考虑供应商可靠性的零售企业越库配送网络优化
2023-01-05杨文宜李伯棠陈杰新
杨文宜 李伯棠 陈杰新
(广州航海学院 广东广州 510725)
引言
越库配送作业的高效之处在于供应商的可靠性、物流中心作业的响应性和市内配送路径的合理性。对于越库配送网络优化,葛显龙和邹登波以运输成本和操作成本最小化为目标,构建了集货和送货车辆路径模型;范厚明等建立以越库作业成本总和最小化为目标的库门分配与车辆路径优化模型;二者关注点在于物流中心作业及配送路径的优化,但忽略了供应商的可靠性。
供应商能否在规定的时间将合格产品送到指定的卸货口、能否满足零售企业对标签和包装的要求等都是供应商可靠程度测量的指标。多属性群决策广泛应用于社会、经济和管理等领域,其可在多决策者和不同指标的影响下评估供应商的可靠程度,决策者对指标的评估量是不确定的,解决方法有基于双向投影权重模型、基于证据推理和广义Shapley值、考虑决策者心理行为的区间二元语义、最佳最差模糊方法和基于三角模糊数和异构专家方法等,在多种不确定环境下正态隶属函数较为符合人类的思考和决策过程。
问题描述与模型构建
(一)问题描述
本文所建零售企业越库配送网络(见图1)由市郊供应商、物流配送中心和市内门店组成。首先把市内门店前一天所提交的产品需求量汇总到物流配送中心,随后由物流配送中心合理挑选上周可靠性较高的供应商进行产品采购并配送至各个门店,不同可靠性的供应商,所提供的产品在配送中心的处理时间和成本与其可靠性存在着线性关系,因此零售企业根据前一周供应商送货的表现,通过设定指标值确定当前一周内供应商的可靠程度;供应商采用直送方式送到某个配送中心,再由该配送中心把货物运送到各个门店。

图1 零售企业越库配送网络过程
基于上述描述,本文从配送时间、配送作业成本和供应商可靠性三个目标出发,对供应商进行进行评估与选择、配送中心选择和配送路径规划等决策,建立零售企业越库配送网络优化模型,并使用基于正态模糊数的多属性群决策方法、多目标处理方法和智能算法对模型进行求解。
(二)模型的建立
1.假设条件与符号说明。根据问题描述,本文假设条件如下:考虑一周内的供应商可靠程度计算和当周内每日配送路径的计划;物流配送中心有能力限制;车辆在当天任务开始前都停在某一物流配送中心内等待配送任务;各门店的卸货时间添加到运输时间中,反映在平均速度里。根据问题描述、假设条件和建模需要,需定义如下符号:
(1)集合:M为候选供应商集合,m∈M={1,2,...,NM};I为门店集合,i,j∈I∈{1,2,...,NI};J为两端配送中心和门店集合,i,j∈J∈{0,1,2,...,NI},0代表配送路径的起点和讫点配送中心;K为车辆集合,k∈K={1,2,...,NK};L为可用配送中心集合,l∈L={1,2,...,NL}。
(2)参数:sml为供应商m与配送中心l之间的距离;Tli为配送中心l与门店i之间的距离;tij为门店i与门店j之间的距离,i,j∈I;v1为市外运输车辆的平均速度;v2为市内运输车辆的平均速度;di为门店i的需求量,i∈I;C1m为供应商m的能力;c2l为配送中心l的能力;Qk为市内运输车辆k的装载能力;Bm为供应商m的备货时间;β为一个足够大的值;csml为供应商m运输到配送中心l的货物在该配送中心内的单位货物额定处理时间;cgm为供应商m的单位货物的采购成本;clml为供应商m运输到配送中心l的货物在该配送中心内的单位货物额定处理成本;α为市内车辆单位距离运输成本;Akl为车辆k是否停在配送中心l中。
(3)决策变量:zml为0-1变量,供应商m对配送中心l服务为1,否则为0;xkij为0-1变量,若车辆k从门店i运输到门店j为1,否则为0,i,j∈J;Yl为0-1变量,若配送中心l被选定作为配送点为1,否则为0;ykli为0-1变量,车辆k运输中配送中心l与起点门店相连为1,否则为0;y`kli为0-1变量,车辆k运输中配送中心l与讫点门店相连为1,否则为0;uki为车辆k经过门店i后累计的总配送量;wml为配送中心l对供应商m的采购量;okl为配送中心l对车辆k的配送量,Um为供应商m的可靠性。
2.目标函数。本文所建零售企业越库配送网络优化模型M1考虑三个目标。
目标1为最小化运输时间,其为供应商备货时间、配送中心额定处理时间、配送中心按不可靠程度对供应商额外增加的处理时间、供应商到配送中心的运输时间与市内配送时间之和,其数学表达式为:
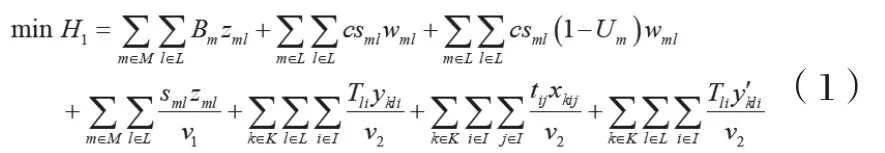
目标2为最小化越库配送网络过程的总成本,其为采购成本、配送中心额定处理成本、配送中心按不可靠程度对供应商额外增加的处理成本、供应商到配送中心的运输成本与市内配送成本之和,其数学表达式为:

