一种视频多模态数据自适应采集策略
2023-02-17刘荆欣
肖 萍,刘荆欣,王 妍,臧 洁
1(中国刑事警察学院 公安信息技术与情报学院,沈阳 110854)2(辽宁大学 信息学院,沈阳 110036)
1 引 言
截止2020年12月,我国网络视频用户规模达9.29亿,占网民整体的93.7%[1].网络视频内容极大程度影响着整个网络空间的生态环境.目前针对网络直播出现的违规行为情况多采用事后处置的方式,在违规行为已经实施并产生一定影响后,管理部门才会介入处理.于是,视频内容分析成为了研究领域的热门课题.然而,在对视频内容进行分析过程中,视频数据的采集呈现了一系列新问题:冗余数据占用资源过多及遗漏关键信息等问题[2-6],极大程度上影响了视频内容分析的资源效用.因此,如何高效采集视频数据对于提高视频内容分析效率起着关键作用.
实际应用中现有视频数据采集设置固定采集频率,不足之处在于一方面会采集到冗余数据,增加存储和处理成本;另一方面会丢失关键数据,不能根据视频数据的变化趋势实时动态调整采集频率,无法高效采集数据.为解决上述问题,本文提出了一种基于热度因子的视频多模态数据自适应采集策略.根据视频的热度变化情况自适应调整采集频率,在降低采集量的同时保证采集数据质量.
主要研究贡献如下:
1)针对视频采集影响因素提取成本高、难以量化的问题,本文提出使用网络直播视频平台中的用户交互性数据中的视频热度数据作为视频采集影响因子,使用“熵权法”计算“关注数”、“点赞数”、“弹幕数”、“分享数”及“在看数”5个热度影响因子对视频的热度影响权重,实现每个时刻视频采集影响因素的量化,为后续采集算法提供更客观准确的依据.
2)本文提出了实施性较强的“基于热度因子的视频多模态数据自适应采集模型”,针对网络直播视频,利用爬虫获取一系列固定时间间隔的热度因子及视频转换后的图像、音频、文本数据,并基于这些数据构建热度因子与图像、音频、文本数据的时间关联矩阵,通过采集算法对视频热度量化数据进行处理,实现采集时刻对应的图像、音频、文本数据的持久化存储.
3)针对现有自适应变频数据采集策略中存在所采数据冗余、遗漏关键信息、执行效率不高的问题,本文提出一种基于多分段旋转门的数据采集策略,根据实时数据构建轻量级预测模型,在降低数据采集量的同时提升了数据采集质量和效率.通过实验从误差分析、数据采集量和采集效率方面验证了采集策略的有效性.
本文后续章节内容为:在第2节中介绍相关工作,阐述了现有文献在视频数据采集方面的研究进展以及待解决问题;第3节介绍基于热度因子的视频多模态数据自适应采集模型,包括热度因子和热度因子的权重计算;第4节介绍多分段旋转门(MSDT)的自适应数据采集策略;第5节通过实验对比数据,分析MSDT的有效性;第6节总结全文.
2 相关工作
近年来,很多学者针对视频的数据采集问题进行了相关研究,主要分为视频采集影响因素与动态调整采集频率两个方面.
在视频采集影响因素的研究中,主要集中在文本语义、像素、场景等因素.XingrunWang等[7]以文本语义特征对视频采集的影响作为研究点,通过神经网络模型计算帧和文本语义的相关性,进而采集与文本描述相关度较大的视频帧.Marcos Vinicius等[8]提出基于颜色共生矩阵来描述视频帧,并选择具有代表性的帧覆盖视频内容.黎洁等[9]提出以上、下行链路的带宽信息及用户的实时视角信息作为VR视频流媒体的自适应采集影响因素.Yunzuo Zhang等[10]提出了利用时空切片来分析对象的运动状态,该文献以对象运动的状态变化作为度量值采集视频信息.戴炀等[11]提出将每个固定长度时间段视频拍摄区域内的环境场景进行建模.根据状态转移概率矩阵和当前的状态来预测未来某个固定长度时间段对应的速度状态,从而实现自适应视频采集.上述频视采集影响因素大都需从视频本身提取,算法复杂度高,不能满足海量网络直播视频数据的采集和处理的实时性需求.
在自适应动态调整采集频率研究方面,目前常用的方法主要有两类:一类是依据历史数据对未来数据变化趋势进行预测,进而调整采集频率.如王妍等[12]提出一种自适应变频数据采集策略SAF,该策略通过构建线性回归模型拟合数据变化趋势,根据数据和模型之间的误差动态调整采集频率,如果真实值与预测值之间的误差小于系统所设定的阈值,则增大下一次采集时间间隔,反之减小下一次采集时间间隔.当数据真实值脱离预测范围时,重新建立预测模型.钟萍等[13]通过一段时间内的数据均方差来判断数据的变化波动情况.这些方法依赖较长时间的历史数据,根据这些历史数据构建预测未来数据变化趋势的模型,模型需要动态调整,计算代价较大.另一类是依据实时数据构建轻量级预测模型.Yang Cui等[14]提出通过SDT旋转门算法检测匝道段事件,该算法通过简单的斜率替换,快速形成上下门之间的预测区域,实时性较高,计算代价较小.缺点是在数据平滑情况下,容错区域永远有效,不会采集数据,这样会丢失背景数据,因此曾文序等[15]提出了相关改进策略SAFC-SDT,该策略在旋转门算法基础上设计了自适应调整采集频率机制,根据位于当前预测模型容错范围内的数据量动态调整数据采集时间间隔,预测模型容错范围内的数据点越多,数据采集时间间隔越大,如果数据值超出容错范围,则迅速减少采集时间间隔,并重新构建下一个预测模型容错范围.采集周期随采集数量增加而加大,虽然解决了背景数据丢失问题,但预测模型转换期间会出现关键信息遗漏问题.
通过分析可以得出,目前的研究未深入分析影响视频热度的相关因素,未考虑视频热度变化对视频采集频率的影响.在动态调整采集频率方法上还存在执行效率低,遗漏关键数据等问题亟待解决.
