基于互信息自适应估计的说话人确认方法
2023-02-15季超群李文文陈德运王莉莉杨海陆
陈 晨,季超群,李文文,陈德运,2,王莉莉,2,杨海陆,2
(1. 哈尔滨理工大学计算机科学与技术学院 哈尔滨 150080;2. 哈尔滨理工大学计算机科学与技术博士后流动站 哈尔滨 150080)
生物特征识别是一项根据人类自身的生物特性进行身份鉴别的技术。近年来随着人工智能、大数据、云计算等技术的飞速发展,生物特征识别技术正越来越广泛地应用于监控、监视、网络安全和执法等方面[1]。在众多生物特征识别技术中,说话人确认[2]技术因兼顾生物特征的生理特性与行为特性,具有更高的安全性,备受研究者的广泛关注。
随着深度学习的快速发展,深度神经网络在很多领域都取得了较好的效果。视觉几何组−中等(visual geometry group-middle, VGG-M)网络[3]最初应用于图像处理领域,由于其在图像处理领域的优异表现被各界关注,并应用于说话人确认任务的特征提取阶段[4]。深层残差网络(deep residual networks,ResNet)[5]则可将浅层数据直接传递到深层网络,有利于梯度优化并加快网络的训练效率。
在目标函数方面,最初以分类为目标的目标函数最为常见[6]。这类目标函数主要围绕softmax 损失从两个角度开展研究,一是通过增加不同类别决策边界间的距离来提升其区分能力,包括其变形角-softmax(angular softmax, A-softmax)损失[7]、加性间隔softmax(additive margin softmax, AM-softmax)损失[8]、动态加性间隔softmax(dynamic-additive margin softmax)[9]、加 性 角 间 隔softmax(additive angular margin softmax, AAM-softmax)损失[10]等;二是通过正则化的形式来增加softmax 损失的区分性,这类方法通常以加权的形式建立起正则化器与softmax 损失的联系,使用的正则化器一般也是可独立使用的损失函数,如中心(center)损失[11]、环(ring)损失[12]等。度量学习侧重于考虑特征间的类间与类内关系,能够帮助以分类为目标的目标函数更全面地计算特征间的相关度与区分度,是开放集度量学习问题。因此,以度量学习为目标的目标函数更适合确认任务。常见的以度量学习为目标的目标函数包括二元交叉熵损失[13]、对比(contrastive)损失[14]、三元组(triplet)损失[15]、四元组损失[16]、基于互信息(mutual information, MI)的目标函数[17]等。且随着采样技术的研究与发展,仅以度量学习为优化目标的方法也能够具有理想的性能,与分类结合度量学习的方法具有相仿的效果[18]。
