基于改进DeeplabV3+的无人机影像土地利用分类
——以岳城水库附近居民区为研究区
2023-01-02刘粉粉王贺封张安兵李家驹马鹏飞
刘粉粉,王贺封,张安兵,李家驹,马鹏飞
(1.河北工程大学地球科学与工程学院;2.河北工程大学矿业与测绘工程学院;3.邯郸市自然资源空间信息重点实验室,河北邯郸 056038)
0 引言
随着社会经济快速发展和城市化进程不断加快,我国土地利用状况不断发生改变[1]。掌握实时可靠的土地利用变化信息,对科学的土地利用规划具有重要现实意义。在土地利用变化研究数据获取方面,目前常采用遥感卫星方式,该方式适用于大区域、多时相地面信息监测,但由于卫星传感器数据采集受时间、空间分辨率及数据质量限制,往往无法及时、精细获取指定区域用地变化信息。近年来,无人机(Unmanned Aerial Vehicle,UAV)低空技术快速发展,因其易操作、成本低、获取数据快、分辨率高等特点,逐渐被应用于土地利用分类、精准农业和国土资源监测等领域,成为获取高分辨影像的重要手段之一[2-3]。在信息提取模型研究方面,基于影像数据的土地分类方法逐渐发展成熟[4-5],主要包括监督分类、非监督分类两大类型,最大似然法、人工神经网络、支持向量机等不同的分类模型,在土地利用、国土监测、植被覆盖变化等多个领域取得了较好应用效果[6-8]。
近年来,随着深度学习的快速发展,语义分割技术的出现为高分辨率影像分类提供了新的更优的解决思路[9]。Long 等[10]提出全卷积神经网络(Fully Convolutional Networks,FCN),该模型使用反卷积层替代全连接层,将语义分割精度推向新的高度。Ronnenerger 等[11]提出用于医学影像分割的U-net 模型,该模型一经问世就在医学影像领域取得显著效果。Chen 等[12-15]提出Deeplab 系列语义分割模型,先后采用条件随机场(Conditional Random Field,CRF)、金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP),在保证不改变分辨率的条件下扩大感受野,提高了分割目标的边界效果。DeeplabV3+将编码器—解码器(Encoder-Dncoder)结构与ASPP 相结合,在多个公开图像数据集上取得较好分割效果,成为当前综合性能优秀的语义分割算法之一。但该模型是由DeeplabV1-3 发展而来,继承了DeeplabV1-3模型的一些缺陷,如模型复杂、训练速度慢、分割精度低等。针对上述问题,学者们进行了相关研究。刘文萍等[16]提出基于改进的DeeplabV3+模型进行无人机影像土地利用分类,结果表明该方法有较好的分类精度。孟俊熙等[17]以DeeplabV3+为基础构建了N-DeeplabV3+模型,结果表明改进后的模型有效提高了小尺度目标的关注度,缓解了目标误分及分割不完全问题,提高了分割精度。王红军等[18]提出一种基于SENet 优化后的DeeplabV3+淡水鱼头、腹、鳍的语义分割算法,实验发现改进后的网络有效克服了细节信息丢失问题,达到了准确定位目的。但由于上述研究主要针对DeeplabV3+模型的某一缺陷进行改进,未能从全局性对网络进行统一改进,因此细节信息丢失、分割不完全及参数量大等问题仍然十分突出。
基于此,本文以DeeplabV3+网络为基础,提出应用MobileNetV2 替换原始DeeplabV3+模型的主干特征提取网络的思路,并将CA 注意力加入MobileNetV2 网络,发挥各模块算法优势,以期增强位置信息和空间信息的关系,在保证模型分割精度的同时,大幅度减少模型参数量,降低模型复杂度,提高模型计算速度。
1 相关网络基础
1.1 DeeplabV3+网络结构
