基于物方体素约束的深度图融合方法
2023-01-15张帅哲刘振东蔡昊琳屈文虎
张帅哲 刘振东 刘 新 蔡昊琳 屈文虎 张 栋
(1. 山东科技大学 测绘与空间信息学院, 山东 青岛 266590; 2. 中国测绘科学研究院, 北京 100089; 3. 泰安金土地测绘整理有限公司, 山东 泰安 271018)
0 引言
基于多视立体视觉的三维重建技术是摄影测量与计算机视觉领域中的研究热点,涉及多学科知识,被广泛应用于自动驾驶、城市建设、医学成像、文化遗址保护等领域[1]。在三维重建流程中,稠密重建是二维影像转换为三维模型的关键一环,一般包括密集匹配和深度融合两个主要步骤[2]。深度融合是指将不同视角的深度图融合到统一的坐标框架下并进行表面计算,以产生整个场景的密集点云。
根据文献[3]所述,深度融合方法主要分为基于体素的融合方法[4-5]、基于特征点扩散的融合方法[6-8]和基于深度图的融合方法[9-14]。其中,基于深度图的融合方法具有较高的鲁棒性、灵活性[13]。因此,该类方法成为最常用的深度融合方法。目前,学者们在基于深度图的融合方法方面开展了大量的研究。Shen[9]首先计算出每个像素对应的三维点,通过重投影将三维点重投影到邻居影像上,比较三维点所对应像素的深度值和三维点与影像的距离,并结合深度一致性筛选点云。刘怡光等人[13]提出一种基于置信度的方法来删除密集点云中的冗余,该方法赋予每个三维点一个置信度,并在互为冗余的三维点中保留置信度最高的三维点。Liu等人[14]通过定义有限数量的虚拟视角,尽可能地减少密集点云的冗余并覆盖全部场景,在虚拟视角上融合深度图。
以上几种方法至少在以下两方面有待改进:一是,密集点云存在密度较大的问题;二是,密集点云存在较多噪声和异常点。鉴于此,本文提出一种基于物方体素约束的深度图融合方法,用于降低点云密度同时尽可能保证点云质量。
1 本文方法
1.1 体素网格尺寸自适应计算
多视影像进行深度图融合时,针对现有大多数方法生成的密集点云的密度不可控问题,本文将在物方建立体素网格进行空间唯一性约束。体素尺寸是需要根据影像的地面分辨率来自适应确定的。一般来说,影像地面分辨率越高,经深度图融合方法生成的点云越密集且质量越高。本文依据影像地面分辨率构建体素网格尺寸函数。