3 基于热度因子的视频多模态数据采集模型
针对网络直播视频采集场景中存在的丢失关键信息、数据冗余、执行代价大等问题,文本构建了基于热度因子的视频多模态数据自适应采集模型,旨在保证采集效率的同时最大化提高所采数据质量,如图1所示.考虑到采集时刻对应的视频数据所含信息难以量化特点,设计了基于视频热度变化趋势动态调整视频数据采集频率的方法.首先,利用爬虫获取一系列固定时间间隔的热度因子及视频转换后的图像、音频、文本数据,并基于这些数据构建热度因子与图像、音频、文本数据的时间关联矩阵;其次利用“熵权法”计算“关注数”、“点赞数”、“弹幕数”、“分享数”及“在看数”影响因子对视频热度的影响权重,根据各热度因子对视频热度的影响权重计算每时刻视频的热度值,将热度值集合作为输入参数传递给采集模块;最后,采集模块通过自适应数据采集策略依据热度值构建预测模型,根据视频热度值在预测模型内的变化趋势计算下一次的数据采集间隔时间,将其作为输入参数传递给调度进程实现数据采集,从而实现动态调整采集频率:在视频热度迅速上升、下降及高热度持续阶段加大采集量;反之,在视频热度较低持续阶段,降低采集量.
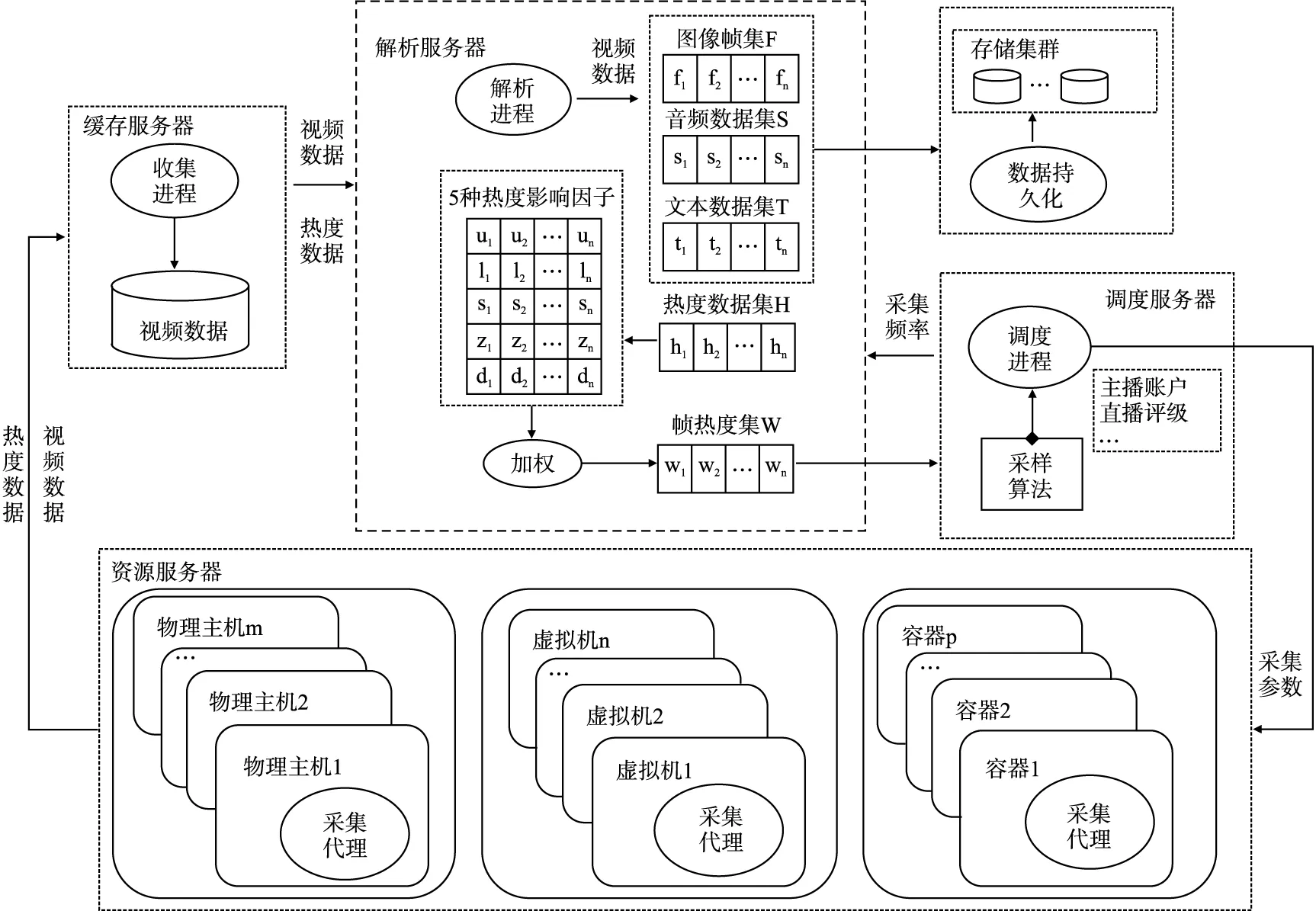
图1 基于热度因子的视频多模态数据自适应采集模型Fig.1 Video multimodal data self-adaptive acquisition model based on heat factors
整个模型分为4个部分:视频数据缓存、视频数据解析、量化视频热度、自适应数据采集.
1)视频数据缓存主要是完成从视频资源服务中采集视频数据及热度影响因子数据发送至缓存服务器中,由调度进程、采集代理和收集进程共同完成.调度进程部署在调度服务器内,根据主播用户身份、直播平台评级信息生成采集地址、采集频率等初始参数,发送至采集代理.采集代理部署在以物理主机、虚拟机或者容器为载体的资源服务器内,接收调度进程发出的采集参数,采集视频数据及“点赞数”等热度影响因子数据定向发送至缓存服务器内,收集进程接收数据进行缓存.
