融合项目序列与微观行为的序列推荐方法
2023-01-31刘学军
费 艳,刘学军
(南京工业大学 计算机科学与技术学院,南京 211816)
1 引 言
随着大数据和互联网技术的迅速普及,推荐系统已经成为帮助人们找到自己潜在兴趣的商品的重要办法,用户在使用在线购物平台时,面对巨大的商品数量以及众多的信息时,往往容易眼花缭乱而无法抉择,推荐系统的引入,能够有效解决信息过载问题.传统的推荐系统以一种静态的方式建模用户和商品的交互并且只可以捕获用户广义的喜好,而在大多数应用中,用户的行为往往是连续的,用户与物品之间的交互、用户偏好以及商品的流行度往往是随时间而变化的,此时,序列推荐系统便应运而生,它将用户和商品的交互建模为动态的序列,并且利用序列的依赖性来学习当前和最近用户的喜好.
由于具有很高的实用价值,这一问题的研究日益增加,各种序列推荐的方案已被提出.一些基于马尔可夫链思想的方法,根据前一个行为预测用户的下一个行为,在很强的独立性的假设下,过去各成分的独立组合限制了预测精度.最近,基于深度学习的方法已经被提出并应用到序列推荐中,这些深度学习方法可以表征用户项目的动态交互,并学习有效的用户行为表示.还有研究将用户或物品的上下文信息融合到模型中来提高预测性能.实验已经证实了这些实验的优点,但是仍然存在以下问题:忽略了用户的微观行为.用户的微观行为即是用户对项目交互的具体操作,往往可以更加细致得刻画用户的兴趣.如图1所示,本文以电子购物网站为例解释考虑用户微观行为给序列推荐带来的意义.
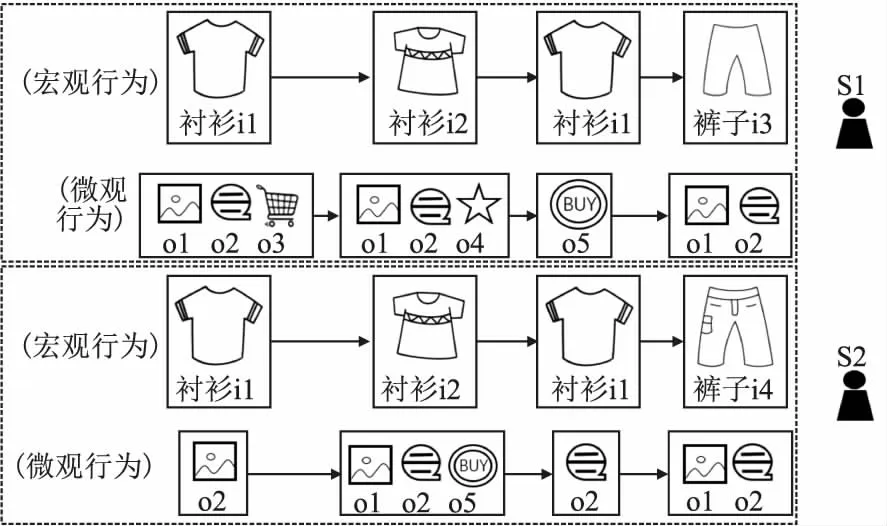
图1 用户微观行为在两个不同序列中的影响Fig.1 Influence of user micro behavior in two different sequences
在图1中,分别展示了两个不同序列的宏观行为和微观行为,可以看出用户的每一个宏观行为都是由一系列微观行为组成的,这些微观行为体现了用户兴趣强弱的不同.同样是想要买一件衬衫,在序列S1中,用户浏览了衬衫1的详情介绍,接着又看了其他用户对于衬衫1的评论,并将其加入了购物车,接着浏览了衬衫2的物品详情介绍,看了其他用户对于衬衫2的评论,收藏了衬衫2,最后回到了购物车页面,下单了衬衫1,系统根据用户前面这一系列行为,为用户推荐了裤子1,用户浏览了裤子1的详情和评论.在会话S2中,用户浏览了衬衫1的详情介绍,接着浏览了衬衫2的物品详情介绍,看了其他用户对于衬衫2的评论,并下单了衬衫2,最后又浏览了衬衫1其他用户对该衬衫的评论,系统根据用户前面这一系列行为,为用户推荐了裤子2,用户浏览了裤子2的详情和评论.从宏观角度看,用户均与衬衫1,衬衫2,衬衫1进行了交互,需要预测用户随后将与哪个项目进行交互,根据传统的序列推荐模式,只基于项目序列建模会话,S1和S2都将出现相同的推荐结果,因为他们都是先后与衬衫1,衬衫2,衬衫1进行了交互,因此,同一个项目可能被推荐为两个会话的下一个交互项目,这与上图中的观察结果不一致.而从微观角度来看,用户的一系列微行为展示了用户对项目的不同操作体现了用户对该项目的兴趣强弱,提供了对用户序列的更细粒度深入的理解,例如,用户收藏的项目可能比仅仅浏览详情和评论的项目兴趣更大,而用户下单的项目则显示了比收藏的项目更强的兴趣.因此,利用并开发用户微观行为信息对于提升序列推荐系统的性能有巨大的影响.
