基于迁移学习的视频重构算法研究
2023-01-03陈海红
陈海红
(永州职业技术学院 信息工程学院,湖南 永州 425100)
随着高性能高清显示设备的发展,人们对高质量内容的需求也在增长。目前大多数的视频图像内容都是低质量的,在高清设备上渲染较低分辨率的内容会降低用户体验。[1~2]因此,如何提高视频分辨率以实现高清设备的显示需求是一个重要的研究课题。视频质量的改善不仅需要提高空间分辨率,同时也需要提高时间维度上的分辨率,大多数现有方法已经分别解决了视频空间超分辨率(VSR)和时间视频超分辨率(TSR)问题。而实现时空视频超分辨率的一个有效方案就是级联VSR模型和TSR模型,以从低分辨率、低帧率视频生成高分辨率、高帧率视频。然而,这种方法没有充分利用可用的时空信息,因此无法达到较好的效果。对此,有研究者研究了联合时空视频超分辨率的问题。然而,这些方法需要大量的低分辨率、高帧率数据集,并假设了从高帧率的视频帧中获取低帧率的视频帧的下采样内核是已知且固定的。本文利用元迁移学习技术,提出了一种新颖的超分辨率视频重构算法,旨在从低分辨率、低帧率视频生成高分辨率、高帧率视频。
一、视频重构算法设计
对于低分辨率、低帧率的视频,我们的目标是在盲超分辨率设置中生成高分辨率、高帧率视频,同时在测试时降尺度内核是未知的。用VLR=[L1,...,LL]表示低分辨率、低帧率视频,用VHR=[S1,...,SN]表示高分辨率、高帧率视频。本目标是将给定输入视频VLR的空间分辨率提高a倍,将时间分辨率提高b倍。本算法的框架如图1所示。
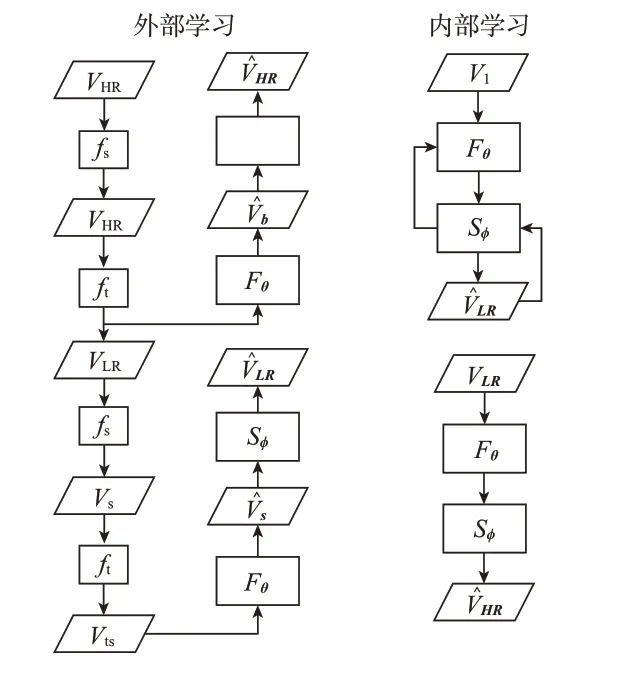
图1 算法框架
(一)外部学习
在大规模的预训练中,使用高质量的外部数据集DHR为元迁移学习提供warm start。由于具有不同降采样内核的超分辨率任务拥有相似的参数空间,大规模的训练有助于估计高分辨率、高帧率视频的natural priori。大规模的预训练也有利于稳定元学习算法MAML的训练过程。[3]外部学习的算法如算法1所示。
算法1外部学习
1:初始化参数θ,φ;
2:生成数据集Ds;
3:Loop until done:
4:从Ds中采样;
5:使用式(1)计算损失;
6:更新φ;
7:从Dt采样;
8:使用式(2)计算损失;
9:更换θ;
10:Loop until done:
11:从Dtr、Dte采样
12:For each Tido
13:使用式(4)计算损失;
14:根据式(5)(6)更新参数;
15:更新参数φ、θ;
16:根据式(8)(9)更新参数;
对于SSR模块,针对HR-HFR视频VHR使用bicubic spatial degradation来获得低分辨率、高帧率视频LR-HFR。视频VHR和形成合成数据集Ds。通过训练网络Sφ进行空间超分辨率任务,以实现视频帧和响应真实视频VHR帧之间l1重构损失的最小化。网络Sφ进行大规模训练的目标函数为:
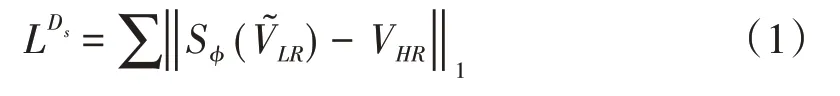
TSR模块用于增加低帧率视频的帧率。通过对帧进行插值,可以将帧率变为原来的2倍。但是,这种方法无法很好地捕捉时间的动态性。对此,借助时间维度中的patch recurrence来进行TSR模块Fθ的网络训练。定义一个时间profile生成器函数fr,该函数将视频作为输入,在时间维度中进行bi-cubic interpolation,并返回时间profile。选择了高帧率视频的alternate帧来生成低帧率视频。然后使用函数fr来生成时间profileV′LR。将数据VˉLR和V′LR作为训练TSR模块的数据集Dt。
TSR模块的损失函数被定义为:

动态任务生成器(DTG)使用diverse degradation设置为即时元训练生成任务。任务Ti是指空间下采样内核和时间sub-sampling。随机选择使用函数fs的anisotropic Gaussian内核进行4倍空间下采样,而使用函数ft进行时间子采样。
在元迁移学习的过程中,需要找到一组可迁移的初始化参数,使我们仅需要少量的迭代步数就可以将模型用于视频,以此实现较大的性能增益。对于时空视频超分辨率,使用元迁移学习策略来学习自适应的权重。使用外部数据集来进行元学习,并在元测试中使用内部学习。
在MAML元学习算法中,元学习器尝试在一个或多个梯度下降步中学习task-specific的最优参数。给定外部数据集DHR,获得一个由VLR、Vs和Vts组成的元任务训练批次Dtr。训练TSR模型Fθ来产生视频,该视频的时间分辨率是输入视频的两倍。SSR模型Fφ将TSR模型的输出作为输入,并重构低分辨率低帧率视频V^LR。这两个模型的输出为:

优化上述两个网络以在每次迭代ni中增加视频的分辨率。Task-specific训练的损失函数如下所示:

对于一个梯度更新,新获得的自适应参数θi和φi如下:

其中,α是学习率。
盲任务适应将模型的参数用于新的任务。元测试批次Dte是从DHR中采样得到的,Dte是由VHR、和VLR组成的。为了将模型用于新任务Ti,模型参数θ和φ将被优化来获得最小测试误差。盲任务适应的目标是:
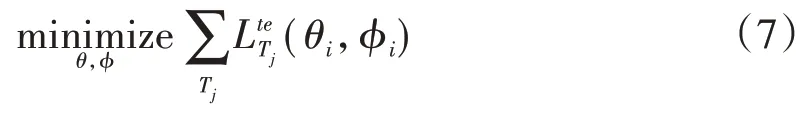
上述优化的参数更新规则如下所示:

其中,β是学习率。
(二)内部学习
算法2是本算法的内部学习和推断步骤。给定一个低分辨率、低帧率的视频,在空间上使用内核估计算法进行采样,[4]并从低分辨率、低帧率视频中选择alternate帧来生成VI。接下来,将VI作为输入进行梯度更新。这样一来,可以学习到给定视频的internal statistics,用于在推断步骤中生成高分辨率、高帧率的视频。内部学习的目标函数是:然后,使用该经过内部学习训练出来的模型进行推断。该模型的输入是VLR,输出是V^HR。
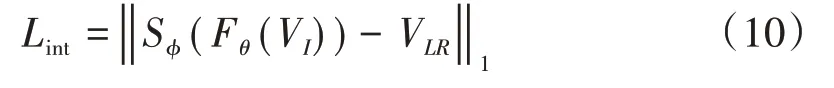
算法2内部学习
1:生成下采样视频VI;
2:For each step do
3:使用式(10)计算损失;
4:更新参数φ、θ
二、实验评估
1.使用公共数据集Vimeo-90K[5]和Vid64[6]来评估本算法。Vimeo-90K数据集含有91 707个短视频,每个视频有7个帧,每一帧的空间分辨率为448×256,使用该数据集进行预训练和元学习。Vid64数据集包含有4个视频序列,每个视频序列包含有30个帧,空间分辨率为720×480。
在PyTorch上实现了本算法。训练的批大小是32,使用ADAM优化器作为元迁移学习中的元优化器。Task-specific学习率α是0.01,适应学习率β是0.000 1。Task-specific训练的迭代次数为10次,内部学习的学习率γ是0.000 1。
将本算法与SConvIMDN、DAINIMDN、SConvSAN、DAINSAN、ZSM[7]和TempPro[8]进行对比,对比结果如表1所示。由结果可知,本算法的性能远远优于两阶段的算法(即SConvIMDN、DAINIMDN、SConvSAN、DAINSAN),而与ZSM和TempPro相比,本算法也略有优势。

表1 实验结果对比
考察算法的平均推断时间结果如图2所示。本算法可以以自适应的方式学习权重,能够很好地适应新任务,并在内部学习阶段中仅需要进行少量的梯度更新。因此,本算法具有最少的推断时间。
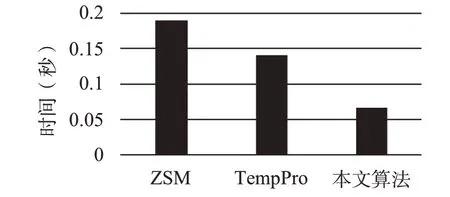
图2 推断时间对比
2.探讨TSR模块和SSR模块大规模训练所带来的好处。场景1是仅使用大规模训练所得到的预训练权重对SSR模块进行初始化,TSR模块则进行随机初始化。场景2是仅使用大规模训练所得到的预训练权重对TSR模块进行初始化,SSR模块则进行随机初始化。场景3是TSR模块和SSR模块均使用大规模训练所得到的预训练权重进行初始化。实验结果如表2所示。由结果可知,仅在TSR模块或SSR模块使用预训练权重都会降低本算法的性能。由此可知,大规模训练对本算法性能的提高是很重要的。

表2 大规模训练对算法的响应
三、结论
本研究提出了一个高分辨率视频重构算法,该算法结合外部和内部学习来实现超分辨率。外部学习使用元学习来学习自适应的网络参数,内部学习能捕捉下采样和degradation的底层统计特征。所提出的算法不仅具有较优秀的性能,还可以适应未知的测试模型。本文在通用数据集上进行评估实验,并将该算法与现有的算法进行对比。实验结果表明,该算法能够有效地提高重构视频的信噪比,能维持视频的结构并提高视频的质量。同时,该算法还极大地缩短了计算时间。
