基于改进自注意力机制的金字塔场景解析网络
2023-01-27郑秋梅徐林康王风华林超
郑秋梅,徐林康,王风华,林超
(1.中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580;2.中国石油大学(华东)信息化建设处,山东 青岛 266580)
0 概述
语义分割是对目标图像中的所有像素进行分类,并赋予对应的ID,利用颜色标注表示该像素的语义信息在自动驾驶和医疗图像中都得到了应用。
图像分割早期阶段提取的是图像的浅层特征,研究人员利用图像中的像素值梯度或设置阈值提出了Ostu[1]、FCM[2]、分水岭[3]等算法,但这些算法无法精细分割复杂场景的图像,分割图也不具有语义信息。
2015 年,LONG[4]等提出的全卷积网络(Fully Convolutional Network,FCN)通过全卷积化将最后的全连接层删除,满足任意分辨率的输入,并结合跳跃结构保证网络分割的健壮性和准确率。文献[5]提出了金字塔场景解析网络(Pyramid Scenarios Parse Network,PSPNet),通过引入金字塔池化模块,融合多尺度上下文信息,弥补了FCN 缺乏对图像全局特征和上下文信息利用的问题。而此类基于特征融合的网络[6-7]在将卷积神经网络(Convolutional Neural Nework,CNN)作为主干网络进行特征提取时,针对特征图中所有的通道和空间都默认具有相同的权重,但并非所有的通道都值得关注,这也导致PSPNet 得到的分割图表现出对小目标与物体边缘语义分割效果不佳,因此可在主干网络中添加注意力模块[8-15]来计算不同的权重以提高主干网络提取特征的能力。
2018 年,HU[16]等提出SE 注意力模块,它从通道维度来计算全局信息并取得特征通道的权重,但忽略了特征图空间位置的权重信息。文献[17]针对城市场景数据集中像素的空间排布规律提出了层次对齐网络,通过类似于全连接的方式取得高度驱动的注意力图,从而实现分割精度的提高,但是这种网络只是针对特定的数据集,并不具有泛化性。文献[18]提出了卷积块注意模块(Convolutional Block Attention Module,CBAM),它对特征图的通道、空间进行注意力的计算,将其添加到基础网络中可使网络更注意目标物体的本身以得到更好的精度。该模块虽然关注了通道和空间的权重信息,但这种采用全连接的方式并未考虑两种维度的内在相关性。对于网络中的特征图,无论空间或是通道信息之间都具有很强的相关性,网络通过计算这种相关性能更好的识别目标并进行分割,2021 年,YUAN[19]等提出了对象上下文网络,它是对通道和空间两个维度采用自注意力机制来捕获内在相关性,自适应地结合局部与全局特征。但该网络并未考虑到使用自注意力机制时对特征图进行降维后,像素排列的顺序会对结果产生影响。而当前对二维特征图进行降维的方式会使具有相似语义的相邻像素在降维后导致距离过大,这样并不利于自注意力机制的计算。
