基于关键字的RDF聚合查询研究
2023-02-17马晓芳杨卫东
马晓芳 杨卫东
(复旦大学计算机科学与技术系 上海 201203)
0 引 言
随着语义网、知识图谱等技术的快速发展,结构化语义数据的应用越来越广泛,这些数据通常使用资源描述框架(RDF)来表示。互联网上出现了大量RDF形式的数据,如Dbpeida[1]、Yago[2]、Freebase[3]等。利用这些数据可以实现在用户搜索时由一般文档检索转换为知识检索,提高返回结果与用户搜索意图的相关度,避免无关信息的展示。对于RDF数据中信息的检索,可以通过W3C组织推荐的标准查询语言SPARQL来实现。但是SPARQL语法非常复杂,且使用URI表示的数据资源可读性较差,要准确书写SPARQL语句还需要用户对原始数据图的模式信息有一定的先验知识,这使得一般用户从RDF数据中获取所需信息是非常困难的,所以对于RDF数据的关键字查询或者自然语言问句查询的研究得到了越来越广泛的关注,旨在方便普通用户获取RDF数据信息,实现语义检索。相比于自然语言问句,RDF的关键字查询更加接近于用户的日常检索习惯也更简洁易用,并且可以包含更多更广泛的查询信息。但是,由于关键字输入中缺少语句中必要的依赖信息,使得对于用户查询意图的理解相较于自然语言更加困难。
对于RDF数据基于关键字的信息检索研究,主要可以分为两大类[12]。一类是将关键字匹配到原始数据图上的元素后,通过在整个数据图上做检索,获得覆盖全部匹配元素的最小子结构,从而直接得到查询结果[7,10-11];第二类则是先将关键字查询转换为意图匹配的结构化查询语句,之后再通过现有的查询引擎执行语句来获得最终的结果[6,8-9]。文献[11]通过划分子图对数据图进行索引,有效降低了搜索空间。文献[8]通过在扩展模式图上进行检索确定查询结构,文献[6]的查询模式与文献[8]类似,并且在结果排序时考虑了给定查询中每个关键字对于其他关键字解释的影响。
直接查询和查询转换两类方法都可以实现对于一般关键字查询的支持,但是直接查询方法只能返回图中存在的元素作为查询结果;查询转换方法也只能得到只包含查询模式的查询语句,无法充分利用SPARQL所支持的丰富查询操作。上述相关研究的重点在于对图进行索引,以降低搜索空间,加快检索效率,而忽略了对于统计信息的查询。例如,对于查询Q1={num, student, university0}表示“查询university0中的学生数”,Q2={Article, max, volume}表示“查询卷数最多的文章”,num/max所指示的查询意图无法被正确解析。同时,对于Q2中的关键字“max”可能指示MAX或TOP1类型的聚合操作,也可能匹配到名为“Max Robert”的人,对应查询意图为“学者max所发表文章的卷数”,由于关键字是否匹配聚合查询的不确定性,使得查询意图的确定更加困难。
