基于主成分分析和深度自编码高斯混合模型的无监督异常数据检测方法研究
2023-02-07刘翔宇朱诗兵
刘翔宇,朱诗兵,杨 帆
(航天工程大学,北京 101416)
0 引言
近年来,网络安全问题变得越来越隐蔽,随着科技发展数据量日益庞大,面对海量的数据和较高维度的特征,高维大数据异常检测成为一个研究热点。
机器学习可分为有监督学习和无监督学习。其中,有监督学习可以较好地识别已知攻击,但面对海量数据和日益隐蔽的新型攻击手段,有监督学习主要存在以下两个缺点:
1)训练过程依赖对数据集的准确标定,真实系统运行期间维护成本较高;
2)难以有效识别训练数据集以外的新型攻击方式。而无监督学习的模型后期使用过程中不依赖数据标签,能够发现训练数据集以外的异常数据,应用前景更为广泛。很多研究人员在无监督学习异常检测领域中进行了广泛研究,比如深度聚类网[1](Deep Clustering Network,DCN)、改进型K-means[2-3]算法等,文献[4]提出了深度自编码高斯混合模型DAGMM(Deep Autoencoding Gaussian Mixture Model),在公共基准数据集上表现卓越。本文将PCA(Principal Component Analysis)特征选择算法和深度自编码高斯混合模型相结合,提出了一种新的无监督异常数据检测方法,该方法先通过特征选择算法去除原始训练集中的冗余特征,提升训练效率,然后将特征选择后的数据集输入深度自编码高斯混合模型进行训练,从而进行异常检测。
本文的创新点如下:
1)通过将PCA特征选择算法应用到网络流量异常检测领域,使整个系统在不需要对数据进行标定的前提下,有效提高模型训练效率,解决了面对海量数据标定困难的问题。
2)通过将PCA特征选择算法和深度自编码高斯混合模型相结合,提出了PCA-DAGMM检测方法,F1指数在kddcup99数据集和CIC-IDS-2017数据集上比DAGMM模型分别提高了4.37%和1.06%,训练时间减少了14.43%和8%,从一定程度上缓解了“维度灾难”问题。
1 相关工作
1.1 特征选择
特征选择可以理解为一种在原特征集合上搜索最优特征子集的方式,主要用于数据预处理。通过从原特征集合中筛选得到最优特征子集,要求特征子集在满足异常检测、目标识别等任务的前提下尽可能精简,且不能降低模型的预测精度,甚至在一定程度上提升预测精度。本文采用PCA算法进行特征选择。
1.2 无监督异常检测
基于有监督学习模型在训练过程中需要大量提前标记的数据,在大数据时代,这样的工作量是让人难以接受的,因此无监督学习算法成为了当前主流的研究方向。现有的无监督异常检测[5-7]大致包括:主成分分析(PCA)、核PCA[8]、鲁棒的PCA、自编码器等基于样本重构的方法;高斯分布、多维高斯模型、混合高斯模型等基于概率密度估计的方法;一类支持向量机(One Class SVM)和支持向量数据描述(SVDD)等基于支撑域的方法。由于基于重构和基于支撑域的方法在处理高维度数据时性能会受到影响,文献[4]将自动编码器和高斯混合模型联动训练,解决了检测过程中存在的局部最优问题。文献[9]基于DAGMM提出了RF-DAGMM方法,不仅提高了模型训练效率,而且在准确率、精确率和召回率等多个指标上均有所提升,但由于随机森林属于有监督的机器学习算法,使得RF-DAGMM算法仍然需要对部分数据进行标定,无法完全满足无监督异常数据检测的要求。
