Task assignment in ground-to-air confrontation based on multiagent deep reinforcement learning
2023-01-18JiayiLiuGangWangQiangFuShaohuaYueSiyuanWang
Jia-yi Liu,Gang Wang,Qiang Fu,Shao-hua Yue,Si-yuan Wang
Air and Missile Defense College,Air Force Engineering University,Xi'an,710051,China
Keywords:Ground-to-air confrontation Task assignment General and narrow agents Deep reinforcement learning Proximal policy optimization (PPO)
ABSTRACT The scale of ground-to-air confrontation task assignments is large and needs to deal with many concurrent task assignments and random events.Aiming at the problems where existing task assignment methods are applied to ground-to-air confrontation,there is low efficiency in dealing with complex tasks,and there are interactive conflicts in multiagent systems.This study proposes a multiagent architecture based on a one-general agent with multiple narrow agents(OGMN)to reduce task assignment conflicts.Considering the slow speed of traditional dynamic task assignment algorithms,this paper proposes the proximal policy optimization for task assignment of general and narrow agents (PPOTAGNA) algorithm.The algorithm based on the idea of the optimal assignment strategy algorithm and combined with the training framework of deep reinforcement learning(DRL)adds a multihead attention mechanism and a stage reward mechanism to the bilateral band clipping PPO algorithm to solve the problem of low training efficiency.Finally,simulation experiments are carried out in the digital battlefield.The multiagent architecture based on OGMN combined with the PPO-TAGNA algorithm can obtain higher rewards faster and has a higher win ratio.By analyzing agent behavior,the efficiency,superiority and rationality of resource utilization of this method are verified.
1.Introduction
The core feature of the modern battlefield is a strong confrontation game.Relying on human judgment and decision-making cannot meet the requirements of fast-paced and high-intensity confrontations,and relying on a traditional analytical model cannot meet the requirements of complex and changeable scenes.In the face of future operations,intelligence is considered to be the key to solving the problem of a strong confrontation game and realizing the transformation of the information advantage into a decision advantage [1].Task assignment is a key problem in modern air defense operations.The main purpose is to allocate each meta-task to execute the appropriate elements to achieve target interception [2] and provide full play to the maximum resource efficiency ratio.The key to solving this problem is establishing a task assignment model and using an assignment algorithm.Weapon target assignment (WTA) is an important problem to be solved in air defense interception task assignment[3].The optimal assignment strategy algorithm is one of the methods for solving the WTA problem.It uses the Markov decision process (MDP) as the main idea.It considers that new targets appear randomly with a certain probability in the assignment process.Hang et al.[4]believe that dynamic weapon target assignment (DWTA) can be divided into two stages:strategy optimization and matching optimization.The Markov dynamics can be used to solve DWTA.On this basis,Chen et al.[5] improved the hybrid iterative method based on the policy iterative method and the value iterative method in Markov process strategy optimization to solve large-scale WTA problems.He et al.[6]transformed the task assignment problem into a phased decision-making process through MDP.This method has good results in small-scale optimization problems.
Although the optimal assignment strategy algorithm continuously improves,the speed of solving large-scale WTA problems is still slightly insufficient.In addition,the WTA method based on MDP cannot immediately deal with emergencies because it needs to wait for processing in the previous stage to end.This paper combines the optimal assignment strategy algorithm for WTA with the DRL method to apply a neural network to the WTA method based on MDP to solve the problems of slow solution speed and not being able to deal with emergencies.
This research aims to apply a multiagent system and DRL to the task assignment problem of ground-to-air confrontation.Because a multiagent system has superior autonomy and unpredictability,it has the advantages of strong solution ability,fast convergence speed and strong robustness in dealing with complex problems[7].QMIX algorithm can train decentralised policies in a centralized end-to-end fashion,and has a good performance in StarCraft II micromanagement tasks [8].Cao J et al.[9] proposed the LINDA framework to achieve better collaboration among agents.Zhang Z proposed a PGP algorithm using policy gradient potential as the information source for guiding strategy update[10]and a learning automata-based algorithm known as LA-OCA[11].Both algorithms have good performance in common cooperative tasks,and can significantly improve the learning speed of agents.However,due to the self-interest of each agent in the multiagent system and the complexity of the capacity scheduling problem of the multiagent system[12],it is prone to interactive conflict when dealing with the task assignment of large-scale ground-to-air confrontation.The multiagent architecture based on OGMN is proposed in this paper,which can reduce the system complexity and eliminate the shortcoming that multiagent systems are prone to interactive conflict when dealing with complex problems.Task assignment is a typical sequential decision-making process for incomplete information games.DRL(DRL)provides a new and efficient method to solve the problem of incomplete information games[13],which relies less on external guidance information.There is no need to establish an accurate mathematical model of the environment and tasks.Additionally,it has the characteristics of fast reactivity and high adaptability [14].However,in the ground-to-air confrontation scenario,there is a large quantity of data,and it is difficult to directly convert the combat task target into a reasonable reward function,so decision-making faces the problems of sparse feedback,delay and inaccuracy,resulting in low training efficiency.According to the characteristics of large-scale ground-to-air confrontation,this paper proposes the PPO-TAGNA algorithm,which effectively improves the training efficiency and stability through a multihead attention mechanism and phased reward mechanism.Finally,experiments in the digital battlefield verify the feasibility and superiority of the multiagent architecture based on the OGMN and PPO-TAGNA algorithms to solve the task assignment problem of ground-to-air confrontation.
2.Background
2.1.Multiobjective optimization method
Since there may be conflicts or constraints between various objectives and there is no unique solution to the multiobjective optimization problem but there is an optimal solution set,the main solution methods of the multiobjective problem in the multiagent system are as follows [15]:
(1) Linear weighted sum method
The difficulty of solving this problem lies in how to allocate the weight,as follows:
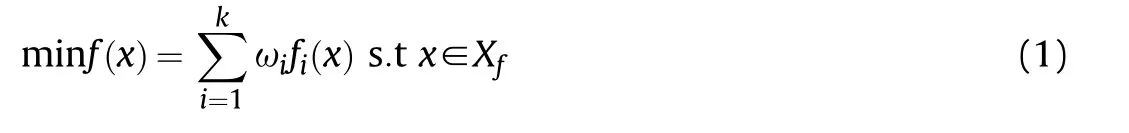
where fi(x) is one of the multiobjective functions,ωiis the weight andThe advantage of this algorithm is that it is easy to calculate,but the disadvantage is that the weight parameters are uncertain,and whether the weight setting is appropriate directly leads to the effect of the optimal solution.
(2) Reward function method
The reward function is used as the solution method of the optimization problem.Its design idea comes from the single-agent system and the rod balance system.The design method of the rod balance system reward function is that after the agent transfers the state,the reward value of failure is - 1,and the reward and punishment value of success is 0.The system has several obvious defects.① During the task executions,the agent cannot define whether it is the state transition that contributes to the final benefits and cannot determine the specific contribution.②The reward function design gives the task a goal but only provides the reward value in the last step,resulting in too sparse of a reward value.The probability of the agent exploring the winning state and learning strategy is very low,which is not conducive to the realization of the task goal.