GILBERT[20]提出一种空间填充曲线,可用一维曲线去包含整个二维空间,称为希尔伯特曲线(Hilbert Curve,HC)。文献[21]利用HC 对二维点云数据进行遍历,这种利用HC 曲线进行遍历的方法在计算机多个领域得到了广泛应用,但在图像领域较少应用。
本文提出一种基于希尔伯特曲线遍历算法和自注意力机制的金字塔场景解析网络HA-PSPNet。将通道、空间注意力模块添加自注意力机制并分别放入PSPNet的两个子网络中,加强两个子网络提取特征的能力,同时利用HC 遍历算法改变图像降维方式,在不增加网络参数量的情况下提高自注意力计算能力,以使网络分割小目标和物体边缘更加精确。
1 相关理论
1.1 金字塔场景解析网络
针对FCN 缺乏对全局信息和上下文信息关注的问题,ZHAO 提出了金字塔池化模块[5]。该模块将主干特征提取网络输出的特征图X∈RC×H×W进行平均池化,生成分辨率为1×1、2×2、3×3、6×6 的特征图。通过卷积再聚合这些具有不同程度上下文信息的特征图,以提高全局信息获取能力,将聚合后的特征图进行上采样,再和特征图X∈RC×H×W进行通道维度的拼接,通过像素分类最后输出预测图。金字塔池化模块结构如图1 所示。
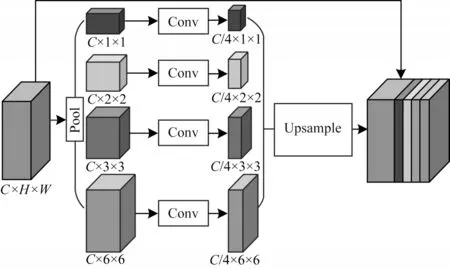
图1 金字塔池化模块结构Fig.1 Structure of pyramid pooling module
为了使网络具有采集全局上下文信息的能力,该模块把不同区域的上下文信息进行聚合,但PSPNet 仍存在对图像中目标的边缘轮廓和一些细小目标进行分割时不够精细的问题,这主要是由于PSPNet 的主干网络进行特征提取时,对特征图中所有通道都默认具有相同的权重,然而并不是所有的通道都值得关注,且在加强网络中经过平均池化后的特征图具有丰富的语义信息,只进行普通的卷积并不能完全利用这些深层次信息。
1.2 CBAM 与自注意力机制
CBAM 主要包括通道注意力模块和空间注意力模块。通道注意力模块的作用是为特征图通道分配不同的权重,给具有重要特征的通道更高的权值。该模块会对输入的特征图进行基于空间的平均与最大池化,再将两种特征图分别进行两次全连接后相加,经过Sigmoid 进行激活操作得到通道注意力特征图,其公式如下:
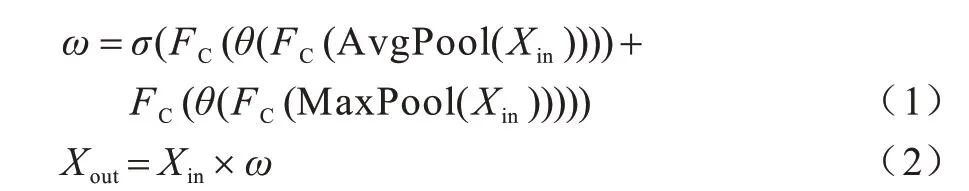
其中:Xin∈RB×C×H×W表示在主干网络中输出的特征图;ω∈RB×C×1×1表示各个通道的权重;FC表示全连接操作;θ为全连接后的ReLU 操作;σ是Sigmoid 操作。经过Sigmoid 操作后得到了每一个特征通道的权重信息,再和Xin进行相乘最终得到Xout∈RB×C×H×W。
空间注意力模块是将上面模块输出的特征图作为输入,将该特征图进行基于通道的全局最大与平均池化,得到两个形状为B×1×H×W的特征图,然后对这两个特征图进行拼接,经过卷积降维到1 个通道,利用Sigmoid 函数生成空间注意力特征图,最后与该模块的输入做乘法,得到最终生成的特征。空间注意力机制公式如下:
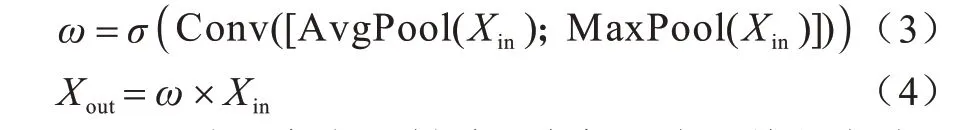
上述两种注意力机制采用类似于全连接的方式,在该方式下计算的权重需要目标图像参与,再对权重值进行计算,忽略了源特征图通道和空间两种维度的内在相关性,而采用自注意力机制可以解决这一问题。它将目标像素与剩余像素进行协方差计算,把像素看成随机变量,参与的目标像素只是所有像素值的加权和,得到的权值信息都与所有像素有关。
2018 年,WANG[22]等在CNN 中提出用selfattention 来实现像素级预测的全局参考。
自注意力机制的协方差公式如下:
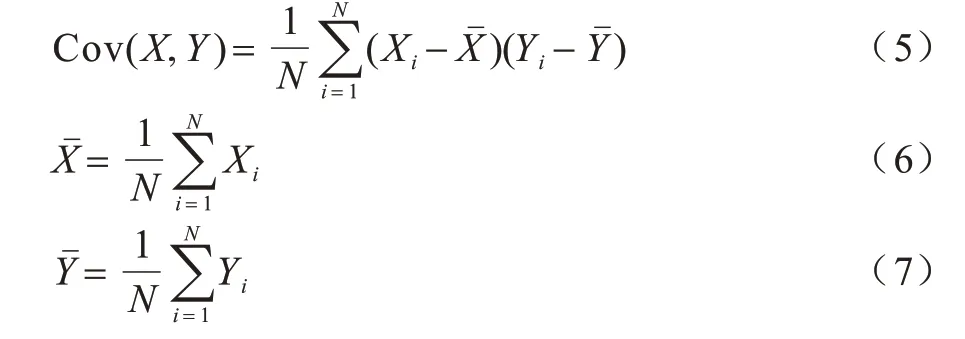
把自注意力机制引入到CBAM 模块中,会使改进后的注意力模块更好地关注于两种维度的自相关性,得到特征图更好的权重信息。
但将自注意力机制放入网络[23]时,它对“词”向量的位置很敏感,不同位置向量所代表的含义也是不同的。例如,“我喜欢她”和“她喜欢我”,虽然两句话所用的字都一样,但是因为字的顺序不一样,所表达的意思也不一样。目前,大多数的降维工作都只是将后一行的像素拼接到前一行,使得特征图上下相似语义像素的信息距离太远,不利于自注意力的计算。
1.3 希尔伯特曲线
从数学的角度看,每一阶伪希尔伯特曲线是一个映射Hn,它的起、终点是正方形的左下角和右下角:

通过将希尔伯特曲线在特征图上的遍历来代替传统的降维方式有一种优点,即能够保证二维平面在被降维到一维向量时四周的像素距离并未拉大,使一维向量能够自然过渡。
2 基于PSPNet 网络的改进
2.1 改进的整体网络结构HA-PSPNet
本文将改进的通道注意力模块添加到主干网络的ResNet[24]中,通过对每个通道进行权重计算来提高主干网络的特征图提取能力,再把改进的空间注意力模块添加进PSPNet 的加强网络中,并将基于希尔伯特曲线设计的遍历算法加入具有丰富语义特征的空间注意力模块中,使得语义信息高度相似的像素排在一起,提高自注意力的计算能力,具体网络结构如图2 所示。
