融合一维Inception 结构与ViT 的恶意加密流量检测
2023-01-27孙懿高见顾益军
孙懿,高见,2,顾益军
(1.中国人民公安大学 信息网络安全学院,北京 100038;2.安全防范与风险评估公安部重点实验室,北京 102623)
0 概述
随着信息技术的发展及公众对隐私与安全的日益关注,非加密的数据传输方式逐渐被加密传输所取代[1]。加密技术的不断发展,使得加密流量在互联网流量中的占比也不断上升,根据互联网研究趋势报告统计,大约有87%的Web 流量是加密的[2]。加密流量在一定程度上保障了用户隐私与安全,但攻击者也通过加密技术来隐藏恶意程序和服务器之间的交互,从而逃避防火墙和网络入侵检测系统等[3]。因此,如何在加密流量背景下有效识别出恶意加密流量,对于维护网络空间安全、抵御网络攻击具有重要意义。
目前针对恶意流量检测的方法大致可分为4 种方式[4]:基于端口号,深度包检测,机器学习和深度学习。基于端口号的方法,即根据数据包包头中的端口号来区分不同种网络应用类型(例如FTP 流量的21 端口、HTTP 流量的80 端口等)。但随着随机端口策略[5]、端口伪装技术[6]等手段的普遍使用,使得基于端口对恶意加密流量进行检测变得十分困难。MOORE 等[7]通过实验发现,目前基于端口进行流量分类的方法在最佳情况下也仅有31%的准确率。基于深度包检测的方法则通过分析整个数据包数据,根据匹配预定义模式来判定流量所属种类。然而,加密技术的使用对网络流量载荷数据进行加密或协议封装,使得这种通过对流量数据进行逐字节匹配的方法在加密流量上变得不再可行。为克服基于深度包检测方法存在的问题,研究人员提出一种将特征工程与机器学习算法相结合的检测方法。不同种类的应用所产生的流量特性有所差异,通过提取能够体现这些特性的特征数据[8],并结合机器学习的方法进行流量分类。但是基于机器学习的方法在很大程度上依赖于所选取的流量特征,往往很难找到有效区分的特征,从而导致模型分类准确率低下[3]。深度学习则通过端到端的方式,能够自动从原始流量中提取特征并进行分类,省去了繁琐的人工提取特征,成为目前检测恶意加密流量的主流方式。虽然深度学习模型能够自动提取特征并进行分类,但是不同的模型结构会生成不同的表征,从而致使模型性能有所差异。因此,如何搭建深度学习模型,生成有效表征以提高恶意加密流量的检测率是值得研究的问题。
为得到更好的特征表示以提高模型的检测结果,并对恶意加密流量进行区分,本文设计一种融合一 维 Inception 结构和 ViT(One-Dimensional Inception structure and Vision Transformer)的恶意流量检测模型,并在公开数据集USTC-TF2016 上通过对比变体模型、常见模型来验证该模型的有效性。
1 相关工作
随着人工智能和大数据的发展,深度学习算法在计算机视觉(Computer Vision,CV)、自然语言处理(Natural Language Processing,NLP)等领域取得了较好的成绩,恶意流量检测领域的研究人员也开始以不同的表示方法处理流量数据,并利用深度学习模型自动提取特征实现检测。
WANG 等[9]将一维卷积神经网络(One-Dimensional Convolutional Neural Network,1DCNN)应用到加密流量分类上,并验证了其假设,即流量是一维的序列数据,1D-CNN 相较于二维卷积神经网络(2D-CNN)更适合流量特征的提取,此外还创建了一个USTC-TFC2016 数据集,并开发了该数据集上的预处理工具[10]。梁杰等[11]则通过将流量包按照最大内容长度截取并对其进行独热编码,之后再利用GoogLeNet[12]实现流量分类,此外还对比了LeNet[13]等模型,证明该方法的有效性。