以度量学习为目标的目标函数能够深度挖掘同类特征和异类特征相关性,使网络朝着类内相似和类间差异的方向进行更新。度量学习在计算距离时,通常采用传统的相似度计算方式,如欧氏距离打分、余弦距离打分等。由于其不具备参数,使得在相似度计算方面存在灵活性弱、适应性差等问题。当把这些传统的相似度计算方式应用于目标函数中时,并不能对特征间复杂的非线性关系进行有效表示。针对这一问题,可以有针对性地开发度量学习方法中的自适应能力,从而使目标函数能够根据特征的特点进行动态调整,并在此目标的指引下提升网络对特征表示的区分能力。考虑到自适应性的度量方式能够根据类内和类间的特征分布进行有针对性的参数更新,使得在该度量方式下选取的特征更具有典型性,更有利于目标函数对于网络的特征表示。基于此,本文利用互信息来衡量同类特征之间的相似性信息和异类特征之间的差异性信息,并将一种能够进行自适应学习的度量方法——神经概率线性判别分析(neural PLDA, NPLDA)[19]引入到目标函数的表示中。经过NPLDA 对embedding特征的真实情况进行动态调整后,基于互信息的目标函数能够更好地指引网络朝着类内相似化、类间差异化的方向更新。本文将此方法命名为互信息自适应估计(mutual information adaptive estimation,MIAD),其将最大化互信息作为神经网络的优化目标。
1 互信息自适应估计
1.1 目标函数表示
本文方法的过程示意图如图1 所示。本文利用互信息来衡量同类、异类说话人特征所在分布之间的差异性。并利用NPLDA 模型对特征间的相似性进行自适应表示,从而保证在每轮更新中,根据embedding 特征的分布特性,有针对性地进行特征间的相似性表示。考虑到需要对同类与异类进行表示,本文所提出的目标函数需以度量学习为目标,并通过三元组数据进行表示,此方法的过程示意图如图1 所示。定义由神经网络提取的embedding 特征xa、xp、xn分 别 为 基 准(anchor)样 本、正 例(positive)样本、负例(negative)样本,基准样本与正例样本所属的说话人类别相同,与负例样本所属的类别不同。根据上述符号定义,本文所提出的目标函数可以表示为:

图1 本文所提出方法的过程示意图
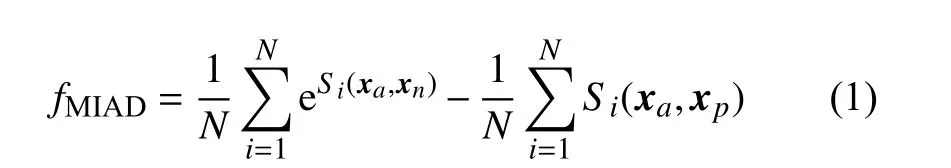