2)视频数据解析.自适应采集视频数据,要实现对某个时刻视频数据的采集影响因子进行量化,根据量化值确定该时刻的视频数据是否进行持久化存储,同时也考虑到后续视频内容分析系统对视频的图像、音频、文本模态数据的分析需求,因此,在解析服务器内按固定时间间隔将视频数据解析为多帧的图像、音频、文本模态数据,其中文本模态数据指的是视频本身所包含的字幕信息,每帧视频多模态数据对应某个时刻的视频数据;另外,将缓存服务内的热度影响因子数据即采集影响因子与多帧的图像、音频和文本模态数据依据时间关联性建立关联矩阵L:
(1)
其中,Li={fi,si,ti,hi}为矩阵中的第i元素,表示i时刻视频的多模态数据,其中,fi表示i时刻的图像模态数据,si表示i时刻的音频模态数据,ti表示i时刻的文本模态数据,具体指i时刻视频中的字幕信息,hi表示i时刻的热度因子数据,其中hi包含“关注”、“在看”、“分享”、“点赞”及“弹幕”5种视频热度影响因子.
3)量化视频热度.使用“熵权法”计算5种影响因子对视频热度的影响权重,通过公式(8)对视频热度进行量化,得到视频热度值集合W={w1,w2,…,wn},其中wi对应时刻的视频热度量化值,将热度值集合W作为输入参数传递至调度进程.
4)自适应数据采集.基于采集影响因子即热度值集合W内数据的变化趋势确定是否持久化存储某个时刻对应的视频多模态数据.根据第4节的多分段旋转门数据采集策略,基于已采集的视频数据热度值构建预测模型,通过判断当前采集时刻视频热度值wt与预测模型之间的误差来计算下一次的数据采集间隔时间Tnext,并将Tnext传给部署在调度服务器上的调度进程,调度进程根据最新的Tnext持久化存储当前采集时刻的图像、音频、文本模态数据到服务器集群.
3.1 热度因子
视频热度本质是指视频所引起的网民关注和讨论的热量程度,直播平台中用户通过“点赞”、“转发”、“发弹幕”等行为参与互动,直播视频每个时刻的“点赞数”、“转发量”、“弹幕数”等数据也实时体现了该视频的热度.本文参考“BiliBili”网站(1)https://www.bilibili.com/内直播视频热度排行影响因子,选择“关注”、“正在看”、“分享”、“点赞”、“弹幕数”5个影响视频热度的因子.热度因子矩阵表示为:
(2)
其中,hi={ui,li,si,zi,di}为集合中的第i元素,表示i时刻的5个视频热度影响因子.ui为视频i时刻的“关注数”因子,即主播的粉丝数,体现主播本身的热度;li为视频i时刻的“在看数”,是i时刻正在观看视频的用户数;si为视频i时刻的“分享数”,是i时刻视频被转发的计数;zi为视频i时刻的“点赞数”,是i时刻视频被点赞的计数;di为视频i时刻的“弹幕数”,是i时刻视频中的弹幕条数.
3.2 热度因子权重计算
不同热度因子对视频热度的影响具有差异性,本文采用“熵权法”对不同热度影响因子进行衡量并赋予权重.熵是信息论中的概念,可用于度量数据所提供的有效信息量[16-19].用熵值来确定权重时,若评价对象在某项影响因子的值差别较大时,表明该影响因子较重要,所提供的有效信息较多,该影响因子的权重也应较大;反之,若评价对象在某项影响因子的值差别较小时,则表明影响因子不重要,所提供的有效信息较少,该影响因子的权重也应较小.使用“熵权法”求解5个影响因子的权重过程如下:
1)本文中有“分享数”、“点赞数”等5个影响因子,设有n个评价视频,t时刻得到的原始数据矩阵为:
(3)
其中,x1j是t时刻第j个评价视频的“关注数”;x2j是t时刻第j个评价视频的“在看数”;x3j是t时刻第j个评价视频的“弹幕数”;x4j是t时刻第j个评价视频的“分享数”;x5j是t时刻第j个评价视频的“点赞数”.
2)为消除量纲差异引起的数据不公平问题,需要对原始矩阵进行标准化处理,即将不同量纲进行变换,形成无量纲差异的标准化矩阵[18].
(4)
其中,min{xij}为第i个影响因子在n个评价视频中的最小值;max{xij}为第i个影响因子在n个评价视频中的最大值;rij为第j个评价视频在第i个影响因子上的标准值.
对原始矩阵X标准化后得到矩阵R:
(5)
3)为了客观衡量不同因子对视频热度的影响程度,采用熵定义求出每个影响因子的信息熵值H1~H5[19].
(6)
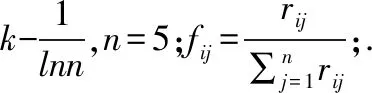
4)基于熵权定义求出每个影响因子的信息熵所占权重[19]:
(7)
本文通过5个热度因子计算j时刻的视频热度值公式为:
Wj=Q1uj+Q2lj+Q3sj+Q4zj+Q5dj
(8)
本文采集的样本数据是“BiliBili”网站2021年4月8日19:00直播热度排行榜的前1-10条、30-32、50-54、70-71、96-100的直播视频记录,提取出的热度因子数据如表1所示.
