基于混合网络模型的多维时间序列预测
2023-01-27刘杭殷歆陈杰罗恒
刘杭,殷歆,陈杰,罗恒
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215009;2.苏州科技大学江苏省建筑智慧节能重点实验室,江苏苏州 215009)
0 概述
时间序列是在时间间隔不变的情况下收集到的连续时间点的数据集合。时间序列在工业生产[1]、市场营销[2]、社会经济[3]、环境监测[4]等行业中普遍存在,通过发现蕴含在时间序列中的潜在规律可获得未来某个时刻的预测值,为决策者提供前沿性的意见,对辅助决策、优化资源、提升工作效率等具有重要的意义[5]。传统时间序列预测方法主要针对简单的时间序列预测问题,包括支持向量机(Support Vector Machines,SVM)[6]、马尔可夫(Markov)[7]、高斯过程(Gaussian Process,GP)[4]等预测模型。在多维时序预测中,由于其时间特征适应性差,因此很难捕捉潜在的特征依赖关系。
在深度学习中,循环神经网络(Recurrent Neural Network,RNN)[8]在多维时序预测上应用广泛,但是RNN 训练时会出现梯度消失或梯度爆炸的现象,而长短期记忆(Long Short-Term Memory,LSTM)网络[9]的出现缓解了这一问题并在时序建模上取得了巨大成功。近期,多维时序预测分为两种流行的深度学习体系结构:第一种是深度模型结构,将LSTM等作为内部的单元组件[10-12],适用于不规则的趋势多维时序建模[13-15];第二种以卷积神经网络(Convolutional Neural Network,CNN)为核心,通过增强卷积的感受野和特征提取能力获得更强大的预测性能,适用于一般多维时序数据建模。文献[16]提出的LSTNet 运用CNN 和RNN 来提取变量间短期局部的依赖模式,并发现时间序列的长期模式,最终提出一种先进的时序预测模型。文献[17]提出一种基于注意力机制的RNN 模型,使用一组滤波器来提取不变的时间模式,以一种新的注意力机制来选择相关的时间序列,并使用其频域信息进行多维数据预测。文献[18]提出一种基于自注意力机制的多维时序数据预测方法,利用并行卷积和注意力机制提取特征。目前流行的时间卷积网络(Temporal Convolutional Network,TCN)[19]通过结合因果卷积、残差卷积和膨胀卷积等使其在时序数据处理上性能更加优越[20]。然而它们仍然存在以下缺陷:其一,由于CNN 和LSTM 主要应用在图像和自然语言领域,在多维时间序列预测中仍然存在时间前后的潜在特征大量丢失的现象[19,21];其二,在实际的高维时间序列的应用中,快速模糊预测一直具有重要的实用意义[22],但是上述深度模型却无法适用于快速模糊预测。
