面向大规模胸片图像的深度哈希检索
2023-02-21管安娜刘骊付晓东刘利军黄青松
管安娜,刘骊, 2*,付晓东, 2,刘利军, 2,黄青松, 2
1. 昆明理工大学信息工程与自动化学院,昆明 650500; 2. 云南省计算机技术应用重点实验室,昆明 650500
0 引 言
随着医院PACS(the picture archival and communication system)的广泛应用,医学图像的数据量迅速增加,高效处理大规模的医学图像数据成为辅助医疗诊断的有效途径之一。通过有效的医学图像检索不仅能够帮助临床专家对疾病的预测和诊断进行决策,而且可以利用检索得到以往类似图像和病例信息,以实现医疗教学;另外,通过精准的医疗图像检索可提供与患者相似的病例图像,作为辅助病症参考。基于文本和基于内容的图像检索方法在医学图像检索中有许多应用(Hwang等,2012)。基于文本的图像检索是通过人工注释的文本描述来检索图像,既耗时又费力,而且用有限的文字难以描述医学图像的内容。相比之下,基于内容的图像检索使用源自图像的特征,例如纹理、颜色和形状,不需要费时和主观的人工标记。例如,吴梦麟等人(2013)针对医学图像底层特征难以描述语义信息的问题,采用图半监督学习提取语义相似度,并结合底层特征和语义特征进行相似性度量。
区别于通用图像,医学图像侧重于提取病灶区域信息来检索具有相似病例的图像(Li等,2018),其特殊性在于:1)大多数是灰度图,噪声较大,某些传统特征并不适用医学图像检索;2)由于成像方式原因,不具备病理意义的区域可能会模糊关键区域之间的差距;3)临床上有用的信息大多高度局限于图像的小区域,存在极大的多样性和复杂性,单独提取它们的全局特征通常不能很好地表示医学图像。本文以胸片图像为例,胸片图像就是胸部X光片,为常规体检项目之一。其不仅具有医学图像的特殊性,也有其独特的地方。速度和经济的优势使胸部X光片成为胸部检查的首选,因此具有较大的图像数据库。此外,胸部X光可以清楚地发现肺部的大体病变,例如肺炎和肿块,所以在临床护理和流行病学研究中发挥着重要作用。
Silva等人(2020)提出一种基于可解释性显著图的方法来检索胸片图像,学习显著图得到深层特征表示,通过欧几里得排序进行检索。Kashif等人(2020)从图像中提取特征并计算语义和视觉相似度,使用无向图进行最短路径算法来检索相似图像。然而,以上方法的检索性能在大数据库上通常受到限制。传统的图像检索方法已经难以高效处理海量数据,将特征哈希与深度学习相结合的深度哈希技术已成为图像检索的发展方向(刘颖 等,2020)。而针对大规模的图像数据,深度哈希检索(Ahmad等,2018)方法能够有效降低存储成本、提高查询速度,避免“维数灾难”。