统计查询是常用的,但在当前RDF关键字查询研究中无法支持对其意图的正确解析。在关系数据库上已有算法对支持聚合关键字的查询进行了研究[4-5]。SQAK[4]通过限制num、max等特殊词语一定匹配聚合操作,并使用保留关键字WITH确定查询解释,最终转换为SQL的子集rSQL。PowerQ[5]则需要用户交互信息进行支持,得到注释图模式并转换为SQL查询。同时,RDF数据上的自然语言问句查询也有研究对聚合查询进行处理,文献[13]通过句子中的依存关系,确定用户查询意图。TBSL[14]则通过问句的语义表征,确定所对应的SPARQL模板,再将命名实体等加入插槽中。
由于数据结构的不同以及语句依存关系的缺失,RDF上的聚合关键字查询无法直接利用上述方法实现。此外,已有聚合关键词的研究忽视了聚合操作关键字可能匹配到一般字面量的情况,而是将聚合关键字作为特殊的保留词[4-5],这会限制查询的表达能力,错过可能的查询解释。为了使用户可以利用简单的关键字进行查询,本文不对输入内容做限制,不强制用户输入指定的聚合关键字。对于可能指示聚合意图的关键字,我们会在匹配阶段计算其为聚合关键字的概率,从而确定可能的查询解释,再通过在模式图上根据查询解释中的元素进行扩展,得到查询意图。
相比于关系数据,RDF数据还需要考虑聚合查询对于查询结构图连接方式的影响,例如对于查询Q3= {AssistantProfessor, interest, sames as, fullprofessor1},其对应的查询结构图如图1所示,操作符“=”连接了两个不同的节点,转换后的SPARQL查询语句如图2所示,通过filter子句对查询意图进行了准确的描述。
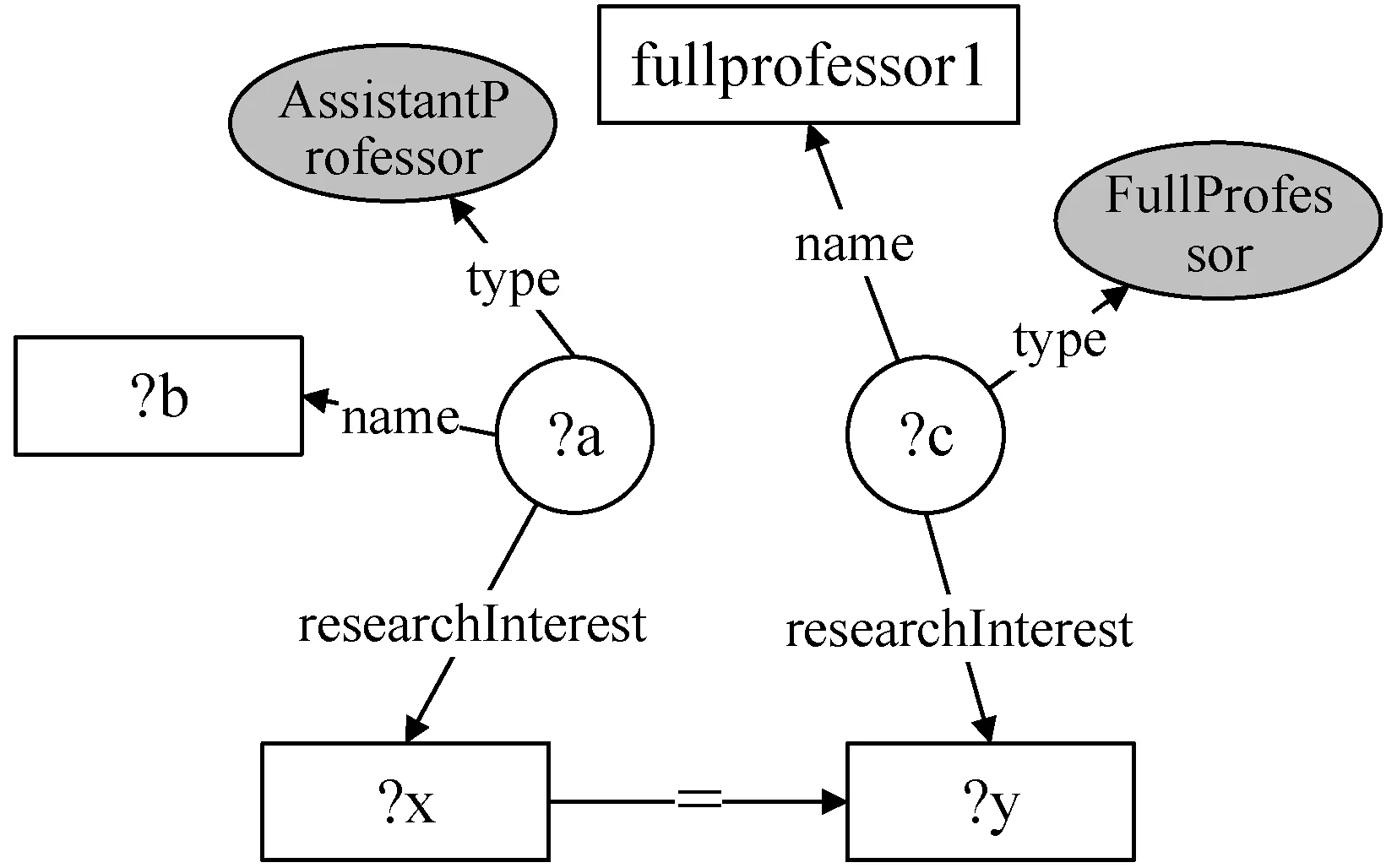
图1 查询Q1对应的查询结构图

图2 Q3对应的SPARQL查询
通过上述分析本文提出了包含聚合信息的关键字查询转换算法,将查询统计信息的关键字转换为带聚合函数的SPARQL语句,实现对于MAX、AVG、MIN、COUNT、SUM及GROUP BY等操作的支持。本文主要贡献如下:(1) 定义带有聚合信息及查询结构图的查询意图,给出具体的描述及含义;(2) 对聚合操作进行分类,并构造关键字与其匹配的字典,在关键字映射阶段,同时获得关键字元素及聚合信息;(3) 提出查询意图对应分数的计算方法,结合查询结构图与聚合信息,获得查询意图的匹配分数;(4) 针对所提出的查询意图,设计模式图上的查询算法及SPARQL语句生成算法。
1 概述和定义
1.1 RDF数据
RDF数据的基本组成单元为三元组
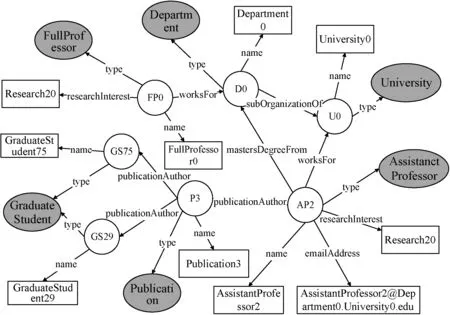
图3 RDF数据图示例
1.2 相关定义
为了支持将关键字查询转换为带有聚合函数的标准查询语句,实现查询语义的扩充,本文提出了特定的查询意图概念,并对相关定义描述如下。
定义1查询意图。关键字查询可能对应的查询意图定义为I=(G,A),其中:G为查询结构图,用于描述查询内容之间的语义关系;A则为聚合信息,当查询不含聚合意图时,A为null。查询图与聚合信息的具体定义分别在定义2和定义3中给出。
