融合灰关联分析和信任度的Slope One算法研究
2023-01-31陈露露张岐山
陈露露,张岐山,朱 猛
(福州大学 经济与管理学院,福州 350108)
1 引 言
推荐系统能够有效地过滤信息,减轻用户认知负担,为用户提供个性化的信息和服务.其中,协同过滤推荐系统是目前应用最普遍、最受欢迎的一种推荐系统.本文研究的Slope One算法是一种简便、高效的基于项目的协同过滤算法[1].作为一种有效的协同过滤算法,Slope One算法被广泛地应用到一些推荐系统中.通过对Slope One算法的相关研究文献进行分析可知,有关Slope One算法的研究有以下趋势:
1)为了提高算法的评分预测准确度,后续许多学者将相似度关系引入到Slope One算法中,如采用Jaccard方法[2]、Pearson相关系数[3]、余弦相似度[4]以及其他相似度方法[5-7]量化用户关系和项目关系,来提高算法推荐质量.
2)为了缓解稀疏数据对算法推荐效果的影响,相关学者采用聚类方法进行矩阵填充[8-10]或者使用矩阵分解[11]以及其他的方法[12,13],出发点都是为了解决数据稀疏问题对Slope One算法的影响.
分析可知,目前有关Slope One算法的研究重点倾向于通过优化相似度来改善算法的预测性能以及解决数据稀疏问题,有关冷启动方面的改善较少.综上,本文提出在Slope One算法上考虑用户之间的均衡接近度和信任度,以此来提高算法的评分预测准确度,并更好地处理算法的数据稀疏和冷启动问题.主要研究内容如下:
1)引入均衡接近度.本文引入均衡接近度灰关联方法来度量用户之间的潜在联系,对Slope One算法进行优化.由于协同过滤算法中经典的相似性量化方法具有一定的局限性.因此,本文提出使用均衡接近度灰关联方法度量用户相似度,从而充分挖掘用户之间的交互信息,有效地缓解算法在贫信息系统中推荐准确度降低问题,提高评分预测的准确度.
2)引入信任度.Slope One算法在进行评分预测时仅仅基于项目之间的评分差异,没有考虑信任用户对推荐结果的影响.本文在此基础之上进行改进,利用JMSD方法度量直接信任;同时考虑到信任的传播特性,结合节点用户的声望获得间接信任,最后综合以上两种信任得到最终信任值,来提高算法的推荐精准度,降低冷启动问题对算法的影响,提高评分预测准确度.
接下来将详细介绍本文的研究工作.
2 Slope One算法概述
Slope One算法(Slope One Algorithm,SO)的主要思想是基于用户项目评级矩阵中每个项目对应的用户评分值,获得项目之间的得分偏差.通过项目得分偏差和用户的历史评级记录获取用户对目标项目的近似评级值.
2.1 Slope One算法
算法运用线性回归模式f(x)=x+b来预测评分,项目i相对项目j的评分偏差devj,i见公式(1).
(1)
用户u对项目j的评分预测值为Puj,见公式(2).
(2)
其中,ui、uj分别指用户u对项目i、j的评分,Sj,i(χ)指对项目i,j有共同评级交互的用户集,Rj指用户u的评级项目集合,card()代表用户评级项目集中的元素总数目.
2.2 Weighted Slope One算法
为了进一步考虑用户的评分数量对算法预测准确度的影响,Lemire 等[1]随后又提出了一种加权 Slope One 算法(Weighted Slope One Algorithm,WSO),见公式(3).
(3)
其中,Cji指对用户项目评级矩阵中对项目i,j有共同评级交互的用户数.
3 融合灰关联分析和信任度的Slope One算法
3.1 融合均衡接近度灰关联的Slope One算法
均衡接近度灰关联方法由张岐山教授[14]提出,在灰熵和灰关联系数的基础上,可以有效地应用在贫信息系统和复杂系统中.本文提出将均衡解接近度灰关联分析方法纳入Slope One算法中对算法改进.
