流形正则引导的自适应加权多视角子空间聚类
2023-01-30林燕铭陈晓云
林燕铭 陈晓云
随着数据采集设备和技术的不断完善,多源异构数据不断涌现,而描述同一事物在不同角度或不同特征下表示信息的多视角数据是其典型代表.由于单视角学习方法无法直接用于多视角数据分析,因此,多视角学习成为机器学习领域的重要研究方向.
现有多视角聚类算法主要包括如下4类:基于协同训练的多视角聚类算法[1]、基于多核学习的多视角聚类算法[2]、基于图学习的多视角聚类算法[3]、基于子空间学习的多视角聚类算法[4].
基于图学习的多视角聚类算法和基于子空间学习的多视角聚类算法由于其良好的聚类性能,近年来引起学者们广泛关注.Nie等[5]提出AMGL(Auto-Weighted Multiple Graph Learning),将学习得到的不同视角图邻接矩阵融合成公共图邻接矩阵.Hajjar等[6]使用集群标签相关性构建一个额外的图,并利用平滑约束对聚类标签矩阵进行约束.
基于子空间学习的多视角聚类算法通常利用自表示学习获取不同视角一致的自表示矩阵,忽视对多视角数据多样性及互补性信息的描述,因此Si等[7]提出CDMSC2(Consistent and Diverse Multi-view Subspace Clustering with Structure Constraint),引入排他项(Exclusivity Term)强化不同视角差异的描述.Chen等[8]提出GLSR(Graph-Regularized Least Squares Regression),引入流形正则约束,保持不同视角的局部几何结构,并采用列稀疏性范数度量残差信息.Wang等[9]提出ARMSC(Auto-Weighted Graph Regulari-zation and Residual Compensation for Multi-view Sub-space Clustering),构造自适应图正则项以自适应调整不同视角权重,利用该权重集成多视角残差表示并融合一致表示,获取多视角数据的一致性和互补性特征.曹容玮等[10]提出双加权多视角子空间聚类算法,采用自适应加权策略构建共享系数矩阵,同时利用加权核范数将共享系数矩阵不同奇异值赋予不同权重.胡世哲等[11]提出基于内容的多视角特征表示和基于上下文的多视角相似度表示的双重加权多视角聚类算法,可充分利用多视角数据间的互补信息.
由于不同视角数据间既有共性又有特性,且不同视角数据质量也有差异,现有多视角子空间聚类方法或认为不同视角对一致性和差异性描述的贡献相同,或利用自适应学习方法对视角权重进行调整.前者导致最终结果容易受到噪声视角干扰,后者可能导致某一视角权重远大于其它视角的权重,进而陷入单一使用某个视角的困境.因此,本文提出流形正则引导的自适应加权多视角子空间聚类算法(Adaptive Weighted Multi-view Subspace Clustering Guided by Manifold Regularization, MR-AWMSC).算法采用核范数学习每个视角的一致性全局低秩表示信息,并利用F范数的组效应刻画不同视角的差异信息.根据流形正则的思想,自适应学习每个视角的权重,自动为每个视角的差异信息分配贡献度.再根据自适应权重集成差异信息并融合一致信息,获得最终的共识表示.最后利用该共识表示实现聚类.在6个公开数据集上的实验表明本文算法能有效提升多视角聚类性能.
1 相关知识
1.1 多视角子空间聚类
假设高维数据分布于多个低维子空间,子空间聚类目的是寻找这些低维嵌入子空间.该类方法通常利用字典表示思想(X=DZ)学习高维样本数据X的表示矩阵Z,并以样本集本身作为字典(D=X),所以也称为自表示模型.其表示矩阵Z可通过求解以下优化模型获得:
其中,第1项为自表示矩阵约束,第2项为重构损失,α为平衡参数,l-范数针对不同类型的噪声而有所不同.不同子空间聚类方法的差异主要在于模型目标函数第1项函数与第2项范数定义的不同.稀疏子空间聚类(Sparse Subspace Clustering, SSC)利用l1范数约束自表示矩阵(Ω(Z)=‖Z‖1)[12],且约束diag(Z)=0,第2项采用F范数约束噪声.而低秩表示(Low-Rank Representation, LRR)子空间聚类使用秩函数或核范数约束自表示矩阵(Ω(Z)=‖Z‖*)[13],并利用l2,1范数约束噪声.
