面向心电检测的混合多模卷积神经网络加速器设计
2023-02-18刘冬生邹雪城陆家昊昂李德建蒋曲明
刘冬生 魏 来* 邹雪城 陆家昊 成 轩 胡 昂李德建 赵 旭 蒋曲明
①(华中科技大学光学与电子信息学院 武汉 430074)
②(国家电网电力工业芯片设计与分析技术重点实验室,北京智芯微电子科技有限公司 北京 100000)
③(楚天龙股份有限公司 东莞 523000)
1 引言
目前,心血管疾病已成为全球致死人数最高的疾病,据世界卫生组织统计,2019年全球约有1790万人因心血管疾病致死,该类疾病已经严重威胁到人类的身体健康[1]。对心血管类疾病患者进行实时监控以及干预可以有效地降低心血管疾病的危害,而随着嵌入式技术发展以及人工智能算法的成熟,通过可穿戴设备完成心电信号的实时分析变为可能。当前大部分的可穿戴医疗设备仅具有采集人体生理信息的功能,通常将医疗诊断算法部署在云端完成数据分析,该方式会加剧云端中心的数据压力,并导致设备的实时监控性较差[2],因此研究专用于医疗诊断和分析的可穿戴设备是具有重大研究和应用价值的。
心电图(ElectroCardioGram, ECG)分类算法主要分为传统机器学习算法与深度学习算法,传统机器学习算法分为信号预处理、特征提取和筛选以及分类算法3个步骤完成,而ECG信号的特征提取和筛选需要大量的先验知识[3]。深度学习算法能自动提取和筛选ECG信号特征并具有极高的预测精度,已成为ECG分类算法的主流方法,其中卷积神经网络(Convolutional Neural Networks,CNN)算法由于其对信号噪声具有出色的鲁棒性以及较强的泛化能力[4],被广泛应用于ECG分类算法中。随着CNN算法的不断更新与迭代,网络模型不断增加,诸多CNN模型需要大量的运算和存储资源完成推理预测,而部署在嵌入式设备场景的CNN模型算法需要在有限的硬件资源完成高性能需求。专用的CNN加速器与传统CPU+GPU协同处理方式相比,虽牺牲了部分通用性,但能以极低的功耗和硬件资源完成CNN模型加速[5]。因此针对嵌入式场景,使用专用的CNN加速器完成CNN模型的预测已成为目前的研究热点之一。
目前对卷积神经网络加速器的研究主要集中在以下3个方面:
(1) 循环展开、平铺与交换提高运算效率:通过对CNN多级循环进行深入研究,使用循环展开、平铺和交换操作对卷积循环进行优化与加速,随后根据采取的循环操作策略设计核心运算单元完成卷积运算,这种空间并行的结构能实现各类数据复用以及运算并行度的提升[6,7]。