定义2查询图。查询结构图G=(V,E)是模式图的一幅子图,或者是由比较操作符连接的多个子图,对于查询中的每一个关键字,查询图中都包含与之对应的关键元素。
定义3聚合信息。聚合信息的形式为A=(operation,ST,AT),其中operation为查询所属聚合操作类型,ST为检索对象,AT为聚合对象,限定ST与AT为查询图G所包含的元素,或为null。
定义4查询解释。在关键字匹配阶段获得查询解释,根据查询解释进行图检索可以得到查询意图。查询解释定义为E=(c,A),其中c为一组关键元素,A则为对应的聚合信息。
1.3 问题描述与算法结构
包含聚合信息的关键字查询转换算法是将RDF数据上关键字查询转换为SPARQL查询语句的研究,旨在理解用户输入关键字的查询意图,并支持转换为复杂的聚合操作。对于给定的RDF数据图G=(E,V,L),我们定义用户输入的关键字查询为一组关键字的集合,即Q={k1,k2,…,kn}。每一个关键字ki,可能为指示聚合意图的关键字或为一般关键字,对于一般关键字则获得RDF图中与其匹配的元素集合Mi。确定查询解释后,在模式图上根据所包含的关键元素进行扩展,并考虑聚合操作对于图连接性的影响,获得查询结构图,再结合聚合信息得到对应的查询意图。根据所提出的意图分数计算方法,选择前k查询意图,将其转换为对应的SPARQL查询语句。
所以,本文算法将关键字转换为SPARQL查询的主要步骤为:(1) 检索关键字索引,与聚合操作词典,获得查询解释;(2) 提取RDF模式图,并根据查询解释在图上进行检索得到排序的候选查询意图;(3) 将查询意图一对一地转换为SPARQL查询语句。算法具体结构如图4所示,输入为数据图与关键字查询,输出则为符合查询意图的SPARQL语句。

图4 RDF关键字查询结构图
2 关键字查询解释
2.1 关键字映射
为了根据关键字获得可能匹配的图元素,我们设计了特定的图元素存储结构,并构建关键字-图元素的映射表。我们认为用户查询时会通过name、title等属性所对应的值来描述实体,所以我们考虑关键字匹配到属性值节点,类别节点和关系标签三种情况,即∀m∈Mi,m∈VL∪VC∪L。对于图中的每一个元素,我们将其存储在定义的数据结构(class,property,value)中,其中,class为元素对应的类别信息,property为边标签,value则为属性值。为了实现关键字的快速匹配,并且支持关键字与元素信息部分匹配的情况,我们构建了关键字的倒排索引。
2.2 聚合操作与聚合信息
根据定义3可知,聚合信息的结构为A=(operation,ST,AT),ST所对应变量出现在SELECT子句中,并可能被MAX、MIN等操作限制,同时也可能出现在group by子句中。当AT不为空时,所对应对象出现在order by、having或filter操作中。operation则为所属的操作类型,聚合操作的分类及描述如表1所示。