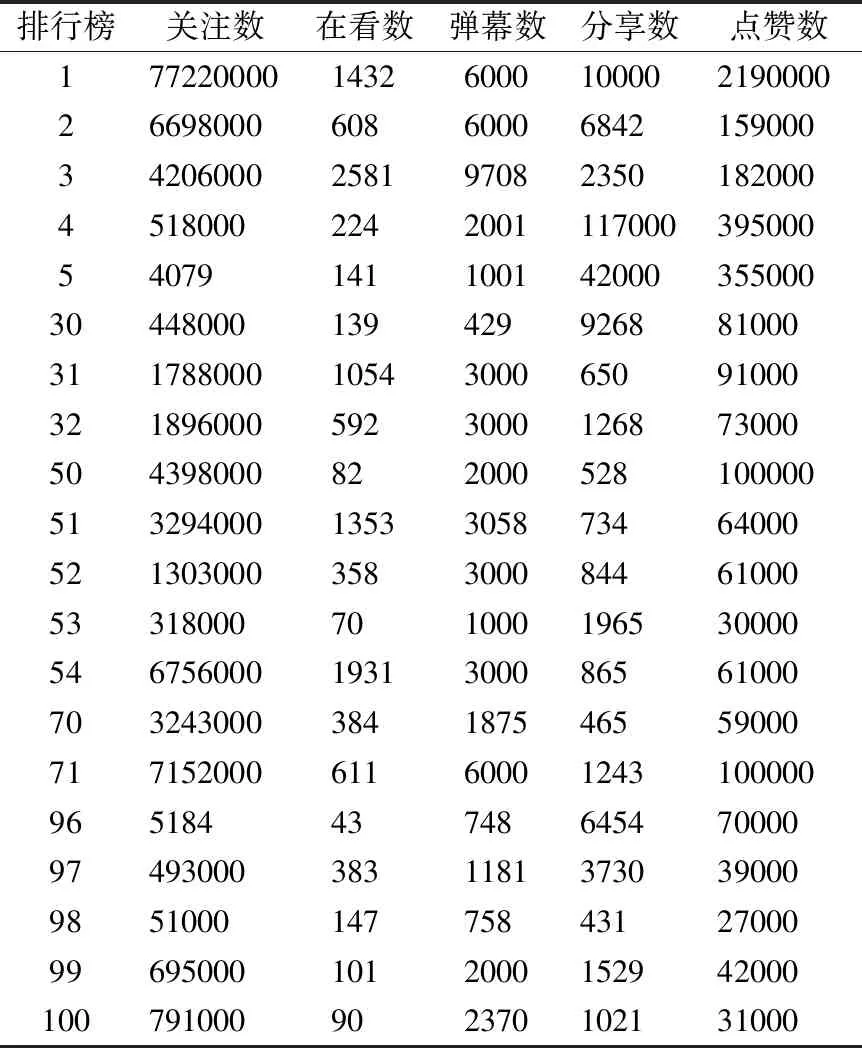
表1 “BiliBili”网站直播视频热度因子数据Table 1 BiliBili website live video heat factor data
使用“熵权法”,计算得到“关注数”、“在看数”、“弹幕数”、“分享数”、“点赞数”5个影响影子的熵值H1~H5分别为0.514、0.792、0.872、0.48、0.548.熵权值Q1~Q5分别为0.271、0.116、0.071、0.29、0.252.从结果可以看出视频的“分享数”权重最高,到达29%,其次为“关注数”和“点赞数”,权重分别为27.1%、25.2%.直播视频的“在看数”和“弹幕数”权重最低,分别为11.6%和7.1%.将算得的Q1~Q5的值代入公式(8)即可得到j时刻的视频热度值.
4 多分段旋转门数据采集策略
针对现有采集策略存在关键信息遗漏与采集量过大等问题,本文提出了多分段旋转门数据采集策略(Multi-segment Swing Door Trending,MSDT).策略的核心思想是根据数据波动变化情况,动态调整数据采集的间间隔.当数据变化趋于平缓,增大数据采集的时间间隔,降低采样系统开销;反之,数据变化波动剧烈时,缩短数据采集的时间间隔,提高数据采集质量[20,21].
4.1 分段类型的确定
在实际采集中,最初视频中播放的是常规场景时,视频热度在较低的一定范围内平缓波动;当视频中出现非常规事件,热度会出现急剧上升,并且在热度值较高的一定范围内平缓波动,随着事件的结束,视频热度会急剧下降,最终回退到热度值较低的一定范围内平缓波动.
根据热度数据变化情况,文本将热度数据变化阶段分为陡峭分段和平缓分段.陡峭分段分为上行陡峭分段和下行陡峭分段,其中,上行陡峭分段表示热度急剧上升阶段,下行陡峭分段表示热度急剧下降阶段.平缓分段分为低区平缓分段和高区平缓分段,其中,低区平缓分段表示热度值在较低范围内平缓波动,高区平缓分段表示热度值在较高范围内平缓波动.
本文设计了基于斜率比较的方法来确定分段类型,采集过程中缓存当前数据点的前两个数据点,判断以这3个数据点为端点的两条线段的斜率和,若绝对值大于90度,则进入到为陡峭分段;否则为平缓分段,如果分段的初始数据点热度值大于整体热度值的均值,则为高区平缓分段,否则为低区平缓分段.假设dcur为采集的当前数据点,dpre_1为dcur之前的第1个数据点,dpre_2为dcur之前的第2个数据点,分段函数为:
(9)
其中,K=K1+K2,K1是以dcur和dpre_1为端点的线段斜率,K2是以dpre_1和dpre_2为端点的线段斜率,C表示以dcur开始为陡峭分段,Gu表示以dcur开始为高区平缓分段,Gl表示以dcur开始为低区平缓分段.hagv为视频整体热度均值.
4.2 不同分段下旋转门处理策略
对于低区平缓分段内的数据,热度较低,在一定容差范围内只需采集关键信息;而对于高区平缓分段内的数据,热度较高,信息量大,在一定容差范围内采集关键信息的同时要增加数据采集量.对于陡峭分段,意味着视频热度急剧上升或下降,需要根据数据的变化趋势自适应调整数据采集时间间隔.根据不同分段下的数据特点,本文提出了不同分段下的采集处理方法,包括平缓分段和陡峭分段.
4.2.1 平缓分段处理
平缓分段内数据变化整体平缓,但包含较多的小幅度数据波动.当进行等间隔数据采集时,会遗漏关键信息.为了提高采集精准度,本文基于旋转门思想设计了平缓分段处理策略,旋转门思想主要是通过上下门的斜率比较,动态调整容差范围,在一个容差范围通过起点和终点代替一系列连续的数据点[22].
设定两个容差范围α、ε,其中α>ε,数据测量时间间隔为T.采集每个旋转门处理周期的初始数据点,代替在一个容差范围内的一系列连续的数据点.在高区平缓分段,由于热度较高,使用较小的容差范围ε来保证采集数据精准度;在低区平缓分段,热度较低,使用较大的容差范围α降低数据冗余,规则如下:
1)确定旋转门处理周期的容差范围.测量初始数据点,设定初始数据点为d1,若d1测量值大于等于全部数据热度均值,说明当前数据位为高区平缓分段,则设定容差范围β=ε;若d1测量值小于全部数据热度均值,说明当前数据位为低区平缓分段,则设定容差范围β=α.
