基于Spark的变压器局部放电模式识别并行化实现
2023-02-17朱永利
李 涛 朱永利
(华北电力大学控制与计算机工程学院 河北 保定 071003)
0 引 言
智能电网的飞速发展导致电力设备在线监测数据量正在呈现指数形式的增长。传统的数据处理方式不能够达到当今智能电网从海量数据中快速收集和分析数据的要求,这种情况会对电力设备在线监测系统的功能方面上提出了更加严格的要求。因此,在Spark平台实现对局部放电类型快速高效的识别并进行诊断对电力设施的安全性和稳定性有着重大的意义。
目前神经网络[1]、支持向量机[2-3]、聚类算法[4]等多种方法运用到放电信号的分类中,但以上所提出的算法都有着各自的一些问题。其中,人工神经网络具有收敛速度慢、过拟合、网络结构难以确定等问题[5]。支持向量机(Support Vector Machine,SVM)算法在处理多分类问题时较为复杂[6],对大数据进行处理的过程中会造成大量的计算负荷。聚类方法在样本较大时存在分类效果差[7]。而以上的方法都没有考虑到原始信号中所提取的特征向量间存在关联。针对上述问题,Raghuraj等[8]提出了基于变量预测模型的模式识别方法。变量预测模型模式识别方法利用训练数据间的关联创建数学模型,然后对测试数据进行测试并且利用最小特征参数预测误差值实现样本间的分类。这种方法优势在于可以对非线性多分类问题进行处理并且防止了神经网络和SVM中结构和参数选择问题。
当前MapReduce分布式编程模型已经普遍应用于电力行业中的大数据处理。但Hadoop在HDFS上重复进行读写操作造成较高的磁盘I/O负荷和时间消耗不能满足数据处理的实时性要求。Spark[9-10]和MapReduce相比具有高效易用、支持DAG和Java、Scala、Python、R四种语言和分布式内存计算等优点,消除了MapReduce在计算时因重复读写磁盘带来的消耗。例如文献[11]将基于Spark的机器学习模型应用于大数据流以进行健康状况预测,围绕Apache Spark引擎构建了可扩展的实时健康状况预测系统,并且将该引擎在云上进行了测试和部署,并在其中将模型运用到了流数据。如文献[12]将Hadoop、Spark和Flink平台的性能进行了对比,Spark与其他两个平台综合比较下性能最佳。在大规模集群下,Spark计算框架在WordCount和K-Means算法中获得了最佳的结果。如文献[13]为网上学习平台开发了分布式课程推荐系统,它旨在使用关联规则方法发现学生活动之间的关系,以帮助学生选择最合适的学习材料。研究结果表明Spark的内存内计算是最快且可扩展的解决方案,提出的系统可以被应用并容易地融入其他学习平台中。
综上所述,本文采取将并行化VPMCD算法应用到Spark平台上构造变量预测模型(VPM),将此模型应用到了局部放电信号的模式识别并且完成了对放电类型的快速分类的实现。
1 基于VPMCD的模式识别方法
1.1 变量预测模型
本文采取特征向量X=[X1,X2,…,Xp]定义某种类别的局部放电信号,特征向量包括p个不同的特征值以及其他特征对Xi影响值(Xj;j≠i)。这些局部放电信号的特征量可能是一对一的关联:X1=f(X2)或一对多的关联:X1=f(X2,X2,…)。对VPMi模型进行数学训练,以反映不同故障之间的相互关联,并用于预测测试样本属于哪个故障类别。
本文采用线性(L)、线性交互(LI)、二次(Q)和二次交互(QI)等模型形式的四种多项式模型类型:
(1)
(2)
(3)
(4)
式中:r(r≤p-1)是模型阶数。
以p个特征值分类问题为例,变量预测模型可以利用预测变量Xj(j≠i)预测变量Xi,其定义如下:
Xi=f(Xj,b0,bj,bjj,bjk)+e
(5)
1.2 VPMCD训练
(1) 通常,假设训练样本具有g个不同的类,每个类拥有nk(k=1,2,…,g)个训练数据。总集合为N[n×p;g],其中p为特征向量维数。读取训练集N。

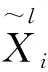
(4) 令k=k+1并重复步骤(3)直到k=g,然后停止。
1.3 VPMCD测试
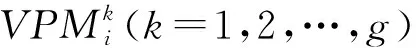
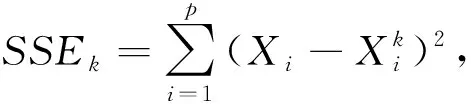
1.4 VPMCD算法流程
VPMCD模型训练和测试的算法流程如图1所示。

