基于半监督学习-多通道卷积神经网络的加氢裂化产品性质预测
2023-02-02罗文山陆鹏飞李保良曹晓红
王 晨, 罗文山, 陆鹏飞, 李保良, 曹晓红, 杨 纪
(中海油 惠州石化有限公司,广东 惠州 516086)
加氢裂化工艺是在高温、高压和催化剂存在下,使重油发生裂化反应,转化为气体、汽油、柴油等的石油二次加工过程,与其他加工工艺相比,其具有液体产品收率高、饱和度高等特点[1]。加氢裂化作为炼油厂重要的二次加工工艺可加工从石脑油到渣油范围的油品,并提供优质高辛烷值汽油、中间馏分油或化工料,通过灵活调节进料与产品方案在企业降本增效中发挥着巨大作用[2]。同时加氢裂化也是满足日益严格的油品清洁标准的最有力手段,因此对加氢裂化产品性质进行实时预测具有重要意义[3-4]。
然而对加氢装置全部升级安装在线分析仪成本高,且仪器需定期校准维护,导致推广实施受限。随着炼油化工企业信息化水平不断提高、数字化转型不断深入,炼油化工企业已逐渐积累大量生产数据,通过数据驱动的机器学习等人工智能(AI)算法对生产大数据进行挖掘建模,实现生产过程故障诊断、关键参数预警、产品性质预测等智能化应用,已逐渐成为目前流程工业界在智能控制优化领域的研究、应用热点[5-7]。机器学习,尤其以卷积神经网络(Convolutional neural network, CNN)为代表的深度学习技术通过逐层特征学习,由低级到高级自动提取与预测任务相关联的潜在表示,已在计算机视觉(Computer vision, CV)、自然语言处理(Natural language processing, NLP)等领域获得巨大成功[8-10]。
近几年得益于深度学习理论、开源框架、GPU等加速计算硬件的不断突破创新,利用深度学习等先进AI算法对炼油化工装置数据的潜在结构、分布特征进行自动学习和逐层特征提取,从而最终实现KPI预测等相关智能应用的研究日益深入。杨帆等[11]综述了神经网络在催化裂化过程模型的构建与分析,并探讨了神经网络与智能优化算法结合方面的优势。李诏阳等[12]基于Aspen HYSYS软件建立了润滑油加氢装置机理模型,并基于机理模型扩展了装置运行数据集,在扩展数据集构建了长短时记忆网路(LSTM),对润滑油产品运动黏度、闪点等性质实现了准确预测。田水苗等[13]基于Aspen HYSYS机理模型扩充而来的蜡油加氢裂化数据集,构建了BPNN用于精制蜡油流量、性质等预测,并通过多目标优化给出了最佳操作工况参数。在堆叠式自编码(Stacked auto-encoder, SAE)应用方面,Yuan等[14]基于SAE对加氢裂化航空煤油产品10%和50%体积沸点进行预测,并结合线性插值通过对SAE逐层预训练实现了小样本学习任务的数据增强(Data augment, DA),所提出的逐层数据增强-堆叠编码器(Layer-wise data augment-SAE, LWDA-SAE)有效提升了模型预测性能。Wang等[15]基于SAE开发了一种有监督堆叠式自编码器(Supervised stacked auto-encoder, SSAE),克服了SAE无监督预训练阶段欠缺提取与目标变量相关特征信息的不足,并在加氢裂化装置工艺参数波动诊断中验证了其有效性。