基于聚类混合采样与PSO-Stacking 的车载CAN 入侵检测方法
2023-01-27孙扬威戚湧
孙扬威,戚湧
(南京理工大学计算机科学与工程学院,南京 210094)
0 概述
随着物联网和通信技术的发展,以海量车辆节点为核心的车联网(Internet of Vehicles,IoV)应运而生[1]。车联网是现代化智能汽车重要的通信方式,通过车联网可实现人-车-路-云之间的信息共享[2]。
车联网大体上可分为车内网和车外网,其中,车内网中最重要的部分是车载控制器局域网络(Controller Area Network,CAN)[3]。由于车载CAN中存在兼容性问题,因此传统的信息安全技术在当今智能网联汽车的车内网中并不适用,很容易受到模拟攻击、DoS 攻击、监听攻击、伪造攻击等网络攻击[4]。入侵检测是近年来新兴的一种信息安全方法,其可提前发现和拦截网络攻击,属于主动安全的范畴,并且可方便地集成到车载系统中,现已成为车载CAN 安全领域的重要研究方向。
近年来,车内网的入侵检测相关研究主要集中在机器学习和深度学习模型上。GHALEB 等[5]提出一种基于人工神经网络(Artificial Neural Network,ANN)的入侵检测模型,并在采集到的真实车载CAN 入侵数据上进行测试,结果表明,该模型的整体检测效果优于常见基线模型,但是其针对样本数较少的攻击类型时检测率较差。ALSHAMMARI 等[6]通过K 近邻(KNearest Neighbor,KNN)和支持向量机(Support Vector Machines,SVM)方法对车内网中的数据进行分类检测,由于所用模型并不适用于大数据量样本,因此模型训练时间较长。YANG 等[7]提出一种基于多层混合模型的车联网入侵检测方法MTHIDS,该方法主要分为数据处理、特征工程、入侵检测、结果输出这4 层,其中,在入侵检测层使用集成学习模型进行分类。实验结果表明,该入侵检测方法误报率较低,整体检测效果较好。AKSU 等[8]提出一种基于特征选择组合多种分类器的入侵检测系统,首先使用改进遗传算法组合K 折交叉验证方法进行特征选择,然后从若干分类器中选择具有最高分类性能的分类器。实验结果表明,该系统具有较好的检测效果。KHAN 等[9]提出一种基于长短期记忆(Long Short Term Memory,LSTM)网络的车载CAN 入侵检测方法,并在实际车载CAN 网络中进行了实验,结果表明,该方法的检测率高于传统的基线检测模型,但是由于其结构相对复杂、计算量较大,因此整体效率较低。
尽管此前的研究工作已经取得了一定的成果,但是整体检测性能仍需进一步提高。近年来,由于人工智能技术的逐渐成熟,深度学习被广泛应用于机器翻译、目标识别等领域。深度学习模型一般效果较好,但其计算成本通常较高,难以应用于计算性能一般的车载系统。比起深度学习,机器学习往往更高效,并且已有学者证明了机器学习在入侵检测系统中的有效性[10]。本文提出一种基于聚类混合采样与PSO-Stacking 的车载CAN 入侵检测方法。