本文基于PCA特征选择算法与DAGMM模型,提出一种新的无监督异常数据检测方法(PCA-DAGMM),该方法可以有效消除数据集中存在的冗余特征,提高异常数据检测效率,且不需要提前对训练数据集标定。实验结果显示,该方法的训练效率和检测结果参数均优于DAGMM模型。
2 PCA-DAGMM异常检测方法
如图1所示,PCA-DAGMM异常检测方法由三个部分组成:特征选择网络、压缩网络和估计网络。特征选择网络可以从初始数据集中筛选出对分类贡献较大的特征子集,淘汰无关特征和冗余特征;压缩网络可以得到样本的低维表示和重构误差;估计网络主要通过高斯混合模型输出样本能量进而判别样本是否异常。
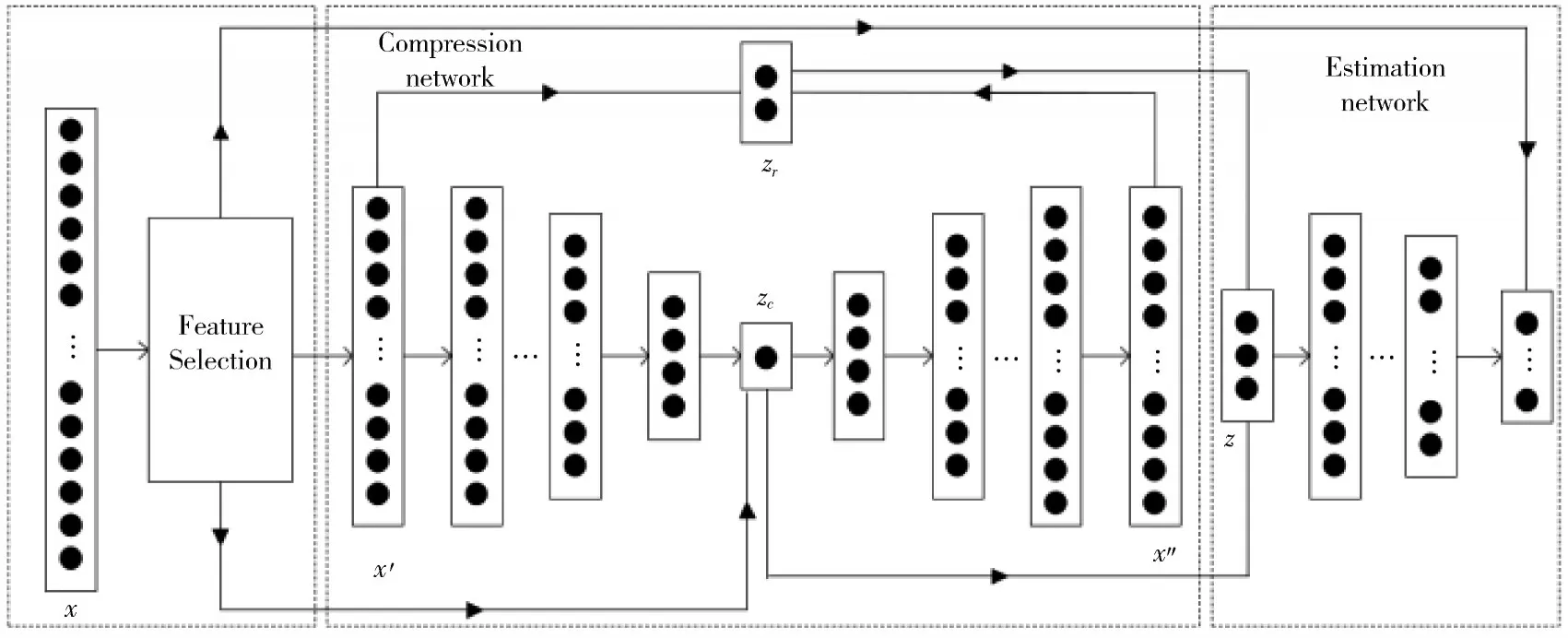
图1 PCA-DAGMM异常检测模型
2.1 PCA特征选择
在进行异常检测的数据采集过程中,将采集近百余种特征,且随着后续监测行为的增加,数据样本的特征不断增多,特征空间中样本点的分布变得愈加稀疏,进而导致“维度灾难”和样本密度稀疏等问题。一般来说,不同数据样本之间的差异往往由部分关键特征所决定,如果能够通过给每个特征赋予不同权重,消除冗余特征和无关特征,保留关键特征,将对建立合理的异常检测模型或缩短模型训练时间起到积极的作用。