CNN在流程工业建模中表现出良好的局部特征学习能力,Wu等[16]基于朴素CNN算法对田纳西伊斯曼化工过程进行了仿真验证;Zhu等[17]构建了滑动窗卷积网络(Moved-window convolutional neural network, MWCNN),通过等宽滑动窗卷积操作学习乙烯裂解过程时域和空间域特征信息,并最终实现乙烯裂解产物气相组分含量预测。考虑到影响加氢产品质量的因素贯穿从进料、反应、分离到分馏整个工艺流程,任一流程环节波动均会影响产品质量,且加氢裂化工艺流程复杂,工况多变,炼化机理和理化性质使得整个工艺过程呈高维、大时滞、非线性等特点[18-19],使得应用深度学习算法实现加氢裂化产品性质预测仍面临诸多挑战。首先在多维度特征学习方面,单纯应用CNN、LSTM等难以同时对加氢裂化工艺流程的时域和空间域特征进行多维度特征抽取,而在样本尺度方面,受限于大部分加氢产品性质的人工化验数据量不足,化验数据不能与装置DCS实时数据在时间维度对齐,大大降低了装置实时数据的利用率,所导致的小样本学习问题将显著影响深度学习模型性能[ 20-21]。
针对上述时空域多维特征抽取问题,提出了将多通道卷积神经网络(Multi-channel convolutional neural network, MCCNN)用于加氢裂化装置建模,通过对历史生产数据的多通道时序采样实现加氢裂化流程的时序特征学习,通过CNN实现加氢裂化流程的空间域特征学习。针对小样本学习问题,提出了基于教师-学生半监督学习(TS-SSL)算法创建虚拟性质数据,并与装置DCS实时数据对齐,从而实现样本数据扩充,最终提出半监督学习-多通道卷积神经网络(SSL-MCCNN),进一步提升对加氢裂化产品性质预测性能。以某煤油-柴油加氢裂化工业装置为研究对象,对装置产品的重石脑油密度、柴油闭口闪点进行预测,结果与BPNN、径向基神经网络RBFNN对比,验证了所提出SSL-MCCNN算法的优越性。
1 MCCNN算法
1.1 CNN与加氢裂化数据维度重塑
Lecun等[22]提出的LeNet5是CNN算法最早用于手写数字识别的研究,LeNet5结构如图1所示。输入为32×32的手写图片依次通过卷积层(Convolutions)、下采样层(Subsampling)和全连接层(Full connection),最终输出预测分类结果。其中C1卷积层包含6个卷积核,用于卷积计算提取图片像素间的局部特征信息,得到6个输出特征图;下采样层用于对输出特征图的降维,进一步提取关键特征表示;最后的全连接层与传统BP网络相同,用于之前卷积结果的一维重塑并输出最终预测结果。
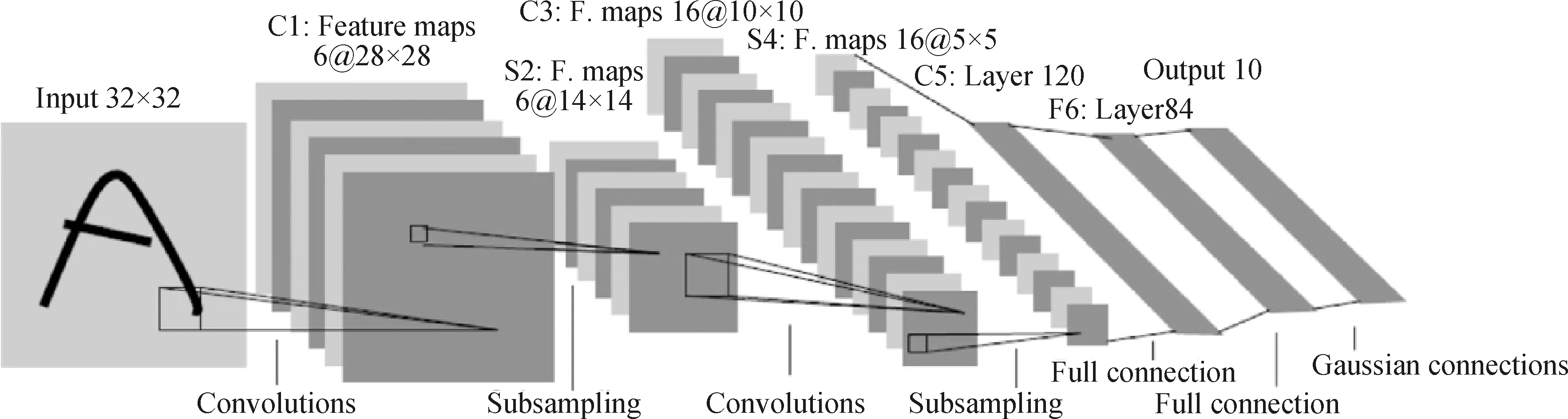
图1 LeNet5模型结构图Fig.1 Structure chart of LeNet5 model
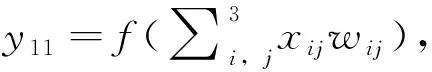

图2 典型卷积操作示意图Fig.2 Typical convolution operation diagram