在本文中,从用户微观行为的角度研究序列推荐的问题,提出了一种融合项目序列与微观行为的序列推荐方法(A Sequential Recommendation Method for Integrating Item Sequence and Micro-behavior,简写ISM-SR).在该模型中,用户序列由宏观序列与微观序列组成.具体来说,用户的宏观序列为传统意义上用户交互的一系列项目,而微观序列就是与项目交互的具体操作序列.为了学习用户的会话序列并为其产生推荐,又因宏观序列与微观行为序列具有不同的特点,本研究将用户的项序列与操作行为序列分别输入GGNN(Gated Graph Neural Network,门控图神经网络)和Transformer来学习各自的嵌入,并生成会话表示,学习会话序列的表示并为其产生推荐.本文的主要工作可归纳如下:
1)提出了项目序列与用户微观行为融合的方法,对用户偏好提供了更加细粒度与深入的了解;
2)根据项序列与操作序列的不同特性,使用GGNN和Transformer分别对序列进行建模,实验证明,本文的方法有效的提高了序列推荐系统的性能.
2 相关工作
2.1 传统的序列推荐方法
传统的序列推荐模型包括基于马尔可夫链的模型以及融合上下文信息的方法.
基于马尔可夫链的序列推荐方法为了预测下一次交互,通常会采用Markov链模型对用户和商品的交互转换进行建模,最简单的基于马尔可夫链的方法利用训练集[17]中的转移频率启发式地计算转移矩阵.但是,此方法不能处理未观察到的转换.FPMC方法[16]提出了一种解决方案,该方法使用张量分解技术分解个性化转移矩阵.而Chen等[1]将项目嵌入到欧几里得空间中,并通过项目嵌入的欧几里得距离来估计项目之间的转移概率.由于当考虑更多先前的项时,状态大小很快就变得难以管理.融合上下文信息的序列推荐方法考虑使用项目的邻域信息或流行度信息并以此来提高序列推荐系统的性能.早期的KNN方法通过考虑交互时间来捕获项目的最新共现信息具有一定的有效性,SKNN方法及其变体[6,10]将整个当前会话与训练数据中的过去会话进行比较,以确定要推荐的项目,然而,SKNN并没有考虑到会话中现成的顺序和时间信息.
2.2 基于深层神经网络的序列推荐方法
深层神经网络(DNN)能够在一个序列中模拟和捕捉不同实体(如用户、项目、交互)之间的复杂的综合关系,因此在过去的几年中,DNN几乎占据了序列化推荐的主导地位.尤其是基于循环神经网络的模型,包括GRU和LSTM,B等[2]最大的贡献就是第一次将RNN应用到序列推荐中来,将项目编码成one-hot嵌入输入到基于GRU的RNN的模型中并实现推荐,文献[3]在文献[2]的基础上提出了一种数据增强技术,同时改变输入数据的数据分布,改进了模型的性能;Wu[4]等人为了获得准确的项目嵌入和考虑项目的复杂转换,将序列建模为图形结构数据,提出了基于图神经网络的序列推荐方法,同样也有将注意力网络应用到序列推荐中的方法,如Liu等[5]提出了一种新的短期注意记忆优先级模型,该模型能够从会话上下文的长期记忆中获取用户的一般兴趣,同时考虑到用户当前的兴趣来自于最后一次点击的短期记忆,具有较好的推荐性能等.基于知识的推荐近年来在提高序列推荐性能的任务中发挥着越来越重要的作用.文献[18]根据知识图谱中中实体之间的不同关系使用Node2Vec来学习用户以及项目表示;Wang[19]等利用知识图谱嵌入模型TransD来学习知识嵌入,提出了深度模型DKN等.尽管这些深度神经网络模型在序列推荐任务重都取得了不错的效果,但是他们都忽略了用户微观行为的重要性,因此仍然有改进的地方.当然,目前为止也有将用户微观行为考虑其中的模型,文献[8]采用LSTM对微观序列进行建模,但是该方法忽略了项目序列和操作序列的不同转换特性.