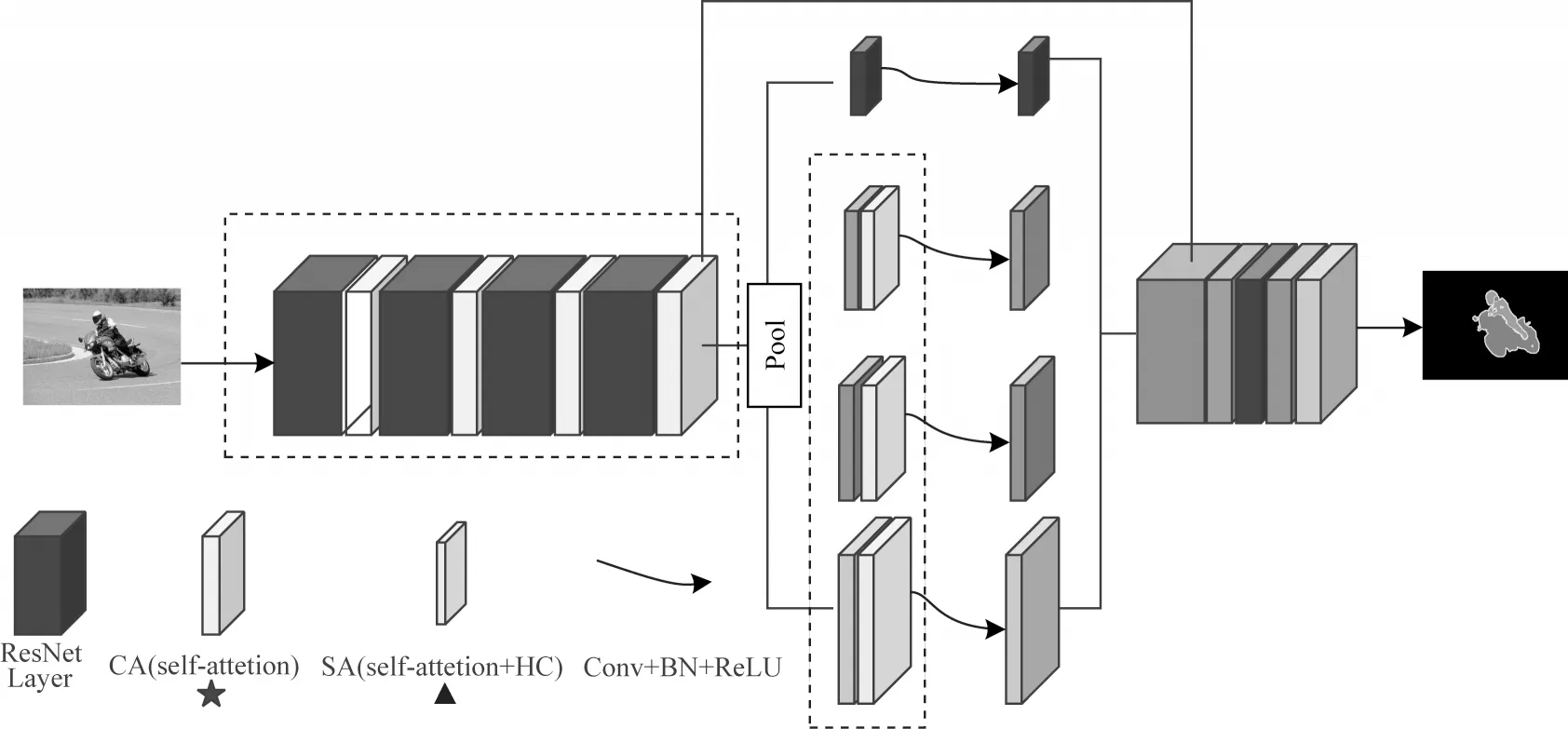
图2 HA-PSPNet 网络结构Fig.2 Structure of HA-PSPNet network
在图2 中,标有星号和三角形方块是本文基于自注意力的通道注意力(Channel Attention,CA)和空间注意力(Spatial Attention,SA)模块。其中空间注意力模块中添加了希尔伯特曲线遍历算法,虚线框是本文对于PSPNet 改进的位置。
2.2 基于通道注意力机制的改进
由于特征图中的每个通道是某一特征的响应,而这些特征之间本身存在一定的联系,若采用简单的全连接获取通道权值容易忽略这种特征间的依赖关系。同时,CNN 在计算全局信息来捕获长范围特征依赖时需要多层网络的累积,导致学习效率低下。自注意力机制的非局部操作可以直接计算两个语义像素之间的关系捕获长范围的依赖关系,且相较于堆叠的卷积网络也更快速。
因此,将通道注意力模块的中间两次全连接变换成自注意力机制,利用自注意力机制从非局部的角度来捕获通道维度上的特征依赖关系,为每个通道分配权重,其模块结构如图3 所示。
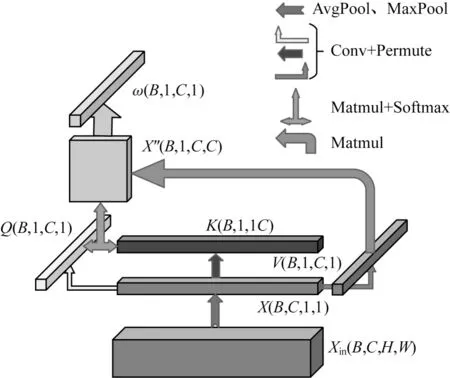
图3 非局部通道注意力模块Fig.3 Non-local channel attention module
该模块是先将平均池化和最大池化后的特征图进行维度的交换,随后通过三次1×1 的卷积变成3 个卷积Q(Query)、K(Key)、V(Value),Query 和Key 分支进行矩阵乘法得到一个形如B×1×C×C的关系矩阵,接着对该矩阵使用Softmax 函数得到每个通道与其他通道的关系的特征图,最后将Value 的分支与特征图相乘。此时得到的结果中每个值都与其他位置的值有关联,代表该通道与其他通道都进行了计算,故有了全局上下文的信息。最后将各个通道的权值图ω与Xin相乘,得到所需的特征图Xout。自注意力公式如下:
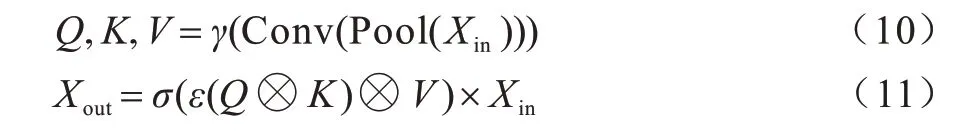
其中:γ表示对卷积后的特征图的维度变换;ε表示Softmax 函数。
通过在主干网络中添加改进后的通道注意力模块,提高了主干网络特征的提取能力,使得平均交并比和平均像素准确率两个指标都有所提升。
2.3 基于空间注意力机制的改进