3.1.1 均衡接近度灰关联方法介绍
根据张岐山教授提出的均衡接近度灰关联方法,设序列X=(x1,x2,x3,…,xn),F为数值映射集,称χ为X的像集灰关联因子集.F为数值映射集,F= {初值化,平均值化,最大值化,最小值化,区间值化,正因字化}.X0∈χ为参考列,Xi∈χ为比较列,i∈I={1,2,…,m},Xo={xo(k)|k∈K},Xi={xi(k)|k∈k},K={1,2,…,n}.
定义1.灰关联公式如下:
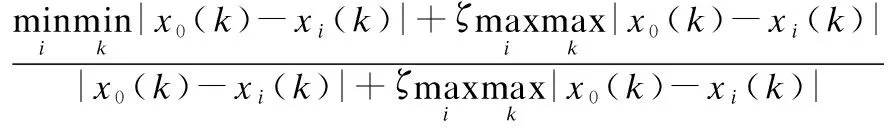
(4)
(5)
其中,ζ为分辨系数,γ(x0(k),xi(k))为参照列X0与对比列Xi的灰关联系数,γ(X0,Xi)为参照列X0与对比列Xi的灰关联度.
定义2.灰关联系数分布映射:Ri表示第i个比较列的关联系数列,Ri={γ(x0(k),xi(k))|k∈K},则称灰关联系数分布映射如下:
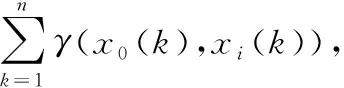
(6)
定义3.灰关联系数熵:
(7)
其中,ln为以e为底的对数.对公式(6)并考虑到其约束条件,应用拉格朗日极值法可得灰熵的最大值为:
(8)
可得X的均衡度为:
B=H⊗(Ri)/Hm(Ri)
(9)
定义4.均衡接近度:
Ba(X0,Xi)=B(Ri)×γ(X0,Xi)
(10)
其中,Ba(X0,Xi)为参考列X0与比较列Xi的均衡接近度.
3.1.2 均衡接近度计算
1)对于目标用户u和相关用户v,以及目标用户向量和对比用户向量中互相匹配的分布点(k1,k2,k3,…,kn),根据公式(4)得到用户u、v在第k个项目上的灰关联因数.由于ζ取0.5时,能够较好地表现处序列的一致性[15],因此本文ζ的取值为0.5.根据公式(5),通过对各个维度上的灰关联因子取平均值,最终得到目标用户和对比用户之间的综合灰关联度.
2)根据公式(6)将目标用户和对比用户在各维度上相匹配的灰色关联系数进行对应,得到用户u与用户v在各个维度上的灰关联系数分布情况.
3)在对最初的数据进行对应之后得到的集合能够符合拉格朗日极值法的相关要求,从而可以获取用户向量灰关联系数熵函数的最优结果.根据公式(7),基于均衡接近度灰关联方法,度量目标用户和对比用户在各维度上的灰关联系数熵.从极值的角度出发,根据公式(8)可得灰熵的最大值.
4)目标用户的灰熵的最佳结果取决于目标用户的历史评级项目数量.根据公式(9)利用均衡接近度来量化用户之间在各个维度上的无差异性,通过计算目标用户和对比用户在各个维度上的灰关联系数熵和其最佳结果之比,最终获得目标用户和对比用户之间的均衡接近度.
5)均衡接近度可以更好地度量目标用户和对比用户之间的相关程度.此外,通过对各维度之间的互相匹配的灰色关联因子集合取平均值,可以得到目标用户和对比用户之间的综合灰关联度,从而进一步挖掘用户之间的潜在联系,有效地将两者结合起来.根据公式(10),最终得到目标用户与其它用户之间的均衡接近度结果.
