一种使用改进预测成本矩阵任务优先排序的异构计算系统列表调度算法
2023-02-18宋宇鲲杨国伟张多利
姚 宇 宋宇鲲 杨国伟 黄 英 张多利
(合肥工业大学微电子学院 合肥 230601)
1 引言
异构计算系统可以将应用程序分配在多个处理器上执行,并且通过处理器间的互联网络进行数据通信,应用程序在系统上的并行计算大幅提高了执行效率。异构计算系统通常由不同的处理器以及连接各个处理器的网络组成。不同任务在相同处理器上的执行时间一般是不同的,而且,由于处理器的异构性,相同任务在不同处理器上的执行时间一般也是不同的。
应用程序表示为有向无环图(Directed Acyclic Graph, DAG)[1],描述了应用程序的属性,例如每个任务在不同处理器上的执行时间,任务之间的数据依赖关系以及通信时间。
异构列表调度的目标是将应用程序分配到异构计算系统的处理器上。在这个过程中,需要考虑不同任务在不同处理器上执行时间的不同以及通信时间不同的问题。该问题是一个非确定多项式时间(Nondeterministic Polynomial-time, NP)完全问题[2-4]。在多项式时间内获得最调度方案几乎是不可能的,于是如何在多项式时间内产生较好的调度方案,成为相关工作的热点研究内容。
对于此问题,很多相关工作采用了启发式算法。这些启发式算法主要分为3类,包括基于聚类的启发式算法[5-7]、基于复制的启发式算法[8-10]和基于列表的启发式算法[11-22]。
相关工作中的基于启发式的列表调度算法将问题求解的搜索空间缩小,在降低了时间复杂度的基础上获得较好的解。为了下文的说明,现令DAG中任务数量为 tn,异构计算系统中处理器数量为p n。
异构最早完成时间(Heterogeneous Earliest Finish Time, HEFT)[11]算法具有O(pn·tn2)的时间复杂度。它在任务优先级排序阶段使用 r ankµ作为依据,该值表示了一个任务到出口任务的最长路径。在处理器选择阶段,它为任务选择获得最早完成时(Earliest Finish Time, EFT)的处理器。但是其只根据单个任务的计算属性来选择处理器,忽略了对后继任务带来的不利后果。
前瞻(lookahead)[12]算法针对HEFT的缺点进行了改进。在任务优先级排序阶段,前瞻使用rankµ作为排序依据。在处理器选择阶段,它会对当前任务的后继任务的处理器选择进行预测,并倾向于选择能使当前任务的所有后继任务在所有处理器的最大EFT最小化的处理器。但是,前瞻算法的时间复杂度增加到O(pn3·tn4)。
预测最早完成时间(Predict Earliest Finish Time, PEFT)[13]算法通过计算乐观成本表(Optimistic Cost Table, O CT)作为算法中抉择的关键依据,在保持O(pn·tn2)的复杂度的基础上,适用了前瞻特性,并且相比HEFT有较大的性能提升。用于任务优先级排序阶段的 r ankOCT没有考虑当前任务在处理上的计算消耗成本,导致优先级列表的预测准确性不佳。