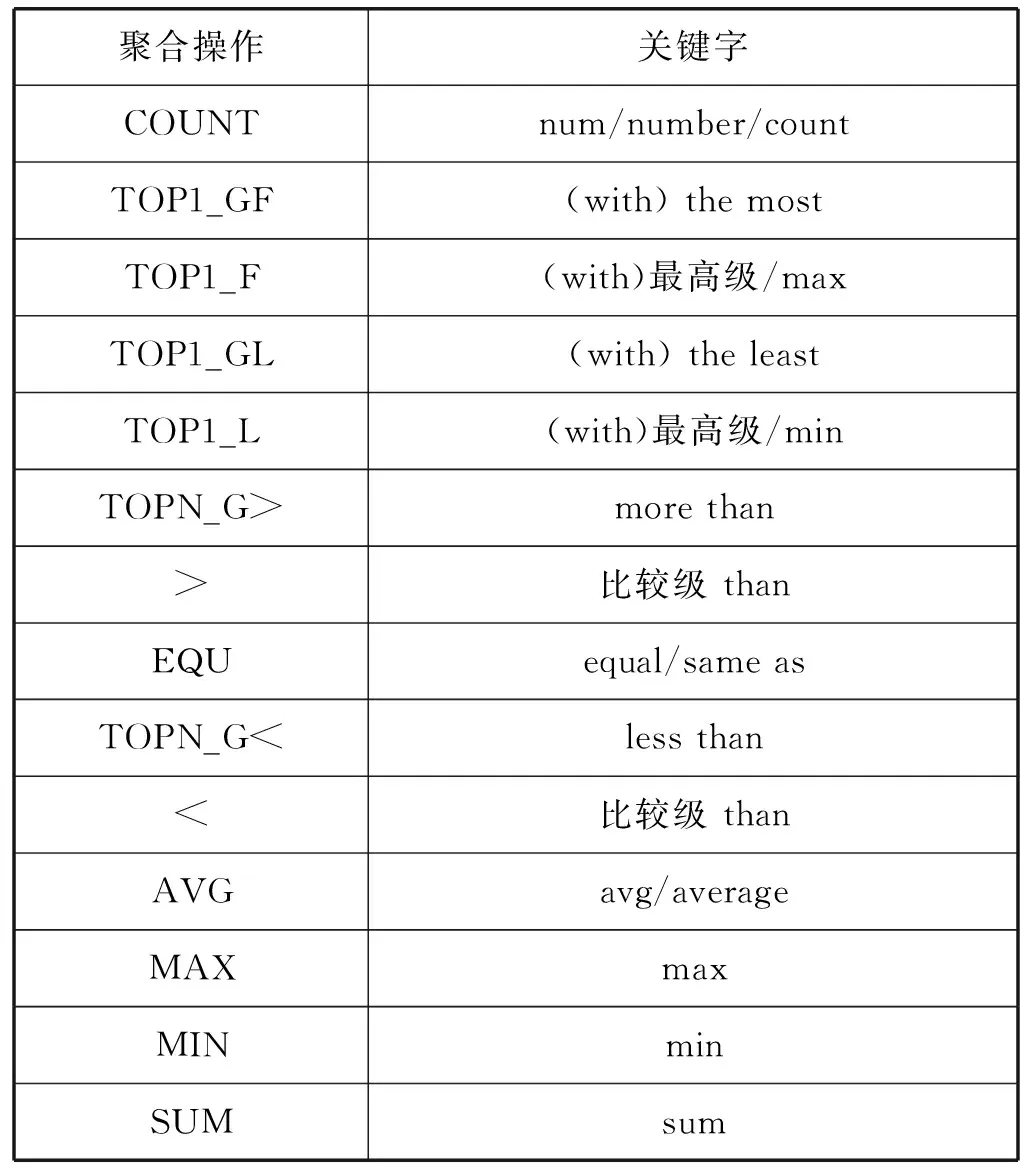
表1 聚合操作分类
通过对SPARQL所支持聚合查询的分析,我们对聚合操作进行了分类,具体定义如表1所示。对于TOP1_G与TOPN_G类型的聚合操作,需要group by来实现查询意图,而其他聚合操作则不需要,这通过聚合信息是否为描述数值型字面量的关系标签来确定。例如“students with most classes”属于TOP1_GF,而对于“students with highest score”则属于TOP1_F,因为score匹配为关系标签,且其宾语为数值型对象。TOP1_G使用group by、order by、count与limit 1获取排名最前的对象。>/<和EQU使用filter子句实现对于结果的过滤,并且该类型的聚合操作会影响查询结构图的连接性,需要考虑操作函数连接子图以获得查询结构的情况。
TOPN使用group by、having、count对查询对象分组,对聚合对象进行计数。MAX、MIN、AVG、COUNT及SUM则为简单聚合查询,查询模块中的AT为null,直接将聚合函数作用于ST。MAX与TOP1的区别在于MAX是直接对属性值最查询,而TOP1则查询具有最值属性的对象,注意:不是包含“max”就对应MAX类别,也有可能是TOP1类型。
如果ki与聚合词典中的key值相匹配,则为候选聚合关键字,如果不存在图元素与ki相匹配,则ki为聚合关键字的概率P(op|ki)为1。当存在图元素与其匹配时,则计算ki匹配图元素的距离倒数S:
(1)
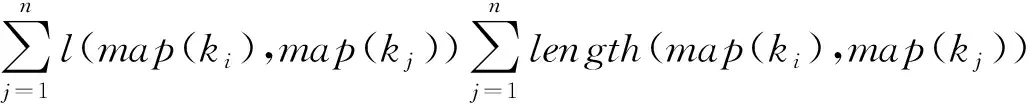
(2)
综上所述,不存在图元素与ki匹配时P为1,否则ki与所匹配字面量编辑距离越小,P越小;ki对应图元素与其他图元素的距离越小,P越小。当P大于阈值时,认为ki与聚合操作匹配。
2.3 查询解释确定
在查询解释确定阶段,对于每一个ki,查看聚合词典,如果ki是候选的聚合关键字则确定是否存在图元素与其匹配,如果不存在,则确定ki为聚合关键字;如果存在,则得到匹配的元素Mi。然后计算Mi所有组合情况,得到元素集合C,对于每一个c属于C,计算ci为聚合关键字的概率。
同时,由聚合操作的分类可知存在聚合操作由词语的比较级或最高级指示,这些特殊的关键字除了指示聚合操作外,其原型形式还会与图元素匹配提供信息。所以对于比较级/最高级形式的关键字,获得对应聚合类型后,将原型词语加入到一般关键字集合中,用于图元素匹配,查询解释获取算法如算法1所示。
算法1查询意图解释生成算法
输入: 关键词查询Q={k1,k2,…,kn}。
输出:一组查询解释。
1.forki in Qdo
2. Mi=map.get(ki)
//关键元素集合
3.ifkiin Operation map.keys()
//候选聚合关键字
4.ifMi==null
//确定为聚合关键字
