融合多记忆模块的半监督单图像去雨方法
2023-02-28李晓洁臧梦薇陆宏菊
刘 岳,崔 嘉,李晓洁,冯 玲,臧梦薇,陆宏菊
(1 山东师范大学信息科学与工程学院,济南 250358; 2 华南理工大学设计学院,广州 510640;3 泰山学院信息科学技术学院,山东 泰安 271021; 4 广州城市理工学院,广州 510850)
0 引 言
单图像去雨是指从单幅的有雨图像中恢复无雨的干净图像。 近年来,单图像去雨研究备受关注,其对于户外计算机视觉任务非常重要,是必不可少的预处理步骤,尤其适用于自动驾驶、场景分割、目标跟踪等任务。 因此,有效的去雨技术通常有助于进行更好的、更准确的图像检测或识别。 由于真实场景中雨结构的复杂多样性,单图像去雨仍是一个具有挑战性的问题。
2011年,Kang 等学者[1]首次提出单图像去雨问题,近年来基于深度学习的方法被引入到单图像去雨任务中,通过训练CNN 网络检测并消除雨纹,可以提高单图像去雨任务的性能。 在该任务上,基于深度学习的方法大多数都采用的是监督学习方式来训练网络的,全监督学习方式训练网络依赖雨图/无雨图像对。 受各种因素的限制难以获得成对的真实的雨图/无雨图像,所以现有的方法通常是在合成的雨图数据集上进行训练。 合成雨图数据集主要是采用在无雨图像合成添加雨纹,尽管合成雨纹的技术在不断进步,但是合成的雨图与真实的雨图在分布上仍然存在着很大的差异,真实雨图要比合成雨图复杂得多。 在合成数据集上训练的模型可能很难推广到现实世界的实际应用中。
为了解决这个问题,一些基于半监督学习的去雨方法[2-4]被提出,将有监督的合成数据的去雨知识迁移到无监督的真实数据的去雨上。 虽然现有的半监督方法已经取得了不错的效果,但由于缺少真实雨图信息,仍存在对真实雨纹的识别能力较差、图像细节丢失等问题。 所以,真实图像的去雨任务仍然是一个开放且具有挑战性的问题。
本文提出了一种融合多记忆模块的半监督单图像去雨网络,此网络分为2 个分支-监督分支和无监督分支,2 个分支共享网络参数。 网络可以同时对标记的合成图像与未标记的真实图像进行训练,具体来说,监督分支在标记的合成图像上进行训练,而无监督分支在未标记的真实图像上进行训练。 本文提出使用记忆模块对多次特征向量进行建模,提高网络对多种雨纹/雨滴的识别能力,可以有效处理不同类型的雨图图像。 本次研究在不同数据集上进行的大量实验表明,与现有方法相比,使用提出的基于多记忆模块训练的半监督框架将未标记的真实数据合并到训练过程中可以获得与之相当的性能。
1 相关性工作
1.1 基于模型驱动的去雨方法
单图像去雨技术可以分为2 类[5]:基于模型驱动(非深度学习)的方法和基于数据驱动(深度学习)的方法。
基于模型驱动的方法将单图像去雨表述为层分离问题。 Kang 等学者[1]提出了一种基于单幅图像的雨条纹去除框架,将雨条纹去除定义为基于形态成分分析的图像分解问题。 Luo 等学者[6]提出了一种变分模型,该模型使用了一种称为屏幕混合模型的非线性复合模型来建模降雨图像,同时从输入图像中检测和去除雨纹。 Chen 等学者[7]提出了一种从矩阵到张量结构的低秩模型来捕捉时空相关的雨条纹。 Sun 等学者[8]提出了一种基于学习的方法,提倡增量字典学习策略来表示高频图像。 Wang 等学者[9]提出了一种基于图像分解和字典学习的高效算法,从单幅彩色图像中去除雨雪。 这些方法可以有效地去除中小尺度的雨纹,但无法处理大而尖锐的雨纹。
1.2 基于数据驱动的去雨方法