使用聚类混合采样方法对初步处理后的训练数据进行采样而测试数据不变。使用基于Gini 系数的梯度提升决策树(Gradient Boosting Decision Tree,GBDT)[11]进行特征重要性评估,删除重要性较低的特征,以实现数据降维。在此基础上,通过粒子群优化(Particle Swarm Optimization,PSO)算 法[12]组合Stacking 模型[13]完成模型参数寻优和入侵检测。
1 理论基础
1.1 K-means 聚类
K-means 算法[14]是基于划分的聚类方法,其核心思想是按照样本之间的相似度将样本分为不同的簇,其中,簇间相似度较低,簇内相似度较高。
对于一个给定的包含n个d维数据点的数据集X={x1,x2,…,xi,…,xn}(xi∈Rd)和要生成的k个簇,K-means 聚类算法将数据组织为k个划分C={ci,i=1,2,…,k},每个划分代表一个簇ci,每个簇有一个聚类中心μi。选取欧式距离作为相似度判断准则,计算类内各点到聚类中心的距离平方和:

聚类的目标是使各簇整体的距离平方和最小,即式(2)取得最小值:

在聚类完成后,每个簇中的样本差异最小,簇间的样本差异最大,此时每个簇中的聚类中心可有效代表该簇。
1.2 SMOTE 算法
SMOTE算法[15]的思想是在少 数类样本与其k个近邻之间的连线上,利用随机函数产生随机数,然后合成新样本,从而增加少数类样本数量,达到对少数类样本过采样的目的。经过SMOTE 过采样,分类器可以更好地对少数类样本进行分类,提高整体分类效果。SMOTE 合成样本的方法如式(3)所示:

其中:xnew表示新生成的样本;xi为聚类中心点;为所选k 近邻样本;δ∈[0,1]为随机值。SMOTE 生成的样本如图1 所示。
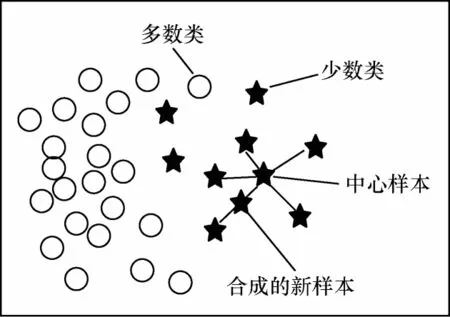
图1 SMOTE 生成的样本Fig.1 Samples generated by SMOTE
1.3 Tomek Links 算法
Tomek Links算法[16]的基本思想是:若最接近的两个样本属于两个类别,这两个样本组合为一个Tomek Links对,可能这两个样本中的一个是噪声,也可能两者都靠近类别边界。删除上述Tomek Links 对,可有效降低类间重叠数据量,从而使分类器能够更好地分类。Tomek Links 采样示意图如图2 所示。
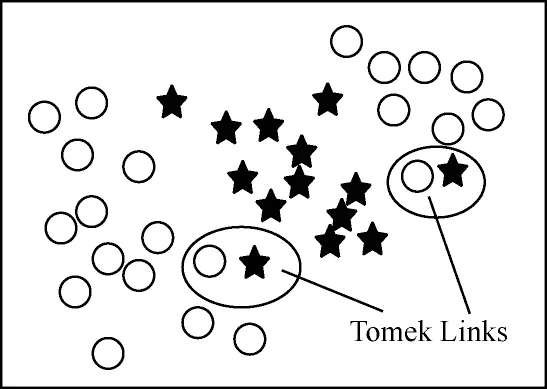
图2 Tomek Links 采样示意图Fig.2 Tomek Links sampling diagram
1.4 Gini 系数
Gini 系数的含义是从数据集D中随机抽取两个数据分属不同类别的概率,概率越小,集合的纯度就越高。在分类问题上,假设数据集D中有K个类别,其中,Pk表示某个样本属于k类的概率,则可以用Gini 值来度量数据集D的纯度:
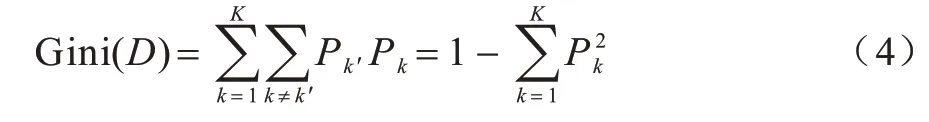
