汉语作为第二语言的韵律组块认知加工研究
2023-01-12陈梦恬王建勤
陈梦恬,王建勤
(1.昆山杜克大学,江苏,昆山 215316;2.北京语言大学语言认知科学学科创新引智基地,北京 100083)
1.引言
组词断句是第二语言口语产出的难点。在即时的话语中,学习者很难确定单位边界的位置和数量,以至于犯两类错误,即停顿不当和停顿过多(曹剑芬,2011)。比如 “小明吃了一碗饭”,如果停顿(用斜线表示)是 “小明吃/了一/碗饭”,那么 “了一”这个单位不合句法,也没有意义。如果是 “小明/吃/了/一碗/饭”,所有单位都符合句法且有意义,可是停顿过多、单位长度太短,会影响口语表达,致使交流受阻。
从语言层面上看,这两类错误是由句法分析不当所导致的。口语单位是以句法词为基础,经长度、语速等调节而成的韵律组块,其切分和组合需符合句法规则,否则会影响口语理解(Selkirk,2000)。长度则被用来平衡组块边界间的距离,使信息焦点分布更均衡,交流更顺畅(周明强,2002)。从认知加工上看,这两类错误还揭示了认知资源的在线分配问题,而这一问题在第二语言口语中更突出(Robinson,2003)。面对同一种语言,学习者没有母语者那样的词汇和句法知识,提取和应用这些知识的过程尚未自动化,常通过增加停顿、缩短组块等方法,来赢得更多的注意力资源和认知加工时间(MacWhinney,2012)。
这里的韵律组块,并非语言学意义上的韵律词、韵律短语等静态的韵律结构的层级单位(Chu & Qian,2001;Frazier et al.,2006),而是动态的口语表达结构的加工单位,具有时间和空间特性(曹剑芬,2003)。空间特性表现在,口语表达结构由独立于句法、语义等的韵律特征的心理表征构成,与句法结构关系密切(Ferreira,1993;Speer et al.,1993)。时间特性是指,实际的口语表达结构,会受长度、语速等因素的制约,在组块上呈现二分趋势,不完全与心理词典中的韵律结构一致(Grosjean et al.,1979)。先前的韵律组块研究,主要从组块的分类和边界特征入手,得出的韵律结构模型,多数基于静态的空间层级描述,非动态的单位切分与组合(张家騄等人,2002;王永鑫、蔡莲红,2010),而后者正是韵律组块在口语中的表现(MacWhinney,2008、2012)。因此,在认知加工层面探究口语的组词断句,应以口语表达结构中的韵律组块为对象。
影响韵律组块的因素主要有两方面:从语言本身来讲,句法的影响最大(Hirose,2003;Hirst,1993),其次是语义和语用(Astésano et al.,2004;赵瑾,2012);从认知加工上看,有长度、语速等(Bachenko & Fitzpatrick,1990;Jun,2003)。综合考查语言和认知因素的研究,在计算机文语转换领域较多(Bruce et al.,1996;Shriberg et al.,2000),得出的一些规则,例如句法成分的分类及其内部粘合程度,决定组块边界不该在哪里,成分长度则在此基础上进行调节,根据语义和信息焦点去掉不必要的边界(Bachenko et al.,1986),对汉语口语韵律组块也有解释力(陈默,2007;裴雨来等人,2009;张连文,2013)。然而,这些规则的设定没有将组块表现与其背后的认知加工联系起来,而这正是学习者的口语产出有别于母语者的原因之一(Ullman,2001),也是第二语言教学的目标之一(魏岩军,2017)。
因此,本研究以口语表达结构的韵律组块为对象,从认知加工出发,通过分析学习者和母语者的句子停顿率和语流长度,来考查句法和长度对汉语口语韵律组块的影响。句法因素由句法成分的性质来代表,长度由名词修饰语的长度来代表(高思畅、王建勤,2019)。前人研究证实,韵律组块中词汇提取与句法计算效率的提高,可由停顿率的减少和语流长度的增加来体现(Rehbein,1987)。具体研究问题如下:
第一,学习者产出含不同句法成分的汉语句子时表现如何?句法成分的性质对其韵律组块有何影响?
