多尺度特征融合的轻量型垃圾分类方法
2023-02-17段中兴何宇超
高 静,段中兴,何宇超
(西安建筑科技大学 信息与控制工程学院,西安 710055)
1 引 言
随着我国人民对生活各方面需求的不断提高,各类生活垃圾数量急剧增加,2019年我国生活垃圾清运量为2.42亿吨,其中45.2%被卫生填埋,50.2%被焚烧处理,绝大多数垃圾由于未做分类,不能回收利用.现今垃圾分类以人工分类为主[1],由于垃圾种类繁多,分类时由于辨识困难,垃圾回收工作难以从源头顺利进行,用于垃圾分类的移动端app等辅助工具对于居民进行分类投放或工厂进行自动化分拣具有非常重要的价值.垃圾分类属于典型的细粒度图像分类问题,相比于其他图像分类有更多的挑战,也有很强的实用价值.
垃圾分类模型要落地于实际工程应用,对模型的要求不仅聚焦于精度高,还有体积小与速度快.近年来,相关学者对于垃圾分类等细粒度图像分类问题展开研究,赵冬娥等[2]提出对垃圾红外光谱的高光谱图像,分析其反射率光谱信息,为改进垃圾分类技术提供了新思路;何凯等[3]提出将注意力机制嵌入到不同尺度当中,进行特征融合之后,精确地提取显著性特征;高明等[4]提出了端到端的迁移学习网络架构GANet(Garbage Neural Network),在网络中使用一种像素级注意力机制PSATT,对于易混淆的垃圾图像分类效果有所提升;钱涛等[5]结合MV-PearINet与K-means方法,将无监督聚类算法应用到特征提取中,对于珍珠细粒度分类取得了不错的效果.对于小样本学习,近年来许多相关方法[6-8]被提出,其中最多的就是应用迁移学习[9],通过预训练来缓解样本不足的问题.
现有图像分类方法执行垃圾图像分类任务时,具有以下特征:图像背景复杂,目标难以定位;垃圾图像易混淆;目标过于集中部分,容易甄选到次要信息;模型可移植性较差.针对以上问题,文本的主要贡献有:
1)提出由多尺度深度可分离卷积构成的多尺度特征提取模块,在输入层获取更为丰富有效的特征信息;
2)输出层使用锯齿状扩张卷积,获得更大的感受野,较好地保留深层特征信息;
3)对网络进行裁剪,减少模型的参数量与计算量,使模型能够兼顾快速性与准确性要求.
本研究还在网络的输入端使用Gridmask数据增强,提高了数据的多样性,将预热与余弦退火相结合优化学习率,有效避免收敛不稳定或后期收敛慢的问题.在“华为云”竞赛提供的数据集上,经过多角度的实验分析,验证了提出模型的优越性.
2 网络结构与算法原理
2.1 多尺度特征提取模块
深度可分离卷积将单个卷积核的任务转变为映射跨通道相关性和空间相关性,把传统的三维(3D)卷积核分解为一个逐通道处理的二维(2D)卷积核和一个跨通道1×1大小的3D卷积核来增强特征提取.
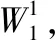
W1=Ck×Ck×P×Q
(1)
(2)
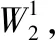
W2=Ck×Ck×1×1×P+1×1×P×Q
(3)
(4)
深度可分离卷积与普通卷积的参数量比值为W,如式(5)所示:
(5)
当卷积核为3×3×128,输入通道与输出通道均为128时,传统卷积的参数量为147456,而深度可分离卷积的参数量为17536,同比缩减了88.12%.对比二者可知,采用深度可分离卷积相比传统卷积能够缩减运算的复杂度.
卷积尺寸单一在一定程度上限制了特征的提取能力,而原深度可分离卷积的Depthwise卷积均使用固定的3×3的卷积核,为获取更为丰富的特征信息,本文使用多尺度深度可分离卷积替换原来的3×3卷积核,获取不同尺寸大小的感受野,将不同尺寸的特征融合,进一步提高模型分类精度,有效应对垃圾图像背景复杂与目标不突出带来的挑战.
