融合时空特征的视觉自动驾驶强化学习算法
2023-02-17雷为民
杨 蕾,雷为民,张 伟
1(东北大学 计算机科学与工程学院,沈阳 110819)2(阿里巴巴集团 达摩院自动驾驶实验室,杭州 310000)
1 引 言
自动驾驶任务尤其是在复杂的城市环境中是一个充满挑战性的问题.其挑战主要来自2个方面:原始的传感器数据维度高,提取有效合理的特征完成对环境信息的表示是关键;另一个方面自动驾驶训练数据往往是车辆正常行驶的视频而极少包含非正常行驶的视频,样本分布不均衡,使得算法带有偏差,泛化性差.
在自动驾驶环境特征提取方面,使用图像作为输入的自动驾算法[1-5]驶取得了突破性的进展.这些研究都是把图片作为输入,经过深度神经网络抽取特征.但是,图像只是对环境的一个空间表示I
在自动驾驶算法方面,常用的算法分为仿生学习(Imitation Learning)算法和深度强化学习(Deep Reinforce Learning)算法.仿生学习从某种角度上可以看做是一种监督学习,其目标是通过深度神经网络去拟合专家的行为.然而,采集的自动驾驶数据往往包含大量的正样本和极少的负样本,造成样本的不均衡.仿生学习的算法容易受到数据分布偏差的影响,当碰到没有见过的场景时,算法往往会采取错误的操作,而错误的操作又会进一步导致没有遇到的场景.近几年,在自动驾驶中常用的另一类算法是深度强化学习算法.深度强化学习算法是在不断试错过程中学习的一类算法.在深度强化学习框架中,代理(Agent)通过与环境的交互,获取对应奖励(Reward),其最终目标是学习策略π使得最终的累积奖励最高.由于奖励只是间接影响算法的决策,所以深度强化学习算法不会受到数据样本比例不平衡的影响.因此,STRLAD算法采用强化学习算法,设计合理的奖励函数,最终产出行为策略.
STRLAD算法的整体框架如图1所示和算法1所示,以视频作为输入,通过双流网络提取特征并融合,然后输入到强化学习算法Soft Actor-Critic(SAC)进行学习.STRLAD算法的贡献如下:1)提出双流网络,完成对环境的时空特征提取;2)使用双流网络的特征,进行强化学习算法尝试;3)通过实验证明其有效性,在CARLA[2]测试中,STRLAD算法能够在复杂拥堵的城市环境中完成自动驾驶任务,成功率达到89%.
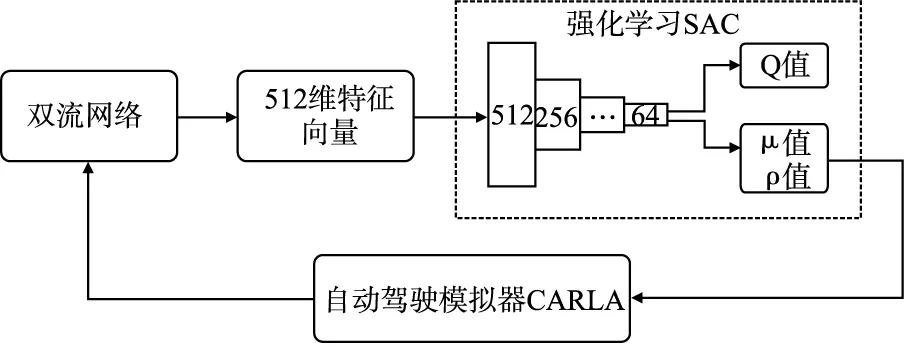
图1 STRLAD算法整体流程图Fig.1 Overall flowchart
2 相关工作
2.1 时空特征
在图像领域,CNN一直占据着主导地位,从早期的AlextNet[10]、VGG[11]、ResNet[12]到ConvNeXt[13]已成为图像特征提取的基础网络.然而,视频本身包含图像和时间两个维度的信息.近几年,随着深度基础网络的发展,视频时空特征挖掘方面有了很大的发展.在2D网络结构中包含:Deep-Video[14]、TwoStreamNet[15]和TSN[16]及其扩展;在3D网络结构中包含:C3D[17]、I3D[18]及其扩展;在视频注意力算法(Transformer)领域包含:TimesTransformer[19]和ViT[20]等.STRLAD的双流网络受到TwoStreamNet和SlowFastNetwork的启发,与两者相比网络结构和输入均不同,双流网络输入包含RGB图片和连续灰度图,主干网络(Backbone)采用改进的ResNet34网络结构.
