基于对比学习的双分类器无监督域适配模型
2023-02-09孙艳丰胡永利
孙艳丰, 陈 亮, 胡永利
(北京工业大学信息学部, 北京 100124)
在大数据时代,图像数据规模不断扩大,图像识别任务在实际应用中越来越重要[1]. 基于深度学习的图像识别方法是目前主流的高性能识别方法,它依赖大量有标注的图像数据训练模型,但数据标注是一项耗费人力成本和时间成本的复杂工作. 为解决上述问题,研究人员提出了域适配方法. 该方法致力于将有标注的源域知识迁移到无标注的目标域[2]上,从而使基于源域数据训练的模型能够解决目标域的相关任务. 根据目标域数据的标注情况,域适配方法可分为半监督和无监督2类. 在半监督域适配问题中,目标域数据含有少量标签. 对于无监督域适配问题,目标域则没有任何标注信息[3],本文重点研究无监督域适配问题.
目前,主流的域适配方法主要是通过减少源域和目标域的域间差异来完成域适配任务,可以分为2类:一类是将不同域数据投影到公共潜在的空间中,通过减小不同域数据在潜在空间中的分布差异实现域适配任务. 其中度量分布距离的方法包括最大化均值差异(maximum mean discrepancy, MMD)[4]或Wasserstein距离[5]等. 另一类主流的方法结合了对抗学习的思想,通过提取域一致性特征消除域间差异. 目前,基于对抗的方法主要分为2种:第1种思路结合了生成对抗网络(generative adversarial networks, GAN)[6]的思想,在模型中引入了域判别器网络. 以域对抗神经网络(domain adversarial neural networks, DANN)[7]为例,该模型使用了一个特征提取器以及一个域判别器. 域判别器用于辨别当前数据来自于源域或目标域,而特征提取器则期望通过提取共性特征来迷惑域判别器,使其无法分辨当前数据来源. 通过对抗训练,最终使得特征提取器学到域一致性特征. 第2种对抗方法主要基于双分类器构建,模型包含2个分类器及1个特征提取器. 以分类器差异最大化(maximum classifier discrepancy, MCD)模型[8]为例,该模型假定不同分类器可以学到多样性特征,若双分类器输出存在差异则表明模型对当前样本分类置信度较低. 在对抗训练过程中,2个分类器最大化对当前样本的判别差异,特征提取器则期望提取域一致性特征以减少分类器输出差异,从而减少边界样本数量. MCD模型使用范数来度量分类器之间的差异,不能很好地结合数据的几何结构,因此,在MCD模型的基础上,基于切片Wasserstein距离(sliced Wasserstein distance, SWD)的双分类器域适配模型[9]使用SWD度量分类器间的输出差异,进一步对齐了数据间的结构信息.
尽管基于双分类器的域适配模型性能优异,但依然存在一些问题:第一,2个分类器共享特征提取器输出的特征,这限制了不同分类器捕获多样性信息的能力,导致模型无法有效检测边界样本;第二,仅依赖不同分类器之间的预测差异不足以捕获目标域中高区分度的有效信息;第三,虽然传统的双分类器模型可检测边界样本,但无法对边界样本进行正确分类,因此,限制了模型的性能. 为解决上述问题,本文提出基于对比学习的双分类器域适配模型. 首先,通过不同的数据增强方式得到不同视角特征,在保证分类器输出多样性的同时,能较好地使用对比损失函数更新模型;然后,针对传统双分类器存在的问题,使用SWD对齐了源域和目标域的标签分布,进一步提升了模型的性能.
1 相关工作
1.1 对比学习
近年来,对比学习[10]模型引起人们广泛关注,因为该方法能在没有标注的条件下,直接将数据本身作为指导信息,学习到数据中区分度较高的特征.