如图1所示,首先进行特征降维,使用1×1标准卷积将输入特征通道压缩为特定数目的特征通道.例如,将G个输入特征通道压缩为G/2、G/4、G/8以及G/8 4种数量的特征图,对压缩后的每个特定通道上的特征图进行Depthwise卷积,卷积核的大小分别为1×1、3×3、5×5以及最大池化,Depthwise卷积的计算如式(6)所示:
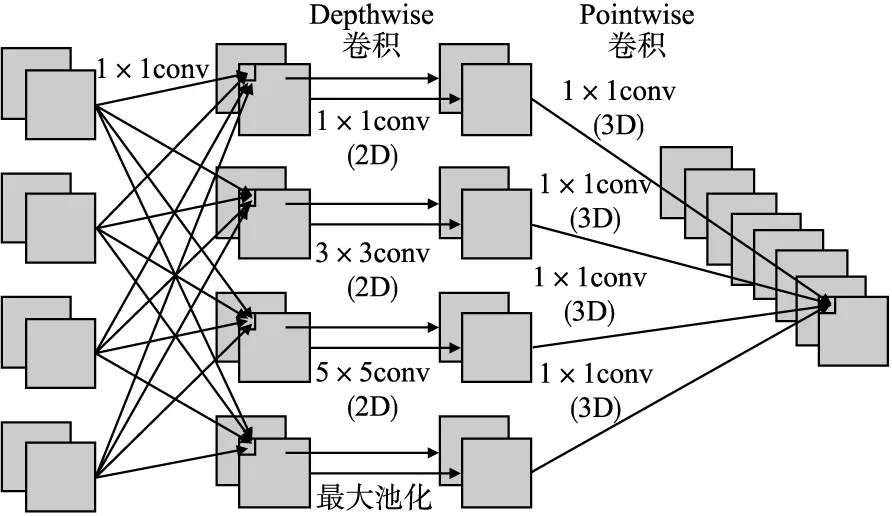
图1 多尺度深度可分离卷积Fig.1 Multiscale fusion depth separable convolution
(6)
式中,d(*)(i,j)为输出特征图坐标(i,j) 处的值,K和L分别为卷积核的宽度和高度,W(k,l)为卷积核中(k,l)的值,y(i+k,j+l)为输入特征图中坐标(i+k,j+l)的值.将多尺度特征卷积通过1×1卷积,卷积之后将特征融合,Pointwise卷积计算如式(7)所示:
(7)
式中,p(*)(i,j,n)为输出特征图坐标(i,j,n) 处的值,Wm为第m个1×1卷积核,y(i,j,m)为第m个输入特征图中坐标(i,j)的值,M为输入特征图的数量.
多尺度特征提取模块由3个多尺度深度可分离卷积叠加连接后与1×1卷积和批归一化融合层经过残差连接组成,如图2所示.在模块输出端引入样本的前馈通道构成闭环,将残差部分与卷积通道部分的输出特征相加,构成浅层特征与深层特征的结合,使深度卷积神经网络的权值收敛更加有效.对于背景复杂与重要特征不突出的垃圾图像,使用多尺度可分离卷积代替最大池化层可以提取任意分辨率的特征,获得通道面上“最有价值”的特征分布,将1×1的卷积与BN(Batch Normalization)[10]融合,能够提高网络的运行速率.
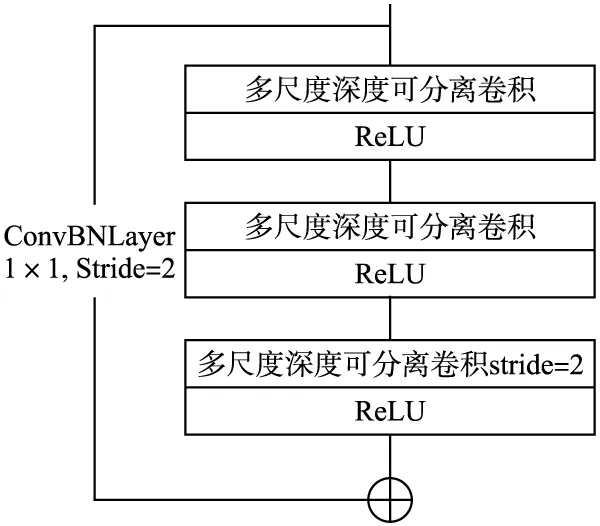
图2 多尺度特征提取模块Fig.2 Multi-scale feature extraction module
令垃圾图像X={x1,x2,…,xN},其中xi表示任意垃圾图像,N表示垃圾图像总数;Z={z1,z2,…,zN}表示垃圾图像的对应类别标签.垃圾图像与对应标签之间的映射关系为f(g),如式(8)所示:
Z=f(X,ω)
(8)
式中,ω为网络中的权重.
多尺度特征提取模块的输入输出映射关系为,如式(9)所示:
fc(X,ω)=H(X)-φ(X)
(9)
其中,H(X)表示网络输入X的期望输出;H(X)-φ(X)表示网络的输出与输入的残差,φ(X)表示1×1卷积通道的输出.