目标3为最大化当天所选供应商的总可靠性,则数学表达式为:

3.约束条件。根据问题描述,本文所建模型需满足如下约束条件:


其中,式(4)限制配送中心对供应商的采购量不大于供应商的能力;式(5)规定每个供应商只能服务一个配送中心;式(6)限制供应商与配送中心之间有运量才能算是供应商为配送中心服务;式(7)限制供应商的供应品不大于配送中心的能力;式(8)对于每个配送中心,采购量大于等于配送路线的量;式(9)限制每条配送路线的量要大于等于该条配送路线的总需求量;式(10)表示只有配送任务存在时该配送中心才能开;式(11)限制装在某车辆的产品总量不大于该车辆的能力;式(12)确保车辆停在配送中心才能被使用;式(13)确保每个门店都要被访问;式(14)规定如果路线访问门店,必须要从配送中心出发;式(15)限制前后门店要衔接;式(16)规定如果路线访问门店,必须回到某个配送中心;式(17)用于累计该路线运输的货物量;式(18)限制路线运输总量不大于市内运输车辆能力;式(19)和式(20)限制有配送任务的车辆必须选择起点和讫点配送中心;式(21)限制同一路线的起点和讫点配送中心不能选在同一配送中心;式(22)限制变量为二元变量;式(23)限制变量为整数。
供应商可靠性计算过程
步骤1:给定决策矩阵,则第t个决策者关于属性对决策方案的决策矩阵为:

依据正态分布的“3σ原则”,可以将正态模糊数转化为区间数。求出相应的区间型决策矩阵为:
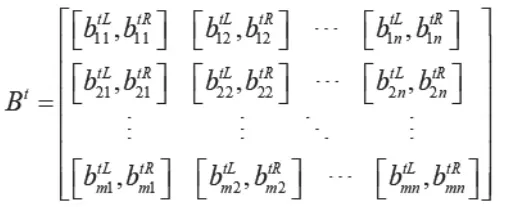
步骤2:求决策群体中各主管的权重。由于受主管的工作内容和专业认知等影响,使得各主管的权重不确定,以正态模糊数的形式给出主管所占权重,记为,其中。然后计算各主管的可信值,其中ε在评价主管权重时对待其评价值的态度,如果看中专家的期望,则取0.5<ε<1。利用可信值函数,按公式求得每个专家的权重。
步骤3:求群体决策矩阵:

步骤4 :求决策属性的权重值。首先找出不同属性Uj下的基础解,所求得的属性权重应使得所有属性下的基础解的加权离差平方和达到最小。令,,则称为属性Uj下的基础解。求解二次规划模型可得,第j个属性Uj的权重值ρj,j=1,2,...,n。
步骤5:求综合决策矩阵。根据群体决策矩阵与决策属性值,求综合决策矩阵Z:
多目标函数处理与解决方法
虽然前述所建非线性模型M1通过上一章节方法转变为线性模型,但受其多目标的影响,模型M1存在冲突目标,本文采用LP指标解决多目标问题,其可最大限度地降低各目标与最优目标间的差异。故3个目标H1、H2和H3的LP指标如下所示:
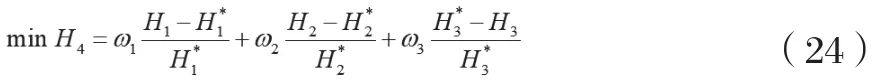
其中,H*1、H*2、H*3分别表示目标H1、H2和H3的理想解(由TOPSIS法求得,具体计算方法参考Nurianni等的做法,且由于其只用于计算多目标决策函数的帕累托最优解,故理想解的具体数值与计算公式在此不再赘述),ω1,ω2,ω3分别表示第1、第2和第3个目标的权重。本文用LP指标方法将多目标模型转换为单目标模型,从而求得所述模型的解。因此,本文所建模型M2为以式(24)为目标、以式(4)-(23)为约束条件的单目标规划模型。
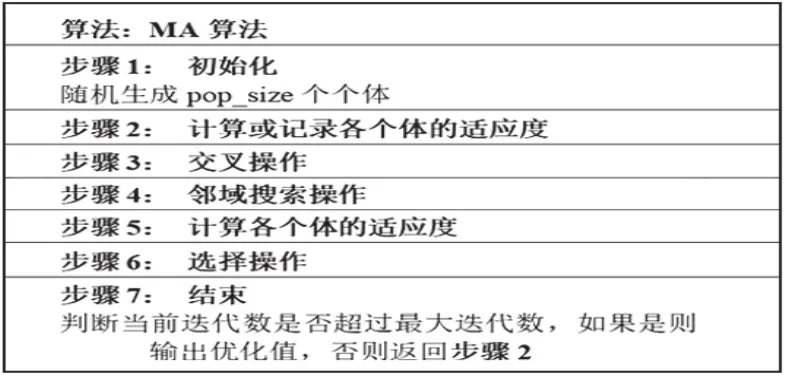
本文使用文化基因算法(Memetic Algorithm,MA)对该模型进行求解,MA算法同时具有全局搜索和局部搜索的功能,并且适合自然整数编码方式。
个体编码和解码。采用多段优先级编码的方式,企业管理人员挑选供应商把货物运输到有能力的物流配送中心,并由其作为起点进行市内零售门店的配送数量的选择和排序。对于此配送作业过程,“挑选供应商”“有能力的物流配送中心”和“市内零售门店的配送数量的选择和排序”的选择都可以按照一定的优先级进行。
对于个体编码的生成策略,分别按照供应商(M)、物流配送中心(L)和门店(I)的总数,分别随机生成1~|M|、1~|L|和1~|I|不重复的整数形成3段优先级。
本文所提MA算法的结构如下:
数值实验
为了验证模型和算法的有效性,根据对广州市内某百货超市企业调研数据的合理数值范围内随机生成若干个算例对算法的效率进行分析。本文模型采用CPLEX12.8软件进行编码和求解,多属性决策方法和算法采用MATLAB2015b软件和YALMIP工具包进行编码和求解。
1.案例分析。J超市企业作为国内知名的企业,在广州范围内有过百家超市门店。由于门店集中于广州城市中心区域,本文取该区域门店及相关配送中心和供应商数据如下:通过数据调查,该企业在广州市中心区域有18个门店、10个配送中心、9个供应商以及20辆车,三类节点各自和相互构成距离矩阵可通过百度地图驾车模式导航测得;由于数据量较多和篇幅关系,依据调研情况给出相关数据的范围如表1所示;对于供应商可靠性的评估值测算,本文采用J企业2017年5月第一周的数据作为原始数据测算,指标选取前文所提15个指标,决策群体为1000人次,使用MATLAB编程并调用YALMIP工具包进行求解,所得可靠性如表2所示,最后通过计算得到三个目标的理想解分别是40848、314662和4.1174。