近年来,基于深度学习的方法被引入到单图像去雨任务中,并取得了显著的效果。 Fu 等学者[10]首先引入了一种端到端的残差卷积网络来去除雨纹。 Yang 等学者[11]在多任务网络中联合检测并清除了雨水。 Hu 等学者[12]设计了一个深度关注网络来处理雨纹和雾霾。 以上这些方法都采用了先进的网络架构通过监督方式学习,在数量和质量上都取得了更好的结果。 尽管这些方法在合成降雨数据集上的表现令人印象深刻,但由于合成训练数据和真实测试数据之间的差距,这些方法在现实场景中的性能显著下降。 为了解决这个问题,Wei 等学者[2]首先提出了一个半监督学习框架,同时利用监督和无监督的学习方式进行图像去雨,该方法通过对高斯混合模型施加一个似然项来模拟真实的雨残差,并最小化合成雨和真实雨分布之间的KL 散度。 随后,Yasarla 等学者[4]提出了一种基于高斯过程的半监督方法,该方法使用高斯过程对雨图图像的潜在特征进行建模,并为未标记的数据创建伪标签。 最近,Huang 等学者[3]提出了一种基于面向记忆的半监督的迁移学习框架,自监督记忆模块可以记录不同的雨退化原型,并且通过自监督的学习方式进行更新,自训练模块用于为无标签数据生成伪标签,将有监督去雨的知识迁移到无监督去雨上。 虽然现有的半监督方法对真实图像的去雨效果有所提高,但仍存在对真实雨纹的识别能力较差、图像细节丢失等问题。
1.3 记忆网络
传统的具有记忆功能的循环神经网络RNNs(包括LSTM[13],GRU[14]等)是将隐层信息压缩成一个密集向量,能够存储的信息十分有限。 为了解决这一问题,Weston 等学者[15]首先提出了记忆网络,通过逐个搜索支持记忆产生输出,其核心思想就是为传统的推理模型增加了一个可读写的外部记忆组件以便更好地存储长期记忆,从而成为一个动态的知识库来为推理组件提供更完整的推理信息。Sukhbaatar 等学者[16]提出了一个端到端的记忆网络,是一种连续形式的记忆网络,其中每个记忆项根据记忆与查询之间的内积进行加权。 本文的工作把Huang 等学者[3]的工作中对记忆模块的更新策略作为启发,尝试更新记忆模块中的雨纹模型并使用半监督学习的方式实现多种雨图像类型的去雨工作。
2 本文方法
2.1 网络框架
本文提出了一个融合多记忆模块的半监督去雨网络,用于提高合成图像和真实图像的去雨能力。网络框架如图1 所示。 本文网络结构分为2 个分支:监督分支和无监督分支。 其中,监督分支在标记的合成雨图上进行训练,而无监督分支在未标记的真实雨图上进行训练,2 个分支共享相同的网络、即MMR。 在监督分支训练中,通过重构损失和感知损失对得到的去雨图像和相应的无雨参考图像(Ground-Truth,GT)之间进行约束。 在无监督分支训练中,通过总变分损失和本体映射损失进行约束,以避免监督分支过度拟合训练数据集。

图1 网络框架Fig. 1 Network structure diagram of this paper
semi-MMR 的详细结构如图2 所示。 由图2 可知,MMR 由编码器-解码器和3 个记忆模块组成,以提高对多种雨纹模型的识别能力并恢复图像细节。编码器-解码器用来提取雨纹特征,记忆模块用于存储并更新雨纹特征实现多种雨纹的识别。 具体来说,雨图图像作为网络的输入,通过编码器映射得到特征向量,不同层次的特征向量通过记忆模块中记录的雨纹模型进行更新,将更新的特征向量馈送到解码器以产生雨纹特征,然后将雨图与得到的雨纹特征做差以获得网络的输出、即去雨图像。
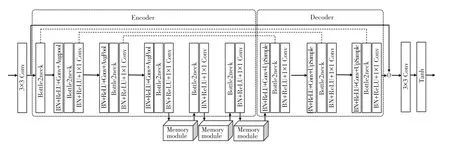
图2 semi-MMR 的详细结构Fig. 2 The detailed architectures of the semi-MMR
2.2 网络结构
本文方法的每个组成部分如下。
2.2.1 编码器-解码器
