结合迁移学习的真实图像去噪算法
2023-01-14周联敏周冬明杨浩
周联敏, 周冬明, 杨浩
(云南大学信息学院, 昆明 650000)
图像在采集和传输过程中会受各种因素干扰,不可避免地引入多种噪声[1]。图像去噪是基本的计算机视觉任务之一,为了得到较干净图像需要对有噪图像进行处理[2]。在图像去噪任务中,去噪方法主要分为传统去噪方法和基于深度学习的去噪方法。传统去噪方法在发展前期占据了重要地位,众多优秀的算法提出并沿用至今。其中具有代表性的传统方法如Buades等[3]基于图像的非局部自相似性提出了非局部均值去噪方法(nonlocal means denoising method, NLM)。NLM去噪方法对图像中所有像素点的相似度都要进行度量,进行遍历计算复杂。之后,Dabov等[4]结合非局部自相似性先验将搜索到的二维相似图像块转成三维块组,再进行去噪处理,称为三维块匹配去噪方法(block-matching and 3D filtering, BM3D)。BM3D算法的处理速度和取得的去噪效果都有了一定提升。虽然传统去噪方法取得了一定的去噪效果,但是需要使用复杂的优化算法进行改进并人为来调节参数,所消耗的计算资源和时间成本是巨大的,处理复杂噪声的效果不佳。
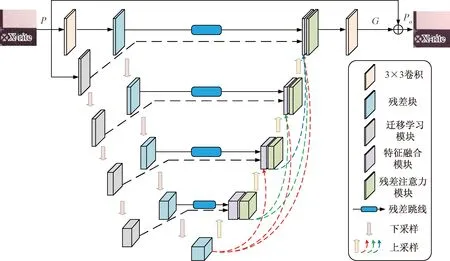
图1 网络整体结构Fig.1 Overall network structure
随着深度学习的研究发展,在图像去噪领域应用深度学习的方法越来越多。深度学习技术是为了让机器能够以类似人类的方式学习,通过大量的数据分析探索深层的规律和知识。基于深度学习技术让机器建立起神经结构模型,使其能够模拟人类感知学习的能力。Jain等[5]最早结合深度学习研究图像去噪,首次将卷积神经网络在监督学习下用于去噪,并取得了很好的去噪表现。Xie等[6]采用深度学习和稀疏编码相结合研究,对全连接层中被激活的神经元个数进行稀疏地约束,提出了栈式稀疏去噪自编码器(stacked sparse denoising auto-encoders, SSDA)。Burger等[7]采用滑动窗口的方式在每个窗口内对图像去噪,提出了多层感知机(multi layer perceptron, MLP)。MLP具有很好的拟合性能,在理想条件下可以拟合多种复杂函数,但面对复杂噪声时就无法适应。