为了解决上述问题,本文建立基于时间卷积网络和自注意力机制(self-attention)的两种混合网络模型(TSANet 和TSANet-MF)。TSANet 在TCN 的基础上结合了全局和局部卷积并行的self-attention结构,并使用并行的自回归(Autoregressive,AR)模型以提升周期性特征的捕捉能力。TSANet-MF 使用TSANet 作为矩阵分解(Matrix Factorization,MF)算法[23-25]的时间正则化项,将原始高维时间序列数据转化为具有更多时序特征的低维时间序列数据。
1 问题定义
多维时间序列由可能相关的多种时间序列组成,而某些特殊的时间序列会存在特征协变量。为研究一般多维时间序列的预测方法,在不使用协变量的情况下,利用历史时间段中的现实数据来预测未来时间步中的时间序列值。
定义1将单维度的时间序列数据表示为X(i)=,其中,i∈{1,2,…,d},d为维度总数,p为末尾的时间戳。
定义2将多维度的时间序列数据表示为X=(X(1),X(2),…,X(d))。
定义3多维度的时间序列预测可表示为在给定时间序列(X1,X2,…,XT)的基础上预测XT+h,其中,T为时间戳,h为在时间戳T后的预测时间范围,XT表示在所有维度中时间戳T范围内的数据,如式(1)所示:
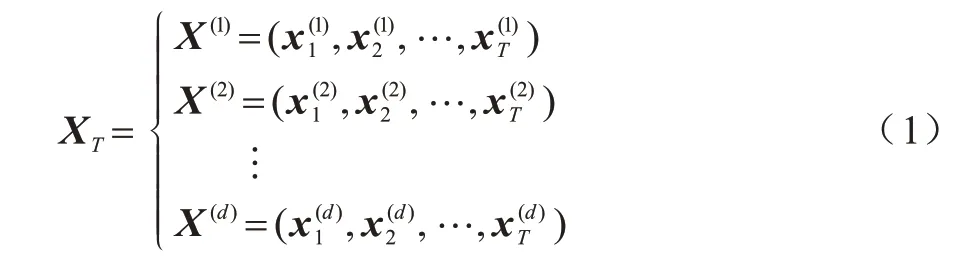
定义4在实际预测中,对于规定的多维时间序列X,以T为输入窗口,采用滑动预测方式,即在(X1+r,X2+r,…,XT+r)的基础上预测XT+h+r(r∈R+),其中r为滑动值。
2 TSANet 模型
虽然TCN 在多维时间序列处理上应用广泛,但由于TCN 仍存在感受野受限导致提取特征能力不足的问题,因此TSANet 设计全局和局部卷积结构并行提取特征,然后使用self-attention 增强特征关联程度。TSANet 将TCN 作为一个模块与self-attention进行并行组合,以此加强特征提取。由于TCN 和两种卷积结构都是非线性的特征提取,因此最后添加并行AR 模型[26]提取原始时序线性特征,以最大程度提取原始序列的周期性特征。TSANet 整体框架结构如图1所示,其中,为TCN 和selfattention 的输出结果,为AR 模型的输出结果,为TSANet 预测的输出结果。
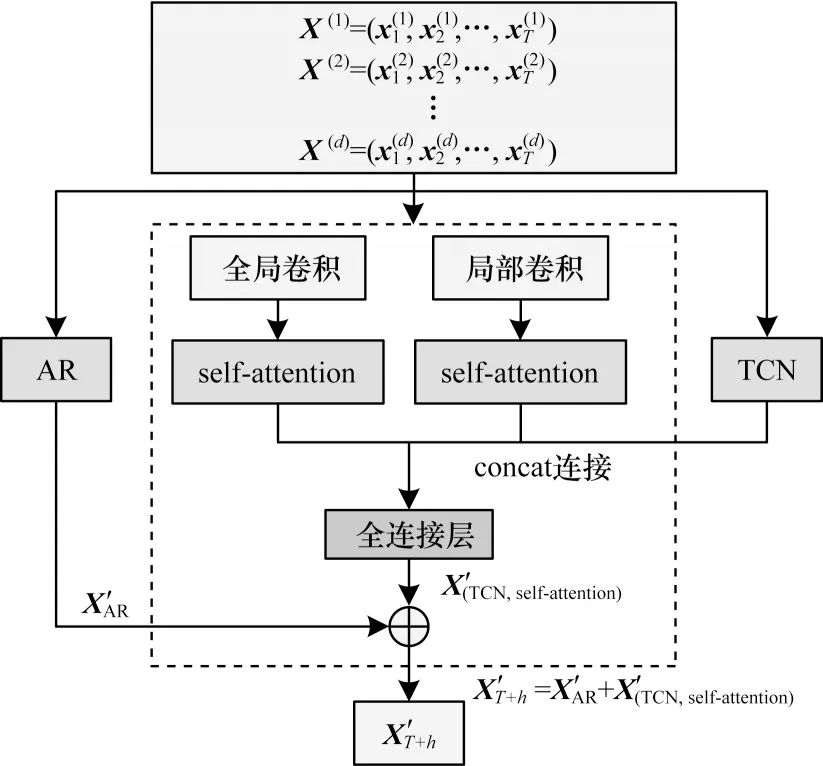
图1 TSANet 框架Fig.1 Framework of the TSANet
2.1 全局与局部卷积
全局和局部卷积可以提取短期和长期的时序特征信息,具有更强大的特征提取能力,适用性更强。全局和局部卷积框架如图2 所示。