相比于其他相似度测量方法,利用均衡接近度灰关联方法可以根据灰色系统中各个要素之间趋势的接近程度,来衡量要素之间的接近程度,从而显示出系统内部各相关要素之间的关联[7].基于此,本文提出利用均衡接近度灰关联方法来衡量用户关系.
3.2 融合信任度的Slope One算法
大多数用户与其信任用户偏好相似或相同,用户的信任网络会影响用户的决策过程.而且引入信任网络,可以为目标用户推荐其信任用户的偏好项目,有效处理算法的用户冷启动问题.因此,本文将信任网络引入到Slope One算法中.
3.2.1 直接信任度量
本文使用常见的JMSD方法来定义用户间的直接信任,该方法是在MSD和Jaccard系数的基础上共同作用得到的.见公式(11).
(11)
其中,|Iu∩IV|代表用户u、v评分项的交集总数,|Iu∩IV|代表用户u、v的评分项的并集总数.
实际情况中,即使对于同一项目,用户之间的评分准则也因人而异.为了降低不同用户之间的评分标准差异对推荐结果的干扰,引入影响因子对用户的评分准则进行修正,见公式(12).
(12)
由于信任关系是非对称的.因此,综合考虑用户之间的评分倾向差异、用户相关系数,以及用户信任的非对称性,定义用户u对用户v的直接信任结果,见公式(13).
(13)
同上,可知用户v对用户u的直接信任结果,见公式(14).
(14)
其中,|Iu∩IV|代表用户u、v评分项的交集总数,|IV|为用户v的评分项目总数.
3.2.2 间接信任度量
用户之间的直接信任建立的前提是彼此之间具有交互的评级项目.如果只考虑直接信任,对于没有评级交互的用户会造成它们之间不存在信任关系.因此,本文考虑信任的传播特征来获取间接信任.采用权值平均的方法对具有多个传输路线的用户之间的信任进行整合,并采用乘积的方式表示信任值随着传输距离的增加而衰减.
声望是社交网络中的一个重要的传播参数[16].对于信任传播过程中的传播节点的用户,其声望越高,表示通过该条路径获得的间接信任的可信度更高.因此,本文在计算间接信任时,引入声望的概念,以更加有效地度量信任.
本文主要从用户的历史交互评级数量和评级的准确性这两方面来量化声望.若某用户经常对系统中各个项目进行分享或者评价,则意味着该用户在推荐系统中为活跃用户,并且该用户相对系统中其他用户的可信度更强.评级数量权重指用户的历史交互评级总数对用户声望的影响程度,见公式(15).
(15)
其中,A为对所有用户的评分数量取平均的结果,|Iu|为用户u的评分项目总数.
同样,若某用户对以往的物品的评分更为准确并符合实际情况,则意味着该用户更加客观和可信.具体而言,可以用目标用户对某项目的评分与系统中所有用户对该项目评分的平均值之间的偏差来表示,见公式(16).
(16)
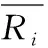
综合考虑用户的评级数量权重和评级准确度,最终得到用户的声望值,见公式(17).
Pu=Su×Hu
(17)
由于随着距离的增加信任会衰弱,本文设定用户间的信任传递距离为2,基于直接信任度并结合节点用户的声望值,最终得到改进后的间接信任,见公式(18).
(18)
其中,Dtrust(u,k)指用户u与用户k之间的直接信任度,Dtrust(k,v)指用户k与用户v之间的直接信任度,Pk指用户k的声望值.
综合直接信任和间接信任得到综合信任度,见公式(19).
(19)
其中,Dtrust(u,v)为用户u与用户v之间的直接信任度,Itrust(u,v)为用户u与用户v之间的直接信任度.
3.3 融合灰关联分析和信任度的Slope One算法
通过对用户均衡接近度与信任度线性加权,综合得到用户相似度,见公式(20).