构建体素网格尺寸函数时,首先应计算影像地面分辨率。考虑到小孔成像原理导致图像中不同区域的像素对应的地面分辨率存在一定差异,因此本文将计算影像的平均地面分辨率作为体素网格尺寸函数中的影像地面分辨率。另外,为加快计算速度,本文将整幅影像划分为多个子区域;然后在每个子区域中,随机采样1~3个像素坐标,并将其作为计算影像平均地面分辨率的采样点。构建体素网格尺寸函数的第二步是求解场景的地面分辨率并计算体素网格尺寸。①求解影像的地面分辨率。影像中所有采样点的地面分辨率的平均值近似作为影像的地面分辨率;而采样点的地面分辨率则以采样点及其1阶邻居在物方的距离求和取平均。②计算体素网格尺寸。由于影像地面分辨率是影像中可识别地面物体的最小像素单元,体素网格尺寸不应小于影像地面分辨率,因此以场景中所有影像的地面分辨率的平均值乘以一个系数作为体素网格尺寸,如式(1)所示。
(1)
其中,ds表示体素网格尺寸;α表示计算系数;li表示影像的地面分辨率;n表示影像数量。注意,α值的大小将会直接改变体素网格尺寸进而影响深度图融合生成的密集点云的密度和质量。在保证点云质量的前提下,建议α合理的范围为1.0~2.0。
1.2 基于几何特征约束的融合点确定
本文方法第二步是融合点的确定,与文献[9]和文献[15]方法类似,在深度一致性条件的基础上,本文方法引入物方点空间距离、物方点法线夹角、重投影误差等几何特征约束条件。具体过程如下。
步骤1:依次将多视影像集合中的每张影像作为参考影像Iref,并确定其邻居影像集Isrc。然后,遍历计算参考影像中像素q对应的三维点P,如图1所示。
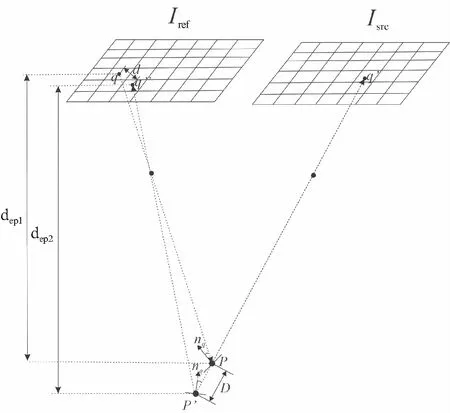
图1 融合点计算示意图
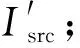
步骤3:多几何特征约束判断。本文利用物方点空间距离、物方点法线夹角、重投影误差等几何特征作为判断条件,如式(2)所示,确定参考影像的像素q能否生成融合点P。
(2)
其中,d为像素q与像素q″在图像坐标系中的距离;dep1为像素q在参考影像Iref所对应深度图中的深度值;dep2为三维点P′相对于参考影像Iref的深度值;A(nq,nq′)为像素q与像素q′所对应法线之间的夹角;D为三维点P与三维点P′之间的距离;θrad为像素q所对应的地面分辨率。
1.3 基于物方体素约束的融合点筛选