预测优先任务调度(Predict Priority Task Scheduling, PPTS)[14]算法使用预测成本矩阵(Predict Cost Matrix, P CM ) 替代O CT,同时考虑了当前任务和直接后继任务的计算消耗,能够更好地预测任务的执行,保持了O(pn·tn2)的时间复杂度,性能比PEFT有进一步的提升。但是,由于P CM中考虑的是当前任务在直接后继任务处理器上的计算消耗,做出的预测偏向于产生相邻任务在同一处理器上执行的局部最优解。而且,PPTS在处理器选择阶段使用P CM也会导致同样的问题。PPTS的作者又提出了增强的预测优先任务调度(Improved Predict Priority Task Scheduling, IPPTS)[22],通过在优先级排序阶段考虑了任务的出度,在大任务数量应用中获得了提升,但其仍未完全解决其使用PCM所带来的问题。
总体来说,此类型的相关工作中,设计用于任务优先级排序或处理器选择的预测列表或矩阵仍有不合理之处,不能充分发挥异构计算系统的性能。
本文针对异构列表调度问题,提出一种新的具有2次时间复杂度的调度算法,称为改进的预测优先任务和乐观处理器选择调度(Improved Predict Priority and Optimistic processor Selection Scheduling, IPPOSS)。IPPOSS优于PPTS和PEFT并且保持2次复杂度。该算法是在PPTS和PEFT基础上的改进,同样具有任务优先级排序和处理器选择两个阶段,并且具有前瞻的特性。与PPTS和PEFT相比,IPPOSS计算改进预测成本矩阵(Improved Predict Cost Matrix, IPCM),该矩阵中的每个元素表示为特定任务选择特定处理器时的执行成本的预计值。然后计算任务优先级rankIPCM,也就是任务在不同处理器上的I PCM值的均值,然后使用r ankIPCM对任务进行排序。在处理器选择阶段,基于实验结果,IPPOSS使用基于EFTOCT[13]的处理器选择策略。但是由于任务优先级排序阶段使用了更好的方法,IPPOSS产生了与PEFT完全不同的处理器选择结果。随机生成的应用图和真实世界的应用图的实验结果分析表明,IPPOSS的性能优于现有相关算法。
2 调度问题模型
调度模型用于应用程序到计算系统上的调度,并且达到一定的性能指标。一般来说任务调度的主要目的是获得最小调度长度,也称为m akespan。
调度模型中的应用描述为一种 D AG=(T,E),如图1和表1所示。T是节点的集合,任意ti ∈T表示DAG中的一个任务。E是有向边e的集合,任意ei,j ∈E表示DAG中的一次通信,也就是任务ti到
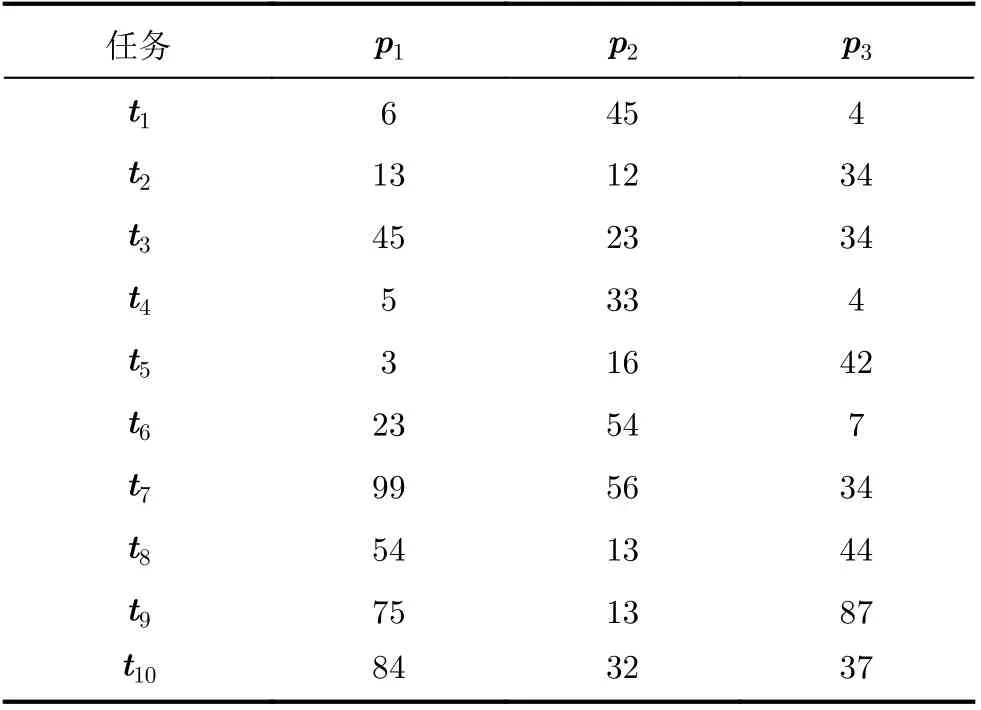
表1 计算消耗