2.3 基于Transformer的序列推荐方法
受到Transformer在自然语言处理领域获得的巨大成功的启发,已经有学者将Transformer应用到序列推荐系统来,SASRec[7]使用了与Transformer模型的编码器部分类似的架构,试图从用户的操作历史中识别哪些项是相关的,并使用它们来预测下一个项;Wu[9]等人针对SASRec本质上是个非个性化模型,提出了一个个性化Transformer模型;Chen[12]等人提出了BST架构,利用Transformer层学习序列中每个项的更深层表示等.但是,这些模型都是在宏观层面对序列进行分析,没有考虑到用户的微观行为.
与上述方法不同,本文融合了宏观层面的项目序列以及微观的操作序列,分别采用不同的方法从多层次多角度建模学习用户序列特征,捕获到用户更加细粒度的偏好和意图,以此来产生下一项推荐.
3 ISM-SR方法
在本节中,首先将形式化描述本文所要解决的序列推荐问题,然后对模型框架进行简单概括与介绍,接着详细介绍ISM-SR序列推荐方法的细节,包括多层次序列特征提取,模型的构建以及生成最终推荐等.
3.1 问题描述
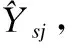
3.2 模型框架
ISM-SR的总体模型框架如图2所示.图2中的黑色实心矩形表示项目序列嵌入,格子矩形表示微观操作序列嵌入,斜线矩形表示模型的其他操作.首先为了捕捉用户兴趣偏好,本研究分别使用不同的模型,GGNN以及Transformer学习项目嵌入以及微观操作序列嵌入,学习后将两者串联起来作为最终的序列表示s,将当前的序列表示s以及候选项目j的嵌入输入多层感知器层(MLP,Multilayer Perceptron)以及softmax层计算得到可能为下一项推荐的得分,为当前用户推荐得分最高的项目,完成模型的推荐功能.
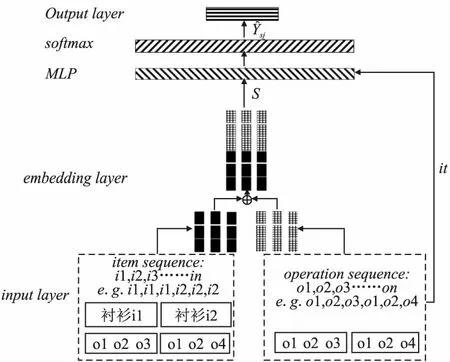
图2 ISM-SR的总体模型框架Fig.2 General model framework of ISM-SR
3.3 多层次序列特征提取
在推荐系统领域,海量的用户行为数据从本质上体现出了用户的兴趣偏好,例如在电子购物网站中,用户对商品的评价打星体现出了用户在购买完该商品验货后对该商品的满意程度,打一颗星表示非常不满意,五颗星表示十分满意,用户可能以后还会买它或者类似的商品等.提取用户行为数据中序列特征对于本文的序列推荐任务至关重要,在本节中,将介绍如何学习序列嵌入,获得给定会话表示以便于提取用户行为特征.在本文的研究中,用户的序列包括项目序列以及操作序列,两种序列对任务建模有着不同的影响,并表现着不同的转换模式,因此采用不同的方式进行建模.