(2) 高效的数据流减少数据通信:通过输入固定[8](Input Stationary, IS)、输出固定[9](Output Stationary, OS)和权重固定[10](Weight Stationary,WS)等数据流方式完成对片内各类数据的高效复用,降低额外访存次数所带来的时延和功耗开销。
(3) 高效的处理单元(Processing Element,PE)阵列设计提高硬件资源效率:通过采用卷积加速算法设计高效的PE单元,有效地提高数字信号处理器(Digital Signal Processor, DSP)的运算效率[11];通过对PE阵列结构的可重构设计,提升整体硬件的能效比[12]。
本文对卷积循环原理和多种数据流进行了深入研究,对先前的工作[13]进行了优化设计,设计了一种面向心电检测的混合多模卷积神经网络加速器。本文首先介绍了心电信号(ECG)以及卷积循环原理,随后介绍了用于ECG分类的1维卷积神经网络(One-Dimensional Convolutional Neural Network,1D-CNN)模型,并根据该模型完成了卷积神经网络加速器的硬件设计。该设计采用了多并行展开策略以及多数据流的运算模式完成了卷积循环的加速和优化,并设计了相应的3D-PE阵列可以在时间和空间上高度复用运算数据,最后给出了硬件设计的实现结果,并与其他文献进行比较与分析。
2 ECG信号与CNN循环原理
2.1 ECG信号
ECG信号记录了人体心脏活动的生理信息,是心血管疾病临床诊断和治疗的重要依据。麻省理工学院所提供的MIT-BIH心率失常数据库记录了大量的ECG信号,是目前使用最广泛的数据库之一。该数据库记录了48条采样频率为320 Hz且持续时间长达30 min的ECG数据文件,采集对象来自47位心血管病患者,这些ECG数据文件均标注了心拍类别、R峰位置等诊断信息。本文选取了MIT-BIH数据库中MLII导联通道的ECG数据作为数据集,将30 min的ECG数据段分割为多个以R峰为中心且序列长度为256的单周期心拍,随后采用Z-Score标准化对单周期心拍数据完成归一化处理。本文随机选取了70%的ECG数据作为模型的训练集,剩余30%数据均分为模型的验证集与测试集。