通过1.2节生成的融合点集合仍存在密度大的问题,本文还需对融合点集进行筛选。融合点集合的密度大主要是由于邻近影像间的重叠度较大,导致同一地物极有可能会被多张影像观察到,因此在同一地物处可能会生成多个融合点。如图2所示,I0、I1、I2、I3、I4分别表示五张邻近的影像;虚线框G0、G1、G2分别代表不同的影像组,影像组中的参考影像分别为I1、I2、I3,其余影像作为邻居影像;点P表示真实世界中的三维点,位于体素V中;P0、P1、P2分别代表由相应影像组确定的融合点。理想情况下,P0、P1、P2三个点的坐标值应与P点相同,但由于误差的存在,导致P0、P1、P2三个点无法与真实世界的三维点完全重合。从图2可以看出,体素V中产生了多个融合点。
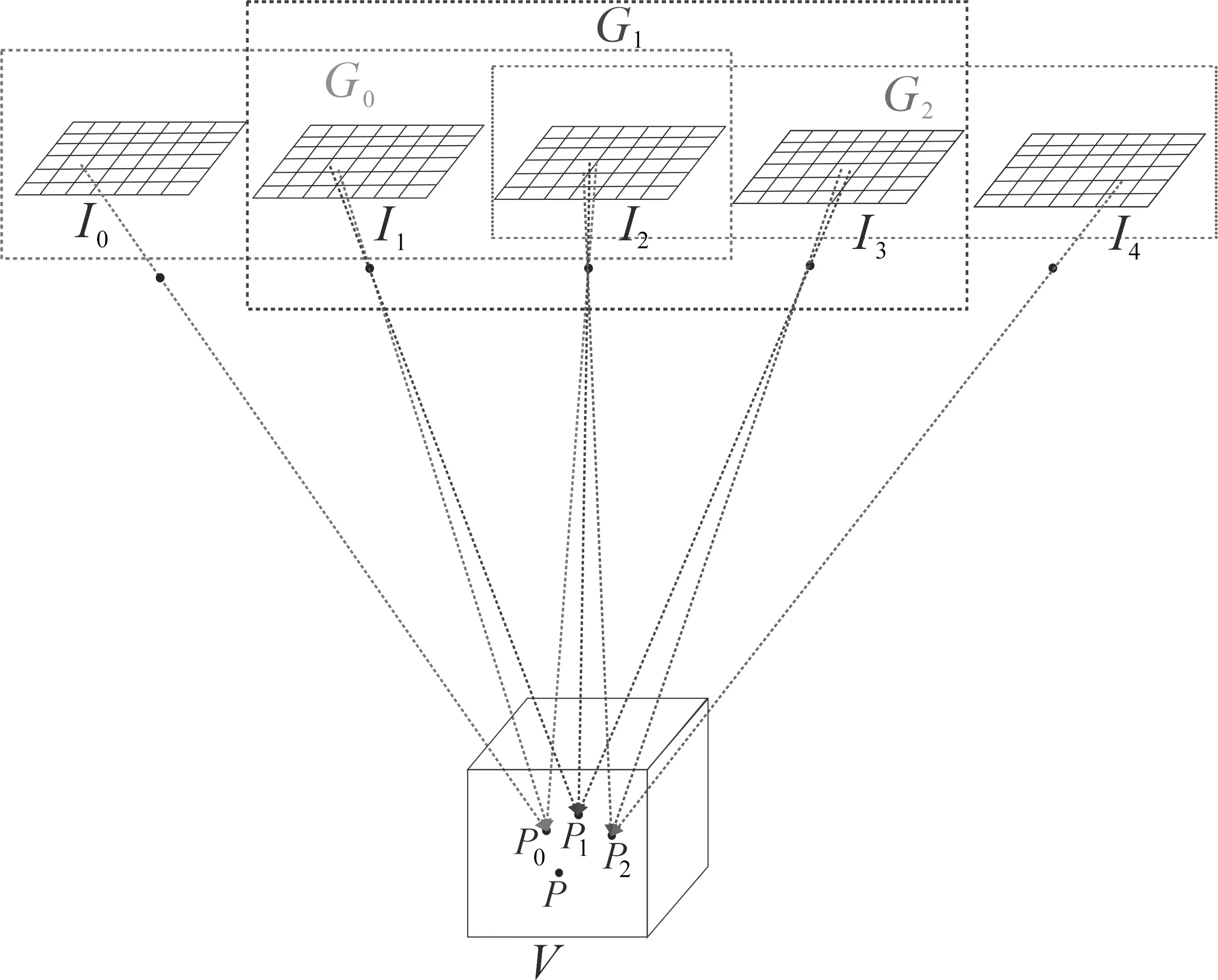
图2 深度图融合示意图
为解决上述问题,本文引入入射角角度、物方点的归一化互相关系数(normalized cross correlation,NCC)、重投影误差等多个约束条件联合构建融合点权重函数,仅保留体素中权重值最高的融合点并作为体素的代表点,权重函数如式(3)所示。
(3)
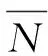
由于八叉树是一种常用且高效的三维空间搜索的树结构,因此,本文利用动态八叉树查询融合点位于的体素节点并利用融合点的权重值进行筛选。具体步骤如下。
步骤1:创建包含根节点的八叉树。遍历融合点,定位其在八叉树中的体素节点v。
步骤2:判断体素节点v内是否存在融合点Pv。若不存在,则将融合点P的空间坐标、权重值以及颜色信息存储在体素节点v中;若存在则进入步骤3。
步骤3:若体素v的尺寸大于1.1节中自适应计算的体素网格尺寸,则将体素v进行划分,停止条件分为两种情况:①融合点P与融合点Pv位于划分后的不同体素节点中;②划分后的体素节点尺寸等于1.1节中计算的体素网格尺寸,同时比较融合点P与融合点Pv的权重值,保留权重值较高的融合点。若体素v的尺寸等于1.1节中自适应计算的体素网格尺寸,则在融合点P与融合点Pv中保留权重值较高的融合点。
步骤4:判断所有的融合点是否全部完成筛选。若完成,则收集所有体素节点中存储的融合点及其相关信息,生成密集点云;否则继续执行上述步骤。
2 实验验证
2.1 实验数据及环境