目前,面向大规模的胸片图像检索仍然存在以下问题:1)如何将深度哈希检索与海量胸片图像结合,解决“维数灾难”,提升检索效率。2)由于胸片图像的类间相似度较高、病灶区域位置较小且难以分辨,导致特征提取时容易遗漏重要病灶信息,影响检索准确率。3)胸片图像噪声较大,仅考虑图像整体特征会由于包含病变区域之外的很大一部分噪声,导致对病变区域的误判;仅考虑图像局部特征会在获取病变信息分布全图时导致重要信息的丢失。4)针对现有的哈希方法学习的哈希码会丢失感兴趣区域和分类信息,导致大规模医学图像检索中小样本检索结果的排序质量降低。
为了解决这些问题,本文提出一种面向大规模胸片图像的深度哈希检索方法,流程图如图1所示。本文方法主要包括特征学习和哈希码优化两个模块。在特征学习模块中,除了获取图像的整体表示(即全局特征)外,构建空间注意模块获取胸片图像的病灶区域(即局部特征)。此外,将两种特征进行融合,相互补充,进一步完善图像的特征表示。在哈希码优化模块中,为了解决分类信息丢失以及排序问题,定义量化损失、二值交叉熵损失和正则化损失的联合函数进行优化学习。
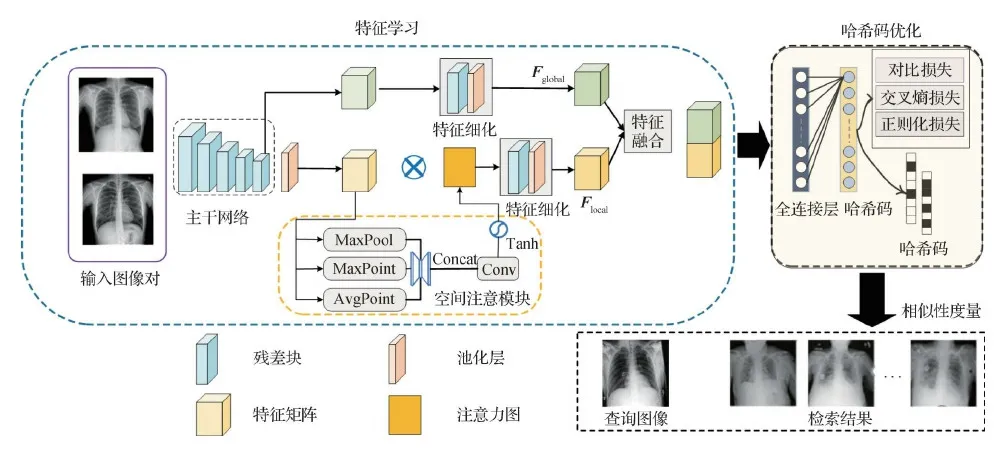
图1 大规模胸片图像深度哈希检索方法流程图
本文的主要贡献如下:1)针对胸片图像类间相似度较高、病灶区域位置较小的问题,构建空间注意模块,挖掘胸片图像的显著区域表示,提取局部特征,增强哈希码的识别能力,提高后续检索的精度;2)在特征提取时,针对胸片图像噪声较大导致的信息丢失问题,定义特征融合模块,对细化后的局部特征和全局特征进行融合,解决病变信息丢失问题,以提高检索结果的准确率;3)在大规模胸片图像检索中,针对哈希学习方法因易丢失病灶区域和分类信息导致的结果排序质量较差问题,定义结合对比损失、交叉熵损失和正则化损失的联合函数,引入深度哈希训练网络中,使实值输出更接近2进制哈希码,提升了检索结果的排序质量。
1 相关工作
根据对数据的处理方式,哈希方法分为数据无关方法和数据依赖方法两类(刘颖 等,2020)。数据无关方法通过独立训练数据得到哈希函数。其中,局部敏感哈希方法(Indyk和 Motwani,1998)是常用的一种数据无关方法。数据依赖方法需要对训练数据进行学习以获得更好的检索性能,也称为学习哈希算法(Kong和Li,2012)。哈希深度学习方法在医学领域的应用取得了巨大成功。Liu等人(2014)采用锚图算法将乳房X光片特征压缩成紧凑的2进制码,以较高的概率保持图像特征空间的领域结构,从而减少存储空间和计算复杂度。Chen等人(2018)将多病症检索问题看做一个多标签哈希学习问题,提出一种基于顺序敏感的深度哈希方法,通过排序表和多标签分类获取多级语义相似度,结合排名损失和多标签分类损失更好地利用多标签信息。Jiang等人(2015)提出一种基于词汇树的图像检索框架,利用词汇树对特征信息进行细化算法,提高了X光片图像的检索精度。Shi等人(2018)给出基于成对的深度哈希排序算法,针对肺癌图像的特殊性设计成对向量,根据向量中的标签信息学习图像特征和2进制码,有效提高了分类准确性。Haq等人(2020)提出一种基于社区的大规模胸片图像检索方法,通过深度学习得到图编码,根据图编码将相似图像划分为社区,在社区中度量检索,在两个大胸片数据集上进行实验,得到了较好的检索性能。本文从提升胸片图像检索结果的排序质量角度入手,提出面向大规模胸片图像的深度哈希检索方法。