2.2 锯齿状扩张卷积
扩张卷积在Deeplab系列[11]模型中用来解决在语义分割中由于下采样引发的特征丢失问题,在不改变特征图尺寸的前提下,仍能获取更大的感受野.为了获取更深层的特征,在输出层使用状扩张卷积,由于扩张卷积核有间隔,当叠加的卷积层都采用相同的扩张率,会导致整体特征图的像素产生中断,发生像素遗漏.如图3所示,使用扩张率均为2的扩张卷积,会出现网格效应[12],白色像素块在卷积时会被遗漏.因此,本设计采用扩张率为[1,2,3]的锯齿状扩张卷积.
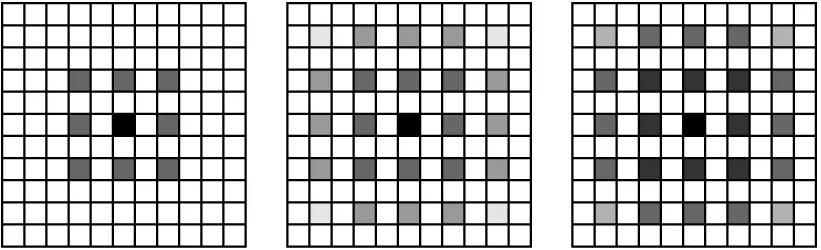
图3 扩张率均为2的扩张卷积Fig.3 Expanded convolution with expansion rate of 2
锯齿状扩张卷积[13]采用连续扩张率的扩张卷积,如图4(a)对应扩张率为1的3×3的卷积核;图4(b)为扩张率为2的扩张卷积,感受野为7×7;图4(c)为扩张率为3的扩张卷积,感受野为13×13.采用锯齿状扩张卷积,所有的像素块都能参与到卷积计算中,对于主要特征不突出的垃圾图像,深度提取图像特征,提高分类准确度.
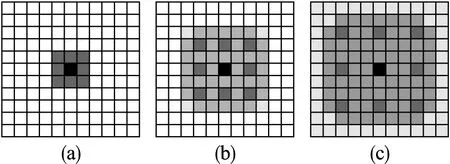
图4 锯齿状扩张卷积Fig.4 Serrated expansion convolution
扩张卷积核和感受野的计算如式(10)和式(11)所示:
fn=fk+(fk-1)×(Dr-1)
(10)
(11)
其中,fk为原始卷积核的尺寸;fn为扩张卷积核的尺寸;Dr为扩张率;lm-1为第m-1层感受野的尺寸;lm为经过扩张卷积后第m层感受野尺寸;Si为第i层步幅大小.
2.3 模型裁剪优化
模型的精度、大小以及推理时间都是决定其工程应用价值的重要指标,本文在不影响模型性能的情况下,去掉一些冗余的部分以减少参数量与计算量.Xception架构的中间层由8个相同的残差模块组成,由于多尺度深度可分离卷积具有较强的特征提取能力,在网络浅层便可获取到丰富的特征,因此,在中间层以1个残差模块为单位裁剪尺度,进行裁剪.经实验得到,当裁剪尺度为2时,模型精度略微下降,推理时间有效减少,综合表现最佳.
2.4 ML-Xception模型
ML-Xception(Multiscale Lightweight Xception)网络是基于Xception[14]框架改进的一种轻量型多尺度特征融合的网络模型.Xception体系架构由36个卷积层组成的残差连接模块构成网络的特征提取基础.Xception与InceptionV3架构的参数量相差不多,但精度有所提升,一定程度上归因于参数更加有效.基线模型性能对比如表1所示.
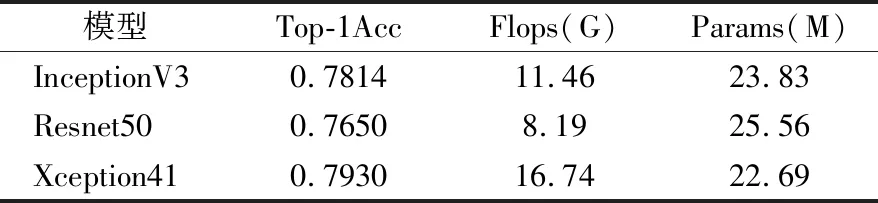
表1 基线模型性能对比Table 1 Performance comparison of baseline models
如图5所示,对于输入图像x∈RH×W×C,首先经过conv_1和conv_2两个普通卷积,初步提取图像特征,原始特征与权重系数对应相乘后获得权重分配的新特征,依次输入到3个多尺度特征提取模块中进行特征学习,3个模块中的多尺度深度可分离卷积为3×3×128、3×3×256以及3×3×728;经过中间层的6个残差模块获取较深层特征;经过输出层的多尺度特征提取模块4,将特征输入到具有连续扩张率的扩张卷积中,获取更深层的特征;将全部特征通过自适应池化,使用Dropout模块丢弃部分特征,最终经过全连接层输出图像分类结果.