2.2.Reinforcement learning
The idea of reinforcement learning (RL) is to use trial and error methods and rewards to train agent learning behavior [16].The basic reinforcement learning environment is an MDP.An MDP contains five quantities,namely,(S,A,R,P,γ),where S is a finite set of states,A is a finite set of actions,R is the reward function,P is the state transition probability,and γ is the discount factor.The agent perceives the current state from the environment,then makes the corresponding action and obtains the corresponding reward.
2.3.Proximal policy optimization
Deep learning (DL) uses a deep neural network as a function fitter and combines it with RL to produce DRL,which effectively solves the problem of dimension disaster in large-scale and complex problems in traditional RL methods.Proximal policy optimization(PPO)belongs to a class of DRL optimization algorithms[17].It is different from value-based methods,such as Q-learning.It directly calculates the policy gradient of cumulative expected return by optimizing the policy function to solve the policy parameters that maximize the overall return,PPO algorithm description is shown in Table 1.
The objective function defining the cumulative expected return of the PPO is as follows:
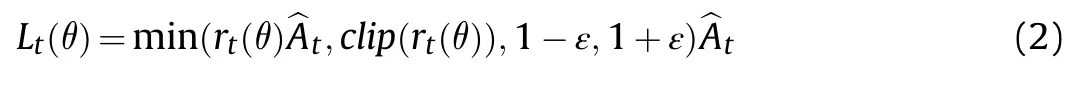
where in the equation as follows:

Atis the dominance estimation function.This can be seen in the equation as follows:
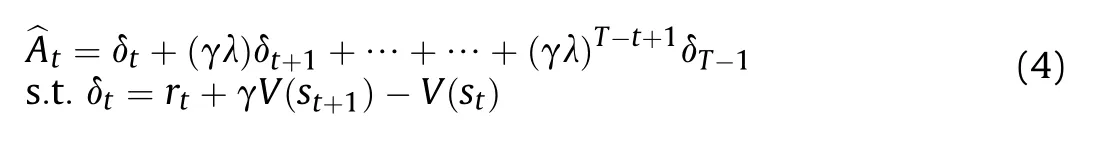

Table 1 PPO algorithm.
2.4.Attention mechanism
The attention mechanism is a mechanism that enables agents to focus on some information at a certain point in time and ignore other information.It can enable agents to make better decisions faster and more accurately in local areas[18].
When the neural network is faced with a large amount of input situation information,only some key information is selected for processing through the attention mechanism.In the model,the maximum convergence and gating mechanism can be used to approximate the simulation,which can be regarded as a bottom-up saliency-based attention mechanism.In addition,top-down convergent attention is also an effective information selection method.For example,when inputting a large text,an article is given,then the content of the article is extracted and a certain number of questions is assumed.The questions raised are only related to part of the article content and have nothing to do with the rest [19].To reduce the solution pressure,only the relevant content needs to be selected and processed by a neural network.
aican be defined as the degree to which the ith information is concerned when the task-related input information X and query vector q are given,and the input information is summarized as follows:

Fig.1 is an example of an attention mechanism.In the red-blue confrontation scene,the computational action can adopt the attention mechanism.For example,the input data x are all currently selectable enemy targets,while q is the query vector output from the front part of the network.
3.Problem modeling
3.1.Problem formulation
Task assignment is the core link in command and control.It means that on the basis of situational awareness and according to certain criteria and constraints,we can make efficient use of our own multiple types of interception resources,reasonably allocate and intercept multiple targets,and avoid missing key targets and repeated shooting,so as to achieve the best effect.The task assignment problem has the principles of the maximum number of intercepted targets,the minimum damage of protected objects and the minimum use of resources.This paper studies the task assignment of ground-to-air confrontation based on the principle of using the least resources and minimum damage to the protected object.
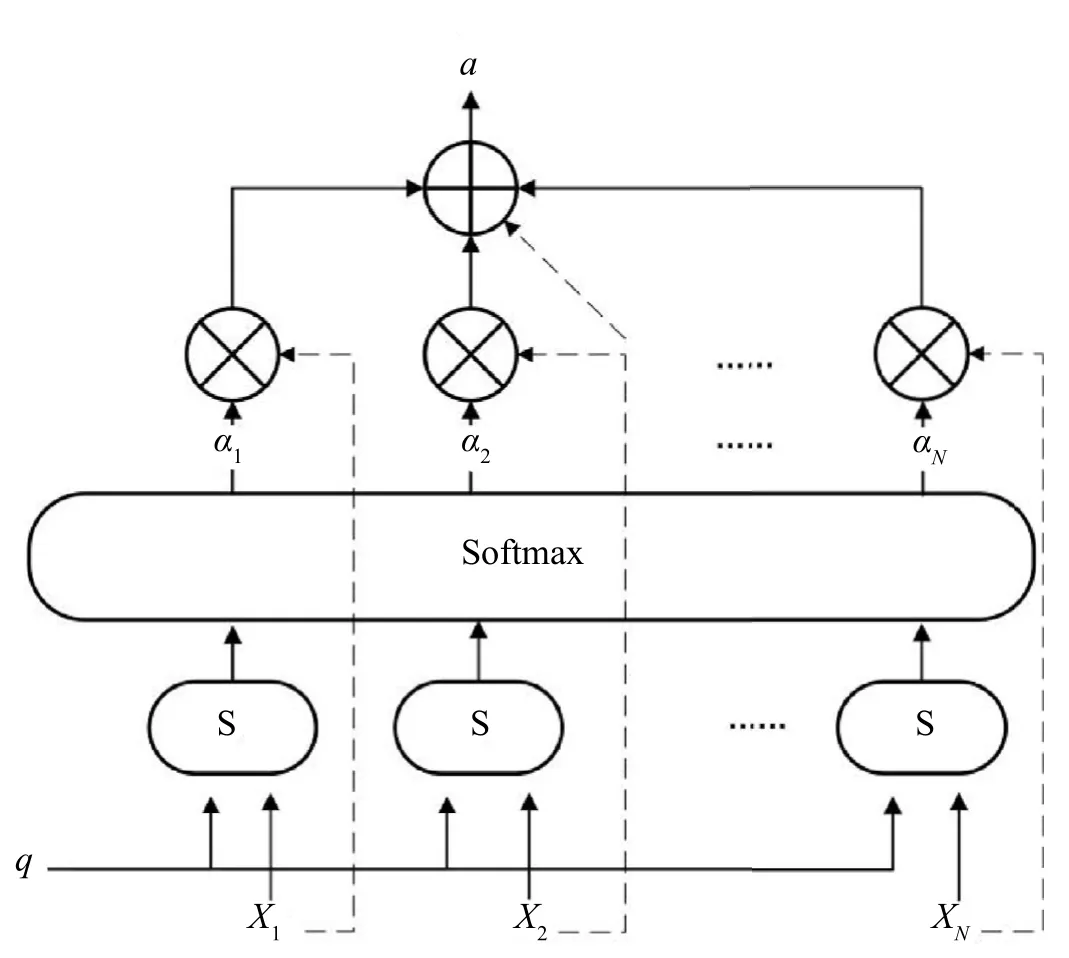
Fig.1.Attention mechanism.