5. aggType=Operation map.get(ki); aggPos=i
6.ifkiin CompSup_Map.Keys0then
7. archetype=CompSup_map.get(ki)
8. Mi=map.get(archetype)
9.elseMi.add(Operation map.get(ki))
10.elseMi=map.get(ki); aggPos=i
11.C=cartesianProduct(Mi)
12.ifaggType==null && aggPos!=null
//存在候选聚合
13.forc in C:
14.ifP(op|ci>threshold
15. ci=aggType=Operation_map.get(ki); aggPos=i
16. aggType: Operation_map.get(ki)
17. Element.add(getAgg(c, aggType, aggPos))
18.elseElement.add(
19.elseifaggType=nullthenreturn
20.elseElement=getAgg(C, aggType, aggPos)
21.returnElement
22.endif
其中,getAgg函数用于聚合信息的获取,输入关键元素组合,以及聚合操作出现的位置。对于每一组c属于C,如果aggType为MAX/MIN,检查聚合位置前是否为类别,如果存在类别,则将aggType对应修改为TOP1类型;对于TOP1类型的,则根据聚合关键字之后的对象是否为数值型属性,具体分为TOP1_G与TOP1。确定所属聚合类别后,获取查询对象和聚合对象的信息:
(1) 聚合类型属于{AVG, MAX, MIN, SUM},聚合位置之后最接近的属性标签为查询对象,聚合对象为null。
(2) 当聚合类型为COUNT,关键字元素中全部类别元素可能为查询对象,分别对应不同的聚合信息结果,聚合对象则为null。
(3) 聚合类型属于{>, <, EQU},查询对象为聚合操作前的类别元素,聚合对象则描述为A-B的形式,其中A为对应的聚合属性元素或类别信息,B则为聚合操作后的字面量。例如,查询Q1对应的聚合信息为(EQU, AssistantProfessor, interest-fullprofessor1)。
(4) 当聚合类型为TOP1时,如果聚合位置前不存在类别信息,则查询对象ST为聚合位置后的类别节点,AT则为聚合位置对应的属性标签;否则查询对象为聚合位置之前的类别元素,聚合对象为聚合位置之后的类别或属性标签。
(5) 当聚合类型为TOPN_G时,查询对象ST为聚合位置之前的类别元素,聚合对象AT则为聚合位置后类别-聚合位置后字面量。
3 查询意图确定与转换
3.1 模式图提取