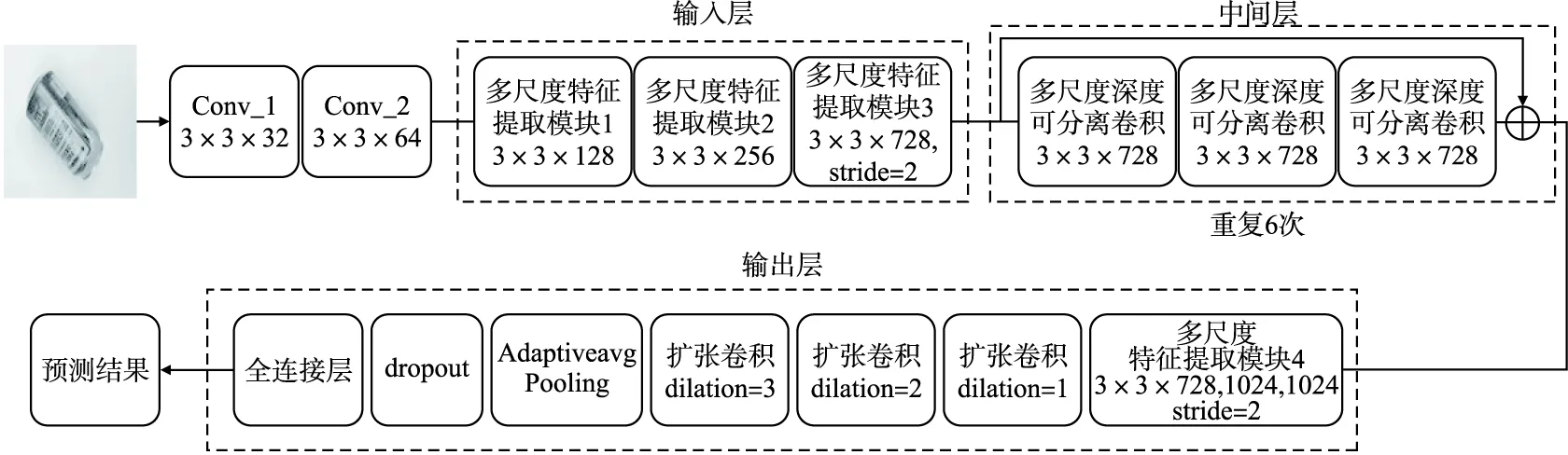
图5 ML-Xception模型框架Fig.5 ML-Xception model framework
3 训练优化策略
对ML-Xception模型使用的训练优化策略如表2所示.

表2 训练优化策略Table 2 Training optimization strategy
3.1 数据预处理与Gridmask数据增强
本研究的训练数据采用“华为云人工智能大赛·垃圾分类挑战杯”赛方依照深圳市颁布的垃圾分类标准制作的数据集,共包括14000余张垃圾图像,分别为厨余垃圾、可回收垃圾、有害垃圾、其他垃圾4大类,共40小类.进行深度学习训练之前要对图像进行预处理,根据计算资源和结果的可靠性,将图像统一调整尺寸为224×224的像素大小,再进行数据增强操作.本研究采用GridMask数据增强[15]方法对原数据集进行增强.
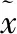
3.2 优化方法
深度卷积神经网络模型在进行训练时,要利用优化器来提高收敛速度与收敛精度,本研究采用自适应随机优化算法Adam[16].Adam算法兼具AdaGrad和RMSProp两种算法的优点,动态调整每个参数的学习率,因此本研究采用Adam优化方法来优化模型.
3.3 损失函数
采用交叉熵(cross entropy)作为损失函数来计算目标与预测之间的差距.计算如式(12)所示:
(12)
其中,Closs为损失值,m为参与训练的样本量,n为参与训练的类别数,q(xij)表示样本x(i)为标签j的概率,p(xij)表示模型预测样本x(i)为标签j的概率.对本文研究的这种多类别分类问题,交叉熵损失求导更简单,有利于加快模型的推理速度,因此本研究选择交叉熵作为损失函数.