ECG信号是周期性的1维时间序列信号,单个周期的ECG信号对应了人体一次完整的心脏激动过程,该信号通常由P波、T波以及QRS波段组成,每个波段的形态特征均能表征被采集者心脏活动的生理信息。如图1所示,ECG信号通常可以分为房性早搏(Atrial Premature Beat, APB)、正常(Normal, N)、室性早搏(Premature Ventricular Contractions, PVC)、左束支传导阻滞(Left Bundle Branch Block, LBBB)、右束支传导阻滞(Right Bundle Branch Block, RBBB)。
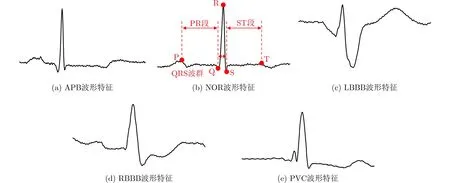
图1 各类型ECG信号的波形特征
2.2 CNN循环原理
1维CNN模型相比2维模型规模和参数量更小,并能深度挖掘ECG信号的特征信息以及精确分类,因此本文采用1维CNN模型对ECG信号进行分类预测。常规的1维CNN模型由卷积层、池化层以及全连接层构建。其中卷积层和全连接层包含了CNN模型90%以上的运算处理,因此在CNN模型的硬件加速中,主要是针对卷积层和全连接层进行优化完成运算加速。
1维CNN模型的卷积层(Convolution, Conv)运算流程如图2所示,其中H,R分别为输出特征图和卷积核的长度,C,M分别为输入和输出特征图的维度数,S为卷积核的步幅。卷积层运算包含了4重循环运算分别为:Loop1:卷积核内方向循环;Loop2:输入通道方向循环;Loop3:输入特征图上方向循环;Loop4:输出通道方向循环。在卷积层运算的4级循环运算中,各循环方向均能并行运算且不互相影响,通过循环展开的方式能有效地提升卷积层的运算并行度,从而加速卷积层运算。

图2 卷积层运算的4级循环
1维CNN模型的全连接层(Fully Connected,FC)运算流程如图3所示,其中M, L分别为输入和输出特征图的长度。卷积层运算包含了4重循环运算分别为:LoopA:输入特征图上方向循环;LoopB:输出特征图上方向循环。在全连接层运算的两级循环运算中,各循环方向也可以进行并行运算,通过循环展开的方式能完成全连接层运算的加速。

图3 全连接层运算的两级循环
3 面向心电检测的CNN加速器设计
3.1 基于ECG分类的1D-CNN模型
本文采用了先前工作所构建的1D-CNN模型[13],如图4所示为1D-CNN模型的结构。本模型由8层Conv层、4层最大池化(Max Pooling, MP)层、1层全局平均池化(Global Average Pooling, GAP)层以及2层FC层组成。尺寸为256×1的1维输入序列为ZScore标准化预处理的原始ECG信号,输出为NOR,LBBB, RBBB, PVC, APB 5种心拍类型的预测概率。其中卷积核的尺寸设置为5×1,步长设置为1,零填充设置为2。本模型参考于网络模型VGG-16,在两次Conv层提取特征后,采用1层MP层进行下采样,舍弃特征图中1/2的序列信息。1D-CNN展平通道采用了GAP层完成,简化了CNN模型,适用于可穿戴设备,FC层放置最后两层,用于对提取的特征进行综合以及分类。