Ground-to-air confrontation system is a loosely coupled system with a wide deployment range.It has a large scale and needs to deal with many concurrent task assignments and random events.The main tasks include target identification,determining the firing sequence,determining the interception strategy,missile guidance,killing targets,etc.The purpose of task assignment in this paper is to use the least resources while protecting the object with the least damage.Therefore,the task assignment of ground-to-air confrontation is a many to many optimization problem.It needs to have fast search ability and strong dynamic performance to deal with regional large-scale air attack,and can dynamically change the task assignment results according to the situation.DRL relies less on external guidance information and does not need to establish an accurate mathematical model of environment and task.At the same time,it has the characteristics of fast reactivity and high adaptability,which makes it suitable for ground-to-air confrontation task assignment.
3.2.MDP modeling
In order to combine the optimal assignment strategy of task assignment with DRL,we establish an MDP model of ground-to-air confrontation,which is divided into the states,the actions and the reward function.
States:(1)The status of the red base,including base information and the status of the base when it is being attacked.(2)The status of the red interceptor,including the current configuration of the interceptor,the working status of the radar,the attack status of the radar,and the information of the enemy units that the interceptor can attack.(3) The status of the enemy units,including the basic information of the enemy units and the status when being attacked by red missiles.(4)The status of enemy units that can be attacked,including the status that can be attacked by red interceptors.
Actions:(1)When is the radar on.(2)Which interception unit to choose.(3) Which launch vehicle to choose to intercept at what time (4) which enemy target to choose.
Reward function:the reward function based on the principle of using the least resources and minimum damage to the protected object in this paper is as follows:
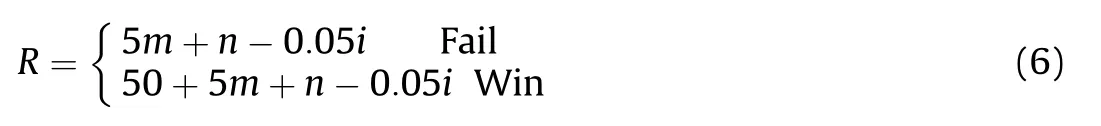
The reward value is 50 points for winning,5 points for intercepting manned targets,such as the blue fighter,1 point for intercepting a UAV,and 0.05 points are deducted for each missile launched.In Eq.(10),m is the number of manned units intercepting the blue side,n is the number of UAVs intercepting the blue side,and i is the number of missiles launched.Since each of the above reward stages is the task goal that the red side must achieve if it wants to win,it can guide the agent to learn step-by-step and stageby-stage.
4.Research on a multiagent system model based on OGMN
4.1.The general and narrow agents architecture design
The task assignment of large-scale ground-to-air confrontation needs to deal with many concurrent task assignments and random events.The whole battlefield situation is full of complexity and uncertainty.The fully distributed multiagent architecture has poor global coordination for random events,which makes it difficult to meet the needs of ground-to-air confrontation task assignments.The current centralized assignment architecture can achieve global optimal results[20],but for large-scale complex problems,it is not practical because of the high solving time cost.Aiming at the command-and-control problem of ground-to-air confrontation distributed cooperative operations,combined with the DRL development architecture and based on the idea of double driving data rules,a general and narrow agents command-and-control system is designed and developed.The global situation in a certain period of time is taken as the general agent input with strong computing power to obtain combat tasks and achieve tactical objectives.The narrow agent based on tactical rules decomposes the tasks of general agents according to its situation and outputs specific actions.The main idea of OGMN architecture proposed in this paper is to retain the global coordination ability of centralized method and combine the efficiency advantage of multiagent.The general agent assigns tasks to the narrow agents,and the narrow agents divide their tasks into sub-tasks,and selects the appropriate time to execute according to their remaining resources,the current number of channels and other information.This method can largely retain the overall coordination ability of general agent,and avoid missing key targets,repeated shooting,wasting of resources and so on.And it can reduce the computing pressure of general agent and improve the assignment efficiency.The general agent assigns tasks to the narrow agent according to the global situation.The narrow agent decomposes the tasks into instructions (such as intercepting a target at a certain time) and assigns them to an interceptor according to its situation.The structural design of general and narrow multiagent systems is shown in Fig.2.
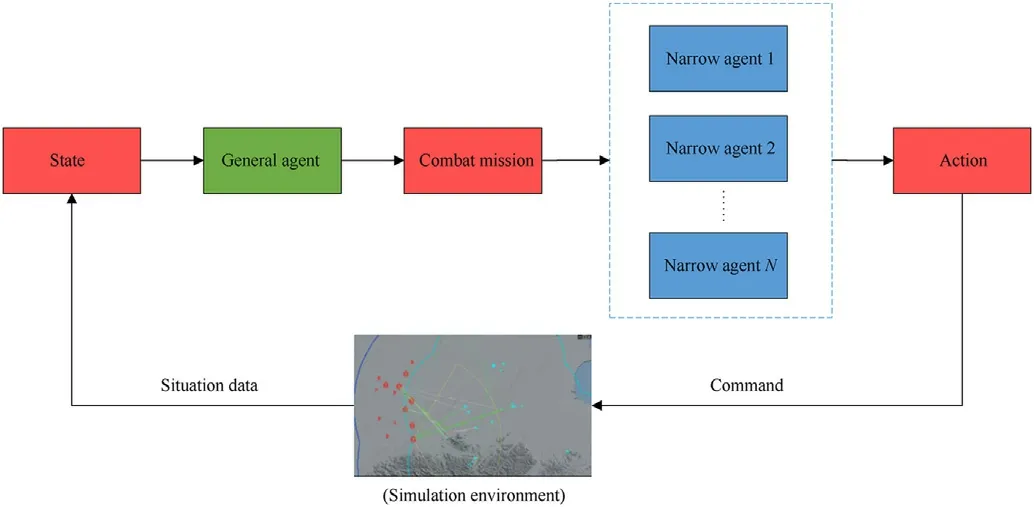
Fig.2.The framework of the task assignment decision model of general and narrow agents.
Based on the existing theoretical basis,this paper vertically combines rules and data to drive general agents and rules to drive narrow agents.The purpose is to improve the speed of a multiagent system to solve complex tasks,reduce system complexity,and eliminate the shortcomings of a multiagent system in dealing with complex problems.It is expected that in a short time,a general agent with strong computing power is used to obtain situation information and quickly allocate tasks,and then multiple narrow agents select appropriate time and interceptors to intercept enemy targets according to specific tasks,as well as their state to save as many resources as possible on the premise of achieving tactical objectives.
4.2.Markov’s decision process of cooperative behavior
Traditional multiagent collaborative decision-making research mainly focuses on model-based research [21],namely,rational agent research.Traditional task assignment research has the disadvantages of relying too much on the accuracy of the model behind it.It only focuses on the design from the model to the actuator,but it does not focus on the model’s generation process.In the intelligent countermeasure environment,there are many kinds of agents.For multiple agents,it is difficult to obtain accurate decision-making models,models,complex task environments and situation disturbances.Additionally,environmental models present certain randomness and time variability [22-24].All these factors need to be studied to control the method of agent models under the lack of information.