Simuv=αBauv+(1-α)Trustuv
(20)
将公式(19)计算得到的用户综合相似度结合到公式(3)中对算法进行改进,得到改进的融合灰关联分析和信任度的Slope One算法 (Research on Slope One Algorithm Integrating Grey Association Analysis and Trust,GTSO),见公式(21).
(21)
其中,Simuv为用户u与共同评价过项目i、j的前K个相似用户v的综合相似度.
3.4 算法描述
融合灰关联分析和信任度的Slope One算法伪代码如下.
输入:User-Item rating matrix,Item setI={i1,i2,…,in}
输出:Puj
1. for u in matrix
2. for v in matrix
3. ifu==v
4. continue
5. else
6.Ba=公式(10)
7. Trust(u,v)=公式(19)
8. Simuv=公式(20)
9. end for
10.end for
11.foriinI
12. for each user
13. ifjin user andiin user
14.devj,i=公式(1)
15.Puj=公式(21)
16. end for
17.end for
18.returnPuj
4 实验结果及分析
4.1 实验环境与数据集
4.1.1 实验环境
实验采用Window10系统,CPU@2.60GHz,RAM 16G,软件环境为Python3.7.
4.1.2 实验数据集
本文使用由GroupLens小组提供的标准数据集MovieLens 100k作为实验数据,实验数据集的详细介绍见表1.为了防止过拟合现象,实验采用5折交叉验证方法.

表1 实验数据集介绍Table 1 Introduction to experimental data sets
4.2 实验评价指标
在实际应用中,Slope One算法通常用于评分预测,本文研究目的是提高算法推荐准确度,因此后续实验中采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)验证改进算法的有效性.
1)MAE.可以直接反映实际分数与预测值的偏差情况,见公式(22).
(22)
2)RMSE.反映实际分数与预测值的偏差情况,但对特别大或特别小的测量误差反映更敏感,见公式(23).
(23)
其中,rui指用户u对项目i的现实评分,preui指用户u对项目i的预测评分,|N|为测试集中的元素数.
4.3 实验结果
为了验证本文提出的融合灰关联分析和信任度的Slope One算法能否有效提高算法推荐质量,设计了以下4组对照实验.
4.3.1 传统用户相似度计算方法实验对比分析
为了验证本文提出的利用均衡接近度灰关联分析方法(以下简称GBSO模型)衡量用户相似度的有效性,将其与另外两种通过传统相似度度量方法得到的算法在MovieLens数据集上进行实验,参照的用户相似度方法包括皮尔逊相似度(以下简称PSO模型)以及余弦相似度方法(以下简称CSO模型),观察分析在K的不同取值情况下MAE 和RMSE的变化趋势.其中,K分别取10、15、20、…、50,实验结果见图1、图2.
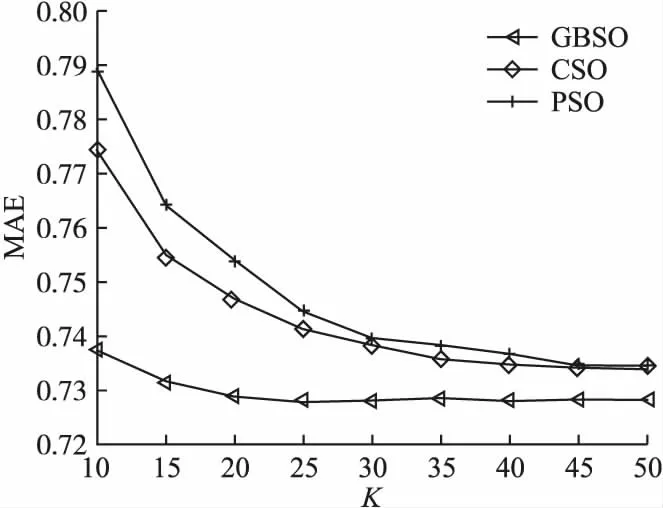
图1 MovieLens数据集上各算法的MAE比较Fig.1 Comparison of MAE of algorithms on the MovieLens dataset
观察图1、图2中MAE和RMSE的变化趋势可知,通过几种相似度方法计算得到的MAE 和RMSE的图形走势大致相同.随着K值的递增,使用3种算法得到的MAE值和RMSE值均表现为下降趋势.当K取值为25时,GBSO模型的评价指标达到最优值,且采用均衡接近度计算得到的GBSO算法的结果明显优于另外两种相似度计算方法,误差值始终低于另外两种对比方法的实验结果,MAE和RMSE的图形收敛速度更快,总体变化趋势更加平稳,说明通过均衡接近度灰关联方法计算用户接近度具有一定的稳定性,相比其他相似度计算方法,在稀疏数据集下具有更好的推荐准确度.
