基于强化学习的多核芯片动态功耗管理框架
2023-02-18曾旭东陈宇飞孙凇昱罗国杰尹勋钊
卓 成 曾旭东 陈宇飞 孙凇昱 罗国杰 贺 青 尹勋钊
①(浙江大学工程师学院 杭州 310015)
②(浙江大学信息与电子工程学院 杭州 310027)
③(北京大学信息科学技术学院 北京 100871)
④(杭州行芯科技有限公司 杭州 310052)
⑤(浙江省协同感知与自主无人系统重点实验室 杭州 310015)
1 引言
近年来,人工智能和物联网技术快速发展,移动智能终端(如车载计算平台、智能手机、平板等)的数量急剧增长。随之,各种应用服务的爆炸性激增对计算能力与能效提出了严格的要求[1-4]。虽然智能终端搭载的多核处理器的处理能力越来越好,但终端严苛的散热设计功耗(Thermal Design Power)不允许芯片长时间运行在高发热的高性能模式[5]。这极大地限制了多核芯片的计算性能和智能终端的运行效率。
为了解决上述问题,基于动态电压频率调节(Dynamic Voltage and Frequency Scaling,DVFS)的多核芯片动态功耗管理技术作为一种可行的方案被提出[6-9]。DVFS[10,11]可以在芯片运行期间实时地、独立地调节内核的工作电压和频率大小,以控制芯片的功耗与发热,因此大多数多核处理器都支持该技术。动态功耗管理技术尝试找到一种DVFS调节策略,在满足智能终端温度要求的同时,使多核芯片发挥出最高的计算性能,从而提供高效顺畅的用户体验。
目前,已有许多关于智能终端中多核芯片动态功耗管理问题的研究。文献[12]根据CMOS电路功耗与频率间的3次方关系、BIPS(Billion Instructions Per Second)与频率间的线性关系,预测每个内核在不同电压频率下的功耗和BIPS,再以芯片的BIPS为优化目标进行实时DVFS。文献[13]将芯片性能建模为线性依赖于频率,然后将功耗管理表述为线性规划问题,通过单纯形法求解功耗管理策略。文献[14]通过建立温度模型计算芯片的功耗预算,将性能最大化转换成一个凸优化问题,然后利用梯度寻找合适的DVFS设置。文献[15,16]讨论了将强化学习中的算法应用于动态功耗管理的可能性,在芯片温度受限的场景下,以优化芯片性能为目标,提出了基于强化学习Q-Learning算法的动态功耗管理技术。但此类算法需要对环境状态进行离散化,因此对存储空间的需求会随着芯片核数的增加而爆炸式增长。
综上所述,面向智能终端设计高性能的多核芯片动态功耗管理技术已经受到了国内外学者的广泛关注与研究,已有工作[12-14]依赖于精确的功耗、温度、性能模型,需要大量且复杂的计算,这与其所分配的有限的计算资源相冲突,因此不易得到最优的DVFS调节策略;并且这些定制化的模型可迁移性较弱,难以被广泛应用于不同的智能终端。同时[15,16]存在存储爆炸的问题,无法满足芯片内核数量的增长趋势。在智能终端不断迭代与芯片内核数不断增长的今天,寻找一种灵活的多核芯片动态功耗管理技术将具有重要研究意义。因此,本文以优化智能终端中多核芯片性能为目标,构建了一个基于GEM5的多核芯片动态电压频率调节仿真平台,在此平台基础上研究智能终端中安全温度限制引起的多核芯片性能优化问题。本文主要研究工作如下:
(1)首先建立一个基于GEM5的多核芯片动态电压频率调节仿真平台,用于仿真验证。
(2)然后提出一种多核芯片动态功耗管理框架,该框架包含一种多核芯片实时功耗模型的建模方法,以及一种基于DQN的动态功耗管理算法。该框架将智能终端中安全温度限制引起的多核芯片性能优化问题视为一个马尔可夫决策过程,可以在周期时间节点上获取芯片当前的状态信息,然后为每个内核调节合适的电压频率,以达到优化计算性能的目的。
(3)最后将本文所提动态功耗管理框架应用到两核Cortex-A57芯片系统上,通过仿真验证了框架的有效性,可以提升2%~4%的芯片计算性能。
2 系统与问题描述
2.1 系统
如图1所示,本文基于GEM5建立了一个多核芯片动态电压频率调节仿真系统。GEM5[17]是一款开源的计算机架构模拟器,可供自由配置处理器、存储系统等模块以模拟出不同结构的计算系统。此外,GEM5还支持对处理器进行DVFS,因此被广泛应用于计算机功耗与电源管理相关的研究。图1系统以一个N核的处理器芯片作为底层计算硬件,搭载有操作系统,可以运行任意应用程序,定义芯片的安全温度为Tlimit, 内核集合为N={1,2,...,N}。内核可以工作在M个不同的电压频率等级下,定义内核的电压频率等级集合为M={1,2,...,M}。假设系统运行应用程序的过程可以划分为τ个时隙,时隙j∈J={1,2,...,τ}, 每个时隙的长度为Δ。操作系统下的动态功耗管理流程为:首先获取芯片每个时隙j内的平均功耗Pj以及时隙j末的瞬时温度Tj, 然后在下一个时隙j+1初调节内核的电压频率至 VFj+1。其中,功耗Pj和瞬时温度Tj分别使用McPAT[18],Hotspot[19]仿真,以获得参考功耗及参考温度。