2)开始旋转门处理周期.存储初始数据点d1,以初始数据点d1为基准点向上增加β生成旋转上门的上支点,旋转上门的斜率Kup=-∞;以初始数据点d1为基准点向下减少β生成旋转下门的下支点,旋转下门的斜率Kdown=∞,在处理过程中,Kup只能增大,Kdown只能减小.
3)更新旋转门的上下门斜率.根据时间间隔T测量当前数据点d.如果d为空,则退出;否则,根据当前数据点d更新旋转门的上下门斜率Kup、Kdown:
Kup=max(K1,Kup)
(10)
其中,K1为当前数据点d与旋转门上支点之间连线的斜率.
Kdown=min(K2,Kdown)
(11)
其中,K2为当前数据点d与旋转门下支点之间连线的斜率.
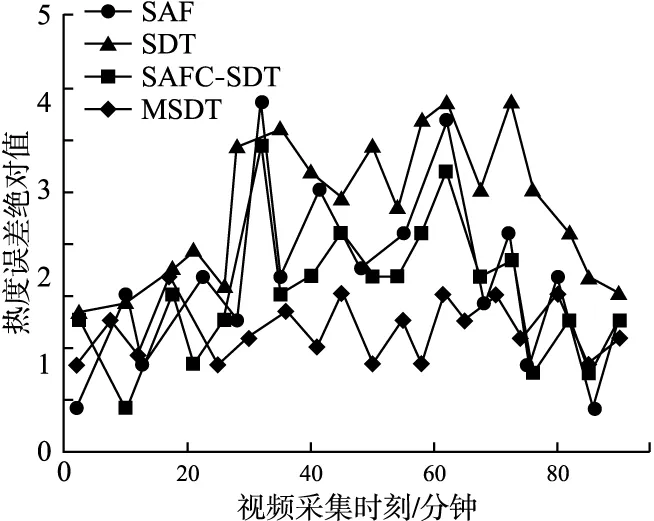
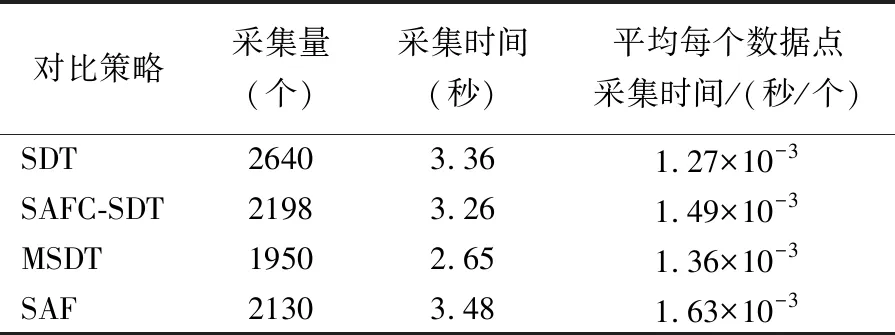
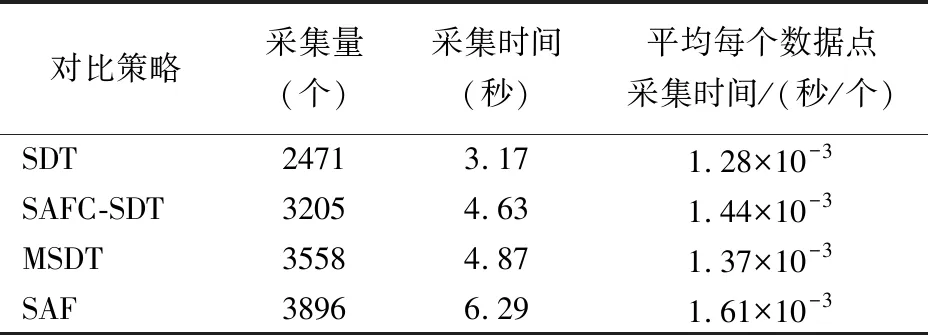
4)判断旋转门处理周期是否结束.比较旋转门的上下门斜率Kup、Kdown,若Kup 4.2.2 陡峭分段处理 陡峭分段分为上行陡峭和下行陡峭,出现在事件的生、发展阶段.在上行、下行分段中,随着事件的进行,会出现大量急剧的数据变化情况.若使用平缓分段处理方法,在一个旋转门周期只存储初始数据点,会出现采集数据量过少,不能很好涵盖数据原始信息等问题.针对上述问题,本文在平缓分段处理的基础上,设计了陡峭分段处理策略. 设容差范围为β,数据采集时间间隔为T.根据时间间隔T,对数据进行存储,根据数据的测量值自适应调整T:若测量值在当前旋转门容差范围β内,说明数据变化趋于平缓,则减少数据采集量,根据当前旋转门容差内的数据个数成倍增大采集时间间隔T,直到T最大.若测量值超出当前旋转门容差范围β,说明数据发生波动,则增加数据采集量,减小T至原来的二分之一.规则如下: 1)开始旋转门处理周期.存储初始数据点d1,以初始数据点d1为基准点向上增加β生成旋转上门的上支点,旋转上门的斜率Kup=-∞;以初始数据点为基准点向下减少β生成旋转下门的下支点,旋转下门的斜率Kdown=∞,在处理过程中,Kup只能增大,Kdown只能减小.设定当前旋转门处理步长p=0. 2)更新旋转门的上下门斜率.根据时间间隔T采集存储当前数据点d.判断若d为空,则退出;否则,根据当前数据点d更新旋转门的上下门斜率Kup、Kdown,更新见公式(10)、公式(11). 3)判断旋转门处理周期是否结束,动态调整数据采集时间间隔T.比较旋转门的上下门斜率Kup、Kdown: 若Kup T=max(T+p×ΔT,Tmax) (12) 其中,T为采集间隔时间,Tmax为最大采集间隔时间,ΔT为极小值,p为当前周期处理步长,表示当前周期内的数据个数.转至2),继续当前旋转门处理周期. 若Kup≥Kdown,说明数据点d超出当前处理周期初始数据点d1的上下β容差范围,说明数据变化波动较大,则减小采集时间间隔T: (13) 其中,Tmin为最小采集间隔时间,则转至1),以数据点d为初始数据点开始一个新的旋转门处理周期. 4.2.3 极大值区间处理 在实际的陡峭分段数据采集中,一个旋转门处理周期结束后的数据采集间隔时间T会达到一个极大值,此时,若以下一个数据为新旋转门处理周期的起始点,将遗漏极大值间隔时间内的数据,降低数据采集质量.为解决上述问题,提出极大值区间数据处理方法. 本文设定极大值为Δtm,极大值区间内统一的数据采集间隔时间α,将间隔时间Δtm划分为i个数据采集时刻,分别为c1,c2,…,ci,i=(Δtm/α)-1,i个数据采集时刻的数据测量值分别是dc_1,dc_2,…,dc_i,其中有n个数据测量值超出前一旋转门处理周期的容错范围,分别是do_1,do_2,…,do_n,n≤i,数据分析过程概述如下: 1)当n=0时,i个数据测量值均处在前一旋转门处理周期的容差范围,此时Δtm内的数据与前一旋转门处理周期所采数据的信息量相似度接近,无需采集. 2)当n=1时,i-1个数据测量值均在前一旋转门处理周期的容差范围,此时这些数据与前一旋转门处理周期所采数据的信息量相似度接近,无需采集;仅单独采集超出容错范围的数据do_1. 