PCA特征选择的本质是一组可能存在相关性变量向一组线性不相关变量的正交坐标系转换,本文通过PCA特征选择算法计算各特征在分类过程中的贡献率,并根据贡献率大小去除冗余特征和无关特征[10]。根据归一化后的数据集求协方差矩阵R:
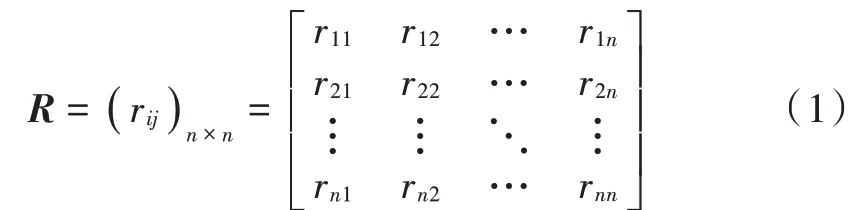
计算可得矩阵R的特征值λ1≥λ2≥…≥λn≥0,各特征值所对应的特征向量为u1,u2,…,un,其中uj=(u1j,u2j,…,unj)T是第j个特征向量的第n个分量。由特征向量组成方程组如下:
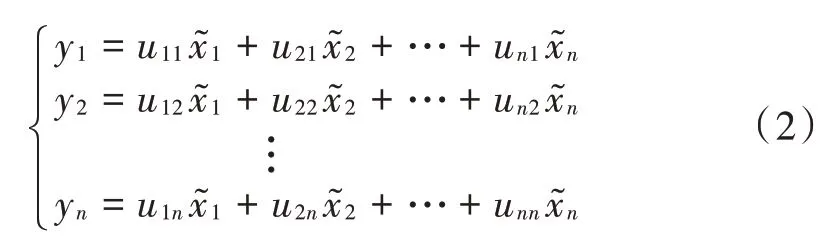
式中:y1,y2,…,yn分别为第1主成分、第2主成分、…、第n主成分。
主成分yi对应的贡献率为bj(j=1,2,…,n),累计贡献率为αp,通常情况下,特征的贡献率越大,其对分类的作用越明显。
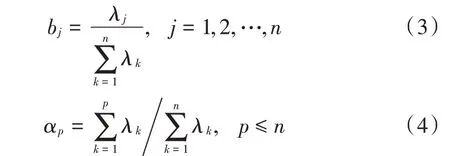
2.2 压缩网络
如图2所示,压缩网络由一个深度自动编码器构成,样本x′经过编码器降维后得到低维样本zc,zc再经过解码器重构得到重构样本x″。
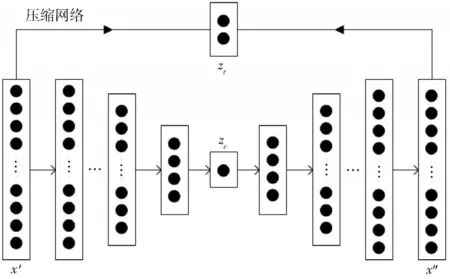
图2 压缩网络
压缩网络的输出z包含两个特征源:低维样本zc;x′与x″之间的重构误差zr。
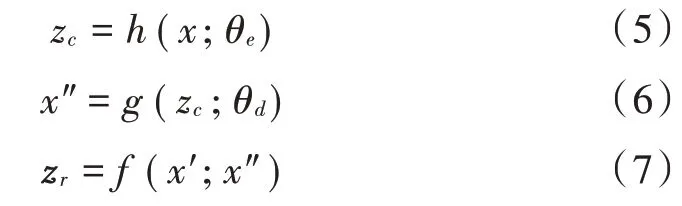

式中zr为二维特征,分别为余弦相似度和欧氏距离。
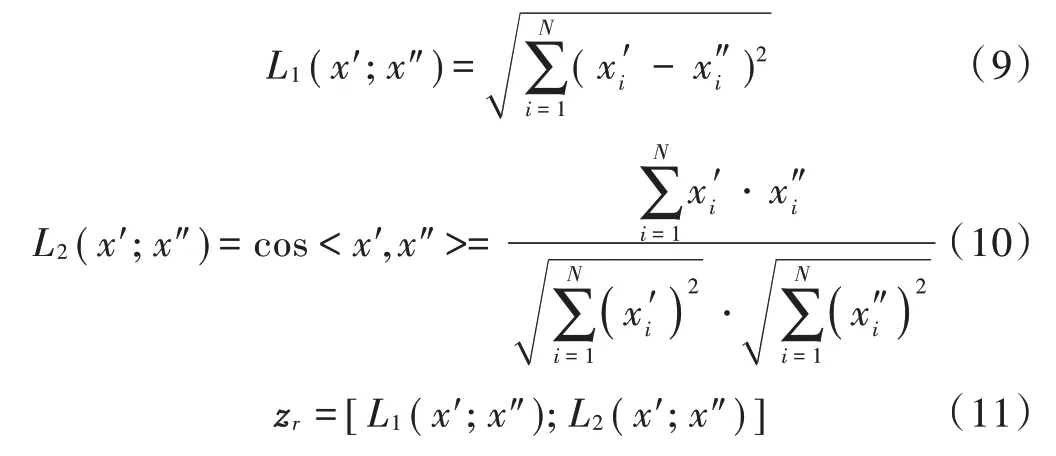