Chen等[8]利用图像的先验信息获取图像结构特征,提出了非线性反应扩散去噪模型(trainable nonlinear reaction diffusion, TNRD)。深层网络带来的性能提升是可观的,其在图像去噪领域的应用也愈加广泛。Zhang等[9]结合批标准化和残差学习使得网络在高斯去噪任务上性能得到提升,提出了去噪卷积神经网络(denoising convolutional neural network, DnCNN)。DnCNN学习噪声图像与干净图像的残差来训练网络去除噪声,解决了随着增加网络深度而导致的梯度弥散问题。Ahn等[10]为了实现更好的图像去噪器,将卷积神经网络特征提取能力和局部特征相结合提出了BMCNN(block-matching convolutional neural network)。该方法可将预先处理过的噪声图像相似块组进行块匹配,能对不规则图像进行去噪。Liu等[11]结合小波去噪算法和U-Net(U-shaped network),用小波去噪中的小波变换和逆变换替换了U-Net中的下采样和上采样操作,提出了MWCNN(multi-wave convolutional neural network)。在RIDNet(real image denoising network)去噪网络中,作者第一个将注意力机制应用于图像去噪,使神经网络能关注图像更为重要的特征[12]。Yue等[13]提出变分去噪网络(variational denoising network, VDN),在去除图像噪声的同时估计噪声分布。Kim等[14]应用自适应实例规范化来搭建去噪网络AINDNet(adaptive instance normalization denoising network),能实现约束特征图和防止网络过拟合。Ren等[15]基于自适应一致性先验提出了可解释的深度去噪网络DeamNet(dual element-wise attention mechanism network)。Liu等[16]利用从先验分布中取样的隐性表征取代了噪声隐性表征,提出一个可逆去噪网络InvDN(invertible denoising network)。虽然这些算法对噪声去除性能得到了提升,但同时也损失了图像的细节纹理和边缘信息。真实噪声图像往往是多种噪声叠加,分布十分复杂,要将其去除仍是具有挑战性的任务。
在前人工作的基础上,现结合迁移学习提出一种真实图像去噪算法,在有效融合特征信息后对图像细节信息加强关注,进而更好地恢复图像。