在视频的时间维度特征研究中,光流表示图像帧之间像素的变化.经典的Lucas光流算法[21]被集成到OpenCV库中得到广泛的应用.然而,光流的大幅度变化(比如建筑物的光照变化)与车辆的控制并没有太大的关系.因此STRLAD算法的双流网络注重学习与自动驾驶有关的特征,与直接使用光流特征不同.
注意力机制[22]能够强化与任务相关的特征权重,前期在NLP领域取得成功,近几年注意力机制在图像和视频领域也取得了很大的发展,从早期的SqueezeNet[23],Non-Local[24]到Transformer网络.STRLAD算法的双流网络网络通过注意力机制融合运动和感知两个特征,为自动驾驶提供更好的特征表示.
2.2 强化学习和深度强化学习
强化学习的发展最早可以追溯到1953年,应用数学家 Richard Bellman提出动态规划数学理论和方法,其中的贝尔曼条件(Bellman condition)是强化学习的核心基石之一.1988年,TD算法[25]诞生,1989年Watkins提出Q学习[26],1994年Rummery提出Saras算法[27].后续强化学习慢慢发展起来,但是由于一直无法解决感知(Perception)问题,导致其无法很好求解复杂环境下的决策问题,使得强化学习这一具备决策能力的算法,并没有被引起广泛的关注.但在2012前后,随着深度学习技术的出现(以Krizhevsky 等人为代表的AlexNet),促使计算机视觉,自然语言处理,语音识别等领域出现爆炸式的技术进步,深度学习也由此成为人工智能领域最热门的关注点之一.强化学习也得益于深度学习的快速发展,迎来新的突破,通过结合深度学习方法,很好地解决了一直困扰强化学习的感知问题.通过将强化学习的决策能力结合深度学习的感知能力,从而实现从感知到决策的端对端学习(End-to-End Learning).现在强化学习主要指的也就是深度强化学习(Deep Reinforcement Learning,简称DRL).
强化学习算法根据环境模型是否已知分为Model-Free算法和Model-Base算法.Model-Free具有通用性,具体又可以分为基于策略梯度优化(Policy)的算法,A2C/A3C[28]、PPO[29]和TPRO[30];基于价值估计的算法(Q-Learning)的算法DQN[31]、C51[32]、QR-DQN[33]和HER[34]等.基于Policy的算法是对策略进行直接学习,算法相对稳定.基于Q-Learning的算法评估状态价值(满足Bellman等式)间接用于优化动作的选取,所以稳定性相对较差,但是Q-Learning算法可以对数据进行重用,数据利用率高.基于Policy算法和Q-Learning算法并不是互斥的,可以通过Q-Learning算法评估动作的好坏,再通过梯度优化策略使得策略价值最大,常见的算法:DDPG[35]、TD3[36]和SAC[37]等.SAC引入熵的概念,平衡策略探索和利用已学策略,因此,STRLAD算法模型中选择SAC算法作为强化学习的主体框架.
Model-Base的算法是已知环境模型的算法,算法从某种角度上是一个动态规划问题或者逐步优化的问题,常见算法包括:蒙脱卡洛树算法(MCTS)等,不是本文讨论的重点.
2.3 仿生学习
仿生学习(Imitation learning,简称IL)是一种仿生学方法,该方法把传感器的原始输入直接映射到最终的动作,是一种端对端的学习方式.早期自动驾驶网络[38]和避障网络[39]使用摄像头作为输入,使用神经网络相关动作进行预测.CIL[40]使用高层转向指令消除自动驾驶车辆在路口的歧义性,开启了导航的一个新的阶段.多任务预测导航算法[4]通过增加预测图像深度和图像分隔任务,使得模型有更好的泛化能力.CILRS[41]增加对速度的预测,同时探索自动驾驶的一些限制.LBC[42]是一种知识蒸馏的方法,提出"老师"和"学生"双网络结构,通过"老师"网络优化"学生"网络,取得很好的效果.尝试多模态的融合[43]研究,证明早期的融合有助于特性的学习.与STRLAD双流网络类似的多模算法[44]融合图像和雷达两种模态,模态之间使用注意力机制,而双流网络关注视频时空特征的挖掘,模态和网络主干都与之不同.