第二,学习者产出含不同长度修饰语的汉语句子时表现如何?句法成分的长度对其韵律组块有何影响?
停顿率,即单位时间内的停顿次数,反映口语韵律组块的切分情况。语流长度,即相邻切分边界间的组块长度,反映组块的组合情况。二者的计算公式如下:
停顿率=句内停顿次数÷音节总数
语流长度=句内句法词个数÷组块个数(单位:词)
2.句法成分性质对口语韵律组块的影响
2.1 实验方法
2×3两因素混合实验设计。自变量:(1)句法成分性质,被试内变量,分为含附属句法成分和不含附属句法成分两类。附属句法成分是指介词短语或副词构成的状语;(2)汉语水平,被试间变量,分为低水平、高水平和母语者三个水平。因变量是停顿率和语流长度。
2.1.1被试
低水平组15人(8男7女),高水平组15人(10男5女),母语者15人(5男10女)。两组学习者的平均汉语学习时间分别为2年和5.3年,同一入学考试的平均分是83和93.3。根据Plonsky和Oswald(2014)对第二语言习得研究的平均数差异效应量评估,本研究将0.4、0.7和1.0视为低、中、高效应量的下限阈值。据G*power软件估算,要达到中等效应量并具备0.80的多因变量混合实验的检验效能,至少需要45名被试。本实验的被试总量符合要求。
学习者和母语者均为中国大陆某高校学生,实验前通过了工作记忆容量测试(Fortkamp et al.,1999;解文倩,2017),无过高或过低的情况。学习者来自美国、英国、加拿大和澳大利亚,16岁前未接触过汉语,来中国以后只在目前就读的大学学习汉语。
2.1.2材料
20个单句(见附录1),根据工作记忆容量将音节数控制在9到16个之间(Miller,1956;Cowan,2001)。不含附属句法成分的句子(M=7,SD=1.1)和含附属句法成分的句子(M=7.4,SD=1.1)在句法词数量上无显著差异(χ2=1.143,p=.767,φ=.239)。句中字词学习者被试都学过,但实验句并非课文的句子。这样做是为了降低其已将实验句当成整个组块来提取的概率,以便考查其在线组块能力。实验前一天,研究者会给每个被试一个词表,解答词和句法结构的疑问,保证其在实验开始前具备所需的词汇和句法知识,减少这些因素对实验结果的影响。
2.1.3步骤
实验任务是看后复述,即在无语境的情况下,看到并熟悉一个句子,等句子消失后,复述这个句子(Sternberg et al.,1978)。与朗读相比,看后复述更能模拟自然的口语产出,又允许研究者控制材料和步骤(高思畅、王建勤,2020)。