图1 具有10 任务和3 处理器的任务以及计算消耗

任意通信ei,j在计算系统网络中传输所消耗的时间表示为ci,j。 由于ci,j必 须要在执行ti和tj的处理器被确定的情况下才能计算出,而静态列表调度以通信消耗作为输入参数,必须提前预知该值,所以一般的做法是,使用平均通信时间ci,j来 表示ei,j的时间消耗。当ti和tj被分配在不同处理器上时,ci,j的计算方法为

其中,l表示所有处理器的平均延迟,也就是平均传输启动时间。b表示所有处理器之间的平均带宽。Di,j表示在本次通信中ti需要传输到tj的数据量。ci,j表示了平均传输启动时间和特定量的数据在传输开始后到传输结束所消耗时间的和。如果ti和tj被分配在同一个处理器上,它们之间不需要通过网络进行数据传输,则ci,j为0。tj的通信。通信ei,j也 表示了任务ti和tj间的数据依赖关系。任务ti被称为tj的直接前驱任务,任务tj被称为ti的直接后继任务。通信消耗标注于图1的对应边上,计算消耗标注于表1,因系统为异构架构,任务在不同的处理器上具有不同计算消耗。
调度模型中的计算系统包含处理器的集合P。本文的调度模型中,应用程序在计算系统上的执行过程进行了一些假设:1个任务指令必须在计算系统中的1个处理器上执行;多个处理器可以同时执行不同任务;任务在处理器上的执行不会发生争用;任意两个处理器之间都通过网络连接并且能进行数据传输;任意两次通信之间不会发生干扰。
任务ti在 处理器pm上 的计算时间表示为W(ti,pm)。它的行数是DAG中任务数量 tn,列数是计算系统中处理器数量 pn。因为本文讨论的是异构计算系统,所以对于相同的ti以及不同的pm,W(ti,pm)也具有不同的值。平均计算时间表示了不指定处理器的情况下,执行任务ti预计所花费时间,表示为
3 IPPOSS算法
IPPOSS包含两个阶段,分别为任务优先级排序阶段和处理器选择阶段。改进预测成本矩阵被用于任务优先级排序阶段,本节首先介绍它的定义和计算方法。
3.1 改进预测成本矩阵
IPPOSS的任务优先级排序阶段基于改进预测成本矩阵,是对PPTS[14]中的P CM的改进。每个元素IPCM(ti,pm)代 表任务ti选 择在pm上执行时,任务ti到 出口任务的最短路径的预计最大值。IPCM中的所有元素通过递归的过程计算,计算过程开始于出口任务,并向上遍历所有的任务,结束于入口任务。I PCM(ti,pm)的计算公式为
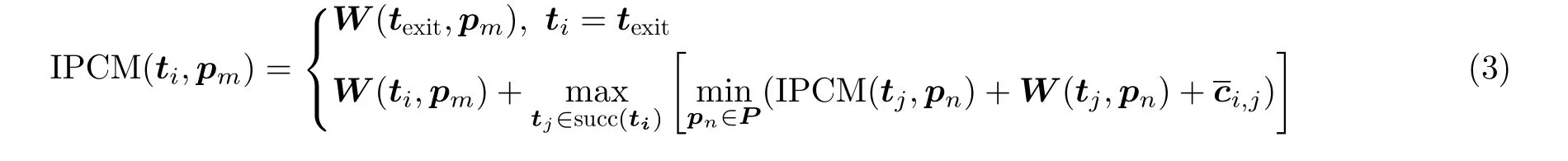
其中,W(ti,pm)表 示ti在pm上执行的异构运算时间。 succ(ti) 表示ti的所有直接后继任务的集合。P表示所有处理器的集合。ci,j表 示ti到tj的平均通信时间。当ti和tj在同一个处理器上运行时,也就是pm=pn时,ci,j=0。W(tj,pn)表示直接后继任务tj在pn上 执行的异构运算时间。当ti为texit,也就是出口任务时,有 succ(ti)=∅ ,IPCM(ti,pm)=W(texit,pm) 。IPCM(ti,pm)不仅考虑了直接后继任务tj在可以获取最小计算、通信时间之和的处理器上执行的时间消耗,而且考虑了当前任务ti在选择的处理器pm上 的时间消耗,所以,I PCM(ti,pm)表示了ti选 择在pm上 执行时,任务ti到出口任务的最短路径的预计最大值。而PPTS中的P CM没用使用准确的当前任务计算消耗,而是使用了一种近似表示,也就是当前任务在其直接后继任务选择的处理器上的计算消耗。这导致不能准确地进行调度预测,从而限制了调度性能。
3.2 任务优先级排序阶段
IPPOSS的任务优先级排序阶段根据rankIPCM(ti)的元素来进行,具有较大的r ankIPCM(ti)的 任务ti被置于任务优先级列表的前面。r ankIPCM(ti)通过任务ti在 每个处理器上的I PCM的平均值求得,定义为