注意力机制已成功应用于卷积神经网络(convolutional neural network,CNN),显著提高了许多医学图像任务的性能(Nie 等,2018),例如分割、分类和检索等。Li等人(2019)提出一种基于注意力的青光眼检测网络,通过注意力预测子网将特征可视化为局部病理区域,提高了青光眼检测及病理区域定位的性能。Woo等人(2018)提出一个注意模块CMBA(convolutional block attention module)。这个模块推导出的特征图包含通道和空间两个维度的信息,实验验证其优于仅使用通道注意力模型的方法。虽然性能得到了明显提升,但仍然会丢失一些小样本信息,导致结果排序质量不理想。Fang等人(2021)提出一个基于注意力的三元哈希(attention-based triplet hashing,ATH)网络以学习低维哈希码,该网络将注意力机制引入网络,结合了通道的最大值、平均值以及最大点值,联合上下文空间信息聚焦于感兴趣区域(regions of interest,ROI)区域。以上研究验证了空间注意机制可以通过捕获感兴趣区域信息来提高医学图像检索的性能。受ATH方法启发,本文在大规模胸片图像检索网络中设计了一个空间注意力机制,结合3个描述符聚焦胸片图像中的显著区域,获取局部特征。
对于基于内容的图像检索来说,图像特征提取是检索准确性的基石。由于单一特征只能从一个角度反映图像信息,因此在实际应用中,使用多特征融合比单一特征性能更为高效。全局特征捕捉图像的整体特征,而局部特征主要描述一组像素的特征,代表了细节。当病变信息只出现在图像相对较小的部分时,全局特征不能完全代表重要的视觉特征。Renita和Christopher(2020)提出使用grey wolf optimization-support vector machine进行医学图像检索,提取尺度和旋转不变特性以及纹理特征,之后采用单词包进行特征的映射。Qin等人(2019)提出一种全卷积稠密网络,分为编码和解码两个阶段,在编码部分提取图像丰富的语义特征,解码部分对带有语义特征的特征图进行上采样,并且使用联合距离将网络不同层的输出相加,作为最终图像检索的特征。Guan等人(2020)提出一种用于胸部疾病分类的卷积神经网络,利用注意力机制提取局部微小的病灶区域特征,再将局部和全局信息进行池化层融合来提高分类能力,得到更完整的一个图像表征。受以上工作启发,本文构建了特征融合模块,将提取并细化后的全局特征和局部特征进行融合,以获得更完整的图像表征,提高检索准确率。此外,由于模型训练过程中分类信息容易丢失,导致检索结果排序效果不佳。本文在哈希码学习模块设计一个联合损失函数来学习哈希码,用于保留分类信息,使特征更易区分。