实验用E-prime 2.0操作,每个实验句随机呈现一次。正式实验前有三组练习句。如果被试不能在规定时间内复述完,程序继续运行,规定时间外复述的词不被计入。复述完整率在85%以下的数据会被剔除。所有被试每个句子的复述完整率都在85%以上,故都为有效数据。整个实验持续7到8分钟。

图1:句子复述任务步骤
2.1.4分析
研究者根据两名不参与实验的母语者听感,确定被试的组块边界,据此计算出停顿率和语流长度。未经专业训练的母语者依据听感判断出的边界,与说话者的产出有较高一致性(王蓓等,2004)。判断一致率为95%,分歧之处由两人商议解决。停顿率和语流长度的计算基于实际产出的句子,包含原有语义基础上的添减、替换词。
因变量的分析由SPSS 25.0重复测量方差分析完成。边界位置和增减、替换词数据,由研究者手动统计。停顿率和语流长度均非严格意义上的定距变量,所以推论统计数据进行了对数转换,公式为Y'=log10(Y+1)。方差分析的效应量由partial eta squared(η2p)表示,简单效应检验的效应量由Cohen'sd表示。推论统计采用转换后的数值,描述统计采用转换前的数值。
1.2 实验结果
停顿率的描述统计数据如下:

表1:实验一停顿率的平均数和标准差
方差分析结果显示,成分性质(F(1,42)=28.307,p<.001,η2p=.403)和汉语水平(F(2,42)=107.832,p<.001,η2p=.837)主效应均显著,成分性质和汉语水平的交互作用显著(F(2,42)=5.377,p=.008,η2p=.204)。经Bonferroni校正后的简单效应检验显示,低水平组含附属句法成分的句子停顿率,比不含的高(t(14)=3.941,SE=0.004,p=.001,Cohen'sd=1.018,95%CI[0.008,0.027])。高水平组也一样(t(14)=3.275,SE=0.004,p=.006,Cohen'sd=0.845,95% CI[0.005,0.024])。母语者两类句子的停顿率无显著差异(F(1,42)=.194,p=.662,η2p=.005)。
语流长度的描述统计数据如下:

表2:实验一语流长度的平均数(单位:词)和标准差