3.3.1 项目序列嵌入
首先,使用门控图神经网络对项目序列进行建模,作为图神经网络的一种,门控图神经网络近年来被用于建模自然语言处理等领域,如脚本事件预测、图像分类、情境识别等[11].而项目序列的转换形式不是连续项目之间的单一方式,前面的项与后面的项彼此都相关,相互依赖,因此这种转换模式依赖于双向上下文,因此为了考虑到节点与节点之间的联系以及项目的复杂转换,可以通过图控神经网络来建模,它能够在考虑丰富节点链接的情况下自动提取图的特征,非常适合项目序列的建模以及特征的提取.
(1)
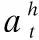
1https://jdata.jd.com/html/detail.html?id=8
图G中所有项目节点的嵌入表示为:
(2)
3.3.2 操作序列嵌入
因为用户对项目的不同操作体现了用户对该项目的兴趣强弱,例如,用户收藏的项目可能比仅仅浏览详情和评论的项目兴趣更大,而用户下单的项目则显示了比收藏的项目更强的兴趣.此外,用户操作序列中各个操作之间也表现出一定的顺序性,而顺序对于预测用户未来的交互项目非常重要.如收藏了项目X的用户,下一步可能会直接下单购买项目X.近年来新出现的序列模型Transformer在机器翻译任务中取得了较先进的性能和效率,与现有的基于卷积模块或基于循环模块的顺序模型不一样,Transformer是一种完全基于自注意力机制的模型,加入了位置嵌入又使这种机制非常高效,能够考虑到序列中的顺序特征.它的思想是,每个顺序输出依赖于输入的相关部分,而这些相关部分才是模型应该关注的.受到启发,本文应用自注意力机制,通过考虑嵌入阶段操作序列的顺序信息,将Transformer方法应用到序列推荐中来.通过它来提取用户操作序列中微观行为之间的依赖关系,结合用户项目序列的学习,输入MLP网络学习隐藏特征之间的相互作用,以产生用户的下一项推荐.
对于操作序列O={o1,o2,o3,o4,…,on},将其嵌入矩阵设为M={M1,M2,M3,…Mn},M∈Rn×d此外,由于自注意力模型中不包含学习序列中项之间位置的模块,而本研究又需要利用序列中的顺序信息,因此在操作序列输入嵌入中加入一个可学习的位置嵌入P∈Rn×d,输入嵌入可表示如下:
(3)
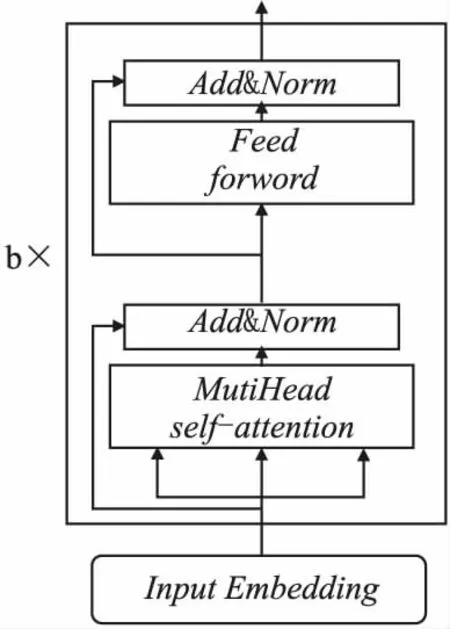
图3 Transformer层Fig.3 Transformer layer
位置嵌入使用文献[13]所提出的方法,使用不同频率的正弦和余弦函数,将位置编码添加到输入嵌入中,将最终获得的操作序列嵌入输入transformer层,它通过捕获序列中与其他项的关系来学习每个项的更深层次的表示,如图3所示,transformer层由由一个个自注意力模块堆叠而成,而每一个自注意力模块又由自注意力层以及逐点前馈网络层组成.注意力[13]的计算方法如下:
(4)
S=MH(E)=Concat(head1,head2,…,headh)WHheadi
=Attention(EWQ,EWQ,EWV)
(5)
其中投影矩阵WQ,WQ,WV∈Rd×d,h表示head的数目,为了使模型具有非线性,采用逐点前馈网络:
F=FFN(S)=RELU(SW(1)+b(1))W(2)+b(2)
(6)
其中,W(1),W(2),b(1),b(2)都是可学习的参数,随着网络的加深,为了避免过拟合,在将嵌入输入自我注意层和FFN层前对输入进行层归一化,对层的输出进行dropout,然后再将输入x加到最终的输出中:
f′(x)=x+Dropout(g(LayerNorm(x)))
(7)
其中,f(x)表示自我注意层或FFN层.为了进一步建模操作序列背后的复杂关系,将自注意力块进行堆叠,其中第b块定义如下:
Sb=MH(F(b-1))
Fb=FFN(Sb)
(8)
经过Transformer层的嵌入学习后,将学习到的输出表示为:
(9)
(10)
⊕表示串联运算.通过这种操作序列嵌入的方法,具有相同项目序列但是微观操作不同的两个序列然后具有不同的表示,可以捕获用户更加细粒度的偏好和意图.