某炼油厂煤油-柴油加氢裂化装置工艺流程如图3所示。考虑到加氢裂化不同工艺流程部位的参数存在复杂机理关系,提出了应用CNN算法逐层提取这些隐含在空间域的关系信息,所提取的信息作为最终预测任务的输入表示。为满足图2所示输入数据的二维矩阵格式,首先对加氢裂化样本数据进行二维重塑,如图4所示。以煤油-柴油加氢裂化装置为研究对象,按照加氢裂化装置从进料、预热、反应、分离、分馏整个流程全面选取126个主要工艺参数,并根据局部工艺子流程顺序按行排列,其中每1行表示1个加氢裂化局部子流程,最终将126维向量数据重塑为9×14二维矩阵作为SSL-MCCNN的输入。
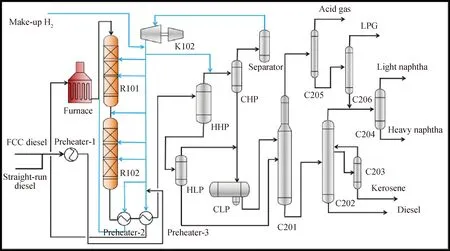
C201—H2S stripper; C202—Main fractionator; C203—Side stripper; C204—Naphtha fractionator; C205—Adsorption-desorption tower; C206—Debutanizer; CHP—Cold high pressure separator; CLP—Cold low pressure separator; HHP—Hot high pressure separator; HLP—Hot low pressure separator; K102—Recycled gas compressor; R101—Hydrotreating reactor; R102—Hydrocreacking reactor图3 煤油-柴油加氢裂化工艺原则流程图Fig.3 Flowchart of kerosene-diesel hydrocracking process

D201—Condensation tank of C201; D202—Condensation tank of C202; D203—Condensation tank of C204; D204—Condensation tank of C206; ER—Effluent rate; ET—Effluent temperature; F101—Feeding furnace; F201—Reboiler of C201; F202—Fractionation furnace; FBP—Final boiling point; FCC—Fluid catalytic cracking; H2/Oil—Volume ratio of hydrogen to oil; IBP—Initial boiling point; K102—Recycle gas compressor; LPG—Liquefied petroleum gas; P—Pressure; delta P—Pressure difference; T—Temperature; WABT—Weighted average bed temperature图4 加氢裂化样本数据维度重塑Fig.4 Dimension remodeling of hydrocracking data sample
1.2 基于多通道采样的CNN算法(MCCNN)