1 方法与理论
1.1 网络整体结构
本文研究结合迁移学习技术提出了针对真实图像的去噪网络,整体结构如图1所示。本文的整体架构是编码解码单元组成的U型网络结构[17]。其中编码单元由迁移学习模块和残差块分别构成两个编码器,解码单元由特征融合模块和残差注意力模块组成。将一张真实噪声图像P∈H×W×3(其中H、W分别表示高度和宽度,为数域)分别送入残差块编码器和迁移学习模块编码器。在编码的过程中,迁移学习模块经过跳线连接到特征融合模块,残差块经过残差跳线连接到特征融合模块,对解码器所需信息起到了补充作用。在解码的过程中,通过密集跳线对信息进一步补充。经过编码解码处理后通过一个3×3卷积得到残差图G∈H×W×3,随后得到恢复后的图像Po=P+G。
1.2 双编码器
在训练网络的过程中,所需的真实噪声与干净图像对采集是十分困难的,现存的真实噪声数据集也十分有限。迁移学习就是解决数据有限的一种有效方法。其目的是以之前任务中学习到的知识为基础,让模型能够运行新的任务[18]。为了提高编码单元的性能,本文使用Res2Net(residual-like network)[19]作为迁移学习编码器。Res2Net最初是为图像分类任务而训练的,具有出色的性能。本文使用的时候删除了尾部的全连接层,只采用前端下采样和预训练参数,Res2Net模块结构如图2所示。
从图2可以看到,Res2Net模块将单一卷积层改变为分层小组的卷积,在各个小组之间通过类似残差的连接结构逐层连接起来。输入经过1×1卷积层后分成了多个子集xi,i∈{1,2,…,q},这些子集通道数分割为原来的1/i,而子集特征图大小保持不变。特征图子集经过3×3卷积层后能获得更大的感受野并且通过跳线加到下一子集3×3卷积层之前,如此累积Res2Net模块输出了多种尺度感受野的多种组合,最后拼接在一起通过一个1×1卷积层对这些信息进行有效融合。采用这种拆分再合并的处理方式使得网络能够提取多尺度特征信息,有利于卷积层对特征图进行处理。用Qi(·)表示除x1外每个子集所对应的3×3卷积层,并且对应的输出是yi。Qi-1(·)和子集xi相加之后传递给Qi(·)进行计算,输出yi[19]可表示为
(1)
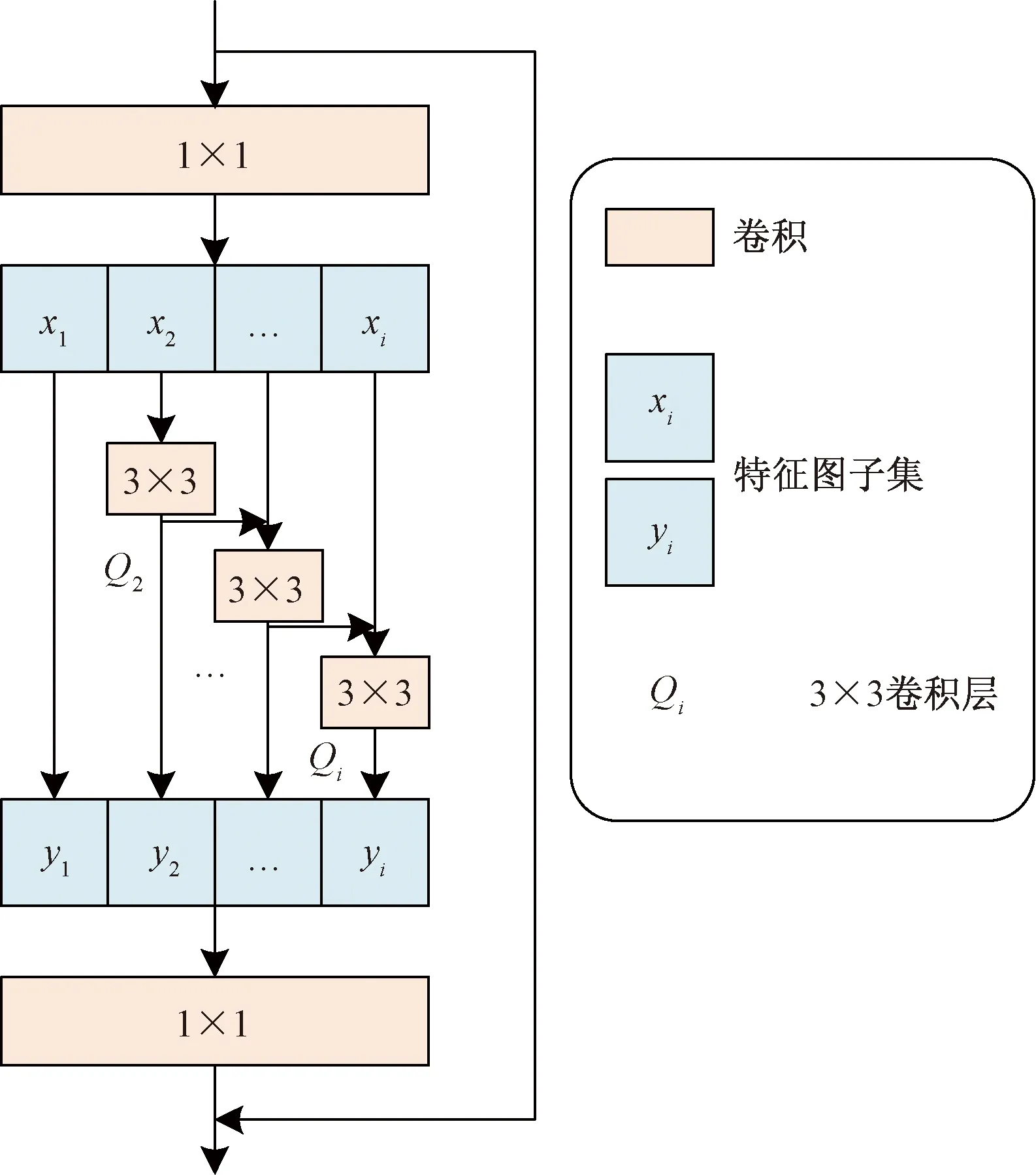
图2 迁移学习模块Fig.2 Transfer learning module