方差分析结果显示,成分性质的主效应(F(1,42)=25.949,p<.001,η2p=.382),汉语水平的主效应(F(2,42)=141.033,p<.001,η2p=.870),成分性质和汉语水平的交互作用都显著(F(2,42)=7.954,p=.001,η2p=.275)。经Bonferroni校正后的简单效应检验显示,低水平组含附属句法成分的句子语流长度,比不含的短(t(14)=4.565,SE=0.013,p<.001,Cohen'sd=1.179,95%CI[0.043,0.088])。高水平组也一样(t(14)=3.489,SE=0.020,p=.004,Cohen'sd=0.901,95% CI[0.027,0.115])。母语者两类句子的语流长度无显著差异(F(1,42)=.080,p=.778,η2p=.002),相反,含附属句法成分的句子语流长度比不含的长。
边界位置的分布数据如下:
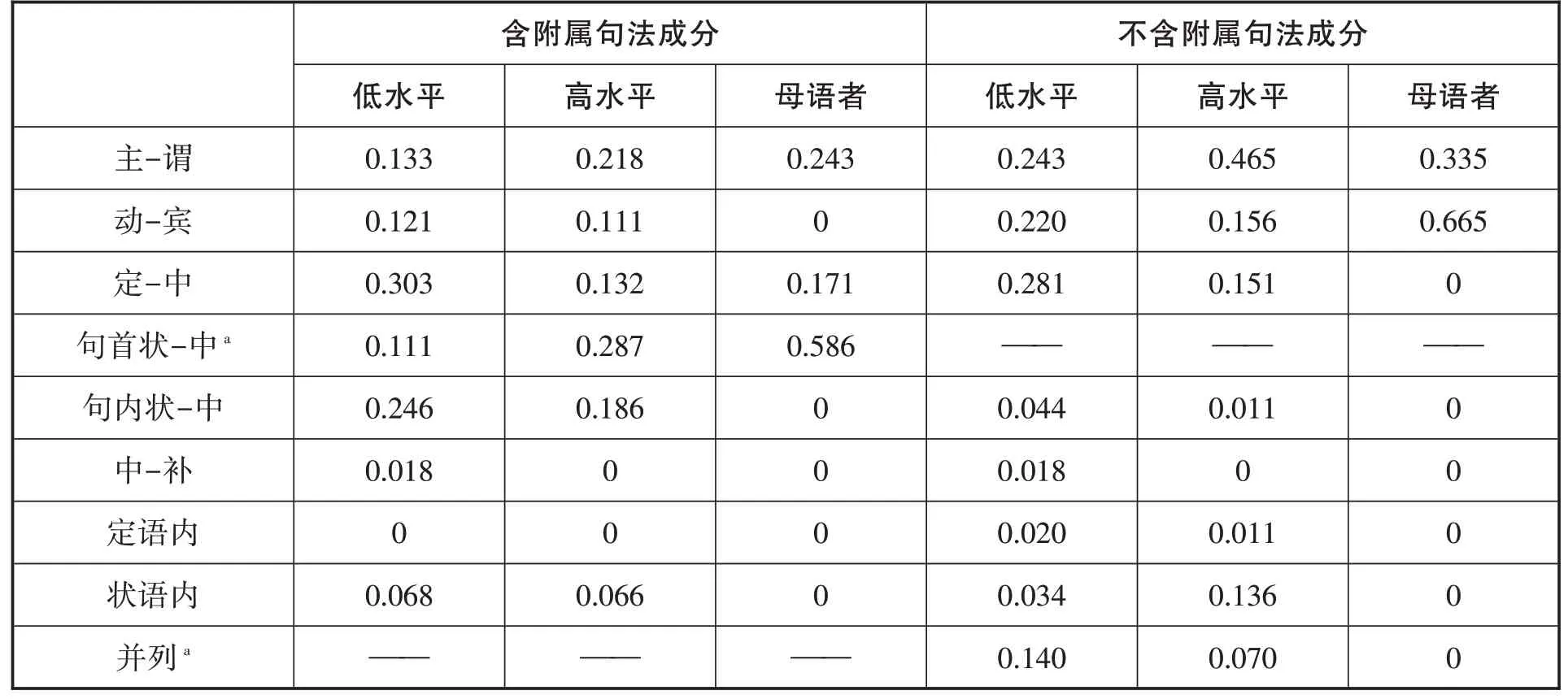
表3:实验一韵律组块边界占句法成分边界的比率
无论句中是否有附属句法成分,低水平组在多数句法成分之间都会设定组块边界,其中以定语-中心语,即名词性成分内部的几率最大,例如 “冬天的/时候/外面/非常/冷”(含附属句法成分) “我们/去了/北京的/胡同”(不含附属句法成分)。高水平组也一样,但其边界主要设在主语-谓语、句首状语-句子主干等较大的成分之间,例如 “冬天的时候/外面/非常冷” “我们/去了北京的/胡同”。母语者的边界数量很少,会选择在动词-宾语等较大的句法成分之间设定边界,例如 “冬天的时候/外面非常冷” “我们去了/北京的胡同”。
增减、替换词的统计如下:

表4:实验一增减、替换词的总个数
附属句法成分的有无,对三组被试的增减、替换词操作没有显著影响。从数量上看,低水平组的操作最多,母语者的最少。从分类上看,减词的概率最大,最少是增词。减词多发生在 “了” “的”等功能词上。替换词出现在 “妹妹” “妈妈”等亲属名词上。增词分两种:(1)根据语义增加 “都” “要”等副词,例如 “公园里的花(都)非常漂亮”;(2)重复某个词,来获得更多的回忆时间,例如 “在我老家(老家)那边黄苹果特别贵”。
2.3 讨论
实验一结果表明,句法成分性质对学习者的汉语口语韵律组块有影响,附属句法成分越多,停顿率就越高,语流长度也越短。这可以从组块的句法加工上解释。Ullman(2004,2005,2016)陈述性-程序性模型(Declarative/Procedural Model)和MacWhinney(2008,2012) “一语+二语”的联合模型(Unified Model)均指出,组块一旦形成,内部用于分析性组合的句法计算,即将多个成分依据句法规则组合成一个整体的过程就程序自动化,进而被整体组块的提取所抑制,无需再消耗注意力资源。