3.4 学习率优化策略
传统的学习率优化方式是给定一个学习率初始值,直接在此基础上梯度下降更新学习率,由于模型的权重是随机初始化的,给定学习率的大小会直接影响模型的稳定性,若给定学习率过大可能会导致模型振荡.因此本文提出预热与余弦退火[17]相结合的学习率控制策略.首先采用warm-up预热的方式,开始训练时采用小的学习率,随着模型慢慢适应新数据集,逐步增大学习率,直到达到最初设置的较大学习率时再采用最初设置的学习率进行训练,然后采用余弦退火(Cosine annealing)算法来降低学习率.避免了因为学习率过大导致振荡的发生.余弦退火通过余弦函数来降低学习率,学习率计算过程如式(13)和式(14)所示:
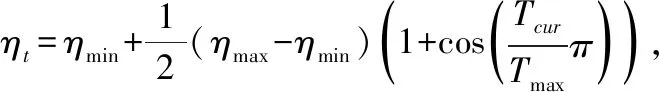
(13)
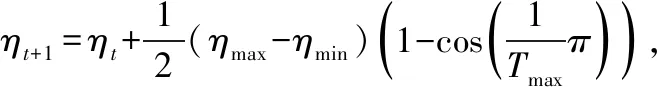
(14)
其中ηmax,ηmin的初始值为学习率的最大值(初始学习率)和最小值(默认值为0),定义了学习率的范围,Tmax是训练的轮次上限,Tcur是训练过程中的当前训练轮数.本文提出的学习率优化策略不仅能够降低模型对最大学习率的敏感性,还有助于提高模型收敛阶段的稳定性.
3.5 权重衰减
在深度卷积网络训练过程中,为了防止模型过拟合采用权重衰减[18],通过权重衰减(L2正则化)缓解模型过拟合,权重变化如式(15)所示:
(15)
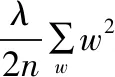
4 实验设计与结果分析
4.1 实验环境与评价指标
实验中用到的软硬件配置以及训练参数设置如表3和表4所示.
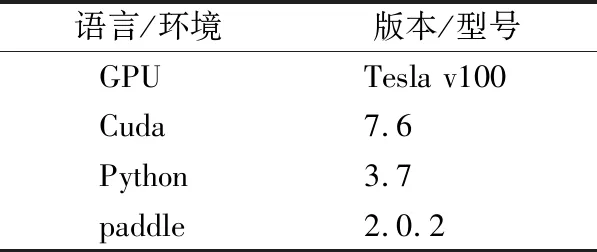
表3 实验配置Table 3 Experimental configuration

表4 训练参数设置Table 4 Training parameter settings
评价指标如下:
1)训练精度.训练集的分类准确度,训练精度的计算如式(16)所示:
(16)
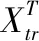
2)验证精度.验证集的分类准确度,验证精度的计算如式(17)所示:
(17)
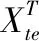
4.2 实验设计与结果分析
为验证不同模型结构以及优化策略的有效性,在“华为云”垃圾分类数据集上,将数据集的90%划分为训练数据,10%为测试数据,进行了相关实验,实验过程及结果如下.
4.2.1 与相关模型的性能对比
将本文模型与InceptionV3、ResNet50以及Xception41模型进行训练及测试,经过7个epoch训练之后,各模型的训练准确率及损失分别如图6(a)、图6(b)所示,为使损失值对比明显,省略前期损失过高阶段,仅绘制70个step之后的损失值.验证准确率及损失如图7(a)、图7(b)所示,最终模型测试结果绘制如表5所示.