除将流量数据表示为图像数据并根据卷积神经网络(CNN)进行空间特征提取外,利用网络流量本身具有的时序性特点,即具有“字节-数据包-数据流”的层次结构,使用循环神经网络(Recurrent Neural Network,RNN)对流量进行时序特征提取也是一种常见的检测方式。叶晓舟等[14]利用流量的层次结构,首先对数据包进行独热编码处理,并使用双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络提取数据包的时序特征,然后将一个网络流内的数据包特征进行拼接,再利用BiLSTM提取其网络流时序特征并进行分类。
ZHUANG 等[15]按照五元组(源IP 地址、源端口、目的IP 地址、目的端口、协议)方式对原始流量进行切分并在同一流内选取3 个连续数据包,类比RGB图像并利用CNN 对其进行特征提取,之后输入到LSTM 中提取3 个连续数据包的流特征,最终实现分类。该类方法使用CNN 对数据包特征进行提取,再利用LSTM 在CNN 特征提取的基础上提取流量时序特征,最终融合CNN 与LSTM 提取网络流量的时空特征。
目前基于深度学习对流量进行特征提取的方法大致可分为3 种方式:将流量数据转换为图像数据利用CNN 对流量进行空间特征提取,将流量视为字节-数据包-网络流序列结构使用RNN 提取时序特征,将CNN 与RNN 融合提取流量的时空关联特征。此外,刘冲[16]提出了HABBiLSTM 检测模型,该模型采用同文献[14]类似的模型结构,但并没有对数据进行独热处理,而是将注意力机制融入到各层次特征提取中,以验证注意力机制能够提升模型效果。
尽管上述研究均取得了较好的结果,但目前该领域研究大多在未加密流量上进行实验。为了更好地提取加密流量表征,有效检测恶意加密流量,本文通过改进Inception 结构并与ViT[17]相融合,构建一维Inception-ViT 模型,以实现更好地检测恶意加密流量。
2 一维Inception-ViT 模型设计
2.1 总体架构
本文模型架构如图1 所示,通过使用端到端的方式实现恶意加密流量检测。首先,对原始流量数据集进行预处理,通过会话切分、数据清洗、数据混淆、统一大小、数据转换等步骤,将其转换成模型所需格式,方便后续进行处理。其次,将处理好的数据输入到CNN 特征提取模块,使用改进的一维Inception 结构来提取更丰富的空间特征信息。最后,将得到的特征向量输入到ViT 模块中,利用多层感知机(Multilayer Perceptron,MLP)获取多个特征组合表示,再计算每个块特征的权重值并输出加权特征向量,突出重点特征,迭代多层后,将最终的特征向量输入到全连接层中得到最终分类结果。
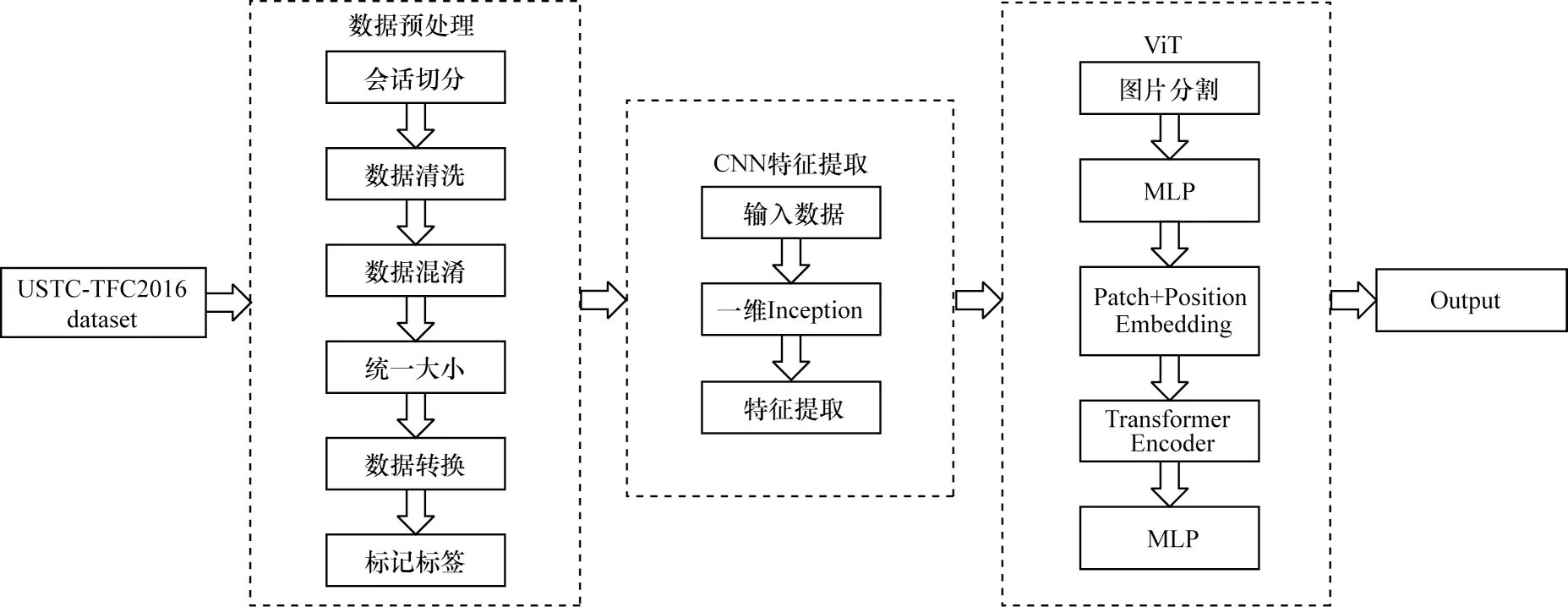
图1 一维Inception-ViT 模型整体架构Fig.1 Overall architecture of one-dimensional Inception-ViT model
2.2 数据预处理
本文所使用的数据集是文献[10]所设计的USTC-TFC2016 数据集,该数据集包括10 种恶意加密流量和10 种正常网络应用流量,样本数据集均为PCAP 文件格式。表1 为本文所使用的数据集,其中,左侧为10 种正常网络流量,由IXIA BPS 仿真设备生成,右侧为10 种恶意加密流量,选自CTU 研究人员采集于真实网络环境中的恶意软件流量,数量列为经过预处理后生成的样本数量。

