基于飞行试验和风洞试验数据的融合算法研究
2023-01-05王文正郑凤麒施孟佶
邓 晨,陈 功,*,王文正,郑凤麒,施孟佶
(1.空气动力学国家重点实验室,绵阳 621000;2.中国空气动力研究与发展中心计算空气动力研究所,绵阳 621000;3.电子科技大学航空航天学院,成都 611731;4.飞行器集群智能感知与协同控制四川省重点实验室,成都 611731)
0 引言
在飞行器设计初期,需要基于气动数据进行多次反复迭代来确定和优化气动外形[1-2]。因此,如何获得精度高、不确定度小且代价低的气动数据成为了气动设计的关键点。
目前获得气动数据的手段主要有飞行试验、风洞试验和数值模拟[3-4]。现有飞行器的气动力建模主要是基于数值模拟或风洞试验数据[5-7]。风洞试验因为存在支架干扰、洞壁干扰和天地相关性等因素,与实际飞行数据存在一定差异,降低了气动力建模精度[8-9];而飞行试验代价昂贵,受大气环境和传感器精度的影响较大,此外由于试验激励的限制,难以获得满足建模需求的辨识气动力数据样本。目前,国内外专门针对飞行试验数据进行建模的研究还较少。美国的Morelli等[10-11]进行了基于飞行试验数据的高效气动建模和基于飞行试验数据的气动模型参数准确性估计等一系列研究。国内王文正等[12]创新性地将数据挖掘技术应用于飞行试验数据分析和气动力参数辨识中,建立了基于飞行试验数据的建模方法、辨识结果一致性检验方法和舵效确认方法,对数值模拟和风洞试验数据的融合验证进行了初步探索。
从国内外研究内容来看,目前飞行试验数据主要用于气动建模和参数辨识等方面,用于气动数据融合方面的研究较少。基于此,本文提出了基于飞行试验数据和风洞试验数据的气动数据融合算法。飞行试验虽然获取的特征点数据少,但采用全尺寸飞行器可以获得真实飞行条件下的历程数据,数据更加真实,精度相比于风洞试验数据更高。可以用少量的飞行试验数据与风洞试验数据相融合,以达到提高数据精度同时降低试验代价的目的。本文以一种轴对称飞行器为研究对象,进行了基于梯度信息和基于高斯过程回归的气动力数据融合方法研究。该方法可更好地利用飞行试验数据,降低飞行试验次数和代价,提高气动力建模精度,研究结果有助于飞行器气动布局与控制系统设计。
1 气动力数据样本
1.1 飞行试验数据样本
本文采用的轴对称飞行器进行了多次飞行试验,通过对遥测数据进行气动力参数辨识[13-14],可以得到飞行器法向力系数CN、轴向力系数CA和侧向力系数Cy沿飞行时间的变化趋势,如图1所示。

图1 飞行试验数据结果Fig.1 Flight test data results
由图1可知,在飞行试验过程中,受操纵配平和机动能力的限制,飞行器主要在俯仰通道进行机动控制,侧向力气动力系数很小。在飞行末端,法向气动力系数变化相比于轴向力系数和侧向力系数更加明显,且末端轨迹落于低层大气中,大气测量手段更多,大气模型更加精确,有助于获得更加准确的飞行试验数据。所以末端法向力系数数据适合作为气动数据融合方法研究的高精度样本数据。
1.2 风洞试验数据样本
对象飞行器在风洞中进行了大量地面气动力试验,获取了较为完整的地面风洞试验数据集,并以此建立了飞行器气动力模型[15-16]。通过该模型,可以预测飞行包线内任意状态点的六分量气动力系数。
如图2所示,该飞行器采用“X”型尾翼布局,进 行 俯 仰 操 纵 时,四 个 舵 的 舵 偏 角 存 在|δ1|=|δ4|、|δ2|=|δ3|关系。为降低气动力系数建模难度,同时考虑到飞行试验沿飞行轨迹状态的激励限制,采用俯仰通道舵偏δ1、δ2为变量、法向力系数CN为研究样本对象。
在特定飞行段,通常认为飞行试验辨识的气动力系数样本点精度较高、数量少;风洞试验数据气动力系数样本点数量多,但是由于存在天地相关性差异,精度较低。这里对上述两种来源的数据样本数量分别取5和60个特征状态点。在某一固定马赫数区域,通过Kriging建模[17-18]得到相应的响应面分布,如图3所示。两种数据样本在相同状态点的数值大小上表现出一定的差异性,但整体变化趋势表现出一致性。即两种来源的数据具有接近的梯度信息,反映了高超声速空气流动的基本物理规律。

