版本,其中CASIA 1.0 包含800 张真实图像和921 张篡改图像,CASIA 2.0 包含7 491 张真实图像和5 123 张篡改图像。COVER 数据集是较小的复制-粘贴数据集,包含真实图像和篡改图像各100 张。 Columbia 数据集是未压缩的拼接数据集,包含180 张拼接篡改图像,183张真实图像。 由于现有标准数据集的图片数量仍然较少,尚不能满足深度学习的训练过程,因此,本文在文献[13]合成的数据集进行预训练,Zhou 等学者在COCO 数据集[28]中复制图像内容后粘贴到其他图像上,复制的依据是图像的分割标注信息,真实图像和篡改图像各42 000 张。
2.1 评价指标
本文使用F1分数和AUC值来评估所提出的双流卷积注意力网络的性能。F1分数是将精确率(P) 和召回率(R)结合的一种度量,精确率是指正确分类的正样本个数占分类器判定为正样本的样本个数的比例,见式(9):
召回率指分类正确的正样本个数占真正的正样本个数的比例,见式(10):
F1分数是精确率和召回率的调和平均值,见式(11):
其中,TP为正确检测到的篡改像素数,FP为错误检测到的篡改像素数,FN为错误检测到的未篡改像素数。
F1分数越高,说明模型越稳健。AUC值是ROC曲线下的面积值,AUC值的大小反映模型泛化能力,AUC值越大,模型泛化能力越强。
2.2 网络预训练
本文将合成数据集的90%用来预训练,余下的用来测试。 训练的过程是端到端的,特征提取网络分别对比使用了CBAM - ResNet101 和改进的CBAM-ResNet101。 本文对比了文献[13]的预训练结果,见表1,这里使用平均精度(Average Precision,AP) 进行评估,结果表明精度有了明显提升。 预训练之后,网络需要在公共数据集上做进一步训练,表2 给出了训练集和测试集的划分。

表1 合成数据集平均精度比较Tab. 1 Comparison of the average accuracy of synthetic datasets

表2 训练集和测试集的划分Tab. 2 The division of training and testing sets
表1 中,RGB Net 是一个单独的RGB 网络,Noise Net 是单独的噪声流网络,RGB-N 是双流网络,RGB-N+CBAM 为加入卷积注意力的算法,最后一行为是本文改进的算法。 由表1 中数据可知,单一的RGB 流或噪声流提取的信息有限,双流网络综合RGB 流和噪声流的特征信息后,平均精度有了明显提升。 在双流网络中引入卷积注意力机制后,提取到的特征图包含更丰富的篡改特征信息,经过Soft-NMS 算法降低漏检的概率后,平均精度有所提高。 改进的注意力机制避免了降维带来的副作用,更有效地利用了不同通道间的依赖关系,进一步提升了网络的特征提取能力。
2.3 结果对比
现有图像篡改取证方法分为传统算法和基于深度学习的算法,本文与以下方法进行对比分析。
(1)ELA[29]:识别图像中处于不同压缩因子的区域的算法。 对于JPEG 图像,整个图像应处于大致相同水平,如果某个区域压缩因子明显不同,则表示可能被篡改。
(2)CFA1[30]:基于CFA 模型的评估算法。 利用相邻像素来估算彩色滤波器阵列并推理出篡改区域。
(3)MFCN[9]:基于边缘强化的多任务图像被动取证框架。
(4)RGB-N[13]:融合噪声信息的双流神经网络算法。
(5)RGB+ELA[31]:基于双流Faster R-CNN 的像素级图像拼接篡改定位算法。
本文采用F1分数和AUC值对比上述5 种算法,结果见表3、表4。 表3、表4 的数据表明,基于深度学习的算法优于传统特征提取算法,原因是ELA 和CFA1 算法都只关注单一篡改特征,并且不能包含全部篡改信息。 在深度学习算法中,本文所提算法表现优于MFCN,在CASIA 和COVER 数据集表现优于RGB-N。 MFCN 性能较差的原因是采用小尺寸卷积核和上采样操作导致底层特征损失,因此对小区域篡改不敏感。 RGB-N 采用大小不同的锚框(anchor)进行定位,较小区域的篡改也可以被检测到,本文在特征提取模块引入改进的CBAM 注意力机制,并在预测时采用Soft-NMS 降低漏检概率,检测结果在3 个数据集上都有所提升。 文献[31]通过将SRM 滤波器替换为错误等级分析算法使提取到的噪声信息包含更多篡改信息,并添加一个预测分支做到了像素级分类。 相比文献[31],本文算法在Columbia 数据集上略优,由于CASIA 数据集拼接区域较为复杂,并且错误等级分析对篡改特征的提取效果优于SRM,故本文算法性能略低于文献[31]算法。 因为COVER 数据集是复制粘贴数据集,所以来自噪声流提供的特征信息几乎失效,因此在该数据集表现较差。