如果句法计算未程序化,成分组合就采用控制性加工,根据句法计算的难易程度来消耗注意力资源。反映到实验一上,附属句法成分的加入,使句法结构变复杂,在线组合句法词形成韵律组块的难度就增加(曹剑芬,2003)。由因变量数据可知,学习者在句子层面的韵律组块,以多个句法词的提取及其之间的分析性组合来实现,属于多步骤的控制性加工,因此会受到句法结构复杂度的影响。不过,学习者在词层面的韵律组块,没有因句法加工而过度消耗注意力资源,即附属句法成分的有无,未对其增减、替换词产生显著影响。在重复词时,学习者也倾向于重复整词而不拆分词。
实验还发现了学习者和母语者在组块边界位置和数量上的不同:(1)附属句法成分越多,学习者的边界就越多,母语者则不受影响,其总体边界数量也很少;(2)无论是否有附属句法成分,学习者都会在各个句法成分之间设定边界,母语者的边界则主要在主语-谓语、句首状语-句子主干等较大的句法成分之间。这种区别,在于二者的韵律组块加工方式的不同。母语者依靠语义联想来提取组块,其内部的句法计算运用的是程序性知识,不消耗注意力资源,所以并非完全按照句法成分关系来进行,也就不易受句法结构复杂度的影响(Ullman,2001)。学习者的句法计算依赖控制性加工,虽其句法词的提取凭借语义通达而近乎自动化,但将句法词通过句法规则组合成韵律组块时,依旧会消耗注意力资源(魏岩军,2017),所以会按照句法成分的层级结构来设定组块边界,结构越复杂,边界就可能越多,组块就越小。除此之外,学习者所受的汉语教学也主要以句法词为单位,通过分析句法结构来组词造句,致使其口语产出过度依赖分析性的句法计算(MacWhinney,2018)。这一点可从高水平组和母语者的边界位置差异中得到印证:虽与低水平组相比,高水平组的边界数量较少,但仍倾向于在高一级的句法成分之间,例如 “我们/去了北京的胡同”的主语和谓语之间设定边界,而不像母语者那样,根据语义和长度,设定在 “我们去了/北京的胡同”的动词和宾语之间。
3.句法成分长度对口语韵律组块的影响
3.1 实验方法
2×3两因素混合实验设计。自变量:(1)成分长度,被试内变量,分为短修饰语和长修饰语两类;(2)汉语水平,被试间变量,分为低水平、高水平和母语者三个水平。
因变量、被试、步骤和数据分析,与实验一相同。