2.3 估计网络
估计网络为高斯混合模型(GMM)通过利用多层神经网络预测每个样本的混合隶属度进行密度估计,是一种聚类算法[11]。P=MLN(z;θm)是以θm为参数的多层神经网络的输出,γ̑=softmax(p)是一个K维度向量。
给定N个数据样本,1≤∀k≤K,GMM中的参数如下:
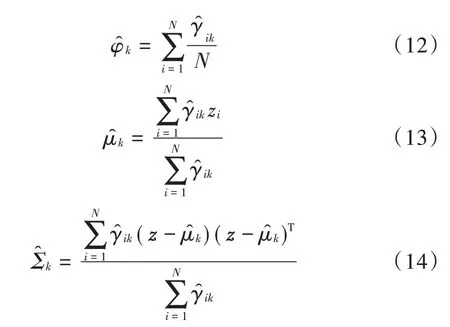
利用以上参数,可以通过以下公式计算样本能量,样本能量越低表示样本越正常,可通过预先选择的阈值将高能样本判定为异常。
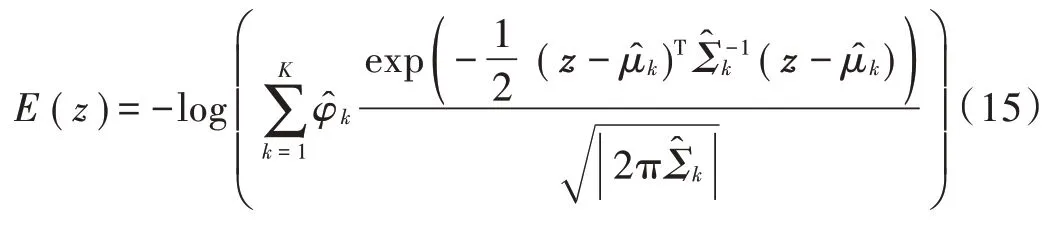
2.4 目标函数
给定N个数据样本,引导DAGMM训练的目标函数[12]构造如下:
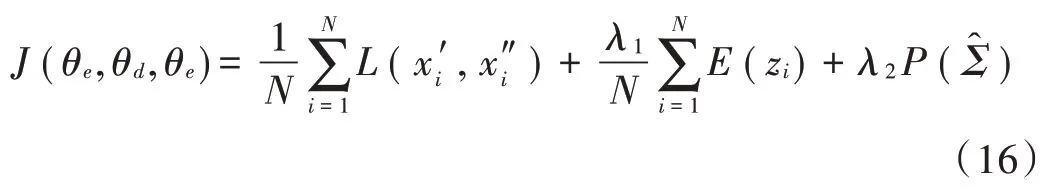
目标函数包括三个部分:L(x′i,x″i)为深度自动编码器在编码和解码过程中引起的重构误差;E(zi)为高斯混合模型输出的样本能量;P()为一个极小值,此部分主要用于防止在高斯混合模型中,协方差矩阵的对角线上的值变为0并最终导致矩阵不可逆。
2.5 自适应判断阈值
假设有N条样本,异常样本在所有样本中所占的比例为ρ,通过PCA-DAGMM计算出每个样本的能量数值,然后将所有样本按照能量数值降序排列,则用于异常检测的阈值T为所有样本中由高到低第ρ×N处样本的能量数值。
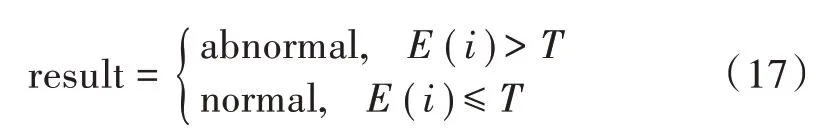
3 实验与分析