The essence of this framework shown in Fig.3 is to solve the large-scale task assignment problem based on the idea of an optimal assignment strategy algorithm and a DRL method.
MDP four elements are set:(S,A,r,p):state(S),action(A),reward(r),transitionprobability(p);Markovproperty:p(st+1|s0,a0,…,st,at)=p(st+1|st,at) strategy function π:S→A orπ:S× A→[0,1];
Optimization objective: The objective is to solve the optimal strategy function π*,maximizing the expected cumulative reward value as follows:
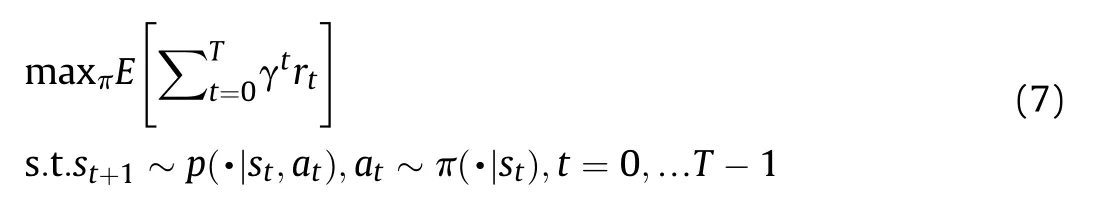
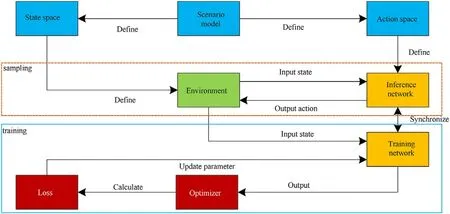
Fig.3.The research framework of the cooperative behavior decision model of general and narrow agents.
The method uses a reinforcement learning algorithm to solve the MDP when p(st+1|st,at) is unknown.The core idea is to use temporal-difference learning (TD) to estimate the action-value function as follows:
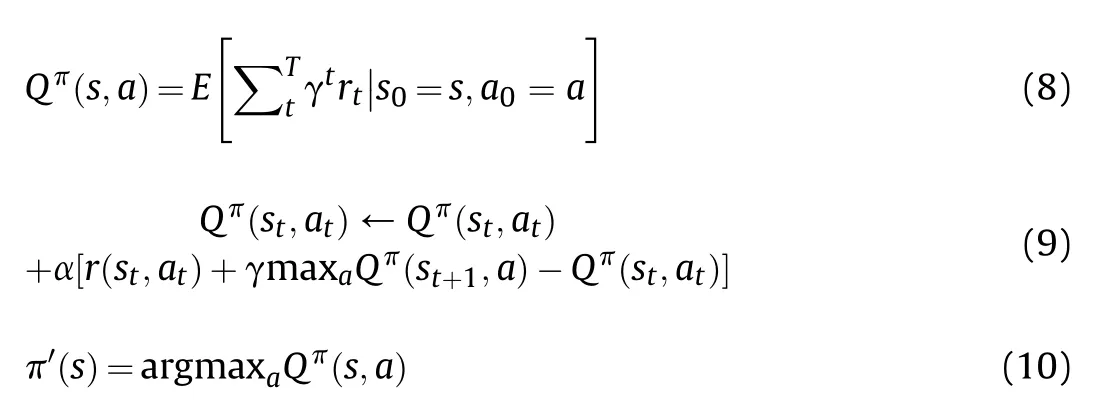
Compared with Alpha C2[25],the model framework optimizes the agent state,which better meets the conditions of rationality and integrity.Rationality requires that states with similar physical meaning also have small numerical differences.For example,for the launch angle θ of the interceptor,since θ is a periodic variable,it is unreasonable to directly take θ as a part of the state.Thus,the launch angle θ should be changed to[cos θ,sin θ].
Integrity requires that the state contains all the information required by the agent's decision-making.For example,in the agent's trajectory tracking problem,the trend information of the target trajectory needs to be added.However,if this information cannot be observed,the state needs to be expanded to include historical observations,such as the observation wake of the blue drone.
5.PPO for task assignment of general and narrow agents(PPO-TAGNA)
To solve the task assignment problem in large-scale scenarios,this paper combines the optimal assignment strategy algorithm with the DRL training framework,designs the stage reward mechanism and multihead attention mechanism for the traditional PPO algorithm,and proposes a PPO algorithm for the task assignment of general and narrow agents.
5.1.Stage reward mechanism
The reward function design is the key to the DRL application in ground-to-air confrontation task assignment.The DRL reward function design must be analyzed in detail.To solve the ground-toair confrontation task assignment problem,the reward value design idea in Alpha C2 [25] is to set the corresponding reward value for each unit type.If there is unit loss,the reward value of the corresponding unit is given.At the end of each deduction round,the reward value of each step is added as the final reward value.However,in practice,the reward value lost by each unit offsets each other at each step,resulting in a small reward value and low learning efficiency.Nevertheless,if only the reward value of victory or failure is given in the last step of each game,the reward value of the other steps is 0,which is equivalent to no artificial prior knowledge being added,which can give the neural network the maximum learning space.However,it leads to too sparse of a reward value,and the probability of neural networks exploring the winning state and learning strategies is very low [26].Therefore,the ideal reward value should be neither too sparse nor too dense and can clearly guide the agent to learn in the winning direction.
The stage reward mechanism adopts the method of dismantling task objectives and giving reward values periodically to guide the neural network to find strategies to win.For example,phased rewards can be given at one time after successfully resisting the first attack.After the loss of the blue side high-value unit,the corresponding reward value is given.After the red side wins,it is given the winning reward value.On this basis,the reward function is optimized according to different objectives in the actual task,such as maximum accuracy,minimum damage,minimum response time,interception and condition constraints,to increase the effect of maximizing global revenue on the revenue of the agent and reduce the self-interest of the agent as much as possible.
5.2.The multihead attention mechanism
5.2.1.Neural network structure
The neural network structure of the multiagent command-andcontrol model is shown in Fig.4.The situation input data are divided into four categories.The first category is the status of the red base,including base information and the status of the base when it is being attacked.The second category is the status of the red interceptor,including the current configuration of the interceptor,the working status of the radar,the attack status of the radar,and the information of the enemy units that the interceptor can attack.The third category is the status of the enemy units,including the basic information of the enemy units and the status when being attacked by red missiles.The fourth category is the status of enemy units that can be attacked,including the status that can be attacked by red interceptors.The number of units of each type of data is not fixed and changes with the battlefield situation.
Each type of situation data carries out feature extraction through two layers of fully connected rectified linear units (FCReLU) and then connects all feature vectors before generating global features through one layer of FC-ReLU and gated recurrent units(GRUs)[27].When making decisions,neural networks should consider not only the current situation but also historical information.Networks need to continuously interact with the global situation through GRU and choose to retain or forget the information.The global feature and the selectable blue unit feature vector are calculated through the attention mechanism to select the interception unit.Each intercepting unit then selects the interception time and the enemy units through an attention operation according to its state and combined with the rule base.