多视角子空间聚类为每个视角数据Xv构造自表示矩阵Cv,公式如下:
(1)
其中,第1项Ω{·}为对不同视角自表示矩阵的约束,第2项L{·}为不同视角的重构损失.多视角样本集的最终邻接矩阵:
多视角数据不但具有一致性信息,并且每个视角又蕴含差异信息.为了同时表示多视角数据的一致信息和差异信息,分解式(1)的Cv=Z+Dv.则式(1)的多视角形式为
其中:第1项Ω{·}为自表示矩阵的一致性约束,可保证多视角数据一致表示矩阵的高类内同质性,刻画不同视角的共享信息;第2项R{·}为自表示的差异性约束,刻画每个视角的差异信息;第3项L{·}为重构损失.多视角样本集的最终邻接矩阵为:
然后将构造的邻接矩阵W输入传统的谱聚类中,得到聚类结果.
1.2 流形学习

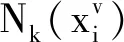
本文假设在多个视角中距离越近的样本越可能来自同一子空间,以此描述多视角聚类的一致性原则,构造多视角流形正则项如下:
其中拉普拉斯矩阵Lv=Dv-Sv,Dv为对角矩阵,
2 流形正则引导的自适应加权多视角子空间聚类
本文提出流形正则引导的自适应加权多视角子空间聚类算法(MR-AWMSC).考虑数据局部几何结构,利用流形正则动态调整每个视角贡献.然后使用交替方向乘子法(Alternating Direction Method of Multipliers, ADMM)[15]求解MR-AWMSC,推导每个子问题的闭式解.表1列出本文主要数学符号说明.

表1 主要符号说明Table 1 Description of main symbols
2.1 模型建立
多视角数据是对同一数据的不同特征描述,理想情况下每个视角学习的自表示矩阵Z应趋于一致,但是实际上多视角数据含有每个视角固有差异属性,Z不一定满足所有视角的相似性.因此本文提出MR-AWMSC,同时学习多视角数据的一致性和差异性信息,具体为
(2)
其中:第1项为所有视角的一致性自表示矩阵Z∈Rn×n的核范数,该项学习全局低秩表示,充分刻画多视角数据共享信息;第2项为第v个视角的差异信息表示矩阵Dv∈Rn×n的F范数,该项利用F范数的组效应性质,使不同视角的差异表示矩阵具有块对角性,更利于聚类;第3项为重构损失项,Ev∈Rdv×n为第v个视角的误差矩阵,利用l2,1范数约束Ev列稀疏,尽可能有效消除噪声视角,得到较干净的自表示矩阵Z;第4项为不同视角流形正则项,可在新的表示空间Z中保持不同视角数据的局部几何结构,利用该流形正则项可得到每个视角的贡献;平衡参数λD和λE分别用于平衡差异信息表示项和误差项.
已有多数方法计算最终邻接矩阵Z*时,是以平均加权策略集成不同视角差异表示Dv,再融合一致表示矩阵Z.
MR-AWMSC的视角权重可随流形正则项的大小同步迭代更新,对于m个视角权重{α1,α2,…,αm}:
(3)
在式(3)中,每个视角的权重能被自适应地设置和更新,根据流形正则项的大小自动为每个视角分配不一样的权重.由式(2)给出的目标函数可知,需要最小化各视角的流形正则项tr(ZLvZT),因此tr(ZLvZT)的值越小表明对应视角v的权重αv应越大,该视角也越重要.
利用m个视角权重可集成多视角差异表示矩阵Dv,并融合一致表示矩阵Z,得到最终的邻接矩阵:
(4)
MR-AWMSC示意图如图1所示.在图中,全局一致性表示矩阵Z体现多视角数据学习的一致性准则,视角差异矩阵Dv刻画不同视角信息质量的差异性.在保持多视角流形结构的同时,MR-AWMSC在优化过程中通过流形正则项自适应学习每个视角的权重,避免人工赋权方式导致权重设置困难.最终通过自适应学习得到Dv,并融合一致表示矩阵Z,获得邻接矩阵Z*,输入谱聚类中,得到聚类结果.

图1 MR-AWMSC示意图Fig.1 Architecture of MR-AWMSC
2.2 模型求解
MR-AWMSC目标函数(式(2))同时从多个视角中学习一致自表示矩阵和多个差异表示矩阵.该问题有多个变量,本文可利用ADMM求解变量.此外,本文还引入辅助变量J∈Rn×n,使目标函数中变量可分离,并分为多个子问题求解.首先,引入变量J作为核范数中Z的替代,则式(2)等价于:
因此,上述模型的增广拉格朗日函数形式可写为
λE‖Ev‖2,1+tr(ZLvZT)) +


1)更新一致表示矩阵Z,固定其余变量,
(5)
令上式对变量Z的导数为0,得到方程
AZ+ZB=C.