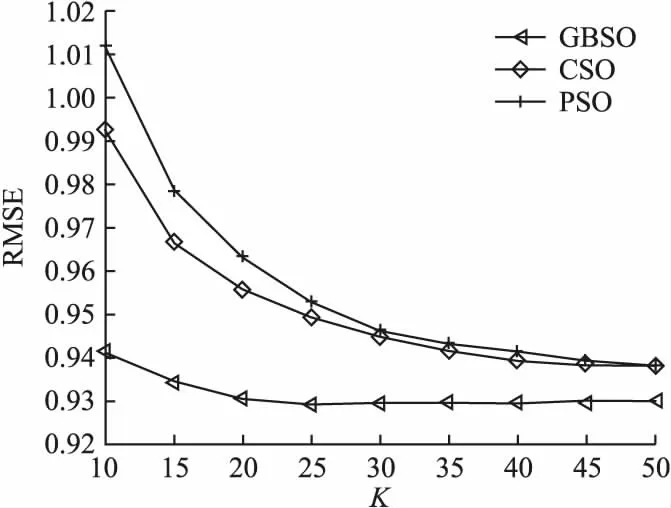
图2 MovieLens数据集上各算法的RMSE比较Fig.2 Comparison of RMSE of algorithms on the MovieLens dataset
4.3.2 算法参数选择
1)相似度权重参数实验分析
在学习参数α对算法性能的影响时,为了获得最优的综合相似度值,本文首先固定邻居用户数进行实验,并且为了避免单次实验结果存在不稳定性,在不同邻居用户数的情况下进行实验.在实验MovieLens数据集上,分别以邻居数为25和50为例,设置α的取值范围为0.1~1,间隔为0.1,观察并分析实验评价指标MAE 和RMSE的波动趋势,实验结果见图3、图4.
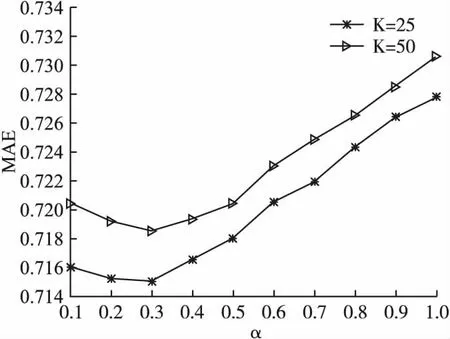
图3 MovieLens数据集上相似度阈值分析Fig.3 Analysis of similarity threshold on MovieLens dataset
观察图3和图4中MAE和RMSE的变化趋势可知,在用户近邻数不同时,MAE和RMSE值都随着参数α的增大呈现先降低后上升的趋势,这表明当本文提出的均衡接近度和信任度占有不同权重时,对算法准确度产生的影响不同.其中,当α取值为0.1~0.3时,MAE和RMSE值逐渐下降, 后续随着α取值的增加,MAE和RMSE迅速上升,增长幅度较大,这说明当均衡接近度占比更高时,算法的预测准确度相对偏低.当α取值0.3时,MAE和RMSE结果达到最优值,算法的推荐准确度更高,这表明引入均衡接近度和信任度加权的方式可以综合考虑用户关系对算法的影响,提高算法的准确度.因此,在后续实验中用户相似度权重设置为0.3.