为了得到特征图中每个像素的权重值,将原模块进行下采样后再上采样还原至原分辨率。通过全连接的方式利用源特征图与目标图的关系来找到权重,而这忽略了特征图像素内部间的关系。因此,本文先将二维的特征图降维到一维向量,再利用自注意力机制来得到特征图中像素上下文的依赖关系,如图4 所示。
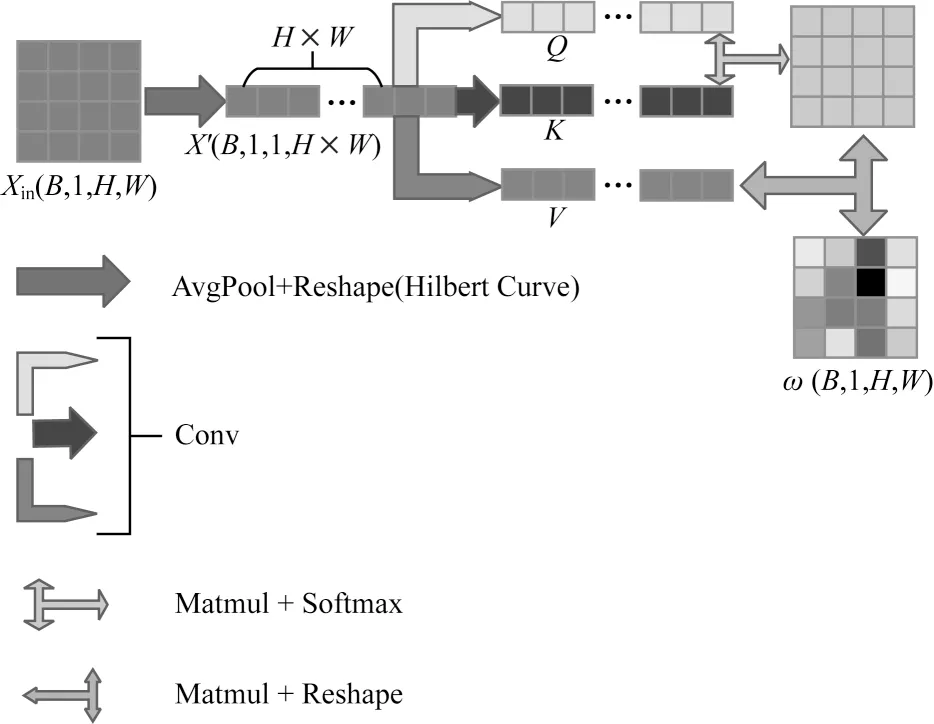
图4 非局部空间注意力模块Fig.4 Non-local spatial attention modules
对于输入的特征图,本文只采用了平均池化,随后对池化后的特征图进行维度变换,通过三次卷积,分别生成Q、K、V。Query 和Key 进行矩阵乘法后使用Softmax 函数生成注意力图,之后和Value 矩阵相乘得到各个像素权重值的向量,最终将向量维度转换成权重图ω,并和输入的特征图Xin相乘。
在1×1 的特征图中不存在和其他像素的关联,故本文只对2×2、4×4、8×8 这3 种特征图进行空间注意力的转化。经过空间注意力计算后,特征图有了更好的表达能力,进一步提高了图像的分割效果。
2.4 希尔伯特曲线的遍历
本文采用希尔伯特曲线而不采用最简单的遍历方式的原因在于:经过多次下采样和池化后的特征图中的像素具有丰富的语义信息,原来语义紧密相关的像素在被降维后,因距离过大而使得用自注意力机制计算出的相关性也产生了变化。而在采用希尔伯特曲线进行遍历后,周围像素没有产生很大的距离,这样可以使自注意力机制发挥更好的作用。
本文针对空间注意力中的遍历算法进行替换,利用希尔伯特曲线遍历后的一维向量进行自注意力机制得到权重值向量,最后通过反希尔伯特曲线遍历升维得到权重图。
图5 所示分别是一~三阶的希尔伯特曲线在特征图中的遍历,可以看出,在二维的特征图中相邻的像素在变成一维后是接近的,尽可能地保持原空间中相邻点的相关性,便于自注意力机制的计算,从而得到更加精确的权重信息。
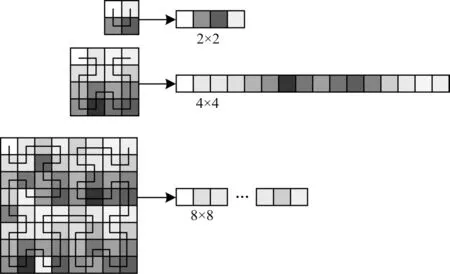
图5 特征图的希尔伯特曲线遍历Fig.5 Hilbert curve traversal of feature graph
本文通过对通道注意力模块、空间注意力模块的改进,将它们添加进PSPNet 网络中不同的位置,使得原网络中的主干网络和加强网络的特征提取能力都有了明显提升,进而提高了整个网络的分割精度。
3 实验与结果分析
3.1 PASCAL VOC 2012 数据集
本次实验采用的是PASCAL VOC 2012 数据集,该数据集针对语义分割部分有20 个分类,外加1 个背景类。
在训练网络时,由于训练集每张图像的大小都不一样,因此本次实验将图像和标签的大小设置为473×473。同时,在对图像和标签进行大小调整时,分别对它们采用双三次(BiCubic)插值和最邻近(NEAREST)插值,随机对图像和对应标签进行左翻转。BiCubic 函数如下:
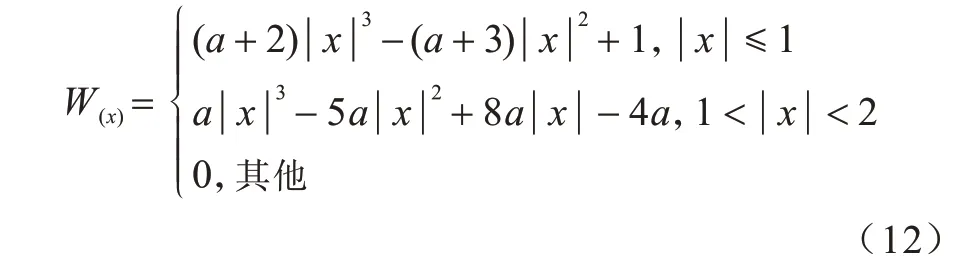
其中:a取-0.5。
3.2 评价指标
本文采用语义分割的两种指标平均像素准确率(Mean Pixel Accuracy,MPA)、平均交并比(Mean Intersection over Union,MIoU)来评价实验效果。
1)MPA
像素准确率(Pixel Accuracy,PA)表示分类正确的像素数与总像素数的比例。表1 所示的是网络对于像素预测值与其真实值相比所包含的4 种结果,其中,TTP表示被模型预测为正类的正样本,TTN表示被模型预测为负类的负样本,FFP表示被模型预测为正类的负样本,FFN表示被模型预测为负类的正样本。

表1 像素预测的4 种结果Table 1 Pixels predict four results

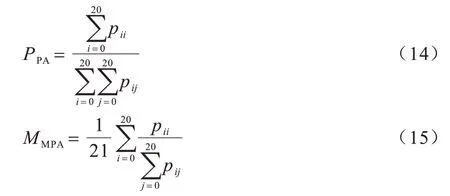
其中:pii表示将第i类分割成第i类的像素数量(分类正确的像素数量);pij表示将第i类分割成第j类的像素数量(图像中的像素总数)。
2)MIoU
交并比(Intersection over Union,IoU)表示的是对图像中某一种类别预测结果和真实值的交集与并集的比例,公式如下:
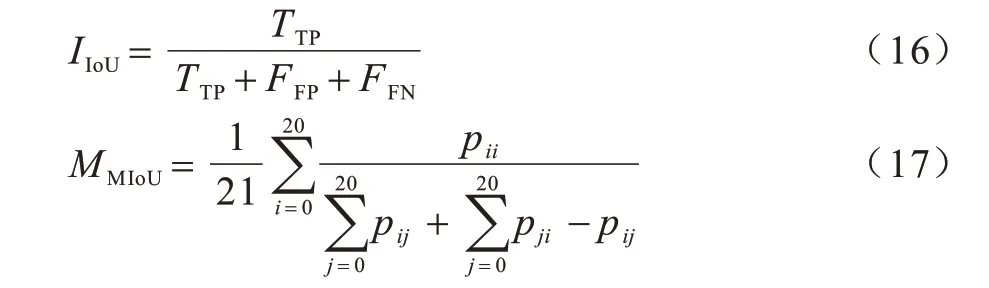
其中:MMIoU是对每种类别计算出的交并比求和后的平均值。
3.3 实验参数
模型构建、数据集的验证与测试均在pytorch 框架下进行,网络的训练是用单块16 GB 的Tesla P100,而网络的评估是在NVIDIA 1650 的显卡下进行的。实验的Batch 值为12,迭代次数Epoch 为60。优化器采用的是Adam 优化算法,初始学习率为0.000 1。该算法实现简单且计算高效,对内存的需求较少,适合应用于大规模的数据场景。设置交叉熵损失函数Cross Entropy Loss(CE)与Dice_loss 之和为损失函数,其公式如下:
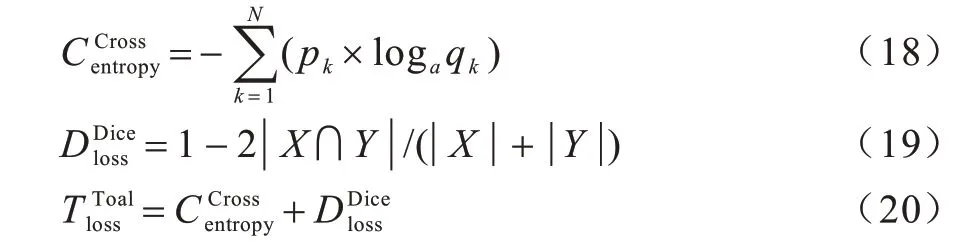
其中:p表示真实值,为one-hot 形式;q表示预测值;X表示Ground Truth 分割图像;Y表示网络预测出的分割图像;表示本次实验的损失函数为两种损失函数之和。
3.4 实验评估
3.4.1 自注意力模块性能评估
本节实验将通道注意力模块、空间注意力模块以及改进后的模块依次放入网络中后对网络在验证集上分割效果进行对比、分析。