表3 3 个公共数据集F1 分数对比Tab. 3 Comparison of F1 scores from three public datasets
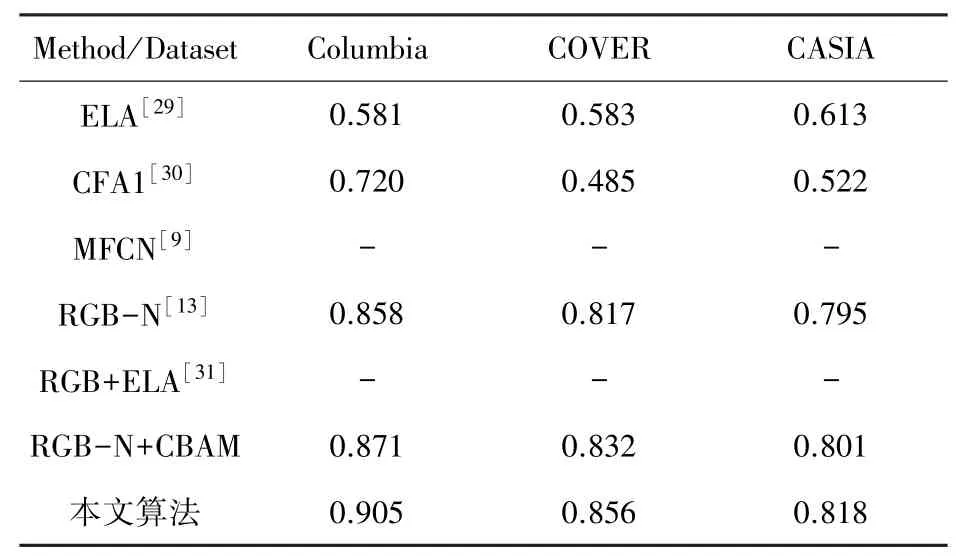
表4 3 个公共数据集AUC 值对比Tab. 4 Comparison of AUC values for three public datasets
2.4 检测结果分析
本文算法篡改检测定位效果如图8 所示。 图8中,(a)表示拼接篡改图像,(b)表示ground-truth,(c)表示文献[31]算法检测定位结果,(d)表示RGBN+CBAM 定位结果,(e)表示RGB-N+ICBAM 定位结果。 图像均来自于CASIA 1.0 数据集。 可视化结果显示,对于拼接边缘较为简单且篡改部分相对较小的区域如第3 列和第6 列,文献[31]所提算法和本文算法都能给出较为精确的定位结果,而对于拼接边缘较为复杂、且篡改部分相对较大的区域,文献[13]给出的可视化结果表现欠佳,也会存在未检测到的区域和检测错误的区域,本文算法则给出了篡改区域的矩形范围。 改进后的注意力通过有效的通道注意力使提取到的篡改痕迹更加丰富,体现在可视化结果中表现为定位的矩形区域更加接近Ground Truth。

图8 拼接篡改定位可视化Fig. 8 Visualization of image splicing detection
2.5 鲁棒性分析
为了验证本文算法的鲁棒性,在CASIA1.0 数据库上利用质量因子QF =70 和QF =50 对图像进行JPEG 压缩,表5 给出了本文算法、文献[13]和文献[31]所提算法的F1分数对比。 结果显示,在QF =70 时,RGB-N 性能下降了23.0%,文献[31]所提算法性能下降了27.9%,在QF =50 时,RGB-N 性能下降了26.3%,文献[31]所提算法性能下降了31.7%,而本文所提算法通过在通道和空间维度对篡改痕迹进行更有效的特征提取,在QF =70 和QF =50 的情况下对比未压缩时分别下降17.7%和25.6%。 从表5 中可以进一步看出,除了在未压缩时F1分数略低于文献[31]的算法,本文所提算法在2 种不同的质量因子情况下性能均优于现有算法,说明本文算法能够更好地抵抗JPEG 压缩攻击。

表5 不同压缩因子下算法的F1 分数Tab. 5 The F1 score of the algorithm under different compression factors
3 结束语
本文提出了一种双流卷积注意力网络对图像篡改区域进行检测和定位。 首先,改进的卷积注意力机制能够抑制图片中无效信息,使提取到的特征更好地刻画伪造特性,双流网络加入噪声域信息可以学习更多丰富的特征;其次,通过引入Soft-NMS 算法降低了伪造区域漏检的概率,提升了拼接篡改的检测精度。实验结果表明,本文算法的检测性能优于一些现有算法,且对JPEG 压缩也具有较好的鲁棒性。 本文算法尚不能做到像素级定位,未来的工作将考虑改进当前网络,进一步精准定位篡改区域。