该方程是Sylvester等式,可利用MATLAB内置函数(lyap)直接求解,其中,
2)更新变量J,固定其余变量.J的优化问题只与Zt+1和Y2(t)有关,等价于求解如下问题:
(6)
上述问题可使用奇异值阈值[16]求解.令
先对Kt+1执行矩阵奇异值分解(即Kt+1=UΣVT),得到问题的解:
Jt+1=US1/μt(Σ)VT,
其中,Sε(x)为软阈值算子,Σ经过软阈值算子Sε(x)按元素操作,得到输出矩阵的对应元素为
3)更新差异信息表示矩阵Dv,固定其余变量,则
为了得到最优解,令上式目标函数关于变量Dv的导数为0,可得到差异信息表示矩阵的最优解:
(7)
其中I∈Rn×n为单位矩阵.
4)更新误差矩阵Ev,固定其余变量,则

令

(8)
5)更新自适应参数αv,固定其余变量.按照式(3)更新αv:
(9)
其中,γ>1,为控制收敛速度的常数,惩罚参数μ通过γ单调上升,直到满足最大值μmax.
当算法收敛后计算得到一致自表示矩阵Z和多个视角的差异信息矩阵{D1,D2,…,Dm}.最后,根据式(4)计算邻接矩阵Z*,并对Z*利用谱聚类的Ncut分割方法,得到最终的聚类结果.
综上分析,MR-AWMSC步骤如下.
算法MR-AWMSC
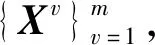
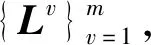
Θ1为0矩阵
输出聚类结果
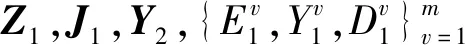
μ=10-6,μmax=106,,迭代次数t=1,
最大迭代次数M=90,ε=10-6,

Repeat:
step 1 根据式(5)更新一致表示矩阵Zt+1.
step 2 根据式(6)更新变量矩阵Jt+1.
step 3 Forv=1 tom:
step 5 计算
Until:
(Θt+1-Θt)<ε或t>M.
根据式(4)计算邻接矩阵Z*,并对Z*执行
Ncut谱聚类,得到聚类结果.
MR-AWMSC主要的时间复杂度由如下变量控制:Z,J,Dv,Ev和αv.更新变量Z为求解Sylvester方程,时间复杂度为O(n3).更新变量J为进行奇异值阈值分解,时间复杂度为O(n3).更新Dv的过程主要是对矩阵求逆,时间复杂度为O(n3+dvn2).更新αv的时间复杂度为O(n3).更新Ev的时间复杂度为O(dvn).因此,总的时间复杂度为O(n3+dmaxn2),dmax为多视角数据的最高维度.
3 实验及结果分析
实验环境为Intel(R) Core(TM) i9-9900K CPU @3.60 GHz,内存32 GB,64位Windows 10系统,并用MATLABR 2019b软件编程实现.
3.1 实验数据集
本文采用如下6个多视角聚类数据集进行实验:图像数据集MSRC_v1[18]、树叶数据集100leaves[8]、电影数据集Movies617[19]、文本数据集BBCSport[9]、手写数字数据集UCI-digit[20]和物体识别数据集Caltech101-20[9].实验前先对每个视角数据进行归一化处理.6个公开数据集的主要信息如表2所示.

表2 多视角数据集主要信息Table 2 Description of multi-view datasets
MSRC_v1数据集包括210幅图像,9个类别.本文从中选择树、建筑、飞机、奶牛、脸、汽车、自行车这7个类别,从每幅图像提取5 个视觉特征.
100leaves数据集包含100种不同植物叶片,每种植物都有16个样本,共1 600个样本.本文提取形状描述符、细尺度边缘和纹理直方图这3种特征.
Movies617数据集包含从IMDb网站收集的17种类别共617部电影,包含2个视角.
BBCSport数据集为包含5个主题领域的体育新闻数据集,包括2004年至2005年从BBC体育网站收集的544份文档,包含2个视角.
UCI-digit数据集共有2 000幅手写数字图像,0~9,共有10类,每类包含200幅图像,每幅图像采用3种视觉特征,构建3个视角.
Caltech101-20数据集包含101个图像类别.本文选择20个物体的2 386幅图像作为最终的数据集,使用6种特征提取方法提取6个视角特征.