对比学习方法并不关注样本的细节信息,而是关注数据中类别区分度较高的特征. 通常,实现对比学习的一种行之有效的方法是使用孪生网络结构,首先对样本使用不同的数据增强方式,然后将其送入孪生网络的不同支路中,通过使用对比损失训练模型使得不同支路特征在嵌入空间中具有一致性表达,从而提取样本的主干信息. 在对比学习模型的特征空间中,同类样本的特征表达相似,不同类样本特征表达互异. 目前,基于动量的对比(momentum contrast, MOCO)学习方法[11]以及对比学习简单表示(simple contrastive learning representation, SimCLR)方法[12]在ImageNet[13]数据集上的准确率能够同监督学习算法相抗衡. 然而,这些方法在实际训练中依赖大量的负样本,这会大量消耗内存资源,导致模型训练成本较高. 同以上的对比学习模型相比,简单孪生(simple siamese, SimSiam)表示对比学习模型[14]使用了梯度停止方法来抑制模式崩塌的问题,因此,该模型仅使用小批次正样本就能达到较好的效果. 受到SimSiam模型的启发,本文将双分类器对抗学习和对比学习思想相结合,在检测边界样本的同时剔除冗余特征,从而提升模型性能.
1.2 SWD
Wasserstein距离广泛用于度量数据分布之间的差异. 相比于其他形式的距离度量,Wasserstein距离更适用于对齐数据分布中潜在的几何结构.
Wasserstein距离由最优运输问题[15]定义,该理论给出了将固定质量的沙土运输到指定大小的洞中所消耗的最小成本的运输方案. 由于日常所获得的数据往往是离散的形式,离散形式Wasserstein距离定义如下:
令Ω⊆Rd为数据分布的度量空间,S,T⊆Ω表示不同分布样本所在的子空间,S和T的边缘分布分别为μs和μt,则μs和μt之间的1-Wasserstein距离定义为
(1)
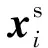
式(1)在进行求解时需要使用交替迭代的方式分别固定运输计划γ和运输损耗c,从而得到源域样本在目标域上的映射.当样本量较大时,使用式(1)度量高维数据分布差异会导致模型计算复杂度较高,因此,本文采用SWD度量分布之间的差异.
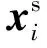

2 基于对比学习的双分类器域适配模型
2.1 双分类器域适配模型
基于双分类器的域适配模型主要由2个部分构成,分别是特征提取器G以及2个分类器C1和C2.此模型首先使用特征提取器提取源域和目标域数据的特征fs和ft,并作为双分类器的输入特征,2个分类器输出数据的预测标签概率分别为p1(ys|xs)、p2(ys|xs)和p1(yt|xt)、p2(yt|xt).该模型通过对抗的方式训练特征提取器以及双分类器.其中,双分类器通过最大化p1(yt|xt)和p2(yt|xt)的差异来检测边界样本,而特征提取器通过提取数据的共性特征最小化2个分类器的输出差异.该模型通过上述对抗学习减少目标域边界样本的数量.模型训练步骤如下.
步骤1在源域数据上使用损失函数Lcls(xs,ys)训练整个深度网络,优化目标为
式中:Lce(·,·)是交叉熵损失;θG、θC1、θC2分别是网络G、C1、C2的参数.
步骤2固定特征提取器中参数,仅更新分类器C1和C2.最小化分类器分类损失以及最大化分类器对目标域样本的判别差异.优化目标为
式中Ldis(·,·)表示双分类器对目标域样本判别差异.
步骤3固定分类器C1和C2中的参数,通过最小化Ldis(·,·)更新特征提取器中的参数,优化目标为
重复以上3个步骤直到模型收敛.
上述训练方法可以检测目标域的边界样本,并利用不同分类器的输出多样性改善模型性能.模型训练过程中的步骤2和步骤3如图1所示.

图1 步骤2、3训练过程Fig.1 Training process of step 2 and step 3
2.2 基于对比学习的双分类器域适配模型
如2.1节所述,传统的双分类器模型期望通过不同分类器输出差异检测边界样本.然而,分类器C1和C2共享特征提取器的输出特征,分类器的输出差异仅依赖不同分类器中参数的差异,这不仅限制了分类器的输出多样性,同时,也导致模型过早收敛.