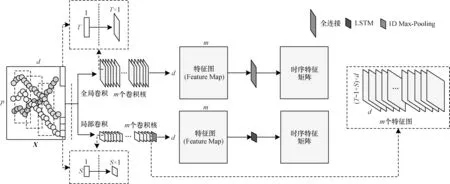
图2 全局和局部卷积框架Fig.2 Framework of the global and local convolution
在全局卷积中,输入多维向量矩阵X后,对单维度为T×1 的时序数据,使用T×1 大小的卷积核,对单维度的全局数据做卷积操作,提取各个单维度下的时序变量的前后步长信息。多维向量矩阵X经过m个卷积核的计算后,生成d×m维度的向量矩阵,其每一行代表时间序列中各个单维度的卷积学习值,在全连接层的计算后,得到完整时序特征相邻矩阵。经过卷积后生成的中间矩阵如式(2)所示:
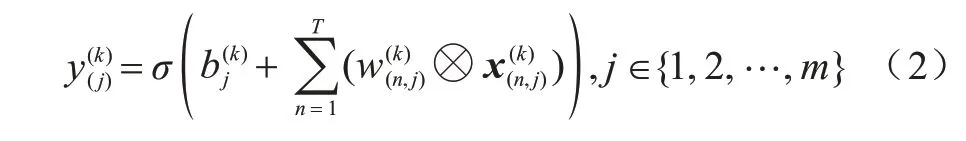
由于时序数据对短期序列的规律较为敏感,因此使用与全局相对应的局部卷积,即对相邻的短期时间段做卷积操作。使用S×1 大小的卷积核(S<T),对于输入多维向量矩阵X,经过一次卷积后得到的(T-1+S)×d维度的数据矩阵,再对每一个维度进行一维最大池化(1D Max-Pooling)的操作,经过计算后得到d×1 维度的向量矩阵。与全局卷积相对应,多维向量矩阵X经过m个卷积核的计算后,生成d×m维度的向量矩阵。局部经过卷积后利用LSTM 加强这种局部卷积前后的特征关联性。经过卷积后生成的中间矩阵如式(3)所示:
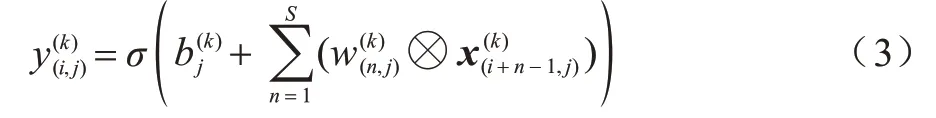
2.2 自注意力机制
self-attention 的使用受到Transformer[27]和文献[18]启发。TSANet 的self-attention 结构如图3 所示。Transformer 是由编码器与解码器构成的,编码器和解码器都是由n个相同层的堆栈组成。每一层都包含两个子层,即多头自注意力机制与全连接前馈神经网络,并在每层连接前进行层归一化操作。TSANet 中的self-attention 使用Transformer 中的编码器部分,调整全局卷积与局部卷积的输出结构,将其作为编码器的输入,其编码器与Transformer 的结构相同,每个self-attention 结构都具有n个相同的堆栈层。最终的输出为全局卷积、局部卷积分别和selfattention 并行计算的结果。这种并行的self-attention利用多头注意力机制处理经过全局卷积和局部卷积输出的时间序列特征结构,以及不同位置不同表示的子空间信息,具有更高的特征提取能力。
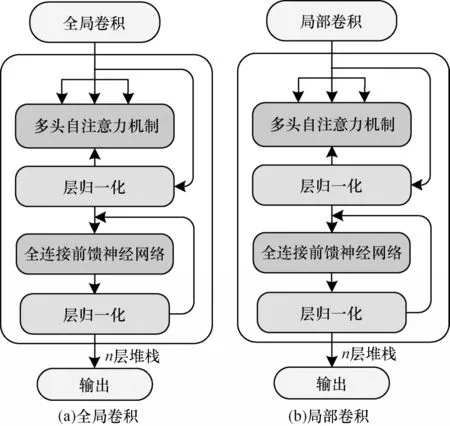
图3 self-attention 结构Fig.3 Structure of the self-attention
3 TSANet-MF 模型