假设离散特征f有N种可能的取值f={f1,f2,…,fN},若通过f划分数据集D,则可能产生N个分支,其中,第n个分支表示在f特征上值为fn的所有样本,标记为Dn。将数据集D中特征f的Gini 系数定义为:
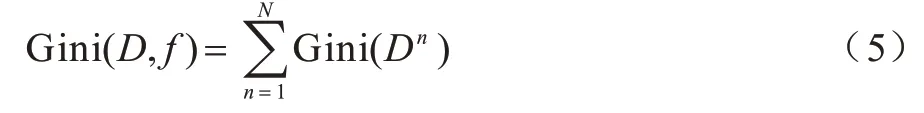
1.5 PSO 算法
PSO 是一种由鸟群觅食过程所演变出的群体搜索算法。与其他搜索算法相比,PSO 具有所需调整参数少、优化速度快、优化范围广等特点[17]。
若一个具有m个粒子的种群在一个D维空间中搜索,其中,每个粒子都具有一定的记忆能力,可以存储搜索到的最佳位置pbest,整个粒子群搜寻到的最好位置是gbest。每个粒子根据自身的pbest与种群搜索到的最好位置gbest之间的关系来调整速度vd和位置xd,以完成对整个空间的搜索。粒子的位置变化范围为[Xmin,d,Xmax,d],速度变化范围为[-Vmax,d,Vmax,d]。第i个粒子在D维空间中的速度及位置调整方法如下:
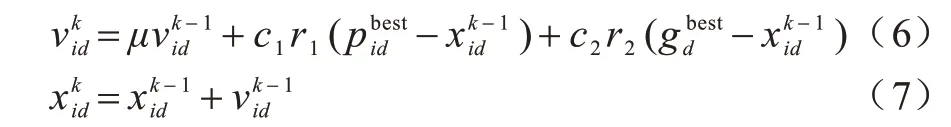
2 车载CAN 入侵检测方法
2.1 聚类混合采样方法
由于实际采集到的车联网数据流量较大,且非攻击类型的数据占绝大多数,使用全部数据来训练模型不仅会花费大量时间,还会带来因数据类别不平衡而导致的模型过/欠拟合问题[18]。本文提出聚类混合采样方法对数据进行采样,在保证样本多样性没有损失的前提下丰富少数类样本,去除冗余数据,从而提高模型的检测效果。
本文所提聚类混合采样方法首先计算各类别样本的平均数nAVG,若某类别中的样本总量高于nAVG,则该类别为上区,反之为下区。对上区中的数据进行聚类采样,从上区数据中随机初始化nAVG个聚类中心,通过聚类迭代更新聚类中心,直到每个聚类不再变化,此时抽取最终的nAVG个聚类中心作为上区数据采样后的结果。在聚类后采样,舍弃的均为代表性较低的冗余数据,因此,可以在不损失数据多样性的前提下降低数据规模。对于下区内的数据,由于数据量不足nAVG个,因此本文采用SMOTE 算法根据现有数据合成所需数量的新数据,组合现有数据和新数据共nAVG个数据,作为下区数据采样后的结果。
汇总上区和下区的数据构成新的数据集,由于使用SMOTE 算法生成了新数据,因此此时的数据集中存在一些处于各类别边界的样本,该类样本在一定程度上会影响模型的分类效果。本文通过Tomek Links 方法清除该类样本,得到最终的数据集。本文聚类混合采样方法整体流程如图3 所示。
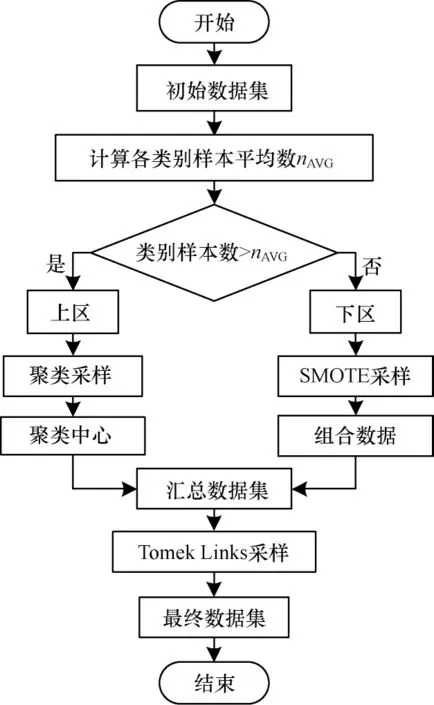
图3 聚类混合采样流程Fig.3 Cluster mixed sampling procedure
2.2 基于Gini 系数的GBDT 特征选择方法
GBDT 是由多棵CART 树所构成的,在单棵树中采用Gini 系数度量特征的重要程度,Gini 系数的值越小,说明集合的不纯度越低,分割效果越好[19]。Gini 系数的计算公式如式(8)所示:
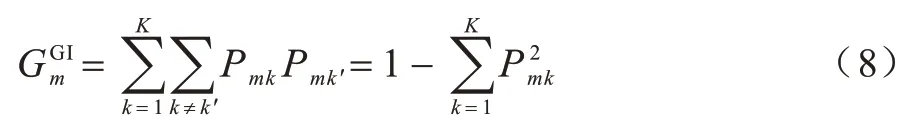
其中:K代表类别总数;Pmk表示节点m中类别k所占的比例。Gini 系数的定义可表示为从节点m中随机抽取分属不同类别的两条数据的概率。
鉴于分支中的样本数量对分支影响不同,将各分支的Gini 值乘以样本数量N,以提高样本数多的分支的影响。因此,特征j在节点m上的重要性可以用加权不纯度的减少量来表示:
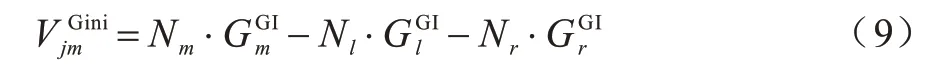
若在第i棵CART 树中,节点集合为M,特征j所在的节点m包含在M中,此时特征j在第i棵树上的重要程度为:

假设GBDT 中有n棵树,那么特征j的重要性可表示为:

对上面的重要性评分进行归一化处理,得到特征j的最终重要性:

重要性接近0 的特征对分类结果贡献较小,甚至会降低分类效果,删除这些特征可降低数据的维度,提高训练速度和分类效果。
2.3 PSO-Stacking 模型
Stacking 是一种集成学习方法,其采用基于模型的异质型集成策略,目的是充分发挥各模型的优势,更好地完成分类任务。Stacking 主要分为两层:第一层使用原始训练数据,利用K 折交叉验证法训练不同种类的基学习器,然后将基学习器输出的分类结果作为特征输入到第二层;第二层根据第一层输出的分类结果训练元分类器,构成完整的Stacking 模型[13]。由于Stacking 模型集成了多个不同种类的模型,因此可弥补单一分类器的缺陷,提高分类效果。本文所用Stacking 模型第一层的基学习器分别为基于GBDT 的XGBoost[20]、LightGBM[21]及CatBoost[22]模型,为了防止过拟合,第二层使用拟合效果较弱的多层感知机(Multi-Layer Perceptron,MLP)模型[23]作为元分类器。
XGBoost 是一种基于GBDT 的集成模型,相比传统的GBDT 模型,XGBoost 采用集成学习思想和前向分布算法,提升了精度和训练速度。直接对残差进行学习很可能会出现过拟合,因此,XGBoost 在目标函数中引入正则化项,在保证准确性的同时可以降低过拟合的风险。
LightGBM 在GBDT 的基础上引入基于直方图的算法,将连续特征放入不同的桶中构建直方图数据,在选择特征划分时,无需每次遍历数据集就可以找到最优切分点,提升了运行效率;同时引入单边梯度采样算法和互斥特征捆绑算法,降低了对系统内存的占用,提升了训练速度;为防止因生长出的决策树较深而引起过拟合的问题,该模型引入带深度限制的叶子生长算法,同时支持并行训练,在保证较高准确率的同时提升了模型的训练效率。
CatBoost 是一种以完全对称树为基学习器的GBDT 模型,相比传统的GBDT 模型,CatBoost 在处理类别特征、密集数值特征、决策树生长评分以及多GPU 并行计算方面进行了较大改进。CatBoost 的基学习器为完全对称树,在这类树中,每一层都使用相同的分割条件,预测速度较快,同时由于这种树是平衡树,因此在一定程度上避免了过拟合问题。