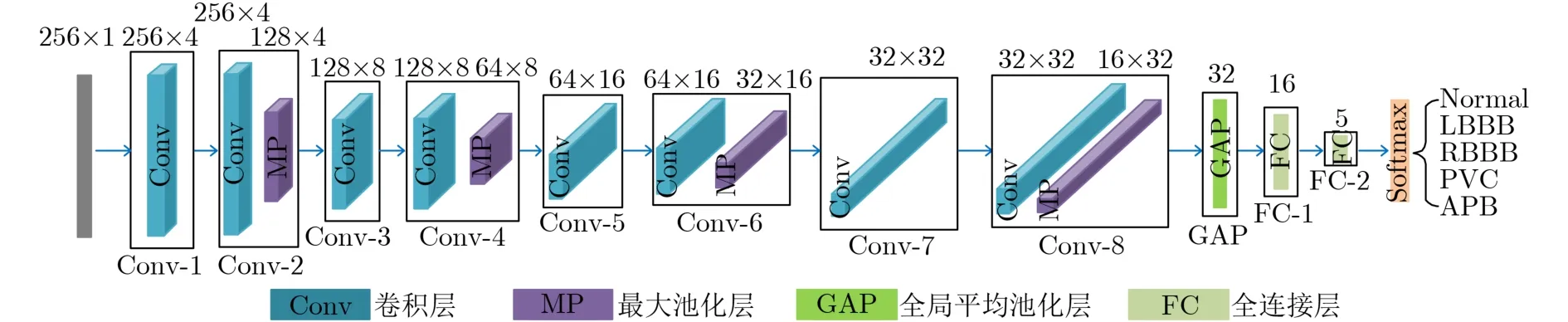
图4 1D-CNN模型结构图[13]
3.2 多并行展开策略和多数据流的运算模式
不同的并行展开策略以及数据流会对硬件加速器的运算性能、运算效率以及数据复用率造成一定影响,所设计的CNN加速器采用了一种多并行展开策略和多数据流的运算模式来完成1D-CNN模型的硬件实现。该模式根据1D-CNN模型各层运算特征所设计,包含了3种不同的运算模式,能最大化各层运算的计算效率以及数据复用。
目前CNN加速方案中常用的数据流为WS,IS和OS数据流,其中WS数据流类型适用于规模较小的网络模型,能在时间上充分复用权重数据,减少权重数据的访存次数,因此该CNN加速方案在卷积层运算中采用了WS数据流类型,为使权重数据在最大程度完成复用,将循环执行顺序更改为Loop4,Loop2, Loop3, Loop1。而在全连接层的运算中,由于全连接层的运算不具备权值共享、局部连接的特性,导致WS数据流无法在时间上复用权重数据,因此在全连接层的计算中采用了IS数据流类型,为使像素数据在时间上最大程度完成复用,将循环执行顺序更改为LoopA, LoopB。
在主流的CNN方案中,卷积层的并行展开策略可分为以下4种:
(1) 展开Loop1, Loop2, Loop4[10];
(2) 展开Loop1, Loop3, Loop4[14];
(3) 展开Loop3, Loop4[15];
(4) 展开Loop2, Loop4[16]。
其中策略(1)与策略(2)由于展开了卷积核方向常常由于不同层的卷积核尺寸发生变化,导致运算阵列需要重新配置增加了控制复杂度,但策略(1)、策略(2)的并行度提升可在3个维度上进行展开,因此不需要对Loop2, Loop4进行充分展开而导致部分层的运算资源浪费,适用于规模较小的网络模型中使用。而对于策略(3)和策略(4),只在两个方向进行循环展开,提升运算并行度需要对两级循环进行充分展开,导致运算阵列在浅层卷积层的运算效率较低,但该方案控制复杂度较低,无需根据不同层进行重新配置。而需要实现的1D-CNN的模型结构精简并且规模较小,卷积核尺寸固定,因此策略(1)与策略(2)适用于1D-CNN的硬件实现。