3.2 对比算法
为了验证MR-AWMSC的有效性,与如下算法进行对比.
1)2种经典单视角子空间聚类算法.
(1)SSC[12].采用l1范数约束样本自表示矩阵.
(2)LRR[13].采用核范数约束样本自表示矩阵.
2)9种经典多视角聚类方法.
(1)ECMSC(Exclusivity Consistency Regularized Multi-view Subspace Clustering)[21].引入位置注意力排他项,衡量不同视角之间的差异性,同时定义指示向量一致性项.
(2)DiMSC(Diversity-Induced Multi-view Sub-space Clustering)[22].利用希尔伯特-施密特独立性准则生成异构性项,描述多视角表示的相关性,多视角融合采用平均加权策略.
(3)LMSC(Latent Multi-view Subspace Cluste-ring)[23].学习多视角数据潜在的统一子空间表示.
(4)CSMSC(Consistent and Specific Multi-view Subspace Clustering)[24].利用一致表示刻画不同视角间的共同属性和一组特定表示描述每个视角的内在特性,多视角融合采用平均加权策略.
(5)FCMSC(Feature Concatenation Multi-view Subspace Clustering)[19].拼接多视角数据特征,利用l2,1范数处理多视角数据中基于样本和簇类的噪声,多视角融合采用平均加权策略.
(6)ARMSC[9].采用核范数学习一致性全局低秩表示,具有组效应的F范数学习残差补偿项,并构造自动加权多视角正则项,保持局部几何结构.
(7)GMC(Graph-Based Multi-view Clustering)[25].将不同视角的图矩阵通过图学习误差自动加权融合为一个一致图矩阵,并约束图拉普拉斯矩阵的秩.
(8)文献[26]算法.核学习多视角聚类算法,定义邻居核以保持块对角结构,增强对基核间噪声和异常值的鲁棒性.线性组合基邻居核,通过精确秩约束子空间分割构造一致邻接矩阵.
(9)MVC-LFA(Multi-view Clustering via Late Fusion Alignment Maximization)[27].核学习多视角聚类方法,最大限度对齐一致核矩阵与加权基核矩阵,集成多视角数据.
3.3 聚类实验结果
本文实验采用如下4个聚类性能评价指标:聚类准确率(Clustering Accuracy, ACC)、标准互信息(Normalized Mutual Information, NMI)、调整兰德指数(Adjusted Rand Index, ARI)和F-score.指标值越高,聚类性能越优.
由于本次实验采用多视角数据集,因此2种单视角子空间聚类算法(SSC和LRR)仅给出最佳视角的聚类结果.为了减少谱聚类结果的随机性,MR-AWMSC执行10次,取10次结果的平均值作为最终结果.
12种聚类算法在6个多视角实验数据集上的聚类指标分别如表3~表8所示.在表中,黑体数字表示最优值,斜体数字表示次优值.由表3~表8可得如下结论.
1)MR-AWMSC在6个数据集上的ACC、ARI、F-score值均是最高的.除Caltech101-20数据集之外,MR-AWMSC在其它5个数据集上的NMI值也是最高的.该结果表明流形正则引导的自适应视角权重学习算法是有效的.
2)多视角聚类算法虽然综合多视角的信息,但单视角子空间聚类算法(SSC、LRR)在MSRC_v1、Caltech101-20数据集上的聚类表现优于ECMSC、DiMSC、FCMSC这3种多视角子空间聚类算法.该结果说明如果未采用合理方式融合多视角数据间的关联信息,多视角聚类算法性能反而不如单视角聚类算法.
3)相比基于子空间学习的多视角聚类算法FCM-SC、DiMSC和ECMSC,MR-AWMSC引入流形正则项,保持数据的局部几何结构,并使用流形正则引导不同视角权重的自适应学习,因此聚类性能更优.FCMSC直接拼接多视角特征,忽略不同视角的差异性.DiMSC将所有视角的相似矩阵进行相加,结果易受噪声视角的影响.ECMSC只考虑不同视角数据的全局结构却忽视不同视角数据局部流形结构的差异.