5.2.2.Standardization and filtering of stat data
State data standardization is a necessary step before entering the network.The original status data include various data,such as radar vehicle position,aircraft speed,aircraft bomb load,and threat degree of enemy units.The unit and magnitude of this kind of data are different,and thus,it must be normalized before being input into the neural network.In the battle process,some combat units later join the battle situation,some units are destroyed,and thus,the data are lost.The neural network needs to be compatible with these situations.
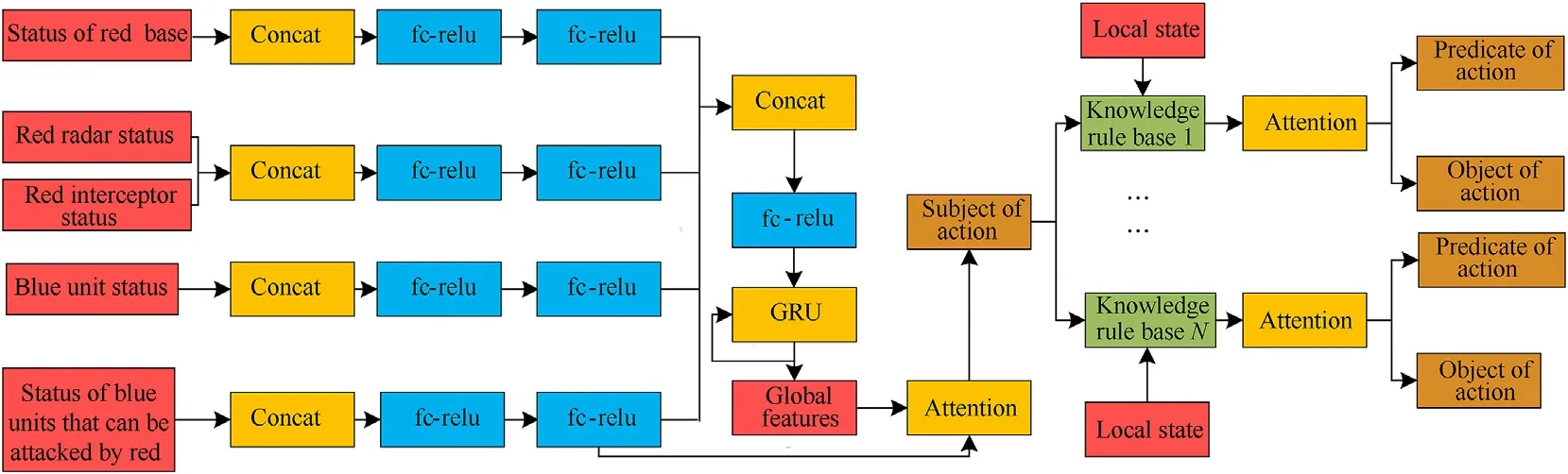
Fig.4.Neural network structure.
Different units have different states at various time points.Therefore,when deciding to select some units to perform a task,it is necessary to eliminate those participating units that cannot perform the task at this time point.For example,there must be a certain time interval between two missile launches by the interceptor,and the interceptor must be connected to the radar vehicle to launch the missile.
5.2.3.The attention mechanism and target selection
In this paper,the decision-making action is processed by multiple heads as the network output,meaning that the action is divided into action subject (which interception unit to choose),action predicate (which launch vehicle to choose to intercept at what time),and action object (which enemy target to choose).
When selecting interception targets,the network needs to focus on some important targets in local areas.In this paper,the state of each fire unit and the eigenvector of the incoming target are used to realize the operation of the attention mechanism by using an additive model.
X=[x1, …, xN] is defined as N input information,and the probability aiis first calculated by selecting the ith input information under the given q and X.Then,aiis defined as follows:
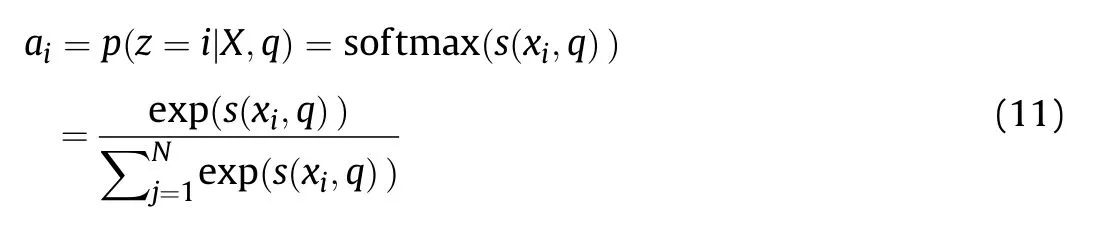
where aiis the distribution of attention,s(xi,q) is the attention scoring function,and the calculation model is the additive model as follows:

where the query vector q is the feature vector of each fire unit,xiis the ith attack target that is currently selectable,W and u are the trainable neural network parameters,and v is the global situation feature vector,namely,the conditional attention mechanism;thus,the global situation information can participate in the calculation.The attention score of each fire unit about each target is obtained,each bit of the score vector is sigmoid sampled,and finally,the overall decision is generated.
5.3.The ablation experiment
To study the impact of the two mechanisms on the algorithm performance,this paper designs an ablation experiment.By adding or subtracting two mechanisms to the basic PPO algorithm,four different algorithms are set up to compare the differences in the effects.The experimental setup is shown in Table 2:
Based on the general and narrow agents’framework in Section 3 of this paper,all algorithms are iteratively trained 100,000 times under the same scenario.The experimental results are shown in Fig.5.The performance of the basic PPO algorithm can be improved by adding the stage reward mechanism and the multihead attention mechanism alone.The multihead attention mechanism can increase the average reward from 10 to approximately 38.The stage reward mechanism has a slightly larger and more stable effect,which can increase the average reward from 10 to approximately 42.When the two mechanisms are added simultaneously,the algorithm performance can be considerably improved,and the average reward value can be increased to approximately 65,which shows that the PPO-TAGNA algorithm proposed in this paper is effectively applicable to the task assignment problem under the framework of general and narrow agents.
6.Experiments and results
6.1.Experimental environment setting
The neural network training environment in this paper is carried out in the virtual digital battlefield.In the hypothetical combat area,for a certain number of blue offensive forces,when the red side has important places to protect and the forces are limited,the red side agent needs to make real-time decisions according to the battlefield situation and allocate tasks according to the threat degree of the enemy and other factors while trying to preserve their strength and protect important places from destruction.In this paper,the task assignment strategy of the red side is trained by a DRL method.Considering physical constraints,such as earth curvature and ground object shielding,the key elements of the digital battlefield are close to those of the real battlefield.The red-blue confrontation scenario is shown in Fig.6.