表1 数据集描述Table 1 Dataset description
网络流量的切分方式可分为5 种[18]:TCP 连接的方式,即按照TCP 协议中的三次握手和四次挥手相应的标志位进行切分;流的方式,即按照五元组(源IP地址、源端口、目的IP 地址、目的端口、协议)进行切分,具有相同五元组的数据包属于同一个流,也可以通过设置流超时或重置判定结束;会话的方式,会话也可以看作是双向流,五元组内的源和目的部分可以互换;服务的方式,按照建立服务所使用的端口号对进行划分,所有使用该端口号对的流量均视为同一组;主机的方式,即按照主机所产生的流量进行切分,即来自主机产生的流量、主机接收来自哪里的流量。
本文对原始PCAP 文件以会话的方式进行切分,相较于其他切分方式,会话能够保存通信双方之间的交互流量,携带更多的信息。具体处理过程如图1 中数据预处理模块所示。
1)会话切分:使用SplitCap[19]将原始PCAP 文件以会话方式切分成小单元。
2)数据清洗:在切分后的数据单元中,部分数据可能丢失了区分恶意加密流量和正常流量的关键信息,一个完整的通信会话标志是完成握手、互相进行应用数据的交互[20],因此本文仅保留了有应用数据的会话,以实现数据清洗。
3)数据混淆:Mac 地址和IP 地址并不是区分不同种流量的有效信息,相反模型如果学习了该类信息反而会造成过拟合,因此本文采用随机替换的方式对Mac 地址和IP 地址进行混淆。
4)统一大小:不同的通信会话,传递的网络数据包数量和大小存在差异,同一网络结构其输入网络的数据形状是固定的,因此需要将会话统一至相同大小[20]。为了更好地进行对比实验,本文参考制作USTC-TFC2016 数据集的原始论文数据预处理方式,最终选取784 Byte 作为会话流固定长度。对于切分后会话长度小于784 Byte 的数据则在末尾填充0x00,对于长度大于784 Byte 数据则进行截断。
5)数据转换:将原始十六进制的数据转换成十进制,并以大小为28×28 的灰度图像进行存储,对生成的灰度图像按照类别随机采样,如图2 所示。