本文依托中国测绘科学研究院研制的倾斜摄影自动化三维建模软件IMS,嵌入本文的深度图融合方法,采用两类倾斜影像数据集进行实验。第一类数据集为滕州市某镇驻地倾斜影像数据。数据集共有影像34 364张,每张影像的地面分辨率为0.03 m,整个测区重建范围为8.62 km2,具体如图3所示。第二类数据集为ETH3D公开数据集,它不仅提供数码单反相机(digital single lens reflex camera,DSLR)拍摄的高分辨率图像,而且还提供高精度激光扫描仪记录的真实点云数据。实验硬件环境为:处理器Inter(R) Core(TM) i9-10900X 3.70 GHz,显卡NVIDIA GeForce RTX 3080,运行内存128 GB。

图3 实验区域展示
本文将从密集点云的密度以及质量两方面进行效果验证。由于本文方法是在Shen的深度融合方法[9]基础上进行改进,Shen的方法已经嵌入在OpenMVS中,因此本文方法的结果将与OpenMVS的结果进行对比分析。
2.2 密集点云密度定量分析
本文方法和OpenMVS方法都将PatchMatch方法生成的深度图作为输入,并在同一环境下进行实验。从实验数据中选取代表性区域(包含植被、道路、建筑等地物)进行实验。
若实验区域的所有深度图进行一次性整体融合生成密集点云,则计算机内存无法满足计算需求,因此本文将实验区域划分为多块子区域(子区域大小为155 m×155 m)然后分块融合。此处,随机取其中6块子区域进行分区域融合,具体如图3所示,然后统计密集点云密度。结果如表1所示。
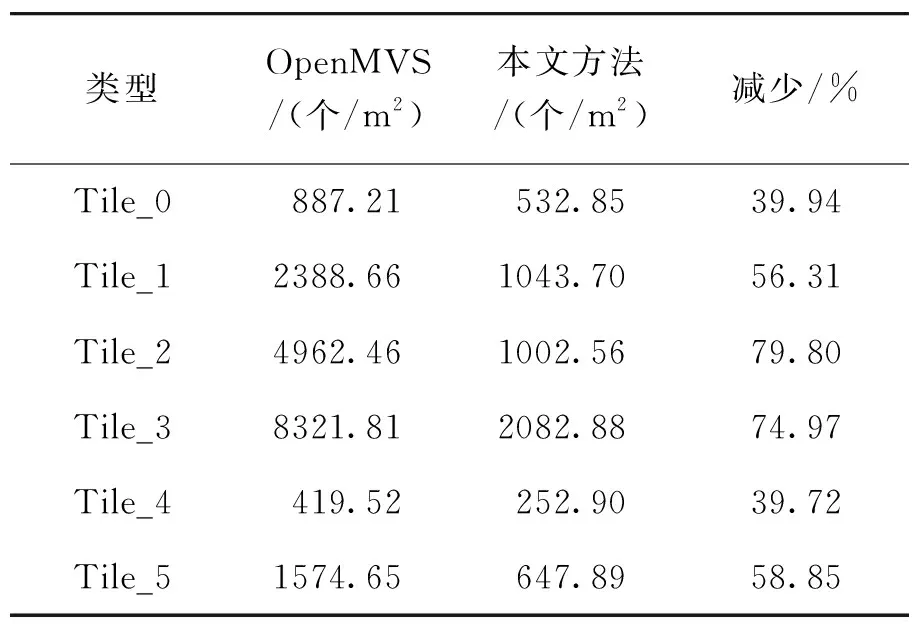
表1 密集点云密度统计对比
从表1可以看出,本文方法生成的密集点云的密度在各个子区域均比OpenMVS方法要少。证明了本文方法能够有效降低密集点云的密度。主要是因为OpenMVS方法在融合过程中并未对场景中同一位置处的融合点进行识别筛选;而本文方法采用物方体素约束,对场景中同一位置处的融合点进行识别筛选,从而大幅降低密集点云的密度。此外,在边缘区域的密集点云数量减少较少,主要是因为该子区域位于整个场景的边缘部分,影像数量及冗余度较少;而在中间区域,影像数量及冗余度较多,密集点云数量减少明显。
2.3 密集点云质量定量分析
为验证本文方法生成的密集点云质量,本文将从密集点云的精度、完整度两个方面进行定量分析。点云精度被定义为重建点云集合中所有点到真实点云集合中最小距离的平均值。点云完整度被定义为真实点云集合中所有点到重建点云集合中的最小距离小于1.5倍点云精度的点云数在真实点云集合中的比重。本节采用ETH3D公开数据集进行点云质量的对比分析。质量对比结果如表2所示,courtyard数据集的密集点云展示如图4所示。