本节对本文涉及的异常数据检测方法进行实验和分析,分别在kddcup99数据集和CIC-IDS-2017数据集上进行实验。
3.1 数据预处理
数据预处理分为两个部分:One-Hot编码和Min-Max归一化。
3.1.1 IDS数据集
本节分别介绍本文使用的两种网络流量数据集kddcup99和CIC-IDS-2017。kddcup99数据集包含正常数据972 781条,异常数据3 925 650条,其中异常类型包括DoS、R2L、U2R和Probe,虽然kddcup99数据集发布于1999年,但依旧是网络异常数据检测领域的基准数据[13]。CIC-IDS-2017数据集包含正常数据和最新的常见攻击,包括DoS、DDoS、Web攻击和渗透攻击等[14],可以较好地模拟真实世界数据。
3.1.2 数据集重组
kddcup99数据集的训练集和测试集均在service特征中存在缺少项,为了方便后续数据处理,对数据集进行重组。表1显示了kddcup99数据集重组后的分布。
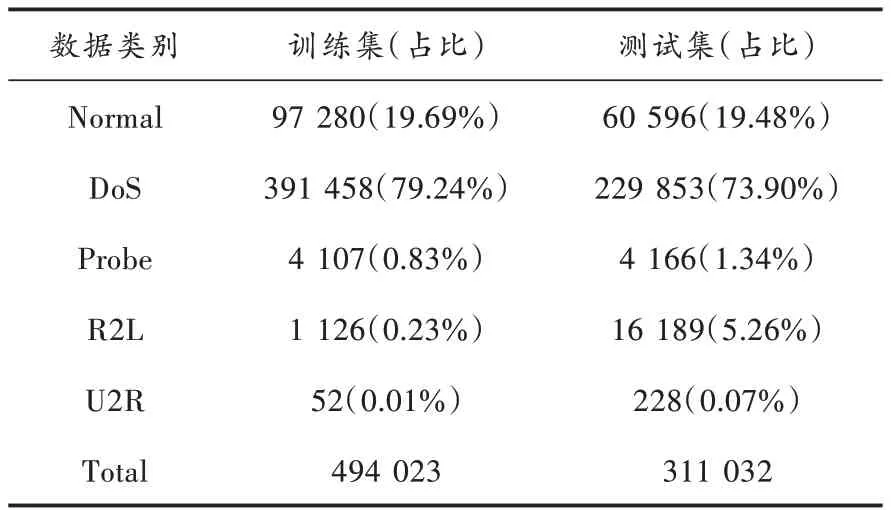
表1 kddcup99重组数据
CIC-IDS-2017原数据集存在部分攻击数据数量较少、分布不均衡的问题,不利于后续神经网络的训练,针对此问题,对CIC-IDS-2017数据集进行重组,表2显示了数据集重组后的分布。
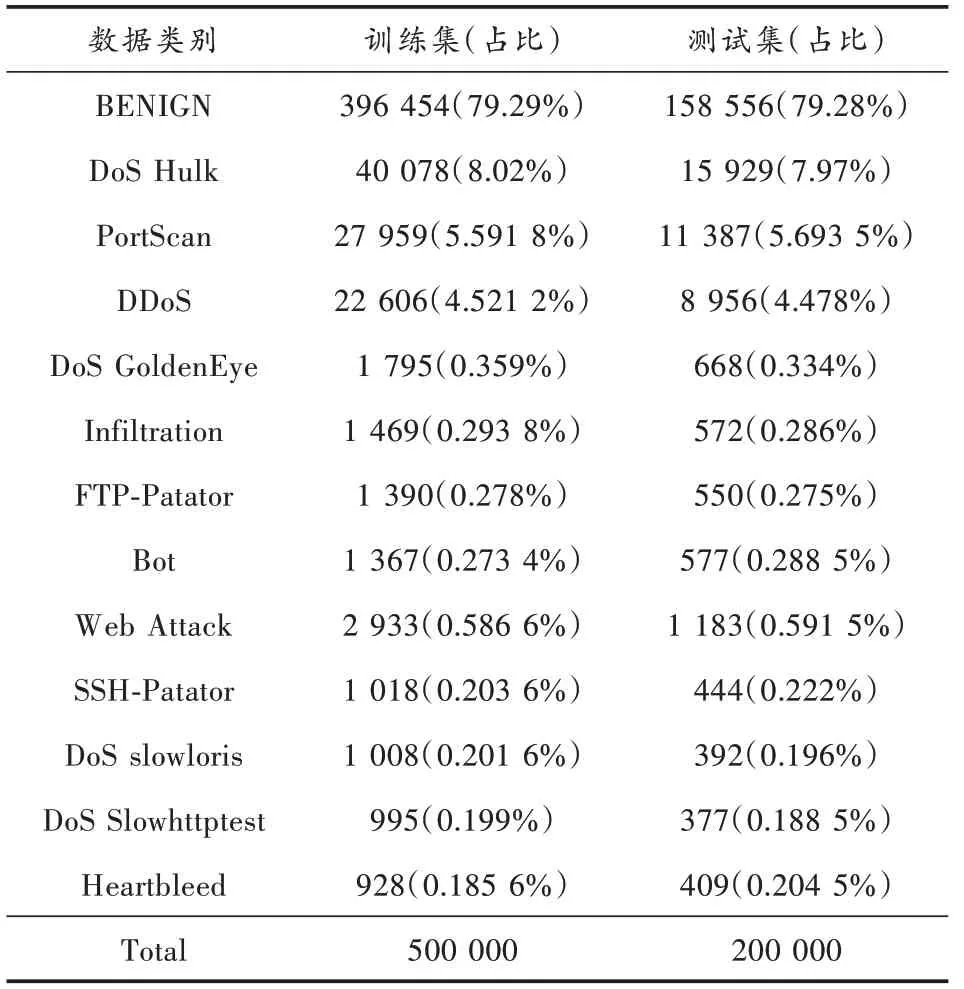
表2 CIC-IDS-2017重组数据
3.1.3 符号特征one-hot编码