在卷积层的运算中,展开Loop2能减小中间计算值的访存次数,而展开Loop3能复用权重数据,但由于已采用WS数据流充分复用权重数据,因此采用策略(1)完成卷积层能有效减少数据通信。对于Conv-1层运算中由于其输入通道维度为1,而策略(1)需要在Loop2展开,导致设计的运算阵列部分硬件资源不参与运算,因此采用策略(2)对Conv-1层进行并行展开,能提升运算并行度以及硬件资源利用率。
如图5所示为该CNN模型各层计算所对应的运算模式,包含3种运算模式,分别对应了Conv-1层、Conv-2~Conv-8层、FC-1~FC-2层的运算,这3种运算模式的整体运算并行度均设置为80。
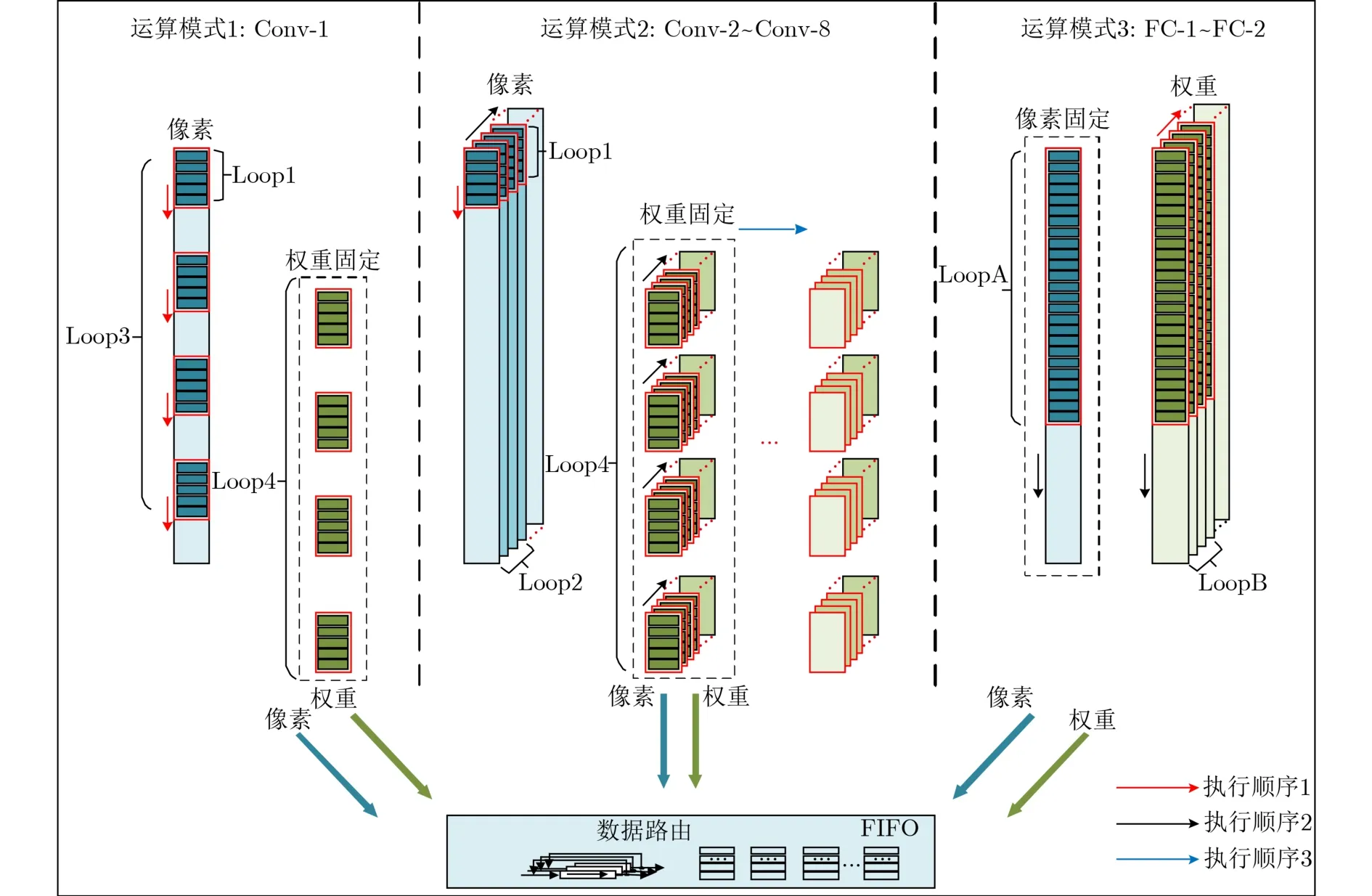
图5 各层计算对应的运算模式
(1) 运算模式1:Conv-1层运算中采用展开策略(2)完成并行展开以及采用了WS的数据流,其中Loop1, Loop3, Loop4的并行度分别设置为5,4,4。该运算模式能在时间和空间上充分复用权重数据,并能在空间上充分复用像素数据。
(2) 运算模式2:Conv-2~Conv-8层运算中采用展开策略(1)完成并行展开以及采用了WS的数据流,其中Loop1, Loop2, Loop4的并行度分别设置为5,4,4。该运算模式能在时间上充分复用权重数据,并能在空间上充分复用像素数据。
(3) 运算模式3:FC层运算中对LoopA和LoopB进行展开并采用了IS数据流,其中LoopA, LoopB的并行度分别设置为20,4。该运算模式能在时间和空间上充分复用像素数据。
3.3 3D-PE阵列模块设计
根据多运算模式所设计的3D-PE阵列模块架构如图6,该阵列由80个PE单元在x,y,z 3个方向堆叠而成。在运算模式1中,方向x的PE单元用于Loop4的并行运算,方向y为Loop1的并行运算,方向z为Loop3的并行运算;在运算模式2中,方向x与方向y的PE单元仍执行Loop4和Loop1的并行运算,方向z更改为Loop2的并行运算;在运算模式3中,方向y与方向z为全连接层中LoopA的并行运算,方向x为LoopB的并行运算。
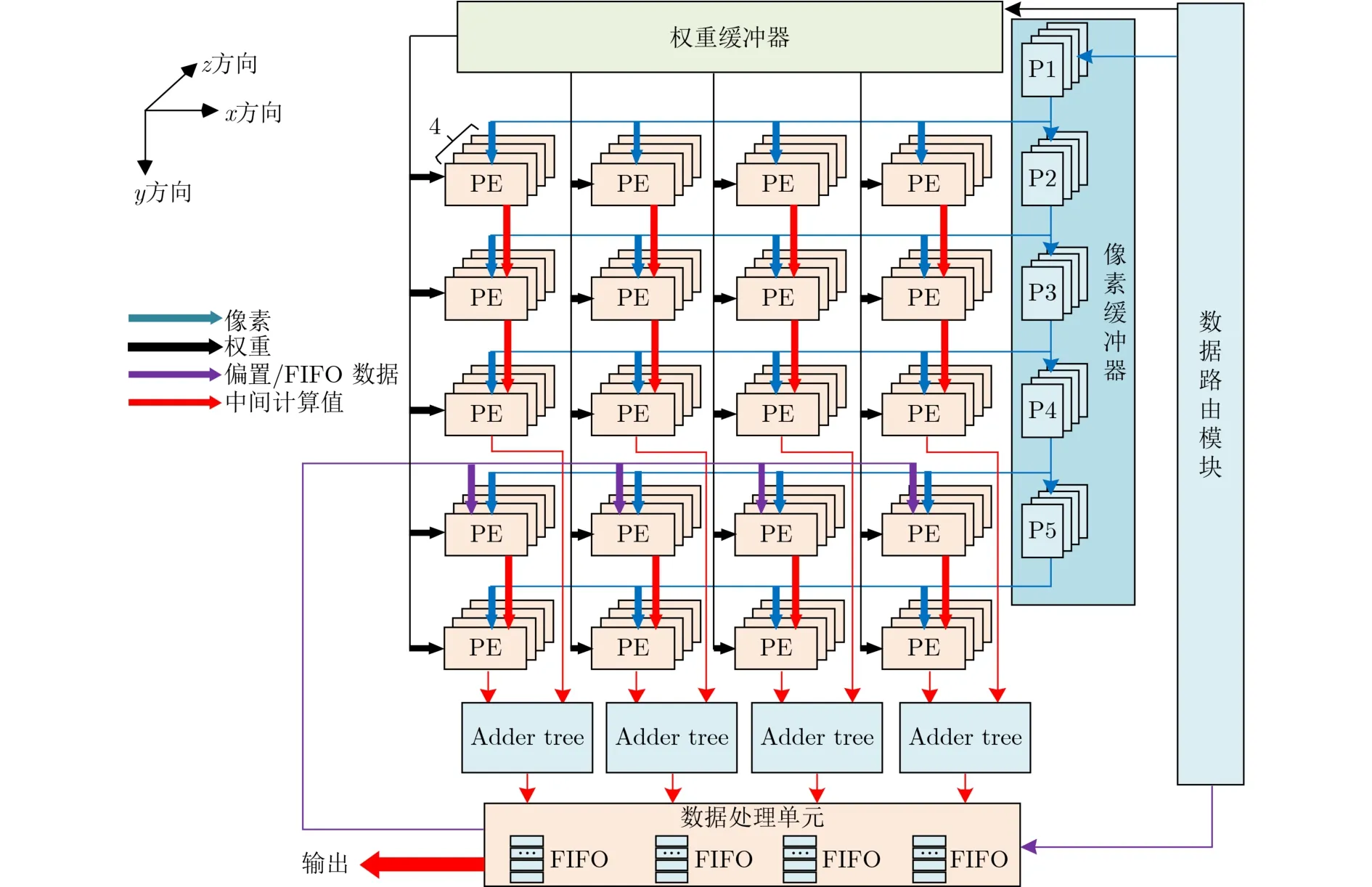
图6 3D-PE阵列结构