rankIPCM是I PCM 的平均值,所以它能够反映任务在调度列表中的重要程度。对于图1的DAG1,HEFT, PEFT, PPTS和IPPOSS算法得到了完全不同的任务优先级排序列表。表2给出DAG1的IPCM的所有元素,由表3可以确定4种算法的任务优先级列表。可以看出,r ankµ与r ankOCT对于T1之后优先进行的任务做出了相同的选择T2,而 rankPCM与rankIPCM则选择T1,T3和T6作为开始的3个任务。rankIPCM与所有3种算法最显著的不同是,将T7排在了T4和T5的前面,而且从图1可以看出,这种优先级排序是一种“越级”排序,因为T4和T5是入口任务T1的直接后继,而T7则不是。对于DAG1,使用r ankIPCM相比其他3种算法的r ank,更具有在全局范围内调整任务优先级列表顺序的能力,而不是按照DAG1中每个任务的分级仅在局部进行优先级顺序的调整,这使得IPPOSS可以获得更好的调度性能。

表2 图 1 中 DAG1 的 IPCM

表3 图 1 中 DAG1 的各算法任务优先级列表
3.3 处理器选择阶段
IPPOSS的处理器选择阶段没有使用E FTIPCM。通过随机生成的应用图实验发现,虽然在两个阶段中都使用I PCM,会获得优于PEFT和PPTS的解,但是如果在处理器选择阶段使用E FTOCT,则会获得更好的解。表4给出了基于 E FTIPCM的处理器选择策略的IPPOSS与PEFT, PPTS和基于E FTOCT的处理器选择策略的IPPOSS的调度长度率(Scheduling Length Ratio, SLR)对比,可以看出,虽然基于EFTIPCM处理器选择策略的IPPOSS比PEFT降低了1.75%的平均S LR,并且有57.5%的样本获得了更低调度长度,但是相比于PPTS,该方法并没有明显的提升。而基于E FTOCT处理器选择策略的IPPOSS的平均SLR进一步降低,此外,样本的成对调度长度对比结果也有进一步的优化。

表4 不同方法的SLR对比(%)
基于实验结果,IPPOSS在处理器选择阶段使用PEFT中的方法,也就是选择具有最小E FTOCT[13]的处理器,E FTOCT的计算公式为

一些相关工作[11,13,14]在处理器选择阶段使用了基于插入的(insertion-based)策略。它们在调度中可以通过充分利用处理器上的空闲时间槽,减少总体调度时间。考虑算法对比的公平性,本文同样使用该策略。
3.4 IPPOSS算法详细描述
IPPOSS算法的细节如算法1所示。

算法1 IPPOSS算法
IPPOSS首先计算I PCM, O CT( 第1行)和rankIPCM(第2行)。然后,通过查找未分配处理器且所有直接前驱任务都已经分配处理器的任务来更新就绪列表(第3行)。接着,为就绪列表中具有最高rankIPCM(ti)的任务ti分 配处理器,以获得最小的EFTOCT(ti,pm)(第4~10行),并更新L istready(第11行)。最后,如果更新后的就绪列表为空,则算法结束(第4、第12行)。
图2给出了4种算法对DAG1的调度结果。其中,PEFT的m akespan 为158 ,PPTS的makespan为156,而本文IPPOSS的m akespan为151。