one-hot编码可以将数据集中的符号特征量化处理为数值特征,同时各个特征取值彼此独立且距离相等。kddcup99数 据 集 中 包 含3个 符 号 特 征:service、flag和protocol_type。根据one-hot编码理论,若符号特征拥有n个选项自由度,可将其拓展为n维特征。例如,service特征有70个选项,即可扩展为70维。以此类推,kddcup99数据集可由原来的41维拓展为122维,在实际操作中,由于数据集中的service特征存在缺少项,onehot编码后特征数为119。CIC-IDS-2017数据集中无符号特征,无需进行one-hot编码。
3.1.4 数值特征归一化处理
数据集中,有的特征取值范围在0~1×109之间,有的取值范围在0~1之间,特征之间存在较大的数量级差异,为了消除这种差异,本文采用Min-Max算法对数值特征进行归一化处理。Min-Max算法公式如式(18)所示:

式中:x为输入样本的取值;xmin为样本取值范围的最小值;xmax为样本取值范围的最大值。
3.2 模型配置
本节根据特征选择算法筛选的特征数量进行模型配置,表3显示了压缩网络中编码器的结构配置情况,解码器结构与编码器对称(注:由于各个特征选择算法对特征权重的评判标准不同,各个特征选择算法针对不同的数据集会产生不同的最优子集,本文最终进行比较的数据均来自各个特征选择算法匹配数据集产生的最优子集)。
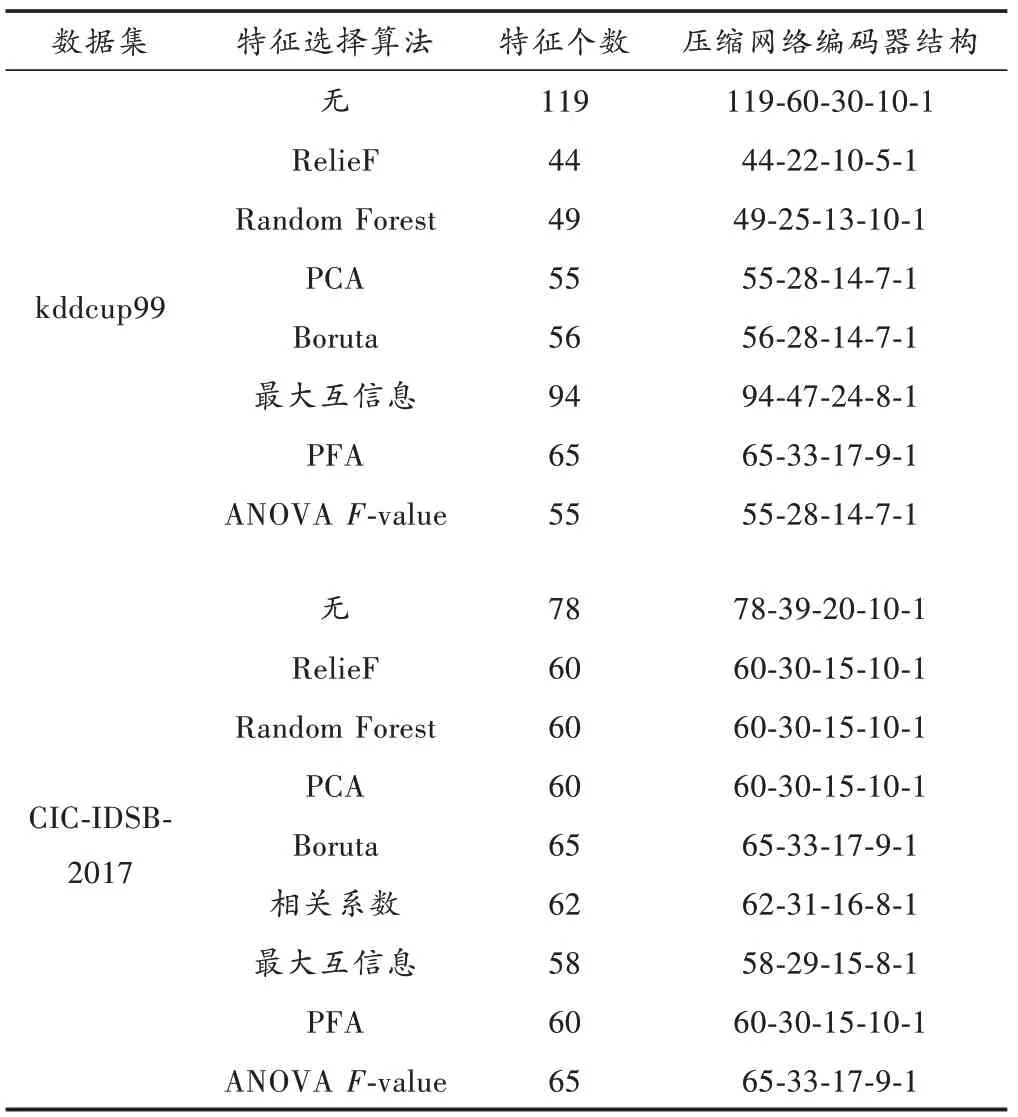
表3 编码器结构配置
激活函数为tanh,估计网络的结构为FC(3,10,tanh)-Dropout(0.5)-FC(10,2,softmax),用于惩罚协方差矩阵对角项上的小值取1×10-12。