3.4 生成推荐
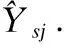
(11)
为了训练模型ISM-SR,本文使用二元交叉熵作为序列推荐任务的损失函数:
(12)
其中,S表示序列集合,D表示项目集合,Ysj∈(0,1)表示用户是否真的会与j产生交互,如果Ysj=1,表示用户的下一项交互项目是j,如果Ysj=0,表示用户的下一项交互项目不是j.
4 实验与评价
4.1 实验数据集
本次实验采用的数据集为JDATA1数据集,该数据集来自中国著名的电子商务网站京东,包含了京东网站上两个月的用户行为数据.其中具体的操作类型有浏览、下单、关注、评论以及加购物车.
对于该数据集,本研究将会话的持续时间阈值设置为1小时,过滤在数据集中出现次数少于3次的项目以及长度为1的会话.实验中,为了验证该模型的序列推荐的有效性,将数据预处理后的数据分为训练集和测试集后在输入序列推荐模型,将早期的90%用户行为作为训练集,并将近期10%的用户行为作为测试集.为了进一步验证本文提出的模型的有效性,模拟了一个稀疏的JDATA数据集,仅保留最初的1%用户行为,将该稀疏数据集表示为Few.在模型的预测过程中,首先会计算项目集中所有项目的匹配分数,然后根据分数的大小生成top-k列表.
4.2 实验配置
实验中数据预处理、多层次序列特征提取、序列推荐模型的构建均采用python语言来实现.具体硬件环境为CPU:Intel Xeon E5-2630 v3,内存:32GB,显卡:NVIDIA Geforce GTX 1080 Ti 2张,Window10系统,软件环境为Pytorch 1.8.0.
4.3 评价指标
本文使用如下两个指标来评估ISM-SR模型推荐性能,包括Hit@k,MRR@k.
Hit@k:命中率,能直观的衡量测试目标项目是否存在于列表的top-k项中,是基于召回的度量,测量了推荐的准确性.
MRR@k:表示用户真正交互的项目在推荐列表中位置序号的倒数平均值,如果用户真正交互的项目没有出现在top-k列表中,则MRR为零.较大的MRR值表示正确的推荐位于推荐列表中较高的位置,表明此时的推荐性能更好.在实验中,K取20.
4.4 实验结果与分析
4.4.1 敏感度分析
本文提出了ISM-SR算法,该算法包含众多不同的参数,尤其是transformer的不同组件,包括自注意力模块的个数b,模型中的所有子层以及嵌入层产生维度为d,学习率(Learning rate,lr)等.这一部分将在JDATA数据集上对这些参数进行分析与研究.
对于超参数学习率lr,它的值过小可能导致模型收敛速度较慢,需要更长时间的训练,当学习率过大可能会导致模型不收敛,损失loss不断上下震荡.为了对比出最优的参数lr,在其他参数不变的情况下,lr取不同的值,Hit@20以及MRR@20的变化情况如图4(a)、图4(b)所示.
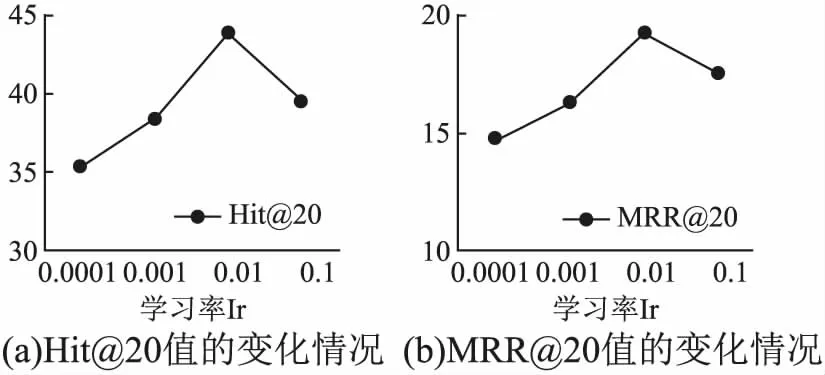
图4 学习率的影响Fig.4 Influencce of LR
从图4(a)、图4(b)中可以看出,随着lr取值越来越大,Hit@20以及MRR@20的值也在增大,实验效果越好,在lr=0.01时,实验效果达到最好,但是随着lr取更大的值,实验效果变差,因此,在本模型中,lr可取0.01.