2.4 自动驾驶中的深度强化学习
CIRL[5]使用录制的视频和车辆操作记录进行仿生学习,首先通过仿生学习训练特征提取网络,然后使用训练好的网络提取特征,再使用DDPG算法进行强化学习,是最早在CARLA环境下使用强化学习的算法.MDRL[45]把图像的输入映射为鸟瞰图(Bird′s Eye View),通过神经网络对鸟瞰图进行编码,然后分别尝试DDQN、TD3和SAC算法,其中SAC算法效果最好.IAs[46]使用ResNet18进行特征提取,然后使用Rainbow-IQN框架进行强化学习.GRIAD[47]提供一个通用的端对端的视觉自动驾驶框架,分为感知编码模块和强化学习模块,其中感知模块进行图像分隔和分类模型的训练,然后冻结感知模块权重作为编码层,编码的特征与专家特征进行混合后使用Rainbow-IQN进行训练.这些研究都是通过特征网络进行图像空间信息特征的提取和压缩,然后进行深度强化学习.STRLAD算法整体框架与之类似,双流网络重点挖掘时空结合的特征,然后冻结双流网络参数进行特征提取,最后使用SAC算法进行强化学习.
3 STRLAD算法模型
3.1 问题设定
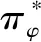
(1)
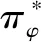
(2)
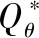
STRSAD算法整体框架分为2个步骤,首先训练双流网络用于特征提取,其次通过SAC强化学习进行策略学习,具体如算法1所示.
算法1.STRLAD模型算法
输入:训练数据集D
输出:策略网络π*(s,a)∈A
//训练双流网络提取特征,见3.2节
Datad←
FunctionFitForward(Datad)→F(o,θd)
Minimize Equation(3)
ReturnFθd
End
//强化学习算法训练,见3.3节
Repeat
D←Store(s,a,r,s′,d)//d表示任务是否结束
Forbatch∈Ddo
Compute Q Equation(10)
Update Policy Equation(12)
End for
Until Convergence
3.2 双流网络
双流网络是一个端对端的深度网络,如图2所示两个网络分支:感知网络和运动网络通道数量之比与感知细胞与运动细胞之比(8∶1 的通道数量)相同,并使用注意力进行特征融合,完成对周围环境的特征表示,是算法的核心和创新点.
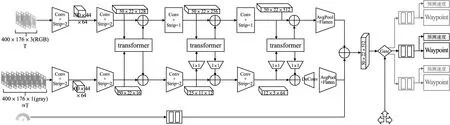
图2 双流网络结构图Fig.2 Dual stream network structure
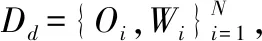
(3)
其中F是以θd为参数的卷积神经网络,Wi表示航点,L表示损失函数.
任务的每一幕(Episode)都有一个目的地Dg={Ci,…,Cm},Ci表示车辆在路口的具体转向方向,消除路口的歧义性,在CIL[40]以及后续研究中也证明其重要性,网络输入表示为:Oi={I,C,V}i,I表示图像输入,V表示车辆速度,C表示路口转向指令.
双流网络从车辆的前置摄像头获取视频输入.感知网络以T的采样率获取RGB图片作为输入,标记为Irgb←T.运动网络以αT采样率获取灰度图作为输入,标记为Igrey,两者比例为Irgb=αIgrey,经过实验验证α=8,T=3结果最优—即感知网络每秒采集3张彩色图片,运动网络每秒采集3×8张灰度图.车辆的速度采用基于车辆仪表盘显示的速度并做归一化,0表示静止,1表示最大速度.双流网络最终输出预测的航点.
双流网采用RestNet34作为主干网络并做重要改进,具体结构如表1所示.

表1 双流网络详细结构图Table 1 Detailed structure of the dual stream network
感知网络从阶段3开始残差模块中的步长均为1,保持分辨率不变,输出特征向量Po.运动网络考虑物体运动的整体性,通道数缩小8倍,分辨率降为原图片的1/32,输出特性向量Mo.
注意力机制[22]完成网络特征融合.假设两个特征:F1∈Rn×d,F2∈Rm×d,其中n,m,d代表不同的维度F1与F2做注意力学习的前提是两者向量维度d相同.Q是F1对应的向量,K,V是F2的对应的特性向量,两者注意力如等式(4)所示:
(4)
最后,双流网络整合两个分支网络特征
双流网络采用L1损失函数回归速度和航点.V和V*表示真实的航点和预测的航点,损失函数表示等式(5)为:
(5)
3.3 强化学习算法
STRLAD算法采用SAC算法作为强化学习的主体.SAC算法是增加熵的离线随机策略强化学习算法.SAC算法最主要的特性就是使用正则化熵,使得训练的策略能够平衡累计奖励和熵,防止模型局部最优.熵表示的是变量的随机性,熵增大使得模型增加对新动作的探索能力,反之则减少.