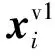
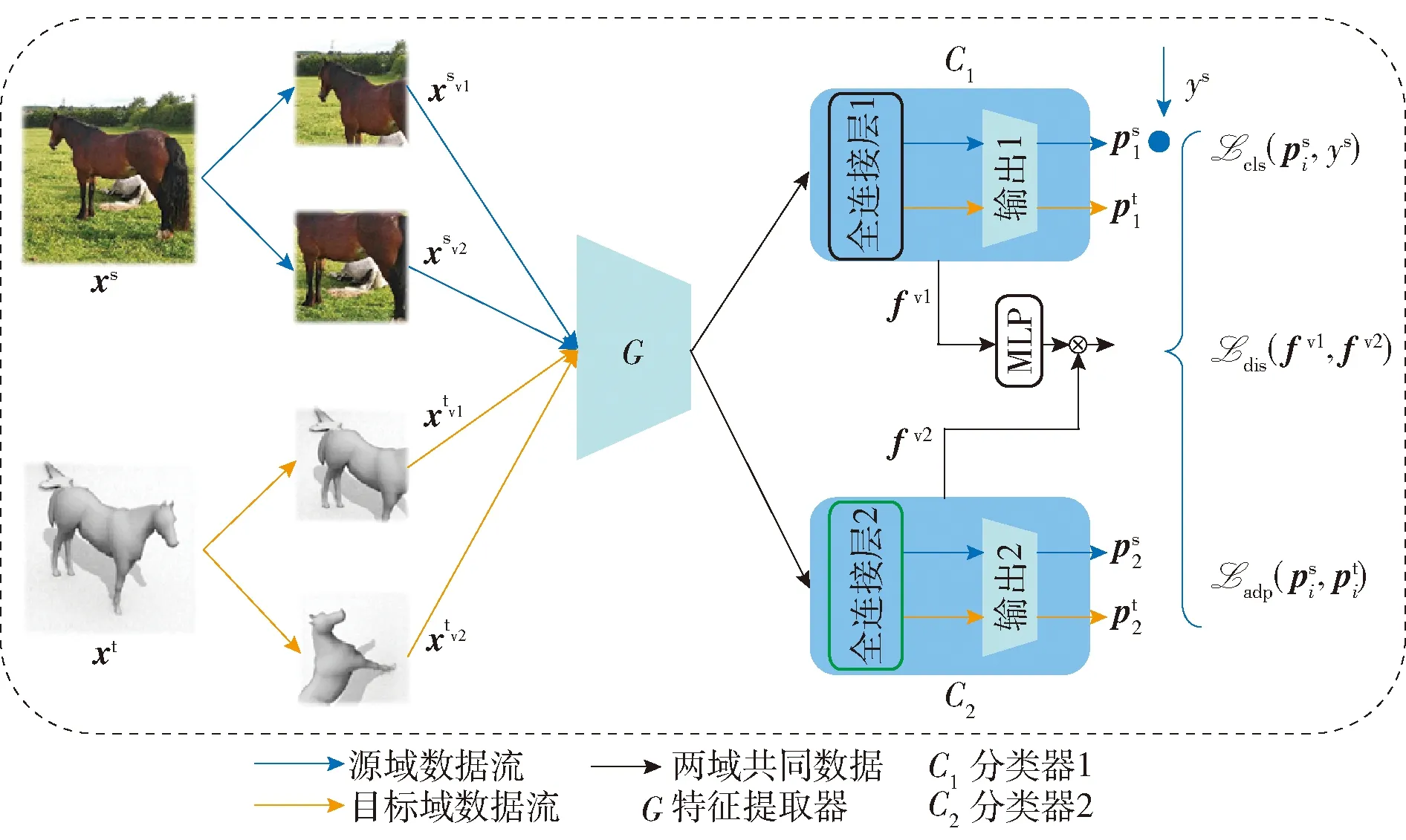
图2 本文模型整体结构Fig.2 Framework of the proposed model
传统的双分类器模型仅关注不同分类器预测概率的差异,导致模型无法捕获特征中有效信息.为解决此问题,本文将对比学习思想融入双分类器域适配模型,通过约束不同分类器中的特征差异继而约束分类器输出差异.余弦相似度的数值范围不受数据维度的影响,因此,本文使用余弦相似度度量不同视角特征的差异,公式定义为
(2)
参照SimSiam模型,本文将同一样本不同视角的特征视为对比学习中的正样本对,使用余弦相似度减少正样本对之间的差异,从而提升模型提取高层语义信息的能力.考虑到仅优化式(2)会造成模式崩塌等问题,本文参照SimSiam模型,使用多层感知机(multi-layer perception, MLP)映射以及梯度停止技巧防止模式崩塌问题.使用梯度停止后,一次仅更新1条支路,因此,本文使用带有对称关系的对比损失更新2条支路.损失函数定义为
式中:stg(·)表示仅使用张量数据部分,而不使用其梯度;M(·)表示MLP映射函数模块,该模块的输入和输出维度一致以满足计算的需要.