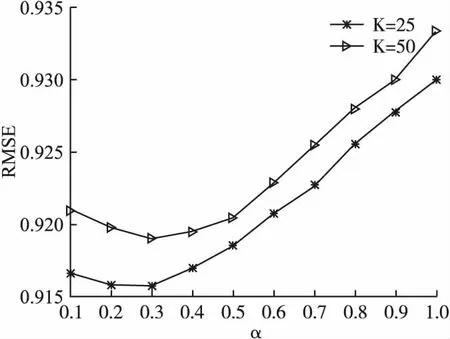
图4 MovieLens数据集上相似度阈值分析Fig.4 Analysis of similarity threshold on MovieLens dataset
2)最佳近邻数实验分析
K取值越大,说明选择的邻居用户数越多,反之越少.在研究近邻用户K值大小对算法性能的影响时,根据上述实验结果,设置用户相似度权重为0.3,K取值范围10~50,步长为5,对GTSO算法进行实验以确定最佳邻居用户数,实验结果见图5.
观察图5可知,随着邻居用户数的不断增加,通过GTSO算法得到的MAE和RMSE值都表现为先降低然后逐渐趋于平稳的走向.此外,当K小于25时,随着K的增加,通过GTSO算法得到的MAE和RMSE值逐渐减少,这说明当邻居用户数较少时,参与预测评分的数据也较少,导致无法准确评估.随着邻居用户的不断增加,与目标用户产生评分交互的用户不断增加,参与评分预测的数据量增加,这样可以降低误差,提高预测准确度.当K大于25时,MAE和RMSE值趋于平稳且整体趋势相近,略有上升趋势,表明如果选择的近邻用户的比例太大,会将相关性低的数据添加进去造成干扰,会影响预测的准确性.因此,在后续实验中取K为25作为最佳邻居用户数.
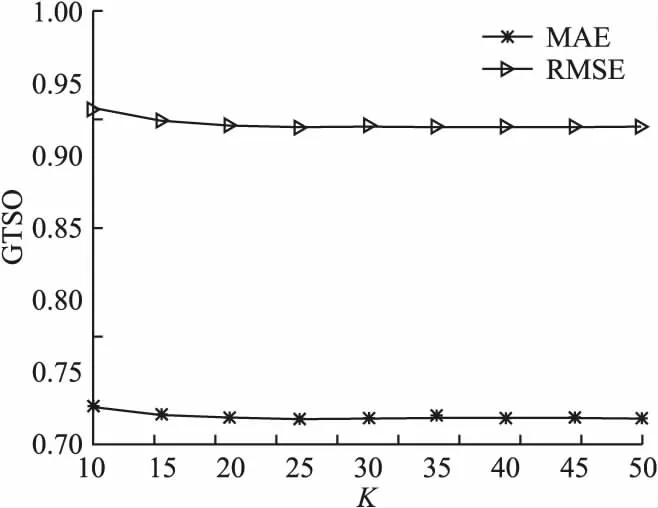
图5 不同邻居数下MAE和RMSE值变化图Fig.5 Changes of MAE and RMSE under different number of neighbors
4.3.3 算法实验结果对比分析
为了验证融合GTSO算法模型的有效性,根据上述实验,设置邻居数K为25,对比SO算法、WSO算法、以及文献[17]提出的CSO算法.对于从u1到u5的数据,依次测试这5组训练集和测试集,以分析实验指标MAE和RMSE的变化趋势.实验结果见表2、表3、图6、图7.