SAC算法的目标是找到累计价值最大的策略等式(6)如下:
(6)
π*表示学习的最优策略,τ表示在策略π的一幕(episode)中所有步骤,γ表示奖励折扣系数,R表示奖励函数,α是熵系数也成为温度值,H表示在状态s下策略π选择的动作的熵.
SAC算法的价值函数Q如等式(7)所示:
Qπ(s,a)≈r(s,a,s′)+γ(Qπ(s′,a′)-αlogπ(a′|s′))
(7)
其中s′表示下一个状态,a′表示下一个动作.价值网络的训练使用的损失函数如等式(8)所示:
L(φi,D)=E(s,a,r,s',d)~D[(Qφi(s′,a′)-y(r,s′,d))2]
(8)
其中:
(9)
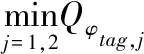
有了价值函数Q,策略的学习就是最大化价值与熵之和,等式(10)如下:
Vπ(s)=Ea~π[Qπ(s,a)-αlogπ(a|s)]
(10)
其中的动作a使用高斯策略如等式(11)所示:
aθ(s,ξ)=tan(μθ(s)+σθ(s)·ξ),ξ~N(0,I)
(11)
最终的策略计算如等式(12)为:
(12)
STRLAD算法的SAC算法模型包含1个策略网络和2个价值网络,其输入都是在双流网络的主干网络上增加512到64的稠密层.价值网络Q的输出是一个标量,策略网络输出动作的均值和方差.
奖励函数的计算使用CARLA环境的航点信息.通过CARLA的API能够获得当前环境中所有车道的连续路径点位置和方向,这些信息提供车辆和周围环境的准确描述.奖励函数包含:车辆的速度rv、车辆的位置rp和车头的角度ra,如等式(13)所示:
R(s,a)=rv+rp+ra
(13)
车辆的速度rv是车辆当前速度与期望速度的差值,取值范围为[0-1],当车辆在红灯或者即将与其他车辆发生碰撞,车辆的期望速度会调整为0,对应的惩罚值也会改变,训练时采用的速度为30km/h.车辆的位置rp的计算依赖车辆当前的位置与车道中心位置的差值,取值范围为[-2,2],2表示与期望的航点位置无偏差,-2表示车辆与车道中心航点的偏差超过2m.车头的角度ra是车头朝向与车辆正确角度(车道中心位置的航点)的偏差值的计算,取值范围为[-1,0],0表示无偏差,-1代表最大偏差,如果没有车头角度的奖励,车辆不能正常行走,经常冲出车道.在训练阶段,使用Adam优化器,学习速率为3×10-4.
4 实 验
本章介绍实验的建立,结果的对比和相关消融实验.
4.1 实验设置
STRLAD算法的训练和验证在CARLA0.9.12中的8个城市中完成,其中城市[1-4,6-8]中的地图中包含的场景相对单一有助于算法的训练,城市5是一个包含十字路口、桥梁和多个车道相对复杂的方格城镇地图,适合算法性能测试.每个城市产生随机的100个行人和70个车辆.每个任务由开始和结束坐标(GPS)组成,车辆在规定时间内无碰撞的到达目的地表示任务成功,否则表示失败,如果违反红绿灯规则但是并没有造成碰撞也表示成功.车辆在行驶过程中,参照CILRS[41]增加转向噪音,增强数据的泛化行.采集的数据包含车辆正面的摄像头RGB视频数据(20HZ),传感器数据包括:速度、导航指令、航点、车辆位置、车头角度、油门、刹车和加速度等.考虑到实验的目标是检测车辆在复杂多物体的环境中自动驾驶的性能,去除了天气条件的影响,只使用Clear Noon天气.模型的评估在城市5中进行,总共设置10个子任务,每个任务包含任务的起始点和转向指令,行驶长度1000-2000m并在预定位置随机产生100个行人和70辆车.评估的指标包含任务完成率RC、碰撞率Col和超时率(Time Out,简称TO).