表1 相关数据

表2 供应商可靠性
根据以上数据,通过调整ω1、ω2、ω3和应用CPLEX12.8求解可得表3,表中最右边3行的加粗数字为当前权重值下的最优值,否则为可行解(在内存不足的情况下仍求不出最优解),然后根据表3右边三行目标值画出图2-图5。在图2上,随着总时间值的增加,总成本的值呈现微降到平稳再上升的趋势,这是因为表3的情景18中,目标1和2的权重值为0,从而导致目标1和2的值迅速增加;在图3上,随着总时间值的增加,总可靠性的值呈现上升、平稳和下降后再上升的趋势,其中关键转折节点分别为表3的情景13(ω=(0.5,0.5,0))、情景12(ω=(0,1,0))和情景18(ω=(0,0,1)),企业决策者在决策时需注意此三种情况,另外观察到当ω1∈[0.3,0.4]∪[0.6,0.8]和ω3∈(0,1]ω3∈(0,1]时,总可靠性的值保持较高水平的平稳性且总时间的值最低;在图4上,随着总成本值的增加,总可靠性的值呈现上升、下降与上升后变为平稳的状态,其中关键转折节点分别为表3的情景12(ω=(0,1,0))、情景6(ω=(1,0,0)),企业决策者在决策时需注意此两种情况,另外观察到当ω2∈(0.5,0.8]和ω3∈(0,1]时,总可靠性的值也保持较高水平的平稳性且总成本的值较低,其中ω2取接近或等于0.6的值时可得最小总成本;观察图5可知,该权衡曲线呈现不规则的形态,说明三目标的冲突性较为明显,另外从图2-图4的图像和分析可得,当ω1∈(0.2,0.4)、ω2∈(0.6,0.8)和ω3∈(0,1]时(即图5中与成本和时间坐标较平行的线段部分),三个目标函数都能取得较好的值,说明在此既定权重取值范围内三个目标值冲突性得以缓和,即可靠性的权重取值对可靠性值的影响不明显,而在总时间的权重值取较小值和总成本的权重值取较大值时,总时间和总成本的值均能保持较低水平。
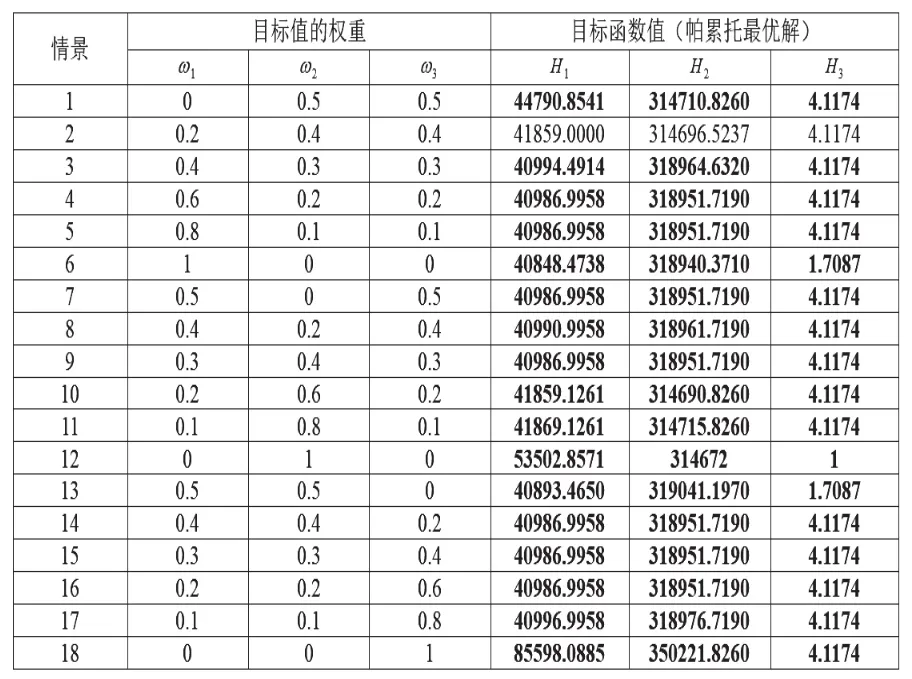
表3 不同权重下的求解结果
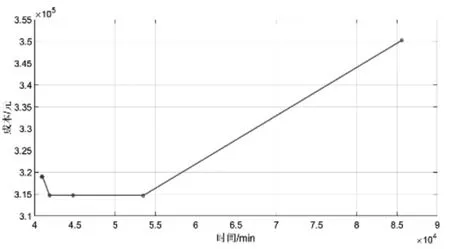
图2 目标函数1与目标函数2的权衡
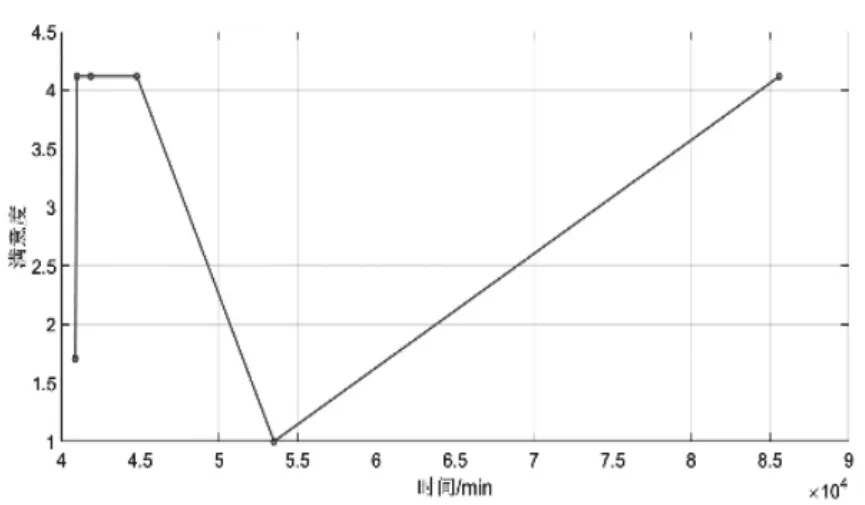
图3 目标函数1与目标函数3的权衡