虽然传统双分类器模型可以检测边界样本,但若2个分类器同时误判,则模型无法纠正该样本. 例如:对于三分类任务,2个分类器对目标域A样本判别概率分别是[0.60,0.20,0.20]、[0.59,0.21,0.20],因为2个分类器的输出基本一致,所以即使对A样本误分类,模型也无法在后续的训练中纠正.
为解决上述问题,本文引入源域和目标域数据标签分布对齐正则项,通过最小化SWD对齐源域以及目标域的标签分布,从而在一定程度上避免这一错误. 当引入了标签分布对齐后,为了减小域间分布差异,标签分布对齐会不断更新A样本的位置,从而,分类器会纠正对A样本的误判. 综上所述,模型最终的标签对齐函数定义为
式中fs和ft分别表示源域和目标域特征.
2.3 模型优化方法
模型优化的过程如下.
步骤1和传统的双分类器域适配模型一致,均使用源域数据交叉熵损失更新整个模型的参数.
步骤2固定特征提取器中的参数,更新分类器以及MLP特征映射模块中的参数.此外,本步中加入标签分布对齐项,并最大化分类器间特征差异.余弦相似度的输出范围为[-1,1],当特征向量正交时相似度最低,因此,本文对Ldis使用绝对值,优化目标为
式中:θC1、θC2分别代表分类器C1和C2中的参数;θMLP为映射模块M中的参数;λ和η代表损失函数中的平衡参数.
步骤3固定2个分类器中的参数,更新特征提取器以及特征映射模块M中的参数.本步保留了自适应损失项,优化目标为
3 实验与分析
3.1 数据集及实验环境
本部分通过跨域识别实验证明模型的有效性及可靠性,使用平均的分类精度衡量模型的性能. 本文参考当前主流的方法,选择2个跨域识别数据集Office-31[16]和Image-CLEF来验证模型的效果. 其中,Office-31数据集中含有3个子域,分别是Amazon、Webcam和DSLR. 每个域中含有31个类别,整个域中共含有4 652张图像样本. Image-CLEF数据集由3个子域构成,分别是Caltech256(Caltech)、ImageNet ILSVRC (ImageILS)以及Pascalvoc 2012(Pascal),括号中的为该数据集的简记. 整个数据集中含有1 800张图片样本,每个子域中分别含有600张图片样本,并包含12个类别. 实验中所有的代码均使用Python以及Pytorch,使用的显卡为RTX 3090.
3.2 对比方法
本文选取的主流对比方法分为以下3类.
1) Source-only方法 此方法使用Resnet-50作为模型的特征提取器,并且仅使用源域数据训练整个模型,而后将训练好的模型直接对目标域数据分类. 此方法为所有对比方法的基准线.
2) 经典方法 本文选择了当前经典的域适配方法,其中包括基于MMD距离度量的深度域适配网络(deep adaptation network, DAN)[17]. 基于域判别器对抗训练的DANN方法以及在DANN的基础上考虑结构匹配的条件对抗域适配网络(conditional adversarial network, CDAN)模型[18].
3) 基于双分类器的域适配方法 为证明引入对比学习思想的有效性,本文与其他基于双分类器的域适配方法进行比较. 其中主要包括首次使用双分类器对抗训练的MCD、在MCD基础上使用Wasserstein 距离度量2个分类器输出差异的SWD以及额外使用域判别器对抗方法对齐2个域数据分布的联合对抗域适配(joint adversarial domain adaptation, JADA)方法[19].
3.3 模型框架及实验参数
本文使用Resnet-50[20]作为主干网络,其他实验参数具体如下.
数据增强:参考SimCLR模型,使用该模型的数据增强方式预处理数据.
优化器:使用随机梯度下降优化器训练模型. 其中,权重衰减值设定为0.000 5. 分类器的学习率设定为0.003,特征提取器的学习率设定为分类器的1/10. 因此,模型既能稳定地提取特征,同时分类器也能更快收敛. 为防止过拟合问题,本文使用ηlr=α0/(1+α1q)β自动调整模型的学习率,式中q的权重参数范围为[0,1],α0=0.01,α1=10,β=0.75.训练批次样本数为36.