训练模型的过程中,通过使用迁移学习编码器加载在ImageNet上预先训练好的权值。这些预先训练好的权值能让模型能够很好地提取鲁棒特征,并且通过中间跳线将这些特征送入对应的特征融合模块。在利用迁移学习模块的先验知识提取鲁棒特征的同时,再通过残差块[20]组成的编码器对当前数据进行处理,提取出特征进行信息补充,残差块结构如图3所示。
在利用残差块进行特征信息的深度提取编码的过程中,图像的细节信息十分重要,而批标准化技术的使用容易造成细节信息的丢失[21]。在图3中,使用残差块时将批标准化层去除了,并采用了Leaky ReLU激活函数,通过3×3卷积得到重建后的残差输出。经过残差块处理后的特征处于网络中较浅层,属于初级特征,与解码器更高级别的特征会存在语义差异[22]。因此,通过中间跳跃连接线将编码特征送到解码器之前需要进行处理。在处理方法的选择上并不是采用通常的卷积层,而是使用了残差连接。该结构在深度卷积网络中十分有效,并且能让学习过程变得更容易[23]。本文研究在中间跳跃连接线上加入一个残差结构的3×3卷积层,残差跳线结构如图4所示。通过使用残差跳线来缓解编码器与解码器特征之间的语义差异,有利于模型的训练过程。
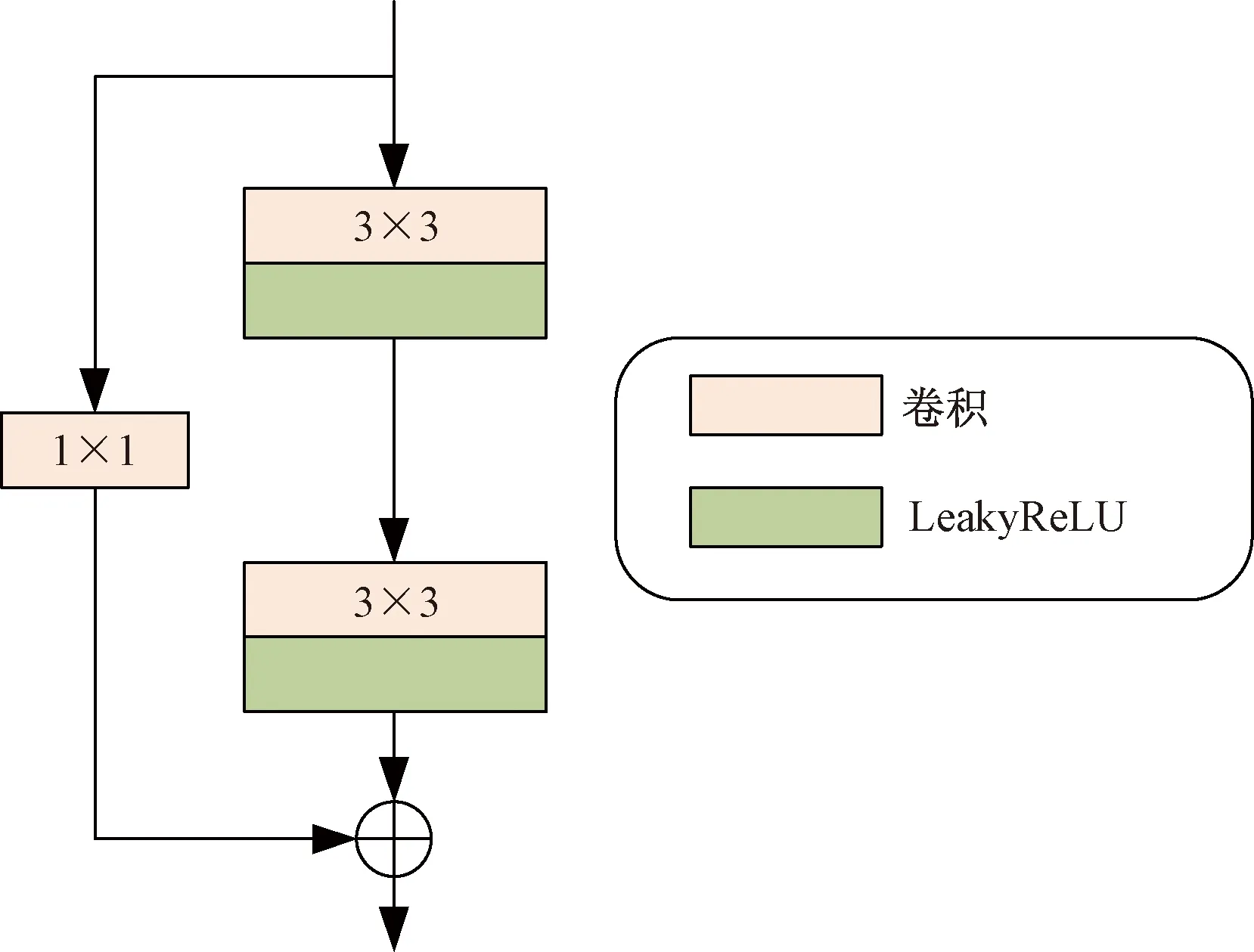
图3 残差块结构Fig.3 Residual block structure
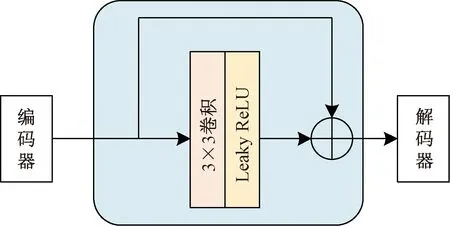
图4 残差跳线结构Fig.4 Residual skip connections structure
1.3 解码器
解码过程是利用编码提取的特征逐渐恢复原图像尺寸和恢复细节的过程,最后获得去噪后的图像。在解码的过程中需要丰富的信息来恢复图像,本文不仅通过中间跳跃连接线提供信息,而且充分利用了解码器之间的信息来进行补充。从图1可以看到,处于低层的解码块特征通过双线性上采样送到每一个上层的解码块中。解码首先要对接收到的多个特征进行融合,不是简单地将这些特征拼接起来。受Zamir等[24]研究的启发,本文引入选择性核特征融合模块(selective kernel feature fusion, SKFF)来对解码收到的特征进行聚合,以3个卷积流为例,结构如图5所示。
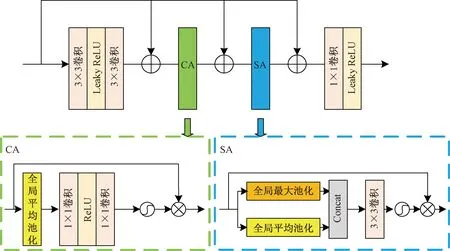
图6 残差注意力模块Fig.6 Residual attention module