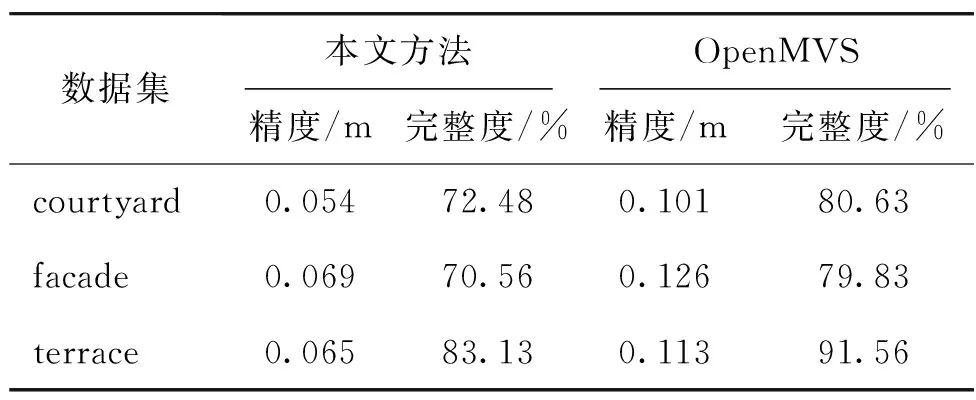
表2 密集点云质量统计对比

(a)真实激光点云数据

(b)OpenMVS生成的密集点云

(c)本文方法生成的密集点云图4 courtyard数据集的密集点云展示
结合表2和图4可以看出,①精度方面:本文方法生成的密集点云精度均比OpenMVS方法要高。主要是由于在深度图融合过程中,OpenMVS方法只考虑深度差异作为约束条件,导致生成的密集点云中存在较多的噪声和异常点;而本文方法通过引入多重几何特征约束计算融合点,且在融合点的筛选过程中,利用权重值选出高质量的融合点,因此密集点云中的噪声和异常点较少。从图4(b)、图4(c)的整体以及局部细节中可以看出本文方法相对于OpenMVS方法噪声和异常点减少较多。②完整度方面:本文方法生成的密集点云完整度均低于OpenMVS方法。这是由于本文方法所使用的约束条件较为严格,且通过物方体素约束进一步降低密集点云的密度,导致完整度稍微偏低。但从图4可以看出,本文方法生成的密集点云仍能较好地保证地物结构的完整度,且与OpenMVS方法所得结果并无太大差异。
3 结束语
现有基于深度图融合的方法生成的密集点云还存在点云密度大且质量参差不齐的问题。为此,本文提出一种基于物方体素约束的深度图融合方法,通过物方体素约束降低点云密度,同时通过多个约束条件联合构建融合点权重函数,剔除噪声和异常点,提高点云质量。通过实验验证及对比分析,得出结论如下:
(1)通过构建物方体素网格,同时利用动态八叉树方法,能够有效地降低点云密度。与现有基于深度图融合的方法相比,本文方法在点云密度方面整体平均减少58.27%。
(2)通过多个约束条件联合构建融合点权重函数,能够有效地剔除密集点云中的噪声和异常点。与现有基于深度图融合的方法相比,本文方法在点云精度方面提升44.75%。但在密集点云的完整度方面,与现有基于深度图融合方法相比降低8.60%。
在多视影像建模流程中,建模的质量和效率是两个主要关键指标。目前,本文方法能够在有效降低密集点云密度的同时保证点云的质量,但效率还有待提升。在未来研究中,重点将集中解决深度融合中的冗余计算问题,用于提高融合效率。