式中,N表示三元组的个数;Si(xa,xn) 表 示第i个三元组中xa与xn的 相似度;Si(xa,xp)表 示第i个三元组中xa与xp的 相似度。通过最小化fMIAD,可以使基准xa与 正例xp的 相似度达到最大、与负例xn的相似度达到最小,从而达到最大化类间相似度、最小化类内相似度的目标。
对于式(1)中的相似度Si(·),简单的相似度度量方法(如欧式距离、余弦距离等)无法保证能准确地衡量embedding 特征间的关系,因此需要根据特征的真实情况来对相似度进行动态调整。基于此,本文将具有验证识别代价能力的NPLDA 引入,并将其用作相似度度量方法。其能够根据同类漏报率、异类误报率进行参数的自适应调整。NPLDA 的相似度计算方式与传统PLDA 的对数似然比打分类似,均能够表示为:
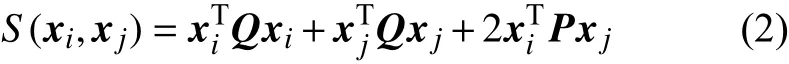
式中,xi、xj为进行相似度计算的embedding 特征;P、Q为NPLDA 模型的参数,它们的初始值是随机生成的0~1 之间呈均匀分布的矩阵,能随着embedding 特征的改变而进行动态调整。
在NPLDA 的训练过程中,需要对同类漏报率、异类误报率进行评价。漏报率与误报率越大,模型损失越大,因此可将最小化它们的加权和当作模型的优化目标。同时,由于漏报与误报针对的识别任务是确认任务(即目标与非目标的二分类问题),因此需要对NPLDA 的训练数据进行划分,以组成以“对”为单位的样本组。针对这一问题,本文采用随机抽样生成标签的方式进行样本组的划分。基于上述描述,NPLDA 的目标函数可以表示为:

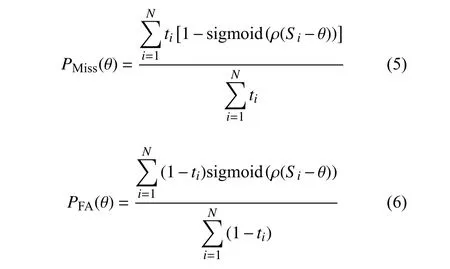
式中,Si为 第i个 样本组的相似度;ti为样本组的标签,当样本组中两个embedding 特征为同类时,ti=1, 反之ti=0; ρ为 翘曲系数,当 ρ值足够大时,Ls(β,θ)的 近 似 值 能 够逼 近 原 始 值,本文 将 ρ设 置为15。
1.2 三元组选取
在本文所提出的目标函数中,需要采用NPLDA以计算embedding 特征的相似度,而在计算目标函数前,还需通过embedding 特征间的相似度以选取三元组。为了统一目标函数与三元组选取时的相似度度量方法,本文在进行三元组选取时,同样采用NPLDA 计算embedding 特征间的相似度,以确保不同环节中相似度的一致性。
在三元组选取时,对于每个类别的embedding特征xa, 首先均需计算其类内相似度S(xa,xp)与类间相似度S(xa,xn)。然后,再从全部备选特征中,选择符合要求的三元组。具体而言,若当前三元组中类内相似度大于类间相似度,则该三元组中的样本为易区分样本,在筛选时应尽量减少对这类三元组的选择。为了加快网络的收敛速度,应选取类内相似度小于类间相似度的三元组,如此便可更直观地向网络传递误差信息,加快网络的收敛速度。同样地,类内相似度与类间相似度相差不大的三元组对于网络参数的更新也具有正向的促进作用,为了能够区分这一情况下的三元组,引入间隔(Margin)变量 α,根据经验 α值一般设置在0.1~1 之间。引入间隔后的三元组选取规则如下:
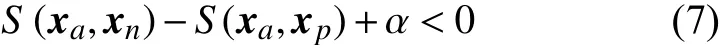
待选择的三元组若不满足式(7),则说明当前网络不能将该三元组进行正确分类,选择该三元组进入网络中学习,使网络在后续的训练中能够对其进行正确的分类。在三元组选取时,需要有针对性地选择训练数据、构建数据组,此过程需要一定的调参经验,对于方法的复现存在少许挑战。
1.3 特征匹配
在说话人确认的测试阶段,需从网络中提取embedding 特征用于后续的特征匹配。定义网络提取的目标说话人embedding 特征为xtarget= (y1,y2,···,yD)T,测试说话人embedding 特征为xtest=(b1,b2,···,bD)T。本文采用余弦距离打分(CDS)进行相似度计算,CDS 可表示为:

2 实验结果及分析
2.1 实验数据库和评价标准
为了验证本文方法在真实应用场景中的有效性,实验采用语音质量参差不齐的大规模说话人识别数据库VoxCeleb1[4]。数据库中的音频均提取自YouTube 视频网站,这些音频取自多种复杂环境,包含各类噪音。数据库的开发集包含1 211 位说话人(690 男,561 女)提供的148 642 段语音音频。评估集则包含开发集类别以外的40 位说话人,共计4 874 条语音。测试时采用官方测试计划列表,总测试数为37 720 次,非目标测试与目标测试比为1:1。评价标准采用等错误率(equal error rate, EER)与 最 小 检 测 代 价 函 数(minimum detection cost function, minDCF),其中minDCF 的参数采用官方设置。EER 与minDCF 的数值越低,说明性能越好。实验将从性能、收敛性及特征可视化3 方面,对所提出方法的性能进行定量与定性的多方位对比分析。
2.2 实验性能对比与分析
本节将对比本文所提方法(MIAD)与其他各类方法的性能,对比的方法包括说话人确认中传统的统计模型与深度神经网络模型。其中,统计模型类方法包括高斯混合模型−通用背景模型(Gaussian mixture model-universal background model, GMMUBM)[20]、身份−矢量(identity-vector, I-vector)结合概率线性判别分析(probabilistic linear discriminate analysis, PLDA),简写为I-vector+PLDA[21]。