从图5中可以看到SKFF首先对并行卷积流按元素求和的方式将特征进行组合E=E1+E2+E3,然后应用全局平均池化来压缩融合特征的空间维度。接下来通过一个1×1卷积层压缩通道,随后是3个并行的卷积层以产生3个特征描述符。在选择操作时,采用Softmax函数来获得3个关注特征f1、f2和f3。最后,分别利用f1、f2、f3来重新校准输入特征图E1、E2、E3,特征校准和聚合的过程可定义为
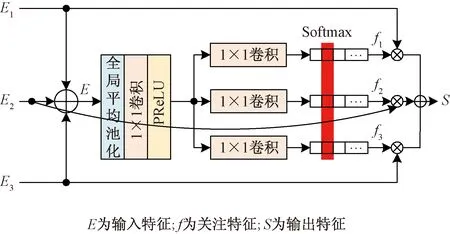
图5 特征融合模块Fig.5 Feature fusion module
S=f1E1+f2E2+f3E3
(2)
在经过特征融合模块后,极大地丰富了解码所需的信息。传统卷积神经网络对特征的重要占比无法判别,会限制较深网络的表达能力。在恢复图像的过程中,为了实现更好的去噪效果,网络对那些更有价值的特征需要更多地关注。因此,将空间注意力[25](spatial attention, SA)和通道注意力[26](channel attention, CA)进行结合来实现残差注意力模块,对特征进行自适应调整。残差注意力模块的结构如图6所示。
残差注意力模块主要是由卷积层、通道注意力层和空间注意力层构成,并在每一层之间使用了残差跳线。这样的局部残差学习结构能让网络绕过低频区域等较不重要的信息,而更关注有效信息,并且避免了梯度消失的问题。该模块首先通过两层3×3卷积层进行初次处理,随后通过CA层,然后馈送到SA层,最终经过一个1×1卷积层压缩通道后送出。
通道注意力层使得神经网络能够将有用的通道信息筛选出来,赋予更大的权重。通道注意力首先使用全局平均池化实现压缩操作,便于对空间全局上下文进行编码,随后经过两层1×1卷积和Sigmoid函数。通过Sigmoid函数后,实现了线性变换以分别为每个通道输出权重,最后使用基于元素的乘积来进行特征映射。空间注意力层能利用卷积特征的空间相关性实现重要特征的关注。空间注意力首先在通道维度分别对输入特征进行全局最大池化和全局平均池化,并将输出连接起来,然后通过一个3×3卷积和Sigmoid函数得到空间注意力图,最后利用元素乘积对输入特征进行权重调整。残差注意力模块的使用对特征权重进行调整,从而赋予重要特征更多的权重,让网络更加关注图像纹理等有效信息,以更好地恢复图像细节。
1.4 损失函数
为了提升图像恢复的效果,网络一般以恢复结果与真实图像进行像素级对比,不断优化缩小差别。本文研究采用了L1损失的一个变种Charbonnier Loss[27]损失函数。该损失函数中多了个正则项,能提高模型的最终表现并加快收敛速度,即