图1 VPMCD算法流程
2 并行VPMCD
2.1 局部放电样本特征量的采集
本文所用的数据是对以上四种放电模型所产生的局部放电信号进行特征提取收集到的数据。所收集原始信号的频率为40 MHz,带宽为40~300 kHz,选择50个工频周期的信号作为一个统计样本。4类放电模型如图2所示。

(a) 电晕放电 (b) 针板放电

(c) 板对板放电 (d) 悬浮放电图2 四种局部放电模型
采取局部放电相位分析(PRPD)方法对以上四种放电类型放电信号的φ-q-n图谱的PRPD特征进行提取并构造特征向量。每类放电收集到400个样本,总共收集到1 600个样本,选择样本中的1 000个样本为训练样本,而剩余的600个样本成为测试样本。对各放电类型的φ-q-n图谱分别提取11维特征分别作为特征向量输入到VPMCD中实现分类识别,提取的特征如表1所示。基于PRPD的特征提取的具体内容如文献[14-15]所述。

表1 PD信号的统计特征
2.2 数据处理流程
Spark平台存在三种可行的并行化编程方法,分别是数据并行、任务并行、数据并行和任务并行结合等三种方案。数据量的持续增长会导致单机环境下训练数据时效率降低。VPMCD在训练不同数据的实验过程中数据相互独立,而且数据的处理的次序对结果无影响。因此,本论文采取将数据部署到多个节点进行数据的并行处理,可以减少训练时间,大幅度提高处理数据的效率。
本文采取稀疏矩阵存储方式对数据进行存储,使用此方式的优势在于计算速度快,并且能够节省数据的储存空间,读取数据较为方便。
数据处理步骤如下:
(1) 所采集的特征向量数据导入HDFS(Hadoop Distributed File System)中并将数据读入文件并创造RDD数据切片。
(2) 为获取实验所需的训练集和测试集,首先通过collect()函数得到各种故障类的数据数量,其次使用map()和split()函数将数据进行划分。
(3) 采用cartesian()和filter()函数对数据矩阵进行计算进而获取每个样本特征值的参数模型。
(4) 通过reduce()等相关函数计算最小预测误差并且计算后获取故障类型的最佳预测模型。
(5) 最后将最优化VPM模型参数保存到HDFS文件系统中。
数据流程如图3所示。
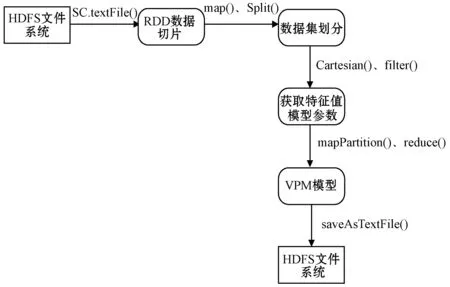
图3 数据流程
2.3 性能优化
本文所涉及的广播(Broadcast)变量属于Spark计算框架中共享变量中的一种,而广播变量的优势在于将只读副本分给各个Executor而不是给所有的Task分发新副本,在很大程度上减少了变量所产生的副本和Executor的内存开销。在进行并行计算过程中,随着数据量和节点数的增多,各个节点间的数据交换和移动将会导致通信开销的增长。
本文采取SparkContext.broadcast()来使用广播变量对节点间数据进行优化,计算过程中在每个节点上存有只读变量,Spark计算框架对广播变量的优化节约了内存空间,对数据的处理效率和全局的处理速率进行了提升。广播变量所定义的函数原型为:
def broadcast[T:ClassTag](value:T):Broadcast[T]
2.4 基于并行VPMCD的变压器局部放电模式识别
本文为了有效地提高对放电类型的快速识别能力,提出在Spark计算框架下局部放电信号模式识别的并行化方法。算法流程如图4所示。
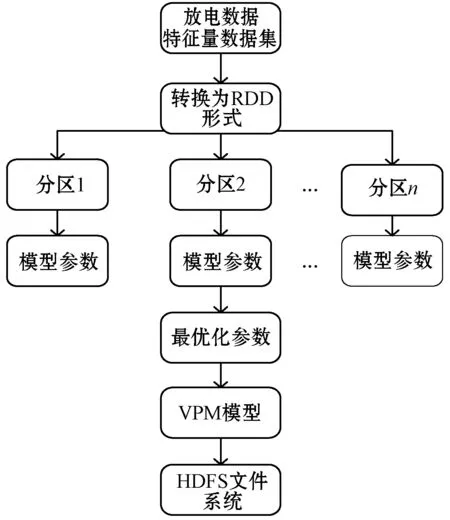
图4 算法流程
算法流程如下:
1) 配置Spark环境,Spark计算框架在内存中完成计算减少了对HDFS重复读写。
2) 将采集到的数据存入到HDFS系统当中,构造训练集和测试集。
3) 从HDFS中将数据载入内存,转换为RDD形式。
4) 采取变量预测模型模式识别中的四种数学模型对带标签的训练数据进行训练,得到参数,进而形成诊断分类模型。
5) 将训练好的模型对测试集分类进而确定放电类型。
3 实验结果及分析
3.1 环境搭建
本文在实验室搭建的Spark集群共设置6个节点,1个主节点(MasterNode)节点和5个从节点(SalveNode),由千兆交换机构成一个内部网络。主节点配置CPU为i3- 2120 3.30 GHz,内存3 GB,硬盘250 GB。从节点CPU为E5- 2609 v2 2.50 GHz,内存7 GB,硬盘300 GB。平台采取YARN Cluster模式进行部署。各个节点的操作系统为CentOS- 7,Hadoop的版本为Hadoop2.9.2,Spark的版本是Spark2.3.0。
3.2 单机环境下放电类型的正确识别率
实验在单机情况下采取在MATLAB平台上分别使用BP神经网络、SVM和VPMCD对随机选取的测试样本进行测试,以此进行算法正确识别率的对比。本实验在联想电脑上进行操作,相关配置:CPU为i5-8250U,内存为8 GB,64位Windows 10操作系统,编程环境为MATLAB R2018a。对样本集中各类放电类型随机选择150个为训练样本,对所有测试集进行测试后分类的结果如表2所示。