TSANet-MF 模型将d维的线性序列组X转化成k维的基向量组M的线性组合(k≪d),将TSANet 作为MF 算法的时间正则化项,弥补MF 算法对于时序关系不敏感的问题,增强时序数据前后信息的依赖性。
TSANet-MF 模型分为训练和预测两个过程,训练过程的目的是训练基向量组M和线性参数矩阵F,预测过程将训练好的低维时序基向量组M和线性参数矩阵F用于实现原始的高维时序数据X的快速模糊预测。
3.1 训练过程
首先将原始高维数据按序列数据转化成两种向量矩阵的乘积,记为X=MF,其中,X为高维矩阵,F为d维参数矩阵,X为分解后的k维矩阵。高维数据的矩阵分解示意图如图4 所示,其中,t为训练集和验证集的总长度,s为测试集的长度。
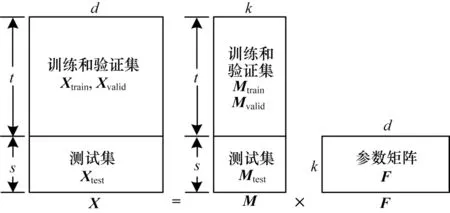
图4 高维时序数据矩阵分解Fig.4 Matrix factorization of high-dimensional time-series datas
在TSANet-MF 模型中,将参数矩阵M和F作为参数同步训练,在每次迭代(iteration)中的参数更新流程如算法1 所示:

在算法2 中:iinit、itrain、ivalid分别代表初始 化、训 练和验证的迭代周期。
3.2 预测过程
TSANet-MF 将高维的时序数据转化为低维的时序数据M后再重新训练TSANet 的参数,损失函数如式(6)所示:
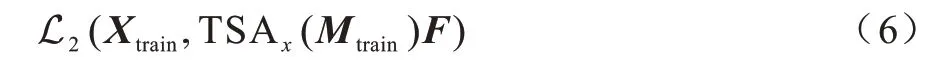
其中:Mtrain为低维数据M划分的用于训练的数据;TSAx(Mtrain)为使用TSANet 的Mtrain的预测数据。
最终在M测试集Mtest上得到的预测数据如式(7)所示:

其中:Mtest为测试数据;TSAx(Mtest)为使用TSANet的Mtest的预测数据;表示TSANet-MF 在测试集Xtest上的预测结果。
3.3 复杂度分析
TSANet 模型中的TCN 和全局与局部卷积都是以卷积为核心的计算操作。根据TSANet 模型网络结构,通过式(8)计算得到TSANet 在全局卷积中一次迭代下的卷积运算的时间复杂度为O(mTd),在局部卷积中一次迭代下的卷积运算的时间复杂度为O((T+S-1)dS),TCN 是利用CNN 的建模结构,其计算的时间复杂度和维度d同样线性正相关。selfattention 的时间复杂度为O(n2d)[27],其中n为序列长度。其余部分的时间复杂度较低,可忽略不计。因此,TSANet 在训练时的计算时间复杂度和数据的维度呈现线性正相关。TSANet 模型的卷积操作的空间复杂度分为参数量和特征图两部分,其中参数量和输入的数据大小无关,特征图则与输入的维度大小有直接关系,输入维度越低,经过卷积后的特征图则越小。总体而言,TSANet 模型的计算复杂度与数据维度线性正相关,即训练时处理的数据维度越小,计算的复杂度越低。