(3)
式(3)中:Z为去噪图像;Z*为参考图像;β为常数,β设置为10-3。
2 实验与结果分析
2.1 度量标准
对于去噪处理后的图像,选用了结构相似性(structural similarity, SSIM)和峰值信噪比(peak signal to noise ratio, PSNR)[28]来进行客观评价,计算公式[28]为
(4)
(5)
式中:Ki,j为去噪图像;Ii,j为无噪原图像;u1、u2分别为Ii,j、Ki,j的均值;σ1、σ2分别为Ii,j、Ki,j的方差;σ1,2为Ii,j、Ki,j的协方差;为了维持稳定性设置常数为c1=0.01、c2=0.02。PSNR越大,SSIM越接近1,则说明去噪图像和无噪图像越接近。
2.2 实验平台与数据集
在DND[29]、SIDD[30]和RNI15[31]3个真实噪声数据集上对模型性能进行了评估。DND(darmstadt noise dataset)[29]数据集是由4个不同尺寸传感器的消费级相机拍摄采集的。该数据集共包含50个真实噪声图像与无噪图像组成的图像对。这些图像被裁切成1 000个大小为512×512的小图像块便于使用。由于DND数据集是不公开无噪图像的,所以该数据集只能用于测试,要获取结构相似性(SSIM)和峰值信噪比(PSNR)需要将去噪结果提交到官方在线系统来评估性能。SIDD(smartphone image denoising dataset)[30]数据集是由5个小光圈的智能手机拍摄形成的。智能手机的传感器相较于相机会比较小,在拍摄照片的过程当中容易产生许多噪声。该数据集包含320个噪声与无噪图像对用于训练,其余40个图像对裁切为1 280个大小为256×256的小图像块用于测试。RNI15[31]数据集是由15幅真实噪声图像组成,没有相对应的无噪图像。因此,本文研究提供了该数据集的视觉效果比较。
使用SIDD数据集的320个图像对用于训练。使用前,先将每一幅原图裁切为300个大小为256×256的小图像块,利用这96 000个小图像块进行训练。本次实验是在DND数据集、SIDD数据集和RNI15数据集的sRGB图像上测试模型性能,PSNR统一在RGB通道上进行计算。使用的是Pytorch框架来搭建模型,硬件设施是NVIDIA RTX 3080Ti显卡和Intel i5-10600KF处理器。训练过程中,应用Charbonnier Loss损失函数和Adam优化器(β1=0.9,β2=0.999)对模型参数进行优化。模型的初始学习率设为4×10-4,最低学习率设为10-5,训练期间利用余弦退火衰减策略[32]使学习率平稳的下降,batch size设为16的情况下,共训练了50个epochs。