2 特征学习
由于残差学习的使用有助于缓解深度架构的梯度消失问题,使训练更加稳定,且其跳跃连接是无参数的,不会增加模型的复杂性。本文采用ResNet50作为主干网络,构建了空间注意模块提取输入胸片图像的全局—局部特征,并引入特征融合及细化分支进行特征学习。
2.1 空间注意模块
为了关注胸部图像中的病灶区域特征,提高哈希编码的特征表达能力,本文构建了空间注意模块,如图1所示。
首先,使用3个描述符关注ROI区域。给定一个网络中间层特征图F∈RW×H×K,输出为注意力图MF∈RW×H×1;其中,K、H和W分别表示特征图的通道数、高度和宽度。沿通道轴使用元素最大值和元素平均值操作,生成两个不同的空间上下文信息FmaxP和FavgP。FmaxP表示沿通道计算每个元素的最大值,FavgP表示沿通道计算每个元素的平均值。二者定义为
(1)
(2)
式中,γi(c)表示在c通道上i元素的响应值,fi表示在第i通道所取得的响应值。
其次,为了关注信息部分,引入特征Fmax作为补充,Fmax为特征经过最大池化层压缩处理得到。MaxPool操作是对每个卷积层的最大局部响应进行编码,而MaxPoint操作是针对特征图最大点的响应。将所得的3个描述符分别输入一个共享的多层感知机(multilayer perception,MLP)进行去噪,然后将得到的输出连接并卷积成一个特征图,再经过正切激活函数。具体操作为
M(F)=ω(γ([MLP(Fmaxp);MLP(FavgP);MLP(Fmax)]))
(3)
式中,ω定义为正切函数,γ代表一个3×3的卷积操作。
在主干网络得到的特征图上,空间注意力模块联合应用了MaxPool、MaxPoint和AvgPoint操作,生成一个三通道特征图。对于每个像素,计算FmaxP补充了沿通道元素平均值的全局统计量,并结合FavgP更好地描述了通道的上下文特征。而最大池化操作Fmax则避免了显著区域的边际值减弱,提高了特征表达能力。因此,构建的空间注意模块有助于获取胸片图像中的显著区域信息,使网络在特征学习过程中专注于临床相关信息区域的特征提取。
2.2 特征融合
特征学习网络结构如图2所示。包含7×7的卷积层、3×3的最大池化层、残差块以及特征细化网络。其中,选取的残差块来源于ResNet网络,主要由一层3×3的卷积层、BatchNormal、ReLU(rectified linear unit)组成,如图3所示,使用了跳跃连接,解决梯度消失问题,从而便于网络加深。特征细化网络为一个独立的网络结构,由1个残差块和1个3×3平均池化层组成,用于将关注的特征嵌入更高层的语义中。

图2 特征学习网络结构
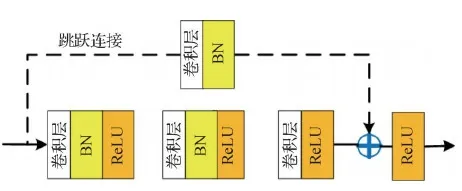
图3 残差块结构
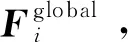
(4)
式中,f(·)为特征细化操作。