图2 4种算法对图1中DAG1产生的调度结果
从时间复杂度上来说,相比于PEFT和PPTS,IPPOSS的复杂度并没有提高。计算 I PCM 和OCT的时间复杂度都是O(pn·(en+tn)),处理器选择阶段的时间复杂度为O(pn·tn2)。总时间复杂度为O(2·pn·(en+tn)+pn·tn2)。对于密集型DAG,有 e n=tn2,总时间复杂度约为O(pn·tn2)。因此,IPPOSS具有与这些算法相同的时间复杂度。
4 实验结果和讨论
本节对比了IPPOSS与其他3种算法(HEFT[11],PEFT[13]和PPTS[14])的调度性能。设置了两种应用图:随机生成的应用图和真实世界应用的应用图。通过设置对比的指标,将4种算法的性能进行了比较。4种对比指标分别为SLR[11]、加速比(Speedup)[15]、松弛度(Slack)[23]和更好的解发生的比例(Percentage of Occurrences of Better Solutions, POBS)[11]。
4.1 随机生成的应用图
本节首先评估HEFT[11], PEFT[13], PPTS[14]和本文的IPPOSS算法对随机DAG的调度性能。本文使用了一款开源的DAG生成软件daggen[24],利用其基本参数生成实验所需的随机DAG。
实验中使用了以下参数的组合来生成随机DAG:n=[10,20,30,40,50,60,70,80,90,100],表示DAG中的任务数量;c cr=[0.1,0.2,0.5,1,2,5,10],表示平均通信时间与平均计算时间的比值;β=[0.1,0.2,0.5,1,2],表示处理器速度的异构性因子;j ump=[1,2,4],表示任务间通信跨越的最大层级数量;r egular=[0.2,0.8],表示DAG的不同级别之间任务分配的规律性; fat=[0.1,0.4,0.8],表示DAG中可能出现的并行执行的任务的最大数量;density=[0.2,0.8],表示DAG中两个相邻层级中的任务间的依赖的数量系数;p n=[4,8,16,32],表示异构计算系统中处理器的数量。
以上8个参数总共有50400种组合,对于每一种组合,随机生成10个DAG,总数量为504000。
图3显示了任务数量值为[10,20,30,40,50,60,70,80,90,100]的平均SLR、平均加速比和平均松弛度。每个数据节点都是50400个随机生成DAG的实验结果平均值。图3(a)表明,对于不同任务数量值,IPPOSS算法的平均SLR是4种算法中最低的。与HEFT算法相比,当任务数量为10时,IPPOSS算法的平均SLR降低最高达7.82%。图3(b)表明,对于不同任务数量值,IPPOSS算法的平均加速比是4种算法中最高的。与PEFT算法相比,当任务数量为50时,平均加速比的提高最高达3.97%。相比其他算法,IPPOSS在任务优先级排序阶段使用IPCM 进行预测,I PCM不仅考虑了直接后继任务在可以获取最小计算、通信时间之和的处理器上执行的时间消耗,而且考虑了当前任务在选择的处理器上的时间消耗,因此IPPOSS进行了更准确的预测,为处理器选择提供了更合理的优先级列表,从而获得了更高的平均加速比。而 I PCM的计算相比其他算法的预测表或预测矩阵并未提高时间复杂度,且算法中其他流程也未提高时间复杂度,从而在保持时间复杂度不变的基础上提高了平均加速比。图3(c)表明,对于不同任务数量值,IPPOSS算法的平均松弛度低于HEFT和PEFT算法。 相比于PPTS算法,在任务数量≤50时,IPPOSS的平均松弛度与PPTS接近。在任务数量≥60时,IPPOSS的平均松弛度略高于PPTS。因为IPPOSS算法具有较为激进性能策略,在获得更短的调度长度和更高的加速比的同时,降低了一定的稳定性。但在任务数量≥60时,IPPOSS仍比PPTS具有更高的稳定性。