图1 多核芯片动态电压频率调节仿真系统
2.2 问题描述
为了对芯片的计算性能进行优化,本文以最大化芯片在时间twork=τ×Δ内执行的总指令数Itotal为目标。因此智能终端中多核芯片性能优化问题可以表示为

式(1)为优化目标函数,其中Ij表示芯片在时隙j内所执行的指令数;f表示芯片在不同电压频率设置下的计算能力; π表示一种功耗管理策略,可以根据Pj-1,Tj-1作出电压频率调节。
3 动态功耗管理框架
图2展示了本文提出的基于强化学习理论的多核芯片动态功耗管理框架。考虑到市面上的芯片一般不含内置的功率计,无法满足本文框架对实时功耗获取的需求,因此该框架包含两个主要工作:(1)构建芯片的实时功耗模型;(2)训练功耗管理算法。首先,该框架通过在芯片上运行基准测试程序,采集芯片的内部数据与参考功耗分别作为自变量和预测量建立功耗模型。然后使用功耗模型和Hotspot组成功耗管理算法的强化学习环境。最后,使用本文所设计的动态功耗管理算法在环境中训练出功耗管理策略,用于优化芯片在安全温度限制下的性能。

图2 多核芯片动态功耗管理框架
4 功耗模型
当处理器芯片执行任务程序时,会触发各种硬件事件:如数据内存访问、指令缓存访问等。不同硬件事件的触发将产生不同的动态功耗[20,21]。因此本文将借助性能计数器(Performance Monitoring Counters),通过采集各种硬件事件的触发次数来构建功耗模型。
考虑到动态功耗管理所分配的计算资源有限,本文采用了一种基于拟合优度R2的硬件事件筛选算法[22],可以从上百种硬件事件中筛选出与芯片功耗相关性最强的事件集合E。从而可以在保证模型精度的同时,压缩模型的计算复杂度。筛选算法具体如下:
步骤1 初始化事件集合E=∅,E包含被选中的硬件事件;
步骤2 初始化拟合优度集合R=∅;
步骤3 从未选中事件中依次取出一个硬件事件e,加入集合E中:E=E+e;
步骤4 以事件集合E作为自变量,通过建立回归模型计算E与芯片功耗之间的拟合优度R2E;
步骤5R=R+R2E;
步骤6E=E-e;
步骤7 重复步骤3-步骤6,直至遍历所有未选中事件;
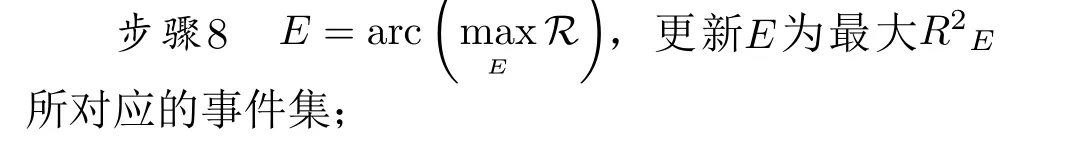
步骤9 重复步骤3-步骤8,直至m axR满足精度要求。
将该算法应用于图1(N核Cortex-A57处理器)系统上的结果如图3所示,其中横轴表示每次通过筛选算法迭代出来的被选中硬件事件;纵轴表示集合E在依次加入被选中硬件事件后与参考功耗之间的拟合优度。图3显示当E={CPU_CYCLES}时,R2=0.61; 当E={CPU_CYCLES,BUS_ACCESS}时,R2=0.76 ···完成筛选后的事件集合E将包含9种硬件事件,与功耗之间的拟合优度接近于1。

图3 拟合优度随硬件事件的筛选而增长
基于E中的硬件事件,本文结合CMOS电路的功耗特征[22-24]提出了图1系统中N核芯片的多元线性回归功耗模型:

式(2)中,Ptotal表 示芯片功耗;E8代表除事件0X67以外的8种被选中事件的集合;β代表模型的回归系数;e代表具体事件;n um代表事件的触发次数;VDD(coreN)表 示内核N的工作电压;fclk(coreN)表示内核N的工作频率;VDD(system)表示核外共享部件的工作电压;fclk(system)表示核外共享部件的工作频率;β0为截距项。


本文在图1(2核Cortex-A57处理器)系统上应用了上述功耗建模算法与公式,通过采集芯片在不同电压频率等级下运行程序时的硬件事件计数值与参考功耗来建立功耗模型。所采集的数据样本,按照0.85:0.15的比例随机划分为训练集与测试集。训练集用于训练功耗模型,测试集用于检验模型的质量。本文基于式(2)在训练集上进行多元线性回归[25]。然后在测试集上对模型质量进行检验,图4展示了模型在测试集上的表现,其中横轴表示绝对百分比误差区间,纵轴表示模型预测功耗与参考功耗之间的绝对百分比误差在各区间的分布情况。虽然图中有少数较大的误差结果出现,但这往往发生在参考功耗较小的情况下,导致即使很小的模型预测误差值也会产生较大的绝对百分比误差。

图4 功耗模型在测试集上的表现

功耗模型在测试集上的平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)使用式(3)进行计算,其中PˆI表示模型的预测功耗,PI表示参考功耗,N表示样本数量。最终功耗模型对测试集的MAPE为5.972%。
5 动态功耗管理算法设计
5.1 强化学习概述
强化学习是机器学习中的一个子领域,它探索如何基于外部环境而行动以取得最大化的预期利益[26],可被用于解决安全温度限制引起的多核芯片计算性能优化问题。因此本文采用强化学习中的算法进行动态功耗管理,接下来将介绍强化学习的理论知识。强化学习是指将智能体放置于环境当中,智能体根据环境状态和行动策略不断采取动作,在此期间学习环境的反馈并优化自己的行为策略,以实现长期累积奖励最大化的过程[27]。强化学习所解决的大多数问题都可以用马尔可夫决策过程(Markov Decision Process, MDP)来表述。本文多核芯片性能优化问题的MDP三要素<S,A,R >可以表述为:
状态空间S:把芯片的功耗与温度设置为环境状态,即sj=(Pj,Tj)∈S。
动作空间A:单个内核具有M个频率、电压等级,因此N核芯片有MN个可配置的频率、电压等级组合。我们将这MN个频率、电压等级组合定义为智能体可采取的动作空间A。
环境奖励R:根据式(1),MDP的优化目标是在运行程序期间最大化N核芯片的累计指令执行数,且温度不能超过Tlimit,因此奖励与指令执行数、温度有关。针对优化目标,本文提出了一种梯度式奖励方法:
步骤1 定义智能体从零时刻开始对芯片进行DVFS,直至终止时刻的过程为一幕(Episode);终止时刻的判定条件为芯片温度超过Tlimit或芯片运行时长达到twork;
步骤2 记N核芯片以中等性能在安全温度下运行twork的 累计指令执行数为Ibench;
步骤3 一幕开始;