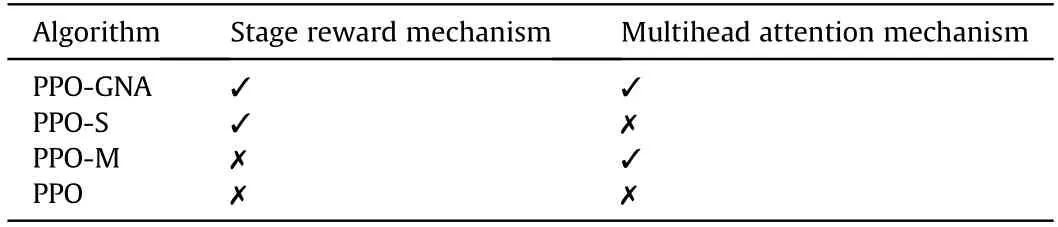
Table 2 Ablation experimental design.
6.1.1.The red army force setting
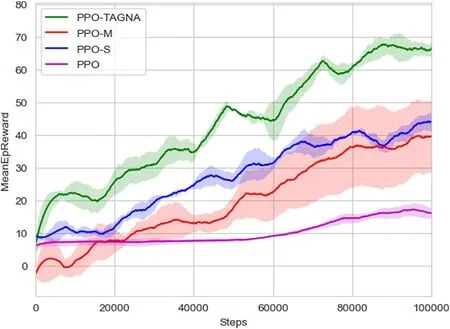
Fig.5.Performance comparison of ablation experimental algorithms.
There are 2 important places,the headquarters and the airport.
One early warning aircraft has a detection range of 400 km.
The long-range interception unit consists of 1 long-range radar and 8 long-range interceptors (each interceptor carries 3 longrange missiles and 4 short-range missiles).
The short-range interception unit consists of 1 short-range radar and 3 short-range interceptors (each interceptor is loaded with 4 short-range missiles).
Three long-range interception units and three short-range interception units are deployed to defend the red headquarters in a sector,while four long-range interception units and two shortrange interception units are deployed to defend the red airport in a sector,for a total of 12 interception units.
6.1.2.Blue army force setting
There are 18 cruise missiles.
There are 20 UAVs,each carrying 2 antiradiation missiles and 1 air-to-ground missile.
There are 12 fighter planes,each carrying 6 antiradiation missiles and 2 air-to-ground missiles.
There are 2 jammers for long-distance support jamming outside the defense area.
6.1.3.Confrontation criterion
If the radar is destroyed,the unit loses combat capability.The radar needs to be started up in the whole guidance process.When the machine is turned on,it radiates electromagnetic waves,which are captured by the opponent and expose its position.The radar is subject to physical limitations,such as earth curvature and ground object shielding,and the missile flight trajectory is the best energy trajectory.The interception distances are 160 km (long range)and 40 km (short range).For UAVs,fighters,bombers,antiradiation missiles and air-to-ground missiles,the high-kill probability in the kill zone is 75%,the low-kill probability is 55%,and for cruise missiles,the high-kill probability in the kill zone is 45%,and the low-kill probability is 35%.The antiradiation missile has a range of 110 km and a hit rate of 80%.The air-to-ground missile has a range of 60 km and a hit rate of 80%.The jamming sector of the blue jammer is 15°,and after the red radar is interfered with,the killing probability is reduced according to the jamming level.
6.2.Experimental hardware configuration
The CPU running the simulation environment is an Intel Xeon E5-2678v3,88 core,256 G memory;the GPU * 2 runs neural network training.The model is an NVIDIA GeForce 2080ti,72 cores and 11 G video memory.In PPO,the superparameter is ε=0.2,the learning rate is 10-4,the batch size is 5,120,and the number of hidden layer units in the neural network is 128 and 256.
6.3.Analysis of the experimental results
6.3.1.Agent architecture comparison
The agent architecture based on OGMN proposed in this paper and the framework of Alpha C2 [25] are iterated 100,000 times in the digital battlefield with the PPO,A3C and DDPG algorithms,and the reward value and win ratio are compared.The comparison results are shown in Fig.7.
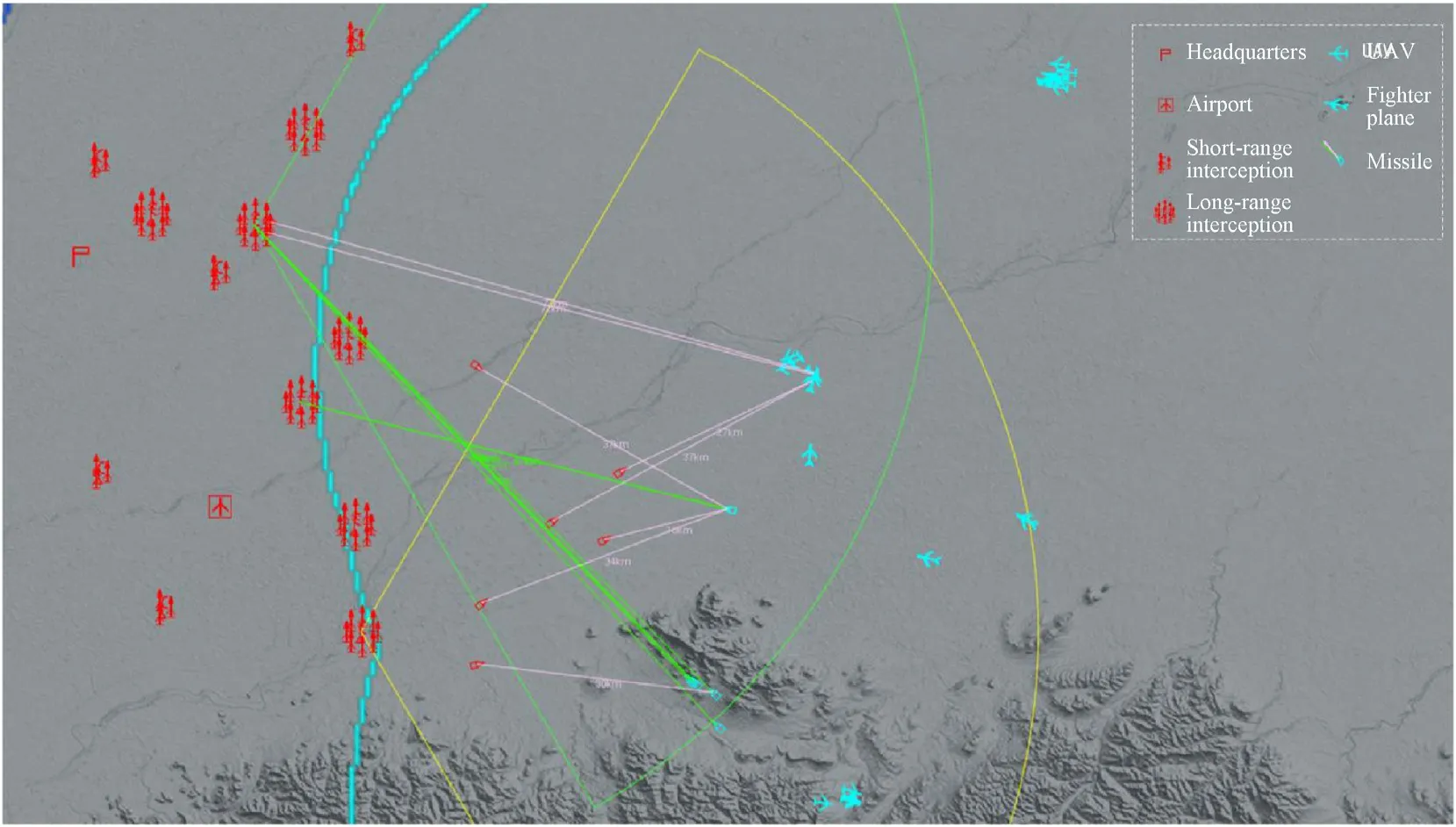
Fig.6.Schematic diagram of an experimental scenario.