其次,提取局部特征。局部特征主要关注于病变区域,有效解决了仅考虑图像整体特征时由于大量噪声导致的误判问题。将Fi输入一个大小为3×3、步长为1的最大池化层中,得到特征F′i。通过最大池化处理,对Fi进行特征细节提取,突出影响较大特征的同时弱化一些不重要的特征,防止ROI区域的边际值减弱。然后,将F′i输入空间注意模块(2.1节)生成注意力图MF′i∈RW×H×1。将该注意力图MF′i与F′i相乘,得到注意局部特征F″i,计算为
F″i=MF′i⊗F″i
(5)
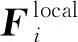
(6)
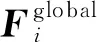
3 哈希码优化
为了得到高质量哈希码,改善结果排序质量,定义联合损失函数用于优化误差。常用的优化方法包括对比度量学习、三元组度量学习等(Li 等,2017)。对比度量学习可以更严格地对相似样本进行聚类,使优化结果更为准确。因此,本文将提取的全局特征和局部特征进行连接输入到哈希码优化模块。哈希码优化模块包含1个完全连接层FC和1个哈希层,引入结合对比度量学习、哈希码正则化和交叉熵损失的联合损失函数进行优化。哈希层上的节点数设置为k,与所需哈希码的长度相等。对于i=1,2,…,k的每一位哈希码,计算使用的函数为
bi=sign(f)
(7)
式中,f是卷积网络提取的高层语义特征。
为了缩小同类样本之间的距离,采用对比损失函数进行优化。该函数的输入为一对图像对,若为同一类样本,则通过优化缩小样本之间的距离;反之,存在一个阈值m,当不同样本之间距离小于m时,则互斥使样本之间的距离接近m。定义的对比损失函数为
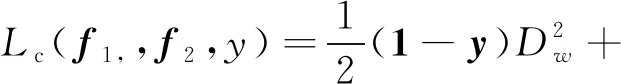
(8)
式中,f1和f2分别为输入样本对的高级语义特征;1是一个数值全为1的向量;定义n维向量y表示输入样本对的监督信息,当样本对相似时,yi=0;否则,yi=1。Dw为L2归一化,用于度量哈希码之间的距离。具体地,当样本对相似时,调整参数最小化f1与f2之间的距离;当样本对不相似时,分两种情况,如果f1与f2之间的距离大于m,不进行优化;如果f1与f2之间的距离小于m,增大两者距离到m,其计算式为
(9)
除了考虑对比损失,还定义了正则化项Lr使2进制码更接近于所需的哈希码。因此,为了优化映射函数,使网络输出近似于2进制哈希码,定义的目标函数表示为
(10)
式中,fi是网络输出的高层语义特征。
为了生成保持语义的哈希码,在上述损失函数的基础上增加了一个交叉熵损失。该函数利用多标签信息,有效约束同类样本的特征分布距离,交叉熵损失函数定义为
(11)
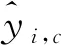
综上所述,本文定义的联合损失函数充分利用了胸片图像的标签信息和语义特征,结合式(8)中的对比损失、式(10)的正则化损失和式(11)的交叉熵损失,生成更具判别性的哈希码。本文哈希优化的联合损失函数表示为