2.3 去噪性能对比试验
为了验证本文提出方法的性能,对多个方法在DND、SIDD和RNI15三个数据集上客观与主观的去噪性能进行对比。表1罗列了不同方法在SIDD和DND数据集上PSNR和SSIM指标方面的去噪性能对比。共有8个盲去噪方法(DnCNN[9]、CBDNet[33]、RIDNet[12]、AINDNet[14]、DeamNet[15]、DANet[34]、InvDN[16]、VDN[13]),3个非盲去噪方法(BM3D[4]、TWSC[35]、FFDNet[36])。由表1可以看到本文方法在PSNR和SSIM指标上都高于其他深度学习和传统去噪的方法。其中,与本文同样使用了迁移学习技术的AINDNet在SIDD数据集上PSNR落后0.32 dB,SSIM落后0.007;在DND数据集上PSNR落后0.22 dB,SSIM落后0.005,可见本文的模型性能更优。在这些方法中,AINDNet、RIDNet、CBDNet在训练时使用了额外的数据,本文模型训练只使用了SIDD数据集,但取得了更好的表现。举例来说,本文模型在SIDD数据集上比CBDNet高出了8.55 dB,在DND数据集上高出了1.61 dB。本文方法相较于最近的方法AINDNet、DeamNet、DANet、InvDN、VDN,性能都有了一定的提高,相较于非盲去噪方法BM3D、TWSC、FFDNet,性能显著提升。
在图7、图8和图9中,分别列出了不同方法在DND、SIDD和RNI15数据集上的视觉效果对比。结合图7和图8可以看到,BM3D、FFDNet、TWSC、DnCNN、CBDNet方法都没有很好地去除噪声,残留了许多噪点。在图7中,RIDNet、DANet、AINDNet、VDN、InvDN虽然能有效去除噪声,但同时产生了图像细节和边缘信息丢失,相较之下本文方法表现更好。DND数据集不公开无噪图像,但通过官方在线系统能获取到PSNR。在图8中,本文方法相较于其他方法,木块的纹理和木块上的数字更接近干净图像,而其他方法出现了伪影和图像精细纹理的丢失。在图9中,RNI15数据集只存在噪声图像。从图9中可以看到,狗狗的眼睛、灯饰的底座和窗户的边框上,本文方法实现了噪声的有效去除,并产生了更加清晰的图像,呈现的视觉效果最佳。