图3 4种算法对不同任务数量的DAG的调度结果
图4显示了ccr值为[ 0.1,0.2,0.5,1,2,5,10]的平均SLR、平均加速比和平均松弛度。每个数据节点都是72000个随机生成DAG的实验结果平均值。图4(a)表明,对于不同ccr值,IPPOSS算法的平均S LR 是4种算法中最低的。与HEFT算法相比当ccr为1时,平均SLR的降低最高达5.96%。图4(b)表明,对于不同ccr值,IPPOSS算法的平均加速比高于HEFT和PEFT。与PEFT算法相比,当ccr为1时,平均加速比提高最高达5.10%。相比于PPTS算法,在ccr≤0.5时,IPPOSS的平均加速比高于PPTS。在ccr≥1时,IPPOSS的平均加速比与PPTS相近。这是因为,PPTS使用的P CM会导致邻近任务在相同处理器上执行的趋势,这会在通信量较高也就是ccr较高的情况下,通过更多地避免通信来获得较好的性能。但是,这种方法会导致陷入单处理器化的局部最优解,因此只在ccr较高时获得了与IPPOSS相近的平均加速比,而在ccr较低时获得了比IPPOSS差的平均加速比。图4(c)表明,对于不同ccr值,IPPOSS算法的平均松弛度低于HEFT和PEFT。虽然在ccr≥1时,IPPOSS与PPTS的加速比接近,但是IPPOSS在SLR和松弛度指标上仍然优于PPTS,这意味着在此情况下IPPOSS比PPTS更容易获得较短的调度长度和更好的稳定性。
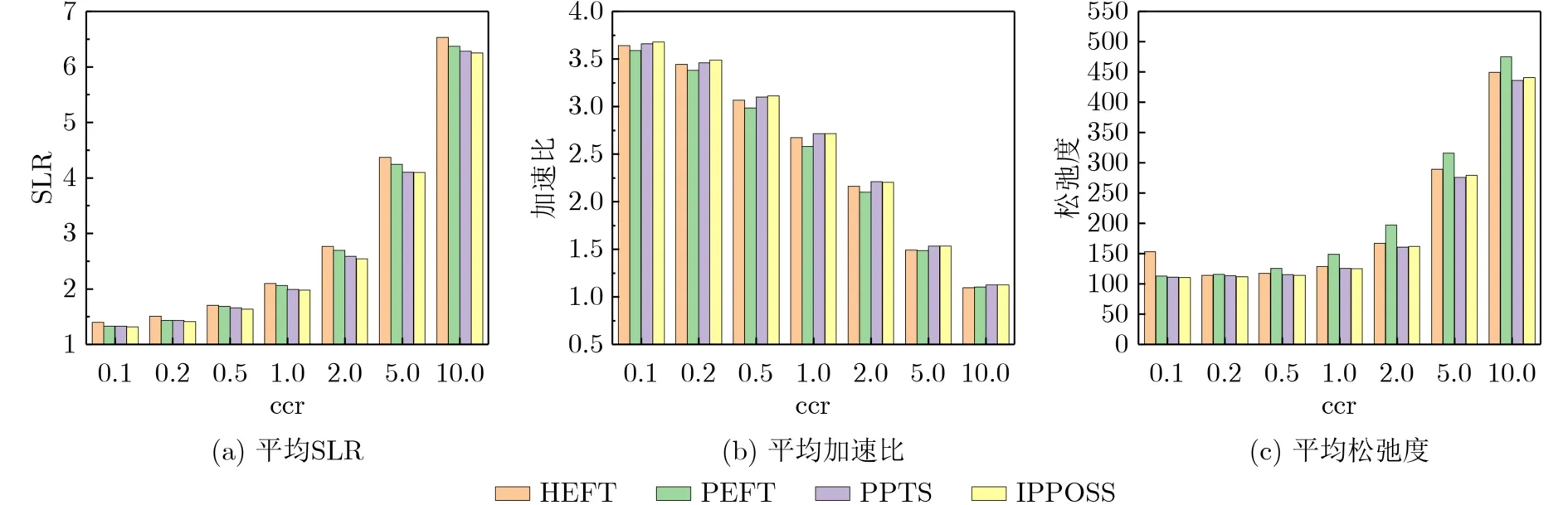
图4 4种算法对不同ccr的DAG的调度结果
图5显示了处理器数量值为[ 4,8,16,32]的平均SLR和平均加速比。每个数据节点都是126000个随机生成DAG的实验结果平均值。图5表明,对于不同处理器数量,IPPOSS的平均SLR和平均加速比在大多数情况下优于其他算法。在处理器数量为4时,IPPOSS的平均SLR与PPTS相近,平均加速比略低于PPTS。原因为PPTS的预测策略倾向于在同一处理器上执行任务,其在处理器数量较少时具有一定优势。图5(a)表明,与HEFT算法相比,当处理器数量为32时,IPPOSS算法的平均SLR降低最高达6.76%。图5(b)表明,与HEFT算法相比,当处理器数量为32时,平均加速比的提高最高达2.00%。