3)当n=2时,i-2个数据测量值均处在前一旋转门处理周期的容差范围,此时这些数据与前一旋转门处理周期所采数据的信息量相似,无需采集;此时以do_1为起始点,开始一个新的数据采集周期. 4)当n>2时,i-n个数据测量值均处在前一旋转门处理周期的容差范围,这些数据与前一旋转门处理周期所采数据的信息量相似度接近,无需采集;针对n个超出前一旋转门处理周期容错范围的数据测量值进行处理,如图2所示. 图2 极大值区间内有两个以上数据点偏离Fig.2 Over two deviation points in a maximum range 对于do_1,do_2,…,do_n,前两个数据点do_1、do_2形成一个新的旋转门处理周期D1,而后依次判断余下数据点do_3,…,doj,…,do_n是否在旋转门处理周期D1的容错范围内,若do_3,…,doj,…,do_n均在,则无需采集,否则寻找第1个不在旋转门处理周期D1容错范围的数据值do_j,而后在do_j+1,…,do_p,…,do_n中寻找第1个不在D1容错范围的数据值do_p,若寻找失败,则表明当前剩余数据均在D1容错范围内,仅需单独采集do_j;否则,存在第2个不在D1容错范围内的数据do_p,此时由数据点do_j与do_p形成一个新的旋转门处理周期D2.判断余下的数据测量值do_p+1…do_n是否处于D1或D2的容错范围内,若均在,则余下数据不予采集,否则按照生成旋转门处理周期D1、D2的思想,以此类推判断do_p+1…do_n中是否存在两个超出容错范围的数据点,若存在则形成新的旋转门处理周期Dl,否则单独采集数据点do_p+1. MSDT算法输入为视频多模态数据的热度值集合W,在第4行根据以当前数据点及前两个数据点为端点的两条线段的斜率和,判断分段类型调用不同分段处理代码,第6-12行为平缓分段处理伪代码,第14-35行为陡峭分段处理伪代码,其中第21-33行为极大值区间处理伪代码,算法最终输出为采集后的热度数据集. 算法1.MSDT算法 输入:原始热度数据集W 输出:采集后的热度数据集P 1.初始化t,T,βmin,βmax,k; 2.while(t+T 3.save(P,W[t]); 4.jump_d_kind(t,W); 5.genSeg: 6. if high(seg_kind)β=βminelseβ=βmax; 7. d0=getData(W[t]); 8. while(isInDoor(W,d0,k,β,t,T))do 9. update(k,t); 10. end while 11. save(P,W[t]); 12. startNewDoor(W,t,β,T); 13.steSeg: 14. d0=getData(W[t]); 15. if isInDoor(,d0,k,β,t,T)then 16. p=p+1; 17. t=t+T; 18. T=max(T+p×△T,Tmax); 19. save(P,d_pre1,d_pre2,W[t]); 20. else 21. CreateMaxData(MD,W,(T/α-1),t); 22. GetOverDate(OD,MD,j*,d_pre1,β); 23. switch(length(OD)) 24. case 0:exit; 25. case 1:save(P,OD[1]);exit; 26. case 2:save(P,OD[1],OD[2]);exit; 27. default:startNew(OD,t,β,T); 