考虑传统CNN算法常用于图像识别、目标定位等空间像素特征提取,首先基于CNN算法特点实现了加氢裂化工艺流程空间域的局部特征提取,而研究表明时域特征对流程工业特征学习依然至关重要[24-25]。炼化生产属典型流程工业,数据样本的产生具有时间连续性特点,一段时间内的装置数据样本蕴含了加氢裂化流程中包括进料、反应、分馏等各工艺段的运行、变化趋势等时序特征信息,对预测未来时间点的产品性质具有重要意义。以长短时记忆网络(Long shot-term memory, LSTM)为代表的RNN类神经网络等时序建模研究,广泛应用于炼油化工装置的时序特征提取[26-27],然而受限于RNN处理复杂工艺流程序列数据时的“梯度消失”、“梯度爆炸”等问题[28],随着序列数据增长,单纯RNN类模型性能发生退化;另一方面,作为序列到序列的建模范式,LSTM等RNN算法因不适于并行加速而导致训练与推理时间成本的增加,已逐渐被注意力模型取代[29]。
考虑CNN算法对RGB 3通道彩色图像的学习特点[30],提出了如图5所示的多通道采样算法,用于加氢裂化装置生产数据样本获取。基于图4所述单个时间点的二维矩阵数据样本,通过增加时间维度方向的采样,以固定采样频率(例如15 min)实施装置历史数据采集,并在时间维度上叠加多个时间点样本,整体得到1个3D样本作为CNN算法的多通道输入,用于多维度描述加氢裂化装置生产工况,最终实现提取装置空间域和时域潜在特征信息,提高模型对产品性质的预测性能。
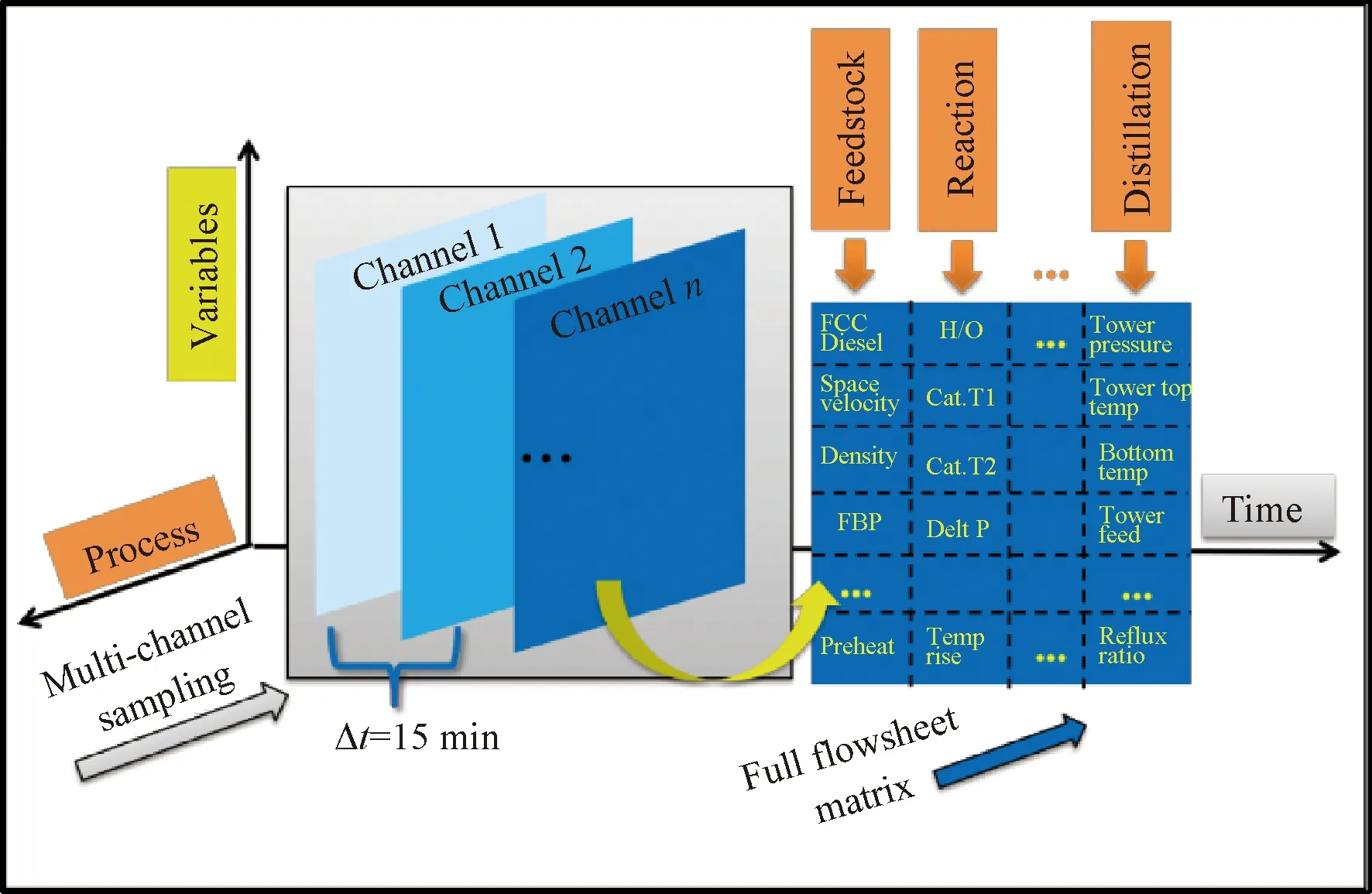
图5 多通道采样示意图Fig.5 Schematic diagram of multi-channel sampling
1.3 MCCNN算法流程框架
根据上述CNN算法用于加氢裂化工艺流程建模方案的描述,结合多通道采样方案,MCCNN算法整体流程如图6所示。经过二维重塑的多通道3D样本数据输入到卷积层,根据预测目标自适应提取工艺流程潜在特征信息,例如对航空煤油性质进行预测,模型自动提取航空煤油分馏塔特征信息;对重石脑油终馏点(FBP)预测,则模型自动提取加氢裂化反应器和石脑油分馏塔特征信息。经卷积计算所提取的特征信息通过全连接层的非线性转换,最终实现对加氢产品各项性质的回归预测。

Conv—Convolutional; FC—Full connected; HN—Heavy naphtha; Kero—Kerosene图6 MCCNN算法流程图Fig.6 Flowchart of MCCNN algorithm
MCCNN模型训练和推理流程如图7所示,分为离线训练和在线推理预测2个阶段。

图7 基于MCCNN产品性质预测流程框架Fig.7 Framework of product properties predicted based on MCCNN
离线训练阶段:
Step1:装置历史数据采集;
Step2:样本数据多通道采样;
Step3:样本数据归一化;
Step4:多通道样本数据二维矩阵重塑;
Step5:样本数据集分割为训练集、测试集;
Step6:模型训练,验证结果满足RMSE指标则部署模型,否则回到Step5。