实验将通道注意力分别放入以ResNet 为主干网络的4 个模块后,此时特征图中的底层特征依然保留,利用通道注意力的加权保留特征图中的一些边缘和关键点的信息;将空间注意力放入到加强网络中用来计算特征图中高层特征的内在相关性,对这些高层特征进行加权计算,同时也为了后面在模块中添加遍历算法。如表2 所示,当初始的通道注意力模块、空间注意力模块加入到网络后,网络的评价指标都得到提升,说明注意力模块提高了网络的特征提取能力。当实验将自注意力机制分别加入两种模块后,网络分割指标逐步得到提升,尤其是MPA提升了1%以上,说明改进后的两种自注意力模块对于基础网络的分割性能具有促进作用,其中,※表示添加自注意力模块,√表示添加,×表示不添加,粗体表示最优结果。
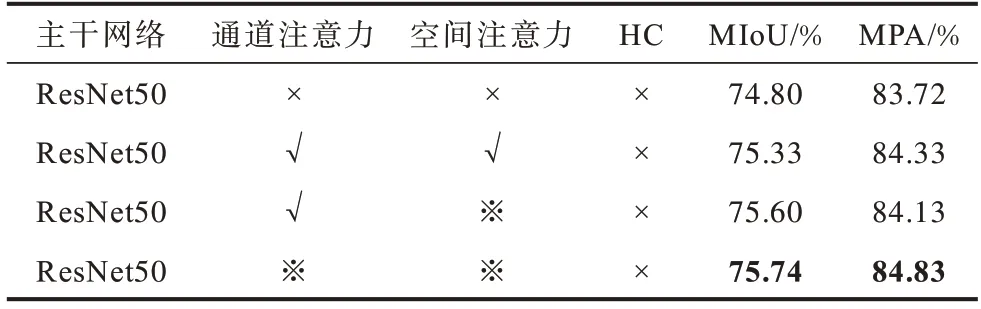
表2 自注意力模块在验证集上的性能Table 2 Performance of the self-attention module on validation set
3.4.2 希尔伯特曲线模块性能评估
本节将希尔伯特曲线加入到改进的模块中,并对网络在验证集上的表现进行分析。同时,把网络在测试集的实验结果放入官网的服务器中进行评价,并与经典网络进行对比。为了证明希尔伯特曲线具有提高自注意力机制计算能力且不增加计算量的优点,增加一个息肉数据集来进行验证。在表3中加入HC 后,MPA 达到了最高值,比基础网络提升了1.35 个百分点,而MIoU 比基础网络也有0.68 个百分点的提升,但还是低于HA☆-PSPNet(表示该网络未添加希尔伯特曲线)。从表4 可以看出,HA☆-PSPNet 只在少数几个类别上IoU 的提升幅度较大,导致MIoU 较高,而HA-PSPNet 对于数据集的绝大多数类别都有提升,且1/2 类别的IoU 达到最高值,因此HA-PSPNet 在整体表现上更优,其中,粗体表示最优结果。
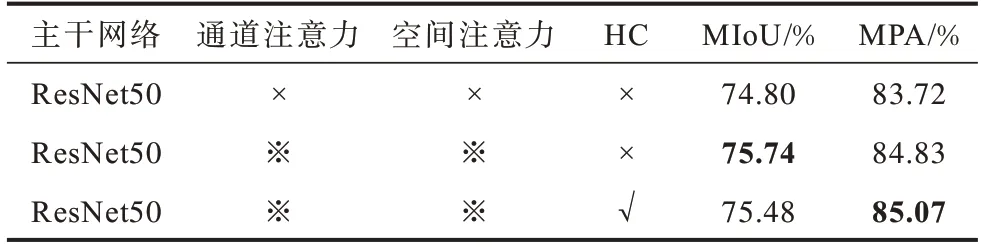
表3 希尔伯特曲线在验证集上的性能Table 3 Performance of the HC on validation set
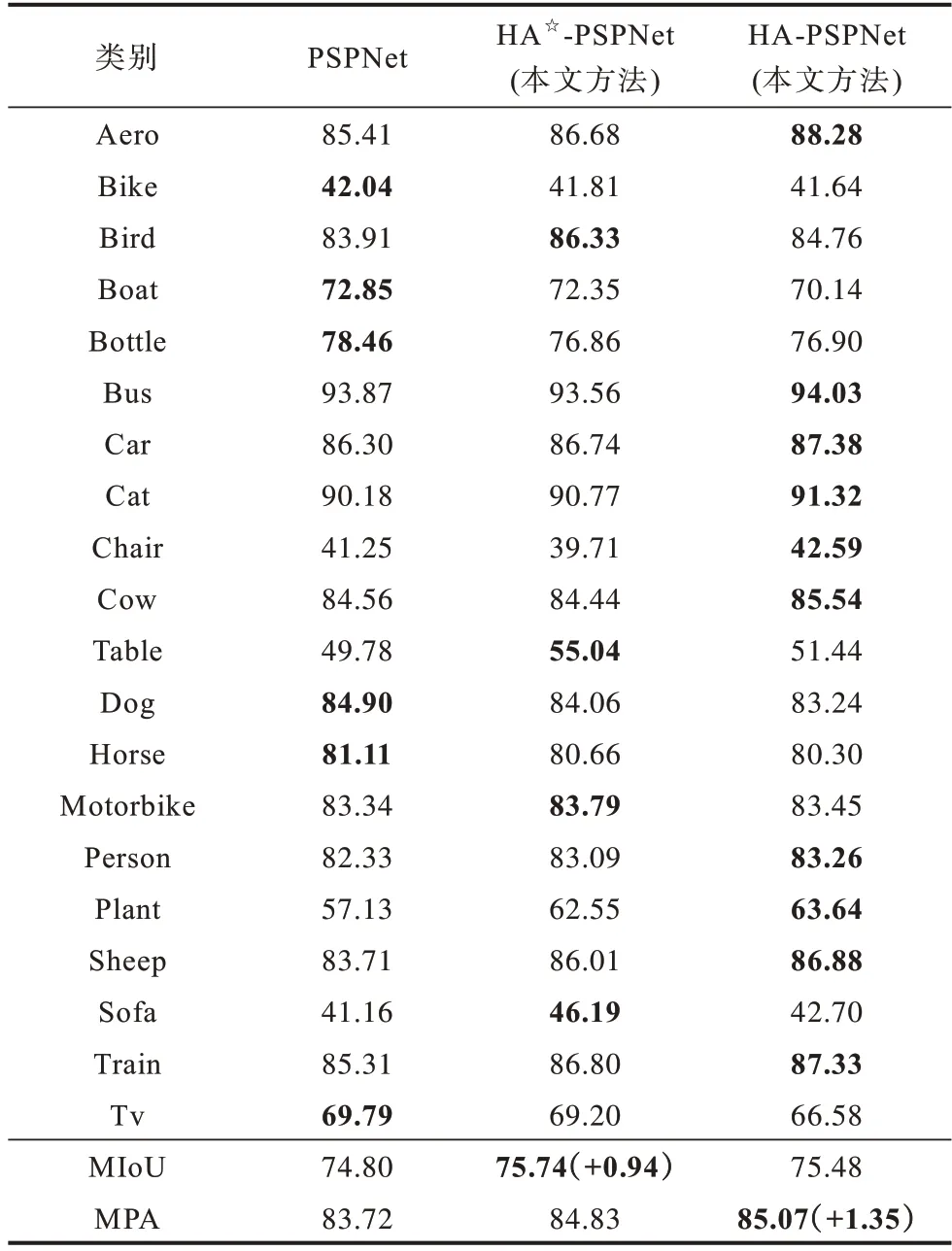
表4 不同类别在验证集上的分割精度Table 4 Segmentation accuracy of different classes on verification set %
从表5 可以看出,本文网络在测试集上对于基础网络依然有着一定的提高,证明了本文网络具有泛化性。