算法的对比只选择以图像作为输入,除LBC[42]以外都采用强化学习算法.LBC是一种仿生学习算法是目前NoCrash数据集的最好算法,最新版本中增加图像热力图改进其性能,在STRLAD训练数据集上进行了复现.MDRL[45]把图像转化为鸟瞰视图,通过深度神经网络进行图像编码,然后进行强化学习.IAs[46]使用手动设置的指标和图像分割进行特征提取,然后通过Rainbow-IQN-Apex进行训练,是一种离散离线强化学习算法.GRIAD[47]是目前官网能够获取到源码的最好方法(排名第三,前两个无法获取源码),是一种混合仿生学习和强化学习的方法.为比较GRIAD也使用1个摄像头作为输入,其他保持不变.STRLAD_cilrsw使用CILRS-W替换双流网络进行特征提取,其它保持不变.CILRS-W是对CILRS[41]的改进,使用其主干网络进行航点的预测,可以看做是只使用双流网络的感知网络分支.STRLAD_griad是借鉴GRIAD训练模型,在训练的过程中增加仿生学习的训练方式.
为相对公平比较,所有模型都使用与双流网络训练相同的数据集和训练时长,对比的强化学习算法都训练到收敛为止.各个算法与STRSAD的对比方法分为训练部分对比和最终测试对比两部分.LBC算法的训练是一个监督学习的过程,与强化学习的训练不具备可比性,因此LBC算法只进行最终测试对比,见表2所示.MDRL、IAs、STRLAD_cilrsw、GRIAD和STRLAD_griad在训练阶段都使用STRLAD的采集的数据集集进行训练,其对比结果如图3所示,最终测试对比都在城市5中进行,其结果如表2所示.
4.2 结果对比与分析
STRLAD算法与各个算法的训练对比结果如图3所示.图3(a)STRLAD算法最终取得与GRIAD算法相当的效果虽然收敛速度慢,其原因GRIAD充分利用仿生学习和强化学习的优点,提高数据利用率.借鉴GRIAD训练方法STRLAD_griad如图3(e)所示达到同样的收敛速度和准确率.图3(b)MDRL算法效果相对于STRLAD效果差,其原因是鸟瞰视图会造成小物体的模糊,无法准确表征周围的环境信息.图3(c)IAs算法效果比STRLAD差,其原因是手动设计的自动驾驶特征不能充分表示拥堵环境中的多个物体.图3(d)STRLAD_cilrsw算法效果比STRLAD差,其原因是双流网络提供时空特征表示比单纯的空间特征更丰富.
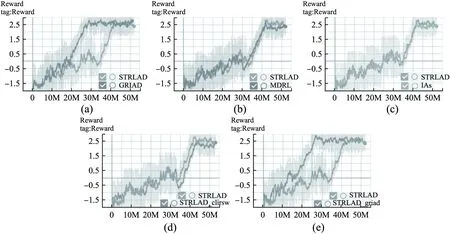
图3 算法训练对比结果图Fig.3 Comparison results of algorithm training
STRLAD算法与各个算法在测试集进行测试,结果如表2所示.
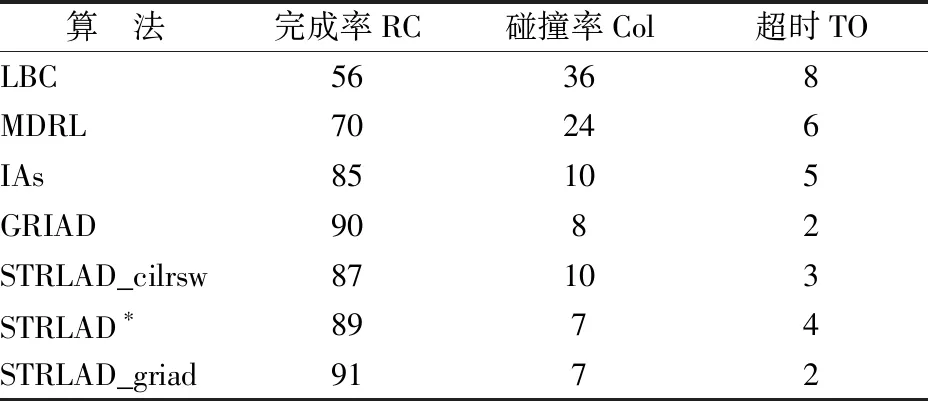
表2 算法模型测试结果对比Table 2 Algorithm model test results comparison
通过对比,1)STRLAD算法完成率高,与GRIAD相比 STRLAD_griad完成率达到最高为91%.LBC无法对动态物体的有效检测,在测试任务上泛化性低,准确率低.MDRL使用鸟瞰图像编码进行特征表示,在大量的动态物体时表现不佳.IAs通过手动设计的指标和图像分隔进行特征提取,模型性能有较大改善,但是在人车密集的长距离任务中对于面对突然出现的行人和车辆表现较差.GRIAD使用专家数据作为最高奖励同时进行在线学习,完成率达到90%,是一个强大的模型.STRLAD_cilrsw算法由于采用CILRS-W进行特征提取,损失时间维度造成完成率下降;2)双流网络提取的特征好.通过STRLAD_cilrsw与STRLAD对比,双流网络使得完成率获得2%的提升;3)STRLAD算法碰撞率最低,达到7%,其原因是使用的强化学习是对车辆动作的连续空间预测,操作更加平滑精准;4)STRLAD算法的超时情况相对较高,与奖励函数的设置有关,需要进一步改进.