DeeplabV3+是谷歌公司在DeeplabV1-3 基础上将金字塔池化模块(ASPP)与编码器—解码器结构相结合而提出的一种新的语义分割模型,是现阶段最优秀的语义分割算法之一[13]。DeeplabV3+网络以DeeplabV3 作为编码器(Encoder),同时又添加解码器(Decoder),该模型采用ResNet101[19]作为主干特征提取网络,后连接带空洞卷积(Atrous Convolution)的金字塔池化模块(ASPP)进行多尺度信息提取。ASPP 模块包括一个1×1 卷积、3 个采用不同空洞率(分别为6、12、18)的3×3 空洞卷积和一个全局平均池化操作,在减少下采样操作和不增加网络参数的基础上保证了空间分辨率,增大了感受野,获取多尺度信息并进行特征融合以更好地实现对多尺度目标分割;然后通过1×1 卷积对通道进行降维处理并将降维后的特征图利用双线性插值方法进行4 倍上采样后传入Dncoder 中,在Dncoder内与主干特征提取网络提取的低层次特征融合,恢复目标的边界信息;最后利用3×3 卷积恢复空间信息和4 倍双线性插值上采样获取图像的语义分割结果。通过实验发现,使用DeeplabV3+网络对无人机影像进行分割,存在边缘粗糙、分割不完全等问题。
1.2 改进的DeeplaV3+网络
1.3 MobileNetV2
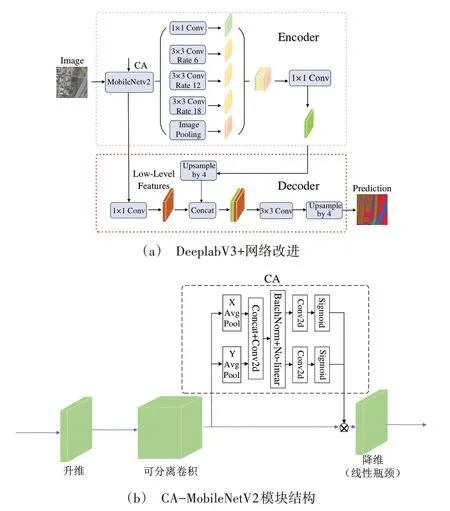
Fig.1 Improved DeeplabV3+network图1 改进的DeeplabV3+网络
MobileNetV1 是谷歌公司推出的一种轻量级计算机视觉神经网络,与其他网络模型相比,该网络降低了模型参数量,这一优势得益于该网络采用了深度可分离卷积(Depthwise separable convolution)[21]。深度可分离卷积是一种分步式卷积,第一层为通道卷积:对每个输入通道应用单通道的轻量级滤波器;第二层称为逐点卷积:负责计算输入通道的线性组合,构建新特征。MobileNetV2 是在MobileNetV1 网络基础上改进而来,MobileNetV1 网络主要思想是将深度可分离卷积进行堆叠,而MobileNetV2 中除了继续使用可分离卷积结构外,还做了线性瓶颈和反向残差改进。反向残差[22]结构先通过扩展层扩展维度,再使用深度可分离卷积提取特征,最后使用投影层压缩数据,使网络重新变小,整个网络中间胖、两头窄,呈沙漏形状。反向残差结构由原始的先做深度卷积再做点卷积变为先做点卷积再做深度卷积,最后再做一次点卷积的运算方式,这种操作使得网络能够较好地提取信息且不会增加过多计算量。线性瓶颈是用在反残差块最后一次点卷积中,使用线性卷积代替原始卷积与ReLU 函数的组合,有助于信息保留,并且将通道卷积和点卷积的激活函数也调整为ReLU6。
1.4 注意力机制模型
近年来,注意力机制被广泛应用于深度学习的各个方面,尤其是在图像分割和目标识别领域。一般认为,特征图的每个通道都同等重要,并没有区分各通道的优先级和重要程度。SENet[23]注意力机制通过对不同的通道赋予不同的权重,达到对重要特征进行强化学习的目的,但SENet在赋予通道权重时忽略了位置信息,而位置信息对空间选择性的Attention Map 十分重要。为此,本文选择了CA(Coordinate Attention)注意力机制,它不仅考虑了通道之间的关系,还考虑了特征空间的位置信息。
CA[24]是一种具有轻量级属性的注意力方法,它有效捕获了位置信息和通道信息的关系。CA 可以被看作一个旨在增强网络学习特征表达力的计量单位,它可以对网络中的任意特征向量X=[x1,x2,.....,xc] ∈RH×W×C进行转化变换,输出与X 大小相同的具有增强表示的变换张量Y=[y1,y2,......,yc] ∈RH×W×C。CA 注意力通过精确的位置信息对通道关系和长期依赖性进行编码,其具体操作可分为Coordinate 信息嵌入和Coordinate Attention 生成。为了获取图像宽度和高度上的注意力并对精确位置信息进行编码,分别从宽度和高度两个方向上对特征图进行加强,获得两个方向上的特征图。Coordinate Attention 结构如图2所示。