GMMUBM 的前端声学特征分别采用梅尔倒谱系数(melfrequency cepstral coefficient, MFCC)特征[2,22]、修改幂归一化倒谱系数(modified power-normalized cepstral coefficients, MPNCC)特征[23]、基于仿射变换与特征转换(affine transform and feature switching,ATFS)的特征[23]。深度神经网络模型则包括以VGG-M、ResNet34[5]为网络结构,并分别以对比损失、三元组损失、AM-softmax 损失为目标函数的6 种说话人识别系统。上述6 种方法均采用CDS 来进行说话人匹配,分别简写为VGGM+Contrastive、 VGG-M+Triplet、 VGG-M+AMsoftmax、ResNet34+Contrastive、ResNet34+Triplet、ResNet34+AM-softmax。对于上述6 种使用VGGM 网络、ResNet34 网络的方法,还分别提取了embedding 特征,并利用NPLDA 作为后端分类器,分别简写为VGG-M+Contrastive+NPLDA、VGG-M+Triplet+NPLDA、 VGG-M+AM-softmax+NPLDA、ResNet34+Contrastive+NPLDA、ResNet34+Triplet+NPLDA、ResNet34+AM-softmax +NPLDA。此外,对比方法还包括:基于CNN 的方法(AutoSpeech)[24]、基 于VGG 的 网 络[25]、SincNet 网络[26]、基于VGG-M+MI[17]的方法。
上述方法的参数设置如下:在统计模型方面,MFCC 特征、MPNCC 特征、ATFS 特征的维度分别为13 维、9 维、9 维,且上述3 种特征均采用一阶、二阶差分。GMM-UBM 的高斯分量个数为1 024 个,i-vector 维度为400 维,PLDA 模型的子空间维度为200 维。在深度神经网络模型方面,首先对输入的语音信号预加重、分帧、加窗等预处理操作。预加重系数设置为0.97,加窗的窗长为25 ms,帧移为10 ms,FFT 的点数设置为512 个。经过以上操作后可以获得一个512×300 维的语谱图特征。VGG-M 网络、ResNet34 网络最后一层全连接层的维度为1 024 维,其对应的embedding 特征亦为1 024 维。