编码器-解码器是基于UNet 型[17]构建的,图2是所提出网络的编码器和解码器的网络结构。 其中,用Bottle2neck 块作为网络的基本组件,充分利用多尺度信息,提高雨纹特征的识别能力。 Bottle 2neck 结构如图3 所示,在每个Bottle2neck 块[18]内构造类似特征金字塔的结构,取代了通用的单个3×3 卷积核,在特征层内部进行多尺度的卷积,形成不同感受野,获得不同细粒度的特征。
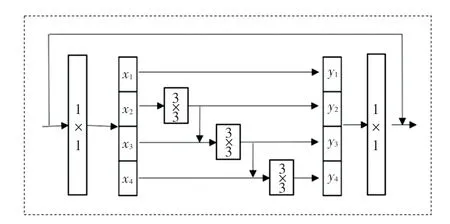
图3 Bottle2neck 结构图Fig. 3 Bottle2neck structure
2.2.2 记忆模块
记忆模块的详细结构如图4 所示。 基于Huang等学者[3]的工作中对记忆模块更新的思想,每个记忆模块中的记忆块都是由512 个记忆项组成,记忆项用于存储各种雨纹特征模型。 每个记忆模块都有2 个步骤。 步骤1 用于更新记忆项,步骤2 用于更新特征向量。 这里给出研究分述如下:
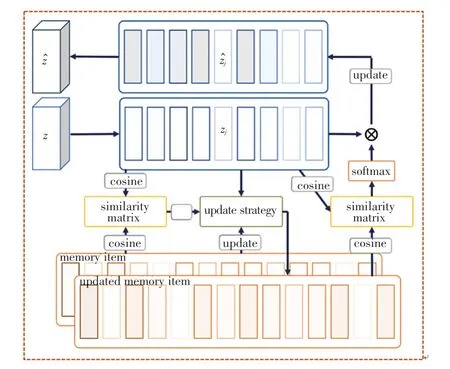
图4 记忆模块结构Fig. 4 Memory module structure
步骤1更新记忆项。 具体来说,可将特征向量,n =h × w作为一个查询项,检索与之最相关的记忆项mi并以自我监督学习的方式更新记忆项,更新策略如下:
其中,τ是衰减率;ε是一个极小参数以避免分式为0;sij是zj与mi的余弦相似性矩阵;1(·) 是一个指示函数,如果参数为真则输出值1,否则输出值0。
步骤2更新特征向量。 首先,计算特征向量和更新后的记忆项之间的相似矩阵S ={sij},然后通过归一化(softmax) 运算得到注意力矩阵A ={aij}。 最后,通过式(2)计算特征向量z,即:
以上是记忆模块的计算流程。
2.3 损失函数
本文的损失函数由2 种损失函数组成,分别是监督损失函数和无监督损失函数。
2.3.1 监督损失函数
在监督训练阶段,使用标记的合成数据来学习网络参数,监督损失函数由重构损失函数和感知损失函数组成。
重构损失Lr是合成数据的参考图像Os与网络生成的无雨图像之间的L1损失,即:
感知损失Lp是利用一个训练好的分类网络所具备的图像语义信息感知的能力来缩小合成数据的参考图像Os与网络生成的无雨图像在特征空间之间的距离,表示为:
其中,Φ(·) 是在ImageNet 上预训练的VGG16网络的conv2,3 层。
因此,监督损失函数Lsu表示为:
其中,λp是感知损失函数的参数。
2.3.2 无监督损失函数
在无监督训练阶段,使用未标记的真实数据来学习网络参数,无监督损失函数由总变分损失函数(Total Variation loss,TV loss)和本体映射损失函数(Identity loss)组成。
总变分损失函数LTV是用来约束网络生成的无雨图像Opred r的平滑度以保留图像的结构和细节,表示为:
其中,∇h和∇v分别表示水平和垂直微分算子。
本体映射损失函数LI是用来约束真实的雨图图像Ir和网络生成的无雨图像Opred r之间的结构差异以提高生成的无雨图像的质量,表示为:
因此,无监督损失函数Lunsu表示为:
其中,λTV是总变分损失函数的参数,λI是本体映射损失函数的参数。
训练过程的总损失函数表示为:
其中,λunsu是一个预定义的权重,用来控制Lun和Lunsu对网络的贡献。
3 实 验
3.1 实验数据集及评价指标
3.1.1 实验数据集