4.3 消融实验
STRLAD算法的双流网络是本文的创新点,因此针对双流网络设计消融实验,强化学习算法保持不变.
注意力机制是否有效?如表3所示,STRLAD_cilrsw只使用感知网络代替双流网络.STRLAD(w/o A)算法去掉注意力机制,2个分支网络特征简单相加.通过实验,STRDAD算法与STRLAD(w/o A)和STRLAD(CILRS-W)相比分别获得1%和2%的提升,证明双流网络的有效性.
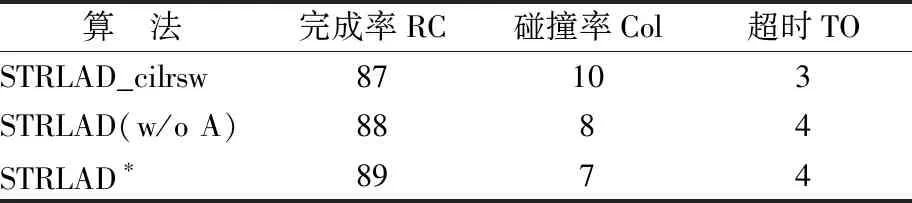
表3 注意力消融实验算法模型结果Table 3 Results of attentional ablation experiments
为进一步证明注意力机制的有效性,图4可视化了注意力权重,双流网络对移动行人、汽车和信号灯都有较高权重,为复杂环境的移动物体检测提供帮助.

图4 可视化注意力机制Fig.4 Visual attention
双流网络采样率之比α取值是否合理?双流网络的感知网络和运动网络的采样率之比决定注意力机制的有效性,消融实验结果如表4所示:α取值太小运动网络无法完成运动特征学习,算法模型退化为STRLAD_cilrsw;α值太大则无法完成与感知网络的对齐,也会造成整体算法性能下降.

表4 双流网络输入采用率之比α实验结果Table 4 Experimental results of the ratio of input adoption rate α for dual-stream networks
4.4 实时性
在自动驾驶中实时性非常关键.在RTX3090 GPU的机器上STRSAD算法的平均耗时是通过平均完成一幕(episode)的所有视频帧的平均值获取,单帧耗时为35.3毫秒.相对于算法IAs(23.7毫秒)和GRIAD(21毫秒)较慢,其原因是双流网络使用更大的主干网络和注意力机制计算有关,需要进一步优化.
4.5 限制性
STRLAD算法的局限性是双流网络的耗时较多,需要进一步优化.算法模型的最终效果好,但收敛速度较慢,需要提高数据利用率和缩短训练时长.
5 结 论
自动驾驶任务中环境的特征表示是算法成功的关键,受视觉中空间和时间特征的不对称性启发,STRLAD算法的双流网络:感知网络和运动网络尝试学习视频的时空特征.感知网络使用改进的ResNet34为主干,保持图像高分辨率不变,完成对环境精细化理解;运动网络为提高实时性,把ResNet34主干的通道缩减为原通道1/8,完成运动特征的学习.STRLAD算法为克服数据样本带来的偏差,采用强化学习SAC算法进行尝试.通过实验证明STRLAD算法模型的有效性,尤其是复杂环境下对移动物体的检测,其完成率达到89%.
在自动驾驶领域,多传感器的多模态的融合(比如Lidar与视觉的融合)是研究热点.未来,STRLAD算法会尝试多模态融合的特征提取,结合最新强化学习算法进行相关研究.