在线推理预测阶段:
Step1:实时数据读入;
Step2:实时数据多通道采样;
Step3:实时数据归一化;
Step4:多通道实时数据二维矩阵重塑;
Step5:MCCNN模型推理预测,获得产品性质预测结果。
2 加氢裂化产品性质预测
2.1 样本数据集构建与模型参数配置
基于2019年6月—2021年9月煤油-柴油加氢裂化装置历史数据,以重石脑油密度、柴油闭口闪点作为预测目标,选取126个工艺参数基于MCCNN全流程建模。样本数据的时序采样采用多通道采样算法(见图5),考虑加氢裂化装置从进料到馏出产品整个工艺流程耗时约30 min,因此选取3个相互间隔15 min的时间点即可对从进料到产品整个工艺流程时序的覆盖。3D采样频率为3 h,每个3D样本的时序通道间隔15 min,每3个时序通道作为1个3D样本并以最后1个时序通道对应的产品性质作为3D样本的标签,如图8所示为时钟6∶00、9∶00、12∶00共3个3D样本。总共获取包含LIMS化验性质标签数据共1552组,按照比例7∶1∶2分割为训练集、验证集和测试集,整个数据集在各工艺流程段的分布如表1所示。

表1 煤油-柴油加氢裂化装置数据集分布Table 1 Distribution of kerosene-diesel hydrocracking unit data set
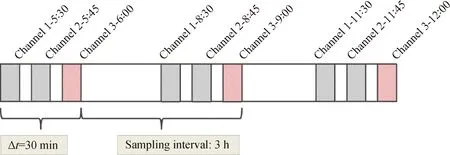
图8 历史数据多通道时序采样示意图Fig.8 Schematic diagram of multi-channel temporal sampling for historical data
根据图6,MCCNN算法包括卷积层、全连接层,考虑煤油-柴油加氢全流程样本矩阵为9×14,尺寸不大,故不采用池化层降维,模型训练优化器(Optimizer)采用Adam[31],设定学习率(Learning rate)为0.001,基于Tensorflow深度学习框架[32]经试错法(Trial-and-error)得到含有3个卷积模块(Conv)和3层全连接网络(FC)的网络模型结构,如表2所示。3通道矩阵样本经归一化预处理后送入含有64个卷积核的第一卷积层(Conv_1(64))进行初步特征提取,然后经批归一化(Batch normalization, BN)和ReLU激活函数(Activation function, AF),对第一次卷积结果进行中心归一化和非线性转化,从而完成第1个卷积模块操作,样本数据完成3个Conv模块的表示学习后,将特征提取结果依次送入3层FC(64,128,1)网络,完成最终预测。考虑重石脑油密度和柴油闪点均为实值类回归预测任务,故模型在训练过程中的度量指标(Metrics)采用均方误差(Mean square error, MSE);模型测试评估指标采用RMSE和判定系数R2,分别见式(1)和式(2)。

表2 MCCNN模型参数配置Table 2 Parameter configuration of MCCNN model
(1)
(2)