在3D-PE阵列中,每个PE单元由乘法器、加法器、反相器以及选择器所构建,每个PE单元在1个时钟周期可以完成1次加法运算以及1次乘法运算。PE单元可通过输入的像素数据符号位对运算器进行动态激活,在针对为负值和零值的像素数据的计算时,PE单元对加法器以及乘法器关闭并直接选通输入的中间计算值作为PE单元的输出。PE单元能完成ReLU函数的实现并有效地去除冗余的运算操作,进一步降低了整体电路的功耗开销。
整个3D-PE阵列采用多级流水线的方式完成卷积运算,阵列中的每个PE单元会沿着方向y进行级联,即上一级PE单元将运算结果输入至下一级PE单元中完成加和操作。其中前3列PE单元进行级联将运算结果输入至加法树模块中,而后两级PE单元同样进行级联将运算结果输入至加法树模块中,其中FIFO中存储的中间计算值以及偏置数据会传输至第4列的PE单元中进行加和操作。方向x与方向z映射的PE单元不进行互联,而是与该方向的其他PE单元并行完成卷积循环运算。
数据路由模块将相应的权重、偏置以及像素数据广播至各个缓冲器中。其中在卷积层的运算中,由于采用WS数据流模式,权重缓冲器在完成了1次Loop3循环后,对PE单元中所固定的权重数据进行更新,并将更新的权重数据广播至各个PE单元,此时权重数据在时间上完成了复用;而在全连接层的运算中,权重缓冲器每个时钟周期都会对权重数据进行更新。像素缓冲器由5组级联的寄存器组成,在卷积层的运算中,每个时钟周期寄存器中的像素数据更新为上一级寄存器存储的数据,并同时将更新的像素数据广播至每一个PE单元中,此时由于展开了Loop1, Loop4,像素数据可在空间上完成复用;而在全连接层的运算中,采用了IS数据流类型,寄存器中的像素数据广播至PE单元后,对下一组像素数据进行预装载,待完成一次LoopB循环后,对PE单元中所固定的像素数据进行更新,此时由于展开了LoopB并采用了IS数据流,像素数据可在时间和空间上同时完成复用。
3.4 池化处理模块
池化处理模块用于完成最大池化层以及全局平均池化层的处理。最大池化层是通过将内核窗口中的像素数据替换为窗口中最大值来降低特征图长度,由3D-PE阵列输出的卷积层运算结果传输至池化处理模块的缓冲区域中,最大池化操作仅需直接从像素缓冲区域读取数据即可,无需额外的RAM访存操作。全局平均池化层用于展平通道维度,对各维度的输入特征图求平均值,在Conv-8层中最大池化操作完成后将结果输入至累加器中,并使用移位操作完成除法操作获得平均值。
3.5 位宽转换设计