It can be seen that the agent architecture based on OGMN proposed in this paper can obtain a higher reward value faster in the training process,and the effect of PPO is the best,which can substantially improve the average reward value and stability.In terms of the win ratio,the agent architecture in this paper also has the same performance,which can achieve a higher win ratio and be more stable.Experiments show that the OGMN architecture can not only largely retain the overall coordination ability of general agent to ensure the stability of training,but also has the efficient characteristics of multiagent,which can improve the training efficiency.
6.3.2.Algorithm performance comparison
Under the same scenario,the PPO-TAGNA algorithm proposed in this paper is compared with the Alpha C2 algorithm [25] and the rule base based on expert decision criteria [5,28-30].The three algorithms are iterated 100,000 times in the digital battlefield,and the comparison results are shown in Fig.8:
6.4.Agent behavior analysis
In the deduction of the digital battlefield,some strategies and tactics can emerge in this study.Fig.9 shows the performance of the red agents before training.At this time,only the unit closest to the target is allowed to defend without the awareness of sharing the defense pressure,and the value of the target is not distinguished.Finally,when the high-value target attacks,the resources of the unit that can intercept are exhausted and fail.
Fig.10 shows the performance of the red agents after training.At this time,the agent can distinguish the high threat units of the blue side,share the defense pressure,make more rational use of resources,defend the key areas more efficiently,and finally take the initiative to attack the high-value targets of the blue side to win.
7.Conclusions
Aiming at the low processing efficiency problem and the slow solution speed of large-scale task assignment issue,based on the idea of an optimal algorithm of assignment strategy and combined with the DRL training framework,this paper proposes the agent architecture based on OGMN and PPO-TAGNA algorithm for the ground-to-air confrontation task assignment.By comprehensively analyzing the large-scale task assignment requirements,a reasonable state space,action space and reward function are designed.Using the real-time confrontation of the digital battlefield,experiments,such as algorithm ablation,agent framework comparisons and algorithm performance comparisons,are carried out.The experimental results show that the OGMN task assignment method based on DRL has a higher win ratio than the traditional method.The use of resources is more reasonable and can achieve better results under limited training times.The multiagent architecture based on the OGMN and PPO-TAGNA algorithms proposed in this paper has applicability and superiority in ground-to-air confrontation task assignment and has important application value in the intelligent aided decision-making field.
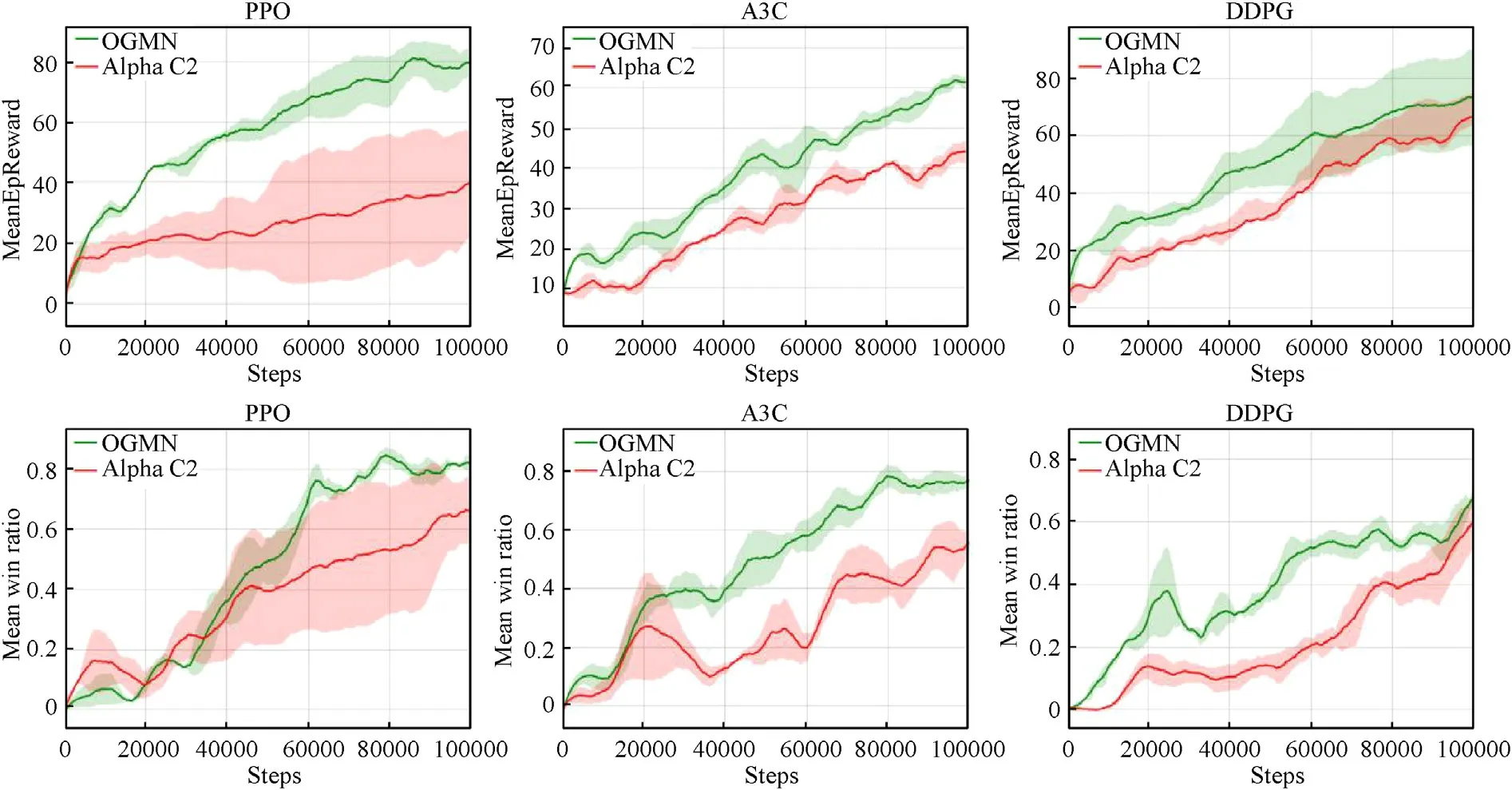
Fig.7.Comparison of agent architecture training effect.