表2 PD信号识别的准确率(%)
可以看出,VPMCD算法与BP神经网络和SVM相比较下具有更高的准确率、实验证明变量预测模型模式识别算法有较高的正确识别率、更好的识别效果。
3.3 VPMCD并行验证
(1) 集群环境和单机环境训练时间的对比。集群环境下的实验需要对样本数据进行随机复制操作。因电力设备故障样本属于小样本,样本数量有限,通过对已采集的数据进行大规模动态随机复制,将数据量从几百条增至百万条。本实验在集群环境和单机环境下的训练时间的对比如图5所示。
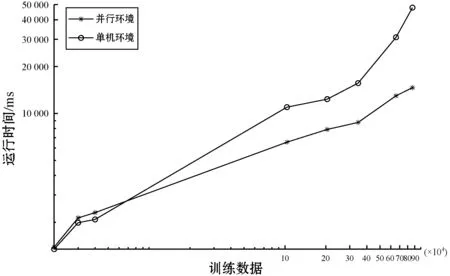
图5 集群和单机环境下运行时间的对比
可以看出,实验所用的数据规模相对少的环境下,单机环境下的处理速度较快于集群处理速度,这是因为Spark在分块和任务调度方面耗费了一些时间,所以导致并行处理效率略低于串行处理。但是随着数据规模从十万条逐步扩大到数十万条,集群环境下的执行时间要明显低于单机环境下的执行时间,由此可看出并行处理具有较为显著的优势。
(2) 加速比与节点间的关系。Spark计算框架能够对大量数据进行快速处理,而且Spark的处理能力与数据量和集群的节点数相关联。加速比[16]不仅能对Spark系统的性能和成效进行分析,还可以将并行环境和串行环境下的运行速度进行定量的对比分析。
本实验的训练数据分别采用50 MB、512 MB、1 024 MB的加速比进行比较。所得结果如图6所示,数据规模较小时,加速比随着节点数的增多反而降低,进而证明本并行VPMCD适合大规模数据处理。数据量较大时,相同的数据规模下加速比随着节点数的增多而提升,节点数相同时,加速比随着数据量的扩充而提高,表现出Spark平台对大规模数据处理的优良性能。

图6 不同数据下加速比和节点数的关系
4 结 语
传统的局部放电模式识别方法难以处理海量的监测数据,难以满足智能电网的需求,本文将Spark计算框架运用到变压器海量数据监测上,对放电信号提取其φ-q-n图谱的PRPD特征构成相关特征向量作为实验样本,并行实现VPMCD算法完成了放电类型的分类。对实验结论进行详细的分析,可以表明变量预测模型模式识别方法的识别精度高于SVM和BP神经网络模型,数据规模较大时,Spark并行处理数据速度远快于传统的串行处理方法。