28. for(j=1;j<=length(OD);j++) 29. if !isInDoor(OD,d0,k,β,t,T) 30. save(P,OD[t]); 31. end if 32. end for 33. end switch 34. T=min(1/2T,Tmin); 35. startNew(W,t+T,β,T); 36. end if 37.t=t+T; 38.end while 为了测试MSDT方法的有效性和可行性,将MSDT方法与SAF、SDT及SAFC-SDT方法进行了4方面的对比实验分析:1)采集质量对比,依据实验结果,绘制实验数据的真实曲线以及算法所确定的数据采集点,可以直观看出采集点在数据曲线的位置,旨在探究本文所提的MSDT算法是否能够实现在陡峭以及高位平缓分段中能够增加数据采集点,在低位平缓分段减少数据采集点;2)不同算法在不同分段内的采集量对比,确定MSDT算法数据采集量的变化比例;3)不同算法的采集误差对比分析,采集误差定义为采集数据与其对应采集周期内数据的均方差,通过该实验对比结果,可以验证MSDT在不同阶段的数据采集精确度控制方面是否具有优势;4)通过对比不同算法的平均每个采集数据点所占时间来验证MSDT的执行效率. 定义采集质量为采集的数据点是否能够反映热度值曲线变化情况.图3-图5为SDT、SAFC-SDT及本文的MSDT策略的采集数据质量示意图,实验数据为(10-50)时段直播视频的热度值数据. 图3 SDT采集质量Fig.3 SDT acquisition quality 图4 SAFC-SDT采集质量Fig.4 SAFC-SDT acquisition quality 图5 MSDT采集质量Fig.5 MSDT acquisition quality 通过结果可以看出,相较于其他两种算法,MSDT算法在(10-25)时段内的采集数量最少,在(25-35)和(35-50)时段的采集数量最多,是由于MSDT算法针对不同分段对应不同采集方法,对于低区平缓分段,只采集关键信息涵盖该时段内被采集对象的原始信息;对于容易出现在事件的发生、发展中的上行陡峭分段和出现在事件高潮的高区平缓分段,增加采集数据量涵盖该时段内被采集对象的原始信息.由于SDT、SAFC-SDT算法未考虑分段情况,因此在(25-35)及(35-50)时段采集量没有明显增加. 使用10组直播视频数据热度作为采集对象,每组视频热度数据的时间长度为90分钟,设计爬虫每隔1秒进行一次爬取,每组视频对应5400个热度值.不同采集策略在4个时间段:(0-25)、(25-45)、(45-65)、(65-90)内的平均采集量如表2所示. 表2 数据采集量Table 2 Amount of data collection 由于本例中的视频热度数据,在开始约30分钟后,嘉宾出现在直播间,在开始约60分钟后,嘉宾离开,所以(0-25)和(65-90)时段主要为低区平缓分段,(25-65)时段为陡峭分段和高区平缓分段.MSDT策略在低区平缓分段通过较大阈值减少采集量,所以在(5-25)和(65-85)时段采集量最少;在(25-45)和(45-65)时段MSDT采集量比SAFC-SDT稍多,是由于MSDT考虑了极大值区间数据采集,但从所有时段的采集量累加看,MSDT采集量最少,比SAFC-SDT减少约26%,比标准SDT减少约11%. 采集数据时,在降低采集量的同时应尽可能提高采集数据的精确度.本文采用均方根误差作为数据采集误差的衡量指标,对SAF方法、SAFC-SDT方法及本文提出的MSDT方法进行误差分析.从图6可以看出,在(30-35)、(60-65)时间段内,SAF方法、SAFC-SDT均达到较大误差,原因在于,这两个时段的数据发生跃迁,由于SAF策略是基于一元线性回归预测模型进行数据采集时间间隔调整,线性方程的斜率是基于前期采集的若干个数据确定的,在一定时间内不能根据后期的数据点进行动态调整,导致在数据波动不稳定时误差较大.