表3 各算法在MSRC_v1数据集上的聚类结果对比Table 3 Clustering result comparison of different methods on MSRC_v1 dataset
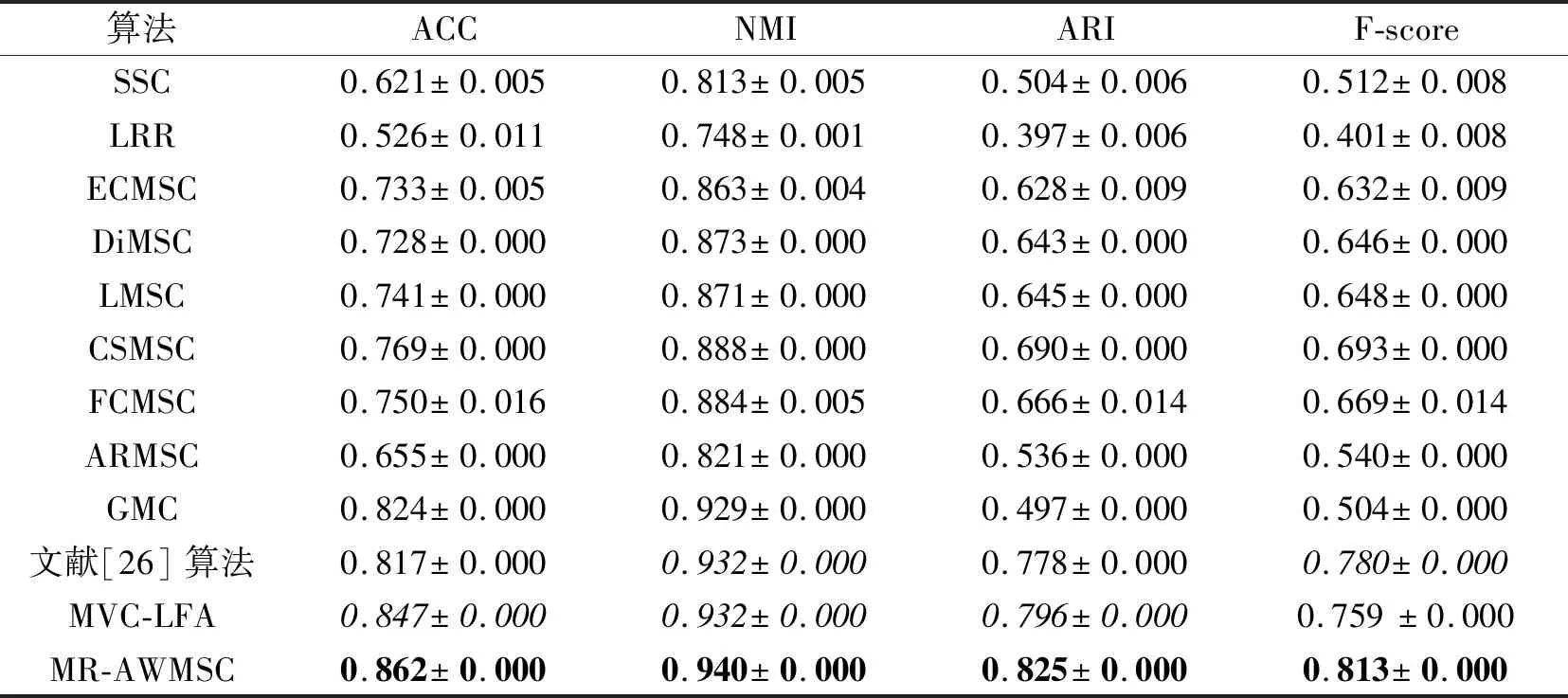
表4 各算法在100leaves数据集上的聚类结果对比Table 4 Clustering result comparison of different methods on 100leaves dataset
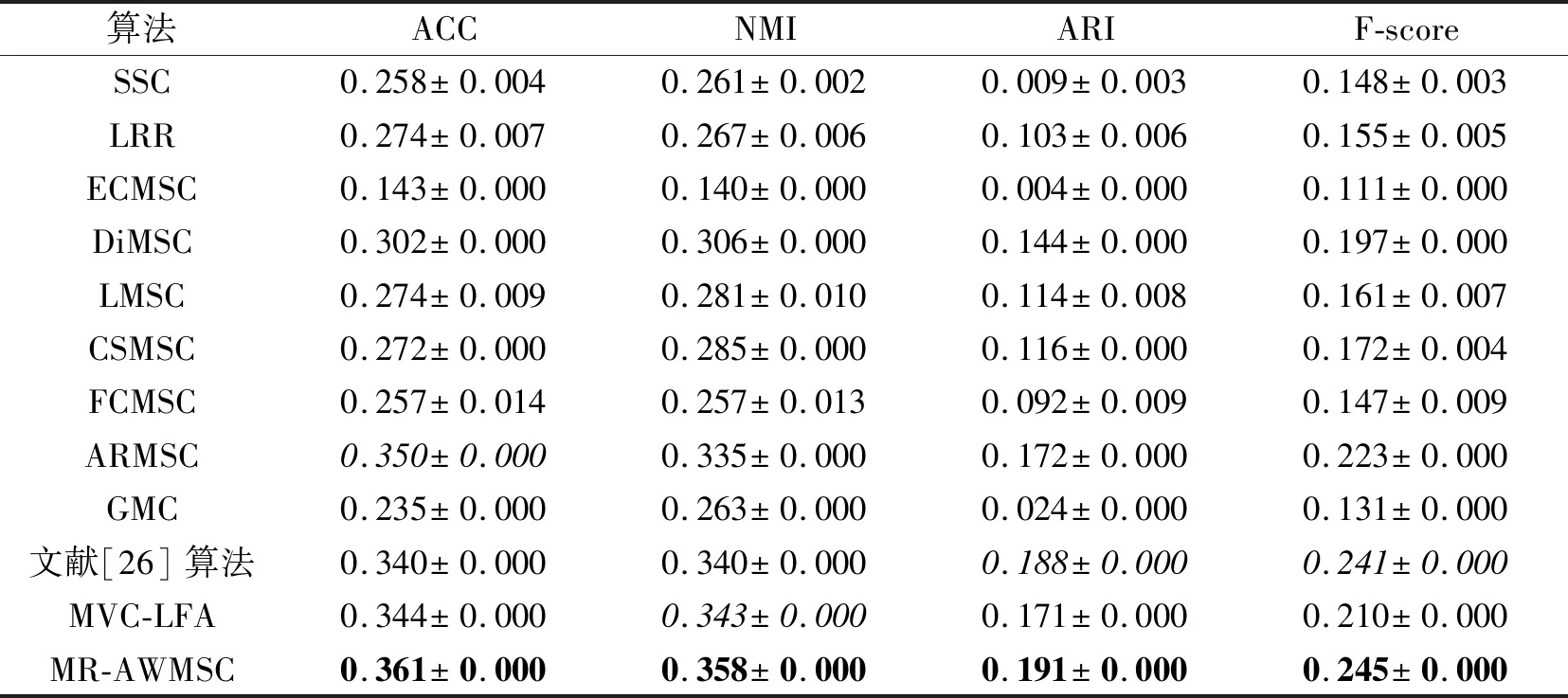
表5 各算法在Movies617数据集上的聚类结果对比Table 5 Clustering result comparison of different methods on Movies617 dataset
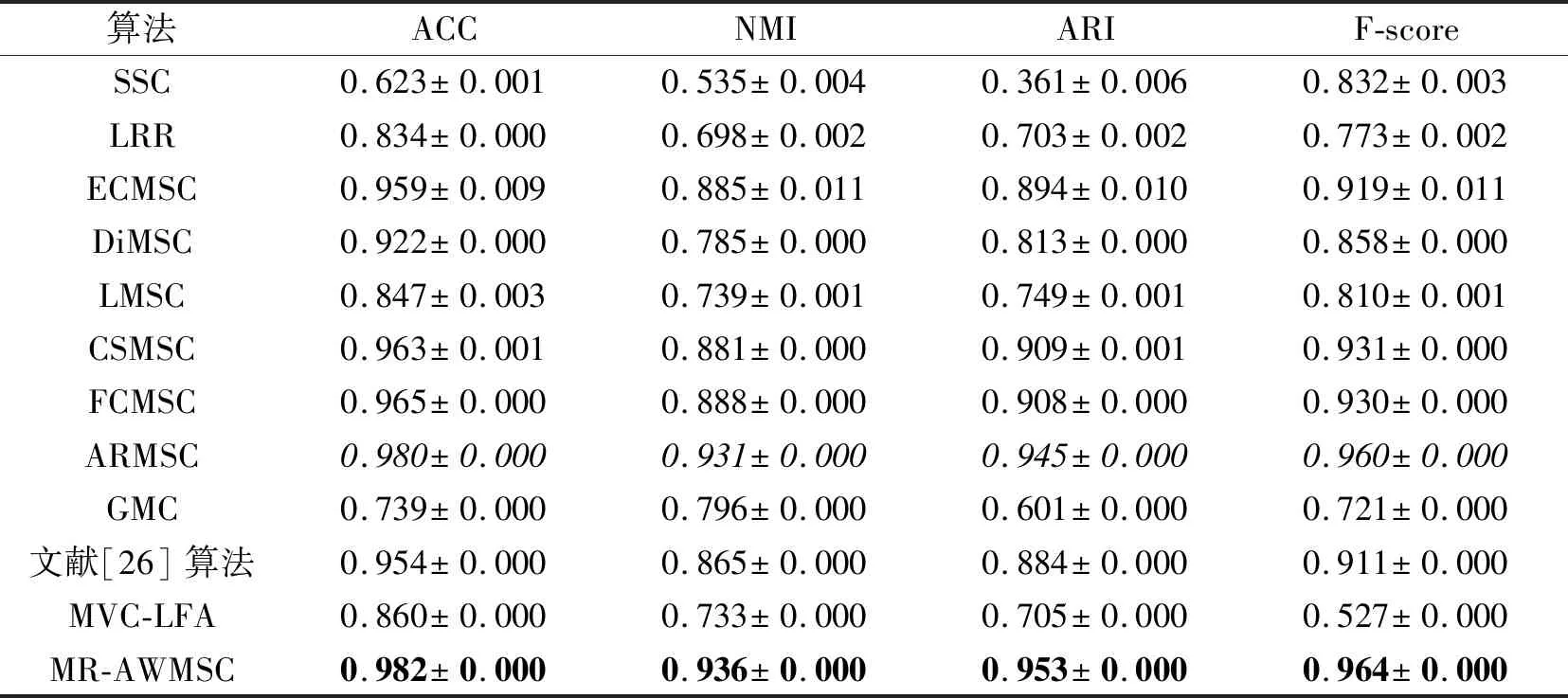
表6 各算法在BBCSport数据集上的聚类结果对比Table 6 Clustering result comparison of different methods on BBCSport dataset