图2 “×”型尾翼舵面控制Fig.2 Illustration of “×”shaped tail rudder surface control

图3 两种来源的数据样本点分布对比Fig.3 Comparison of two source data sample points distribution
2 基于梯度信息的数据融合方法
2.1 算法原理
基于梯度信息的数据融合是最为朴素的一种数据融合算法。根据数据来源的不同,数据的变量是多维的,建立偏导数的阶数也可以是多阶的。阶数的增加会带来计算代价的大幅增加,这里考虑一般性和建模精度的要求,采用一阶偏导信息建立融合模型。已知有m个n维的样本点,它们的值及一阶偏导数信息如下:
数据样本:

一阶导数:

风洞试验数据多,可以较为准确地求得样本空间内任意位置处的一阶梯度。在任意高精度数据样本点处的融合气动力系数模型计算公式如下:

式中:Sh0为 已知高精度样本点;Sh是预测数据点。式(4)和式(5)是两种求解梯度信息的方法,工程应用中一般采用后者。需注意的是,当求解梯度信息选用的距离ΔS和 样本值的距离Sh-Sh0相同时,计算结果最精确。
在预测过程中,若在整个样本空间的气动力模型是连续的,由一个高精度样本点及附近的一阶梯度信息可以求得所有需要的预测值。但在实际中,因为各种误差,气动力系数模型的一阶梯度是不连续的,会导致由多个高精度点计算得到的融合模型不光滑。
为了解决这一问题,本文创新性地设计了基于样本点相对距离的加权融合算法。如式(6)所示,对于新的预测点,首先计算它与所有已知高精度样本点的距离,并以距离为权值,对每个高精度样本点求得的预测值进行加权融合:

式中:wi为第i个高精度样本点的权值,di为预测点距离第i个高精度样本点的距离,yk为新的预测点的值,yi为单独使用1个高精度样本点求得的预测值。预测点距离样本点的距离越大则该样本点的影响越小,权值越低。这种方法既解决了融合模型不连续,也利用了所有已知样本点的建模信息,融合精度更高。
2.2 数据融合结果
将高精度飞行试验数据随机分为训练集和验证集,用训练集与风洞试验数据进行融合,并用验证集进行验证,融合结果如图4所示。由图4可知,融合曲面具备与低精度数据回归曲面相同的变化趋势,并与高精度数据回归曲面部分重叠。融合模型综合利用了低精度数据的梯度信息和高精度数据的响应值信息,预测精度更加准确。

图4 基于梯度信息的气动数据融合算法结果Fig.4 Results of aerodynamic data fusion algorithm based on gradient information
利用验证集样本求得三种模型的均方根误差(root mean square error,RMSE):仅利用低精度数据建立的回归模型预测均方根误差为7.012×10-2;仅利用高精度数据建立的回归模型预测均方根误差为1.632×10-2;基于梯度信息的气动数据融合模型预测均方根误差为7.125×10-3,数据融合模型具备更高的精度。
3 基于高斯过程回归的数据融合方法
3.1 算法原理
高斯过程回归(Gaussian process regression,GPR)是一种基于贝叶斯优化的回归算法,对处理小样本、非线性、高维数等复杂问题具有良好的适用性[19-21]。在数据集合D={(xi,yi)}ni=1中,考虑到噪声,高斯过程回归的一般模型为:

式中, f(x)为 具有联合高斯分布的变量集合,ε为高斯白噪声。根据贝叶斯原理,高斯过程回归在数据集D建立了 y的先验函数,则样本点和新的数据点f*的后验分布为:

式中,N( )表示正态分布,K为样本点之间对称正定的协方差矩阵,K*为预测点与样本点之间的协方差矩阵,K**为 预测点自身的协方差,σ2n为噪声的方差,In为单位矩阵。
令X为x的集合,由此计算得到预测值f*的后验概率分布为:
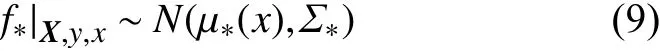
式中:

即新的预测点均值和方差分别为µ*(x)和 Σ*。
采用基于高斯过程回归的气动数据融合算法对不同来源的气动数据进行融合,步骤如下:首先,对不同来源气动数据进行高斯过程回归处理,得到预测点的均值µGPR和 方差σ2GPR,它反映了高斯回归模型的不确定度;接着,依据专家经验、试验经验等先验信息,设定数据源本身的保真度函数σ2F,它反映了样本的精度;然后将两者结合起来得到每一种数据源的总的不确定度µT,i(x)和σ2T,i(x);最后以不确定度方差作为权值进行融合。公式如下:
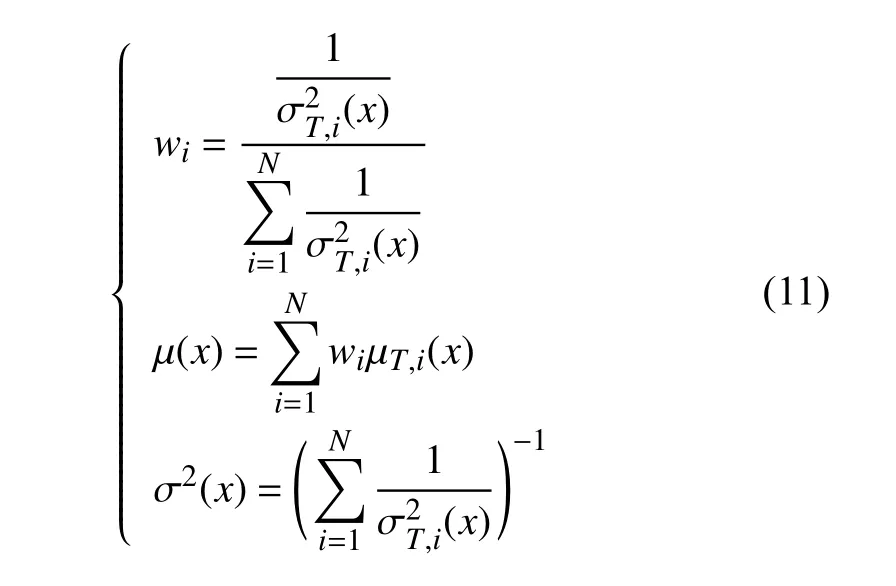
3.2 数据融合结果
分别对飞行试验辨识气动力系数样本和风洞试验气动力系数样本进行高斯过程回归处理,得到每一种数据源的回归曲面和置信区间,如图5所示。由回归模型预测结果可知,对于低精度数据样本,数据样本点多,高斯过程回归模型的不确定度低,但是根据先验知识可知数据本身的准度较低,而高精度数据样本则与之相反。
对两种来源数据分别进行高斯过程回归处理之后,采用基于不确定度的加权融合算法进行融合,结果如图6所示。融合数据曲面在数值上更接近于高精度数据回归曲面,并且融合之后的置信区间相比于单源数据直接建模结果更小,表明数据的不确定度更低。融合方法达到了提高数据精度、降低数据不确定度的目的。