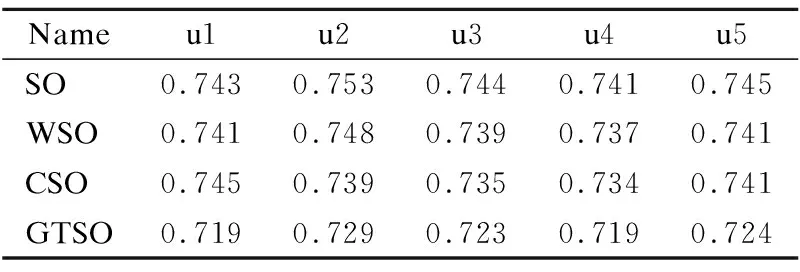
表2 MAE对比Table 2 MAE contrast
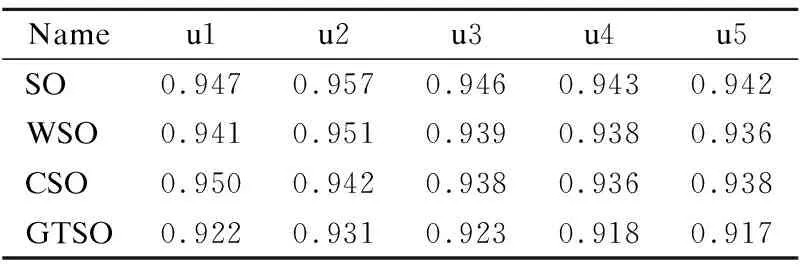
表3 RMSE对比Table 3 RMSE contrast
通过表2、表3可以清晰地观察到各个算法在以上5组数据中的评分预测情况.通过图6、图7可以更加直观地突显出本文改进的GTSO算法的优势,GTSO算法在本文采取的评估指标上得到的实验结果准确度均优于SO、WSO算法.分析实验结果可知,GTSO算法的MAE和RMSE的均值相比CSO算法降低了约1.74%、1.663%.这说明在SO算法中,采用均衡接近度度量用户之间的相关程度要优于余弦相似度.总的来说,相对于传统的SO算法和WSO算法,改进后的GTSO算法的平均MAE分别下降了2.84%、2.49%,RMSE均值分别下降了2.6%、1.99%, 证明了本文改进算法可以有效降低数据稀疏对算法的影响,在稀疏数据下可有效提高算法的评分预测准确度.
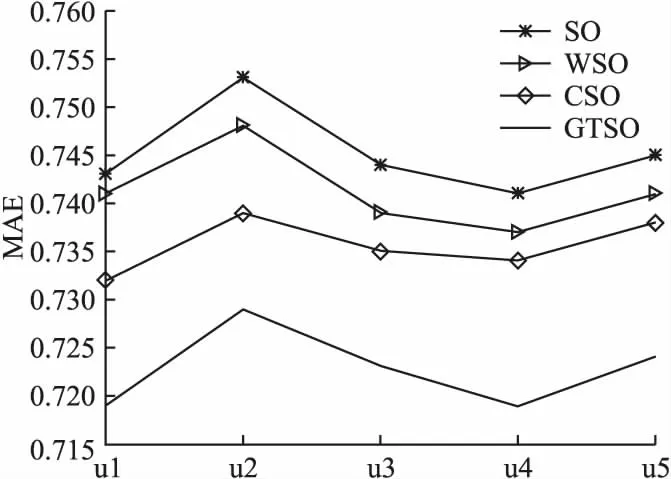
图6 各算法MAE对比图Fig.6 MAE comparison diagram of each algorithm
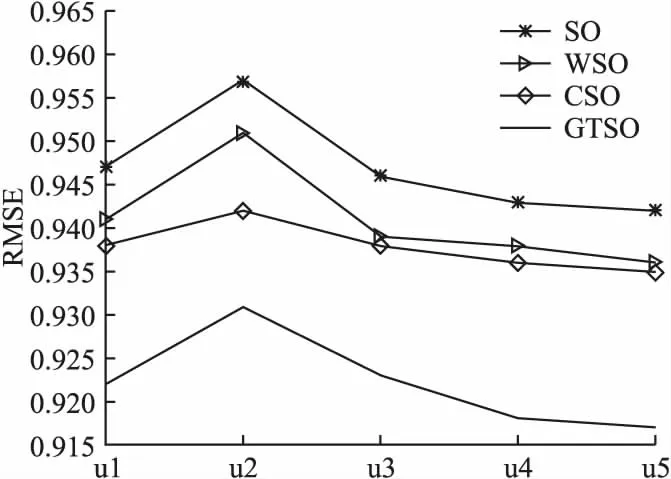
图7 各算法RMSE对比图Fig.7 RMSE comparison diagram of each algorithm
4.3.4 算法冷启动对比分析
在算法冷启动分析实验中,将评分总数低于25的用户设置为冷启动用户.将本文改进的GTSO算法与SO算法、WSO算法得到的MAE值和RMSE值进行对比和分析,以此来验证GTSO算法可以有效地降低用户冷启动问题对推荐性能的影响.实验中,将K的取值从10增长至50,间隔为10,实验结果见图8、图9.