L=Lc+αLr+βLcb
(12)
式中,α和β分别为正则化损失和交叉熵损失函数的权重。
在进行优化得到高质量哈希编码后,通过相似性度量方法计算得到检索结果。本文采用汉明距离(Hamming distance)计算哈希码之间的相似度,向量越相似,汉明距离越小,根据相似性对查询数据集进行升序排序,返回排名前k的图像。汉明距离计算为
d(x,y)=∑x[i]⊕y[i]
(13)
式中,x和y表示K维哈希编码,i=0,1,…,k-1,d(x,y)表示x与y之间的汉明距离,⊕表示异或操作。至此,通过以上方法输出最终的检索结果。
4 实验结果与分析
4.1 实验设置与评估标准
为了验证方法的性能,使用两个公开可用的大规模胸片数据集进行实验。1)美国国立卫生研究院(National Institutes of Health,NIH)的ChestX-ray8数据集(Wang等,2017),包含30 805名特殊患者的112 120幅正面X-ray图像,每幅图像附带有相关的文本挖掘疾病标签。2)美国斯坦福大学发布的CheXpert数据集(Irvin等,2019),包含223 648幅胸片和对应的病理报告。对检索任务,本文将数据集中原始图像的70%用于训练,30%用于测试。
实验采用Pytorch实现提出的网络框架,设备搭载Intel Core i9-9900k CPU @3.60 GHz, NVIDIA GeForce RTX 2080Ti GPU和64 GB DDR4 2 666 MHz RAM。训练网络时,使用带动量的小批量随机梯度下降(stochastic gradient descent,SGD)进行优化,最小批次设置为64,初始学习率为0.01,权重衰减为0.000 1,动量为0.9。共训练50个epoch,训练20个epoch后,学习率下降到0.001。通过交叉验证,将正则化损失参数α和交叉熵损失参数β设置为0.5。
评价指标采用哈希检索中常用的归一化折现累积增益(normalized discounted cumulative gain,nDCG)和平均精度(mean average precision,mAP)。其中,nDCG表示检索结果排名位置对检索结果的影响,mAP指检索图像的平均准确率。
4.2 实验结果与性能分析
4.2.1 检索结果及对比分析
为了验证本文方法的检索性能,与其他6种同任务的经典通用散列方法进行比较,包括SSH(semi-supervised hashing)(Wang等,2012)、ITQ(iterative quantization)(Gong等,2013)、DH(deep hashing)(Liong等,2015)、DSH(deep supervised hashing)(Liu等,2016)、DRH(deep residual hashing)(Conjeti等,2017)和ATH(Fang等,2021)。其中,DH、DSH、DRH和ATH是基于深度学习的哈希方法,其他是基于浅层的哈希方法。