原始数据图中通常含有大量的实体和关系,在查询意图确定时需要搜索的空间很大。对于本文中将关键字转换为SPARQL查询语句的任务,在图检索阶段只需确定所匹配的关键元素之间的结构关系,而无须遍历完整的数据图进行精确的匹配。所以我们在包含结构信息的模式图上,实现对于查询结构的确定,进而完成查询转换。
我们从数据图中提取了包含类别实体和类别间关系的模式图,同时本文在模式图中考虑关系标签也为特殊的图节点,在关键字匹配到数据图中的关系标签时也能正确地得到对应搜索意图的关键元素查询结构。对于图3中的RDF数据图,对应的模式图如图5所示。
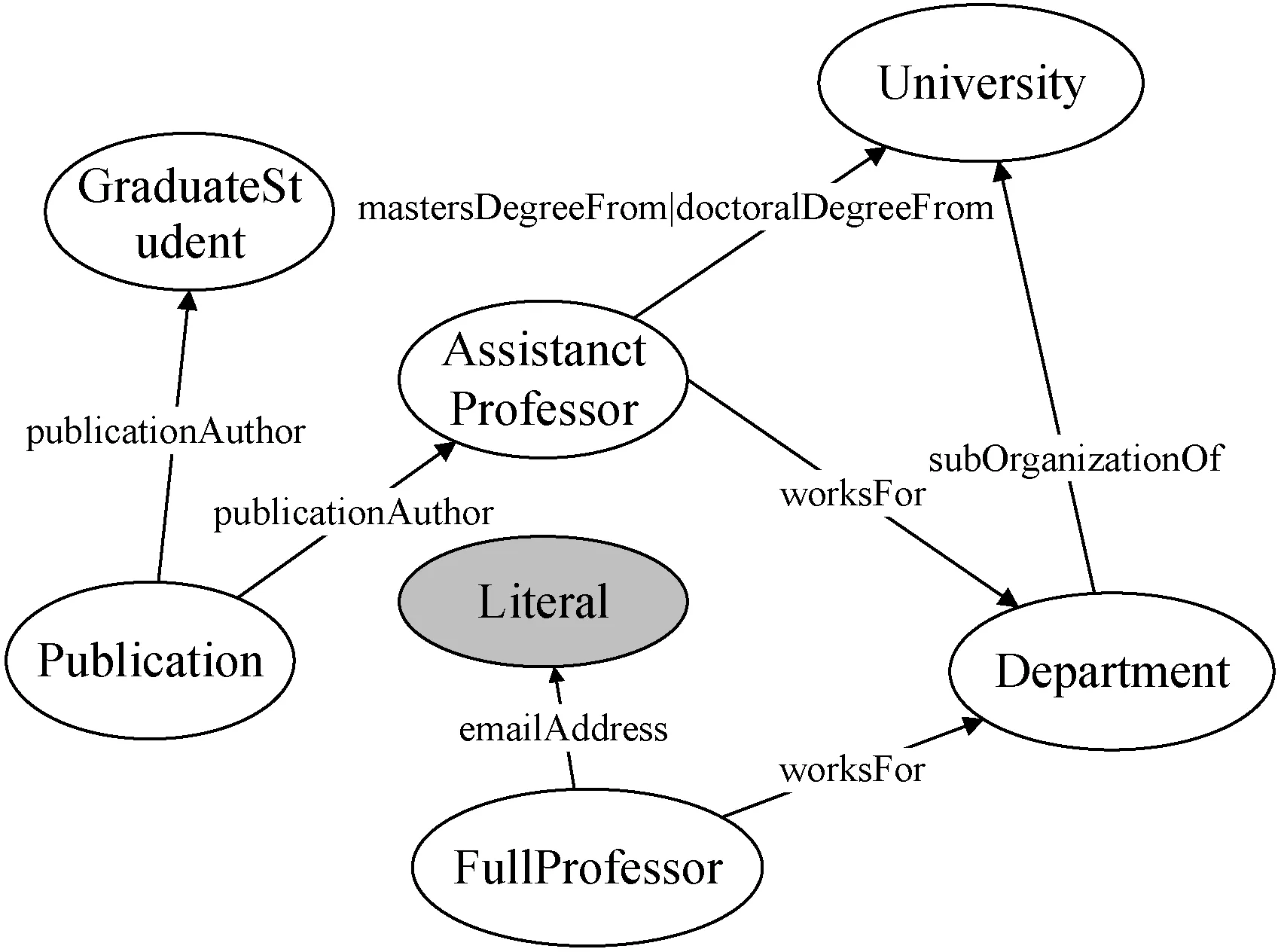
图5 示例模式图
3.2 查询意图计算
在2.3节获取查询解释后,利用查询解释中的元素在模式图上进行扩展,并虑聚合操作对图连接的影响,得到候选查询意图。查询意图获取如算法2所示。
算法2查询意图获取算法
输入:意图组件集合Element={
输出:查询意图集合I={
1.forE in Elementdo
2.ifE.A.operation in {>, <, EQU}then
3. prop=E.A.info.split(-)[0]; value=E.A.Info.split(-)[1]
4.ifvalue not numberthen
5. pos=getpos(prop)
6. C1=cl, c2, …, cpos; C2=prop, cpos, …, cn
7. G1=Expand(C1, max); G2=Expand(C2, max)
8. G.E=G 1.E ∪G2.E
9. G:edge=Gl.edge ∪ G2.edgel∪E.A.operation("Literall","Literal2")
10.else
11. G1=Expand(Evalue, max); G.E=G1.E.add(value)
12. G.edge=G1.Edge.add(A.operation("Literal", value))
13.endif
14.elseG=Expand(E.C,max)endif
15.forg in Gdo
16.fornode in g.Edo
17.ifnode.property!=nullandnode.element!=nullthen
//字面量
18. g.E.add(node.element)
19. g.edge.add(node.property(node.classes,node.element))
20.endifendfor
21. I.G=g; I.A=E.A
22. Result.add(I)
23.endforendfor
24. Result.GetTopk()
25.returnResult
当聚合类型属于{>,<,EQU},聚合操作会影响查询结构图的连接性,将查询分为两个部分,分别进行扩展,并进行连接。其中,Expand函数用于进行摘要图的扩展,根据给定的关键元素集合以及最大查询距离max,获取包含全部元素的子图。在图的扩展的过程中,采用反向搜索策略,由关键元素出发,按照模式图中的结构进行扩展,直到到达连接元素,获得对应查询结构图。