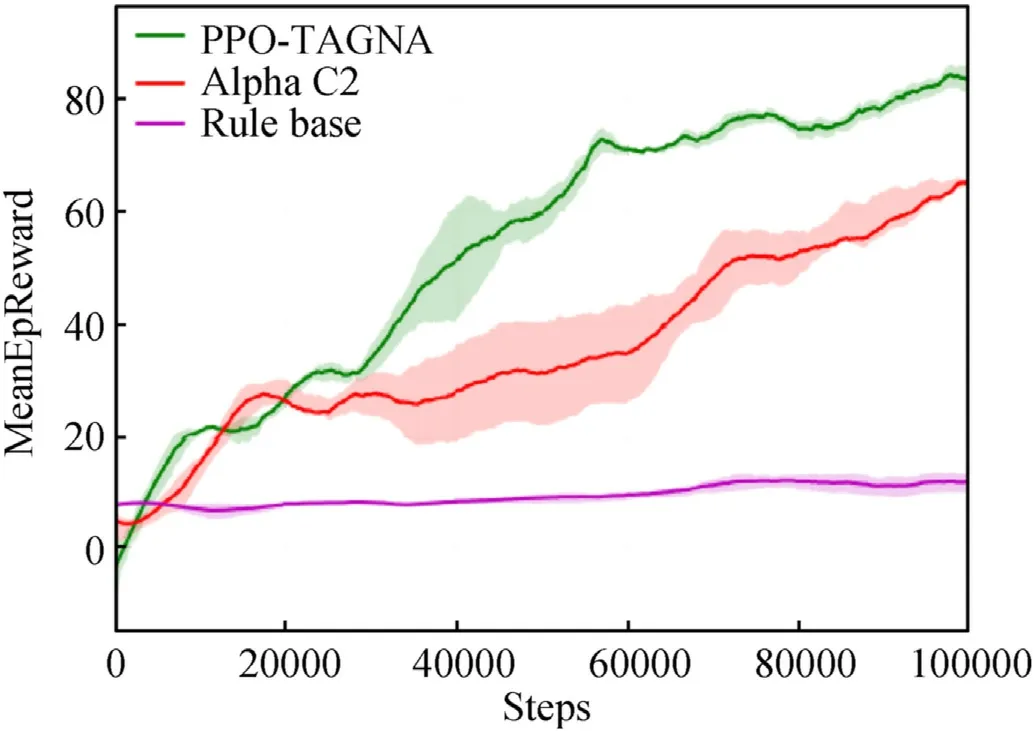
Fig.8.Algorithm performance comparison.
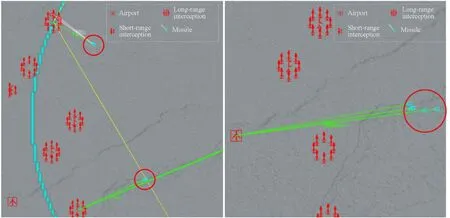
Fig.9.Performance of agents before training.
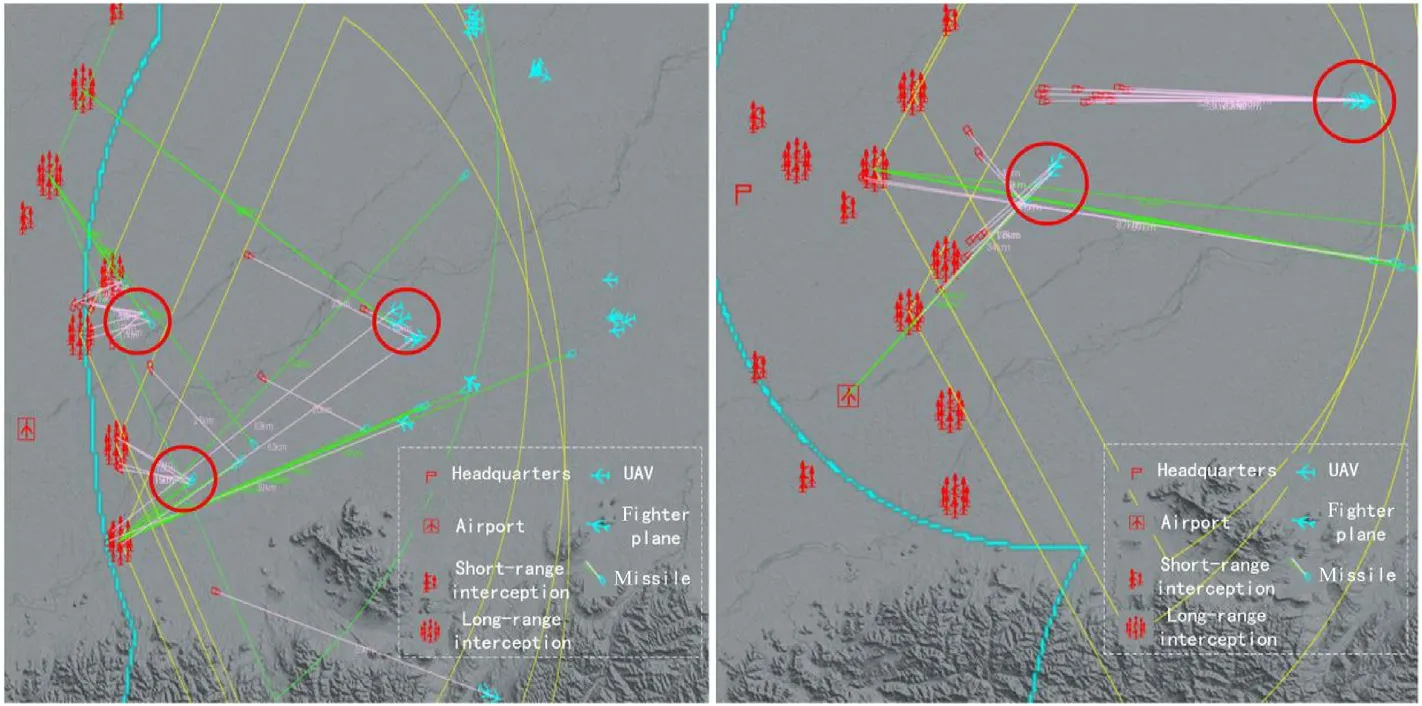
Fig.10.Performance of agents after training.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
The authors would like to acknowledge the Project of National Natural Science Foundation of China (Grant No.62106283),the Project of Natural Science Foundation of Shaanxi Province (Grant No.2020JQ-484) and the Project of National Natural Science Foundation of China (Grant No.72001214) to provide fund for conducting experiments.
杂志排行

Defence Technology的其它文章
- A review on the high energy oxidizer ammonium dinitramide:Its synthesis,thermal decomposition,hygroscopicity,and application in energetic materials
- Blast wave characteristics of multi-layer composite charge:Theoretical analysis,numerical simulation,and experimental validation
- Deep learning-based LPI radar signals analysis and identification using a Nyquist Folding Receiver architecture
- A small-spot deformation camouflage design algorithm based on background texture matching
- Quasi-static and low-velocity impact mechanical behaviors of entangled porous metallic wire material under different temperatures
- Sensitivity analysis of spacecraft in micrometeoroids and orbital debris environment based on panel method