表7 各算法在UCI-digit数据集上的聚类结果对比Table 7 Clustering result comparison of different methods on UCI-digit dataset

表8 各算法在Caltech101-20数据集上的聚类结果对比Table 8 Clustering result comparison of different methods on Caltech101-20 dataset
4)相比基于图学习的多视角聚类方法GMC,MR-AWMSC在6个数据集的各项评价指标上均更优.其原因是GMC未考虑多视角差异信息,构造的统一相似图易受噪声影响.而MR-AWMSC利用流形正则项自适应学习视角权重,可更恰当地集成不同视角的差异信息,获得更优的聚类性能.
5)相比基于核学习的多视角聚类方法(文献[26]算法和MVC-LFA),MR-AWMSC在MSRC_v1、UCI-digit、Caltech101-20数据集上的聚类性能更具竞争力.其原因在于,核方法中核函数的选择可直接影响最终聚类性能,同时二者的多视角加权融合策略未考虑不同视角非线性结构的差异.然而相比其它多视角聚类算法,文献[26]算法和MVC-LFA在一些数据集上的聚类准确率较高,说明核方法对于改善非线性数据的聚类性能也是有效的.
6)相比同是自适应视角权重学习的ARMSC,MR-AWMSC的聚类准确率更高.其原因在于,相比ARMSC 的自适应图正则项,本文的流形正则引导的自适应视角权重更能充分刻画每个视角的一致信息和差异信息,而 ARMSC在某些视角上的权重分配较低,往往导致过于关注某个单一视角的困境,无法充分综合利用多视角信息.
MR-AWMSC在MSRC_v1、BBCSport数据集上学习的邻接矩阵的可视化结果如图2所示.

(a)MSRC_v1
由图2可看出,MR-AWMSC在MSRC_v1、BBC-Sport数据上得到的邻接矩阵都具有明显的块对角结构,由此可说明MR-AWMSC学习得到的邻接矩阵适用于聚类.
3.4 不同加权策略实验
为了对比不同加权组合策略对多视角子空间聚类的影响,本文分别采用平均加权策略和自表示学习误差加权策略作为对比方法.平均加权策略的第v个视角权重αv=1/m,m为视角数,所有视角权重相同.算法其它部分与MR-AWMSC相同,记为AWMSC(Average Weighted Multi-view Subspace Clustering),组合得到邻接矩阵:
自表示学习误差加权策略的第v个视角权重为:
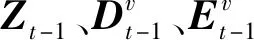
在6个多视角数据集上对AW-MSC、SL-MSC和MR-AWMSC进行聚类实验,每种方法均取10次聚类平均准确率,结果如图3所示.