式中:N为样本数据容量;Yobs,i为标签变量(此处指加氢裂化产品性质)真实值;Ymodel,i为标签变量预测值;Ymean为标签样本平均值。RMSE为预测值与真实值之间的均方根误差,RMSE值越小,则模型越精确,量纲与标签变量相同。R2指MCCNN模型自适应学习到的特征信息对标签变量整体变化方差的解释程度,表征模型学习到的特征信息用于预测产品性质的合理程度,R2值越大,模型越合理[33]。
2.2 重石脑油密度预测
基于MCCNN模型对重石脑油产品密度预测值(Predicted values, PVs)、真实值(Actual values, AVs)及绝对误差(Absolute error, AE)如图9(a)所示,CNN、BPNN、RBFNN对比模型预测结果如图9(b)、(c)、(d)所示。CNN算法对加氢裂化全流程参数空间域的局部潜在关系和特征知识进行自适应特征提取,深入学习到了加氢裂化反应深度、石脑油分馏过程等关于预测重石脑油密度对应的特征表示,RMSE和R2分别为1.61和0.62,性能显著优于BPNN和RBFNN。MCCNN模型基于CNN算法在提取加氢裂化流程空间域特征基础上,通过多通道采样增加了对加氢裂化动态时域特征的学习提取,使得RMSE和R2分别达到1.30和0.75,性能最优。
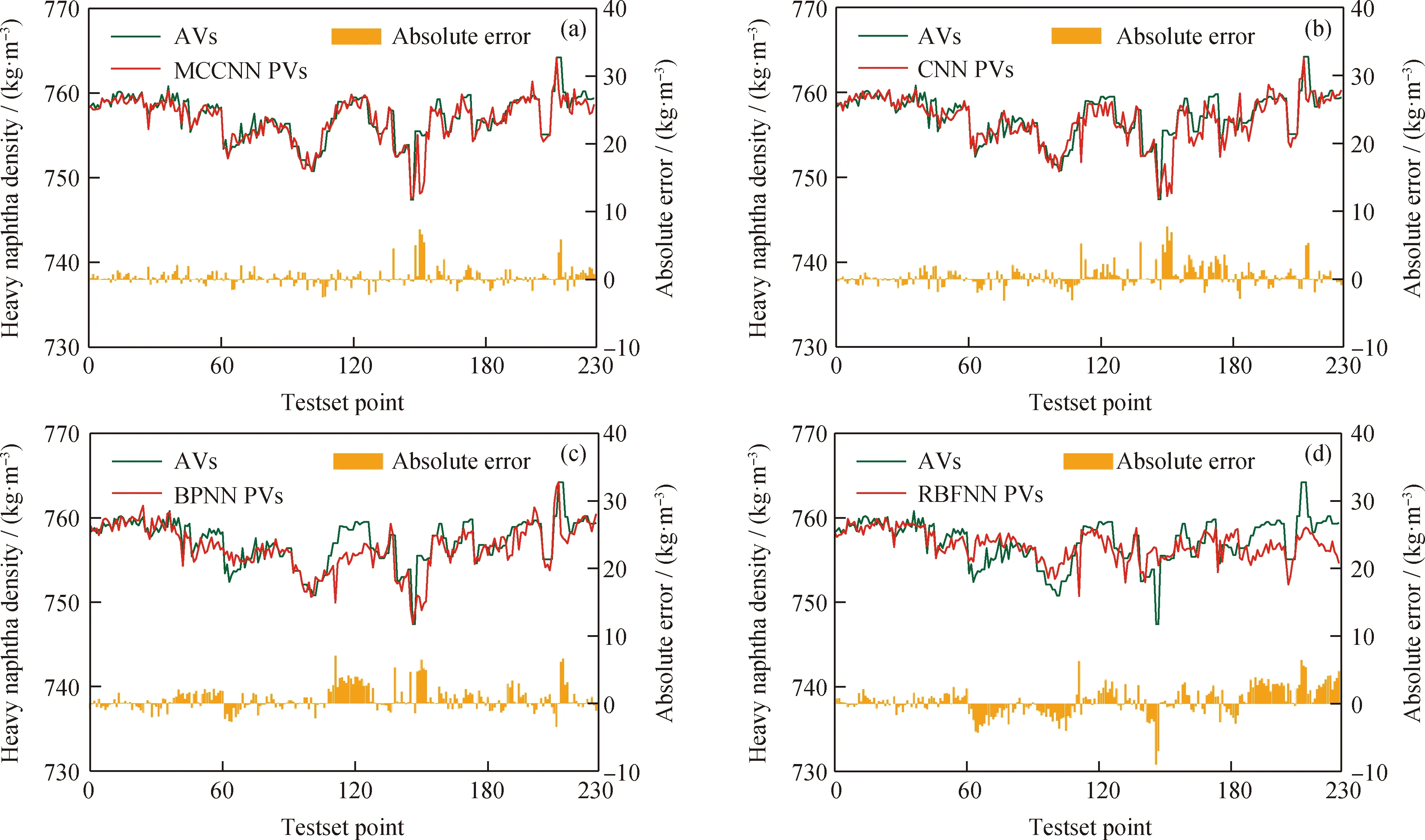
AVs—Actual values; PVs—Predicted values图9 不同模型预测的重石脑油密度(20 ℃)对比Fig.9 Comparison of heavy naphtha density (20 ℃) predicted by different models(a) MCCNN: RMSE=1.30, R2=0.75; (b) CNN: RMSE=1.61, R2=0.62; (c) BPNN: RMSE=1.83, R2=0.51; (d) RBFNN: RMSE=2.11, R2=0.34
2.3 柴油闪点预测
MCCNN模型对柴油产品闪点预测结果如图10(a)所示,CNN、BPNN、RBFNN对比模型预测结果如图10(b)、(c)、(d)所示。与对重石脑油密度预测原理相同,CNN算法对加氢裂化全流程参数空间域的局部潜在关系和特征知识进行自适应特征提取,深入学习到了加氢裂化反应深度、主分馏过程等关于预测柴油产品闪点对应的特征表示,RMSE和R2分别为2.20和0.91,性能显著优于BPNN和RBFNN。MCCNN模型基于CNN空间域特征提取基础上,通过多通道采样增加了对加氢裂化动态时域特征的学习提取,RMSE和R2分别为1.70和0.94,性能达到最优。

AVs—Actual values; PVs—Predicted values图10 不同模型预测的柴油闪点对比Fig.10 Comparison of diesel flash point predicted by different models(a) MCCNN: RMSE=1.70, R2=0.94; (b) CNN: RMSE=2.20, R2=0.91; (c) BPNN: RMSE=2.69, R2=0.86; (d) RBFNN: RMSE=3.18, R2=0.81