图5 4种算法对不同处理器数量的DAG的调度结果
表5列出了IPPOSS与其他算法相比产生的更好、相等和更差的调度长度的百分比。IPPOSS算法分别在44.9%, 58.8%和66.7%的DAG中获得了更短的调度长度,只在22.7%, 15.2%和23.5%的DAG中获得了更长的调度长度。

表5 4种算法的调度长度的成对比较(%)
4.2 真实世界应用的应用图
除了随机生成的应用图,本文还评估了HEFT[11],PEFT[13], PPTS[14]和IPPOSS算法对两种真实世界应用的DAG图的调度性能,包括高斯消元[25]和蒙太奇(Montage)[26]。前者是用于求解线性方程组等重要矩阵运算中的算法,后者是一种天文图像拼接引擎,可将天空的各个图像组合成一个拼接图。这两种应用的DAG在具有一定的并行性的同时还具有一定的复杂性。此外,它们的DAG中的任务数量可以被较灵活地定义。所以,本文实验中使用了这两种真实世界的应用。
对于这些应用的DAG,因为基本形状结构已经固定了,本文设置3种参数用于生成具有不同通信和运算特性的应用图,这些参数包括:ccr=[0.1,0.2,0.5,1,2,5,10],β=[0.1,0.2,0.5,1,2] ,pn=[4,8,16,32]。
第1种真实世界应用的应用图是高斯消元,其任务数量等于(m2+m-2)/2,其中m是矩阵的尺寸。实验中使用的矩阵尺寸m=[5,10,15,20],对应任务数量t n=[14,54,119,209]。
图6显示了不同矩阵尺寸下的平均SLR和平均加速比。图6(a)表明对于不同矩阵尺寸值,IPPOSS的平均SLR是4种算法中最低的。与HEFT算法相比,IPPOSS算法的平均SLR降低分别为9.93%,5.57%, 5.16%和5.14%。与PPTS算法相比,IPPOSS算法的平均SLR降低分别为6.43%, 3.43%, 6.33%和6.91%。图6(b)表明对于不同矩阵尺寸值,IPPOSS算法的平均加速比是4种算法中最高的。与HEFT算法相比,IPPOSS算法的平均加速比提高分别为3.44%, 4.21%, 3.88%和3.53%。

图6 4种算法对不同矩阵尺寸的高斯消元应用的调度结果
第2种真实世界应用的应用图是蒙太奇,任务数量设为[ 33,50,96,195,411]。
图7显示了不同任务数量下的平均SLR和平均加速比。图7(a)表明对于不同任务数量,IPPOSS算法的平均SLR是4种算法中最低的。与HEFT算法相比,IPPOSS算法的平均SLR降低分别为8.49%, 8.46%, 8.18%, 9.28%和9.68%。图7(b)表明对于不同任务数量,IPPOSS算法的平均加速比是4种算法中最高的。

图7 4种算法对不同任务数量的蒙太奇应用的调度结果
5 结论
本文针对异构列表调度问题,提出一种同时优于PPTS和PEFT并且保持2次复杂度的调度算法IPPOSS。本算法使用IPCM进行预测,更合理地进行了任务优先级排序,从而在经过处理器选择阶段后获得了更好的解。在随机生成的应用图实验中,IPPOSS的SLR优于HEFT, PEFT和PPTS。对于加速比和松弛度指标,IPPOSS比HEFT和PEFT更好,并且与PPTS的结果相近。此外,对于相同的DAG,相比于其他3种算法,IPPOSS容易出现更好的调度结果。对于真实世界应用高斯消元和蒙太奇,IPPOSS算法的SLR和加速比指标也优于这4种算法。