综上所述,本文Stacking 模型使用的3 种基学习器整体效率较高、预测效果较好,且元分类器为拟合效果较弱的MLP 模型,在一定程度上降低了过拟合的风险。Stacking 模型架构如图4 所示。
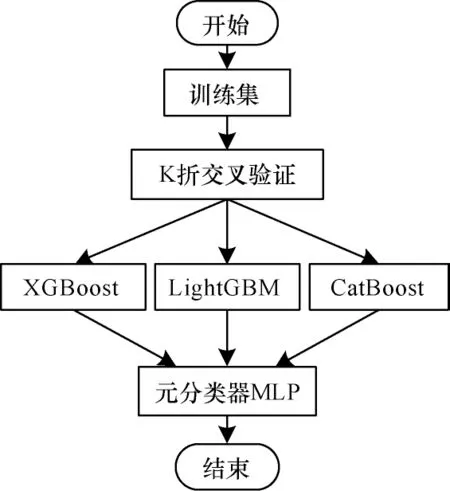
图4 Stacking 模型架构Fig.4 Stacking model architecture
为了进一步提高模型整体的检测效果,本文在Stacking 模型的基础上引入PSO 算法对模型进行优化。本文模型所选基学习器均基于树模型,在基学习器中参与寻优的参数为树的深度、学习率和迭代次数,元分类器中参与寻优的参数为单隐藏层的形状和学习率。使用PSO 算法分别对Stacking 模型中的各基学习器和元分类器的参数进行迭代寻优,当达到设定的最大迭代次数(100)时,寻优结束。选取最优参数组合作为各模型最终的参数,使用优化后的基学习器和元分类器构建Stacking 模型,重新训练Stacking 模型并保存训练后的结果。PSO-Stacking模型的执行流程如图5 所示。
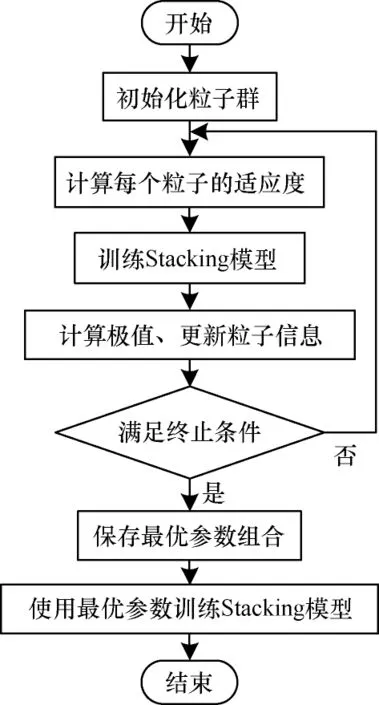
图5 PSO-Stacking 的执行流程Fig.5 Implementation procedure of PSO-Stacking
2.4 车载CAN 入侵检测模型
本文所提基于聚类混合采样与PSO-Stacking 的车载CAN 入侵检测模型主要分为4 个模块:
1)数据预处理模块。首先对初始数据进行数值化,同时为了规避量纲差异对模型效果的影响,对数据进行归一化处理,如式(13)所示:

其中:xi表示初始值;xmin为数据的最小值;xmax为数据的最大值;为归一化处理后的值。对数值化和归一化后的数据进行划分,分成训练数据和测试数据,对训练数据进行聚类混合采样,平衡样本数据量。
2)特征选择模块。对经过数据预处理后的训练集和测试集使用基于Gini 系数的GBDT 特征选择方法进行特征选择,删除重要程度较低的特征。
3)PSO-Stacking模块。通过PSO 算法优化Stacking模型,寻找使模型整体最优的参数组合,重复此过程,直至寻优结束,存储经过训练集训练过且效果最好的Stacking 模型。
4)入侵检测模块。使用保存的经PSO 优化后的模型对测试数据进行检测,输出检测结果。
本文车载CAN 入侵检测模型整体流程如图6所示。
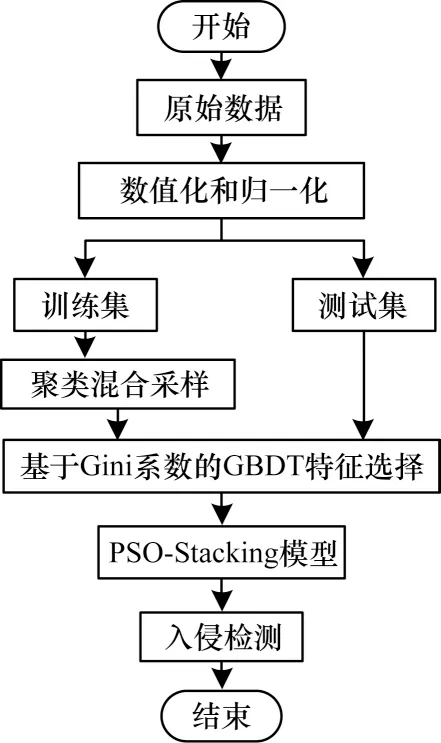
图6 车载CAN 入侵检测模型整体流程Fig.6 Overall procedure of intrusion detection model for in-vehicle CAN
3 实验结果与分析
3.1 数据描述
有别于传统互联网,车载CAN 网络通过CAN报文传输数据,其数据结构较为固定。CAN 报文由7 个字段组成,分别为开始字段、仲裁字段、控制字段、数据字段、循环冗余校验字段、应答字段和结束字段,其中,仲裁字段包含标识符字段和远程传输请求字段[24]。CAN 报文结构如图7 所示,在CAN 报文中数据字段最为重要,攻击者可通过向数据字段注入恶意信息来入侵和控制车辆。