而SAFC-SDT策略遗漏了两个旋转门处理周期转换之间数据采集情况,导致在数据变化陡峭上行或下行阶段误差加大,本研究所提出的MSDT策略,由于考虑了数据不同变化阶段的采集情况,在数据出现跃迁情况下,对误差的控制最为稳定,同时比SAF降低28%左右,比SAFC-SDT降低24%左右. 图6 误差分析Fig.6 Error analysis 本文将采集效率定义为平均每个数据点所占用的采集时间,本小节分别针对完整分段数据和陡峭高区平缓分段数据集测试不同采集策略下的采集效率. 表3实验数据为30组直播数据热度在(0-90)时间分段内的热度值,为完整分段热度数据,包含低区平缓、上行陡峭、高区平缓及下行陡峭分段.在采集量方面,MSDT方法采集量最低,是由于MSDT方法在低区平缓分段内采用高容差极大降低了采集量;在采集效率方面,MSDT比SAF提高17%,比SAFC-SDC提高9%,由于MSDT在SDT基础上设计了分段判断以及周期动态调整机制,增加了处理时间,因此MSDT采集效率比SDT方法降低7%. 表3 完整分段采集效率Table 3 Overall acquisition efficiency 表4实验数据为30组直播数据热度在(25-85)时间分段内的热度值,包含上行陡峭、高区平缓及下行陡峭分段.在采集量方面,MSDT所采数据量低于SAF但高于SDT及SAFC-SDT,是由于针对上下行陡峭分段及高区平缓分段数据,MSDT在一个SDT容错周期内设定了采集周期,增加采集量,并且在SAFC-SDT基础上考虑了极大值区间的采集数据;在采集效率方面,MSDT比SAF提高15%,比SAFC-SDC提高5%,比SDT降低7%. 表4 陡峭及高区平缓分段采集效率Table 4 Steep and gentle in high area acquisition efficiency 本文针对视频数据采集存在数据冗余、占用资源过多、遗漏关键信息等问题,设计了基于热度因子的视频多模态数据采集模型,实现当视频热度迅速上升、下降及高热度持续阶段加大采集量;反之,在视频热度较低持续阶段,降低采集量的效果.使用“关注数”、“分享数”等热度因子对视频热度进行量化并提出一种基于多分段旋转门的数据采集策略,根据视频热度数据的变化趋势,设计了不同的分段采集策略,根据视频热度之间的时间相关性,基于旋转门思想根据数据变化趋势构建容错区域,根据区域中数据的变化趋势自适应调整下一个数据采集时间间隔,在降低数据采集量的同时又考虑了不同旋转门周期之间的极大值区间的数据采集情况.为验证本文所提策略的有效性,从采集质量、采集数量、误差分析及采集效率4个方面进行对比分析.实验结果表明,MSDT降低了数据采集量和误差,提升了数据采集质量和效率.本文所提策略采集视频数据时仅考虑了热度影响因素,并且采集模型内使用了先缓存、解析、再采集的模式,面向直播视频数据的实时采集存在一定延迟.在未来研究工作中,一方面对视频违规信息的其他影响因素进行更深入研究,进一步提高采集质量;另一方面是将基于热度因子的视频多模态数据自适应采集策略与先进的视频违规信息判定算法相结合,实现视频数据的有效采集判定,提高视频内容监管系统的整体性能.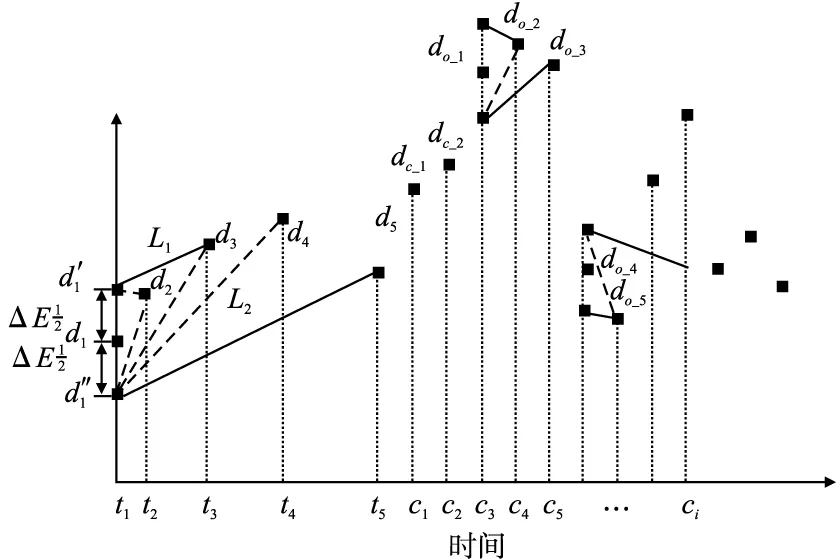
4.3 MSDT算法
5 实验及性能分析
5.1 采集质量
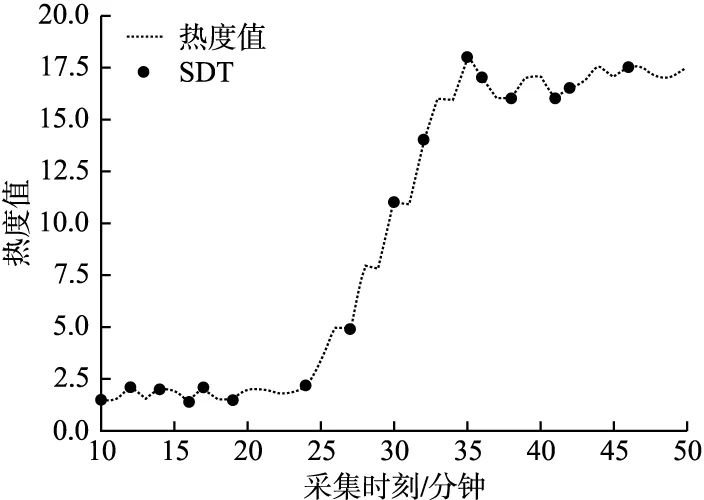
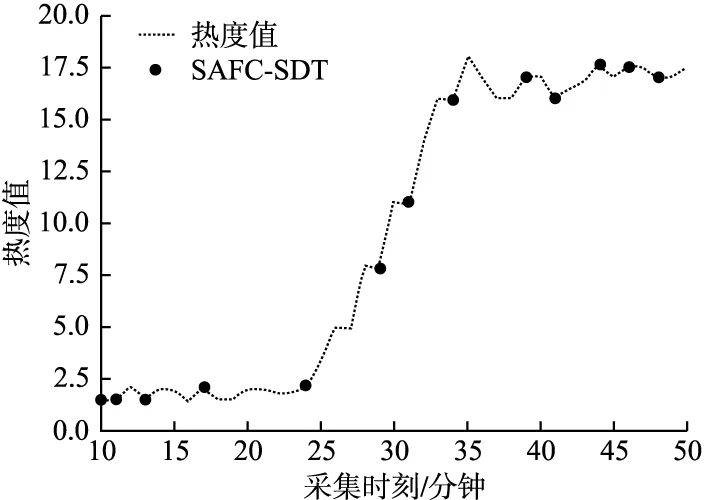
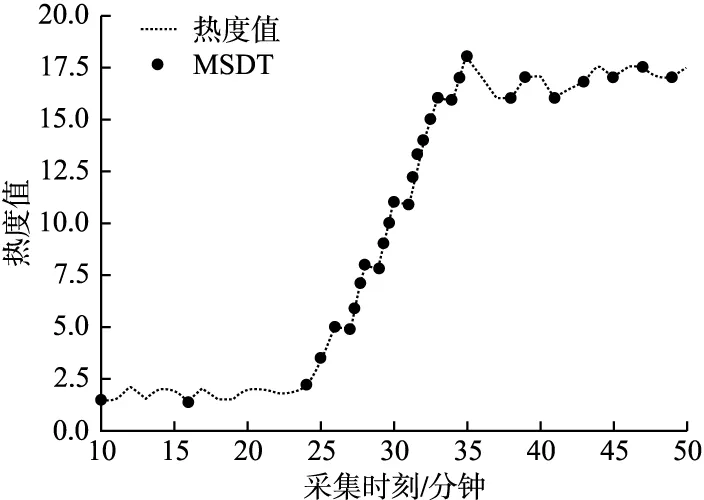
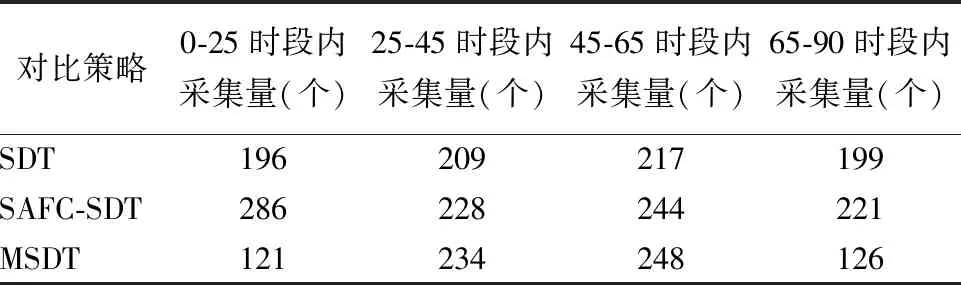
5.2 采集数量
5.3 采集误差
5.4 采集效率
6 结 论