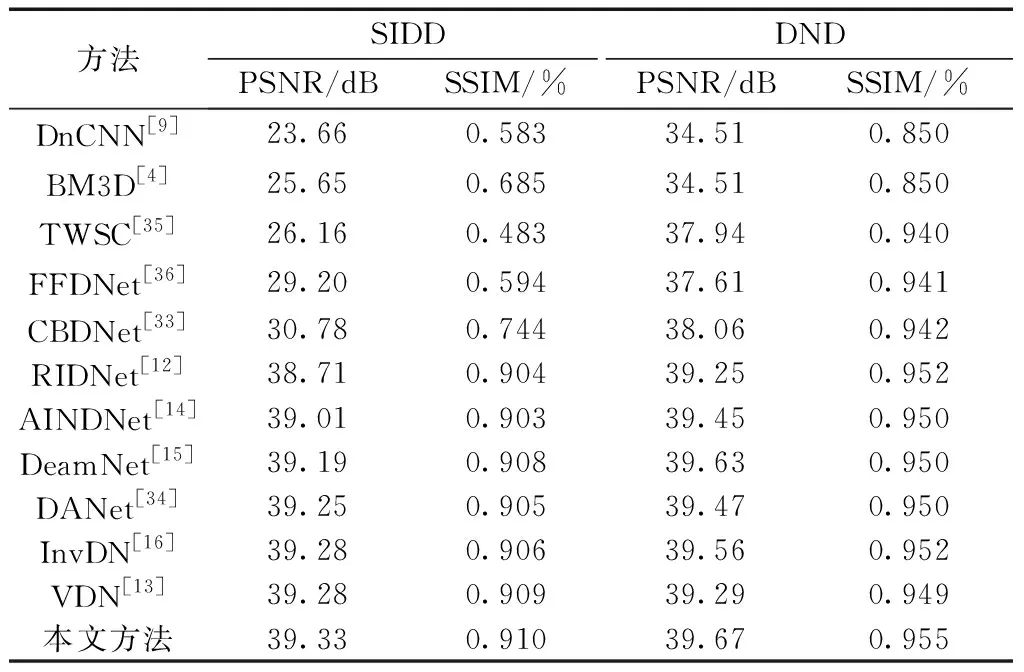
表1 不同方法在SIDD和DND数据集的去噪结果对比Table 1 Comparison of denoising results of different methods on SIDD and DND datasets
DND、SIDD和RNI15三个数据集采集的设备与方式是各不相同的,噪声特性也不同。本文方法只在SIDD数据集上进行训练,在三个数据集上经过测试,都表现出优秀的性能,体现了本文方法具有很好的泛化能力。
2.4 消融实验
对迁移学习编码单元(A)、残差注意力模块(B)和残差跳线(C)进行了消融实验。本实验中所使用的SIDD训练测试数据和参数设置与之前对比实验是相同的。从表2可以看到,实验1~实验3表示分别去掉模块A、B、C之后,模型性能分别下降了0.77、0.26、0.12 dB,其中迁移学习编码单元对模型性能有着较大的影响。实验4表示将3个模块都去除,模型性能大幅下降了2.5 dB。由此可见,迁移学习编码单元、残差注意力模块和残差跳线都使得模型性能得以提升,并且这些模块组合于模型中时去噪效果更优。

图7 DND数据集的去噪结果对比Fig.7 Comparison of denoising results of DND dataset

图8 SIDD数据集的去噪结果对比Fig.8 Comparison of denoising results of SIDD dataset

图9 RNI15数据集的去噪结果对比Fig.9 Comparison of denoising results of RNI15 dataset
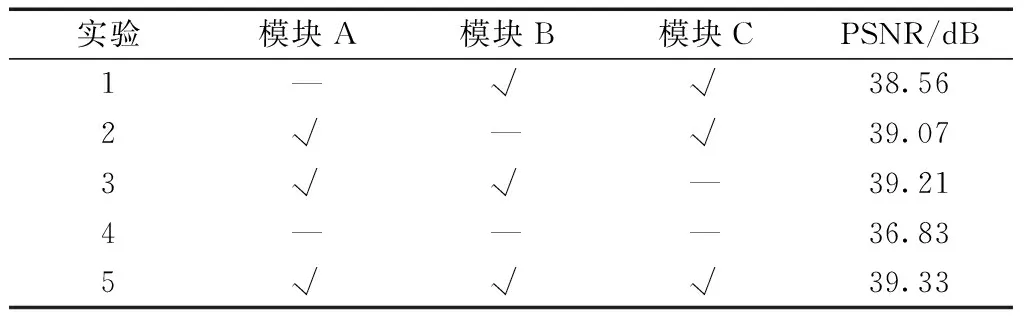
表2 模块A、B、C的消融实验Table 2 Ablation experiments of modules A, B and C
3 结论
针对真实噪声图像复杂的噪声分布,结合迁移学习技术,提出了一种能有效去除真实噪声的去噪模型。该模型利用迁移学习模块预先训练好的权值能很好地提取鲁棒特征,结合残差编码单元对信息进行补充,在解码单元利用残差注意力模块进一步处理恢复图像。实验结果表明,该模型在有效去除噪声的同时,能很好地保留图像细节和边缘信息,在不同数据集上有很好的泛化能力。