接着,展示了自注意力模块叠加对实验的影响.如图5(a)、图5(b)所示,实验发现,对于本模型更多的自注意模块是首选的,对于JDATA数据集,在b=5时获得了最佳性能.
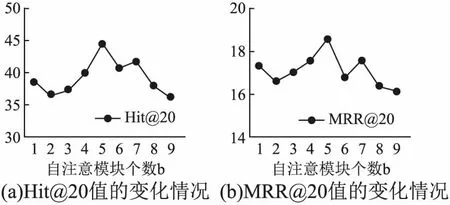
图5 自注意模块个数的影响Fig.5 Influence of the number of modules
在图6中,还分析了一个关键的超参数潜在维度d的影响,当d取64,128,256,512时,可以看到两个评价指数的值都是先上升然后逐渐降低,模型的推荐性能也因此先上升然后逐渐降低,因为嵌入维度过大会导致过拟合现象,说明实验中取较大的嵌入维度不一定会得到更好的模型性能,当嵌入维度取128时,模型性能最好.
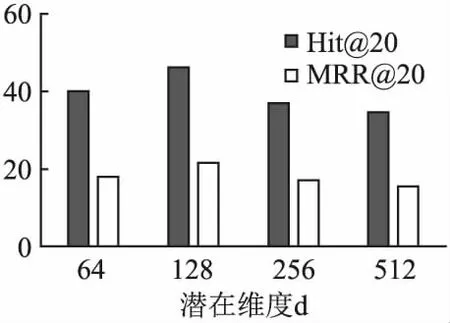
图6 潜在维度d对实验效果的影响Fig.6 Influence of potential dimension d on experimental results
实验中对于模型中的其他参数如多头注意力中头的个数nhead等同样进行了分析,由于文章篇幅限制就不再描述.
4.4.2 算法对比
经过大量的实验,模型ISM-SR中的各种参数得到了调整.为了探究本文提出的模型的整体推荐性能,接下来将与以下几种方法在JDATA数据集以及Few数据集上进行对比.
FPMC[16]:一种基于个性化马尔可夫链以及矩阵分解的序列推荐预测方法.
GEU4Rec[2]:第一次将RNN应用到序列推荐中来,将项目编码成one-hot嵌入输入到基于GRU的RNN的模型中并实现推荐.
GEU4Rec+[3]:在文献[2]的基础上提出了一种数据增强技术,同时改变输入数据的数据分布,改进了模型的性能.
NARM[14]:基于GRU的序列推荐模型,引入注意力机制考虑用户偏好的长期依赖关系.
SR-GNN[4]:将序列建模为图形结构数据,提出了基于图神经网络的序列推荐方法.
MKM-SR[15]:同样是将用户微观行为考虑其中,使用GRU处理用户操作序列.
此外,为了证明在本文模型中纳入微观行为有效性,进一步提出ISM-SR的一些变体进行比较.
IS-SR:该变体去除了操作嵌入学习的模块,剩下的模块与ISM-SR相同;
ISM-SR-RPE:该变体去除了操作嵌入学习模块中的位置嵌入,也就是仅考虑序列中用户的具体操作,不考虑各个操作的顺序.
为了进行公平比较,ISM-SR以及对比模型使用相同的嵌入维度,设置为128,batch_size设置为128,多头注意力的nhead取8,lr=0.01,b=5.如表1所示,展示了所有方法的推荐性能对比.