材料为20个单句(见附录2),分为短修饰语句(M=6.5,SD=0.7)和长修饰语句(M=8.9,SD=1.0)。短修饰语为单层定语,长修饰语为多层定语。一半的修饰语出现在主语位置,另一半出现在宾语位置。卡方检验显示,两种修饰语的句法词数量存在显著差异(χ2=16.571,p=.005,φ=.910),表明其长度有显著区别。
3.2 实验结果
停顿率的描述统计数据如下:
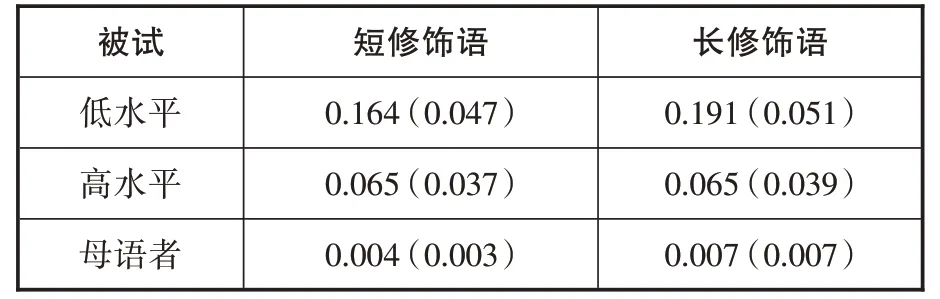
表5:实验二停顿率的平均数和标准差
方差分析结果显示,修饰语长度的主效应不显著(F(1,42)=3.215,p=.080,η2p=.071),汉语水平的主效应显著(F(2,42)=117.123,p<.001,η2p=。848),修饰语长度和汉语水平的交互作用显著(F(2,42)=3.847,p=.029,η2p=.155)。经Bonferroni校正的简单效应检验显示,低水平组长修饰语句子的停顿率,比短修饰语的高(t(14)=2.507,SE=0.004,p=.025,Cohen'sd=0.647,95% CI[0.001,0.018])。高 水 平 组(F(1,42)=.012,p=.914,η2p<.001)和母语者(F(1,42)=.007,p=.932,η2p<.001)两类句子的停顿率无显著差异。
语流长度的描述统计数据如下:

表6:实验二语流长度的平均数(单位:词)和标准差
方差分析结果显示,修饰语长度的主效应(F(1,42)=81.923,p<.001,η2p=.661),汉语水平的主效应(F(2,42)=144.345,p<.001,η2p=.873),修饰语长度和汉语水平的交互作用都显著(F(2,42)=10.537,p<.001,η2p=.334)。经Bonferroni校正的简单效应检验结示,低水平组两类句子的语流长度无显著差别(t(14)=1.704,SE=0.013,p=.111,Cohen'sd=0.440,95%CI[-0.050,0.006])。高水平组(t(14)=4.592,SE=0.016,p<.001,Cohen'sd=1.186,95% CI[0.040,0.110])和母语者(t(14)=13.401,SE=0.008,p<.001,Cohen'sd=3.460,95% CI[0.088,0.121])长修饰语句子的语流长度,比短修饰语的长。
边界位置的分布数据如下:
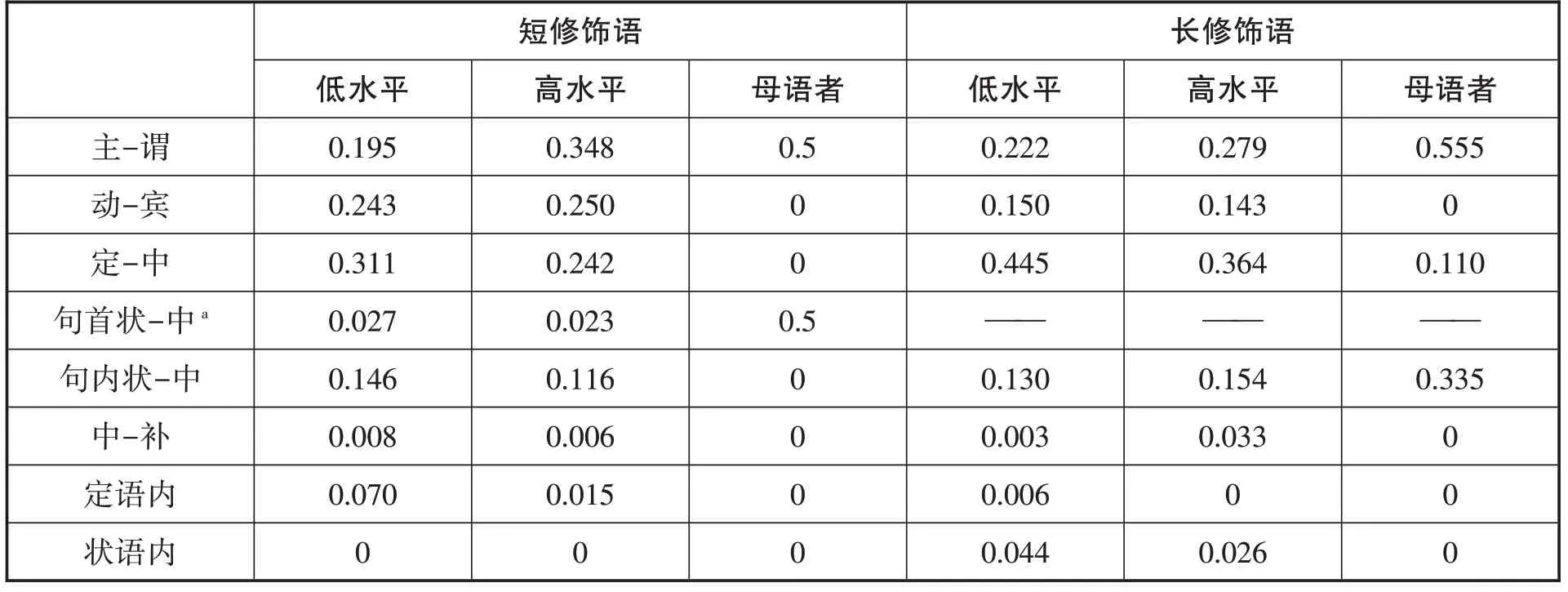
表7:实验二韵律组块边界占句法成分边界的比率