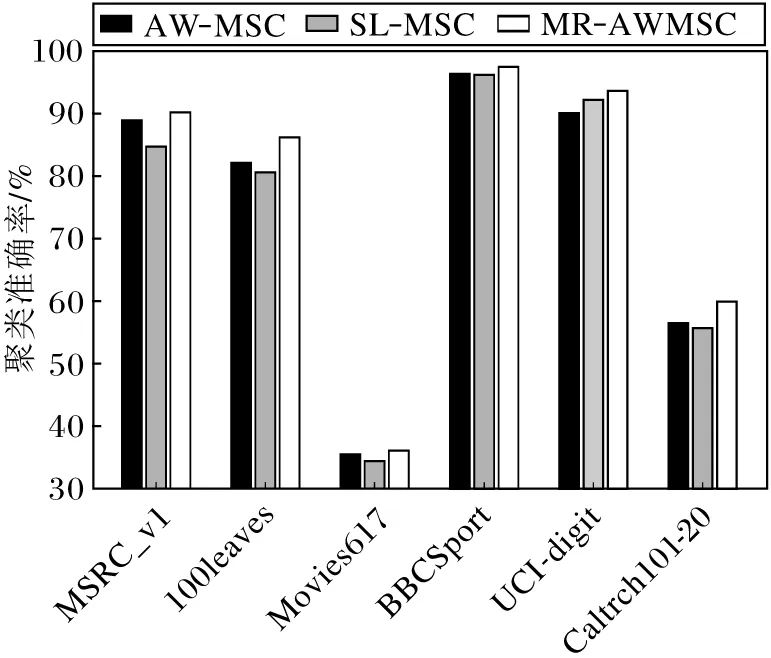
图3 3种加权策略的聚类准确率Fig. 3 Clustering accuracy of 3 weighting strategies
由图3可看出,MR-AWMSC在6个数据集上的聚类准确率最高,而SL-MSC在除了UCI-digit数据集以外的数据集上的聚类准确率均低于AW-MSC.其原因是SL-MSC学习获得的视角权重与数据线性自表示有关,不能较好地捕获非线性多视角数据的非线性结构特征,因此学习的视角权重多数情况下还不如AW-MSC有效.相比MR-AWMSC,AW-MSC同等看待每个视角,忽略不同视角对于聚类效果的贡献具有差异性,某些数据集上的聚类性能不佳.总之,MR-AWMSC的流形正则引导的视角权重有效提取数据的流形结构信息,并自动为不同视角差异性分配贡献度,因此优于SL-MSC和AW-MSC.
3.5 数值收敛性分析和参数选择
为了观察MR-AWMSC的数值收敛性,给出100leaves、UCI-digit数据集上算法的迭代误差曲线,如图4所示.

图4 MR-AWMSC在2个数据集上的收敛性分析Fig.4 Convergence analysis of MR-AWMSC on 2 datasets
由图4可看出,随着迭代次数增加,迭代误差不断下降,45次后趋近于收敛,说明MR-AWMSC是数值收敛的.
MR-AWMSC包含2个平衡参数λE和λD,分别用于平衡误差项和不同视角差异表示矩阵项.为了观察平衡参数对聚类准确率的影响,采用网格搜索法计算λE和λD不同取值下的聚类准确率,如图5所示.λE和λD的取值范围均为{0.001,0.005,0.01,0.05,0.1,0.2,0.4,0.5,1}.
由图5可看出,λE和λD的取值对聚类准确率的影响是明显的.在Movies617、100leaves数据集上,平衡参数λD值为0.4~1,λE值为0.001~0.01时,可得到较高的聚类准确率.在MSRC_v1、UCI-digit数据集上,λD和λE的值均为0.001~0.01时,聚类准确率较高.在Caltech101-20、BBCSport数据集上,λD和λE值均为0.2~1时,可得到较高的聚类准确率.因此若在一个合理的范围内选择参数,可得到较好的聚类结果.

(a)Movies617 (b)100leaves (c)MSRC_v1
4 结 束 语
本文提出流形正则引导的自适应加权多视角子空间聚类算法(MR-AWMSC).算法的视角权重可随流形正则项的大小迭代更新,利用视角权重集成多视角差异表示矩阵,并融合一致表示矩阵,得到最终的邻接矩阵.MR-AWMSC通过对视角自适应加权获得的邻接矩阵既蕴含不同视角的全局低秩一致性信息,也考虑不同视角的差异,得到比经典平均赋权的视角组合方法更优的结果.在6个基准数据集上进行聚类实验,结果表明MR-AWMSC是有效的.