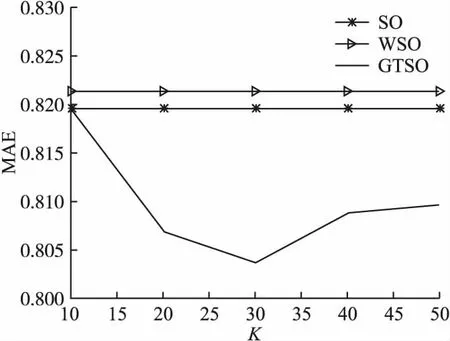
图8 各算法冷启动下MAE对比图Fig.8 Comparison diagram of MAE of each algorithm under cold start
观察图8、9可知,由于SO、WSO算法未考虑近邻用户,因此随着近邻数的变化通过这两个算法得到的评分数少于25的冷启动用户的MAE值和RMSE值始终保持不变.而且由图可知,SO算法和WSO算法受用户冷启动问题影响较大,得到的推荐结果误差较大.而本文提出的GTSO算法,在任意近邻值下对于冷启动用户均具有更好的推荐质量.当K取值为30时,MAE值和RMSE值处于最低值,后续有上升趋势但很快又趋于平稳,充分证明了GTSO算法处理用户冷启动问题的有效性.
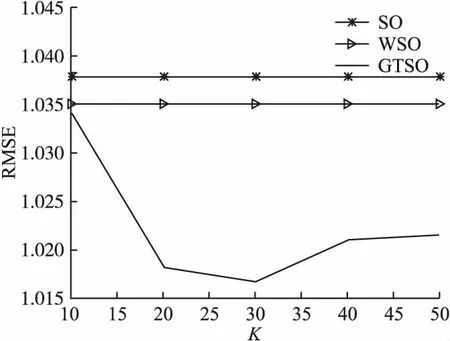
图9 各算法冷启动下RMSE对比图Fig.9 Comparison diagram of RMSE of each algorithm under cold start
以上4组实验结果表明,融合灰关联分析和信任度的Slope One算法得到的实验结果算法在推荐性能上均优于SO算法、WSO算法、CSO算法.在K值较小的区间中, GTSO算法的MAE值和RMSE值也比其他算法小很多,预测评分也更加准确,可以有效降低算法的冷启动问题,在稀疏数据具有明显的特征,预测准确度提高情况较好.
5 结束语
针对Slope One算法没有考虑到用户之间的潜在联系以及用户信任关系对推荐的影响,导致推荐质量不佳.本文提出的融合灰关联分析和信任度的Slope One算法将灰关联方法以及信任概念引入到Slope One算法中.最后的实验结果表明,从灰色系统整体角度出发进一步考虑到用户之间的信任关系,可以更好地解决算法在贫信息系统中的冷启动问题,提高算法性能.未来研究工作将进一步考虑用户偏好随时间的变化等因素对算法的影响,提高算法的预测准确度.