表5 不同算法在测试集上的性能Table 5 Performance of different algorithms on test set %
为了体现HA-PSPNet 的优越性,本文利用kaggle 竞赛中的结肠镜息肉分割和肿瘤表征数据集(BKAI-IGH NeoPolyp)进行再次验证。该数据集图像中所有息肉分为肿瘤性或非肿瘤性类别,外加一个背景类。本文在读取数据集时,只将输入图像的大小设置为512×512 像素,未作其他的图像预处理。
从表6 可以看出,希尔伯特曲线可以提高自注意力机制的计算能力,且由于希尔伯特曲线只是针对图像降维算法的改变,并未设计网络模型的改动,故从表7 可以看出,对于整个网络的参数量并未提升,因此无需更多的计算量。

表6 息肉分割数据集验证结果Table 6 Verification results of polyp segmentation data set %

表7 两种方法的参数量Table 7 Parameters of two methods
3.4.3 结果分析
图6 所示为三种方法在数据集上的分割效果,其中,HA-PSPNet 在一些小目标和物体边缘上处理的更好,比如HA-PSPNet 对于靠里面的飞机能够很好地识别出来,对椅子、桌子的腿部和绵羊边缘处分割效果比基础网络更为明显、精细。无论是HA☆-PSPNet 还是HA-PSPNet,都对原网络有所提升,但从两种数据集的整体表现来看,HA-PSPNet 比HA☆-PSPNet 更好,而HA☆-PSPNet 在一些类别上分割大幅提升,只能说明具有一些特殊性。

图6 三种方法在数据集上的分割效果Fig.6 The segmentation effect of three methods on data set
从图6 可以看出,当两种改进后的自注意力模块分别放入主干网络和加强网络后,使得网络能够识别到图片中的小目标,且对于物体的边缘分割更加精细,同时在不增加网络参数量的情况下通过希尔伯特曲线遍历算法代替传统的遍历算法来提高自注意力模块的计算能力是可行的,表明本文对于PSPNet 的改进是有效的。
4 结束语
本文通过对PSPNet 网络进行改进,提出一种HA-PSPNet 网络。该网络将带有自注意力机制的CA、SA 模块放入到PSPNet 网络中,增强了网络的特征提取能力,使得整个网络对细节的处理更加精细,并利用希尔伯特曲线对空间注意力模块的像素进行遍历,在没有增加计算量的前提下,提高了自注意力模块的计算能力。实验结果表明,HA-PSPNet 网络可明显提高像素精度。但本文只对希尔伯特曲线遍历算法进行初步研究,目前只运用在前三阶的曲线遍历,后续将其运用在更高阶的特征图上,从而能够得到更广泛的应用。