从表1可以看出,在JDATA和Few这两个数据集上,相对于传统的推荐方法FPMC,深度神经网络方法GEU4Rec,GEU4Rec+,NARM以及SR-GNN取得了更好的实验效果,是因为FPMC方法只捕捉一阶的马尔可夫关系,但是现实生活中用户的偏好会受到各种因素的影响产生间歇性的变化,并不是绝对连续的.
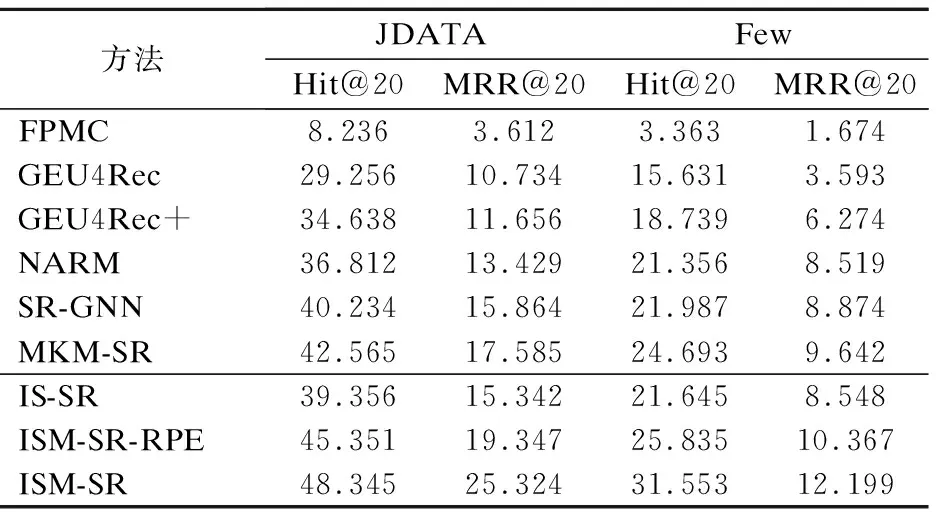
表1 推荐性能对比Table 1 Recommended performance comparison
而本文所提出的模型ISM-SR的推荐效果优于以上所提出的所有方法,在各项指标都有所提升.与GEU4Rec,GEU4Rec+相比,ISM-SR方法的推荐性能提高很多,这是因为这两种方法虽然考虑到了用户的序列行为,使用RNN来解决序列问题,但是没有将用户的微观行为即用户与项目相互时的具体操作考虑其中;NARM以及SR-GNN方法比前两种深度神经网络方法取得了更好的效果,这是因为NARM方法在使用基于具有GRU单元的RNN来建模用户行为序列,SR-GNN为了使用了图神经网络来建模顺序序列,同时,这两种方法还加入了注意力机制来捕获用户的兴趣,提高了模型性能,但是它们同样没有考虑到用户的微观操作行为,本文的方法将用户的微观操作行为考虑进来,且根据项目序列与操作序列的不同特点使用了不同的方法进行建模,取得了比NARM以及SR-GNN方法更好的效果.而与MKM-SR方法相比,本方法使用Transformer来处理用户的操作序列,一方面Transformer比GRU可以捕获时间序列中更加长期的依赖,另一方面Transformer的并行计算能力强,通过自注意力模块提取不同的特征,计算效率高,节省时间,同时它的自注意力机制也使模型具有一定的可解释性.
与ISM-SR的两种变体方法相比,ISM-SR取得了更好的序列推荐效果,证明了本文在序列推荐任务中将用户操作微观行为考虑进来的有效性,同时各个操作行为的顺序也是十分重要的因素,可以进一步提升序列推荐的效果.
5 总结与展望
对于序列推荐任务,在用户宏观项目序列的基础上,本文从更加细粒度的角度出发,提出将用户微观行为即用户与项目交互的具体操作序列考虑进来,并根据宏观项目序列与微观操作序列的不同转换模式,分别采用图神经网络以及Transformer来分别建模序列,以便获取不同层次的用户特征,将学习出来的两种序列嵌入串联起来输入MLP及softmax网络,计算出可能为下一项推荐的得分,以产生用户的下一项推荐.综合实验表明,本文提出的方法优于基线方法,有效地提高了推荐系统的性能.
未来的工作可以在此基础上,考虑融合当前会话的上下文信息,如邻域知识、流行度因素等,应该会对推荐任务起到一定的辅助作用.