图2 20 类流量的灰度图像Fig.2 Gray scale image of twenty types of traffic
6)标记标签:将灰度图像按照类别存放在标签命名的文件夹下。
2.3 CNN 特征提取模块
编码器具体结构如图3 所示,其中,数字大小即为该层所使用的核参数大小,卷积层、池化层均采用填充的方式,两者的步长分别为1 和2,然后再将提取后的特征向量转换成大小为14×14 的特征图输入到ViT 模块,进行下一步的操作。
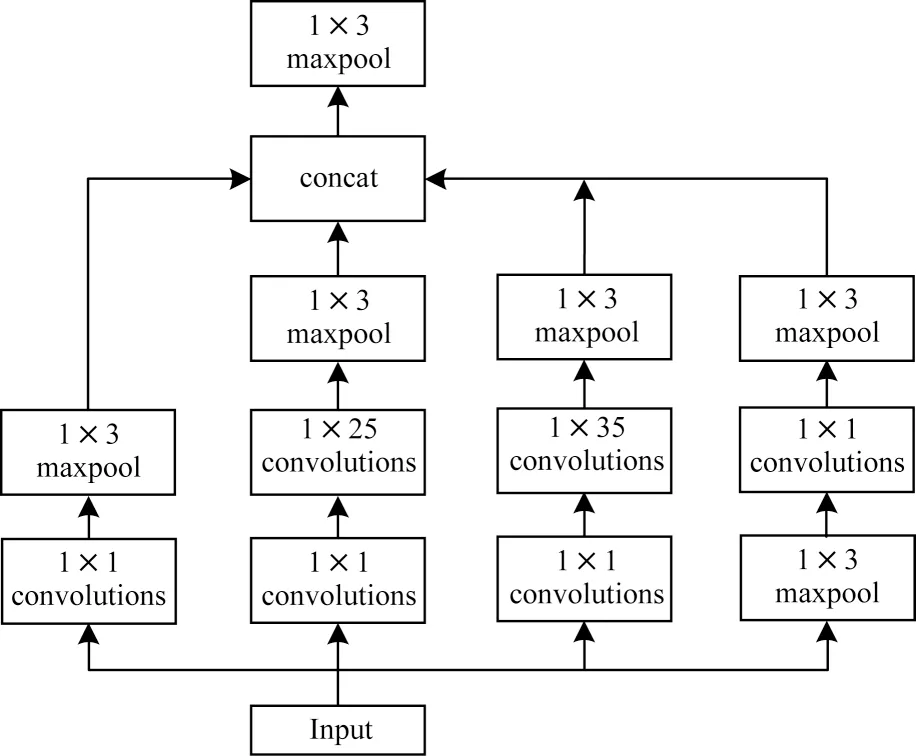
图3 一维Inception 结构Fig.3 Structure of one-dimensional Inception
在典型的GoogLeNet网络中,其特有的Inception结构相较于直接增加网络深度和卷积层数量[11],在多尺度卷积核上提取图像的不同尺度特征,能够在分类时提供更丰富的视野,此外Transformer 编码器缺少卷积神经网络内固有的一些归纳偏置[21]。因此,本文添加了CNN 特征提取模块,对原Inception结构进行改进,使用一维卷积替换原有二维卷积,同时添加池化层在保持特征不变性的前提下去除一些冗余信息[22],防止模型过拟合。
2.4 ViT 模块
经典ViT 模型主要使用Transformer 编码器[23],该编码器由一个多头注意力(Multi-Head Attention,MHA)和前馈网络(Feed-Forward Network,FFN)两个子层构成。其中FFN 层实质上就是两层线性映射,每个子层前使用层标准化(Layer Normalization,LN),每个子层后使用残差连接,Transformer 编码器结构如图4 所示。