为公平比较,采用相同数据集进行实验。表1展示了本文方法与其他哈希方法在ChestX-ray8和CheXpert数据集上的nDCG@100和mAP。可以看出,基于深度学习的哈希方法比基于浅层的哈希方法表现更好,本文方法的检索性能较其他深度学习的哈希方法具有一定优势。由于本文方法融合了全局和局部特征,并构建了用于深度哈希检索的特征融合模块,在ChestX-ray和CheXpert数据集中的nDCG比ATH方法分别提高了4%和3%,mAP值较ATH方法均提高了至少5%。此外,本文引入空间注意模块用于获取显著区域,在两个数据集上检索返回top-10的图像中,mAP值较DSH方法均有明显提升。实验结果表明,空间注意模块能够聚焦局部病灶显著区域,同时也验证了特征融合模块构建的必要性。

表1 本文方法与同任务哈希方法在ChestX-ray8和CheXpert数据集上的性能比较
本文方法与同任务的哈希方法在CheXpert数据集上的特征计算时间、检索时间、训练时间和显存占用等方面的效率如表2所示,表中数值是各项指标在整个测试集上的平均结果。可以看出,传统哈希检索方法的训练时间明显快于深度哈希检索方法,并且显存占用很小。而深度哈希检索方法都处于一个量级内。与4种深度哈希方法进行比较,由于嵌入了空间注意模块和特征融合模块,本文方法的网络训练时间和内存占用略高,特征计算时间和检索时间差距不大,但在结果准确率上有一定优势。

表2 本文方法与同任务哈希方法在CheXpert数据集上的效率比较
图4为本文方法部分查询图像的检索结果,每一行代表一组样本查询,第1列是查询图像,其他5列是前5个检索结果,每幅图像下面标注为疾病标签缩写,含义如表3所示。从图4可以看出,前两个检索示例展示了具有单个阳性标签的查询图像的检索结果,后两个查询示例展示了具有多个疾病标签的查询图像的检索结果。所有阳性疾病标签都可以从检索到的前几幅图像中检索出来,并能优先返回与查询图像共享更多疾病标签的图像。实验证明,本文方法能够提高检索结果的排序质量,同时返回高相似的结果。
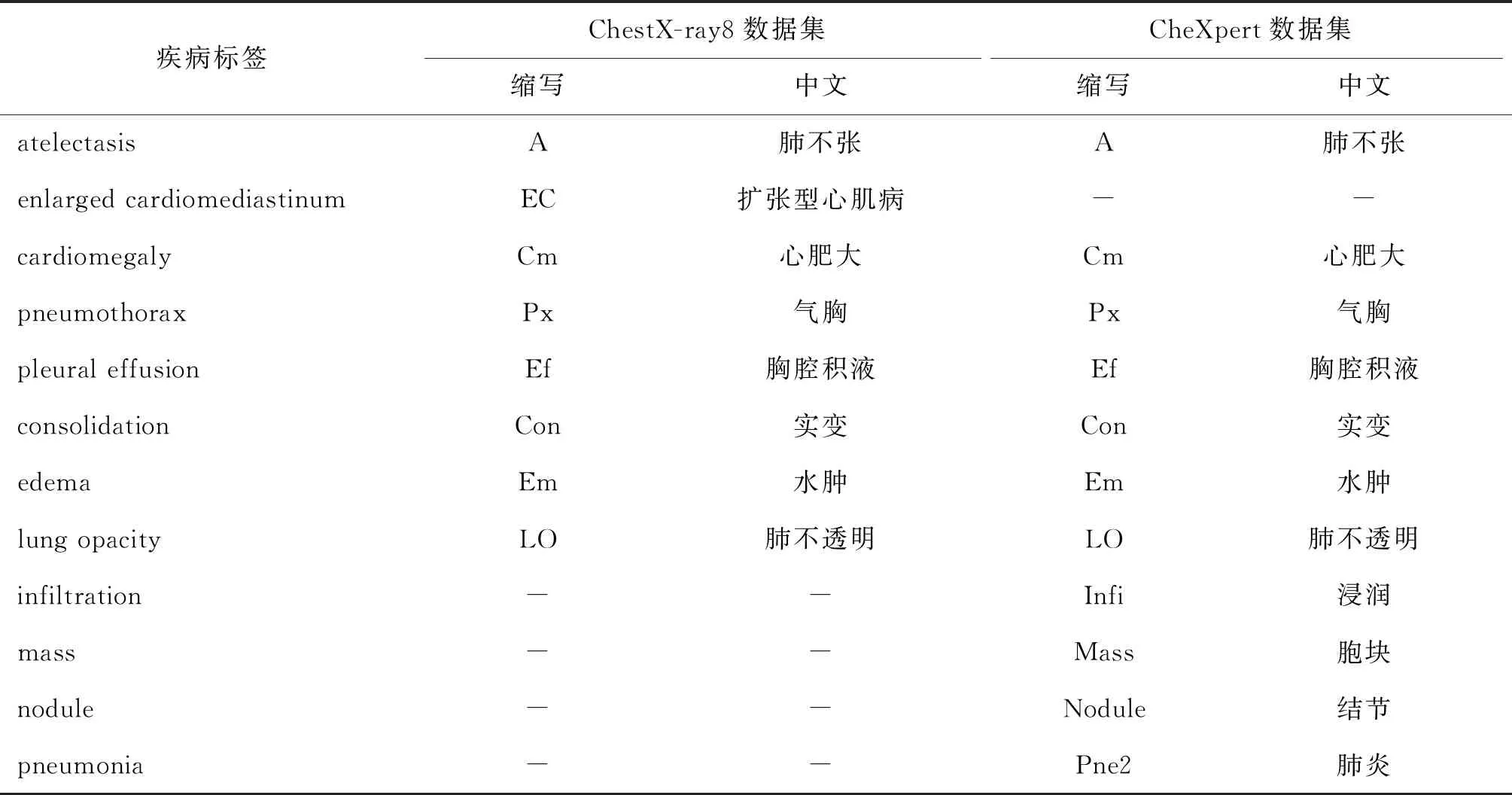
表3 ChestX-ray8和CheXpert数据集中疾病标签的含义
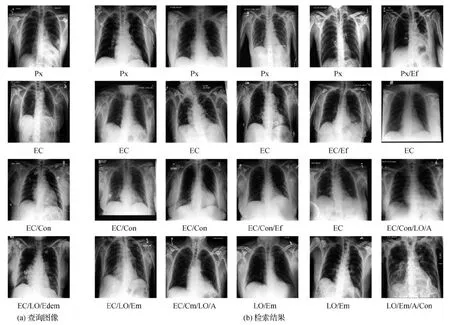
图4 本文方法的检索结果
4.2.2 可视化分析
本文提出的空间注意模块使用3个不同空间上下文信息描述特征图的有效性,即沿通道轴元素的最大值FmaxP、元素平均值FavgP和最大池化Fmax。实验在CheXpert数据集进行,对比方法包括本文方法及两种变体:本文w/o (FmaxP+FavgP) 和本文w/oFmax。本文w/o (FmaxP+FavgP) 表示不考虑通道元素最大值和通道元素平均值;本文w/oFmax表示不考虑最大池化。实验结果如表4所示。由表4可以得出,不考虑FmaxP和FavgP的情况下,本文方法的mAP值降低了0.18。不考虑Fmax的情况下,mAP降低了0.07。说明使用3个描述符能更有效地获取显著区域的信息。