步骤6 重复步骤4-步骤5,直至一幕结束。
其中g0,g1, ···,gn是集合G中的元素,本文称G为指令数梯度,G中的元素为实数。r0,r1, ···,rn是集合R中的元素,本文称R为奖励梯度,R中的元素为正实数。G与R的关系如表1所示。

表1 梯度式奖励
本文希望通过设置上述奖励方法作为环境奖励来引导智能体进行学习。当累计指令执行数达到一定数量时,智能体将获得相应的奖励,受此影响,智能体会基于该奖励进一步更新策略以获得更高的奖励。学习能否成功取决于梯度设置是否合理,例如将g0设置得过大,那么智能体可能在“探索”阶段拿不到奖励,导致其始终无法进行有效学习。因此本文将结合实验设置合适的梯度,从而引导智能体逐步改善策略,达到优化芯片性能的目的。
5.2 基于DQN的动态功耗管理算法

步骤1 初始化ε参数,设置折扣率γ;根据图1系统确定动作空间A,安全温度Tlimit,芯片工作时间twork,时隙长度Δ; 设置最大训练幕数Nepi,以及一幕中电压频率等级调整的最大次数τ=twork/Δ;定义训练阈值Ntra, 样本批次大小Nbat,网络更新阈值Nupd;
步骤2 随机初始化行为Q值神经网络与目标Q值神经网络相同;
步骤3 训练幕数nepi=0; 网络训练次数nupd=0;
步骤4nepi=nepi+1 ;j=-1;设置芯片初始状态s0=(P0,T0);
步骤5j=j+1;
步骤6 智能体观察芯片当前状态sj ∈S,根据ε-greedy策略和行为Q值神经网络采取行动aj ∈A,然后获得梯度式奖励rj+1与 新的状态sj+1;将样本数据(sj,aj,rj+1,sj+1)保存到历史样本库中;
步骤7 当样本库中的数量达到训练阈值Ntra时,随机抽取Nbat个样本训练行为Q值神经网络,nupd=nupd+1;
步骤8 当nupd%Nupd=Nupd-1时,将行为Q值神经网络的权重参数赋值给目标Q值神经网络;
步骤9 重复步骤5-步骤8,直至j=τ-1或Tj >Tlimit;
步骤10 重复步骤4-步骤9,直至nepi=Nepi;
参数ε将随着步骤4中训练幕数nepi的增大而衰减,这可以使得智能体在训练前期充分探索环境,在训练后期充分利用所学经验,有利于寻找全局最优解。上述算法的训练框架与流程如图5所示,其中,考虑到样本是由智能体与环境交互所产生的,样本之间存在相关性,因此本文采用了一种如图6所示的历史回放机制,建立了一个历史样本库用于存放样本,然后从中随机抓取网络训练所需的样本,打乱样本之间的相关性,从而满足神经网络训练对样本的独立同分布性要求。