其中:在特征图和卷积核邻边相等的情况下,M表示单卷积下输出的特征图边长;K表示单个卷积核的边长;Cin和Cout分别表示卷积层输入和输出的通道数。
在TSANet-MF 模型的训练过程中,利用算法2训练参数F、M,以一次iteration 参数更新流程,即算法1 为例,TSANet 模型在用于时间正则化时,训练的输入为Mb,Mb维度较小,复杂度较低。其余的空间和时间复杂度来源于F、Mb的更新。空间复杂度是F、Mb的参数量,其中,F为k×d的参数矩阵,Mb为s×T×k的参数矩阵。时间复杂度表示为运算中F和M的计算量(FLOPs),分别为(2k-1)×T和(2×T-1)。TSANet 模型在预测过程中,利用M训练TSANet 的参数,由于M的维度k远远小于原数据维度d,因此计算代价也远远小于高维数据训练的计算代价。
综上,TSANet-MF 模型相对于TSANet 模型大幅度减少了训练过程中的时间和空间的复杂度,但是维度转化的过程中由于时间序列特征缺失而无法达到相对准确的预测,因此TSANet-MF 模型可用于实现高维时间序列数据的快速模糊预测。
4 实验设计
4.1 数据集选取
为了验证多维时间序列数据预测方法的通用性,需要选取不同领域和形式的时间序列样本。因此,分别选取加州大学欧文分校(UCI)机器学习库[28]中Electricity、Traffic、Solar、Exchange 等4 种原始数据集,详细信息[16]如表1 所示。所有数据集划分为训练集(60%)、验证集(20%)和测试集(20%)。
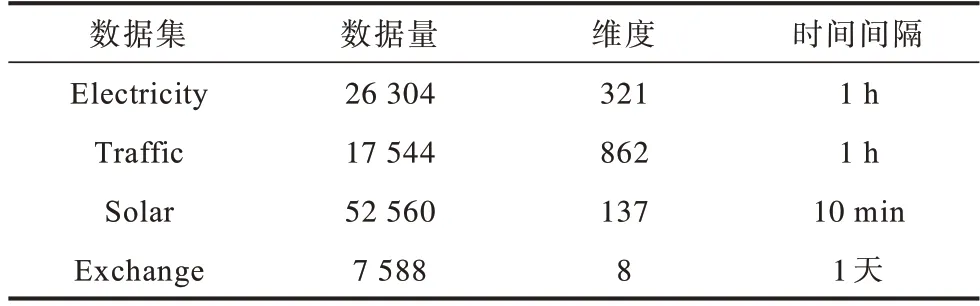
表1 数据集基本特征Table 1 Basic characteristics of datasets
4.2 实验细节设置
基准模型:TSANet 实验以深度学习中主流的多维时间序列模型TCN、LSTM-AR、LSTNet[16]和TPALSTM[17]作为基准模型。TSANet-MF 实验以传统的MF 模型[24]和TCN-MF 模型[25]作为基准模型。
实验环境:TSANet 代码全部由Python3.6 实现,使用Pytorch 深度学习框架,利用Pytorch-Lightning库,快速搭建模型。实验运行在CentOS Linux 上,GPU 环境为4×NVIDIA Tesla P100 16 GB。
数据指标:实验采用3 种评估指标,分别为平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)和相对平方根误差(Root Relative Squared Error,RRSE),这3 种指标的值越小,则表示误差越低。