无论修饰语有多长,低水平组都会在多数句法成分之间设定组块边界,其中又以定语-中心语,即名词性成分内部的几率最大,例如 “她/妈妈/的眼睛/大大的”(短修饰语句)、 “这是/我在/上海/拍的/照片”(长修饰语句)。高水平组也一样,但其除了定语-中心语,还会在主语-谓语等较大的句法成分之间设定边界,例如 “她妈妈的/眼睛/大大的”、 “这是/我在上海拍/的照片”。母语者的边界数量很少,也会选择在主语-谓语、状语-中心语等较大的句法成分之间设定边界,例如 “她妈妈的眼睛/大大的” “这是我在上海/拍的照片”。
增减、替换词的统计如下:
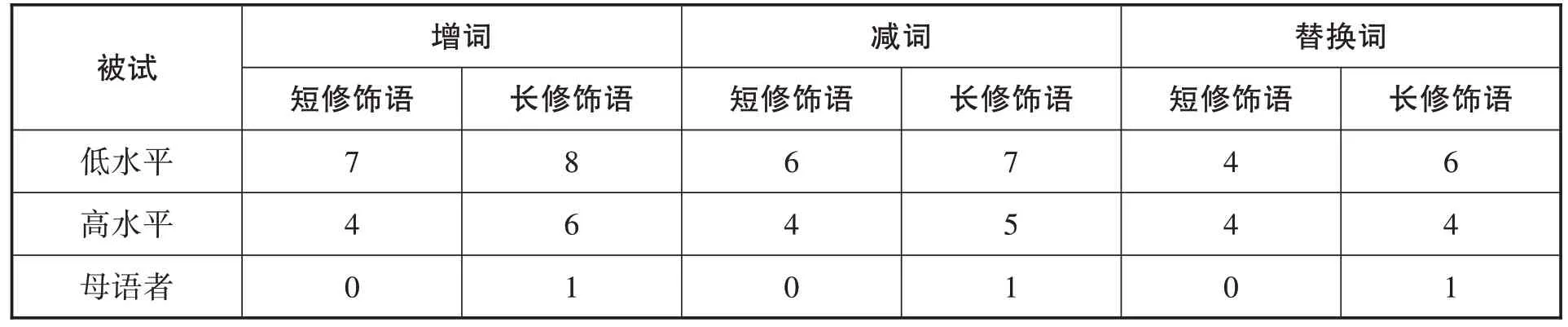
表8:实验二增减、替换词的总个数
修饰语的长短对增减、替换词无显著影响。减词发生在 “的” “在”等功能词上。替换词出现在 “他” “这里”等代词或是 “很” “非常”等副词上。增词也分两种:(1)根据语义增加 “了” “的”等功能词,例如 “我(的)朋友很喜欢踢足球”;(2)重复某个词,以赢得更多的回忆时间,例如 “一斤这么小的苹果应该(应该)不贵”。
3.3 讨论
实验二结果表明,成分长度对学习者的汉语口语韵律组块有影响,这种影响要分不同的指标来看:修饰语越长,低水平组的停顿率就越高,语流长度则无明显变化;修饰语的长短,对高水平组的停顿率无显著影响,而修饰语越长,其语流长度也越长。
长度对第二语言韵律组块的影响,与第一语言 “句法-韵律的间接关系论”一致,即韵律组块依据的是口语表达结构而非句法结构(Gee&Grosjean,1983)。长度的调节,建立在词汇和句法通达的基础上,用来保证组块的语义完整性和口语产出的自然性(Breen et al.,2011),因而不如语言本身特征,例如句法成分性质对韵律组块的影响大。这一点可从实验二中得到印证:学习者的组块表现,与实验一相比更接近母语者,受修饰语长度的负面影响较小。尽管如此,学习者的韵律组块仍受其认知加工方式的制约:修饰语长度的增加,使组块内部的句法结构变复杂,学习者依托控制性加工的句法计算就需要更多的注意力资源(Robinson,2003)。同时,复述时间也变长,完成复述任务也需要更多的注意力资源(Koelega,1996)。一旦这些过程消耗的注意力资源增加,韵律组块的其他方面,例如语义通达所能动用的认知资源就会减少,组块结果也就受影响。不过,学习者的增减、替换词操作,依旧不受修饰语长短的影响,所以其句子层面的韵律组块表现,与句法计算而非词的组块有关。