3.3 实验结果
基于上述模型配置进行实验,对不同的特征选择算法分别进行15次测试取平均值作为结果。
表4中结果表明,在基于kddcup99数据集的实验中,Boruta算法和PFA算法表现较好;在基于CIC-IDS-2017数据集的实验中,RelieF算法、最大互信息算法和相关系数特征选择算法表现较好,算法表现的差异可能来自处理后的数据集稀疏程度的不同(kddcup99数据集经one-hot编码后会更稀疏)。其中PCA在两个数据集中均表现优异,PCA-DAGMM方法在kddcup99数据集和CIC-IDS-2017数据集基础上,F1指数比DAGMM模型分别提高了4.37%和1.06%,训练时间减少了14.43%和8%,以上数据充分证明了本文提出的方法在网络异常流量检测方面能够有效提高模型性能和训练效率。
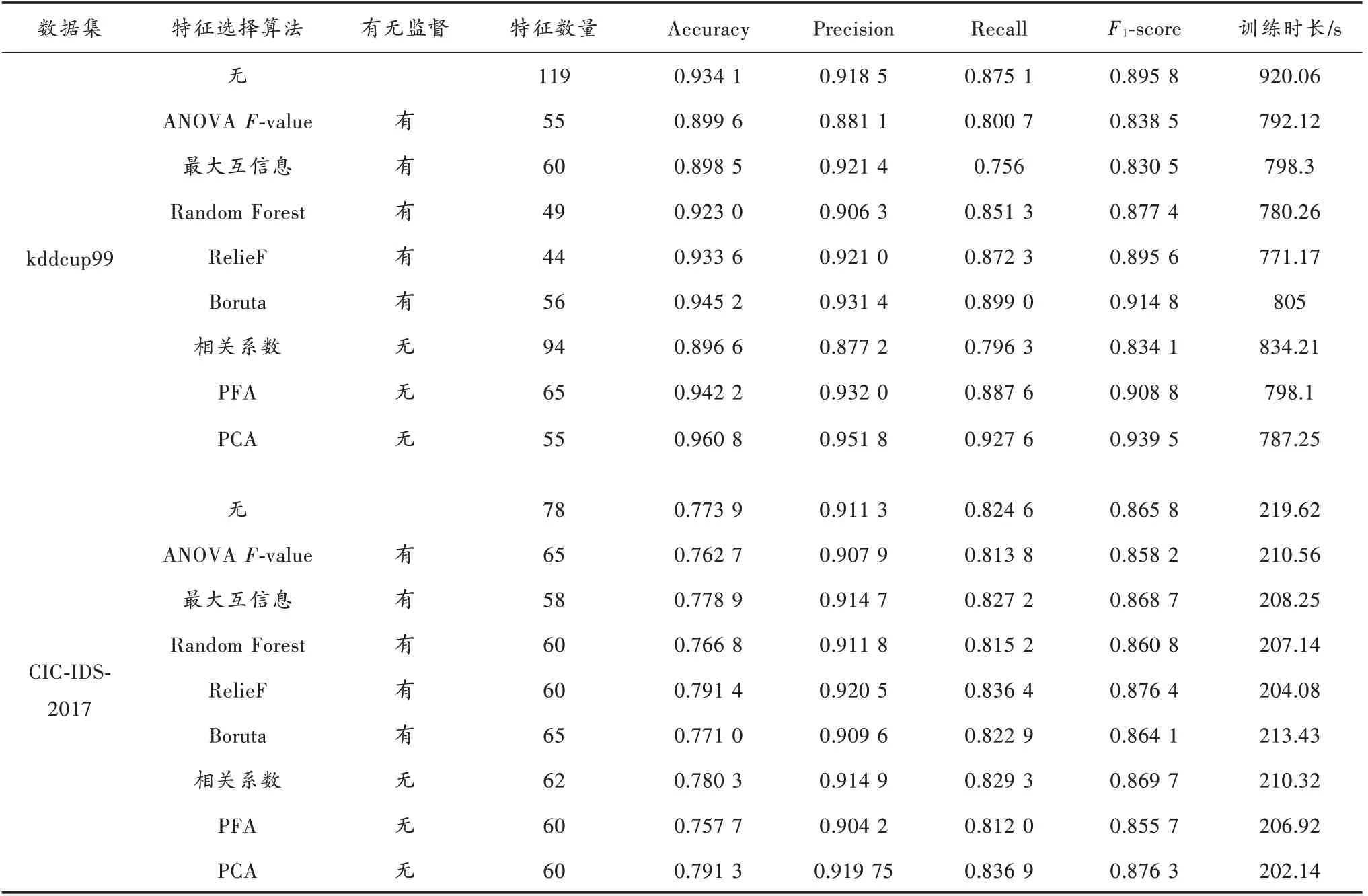
表4 实验结果
4 结语
本文提出新的无监督异常数据检测方法PCADAGMM,基于kddcup99数据集和CIC-IDS-2017数据集的实验结果表明,新模型通过PCA特征选择算法实现数据降维,保留有效特征,摒除冗余特征和无关特征,有效提升了训练效率。PCA-DAGMM方法在不降低分类器性能的前提下,无需对数据集标定,能够有效提高分类器训练效率,且准确率、精确率、召回率和F1指数均优于DAGMM模型及DAGMM与其他特征选择算法联合训练的结果,为高维度网络数据异常检测提供了新的思路。