训练和预测方法:训练之前使用最大最小归一化处理,避免数据受尺度影响。实验采用滑动窗口(Window)的预测方法,以Window 期内的数据预测滑动窗口期后时间范围(Horizon)线的数据。
参数设置:由于深度学习的超参数与实验结果相关,通过参考同类的深度学习模型参数设置相关参数范围,再设定Early stop 以获取训练过程中性能最优的模型。模型参数范围和调优的具体参数设置如表2 所示。
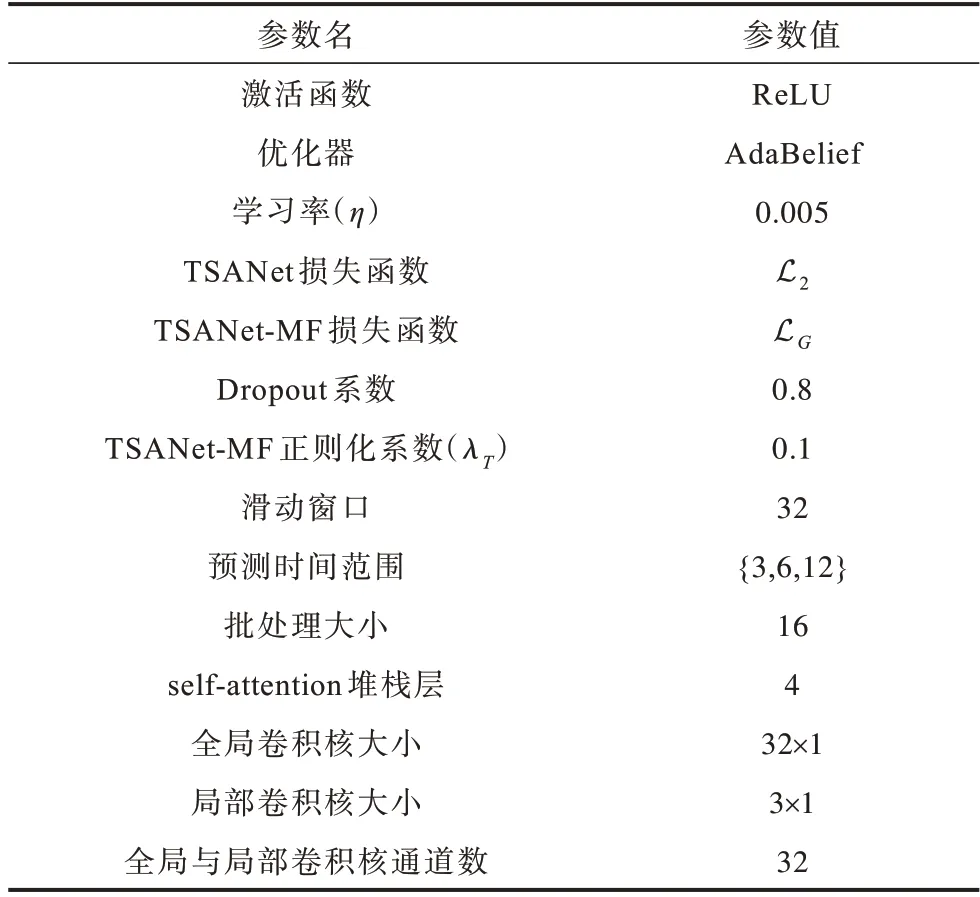
表2 模型主要参数配置Table 2 Configuration of main parameters of the model
5 实验结果分析
表3 为TSANet 和基准模型在测试集上的评估结果,其中,H表示Horizon,取值范围为{3,6,12},表示Electricity、Traffic 数据集的第3 小时~第12 小时、Solar 数据集的第30分钟~第120 分钟和Exchange 数据集的第3 天~第12 天的预测结果,粗体的数字表示模型对比的指标最低。从实验结果可以看 出,TSANet 在4 种数据集中的Exchange、Electricity 和Traffic 3 种数据集上的MAE、RMSE 和RRSE 指标相对最低,说明预测性能优于其他基准模型。特别地,在H=12 的Exchange 和Traffic 数据集的预测上,TSANet 比TCN 的RRSE 的预测精度提升了4.26%和22.87%,预测性能提升较高。总体而言,TSANet 在一般多维时序数据的预测上具有一定的优势。在Solar 数据集上,TSANet 与基准模型的预测指标都很接近,预测性能提升不明显,说明数据不具有良好的特征表现。具体来看,在Exchange 数据集 上,当H分别为3、6 和12 时,TSANet 的MAE、RMSE、RRSE 是逐渐增高的,说明数据特征按照时间分布非常明显,对于近期的预测性能较好,符合时序特征的特点。对于Electricity 和Traffic 数据集,当H分别为3、6 和12 时,性能表现接近,说明时间序列分布具有明显规律,TSANet 对于近期和远期的预测都能达到一定准确度。

表3 不同数据集上5 种预测模型的预测结果Table 3 Prediction results of five prediction models on different data sets