可穿戴设备场景对硬件的存储、运算和能耗资源有较为苛刻的要求,所设计的CNN加速器运算精度设置为16 bit定点数,能有效提升整体电路的资源效率。网络模型训练的权重参数和ECG训练全部量化为16 bit的定点数,每层运算结果采取了动态的数据格式来提升量化精度。本文首先在软件端对1D-CNN模型每层运算数据的整数位宽进行统计与分析,随后根据每层数据位宽的统计结果,给每层数据选择不同定点数据格式。池化处理完成后的数据结果输入到输出缓冲器中完成数据的位宽转换,位宽转换采用了饱和截位的操作来完成,截位操作改变运算结果的数据格式,针对溢出的运算结果进行饱和处理。
3.6 总体硬件架构
CNN加速器的总体硬件架构如图7所示,所设计的CNN加速器由中央控制模块、数据路由模块、3D-PE阵列模块、池化处理模块、输出缓冲器、直接存储器访问模块、I/O模块以及片上RAM组成。中央控制模块可以根据运算层数以及卷积循环次数来生成相应的控制信号和地址信号,确保各模块工作正常;3D-PE阵列模块和池化处理模块用于完成卷积层与池化层的运算;数据路由模块可根据运算模式以不同的数据流传输数据;输出缓冲器用于结果位宽转换;DMA和I/O模块负责与外部进行通信;片上RAM总大小为32 kB,用于存储权重、偏置以及像素数据。该设计的输入数据设置了多级缓冲,其中DMA模块、数据路由模块、3D-PE阵列模块均内置了缓冲单元分别作为数据的1,2,3级缓冲,确保整体系统能高速全流水线地完成前向推理,由于每层运算结果存储在片上RAM中,输出数据仅设置一级缓冲即输出缓冲器。

图7 CNN加速器的总体硬件架构
4 实现结果及对比
4.1 硬件实现精度结果
用于评估1D-CNN模型的性能评估指标分别为总体准确率(Accuracy, Acc)、敏感性(Sensitivity, Sen)、特异性(Specificity, Spec)、阳性预测率(Positive predictive rate, Ppr)。这些指标使用真阳性(Ture Positive, TP)、真阴性(Ture Negative, TN)、假阳性(False Positive, FP)、假阴性(False Negative, FN)所计算,计算公式为
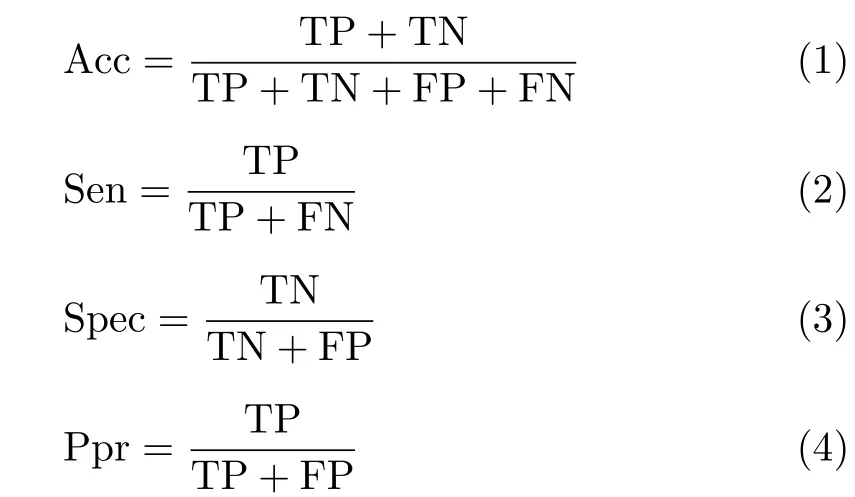
本文使用了Xilinx的ZYNQ ZC706完成了CNN加速器的FPGA原型验证,采用软件平台Intel Core i5-10400中1D-CNN模型使用的测试集对硬件加速器进行了测试。硬件分类的混淆矩阵如图8所示,其中N, LBBB, RBBB类型的心拍预测精度均大于99%,而PVC, APB由于数据集较少导致预测精度与其他3种类型的心拍相比稍低。表1为软硬件平台测试集的性能指标结果,其中Acc, Sen指标仅有0.01%和0.05%的精度损失,而Spec和Ppr指标与软件平台结果一致。