3.3 意图排序方法
由于本文定义的查询意图中包含了聚合信息,所以在对于意图分数进行计算时,需要同时考虑查询图和聚合信息两个部分。对于查询意图I=(G,A),本文设计了新的度量策略来计算由关键字查询获得查询意图的对应分数,主要考虑以下三个指标:
(1) 关键字匹配度。查询图中元素与所对应关键字的匹配程度是衡量意图是否准确的重要指标。同文献[8]一样,对于每一个关键元素,计算其与对应关键字之间的编辑距离;对于非关键元素则认为编辑距离为0,匹配度Sim(G)则为全部元素编辑距离之和的倒数。
(2) 查询图大小。与其他相关研究一样,本文同样认为用户查询的是与给定元素邻近的信息,所以越紧凑的查询结构图,越可能符合用户的查询意图。因此本文使用图中节点数与边数的总和来表示查询结构图的大小SizeG。
(3) 聚合信息的置信度。聚合信息的匹配程度同样是度量查询意图理解准确性的重要指标。对于聚合信息A=(operation,ST,AT),当A为null时,其对应分数为0;当A属于直接聚合和间接聚合两类时,置信度的计算方法分别描述如式(3)、式(4)所示。
当A为直接聚合时:
(3)
当A为间接聚合时:
(4)
Path(AT→ST).length表示在查询结构图中AT与ST所对应元素之间路径的长度。根据上述三个方面影响,得到对于查询意图构建代价的计算方法:
Score(I)=Score(G)+(1-α)Score(A)
(5)
式中:α为调和参数,一般取0.5;Score(G)为查询结构图的分数。
(6)
3.4 SPARQL查询生成
获得查询意图后,可以根据查询结构图转换得到与其对应的查询语句。对于每一个三元组
聚合信息同样利用所包含的信息进行转化,对于TOP1类型的聚合操作,在WHERE子句之后使用group by修饰ST对应变量,再加入order by desc/asc count(variable(AT))(只有TOP1_G类别需要使用count),最后使用limit 1实现返回结果中排序第一的对象;对于TOPN类型的操作,则使用group by修饰ST对应变量,再加入having(count(variable(AT)))对结果进行筛选;而对于MAX/MIN等直接聚合的查询,则通过在SELECT子语句中添加operation(ST)限制,类约束待返回的结果,表达对应的查询语义,例如SELECT MAX(?x),可以返回?x位置所对应的值最大的结果。
4 实 验
为了验证算法的正确性及有效性,本文使用Java语言和Jena框架来解析和处理RDF数据,并实现了上述算法(Power Keyword to SPARQL, PowerKTS)。
4.1 实验环境及数据
实验所用的环境为Windows 10操作系统,i5 CPU,8 GB内存。实验数据为Lehigh大学的开放基准数据集LUBM和RDF形式的2005年DBLP数据,对于LUBM通过代码生成了包含127万条三元组的RDF数据,两个数据集的具体信息表2所示。