分类器:为确保分类器的多样性,2个分类器的结构彼此互异. 分类器C1由2个全连接层以及1个输出层构成. 全连接层的输出维度分别是1 024、1 024. 分类器C2由3层全连接层以及1层输出层构成,全连接层的输出维度分别是1 024、512、1 024. 本文选取全连接的最后一层作为该支路特征的输出层.
MLP:MLP的各层中均包含批量标准化(batch normalization, BN)层,在全连接层的输出层后连接BN层以及ReLU层. MLP由3层全连接层构成,并且输入和输出层的维度均为1 024,隐含层的节点数量为512,这使得MLP类似于一个瓶颈的结构.
3.4 实验结果及分析
为证明本模型的有效性,本文在Office-31以及Image-CLEF数据集上设计跨域识别实验,并与所选取的对比方法进行比较. 所有实验数据均为模型30次迭代之后的输出. 由于SWD模型在2个数据集上均缺失相关数据,本文在2个数据集上复现了SWD模型实验,并记录实验数据,实验结果见表1、2. 表中:其他对比方法结果均摘自模型原文;黑体部分表示此项适配任务最优的结果;识别任务记作S→T, S表示有标注的源域数据,T表示无标注数据的目标域,S→T表示利用源域的标注数据解决目标域上的分类任务.
由表1和表2可知,对于域适配较为困难的任务DSLR→Amazon以及Caltech→Pascal,基于双分类器的域适配方法普遍比经典的基于对抗学习的域适配模型性能高,这表明引入双分类器能够更好地挖掘样本的有效信息,从而区分处于分类边界的样本. 本模型在2个数据集上的平均分类性能达到了最佳,这表明对比学习结合双分类器模型能促使模型提取到样本中高层的语义信息,减小特征分布的混淆程度. 此外,从特征的角度定义分类器之间差异能使得损失函数直接作用于特征,减少梯度反向传播时带来的误差积累.

表1 模型在Image-CLEF数据集上的域适配性能(ResNet-50)

表2 模型在Office-31数据集上的域适配性能(ResNet-50)
为直观展现模型性能,本文使用t-SNE[21]对域适配任务Pascal→Caltech进行数据降维可视化,同时,选取Source-only、MCD以及SWD作为对比方法. 数据可视化结果如图3所示,不同的颜色代表数据中不同的类别. 图中:“●”代表源域数据;“×”代表目标域数据.
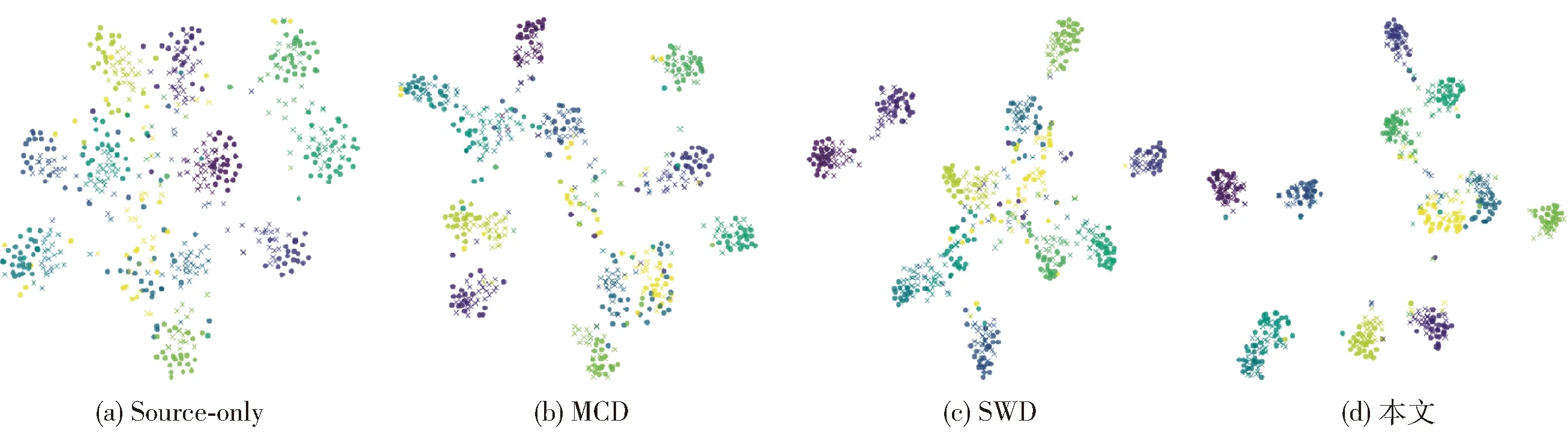
图3 数据分布结构Fig.3 Structure of data distribution
从图3可以看出,由于存在域差异,Source-only方法无法有效对齐源域和目标域上的数据. 相比于Source-only方法,MCD以及SWD均能减少目标域上的边界样本数量. 然而,当目标域数据分布结构较复杂时,不同类样本之间的距离依旧不明朗. 由图3可知,本模型数据分布结构更为清晰,不同类之间类中心距离较大,不同域中同类样本对齐紧密. 这表明本模型具有提取数据有效信息的优越性.