通过TSANet中Global(全局卷积-self-attention)、Local(局部卷积-self-attention)、TCN 这3 个分模块验证TSANet 的预测能力。由于在Solar 数据集上模型预测效果不明显,因此实验使用Exchange、Traffic和Electricity 数据集。图5 给出了TSANet 及其分模块的预测结果。由图5 可以看出:在Exchange 数据集实验中,当H为3、6 和12 时,Global 和Local模块预测的MAE、RMSE 和RRSE 较高,TSANet 和TCN预测效果非常接近,其中TSANet 的3 种指标相对较低,说明TSANet 预测性能超过分模块的预测性能;在Traffic 数据集实验中,当H为3 和12 时,TSANet、TCN、Global 和Local 预测误差是逐渐升高的,当H为6 时,Global 预测误差最高,TSANet 预测误差最低,其中TSANet 预测性能是最好的;在Electricity 数据集中,虽然所有模型的预测结果非常接近,但是TSANet 仍然是误差最低的。上述结果表明,TSANet 训练稳定且具有较好的预测性能。
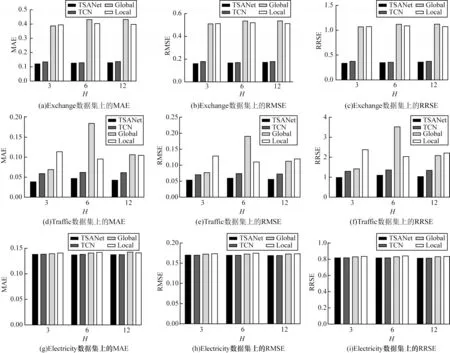
图5 Exchange、Traffic 和Electricity 数据集上TSANet 及其分模块的预测结果Fig.5 Prediction results of TSANet and its sub-modules on the Exchange,Traffic and Electricity data sets
TSANet-MF 实验使用Electricity 和Traffic两种高维数据集。在M维度k=64 时,TSANet-MF、TCNMF 和MF 实验结果如表4 所示,其中粗体表示模型对比中最低的指标。由表4 可以看出,MF 在所有数据集中的全部指标都较高,则性能最差,TSANet-MF 的预测指标略优于TCN-MF 模型,整体性能最好。
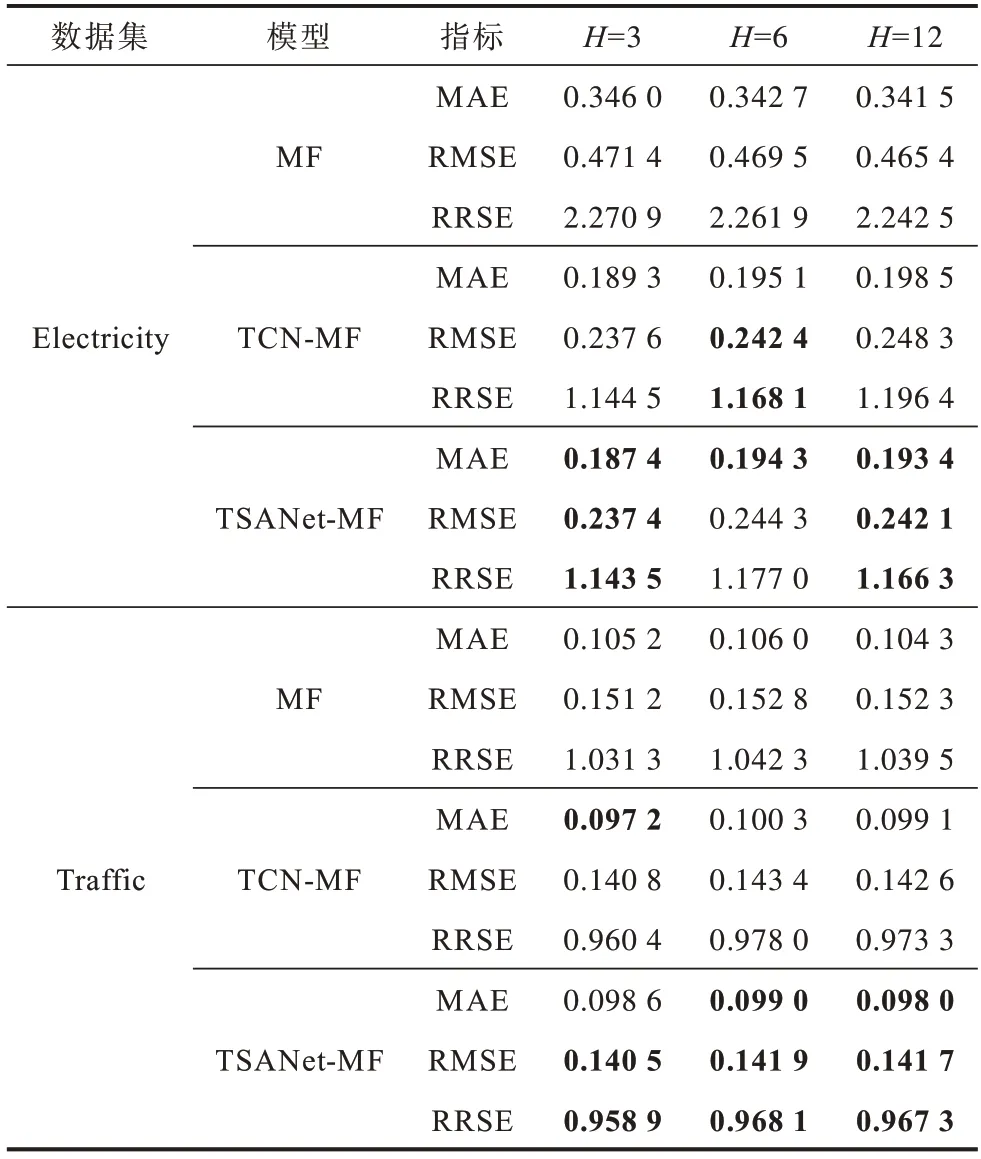
表4 高维数据集上3 种模型的预测结果Table 4 Prediction results of three models on the high-dimensional data sets
表5 给出了H=3 时TSANet-MF、MF、TCN-MF和TSANet 在高维数据集上的总训练时间。由表5可以看出:TSANet-MF 在Electricity 和Traffic 数据集上的训练时间与TSANet 相比分别提升了86.9%、93.4%,说明TSANet-MF 在TSANet 的基础上,训练效率大幅度提升;TSANet-MF 和MF、TCN-MF 模型的训练时间最高相差430 s,说明TSANet-MF 在高维时间序列上同样具有非常高的预测效率。

表5 4 种模型的训练时间Table 5 Training time of four models 单位:s