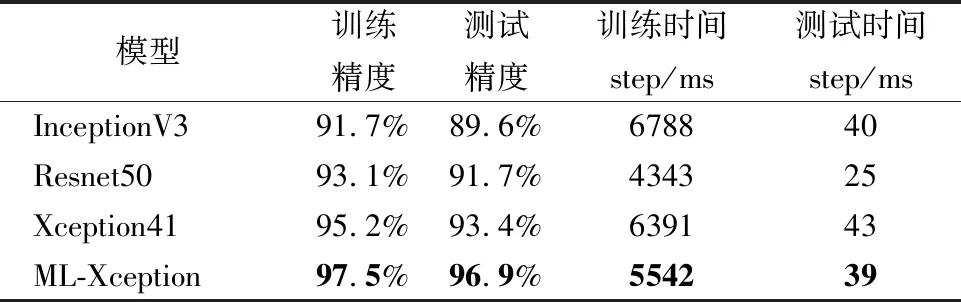
表5 不同模型的结果对比Table 5 Performance comparison of baseline models
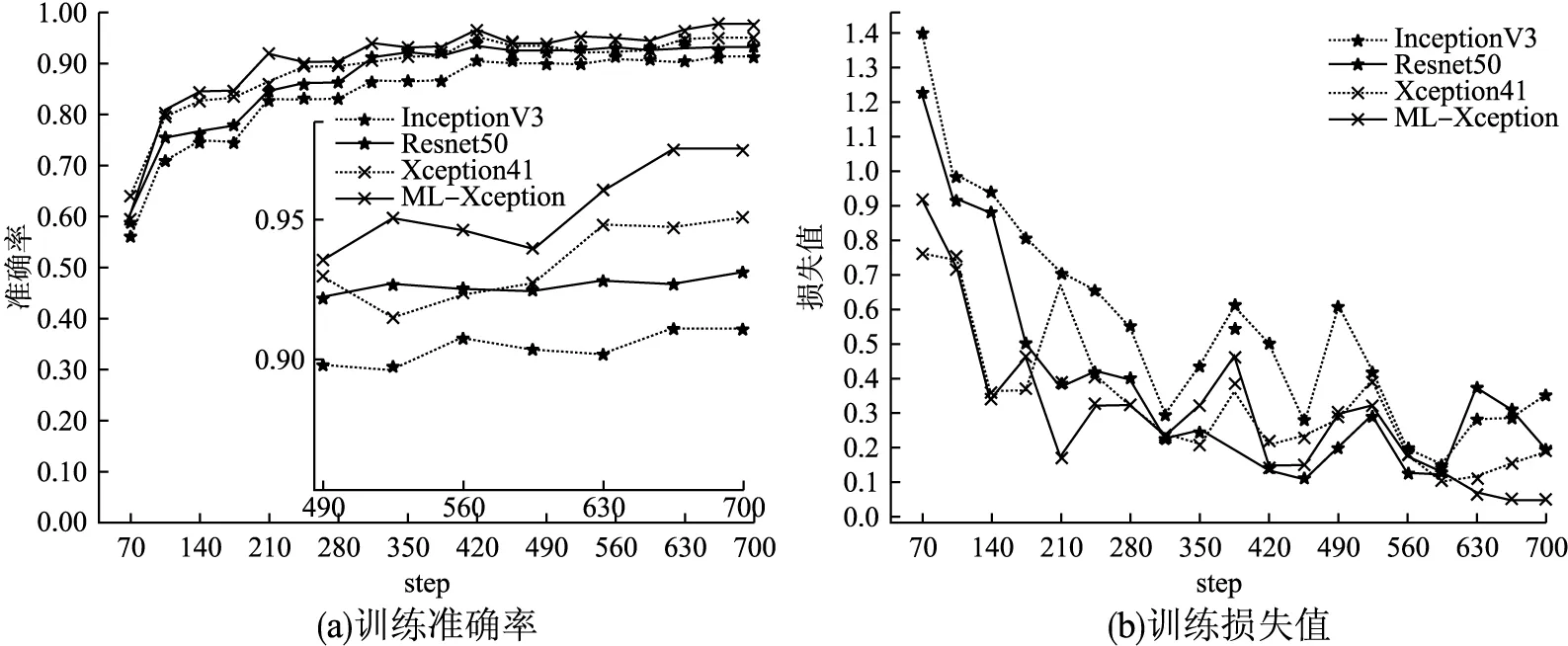
图6 不同模型训练结果Fig.6 Different models training results
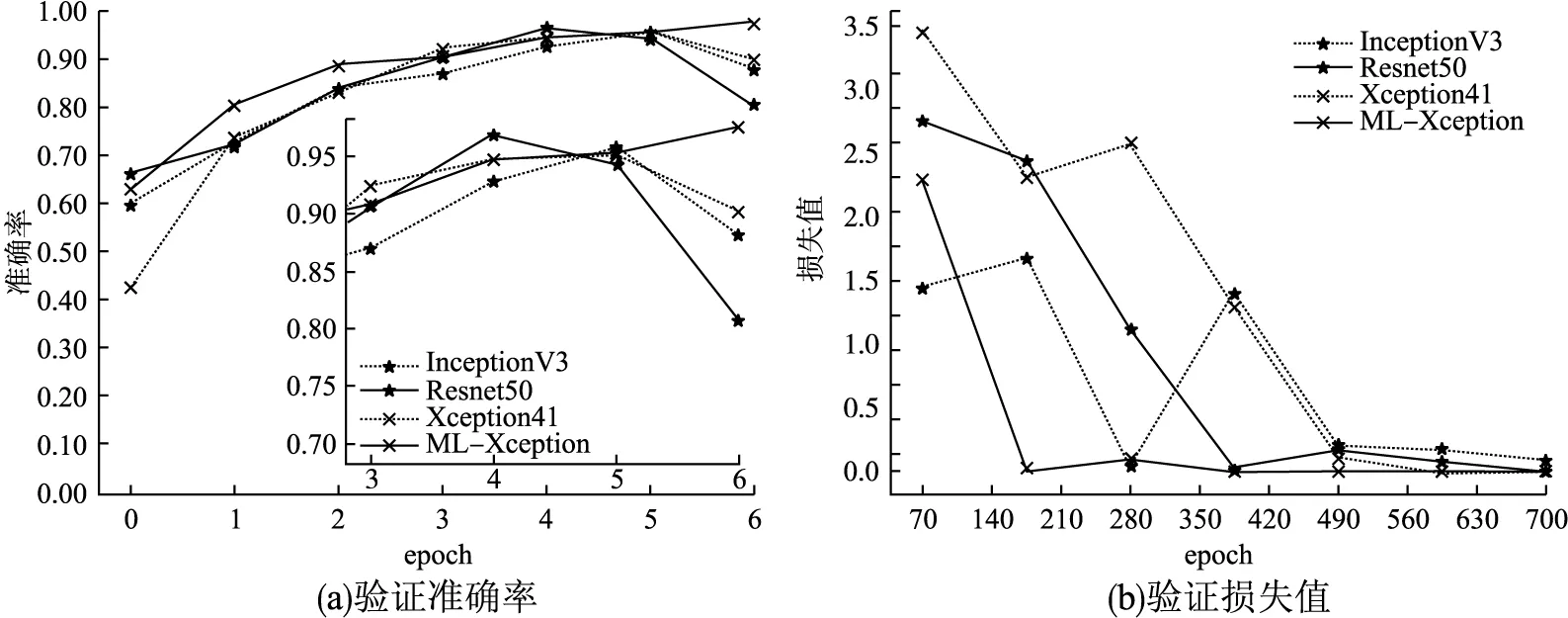
图7 不同模型验证结果Fig.7 Different models verification results
由结果可以看出本文模型损失值的下降速度和收敛速度最快,InceptionV3、Resnet50、Xception41模型的训练精度均低于本文模型,测试精度分别低于本文模型7.3%、5.2%、3.5%,并且测试精度在达到高峰后均有所下降,说明在训练时发生了过拟合,导致训练精度提高,测试精度反而下降,而本文模型表现良好.从第70个迭代周期起,各模型的准确率曲线波动幅度差异逐渐明显,到第600个周期,其他模型曲线基本趋于稳定,而本文模型仍呈上升趋势,稳定之后与Xception模型曲线准确率相差约2.3%.