本文同时使用合成数据集和真实数据集训练和评估网络模型。 在监督训练阶段中,分别使用3 个基准合成数据集训练模型,Rain200L[11]数据集由1 800对训练图像和200 对测试图像组成,其中只包含一种类型的雨纹且雨纹密度较低;Rain200H[11]数据集由1800 对训练图像和200 对测试图像组成,其中包含5 种类型的雨纹且雨纹密度较强,更贴近于实际应用中的情况;Rain800[19]数据集包含700 对训练图像和100 对测试图像,其中每个图像都包含一个或多个不同方向或密度的雨纹图像。 在无监督训练阶段中,使用从SIRR[2]、Syn2Real[4]和谷歌搜索中搜集的150 张真实雨图图像作为真实数据集(real-data),其中120 张作为训练数据,30 张作为测试数据。
3.1.2 评价指标
由于合成的雨图图像存在ground-truth,因此可以使用峰值信噪比(PSNR[20]) 和结构相似指数度量(SSIM[20]) 来评价降雨去除方法的性能。 而真实的雨图图像不存在ground-truth,采用自然图像质量评估器(NIQE[21]) 和基于感知的图像质量评估器(PIQE[22]) 等无参考图像评价指标对图像质量进行评估。
3.2 参数设置
本文使用PyTorch 深度学习框架,python3.6 编程语言,Ubuntu18.04 系统,Tesla A30 的GPU 进行训练。 在训练过程中,图像被随机裁剪为256×256的大小,训练世代数设置为500epochs,batchsize设置为4。 初始学习率设置为0.002,使用Adam 优化器对参数进行优化。 所有的后续实验均在相同环境设置下进行。 相关参数设置如下:衰减率τ设置为0.999,极小参数∊设置为1e-6,感知损失函数参数λp设置为0.04,总变分损失函数参数λTV设置为0.01,本体映射函数参数λI设置为0.1,总无监督损失函数参数λunsu设置为0.5。
3.3 消融实验
为了验证本文所提出的网络结构和损失函数的有效性和优越性,分别对网络的分支、损失函数等因素进行了消融实验。
在本文中,提出了半监督框架,该框架使用监督/无监督分支共同利用合成/真实训练图像来训练模型。 2 个分支共享相同的网络结构,并结合2 个监督/无监督损失提供相应的信息来约束网络训练。为了验证无监督分支的有效性,去掉无监督分支,只使用合成数据集来训练模型。 对不同分支的消融实验见表1。 表1 中,Input 表示未经处理的真实雨图图像,MMR 是指仅使用合成数据集Rain800 上训练的模型,Semi-MMR 是指在本文所提出的方法在Rain800 & Real-data 上训练得到的模型,通过对NIQE和PIQE值的比较,证明了本文半监督方法的有效性。
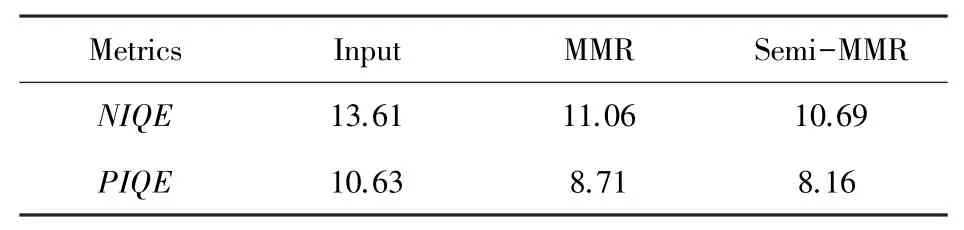
表1 对不同分支的消融实验Tab. 1 Ablation experiments on different branches
此外,为了验证半监督分支的2 项损失函数都有助于提高模型性能,本文对损失函数进行了消融实验。 对损失函数的消融实验结果见表2。 表2中,Q1表示仅在无监督分支使用总变分损失函数LTV,Q2表示仅在无监督分支使用本体映射损失函数LI,Q3表示本文方法在无监督分支所使用的总损失函数,即同时使用LTV和LI。 从表2 中可以看出,2项损失函数对去雨效果都有不同程度的增强作用。
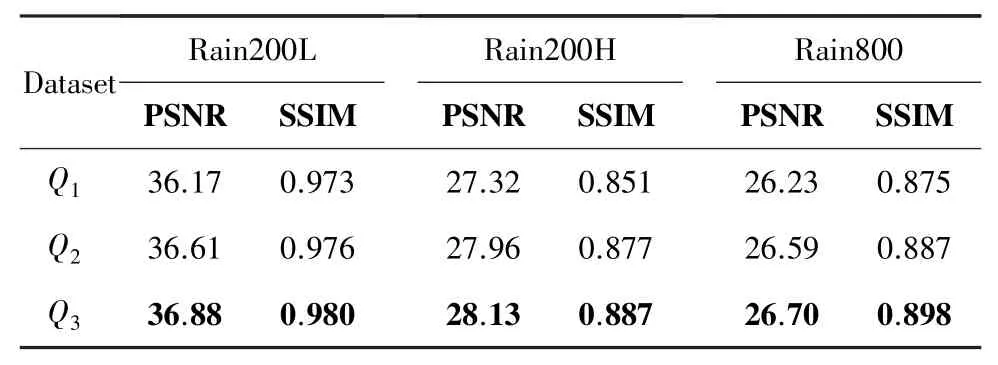
表2 对损失函数的消融实验Tab. 2 Ablation experiments on loss functions
3.4 对比实验
将本文方法与4 种其他的单图像去雨模型进行比较,其中包括2 种监督学习模型(DDN[10],PReNet[23]) 和2 种半监督学习模型(SIRR[2],Syn2Real[4])。 2 种监督学习模型直接在Rain200H、Rain200L、Rain800 上进行训练,半监督学习模型在Rain200H & Real-data、Rain200L & Real-data 和Rain800 & Real-data 上进行训练。