一般而言,高维原始数据在矩阵分解时,转化的矩阵维度越低,预测准确率越低,这是因为矩阵分解算法在分解时会失去原始时序数据的一些特征,分解维度越低,失去特征越多。为了验证M的维度对于预测性能的影响,实验在Electricity 和Traffic 数据集上对维度k为32 和64 时的TSANet-MF 进行预测对比,如图6 所示。由图6 可以看出:在Electricity 数据集上,当k=32时,H取3、6、12 的MAE、RMSE 和RRSE 预测指标明显比k=64 时高,说明k=32 时数据预测的误差很大;在Traffic数据集上,当k=32时,H取3、6、12的MAE、RMSE和RRSE 预测指标比k=64 时略高,说明k=32 时的预测性能略差。虽然Electricity 和Traffic 数据集都是高维时序序列,但是Traffic数据集的维度远远高于Electricity数据集。在转化为低维数据M时,即当k=64 时,对于Traffic 数据集而言,已经失去了大部分时序特征,因此在k=32 和k=64 的实验中,可以看出两者的误差非常大且非常接近。在两个维度下的对比实验结果说明了高维时序数据矩阵分解的维度与预测准确度的关系,即分解的维度越低,失去的特征越多,预测的误差越大。
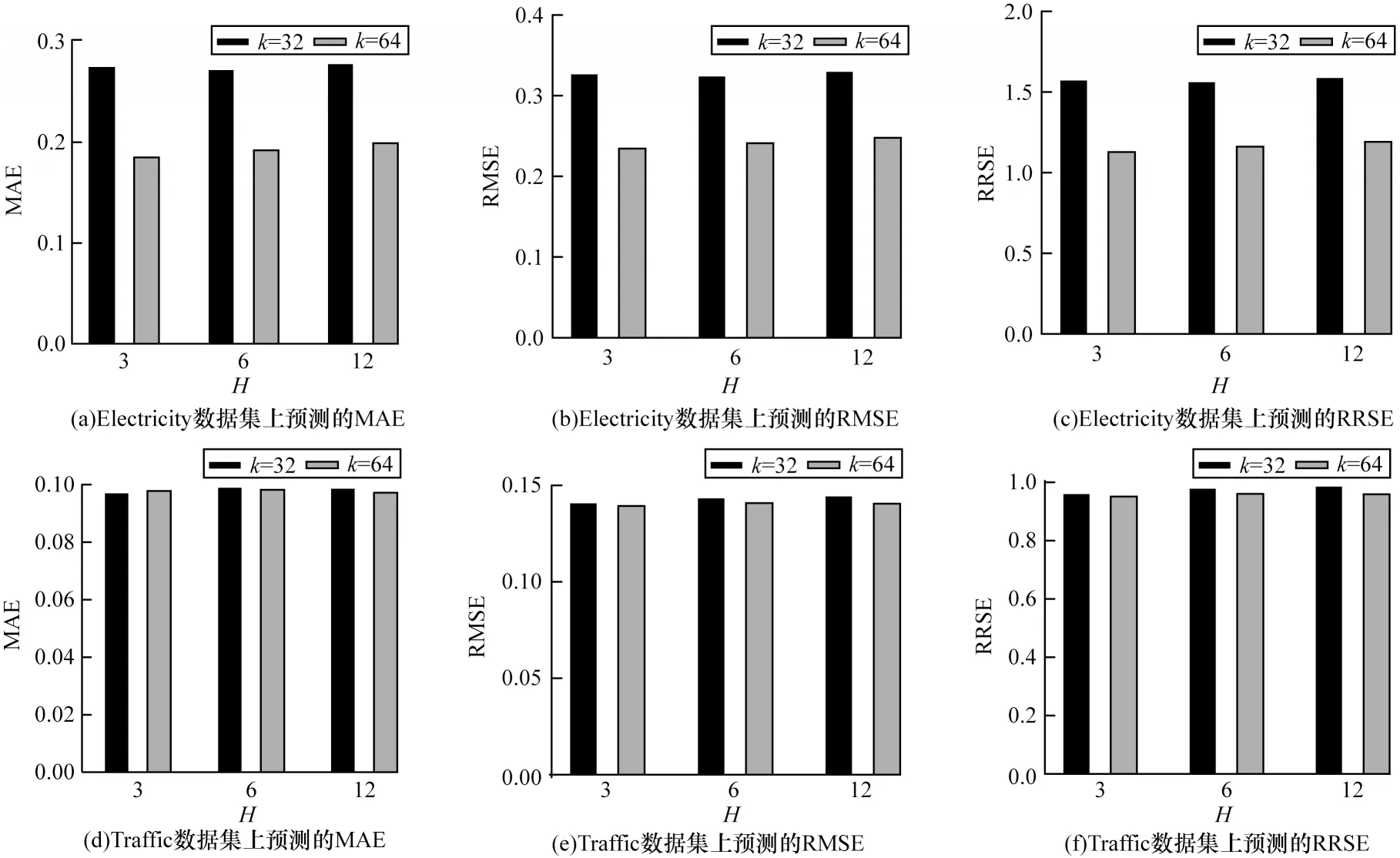
图6 M 维度为32 和64 时高维数据集上的TSANet-MF 预测结果Fig.6 Prediction results of TSANet-MF on the high-dimensional data sets when the dimensions of M are 32 and 64
基于以上实验结果总结归纳TSANet 和TSANet-MF 具有以下优势:1)TSANet 具有较高的预测准确度,可以有效地应用在一般多维时序数据预测中;2)TSANet 利用TCN、全局和局部卷积、selfattention 和AR 模型能够最大程度地捕捉多维时序数据特征;3)TSANet-MF 可以将高维时序数据转化为低维时序数据以提高预测效率;4)TSANet-MF 可以实现高维时序数据的快速模糊预测,并且具有相对较高的预测性能。
6 结束语
本文建立基于TCN 和self-attention 的两种混合网络模型。TSANet 融合了线性和非线性的神经网络结构,结合TCN、自注意力机制等提取不同数据周期性特征。TSANet-MF 是TSANet 的衍生模型,使用时间正则化项更准确地进行数据降维分解,从而实现高维时序数据快速模糊预测。实验结果表明,相比于基准模型,TSANet 可以有效提升时间序列的预测精度,TSANet-MF 具有更高的训练效率。后续将继续研究数据离散尺度较大情况下的高维时间序列预测方法,加强深度神经网络在时序预测中的可解释性。