该高度差产生的原因有:多尺度特征提取模块是一个全部由多尺度深度可分离卷积构成的残差模块,替换了池化层后避免了对特征的随意丢弃,其中线性残差部分是1×1卷积和批归一化层融合的模块,多尺度深度可分离卷积将不同尺寸的特征图融合起来,残差模块将浅层与深层特征融合,使得模型特征更加丰富;输出层使用锯齿状扩张卷积扩大了卷积核的感受野,进一步提高了特征提取能力,使得分类性能有比较大的提升.
4.2.2 多尺度特征提取模块有效性验证
为了验证多尺度特征提取模块的有效,实验对比了Xception、使用深度可分离卷积替换了最大池化后的模型Xception-Sep以及使用了多尺度特征提取模块的模型Xception-D,结果如表6所示.使用可分离卷积替换最大池化,减少了特征丢失,模型的分类准确率提高了0.3%,一定程度上提高了模型的特征提取能力,采用多尺度特征提取模块的模型相较Xception模型,分类精度提高了1.1%,多尺度卷积的引入使得模型的复杂度变高,参数量增多,但残差模块中将卷积层和批归一化层融合,有利于优化计算复杂性.结果表明,多尺度特征提取模块有利于特征信息的提取,提高分类准确率.

表6 不同特征提取模块对比Table 6 Comparison of different feature extraction modules
4.2.3 锯齿状扩张卷积的有效性验证
对比扩张率不变与锯齿状扩张卷积两种结构下的ML-Xception网络性能,实验结果如表7,采用相同扩张率的扩张卷积训练精度提高了0.3%,锯齿状扩张卷积的训练精度提高了1.7%,说明其对于深层特征提取的有效性.