3.4.1 合成数据的对比实验
首先在合成数据集上评估每种方法。 在合成数据集上进行定量分析,采用PSNR和SSIM作为评价标准,数值越大,表示结果更好。 对合成数据的定量分析结果见表3。 表3 中,“∗”表示模型分别在合成数据集和真实数据集上训练。 从表3 中可以看出,本文模型在3 个数据集的测试数据上都获得了最好或相当的性能。 本文模型的PSNR 值在3 个数据集的测试数据上与其他方法相比均获到了不同的增益,SSIM值在Rain200L 和Rain200H 数据集的测试数据上取得了最大值,但在Rain800 上比PReNet模型的值略低。
在合成数据集上进行定性分析,图5~图7 是分别在3 个合成数据集上的可视化效果,从图5 中可以看出: 在Rain200L 上SIRR 和Syn2Real 能够去除部分雨纹,但图像中仍然会存在一些未能去除的雨纹;在Rain200H 上存在类似的结果,而且图像中存在伪影,效果不理想;在Rain800 上,SIRR 的去雨效果良好,但某些图像色彩出现了偏差,Syn2Real 的去雨效果不甚理想,图像中仍存在大量雨纹。 本文方法在3 个数据集上均可以去除大部分的雨纹,并且去雨图像的细节保持得也较为完整,与GT 最为接近,体现了本文方法的优越性。

图5 在Rain200L 数据集上的比较Fig. 5 Comparison on the Rain200L dataset

图6 在Rain200H 数据集上的比较Fig. 6 Comparison on the Rain200H dataset

图7 在Rain800 数据集上的比较Fig. 7 Comparison on the Rain800 dataset
3.4.2 真实数据的对比实验
研究中,还在真实数据集Real-data 的测试集上对本文方法进行分析。
以Rain800&Real-data 作为训练基础进行定量分析,采用NIQE 和PIQE 作为评价标准,数值越小、表示结果更好。 对真实数据的定量分析结果见表4。 从表4 中可以看出,本文方法取得了最低的NIQE 值和PIQE 值,体现了本文方法的优越性。
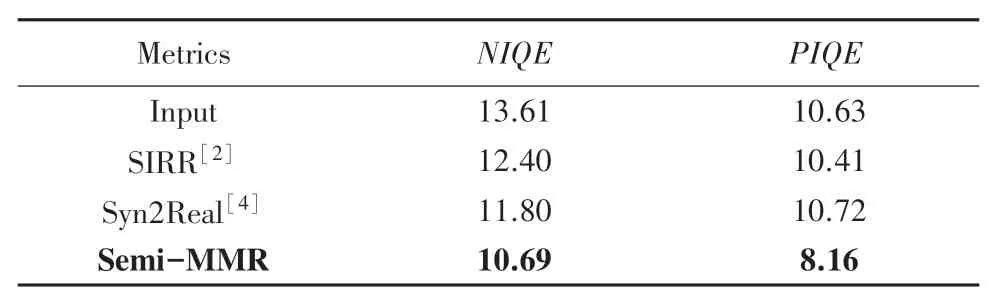
表4 对真实数据的定量分析Tab. 4 Quantitative analysis of real-world data
在真实数据集上进行定性分析,可视化结果如图8 所示。 SIRR 方法能识别大部分的雨纹,但细节恢复能力较差,存在一些过度平滑的结果;Syn2Real方法能实现较好的视觉效果,但图像仍能看到未去除的雨纹;本文方法处理得到的图像结果清晰,细节恢复较好,可以有效提高真实图像的去雨效果,提高了模型的实用性。

图8 在Real-data 数据集上的比较Fig. 8 Comparison on the Real-data dataset
4 结束语
在本文中,尝试用融合多记忆模块训练的半监督框架来解决单图像去雨问题。 本文在标记的合成雨图和未标记的真实雨图像上训练网络,通过多记忆模块对中间潜在向量进行建模,提高了网络对多种雨纹/雨滴类型的识别能力。 本文方法很大程度上缓解了传统的深度学习方法在该任务上存在的问题,即合成数据训练的网络难以实际应用的问题。此外,在合成数据集和真实数据集上的实验均验证了本文方法有效性,显著提高了当前基于深度学习方法的单图像去雨模型对真实雨图的鲁棒性。 本文方法仍然不能适用于所有可能极其复杂的雨天图像。 在网络训练中更精细地减小合成域和真实域之间的差异,可能是进一步提高该任务性能的未来方向。