3 TS-SSL实现MCCNN性能提升
3.1 TS-SSL算法及SSL-MCCNN算法
目前大部分加氢裂化装置产品性质为人工化验分析,产品性质数据作为MCCNN模型训练的样本标签,数量远小于装置生产运行的DCS数据,因此基于装置历史数据训练MCCNN模型实现对产品性质预测属典型小样本学习问题。相关研究表明,基于SSL算法生成虚拟样本集,可有效解决模型有监督训练标签不足的问题,从而提升模型性能[34-35]。SSL用于应对小样本学习问题原理如图11所示。随着每一轮半监督训练产生新的虚拟样本集,使得总样本集的分布逐渐接近整体分布,从而提升分类超平面精确度。

图11 SSL提升小样本学习性能示意图Fig.11 Schematic diagram of improving the learning performance of small samples by SSL
在流程工业小样本学习建模研究中,Yuan等[36]通过半监督堆叠自编码器(Semi-supervised stacked auto-encoder, SS-SAE)在半监督训练阶段实现了流程工业无标签数据和有标签数据的合理利用,并在脱丁烷塔和加氢裂化过程建模中验证了算法的有效性。Zhu等[21]基于局部线性嵌入(Local linear embedding, LLE)生成虚拟样本并使用BPNN模型对虚拟样本打标,最终构建虚拟数据集,用于再次训练BPNN模型以提升性能,提出的算法有效性在对苯二甲酸纯化和聚乙烯2个工业装置得到验证。Zhang等[37]基于等距特征映射(Isometric mapping, ISOMAP)和插值算法生成虚拟样本,并使用基于有监督训练的极限学习机(Extreme learning machine, ELM)对虚拟样本打标,从而构建虚拟数据集实现ELM性能提升,该算法在对苯二甲酸纯化装置得到验证。
考虑加氢裂化装置已存在足量DCS装置运行数据而缺乏相应产品性质化验数据,提出TS-SSL用于构建虚拟标签,最终提升MCCNN模型性能,图12 为TS-SSL小样本学习算法示意图。TS-SSL算法的步骤如下:

图12 TS-SSL小样本学习算法示意图Fig.12 Schematic diagram of learning algorithm based on TS-SSL for small samples
Step1:对原始样本集(xi,yi)分层抽样,得到原始训练集(Original trainset)和原始测试集(Original testset);
Step2:基于Original trainset训练MCCNN得到教师模型(Teacher);
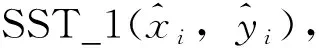
Step5:基于Original testset对Student模型评估得到RMSE1;
Step6:若RMSE1小于当前最优RMSE,则Student模型作为Teacher模型,继续Step3,否则回到Step4;
Step7:持续迭代TS-SSL过程直到满足RMSE所设定的阈值或达到设定的SSL轮数。