图4 目标函数2与目标函数3的权衡
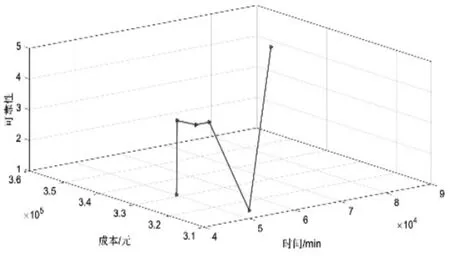
图5 目标函数1、2与目标函数3的权衡
此外,针对于不同权重下,即使三个目标值相同,所提模型的最优解或可行解都有所不同,说明零售企业管理人员在确定周计划后,每天的配送路径计划需根据当天的路况情况合理选择较优路线。为了探讨可靠性对越库配送网络的影响,以目标1为主要目标(越库配送网络的主要考虑因素为时间)给予限定值,将目标2和3转化为约束条件,可得如下模型M3:

通过改变λ的取值范围{315000,320000,360000}和θ的取值范围{0,1,1.7087,4.1174},可得模型M3的结果如表4,其中加粗数字为配送中心。在表4中,对于θ为0和1,在增加时供应商由选择4到选择3和4,而路径只是车辆和起点配送中心、终点配送中心略有变化以外,两条路径访问的门店顺序是一样的;对于θ为1.7087时,在λ增加时供应商由选择2和4变为选择3和4,并且路径都不尽相同;对于θ为4.1174时,在λ增加时供应商的选择保持不变,但路径都不尽相同。综合以上分析,可靠性要求的变化对于零售企业制定配送计划是有影响的。

表4 不同限定值下的结果
在实际应用中,通过应用本文方法,零售企业可根据上周的收货情况用于确定本周候选供应商的可靠性,同时在时间、成本和总可靠性的目标下,优化当周每天的供应商供货和零售企业配送方案。这样的良性循环,既可以督促供应商提高供货质量和及时交货,也可以加快货物越库作业的速度。
2.算例分析。在门店增加的时候,现存商业求解器的效率明显降低,比如前述节所提实际案例里,在表3情景2下求解所得结果是可行解,因此需要启发式算法求解。本文沿用表1和表5的数据生成规模不同的算例共9个,设置ω1=0.2、ω2=0.7和ω3=0.1,通过使用CPLEX和MA算法对9个算例进行求解得到表6,其中MA算法对每个算例各求解20次。在这9个规模算例中,MA所求得的函数值与CPLEX求得的精确解相差不大;当问题规模扩大到算例6时,CPLEX的求解时间已经超过一个小时,并且只能求出可行解,而MA仍可以在较短的时间内求得较优解;当问题规模扩大到算例7时,CPLEX已经出现内存不足的情况,而MA仍可在可接受的时间内求出近似最优解。由此可见,本文算法在求越库配送网络问题时具有求解时间较短兼求解结果较优的良好性能。
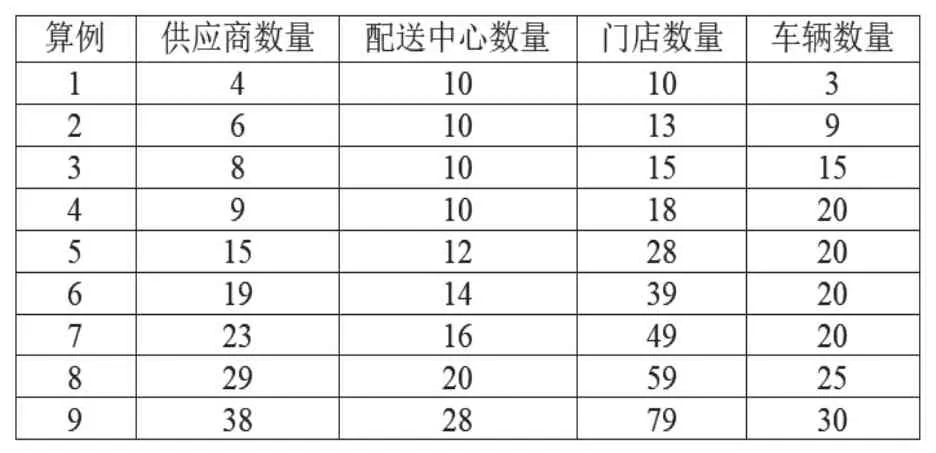
表5 算例规模(个)

表6 CPLEX与MA算法结果对比