在三元组选取时,间隔 α设置为0.3。VGG-M、ResNet34 的优化算法采用随机梯度下降(stochastic gradient descent, SGD)算法,初始学习率为1 0−3, 最终学习率为1 0−4。在MIAD 目标函数中的NPLDA 模型则使用适应性矩估计(adaptive moment estimation, Adam)算法作为优化器。基于以上参数设置,不同方法的实验性能如表1 所示。
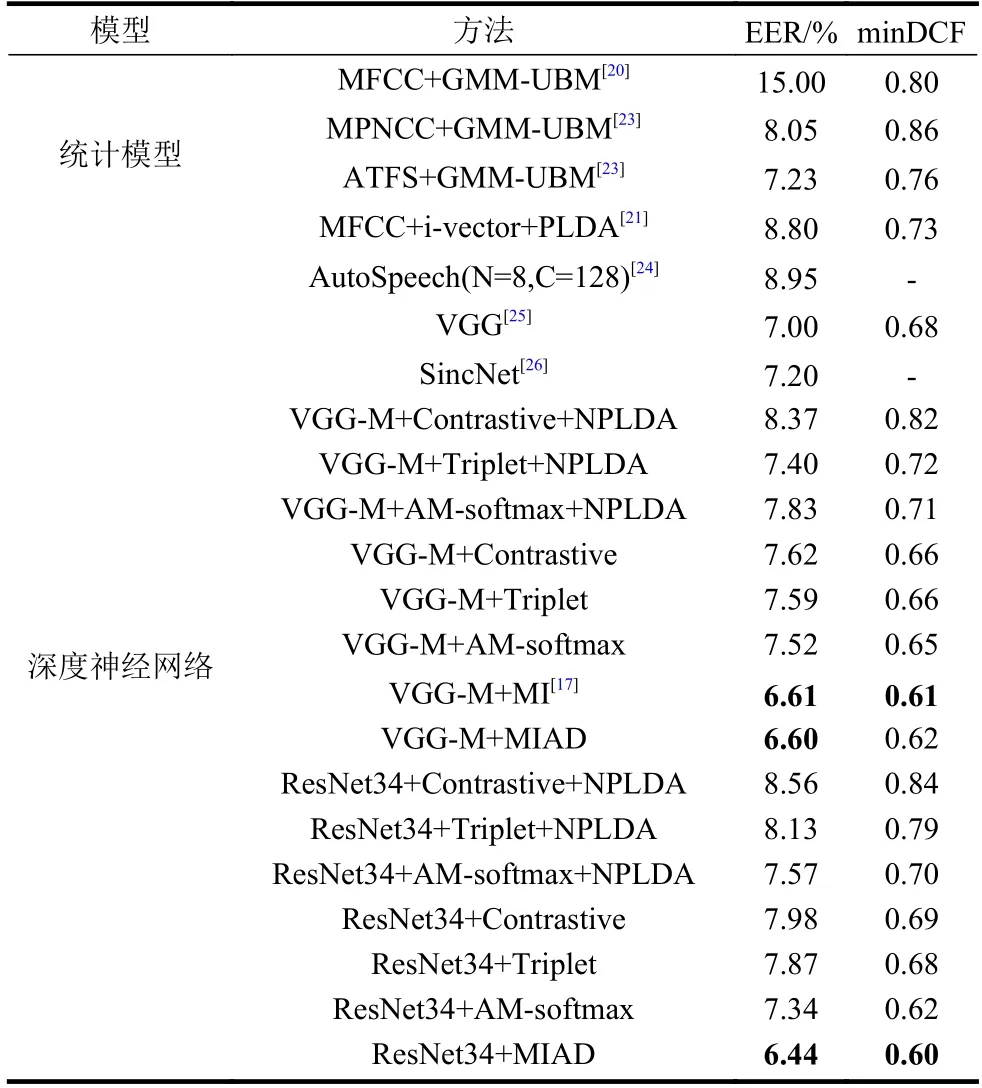
表1 不同方法的性能对比
从表中可以看出以下几点。
1) VGG-M+MIAD 方 法、ResNet34+MIAD 方法的性能明显优于使用相同网络的其他方法,EER明显降低。在相同网络结构的条件下,MIAD 能够取得优于其他目标函数的性能。
2) 相比于VGG-M+MI,本文所提方法的EER虽然只有小幅度降低,但相比于其他目标函数的性能提升明显,EER 最多降低了2.35%。且所提方法的亮点在于能够有针对性地开发度量学习的自适应能力,能使目标函数根据特征的特点进行动态调整,还能消除三元组选取阶段和目标函数相似度度量方法不一致的隐患。
3) ResNet34+MIAD 相比于其他深度神经网络方法,相对等错误率最多降低了28%。本文所提的MIAD 目标函数能够有效地衡量同类、异类说话人特征所在分布之间的差异性,引入自适应方法能够更有针对性地对embedding 特征进行表示,有效提升了识别系统的性能。
2.3 收敛性对比与分析
本节将对比具有相同网络结构的不同目标函数方法的收敛性。网络结构分别为VGG-M、ResNet34,目标函数则包含AM-softmax 损失、三元组损失、对比损失、MIAD 损失。收敛性曲线采用EER 和minDCF 作为性能评价指标,上述所有方法均使用相同的预训练模型。4 种方法的收敛性曲线图如图2 所示,从图中可以看出以下几点。
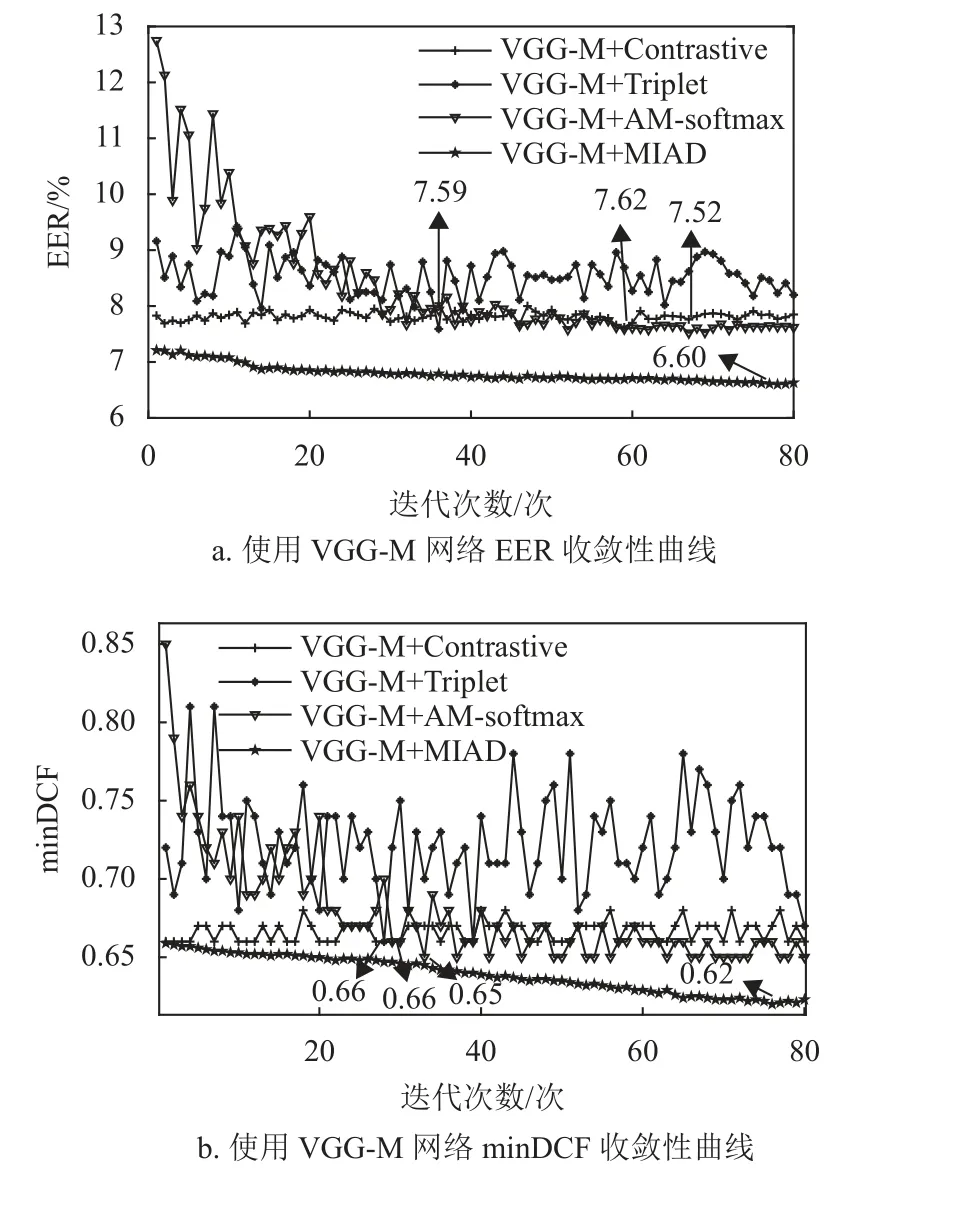
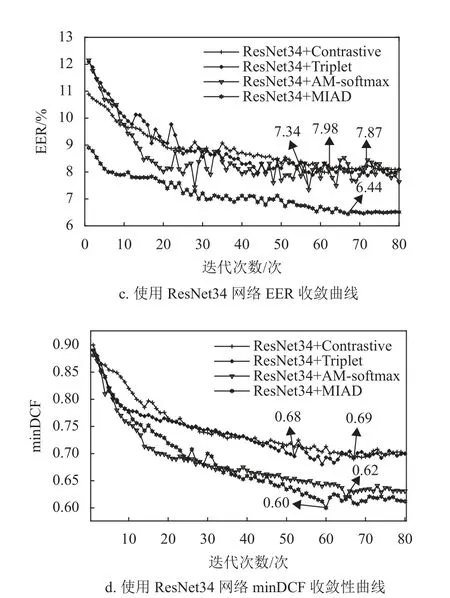
图2 收敛性曲线对比图
1) 随着迭代次数的增加,全部方法的等错误率和minDCF 均有下降趋势。本文的MIAD 方法在使用两种网络结构的情况下,等错误率和minDCF 更低。
2) 本文方法VGG-M+MIAD 在经过78 轮迭代后等错误率达到最低,数值为6.60%,ResNet34+MIAD 在经过67 轮迭代后等错误率达到最低,数值为6.44%,相比于其他使用相同网络结构的方法性能更好。可以证明本文方法能够提升说话人识别系统的性能。