图5 单源气动数据高斯过程回归结果Fig.5 Singlesource aerodynamic data Gaussprocessregression results
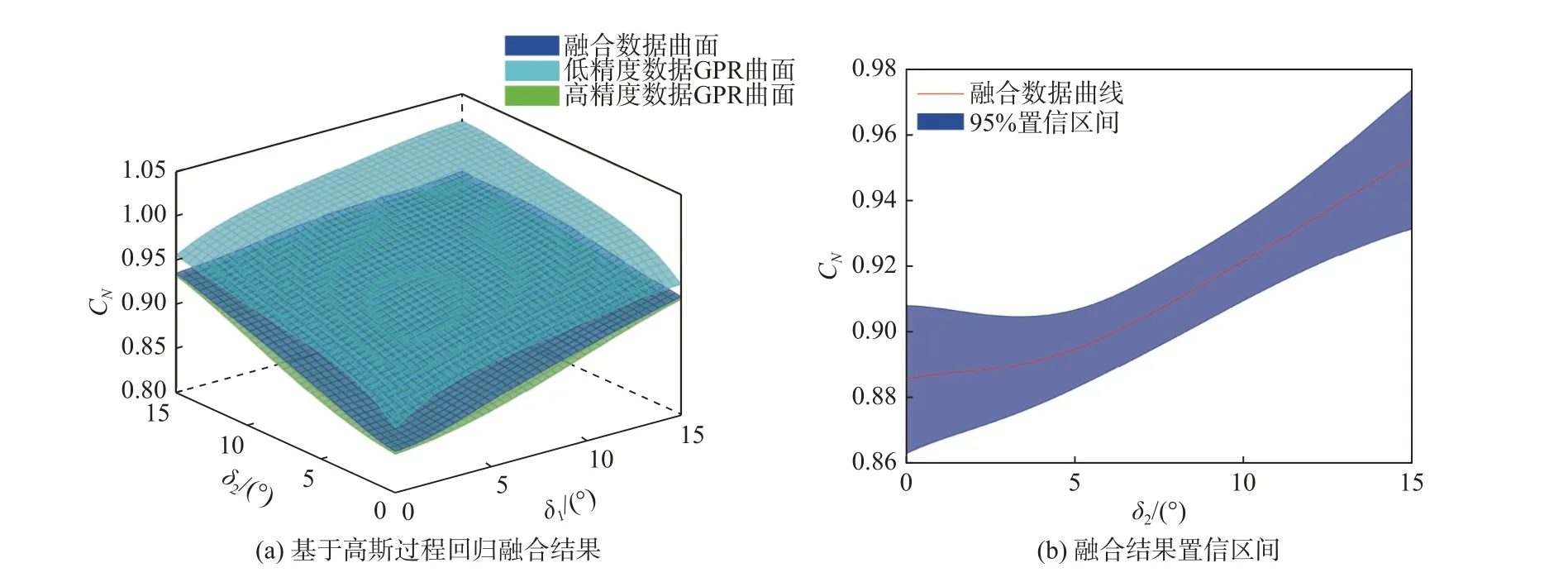
图6 基于高斯过程回归的气动数据融合结果Fig.6 Aerodynamic data fusion resultsbased on Gaussian processregression
4 结论
本文分别采用基于梯度信息和基于高斯过程回归的数据融合方法对飞行试验辨识数据和风洞试验数据进行融合,得到以下结论:
1)分析两种来源数据的差异性和一致性,两种数据样本在相同状态点的数值大小上表现出一定的差异性,但整体变化趋势表现出一致性。基于此,创新性地采用了基于梯度信息和基于高斯过程回归的两种融合算法对该飞行器气动力数据进行融合建模,结果均得到了比单源数据模型精度更高的融合模型。
2)创新地提出了一种以样本点相对距离作为权值的加权融合方法。当预测点距离样本点的距离越大,则该样本点的影响越小,权值越低。通过这种方法计算得到的预测值,解决了融合曲面不连续的问题,同时利用了所有已知的样本点,精度更高。
3)如果高、低数据的梯度信息较为一致,则基于梯度信息的数据融合适用性更高,预测结果更加准确;而基于高斯过程回归的数据融合方法不仅可以给出预测值,还可以分析置信区间,有利于不确定度的分析和研究。