图7 CAN 数据报文结构Fig.7 CAN data message structure
本文使用的车载CAN 入侵数据集为HCR 实验室在KIA SOUL 汽车上提取的真实数据[25],其特征包括时间戳、CAN 标识符、CAN 数据字节数以及CAN 数据字段,攻击类型主要为拒绝服务攻击(DoS)、模糊攻击(Fuzzy)以及模拟攻击(Impersonation,Imp)。本文在上述数据集中选取数据字段长度为8 Byte 的样本作为实验数据。
3.2 实验环境与评估指标
本文全部实验均在Windows10 系统下进行,操作系统为64 位,处理器版本为Intel®CoreTMi5-6500 CPU @3.20 GHz,内存为16 GB,所使用的开发语言版本为Python3.8。
实验评估指标均以混淆矩阵为基础,用于计算各项评估指标的混淆矩阵如表1 所示。

表1 混淆矩阵Table 1 Confusion matrix
实验采用准确 率(Accuracy,ACC)、漏报率(False Negative Rate,FNR)和精确度(Precision,PRE)作为模型的评估指标,各指标的计算方式分别如式(14)~式(16)所示:
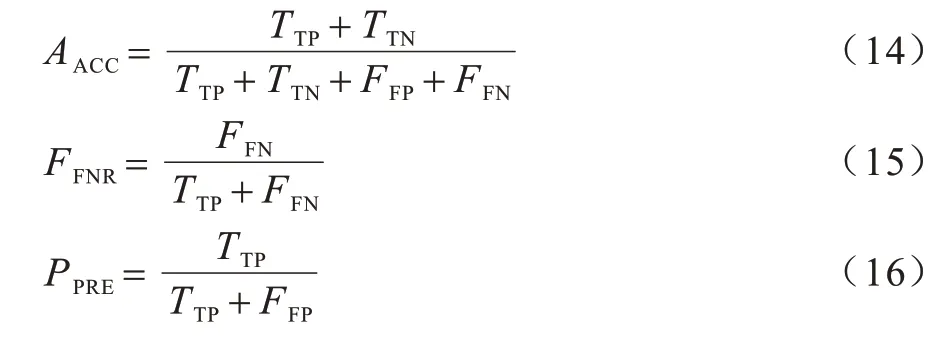
3.3 结果分析
实验内容主要分为两部分:第一部分使用所提PSO-Stacking 模型在原始训练集和经过聚类混合采样、特征选择处理的训练集上进行训练,对比其检测结果,证明所提聚类混合采样和特征选择方法的有效性;第二部分将所提基于聚类混合采样与PSOStacking 的车载CAN 入侵检测模型与现有常见车载CAN 入侵检测模型进行对比,证明所提模型的先进性和实用性。为了避免实验结果的偶然性,所提模型的准确率、漏报率和精确度均为35 次重复实验结果的平均值。
3.3.1 聚类混合采样与特征选择方法分析
本部分主要证明所提聚类混合采样方法和基于Gini 系数的GBDT 特征选择方法的有效性。实验所用测试数据和经过聚类混合采样前后的训练数据如表2 所示,可以看出,聚类混合采样可以在一定程度上降低多数类样本冗余,同时丰富少数类样本,解决了数据比例失衡的问题。
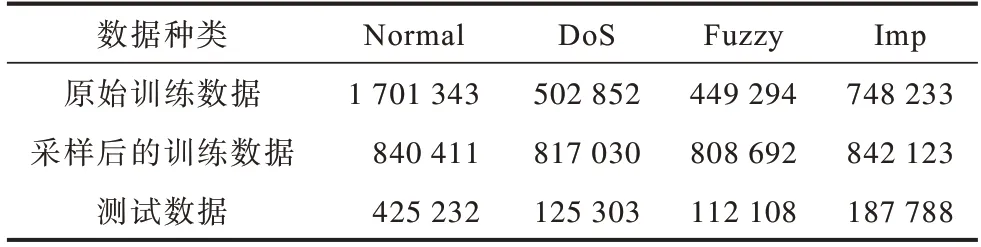
表2 样本数量对比Table 2 Comparison of sample quantity
表3 所示为使用原始训练数据(第一种)、仅经过特征选择处理的训练数据(第二种)、仅经过聚类混合采样处理的训练数据(第三种)、同时经过聚类混合采样与特征选择处理的训练数据(第四种)对PSO-Stacking 模型进行训练所需的时间。从表3 可知,在其他条件均相同的情况下,使用经过聚类混合采样和特征选择处理后的训练数据训练PSOStacking 模型,能够降低训练样本的数量和维度,使得模型训练速度更快。