表4 不同空间上下文描述特征图的有效性对比
为了说明空间注意模块在有效信息捕捉中的作用,图5给出了不同变体的热力图可视化结果。可以观察到,相比于不考虑FmaxP和FavgP的情况,本文方法对于显著区域的关注更具体,减少了胸片的噪声影响;相比于不考虑Fmax的情况,本文方法对显著区域的关注更全面,有效解决了病灶的遗漏问题。
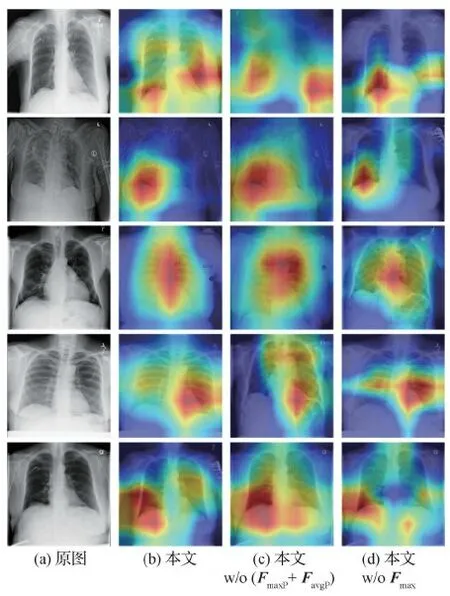
图5 不同方法的热图结果
为进一步验证空间注意模块的有效性,在CheXpert数据集上进行实验,对疾病定位进行性能比较,定位结果如图6所示。对Nodule和Mass等疾病,病变区域定位的准确性优于另外两种方法。对Cm疾病,病变区域的定位结果与其他方法差异不大,主要原因在于该方法主要侧重小的病变区域。实验结果表明,本文引入的空间注意模块对小病变区域的定位具有一定优势,能够有效捕捉病变区域,增强哈希码的可识别性。
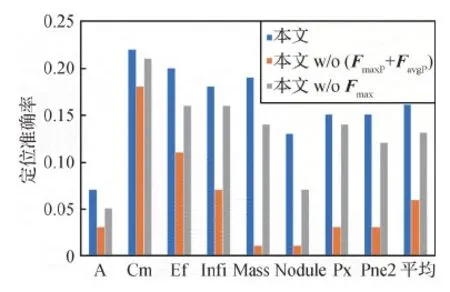
图6 疾病定位结果
4.2.3 消融实验分析
为验证融合全局特征与局部特征的有效性,采用mAP和nDCG@100作为评价标准,实验结果如表5所示。从表5可以看出,本文方法融合特征的mAP值相比单一特征至少提高了4%,检索结果最好。nDCG@100为0.27,也超过单一特征的性能,获得了更好的排序结果。实验结果说明,通过全局特征和局部特征的融合,不仅关注整体特征,还考虑局部病变区域,使网络中的特征包含了小样本以及同类的相关信息,能够缩小类内差距,有益于提高检索的准确率。

表5 使用不同特征的性能分析
训练损失的定性结果如图7所示。从图7可以看出,网络收敛速度开始较快,但慢慢振荡,最终趋于稳定拟合。
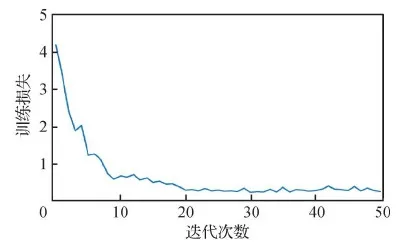
图7 训练损失结果
5 结 论
为解决大规模胸片图像的检索难题,提出一种面向大规模胸片图像的深度哈希检索方法。首先在网络中构建空间注意模块,提取局部特征,增强哈希码的识别能力。然后针对病灶信息丢失问题,定义特征融合模块,将细化后的全局特征和局部特征进行融合。最后结合3个损失函数进行哈希码优化,提升检索结果准确率。实验结果显示,在ChestXay-8和CheXpert数据集上,检索准确率分别提高了6%和5%,表明本文方法在胸片图像检索中具有明显优势。
虽然本文方法能够对医学图像进行精确检索,但是仍然存在需要改进的地方。一方面,可以参照现有的哈希方法,对损失函数进一步优化,使其更易于区分小样本图像;另一方面,为了关注ROI区域,可以尝试调整网络的组合顺序。在未来工作中,将围绕这些方面进行研究,致力于在胸片图像检索中获得更好的性能。