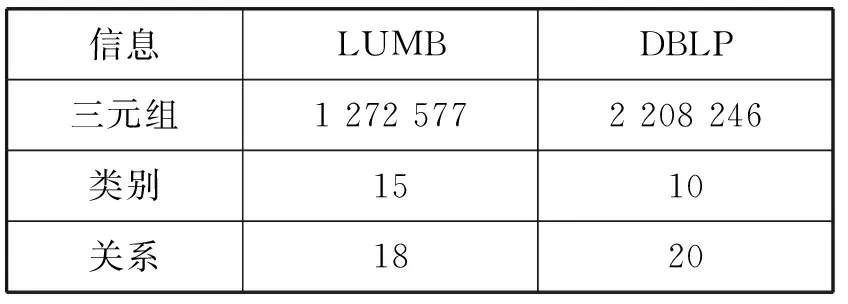
表2 实验数据集信息
本文给定10组关键字查询进行实验,所用具体查询及对应意图如表3所示,L表示LUBM数据集上的查询,而D则表示DBLP上的查询,给定查询关键字中包含一般查询及聚合相关查询。

表3 实验关键字查询数据
4.2 查询准确性评估
对于查询结果准确性的评价,我们采用信息检索领域常用的评价指标MRR(Mean Reciprocal Rank)。
式中:n为正确答案在所返回结果中的排名。即当排序中第一位为正确结果时MRR值最高,此时值为1;而当结果中不包含正确意图时,MRR值为0。
对于上述10组查询,算法1中的阈值设置为1/3,则查询结果对应的MRR值如图6所示,由实验结果可知PowerKTS可以正确实现对于查询统计信息的关键字的处理,返回对应的查询意图,而KAT则只是将聚合关键字与图元素进行匹配,无法正确解析查询意图。而对于一般查询,PowerKTS也可以取得与KAT一样的查询准确度。
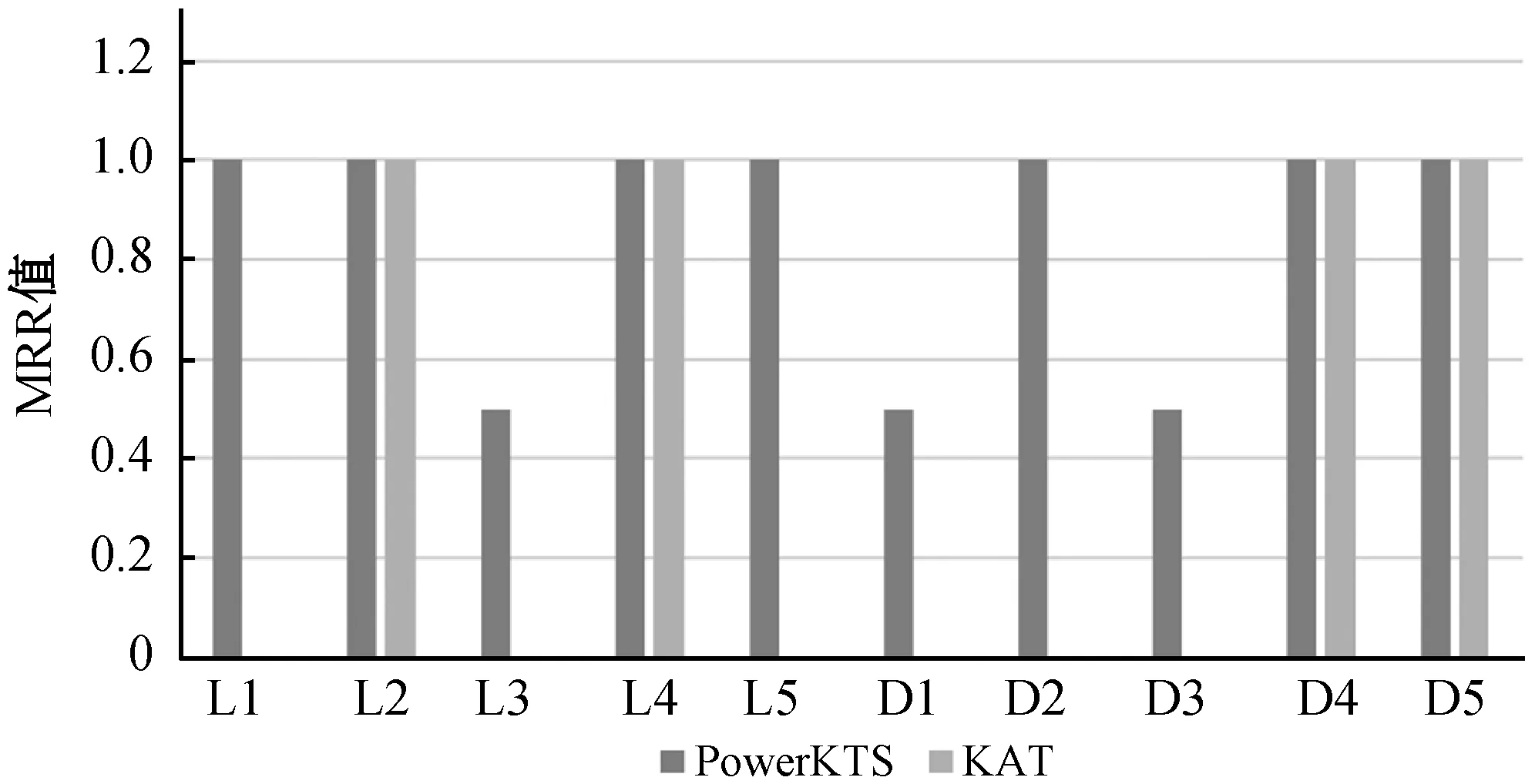
图6 查询准确性结果
4.3 索引空间分析
在倒排索引构建时,将每一个图元素看成是一个文档,分别考虑关键字出现在类别节点、字面量节点以及边标签中的情况,实现索引构建。对于不同的数据集,获得关键字索引文件的大小以及构建时间如表4所示。
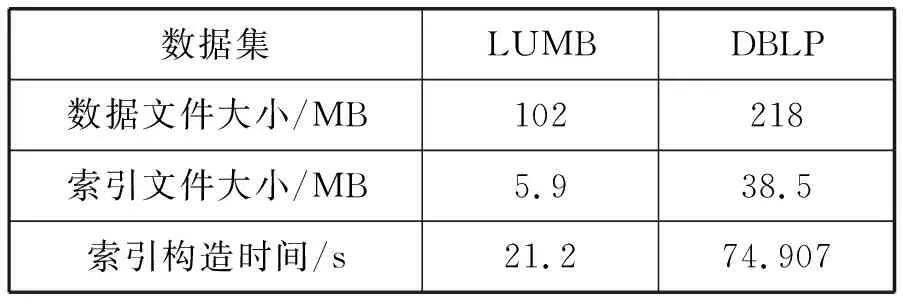
表4 关键字索引构建效率
4.4 查询效率
为了验证本文算法的查询效率,对于给定的关键字查询,实验记录从输入查询到返回SPARQL查询语句所需要的时间,并与KAT算法进行比较。执行时间结果如图7所示。
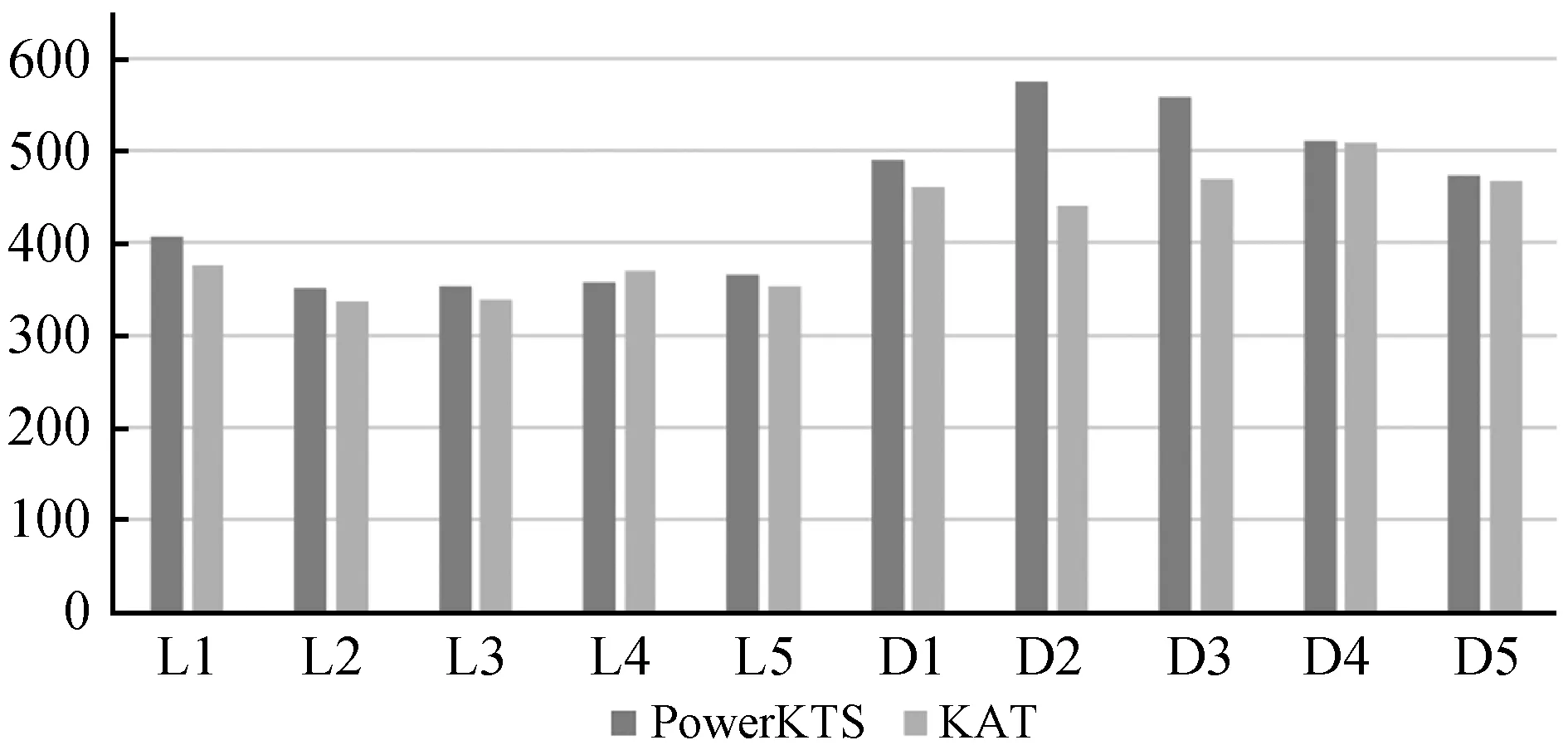
图7 查询转换时间结果
由于在转换过程中需要对给定关键字查询是否为聚合查询进行判断,并获取聚合信息,且模式图的规模很少,两种算法图检索所需时间都非常短,所以PowerKTS的执行时间平均略高于KAT,但是两者差距非常小,验证了算法的查询效率。
5 结 语
本文针对RDF数据上的关键字检索问题,在已有研究的基础上,提出了一种将关键字转换为SPARQL查询的方法,并且支持聚合查询的转换。提出了包含聚合信息的查询意图,对聚合操作进行分类,通过构建聚合词典以及关键字索引,实现对于查询解释的高效获取,并且考虑候选聚合关键字可能对应图元素的情况,对查询解释包含聚合意图的概率进行计算。然后在模式图上进行图扩展,考虑聚合操作对于查询结构图连接性的影响,获取候选查询意图。本文还根据查询意图的组成信息,提出了对应的评分策略,对候选意图进行排序。最后,利用查询转换算法,将查询结构转换为结构化查询。实验验证本文算法可以将关键字转换为符合查询意图的查询语句,支持对于统计信息的查询,并且具有较高的转换效率。