图4 Transformer 编码器结构Fig.4 Transformer encoder structure
如图4(a)所示,在Transformer 块中对于序列中任何位置的任何输入X∈Rd,都需要满足Sublayer(X)∈Rd,以便进行残差连接X+Sublayer(X)∈Rd,其中Sublayer(X)为子层所实现的函数。层标准化的作用是将神经网络中某一层的所有神经元进行归一化,加快模型训练速度、加速收敛。假设该层有D个神经元,该层输入X={x1,x2,…,xD},层标准化计算如式(1)所示:

其中:ϵ的作用是为了防止分母为0;μ为均值;σ2为方差。
μ、σ2的计算如式(2)、式(3)所示:
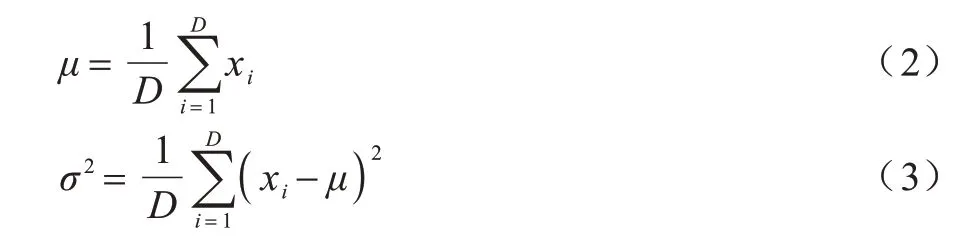
注意力机制就是让机器对于模型输入的不同部分赋予不同的权重,以突出关键信息。对于输入的序列X={x1,x2,…,xD},其中,xt为第t个向量,使用多层感知机对xt做三次线性变换,由xt向量衍生出qt、kt、vt。再将所有向量衍生出的qt、kt、vt拼成向量矩阵,并分别记作查询矩阵Q、键矩阵K、值矩阵V:

注意力权重则是通过计算查询和键的相关性并进行softmax 计算得到的,其中本文所使用的ViT 模块以点积的方式计算两者的相似性,之后将得到的注意力权重与值矩阵V进行加权求和,最终得到注意力输出。具体计算过程如式(5)所示:

多头注意力就是对于输入序列使用不同的权重矩阵进行h次线性变换,得到不同的注意力输出hi,最终合并出全局特征H=Concat(h1,h2,…,hh),再利用多层感知机将其转换至想要的向量维度,如图4(b)所示。
ViT 模块通过对图像数据进行切分,将其转换为一维图像块序列,从而使Transformer 能够对其进行处理,其模型结构如图5 所示。
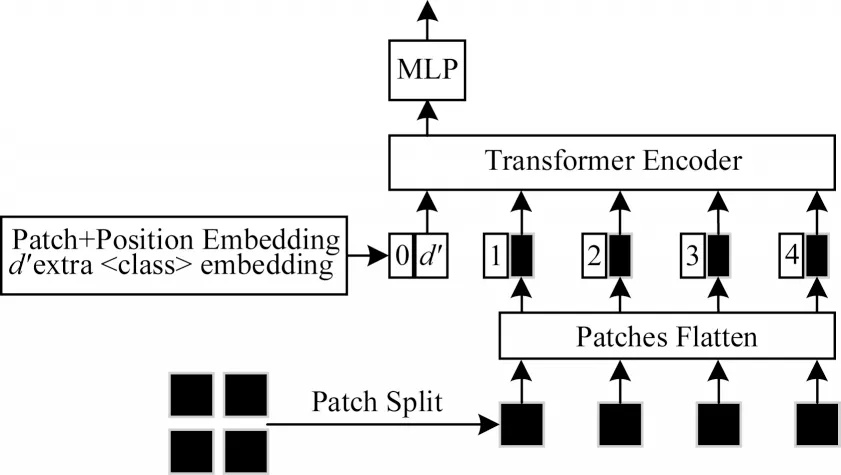
图5 ViT 模型结构Fig.5 ViT model structure
ViT 模型结构步骤如下:
2)图像块嵌入:将图像块从(N,P2×C)转化为(N,D),利用MLP 做一个线性变换。此外,人为追加一个用于分类的可学习向量<class >,方便日后对序列数据进行分类。
3)位置编码:由于Transformer 编码器并没有像循环神经网络那样的迭代操作,因此需要将切分后的图像块位置信息提供给Transformer 编码器,即在图像块嵌入中添加位置编码向量。
4)Transformer 编码器:由多个Transformer 块组成,对经过步骤1~步骤3 处理后的图像块序列进行特征提取。
5)多层感知机(MLP):将经过Transformer 编码器处理后,用于分类的可学习向量<class >提取,并接入到全连接层进行分类。
3 实验结果与分析
3.1 实验环境和模型超参数设置
本文实验操作系统为Windows 11 家庭中文版,GPU 型号为GeForce RTX 3070,cuda 版本为11.4,使用Anaconda3-4.10.3 版本编辑环境,python 版本为3.7。
一维Inception-ViT 模型参数设置如下:在预处理过程中,统一会话流大小为784 Byte;在CNN 特征提取模块,一维Inception 结构卷积核尺寸如图3 所示,卷积核个数分别为32、[32,64]、[16,32]、32,激活函数为relu,经过该模块处理后图片从28×28 大小变成14×14;在ViT 模块,图片输入大小为14×14,图像块尺寸为7×7,图像块嵌入大小为64,在Transformer 编码器中Transformer 块个数为4,多头注意力的个数为2,多头注意力线性变换大小为64,其他MLP 维度均为128。模型选择交叉熵作为损失函数、Adam 优化算法,批大小为50,学习率lr为1×10-4,epoch 大小为10。
3.2 评价指标
由于本文主要对恶意加密流量进行多分类检测,为了更好地衡量模型对恶意加密流量检测效果,主要选取平均召回率(Average Recall,AR)、平均F1值(Average F1_Score,AF)作为评价指标。其中平均召回率和平均F1 值为每一类流量的召回率(R)和F1 值(F1_Score,F)的调和平均值,N为数据集中种类总数,TTP为将A类流量预测为A类的样本数,FFP为将非A类流量预测为A类的样本数,TTN为将非A类流量预测为非A类的样本数,FFN为将A类流量预测为非A类的样本数。计算过程所涉及的精确率(P)等具体计算公式如式(6)~式(10)所示:

3.3 实验结果
3.3.1 一维Inception-ViT 模型参数选择
不同的Transformer 块个数m可以组成不同深度的ViT 模型,不同的多头注意力并行头个数h形成不同的Transformer 块。过多或过少的模型深度或并行头个数均有可能造成有效特征的缺失或干扰[24],从而影响模型的检测结果。因此,本文设置Transformer 块个数取值为1、2、3、4、5、6,多头注意力并行头个数取值为1、2、4、6、8,在公开数据集USTCTFC2016进行30组实验。使用平均召回率、平均F1值作为评价指标,以选取最佳超参数组合。实验最终结果如图6、图7 所示,其中,x轴为Transformer 块个数m,y轴为评价指标值,图例为多头注意力并行头个数h。

图6 不同超参数组合的平均召回率实验结果Fig.6 Experimental results of average recall of different superparametric combinations

图7 不同超参数组合的平均F1 值实验结果Fig.7 Experimental results of average F1 value of different superparametric combinations
从图6、图7 可以看出:当Transformer 块为4 且并行头个数为2 时,平均召回率值和平均F1 值分别为99.42%和99.39%,均优于其他超参数组合。固定模型深度即Transformer 块个数,可以看出随着并行头个数的增加,模型性能并非一直提升,过多的并行头数量可能会加剧噪声的干扰,反而会使模型性能下降。同样,固定并行头数量随着模型深度的增加,模型性能并非一直上升。合适的Transformer 块个数与并行头个数能够更有效地提取流量特征,因此本文最终选取Transformer 块个数为4、多头注意力并行头个数为2 的ViT 模块。
3.3.2 不同CNN 特征提取模块对比实验
为评估一维Inception-ViT 模型中CNN 特征提取模块的有效性,设计以下变体模型,除改动外模型其他参数保持一致:
1)ViT 模型。去除CNN 特征提取模块,仅使用ViT 模块对流量数据进行分类。
2)一维Inception 模型。去除ViT 模块,仅使用改进后的一维Inception 结构连接两层全连接层进行分类,其中全连接层的维度为128。
3)1D-CNN-ViT 模型。替换所使用的CNN 特征提取模块,具体模块结构如图8 所示,采用两层一维卷积加最大池化结构用于特征提取,其中卷积核个数设置为[32,64]。

图8 一维卷积结构Fig.8 Structure of one-dimensional convolution
4)2D-CNN-ViT模型。同1D-CNN-ViT 模型结构类似,但使用二维卷积,具体模型结构如图9所示。