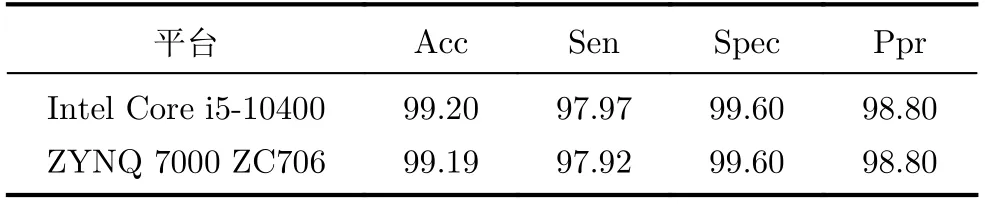
表1 软硬件平台测试集的性能指标(%)

图8 FPGA硬件分类结果的混淆矩阵
4.2 硬件实现性能评估
表2为本文硬件实现的性能比较,目前基于FPGA实现的1D-CNN模型加速器的文献与研究较少,并且相关硬件参数结果不够详细,因此本设计与基于2D-CNN模型VGG-16的CNN加速器进行性能比较。由于采取网络模型不同导致了硬件的吞吐性能存在一定差异,为使性能比较更为直观,本文使用硬件效率(Efficiency)和DSP效率(DSP Efficiency)作为CNN加速器的性能评估指标,可以客观地评价CNN加速器的单位硬件资源所实现的性能。
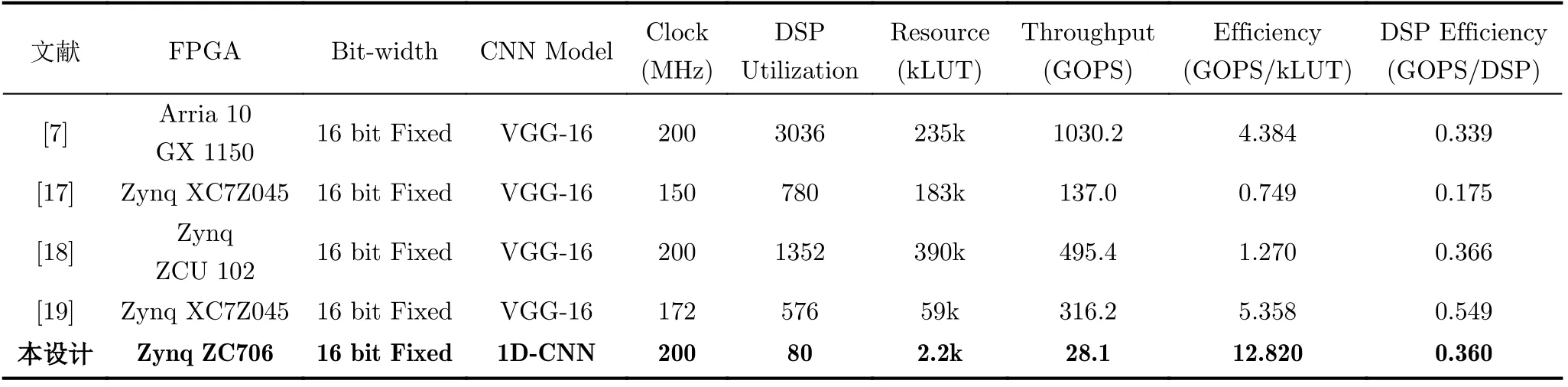
表2 CNN加速器性能比较
文献[7]充分分析了卷积循环原理,提出了一种特定的CNN加速数据流来达到最小化数据通信和提高硬件效率的目的,实现了较高的运算性能;文献[18]采用了一种稀疏数据流可以跳过零权重乘加运算的周期,并对加速器架构和循环平铺进行了共同设计,最大限度地减少了片外存储访问,同时提升了整体性能,该加速器在所列出的文献中达到了第2高的DSP效率;文献[19]基于有效脉冲响应算法提出了一种快速卷积单元(FCU),有效地提升运算单元的硬件效率,其DSP效率为所列出的文献中最高。本设计消耗的资源为2247个LUT、1472个FF、907片Slice、15块BRAM以及80个DSP单元,并能在36.58 μs完成单次心拍预测,所设计的CNN硬件加速器与列出的文献相比,达到了第3高的DSP效率,并且硬件效率达到了12.82 GOPS/kLUT,是文献[19]的2.39倍。
5 结束语
为了降低心血管疾病对人类健康的威胁,针对可穿戴设备应用场景,本文设计了一种面向心电检测的混合多模卷积神经网络加速器。该加速器采取了一种多并行展开策略和多数据流的运算模式完成了卷积循环的加速和优化,设计了相应的3D-PE阵列能在时间和空间上高度复用运算数据,并在Xilinx ZYNQ FPGA平台进行原型验证。本设计的工作频率为200MHz,能在36.58 μs完成单次心拍预测,并且该CNN加速器的硬件效率达到了12.82 GOPS/kLUT,与同类文献比较,该设计硬件效率以及资源开销表现出色,在可穿戴设备场景具有一定的应用价值。