3.5 消融实验
为验证使用分类器输出的多样性对实验结果的影响,图4记录了Image-CLEF数据集上的Pascal→Caltech的实验结果.
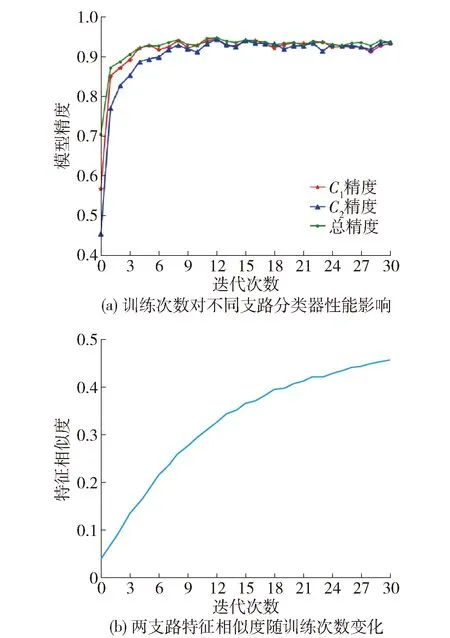
图4 2个分类器的差异Fig.4 Difference between two classifiers
由图4可知,在模型训练的开始阶段分类器的预测准确率差异较大,并且2个分类器在模型的初始阶段性能均差于双分类器的综合性能. 这表明2个视角的数据能够在训练初期提供互补的信息,从而提高分类器综合性能. 随着模型训练次数增加,分类器间的特征相似性逐渐增高,分类器的预测准确率逐渐升高且趋向一致. 这表明随着双分类器的输出差异逐渐变小,目标域边界样本也逐渐减少,证明本模型能够有效减少边界样本数量.
此外,为验证各模块作用,本文基于Image-CLEF数据集中的Pascal→ImageILS、ImageILS→Caltech和Caltech→Pascal进行消融实验. 实验结果如表3所示. 表中:“w/o adp”表示模型不使用SWD对齐源域和目标域的标签分布;“w/o dis”表示模型不使用对比损失. 在3个分类任务中,Caltech→Pascal属于较困难的域适配任务,Pascal→ImageILS和ImageILS→Caltech则属于较容易的域适配任务. 从表3的结果可以看出,对于困难的任务Caltech→Pascal,若仅对齐标签分布而不使用对比损失(w/o dis),模型性能下降了4%. 相比之下,仅考虑对比损失而不考虑标签分布匹配模型(w/o adp)性能仅下降了1.3%. 实验结果表明,对于复杂的域适配任务,对比损失对模型的结果影响较大. 对于Pascal→ImageILS以及ImageILS→Caltech两个较为简单的任务,若去除标签分布匹配项(w/o adp)则对模型的结果有较大的影响. 这表明,面对域差异较大的任务时,基于对比损失得到的区分度较高的特征对模型性能的影响更大. 当域间差异较小时,通过标签分布对齐能更好地提升模型的性能. 以上实验结果证明了结合域对齐以及对比损失可以有效提升模型的性能且模型中各部分都是不可或缺的.

表3 消融实验
4 结论
1) 本文提出一种基于双分类器的对比对抗学习方法,在传统双分类器域适配模型的基础上进一步融入了对比学习思想. 数据可视化和识别实验的结果表明,双分类器模型结合对比学习思想能较好地提升模型的性能.
2) 虽然本文方法在分类实验中取得了较好的效果,但将本模型扩展到目标检测任务是否会导致计算复杂度增高还有待研究,未来将进一步探索本模型的可扩展性.
