人体关键点检测及教学应用之人脸表情识别
2023-01-30于方军焦玉杰山东省淄博市博山区山头中心学校
于方军 焦玉杰 山东省淄博市博山区山头中心学校
孙丽君 山东省淄博第二中学
人类的面部表情常见的有高兴、愤怒、悲伤、吃惊、厌恶和恐惧等。MediaPipe中的面部识别(Face Mesh)能识别468个脸部关键点,如图1所示是识别脸部关键点及放大后的嘴部特征点,其中上下嘴唇中间特征点标号分别是13、14。

图1 MediaPipe识别的脸部关键点及嘴部放大图
首先从嘴部坐标识别入手,了解脸部关键点检测过程,并借助上下嘴唇中间关键点坐标距离做一个控制舵机的程序,控制对应的开源机器人模仿人开口说话;然后通过OpenMMlab开发的MMEdu工具,体验基于MMEdu实现的表情识别,了解表情识别的流程;接着介绍苹果系统如何通过unity插件,把采集到的人脸关键点信息投射到数字人脸部,让数字人拥有人的脸部表情表达。
● 机器人嘴部控制——借助舵机转动角度控制嘴部开闭
利用采集到的脸部关键点数据,找到上下嘴唇中间点13、14的y坐标变化,结合用开源硬件制作的表情机器人Fritz模型,可以实现简单的张嘴、闭嘴控制,硬件选用arduino板,用pinpong库进行控制。
获取嘴部关键点坐标,通过下页表1中的代码读取嘴部关键点13(上嘴唇中间点)、关键点14(下嘴唇中间点)的y坐标,在MediaPipe中用图像高度的像素值w与这个读取坐标值相乘,得出该点的像素坐标。闭嘴和张嘴两种状态,y坐标的差值大约在0~28像素之间。

表1 嘴部关键点13、14坐标读取及代码
用舵机控制脚连接开源硬件arduino板的8脚,控制其转动的角度。安装pinpong库(用pip install pinpong安装),用from pinpong.board import Board,Pin,Servo导入pinpong库的舵机(Servo)控制,使用时需要先定义好输出脚,本例中笔者定义8脚为输出脚,运行代码,根据实时采集到的嘴部13、14关键点坐标差值变化,映射设为舵机角度变化,并控制接在arduino板8脚的舵机转动角度。代码及效果如图2所示。
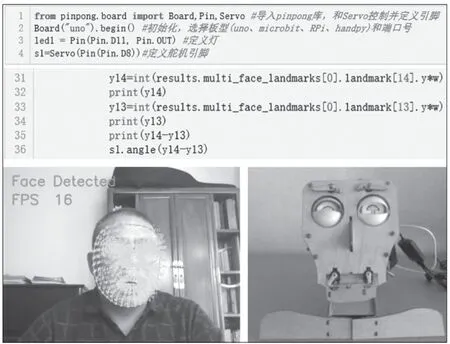
图2 控制Fritz表情机器人嘴部动作代码及效果演示
本案例只是对MediaPipe提供的训练好的模型的一个简单应用,对于要训练的特定的表情表现如“开心”“生气”“伤心”“惊讶”等,爱好者可以自己设计一个神经网络模型,并用采集到的数据训练它,让计算机学习认识各种特定表情。
● 复杂表情识别——借助云计算平台实现从数据中学习
在计算机硬件性能不足以支持大数据集的模型训练时,可以借助网络云计算平台,如www.openinnolab.org.cn。平台上有很多人工智能的案例,分为MMEdu和BaseEdu两个分支,本案例采用MMEdu的图像分类模块MMClassification(简称MMCls)完成模型训练,平台提供了CPU和GPU模式选择,本案例选择了GPU模式。
选择合适数据集,笔者把Kaggle比赛的7个情绪类公开数据集精简为4个,分别为开心(Happy)、生气(Angry)、伤心(Sad)、惊讶(Surprise),数据集图片类型为png图像,大小为48×48像素。trainning_set为训练集,val_set为验证集,test_set为测试集。四个数据集标签为:0 Angry;1 Happy;2 Sad;3 Surprise。文本文件classes.txt说明类别名称与序号的对应关系,val.txt说明验证集图片路径与类别序号的对应关系。数据集文件夹结构及对应文件如图3所示。

图3 数据集文件夹结构及对应文件
(1)克隆并搭建模型。首先通过平台提供的克隆操作,把平台提供的案例克隆到项目中并修改、运行。接着在导入MMedu的分类模块后,实例化一个神经网络模型,MMEdu提供了很多常用的网络模型,如LeNet、MobileNet、ResNet50等。指定分类的类别数,如本例中为4类。指定数据集路径和训练完成后数据集存放路径,即可完成模型搭建。上页图4所示为模型搭建代码。

图4 模型搭建代码
(2)模型训练。通过model.train()开始训练,把所有数据都训练一遍为一轮,共训练100轮,“validate=True”表示每轮训练后,在验证集上测试一次准确率,本案例用device=’cuda’表示选用GPU模式,实测100轮共训练了3.5小时(如图5)。
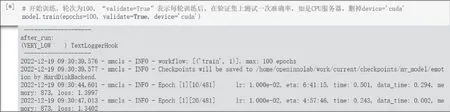
图5 模型训练代码及过程
(3)表情识别过程。当训练好模型后,上传要识别的图片yuxi.png,代码中要识别的图片改为上传图片,导入对应的模型文件,加载训练好的权重文件(best_accuracy_top-1_epoch_65.pth),指定后分类标签文件classes.txt,输出识别结果为开心(happy)(如图6)。

图6 表情识别过程代码及结果
通过分析代码,我们看到搭建模型只需要5行代码,训练模型需要1行代码,部署应用模型需要4行代码,相比之下,MMEdu结构简洁,代码复杂度低,特别适合于基础教育的人工智能教学。
● 表情识别应用——借助专用设备把表情投射到虚拟数字人
在本案例中,只要下载对应的包就可以实现简单的表情捕捉与投射,下面以unity为例进行脸部表情捕捉演示。
先在unity的PackManager包管理菜单中,使用“Add package from git URL”下载live capture包(URL填入com.unity.live-capture即可),并把自带的实例资源一起导入,示例资源可以直接使用。
在支持深感摄像头的IOS客户端的App Store中,查找并安装Unity Face Capture,在计算机端进行相应的防火墙设置,启动其companion App server后,启动移动端的Face Capture就可以连接计算机端,实时捕捉人脸表情,并投射到unity中的数字人面部(如图7)。

图7 用unity Face Caputer实现表情捕捉
除此之外,在unity中借助于相应插件,还可以把手部捕捉、人体姿态捕捉投射到对应数字人上,实现躯体的多种控制。