母语者的韵律组块不受修饰语长度的负面影响,反而能根据其长短来调整组块的大小。这种策略被称为 “压缩组合”策略,便于母语者充分利用注意力资源,减少不必要的组块边界。学习者,特别是高水平组,在本实验中的组块策略与母语者一致,但其边界数量仍较多,且常出现在高一级的句法成分,例如主语和谓语之间。当修饰语长度增加时,又会在修饰语内部,即定语和中心语之间设定边界。这表明,高水平组的韵律组块仍受控制性加工的句法计算影响,而不是像母语者一样,依靠语义联想和长度调节来进行。
实验还发现,长度在停顿率和语流长度上的作用不完全一致:低水平组的停顿率受修饰语长度的负面影响较大,高水平组的语流长度受其正面影响较多。这与Towell等人(1996)的研究结果一致,即存在 “语流长度增加但停顿率不变”或是 “语流长度不变但停顿率减少”的韵律组块表现。这些不一致的现象反映了具体语言材料的认知加工难易度和第二语言认知加工能力的非线性发展趋势。再者,停顿率与语流长度考查的韵律组块的维度不同:停顿率的基本单位是音节,考查组块的切分;语流长度的基本单位是句法词,考查组块的成分组合(曹建芬,2011)。二者在实验中的不同表现也表明,韵律组块存在切分与组合两个子过程,而这两个过程在认知加工上有何区别,值得进一步探究。
4.结语
研究通过两个看后复述实验,证实了句法成分的性质和长度,对学习者汉语口语韵律组块的影响,这种影响可归结为句子层面句法计算的注意力资源分配与认知加工方式的问题。学习者要想提高韵律组块能力,需习得母语者的 “压缩组合”策略,将句法计算程序化的同时,依靠语义联想而非分析性的句法成分组合,来产出句子。
研究对第二语言口语教学的启示如下:首先,应增加口语的韵律组块而非句法词和句法短语的输入,例如魏岩军(2017)中提到的 “最近几天” “从来都不”等多词短语,帮助学习者形成长时记忆里依靠语义联想来整体提取的组块。其次,应加强工作记忆作用下的即时组块练习,例如在不同语境下重复同一组块,或将其与不同的组块组合,例如 “从来都不”+ “吃”, “从来都不”+ “说”。只有不断激活组块的句法计算过程,将控制性加工的句法成分组合,转变为程序自动化的产出编码,才能使学习者的汉语口语韵律组块摆脱注意力资源的限制,将更多的工作记忆运用于语义联想下的组块加工。这样一来,学习者就能依据句子的语言特征,例如句法结构和长度,来伸缩调整组块的大小,进行语义完整且流利的口语表达。

附录1:实验一实验材料

附录2:实验二实验材料