图9 二维卷积结构Fig.9 Structure of two-dimensional convolution
5)Inception-ViT 模型。使用原始Inception 结构作为CNN 特征提取模块,模型结构如图10 所示,此外为将大小统一,添加了核大小为3×3 的最大池化层。
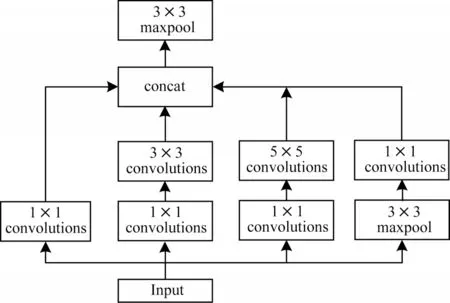
图10 Inception 结构Fig.10 Structure of Inception
6)No_Pooling-ViT 模型。去除了最大池化操作,具体模型结构如图11 所示。

图11 去除池化操作后结构Fig.11 Structure of removing the pooling operation
表2 给出了一维Inception-ViT 模型与其变体模型的对比结果。可以看出一维Inception-ViT 模型性能最好,在平均召回率和平均F1 值指标上分别达到99.42%和99.39%,相较于仅使用单一模块的ViT 模型和一维Inception 模型有所提升。此外,去除池化操作后的No_Pooling-ViT 模型相较于一维Inception-ViT 模型性能有所下降,说明池化操作的下采样有助于减少冗余信息,提升模型的检测结果。对比有无添加Inception 结构的4 种模型(1D-CNN-ViT 和一维Inception-ViT、2D-CNN-ViT 和Inception-ViT),添加Inception 结构的模型均比没有添加Inception 结构模型性能有所提升,说明多尺度卷积核能够提取更丰富的特征信息,使得模型分类更为准确。对比一维卷积和二维卷积模型(1D-CNN-ViT 和2D-CNNViT、Inception-ViT 和一维Inception-ViT),使用一维卷积的模型都比使用二维卷积的模型性能要好,甚至1D-CNN-ViT 模型比添加了Inception 结构的二维卷积Inception-ViT 模型效果更好,即在时序性数据上一维卷积比二维卷积更适合。