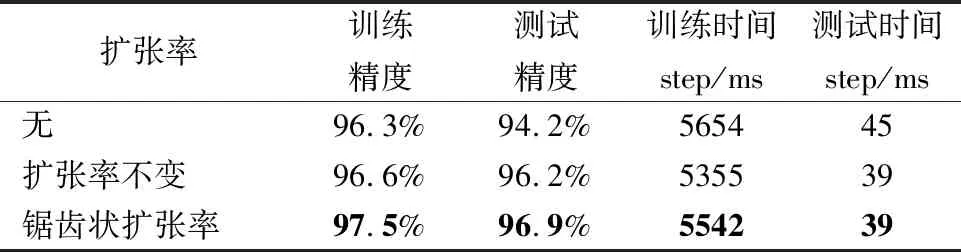
表7 扩张率设置对比实验Table 7 Comparative experiment on expansion rate setting
4.2.4 模型裁剪优化验证
对Xception架构中间层的残差模块进行裁剪,对比模型性能,确定最佳网络深度,结果如表8所示.
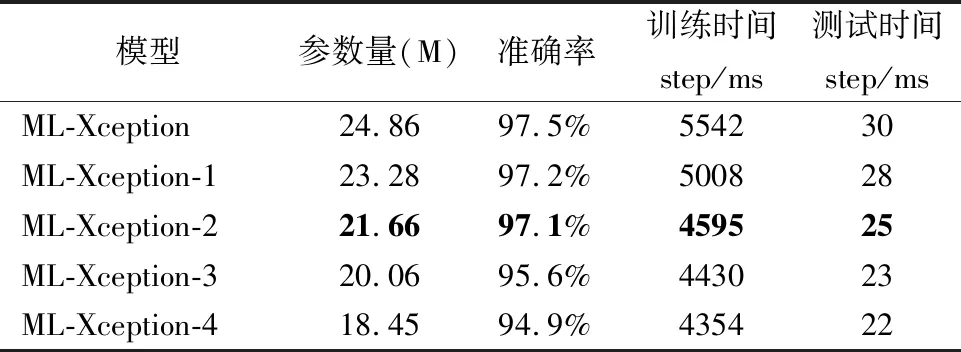
表8 裁剪模型性能对比Table 8 Performance comparison of cutting models
由表中结果可知,当裁剪的残差模块数量为2时,模型的精度略有下降,但推理时间减少较多,综合性能最优.因此选择裁剪2个残差模块,使模型兼顾较少的参数量与高精度的要求.由于中间层的残差模块均相同,因此裁剪结果与裁剪位置无关.
4.2.5 训练优化策略的有效性验证
设置不同优化策略组合,对比分析实验结果,验证数据增强、Dropout、预热组合优化的有效性.
由表9可知,增加预热之后模型收敛时间减少了27ms,精度增加了1.6%,说明了预热对于模型训练的有效性,增加数据增强和Dropout之后,测试精度与训练精度的差距减少至0.5%,说明模型的鲁棒性得到提升,但是数据增强扩充了样本复杂度,在相同的训练批次下,训练精度会有所下降,最终组合3种优化策略,训练精度和测试精度都得到较大幅度的提升.结果表明,该训练优化策略对模型性能有显著提升效果.

表9 优化策略性能验证Table 9 Performance comparison of optimization strategy
5 结 论
本文针对现有垃圾图像分类方法不能兼顾高精度和低延时的要求,存在垃圾类别易混淆等问题,设计了一种多尺度特征融合的轻量型分类模型ML-Xception,相较于传统模型,该模型使用多尺度特征提取残差模块,进行不同尺寸的特征融合,浅层特征与深层特征的融合,分类精确度提高了1.1%,引入锯齿状扩张卷积,显著提升模型精度,裁剪模型,进一步优化模型的复杂度和参数量.同时,本文所使用训练策略,可以推广至其他同类问题,结合预热与余弦退火学习率控制策略,实现学习率的凸变化,配合Adam优化方法以及数据归一化,加快模型收敛速率,运用Gridmask和随机翻转等数据增强结合迁移学习,可缓解小样本集训练过拟合问题,综合以上策略,使模型的训练更加平滑,达到最优状态.
在后续研究中,可以尝试应用无监督等算法,自动标注海量缺失标注样本,或者使用GAN网络等生成模型,扩充数据集,进一步提升模型的实用性.