表3 聚类混合采样与特征选择前后的时间分析Table 3 Time analysis before and after cluster mixed sampling and feature selection
图8 所示为使用上述4 种情况下的训练数据分别训练PSO-Stacking 模型时对测试数据的检测准确率。从图8 可以看出,使用第二种训练数据训练PSO-Stacking 模型的检测准确率相对于第一种训练数据的检测准确率略有提升,使用第三种训练数据训练PSO-Stacking 模型的检测准确率相对于第一种和第二种训练数据的检测准确率提升较大,使用第四种训练数据训练PSO-Stacking 模型的检测准确率最高。
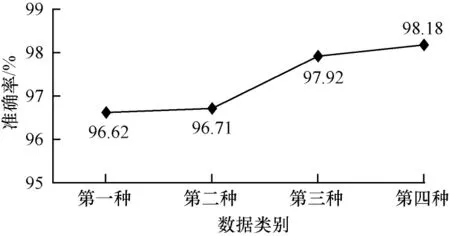
图8 本文模型的准确率分析Fig.8 Accuracy analysis of the proposed model
表4、表5 分别表示训练数据在上述4 种情况下对测试数据中不同类别的样本的检测精确度和漏报率,最优结果加粗标注。
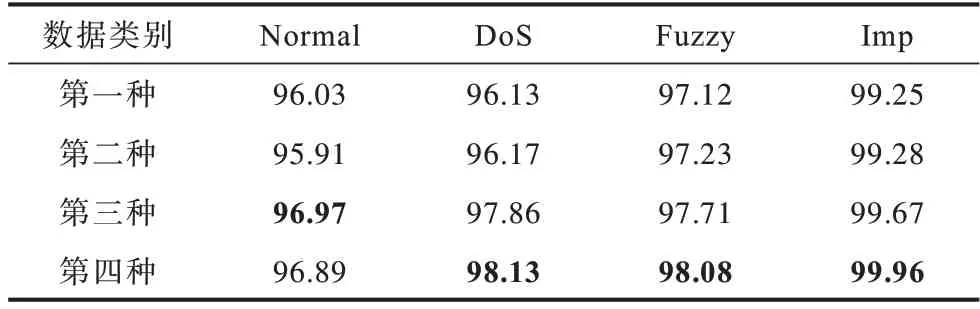
表4 聚类混合采样与特征选择前后的精确度分析Table 4 Precision analysis before and after cluster mixed sampling and feature selection %
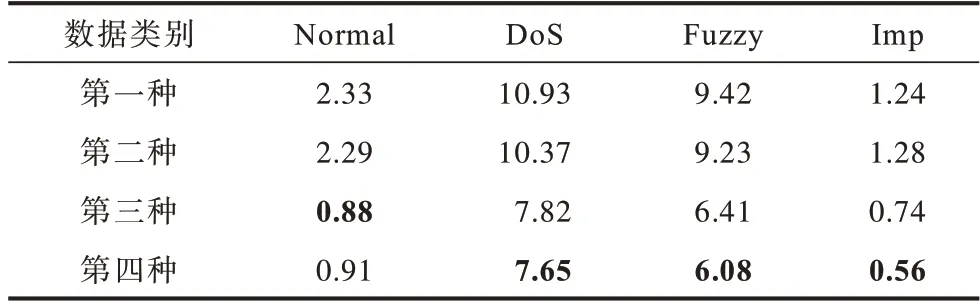
表5 聚类混合采样与特征选择前后的漏报率分析Table 5 False negative rate analysis before and after cluster mixed sampling and feature selection %
从表4 可以看出,使用第四种训练数据训练的PSO-Stacking 模型仅在对Normal 类型样本的检测精确度略低于第三种训练数据,对其他类型样本的检测精确度均较高,整体检测效果较好。从表5 可以看出,使用第三种训练数据训练的PSO-Stacking 模型对Normal 类型样本的检测漏报率最低,除此之外,使用第四种训练数据训练的PSO-Stacking 模型检测漏报率最低,检测效果最好。
综合上述结果可以看出,本文所提聚类混合采样与特征选择方法,在一定程度上平衡了数据集中各类别样本的数量,降低了模型的训练时间,同时提升了模型的整体检测效果。
3.3.2 所提模型与其他常用模型对比实验分析
在初始训练数据和测试数据相同的情况下,本文所提模型与常用车载CAN 入侵检测模型的检测准确率对比如图9 所示。从图9 可知,SVM 模型[6]的检测准确率相对较低,只有92.82%,其次是ANN[5]和KNN[6],准确率分别为93.62%和94.67%,检测准确率较高的是MGA-DTC[8]及MTHIDS[7],前者首先使用改进遗传算法组合K 折交叉验证方法进行特征选择,然后使用基于决策树的算法进行入侵检测,整体检测准确率为96.68%,后者与本文所提模型均基于集成学习模型,因此检测准确率较高,但在集成方式以及数据采样和特征选择方法上,MTHIDS 与本文模型有较大的区别。从图中实验结果可知,本文所提模型的检测准确率高于其他常见车载CAN 入侵检测模型,在一定程度上证明了本文所提方法的先进性。