表2 多分类下不同变体模型AR 和AF 结果对比Table 2 Comparison of AR and AF results of different variant models under multiple classifications %
综上所述,一维Inception 结构相较于其他CNN特征提取模块能够获取更丰富的特征信息,此外结合ViT 模块,利用注意力机制突出重点特征,从而提升了一维Inception-ViT 模型的检测性能。
3.3.3 常见模型性能对比实验
为进一步验证一维Inception-ViT 模型的有效性,在相同的训练次数下,本文选取了8 种模型(1DCNN、2D-CNN、GoogLeNet、ResNet、BiLSTM、HiLSTM、HABBiLSTM、CNN+LSTM)作为基准模型进行对比。其中:1D-CNN[9]模型将经过预处理后的图像数据转换成一维序列输入到一维卷积神经网络中进行特征提取并分类;2D-CNN[10]模型与1DCNN 模型类似,但其使用二维卷积的方式进行特征提 取;ResNet[25]模型由HE等于2016 年提出,考虑到输入图片的大小,本文使用ResNet-14 对其进行分类;BiLSTM 模型使用双向LSTM 从会话层级对输入的图片数据整体提取其时序特征并分类;HiLSTM[14]模型将流量看作“字节-数据包-会话流”结构,同时对数据进行独热编码,将一个流量字节转换为256 维的向量,使用BiLSTM 在数据包和会话层级分别提取时序特征并进行分类;HABBiLSTM[16]同HiLSTM 模型结构类似,但其不对数据进行编码,同时在数据包和会话流层分别添加注意力机制,用来计算重要时序特征;CNN+LSTM 模型参考文献[15]的模型结构,首先利用CNN 提取数据包的空间特征并使用MLP 将提取后的特征变换至指定维度,之后再使用BiLSTM 对数据包层特征组成的序列进一步提取网络流特征实现分类。
从表3 可以看出:一维Inception-ViT 模型性能最好,在AR 和AF 指标上分别达到了99.42% 和99.39%,相较于其他基准模型在AR 指标上分别提升了0.19、0.52、1.96、0.31、7.13、0.53、0.45、2.00 个百分点,在AF 指标上分别提升了0.17、0.49、1.87、0.27、7.16、0.61、0.44、1.88 个百分点。
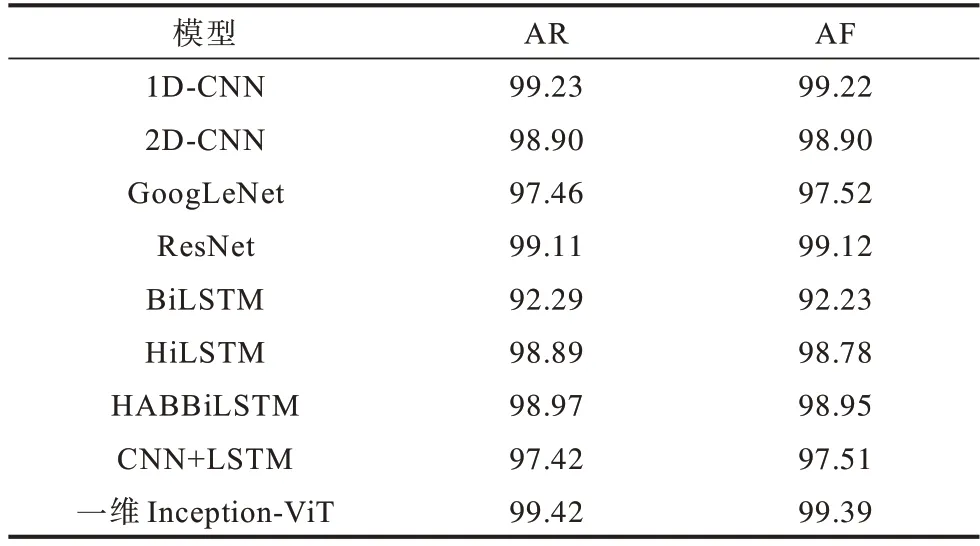
表3 各模型AR 和AF 结果对比Table 3 Comparison of AR and AF results of each model %
此外,为进一步验证所提模型在加密流量多分类上的性能,图12 所示为各模型的混淆矩阵。从图12 可以看出:多数模型在Neris 和Virut 两类上具有一定混淆。一维Inception-ViT 模型预测为Neris类样本中有23 个属于Virut 类,预测为Virut 类中样本有45 个属于Neris 类,相较于基准模型中性能最好的1D-CNN 模型,减少了16 个样本混淆。为了更好地进行对比,表4 统计了各模型在Neris 和Virut 两类上F1 值评价指标结果。从表4 可以看出:一维Inception-ViT 模型在Neris 和Virut 两类区分上结果最优,相较于基准模型中性能最好的1D-CNN 模型分别提升了0.81 和1.33 个百分点,相较于Neris 和Virut 两类上分类结果最优的基准模型ResNet 分别提升了0.48 和1.1 个百分点。对于ResNet 模型,从图12 混淆矩阵可以看出:该模型在对恶意加密流量Shifu 类进行预测时,错误地将其他种类流量的8 个样本预测为该类,而一维Inception-ViT 模型在该类别上仅错误预测1 个样本,对恶意加密流量检测更为准确。

表4 各模型在Neris 和Virut 上的F1 值Table 4 F1 value of each model on Neris and Virut %

图12 各模型混淆矩阵Fig.12 Confusion matrix of each model
综上所述,一维Inception-ViT 模型能够在加密流量多分类任务上拥有最优性能,同时相较于其他模型能更有效地区分恶意加密流量。
4 结束语
本文构建一种融合一维Inception 和ViT 的恶意流量检测模型,通过改进GoogLeNet 中的Inception结构,使用一维卷积替换二维卷积并添加池化层去除冗余信息,通过融合ViT 模块增强特征区分度,提升模型检测结果。实验结果表明,该模型在多分类实验下,平均召回率和平均F1 值相比对比模型均有所提高,同时在恶意加密流量区分度上也有明显提升,可获取更有效的加密流量表征,增强了对恶意加密流量的检测。但本文仅在单一数据集上进行了实验,且在数据预处理中采用截断的方式,可能会造成有效信息丢失。后续将考虑采用不同的数据预处理方式,并在多种数据集上进行实验,以获取更好的效果。