图5 动态功耗管理算法的训练框架与流程
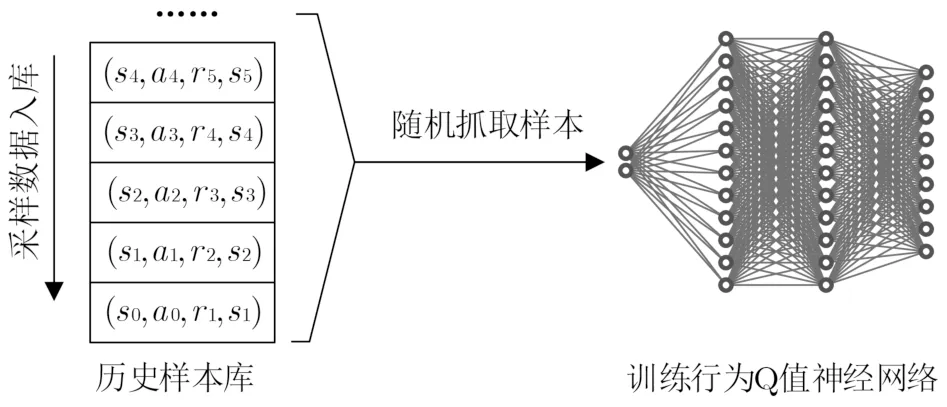
图6 历史回放机制
6 仿真结果
本节将利用动态电压频率调节仿真系统对所提出的动态功耗管理框架进行验证,将本文基于DQN算法的动态功耗管理框架表示为“DDPMF(DQN-Dynamic Power Management Framework)”,并与另外两种传统方案进行比较:
MaxBIPS[12]:该方案由IBM提出,它首先建立芯片功耗与工作频率的3次方模型、BIPS与工作频率的线性模型;然后使用模型预测每个内核在不同电压频率等级下的功耗和BIPS,以最大化BIPS为目标动态调节电压频率等级,同时满足芯片的整体功耗预算。
Ondemand[30]:该方案是Linux默认的功耗管理方案,它定义芯片的负载为总周期数减去内核闲置周期数,再除以总周期数。设有超参数U∈[0,1],在功耗预算内,当芯片在过去一段时间Δ内的负载大于U时,将调整电压频率至最高等级;当负载小于U时,将对内核进行降频。
图1仿真系统的仿真参数设置如下:采用ARM v8-A Cotex-A57内核,内核的可配置电压频率等级数M=3 ,内核总数N=2 。 芯片安全温度Tlimit=70 °C;工作时长twork=9 s;电压频率调节间隔Δ=30 ms。DDPMF中动态功耗管理算法的训练参数设置如下:折扣因子γ=0.99 ;ε的初始值为0.9,衰减速率为-0.0000356,最小值为0.01;Nepi=25000;Ntra=1000;Nbat=64;Nupd=1000;环境奖励梯度设置如表2所示。
图7展示了DDPMF中动态功耗管理算法的训练过程,记录了智能体累积得分随训练幕数的变化情况。在第0到16000幕左右时,智能体只能获得近似0分的奖励,此时仍处于探索状态;从第16000左右幕开始,智能体取得了较为明显的奖励,说明其已经通过探索发现了一条奖励路径;在接下来的几千幕中,智能体在表2梯度的引导下,不断改善自身行动策略,使每幕的得分不断提高,在20000幕附近已经可以较稀疏地获得高分,直到24000幕左右时基本每幕都能稳定获得高分,说明算法已经收敛,找到了最优的动态功耗管理策略π′。

图7 DDPMF中动态功耗管理算法的训练过程

表2 环境奖励梯度


7 结束语
本文针对移动智能终端中安全温度限制引起的多核芯片计算性能优化问题,提出了一种动态功耗管理框架(DDPMF)。首先介绍了一种功耗建模方法,用于获取CMOS多核芯片的实时功耗。然后,设计了一种基于DQN的动态功耗管理算法,结合有效的梯度式环境奖励进行训练,得到了最优的多核芯片动态功耗管理策略。仿真结果显示,本文DDPMF与其他方案相比,能够有效实现多核芯片的计算性能优化。

图8 3种动态功耗管理方案(或策略)在多核芯片DVFS仿真系统上的性能对比实验结果