图9 不同模型的检测准确率对比Fig.9 Comparison of detection accuracy of different models
表6、表7 列出了在初始训练数据和测试数据均相同的情况下所提模型与其他常见车载CAN 入侵检测模型在精确度和漏报率上的对比。从表6 可知:ANN、KNN 及SVM 模型的检测精确度相对较低;由于进行了特征处理,MGA-DTC 模型的检测精确度高于上述3 种模型;MTHIDS 与本文所提模型除了进行特征处理之外,还对数据进行了采样,平衡了各类别数据的比例,因此检测精确度较高。本文所提模型仅对Normal 类型样本的检测精确度略低于MTHIDS,对其余类型样本的检测精确度均高于其他模型。从表7 可知,本文所提模型对Normal 类型及Imp 类型样本的检测漏报率略高于MGA-DTC 和MTHIDS,对DoS 类型及Fuzzy 类型样本的检测漏报率均低于其他模型,总体而言,本文模型的整体漏报率较低,实用性较好。
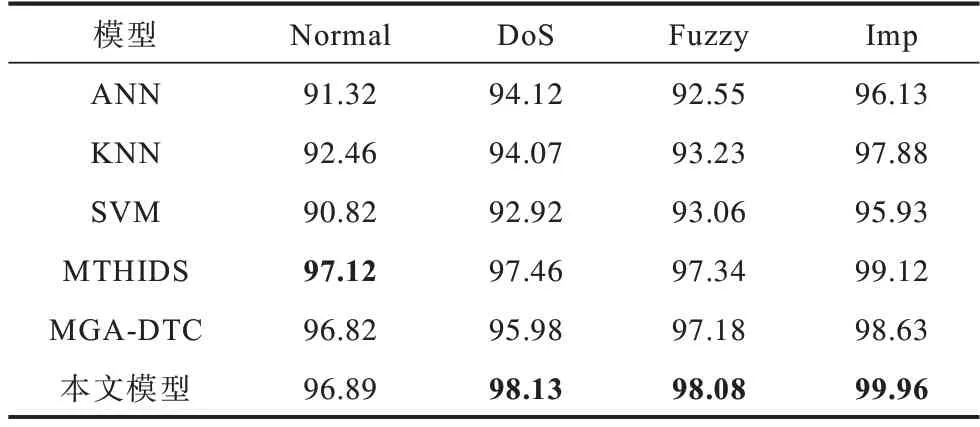
表6 不同模型的检测精确度对比Table 6 Comparison of detection precision of different models %
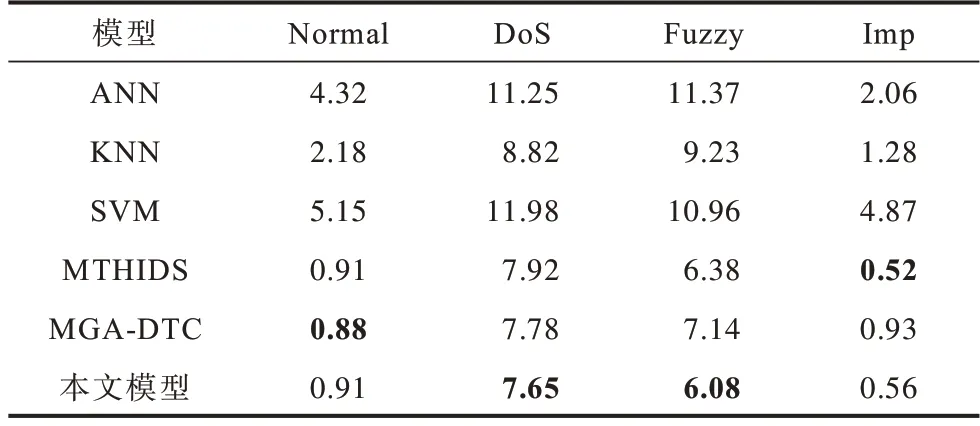
表7 不同模型的检测漏报率对比Table 7 Comparison of detection false negative rate of different models %
综上所述,本文所提模型能够较好地解决车载CAN 中数据比例失衡的问题,充分挖掘数据特征,具有较好的入侵检测能力,在车载CAN 入侵检测中体现出先进性和实用性。
4 结束语
针对当前车载CAN 中多样化的网络攻击形势以及现有车载CAN 入侵检测方法存在的不足,本文提出一种基于聚类混合采样与PSO-Stacking 的车载CAN 入侵检测方法。车载CAN 环境中网络数据流量较大且各类别数据比例失衡,直接使用采集到的原始训练数据训练模型可能会降低模型的检测效果,为此,本文设计一种聚类混合采样方法对采集到的训练数据进行采样,去除多数类样本冗余,同时合成少数类样本,以保证各类别数据平衡。提出基于Gini 系数的GBDT 特征选择方法,删除重要程度较低的特征,降低数据维度。在此基础上,通过PSOStacking 模型完成入侵检测。实验结果表明,该方法整体检测效果较好,具有一定的先进性和实用性。下一步将在实际车载CAN 环境中对检测模型进行优化,尝试使用生成对抗网络合成少数类攻击数据,降低对少数类攻击的检测漏报率,进一步提升检测效果。