3) 本文方法在使用相同网络的情况下,均拥有更低的minDCF,VGG-M+MIAD 数值为0.62,ResNet34+MIAD 数值为0.60。进一步证明了本文方法具有更好的性能。
2.4 可视化分析
为了更直观地衡量本文方法的有效性,使用t-SNE[27]方法对不同方法进行可视化表示。对比方法包括i-vector 特征、PLDA 说话人隐变量、VGG-M+Contrastive 的embedding 特 征、VGG-M+Triplet 的embedding 特 征、VGG-M+AM-softmax的embedding 特征、VGG-M+MIAD 的embedding特 征、ResNet34+Contrastive 的embedding 特 征、ResNet34+Triplet 的embedding 特 征、 ResNet34+AM-softmax 的embedding 特 征、ResNet34+MIAD的embedding 特征。从评估集中随机选择5 位说话人进行可视化表示,每位说话人包含80 段语音,不同类别的说话人对应不同灰度的点。t-SNE 方法的各项参数设置为:维度30 维,困惑度10。
基于上述实验设置,不同方法的可视化对比图如图3 所示。从图中可以看出以下两点。
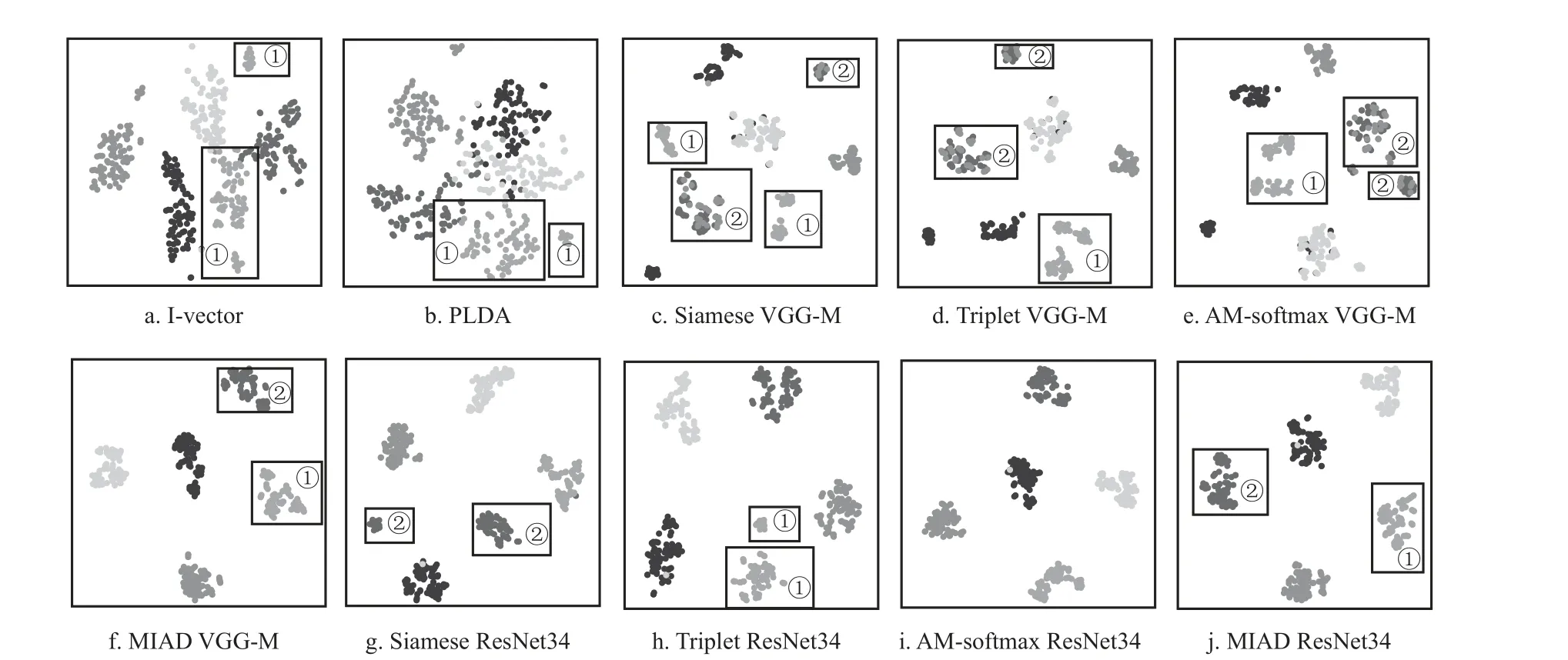
图3 不同特征的可视化对比图
1) 相比于图3a~3e、3g~3j,图3f、3j 中的可视化特征聚集得更紧凑。由此可见,本文方法能够更好地捕获同类特征的相似性。
2) 在各子图的矩形框①中,图3a-3e、3h 中的同类特征均被聚到2 簇中,但图3f、3j 却能很好地聚到同一簇中。同样地,在子图的矩形框②中,图3c-3e、3g 中的同类特征均被聚到2 簇中,但图3f、3j 却能很好地聚到同一簇中。由此可见,对于那些类内差异性大的特征,本文方法仍然能够很好地对其同类相似性进行表示。
3 结 束 语
本文提出了一种基于互信息自适应估计的目标函数,该目标函数能够根据特征的实际情况进行动态调整,使得互信息估计能够挖掘到更有价值的同类、异类特征信息。该方法还将具有自适应能力的度量方法NPLDA 应用于特征选取阶段,NPLDA能够根据特征的真实情况有针对性地更新参数,使选取的特征更典型,从而有效提升在此目标函数监督下网络的表示能力。从性能、收敛性、特征可视化3 个方面的对比分析可以证明,本文方法在说话人确认任务上具有良好表现。在后续的研究工作中,考虑到NPLDA 中的漏报与误报对应的是目标/非目标的确认任务,因此可以将其目标函数改进为基于互信息的损失,从而为整个网络的优化带来正向提升。