3.2 SSL-MCCNN用于加氢裂化产品性质预测
基于TS-SSL算法对煤油-柴油加氢裂化装置重石脑油密度预测样本数据集和柴油产品闪点预测样本数据集进行扩充,如表3所示,2个预测案例数据

表3 基于TS-SSL数据集扩充Table 3 Data set enlargement based on TS-SSL
集经4轮TS-SSL半监督学习打标,样本容量由最初1552扩充到4656,显著增大了用于MCCNN有监督训练的样本数据。
应用表3所示每轮数据集训练MCCNN并分别对重石脑油密度和柴油闪点进行预测,预测值(PVs)和实际值(AVs)如图13所示。由图13(b)、(d)可见,随着SST轮数增加,与单纯MCCNN相比,得益于训练样本扩充,SSL-MCCNN对重石脑油密度的预测结果RMSE由1.3降低为0.83,R2由0.75提升为0.90,同时对柴油闪点的预测结果RMSE由1.7降为1.03,R2由0.94提升为0.98,表明随着虚拟样本数据的增加,模型提取到了更多工况下的特征信息,在预测性能得到提升的同时,所提取特征信息的合理性也显著增强。
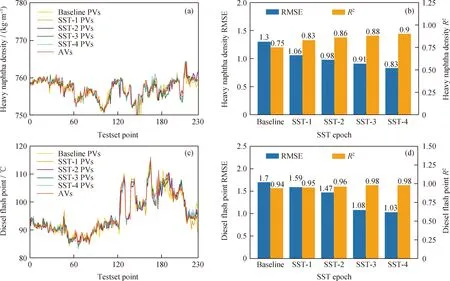
AVs—Actual values; PVs—Predicted values图13 重石脑油密度和柴油闪点的SSL-MCCNN预测对比Fig.13 Comparison of heavy naphtha density and diesel flash point predicted by SSL-MCCNN(a) Prediction result of heavy naphtha density; (b) Prediction performance of heavy naphtha density; (c) Prediction result of diesel flash point; (d) Prediction performance of diesel flash point
4 结 论
(1)根据加氢裂化工艺流程特点,提出了多通道卷积神经网络(MCCNN)算法用于全流程建模,并通过多通道二维矩阵样本采样,自适应提取加氢裂化过程与产品性质预测相关的空间域和时域特征信息,对重石脑油密度预测的RMSE和R2分别为1.30和0.75,对柴油闪点预测的RMSE和R2分别为1.70和0.94,与CNN、BPNN和RBFNN模型相比显示出优越性能。
(2)针对加氢裂化产品性质预测的小样本学习问题,提出了教师-学生半监督学习(TS-SSL)算法生成虚拟数据样本集,通过数据增强促进模型提取到丰富的特征信息,所提出的半监督学习-多通道卷积神经网络(SSL-MCCNN)对重石脑油密度预测的RMSE和R2分别为0.83和0.90,对柴油闪点预测的RMSE和R2分别为1.03和0.98,与单纯MCCNN相比,预测性能进一步得到提升。
(3)加氢裂化工艺流程复杂,不同工艺参数的相互影响横跨整个工艺流程,所提出的MCCNN算法能够提取工艺流程空间中的局部特征信息,但对于全局特征信息和核心催化剂反应特征信息的提取有待进一步研究。