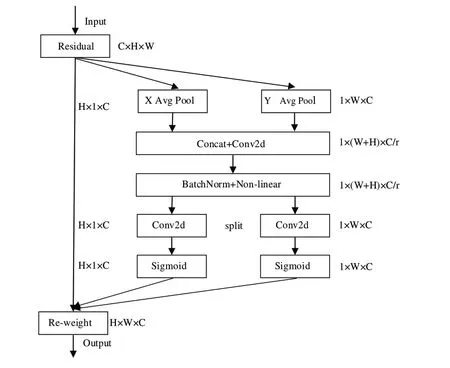
Fig.2 Structure of Coordinate Attention图2 Coordinate Attention结构
(1)Coordinate 信息嵌入。为了获取图像宽度和高度上的注意力并对精确位置信息进行编码,先将输入特征图分别按照宽度和高度两个方向分别进行全局平局池化,分别获得在宽度和高度两个方向上的特征图。具体而言,给定输入X,首先采用(H,1)和(1,W)的池化核分别沿着水平和垂直方向对每个通道进行编码操作。因此,第c通道的高度为h的输出可以表示为:
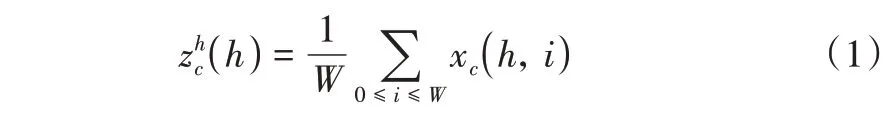
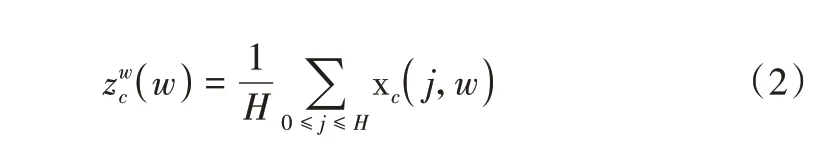
在进行照片创意时,她最为在意的是最终成品的可控性与操作性——“是”与“像”之间、真实与人造之间的矛盾。斯各格兰德认为,向自然意象转型寻求灵感,这一点似乎深深根植于美国文化中。
上述两种变换分别从两个空间方向对特征进行聚合,得到一对方向感知特征图。这与SENet中产生单一特征向量的SE block不同。这两种转换允许注意力模块捕捉沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,有助于模型更好地定位感兴趣目标。
(2)Coordinate Attention 生成。通过式(1)、式(2),可以很好地获得全局感受野并对精确位置信息进行编码。为了利用由此产生的特征,通过信息嵌入中的变换后,将式(1)和式(2)产生的聚合特征图进行拼接操作,然后使用1×1 卷积变换函数F1对其进行变换操作,此过程称为Coordinate Attention 生成。
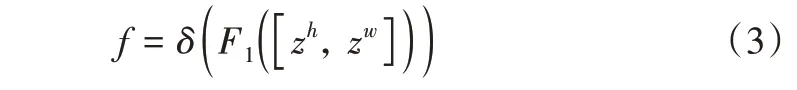
其中,[]是沿空间维度的拼接操作,δ为非线性激活函数,f∈RC/r×(H+W)是在水平方向和垂直方向对空间信息进行编码的中间特征图,r是用来控制SE block 大小的缩减率。沿着空间维度将f分解为2 个独立的张量f h∈RC/r×H和f w∈RC/r×W,再利用另外两个1×1 卷积变换Fh和Fw分别将fh和fw变换为具有相同通道数的张量到输入X,得到:
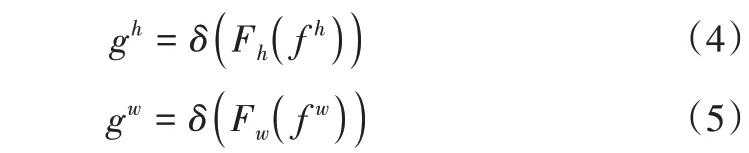
其中,δ是Sigmoid 激活函数。为了降低模型复杂性和计算开销,通常使用适当的缩减比r来缩小f的通道数,然后对输出gh和gw进行扩展,分别作为注意力权重。最后Coordinate Attention 块的输出Y=[y1,y2,...yc]可以写成:
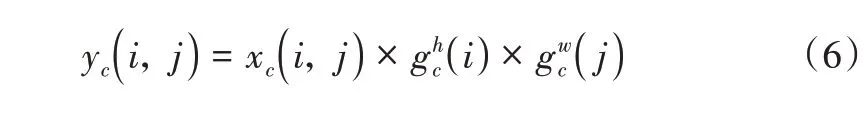
2 实验与分析
2.1 数据采集与实验数据集构建
本次实验的研究区为岳城水库附近的居民区,位于河北省磁县,其地理坐标位于114.07°~114.22°E、36.25°~36.35°N 之间,如图3所示,考虑到地物类型丰富程度,经数据筛选处理后,在研究区内选取3 块地物类型不尽相同的实验区。
采用型号为安尔康姆“md4-1000”四旋翼无人机,搭载索尼“A6000”相机进行数据采集;使用mdCockpit3.5 软件进行航线设计,无人机飞行高度为150~200 m,航向重叠率度为80%,旁向重叠度为70%,布设像控点并进行测量;在确保天气和启航条件满足要求时进行外业航摄;基于获取的无人机照片、pos 信息及像控点坐标,采用Pix4DMapper软件进行数据处理,得到研究区域正射影像。
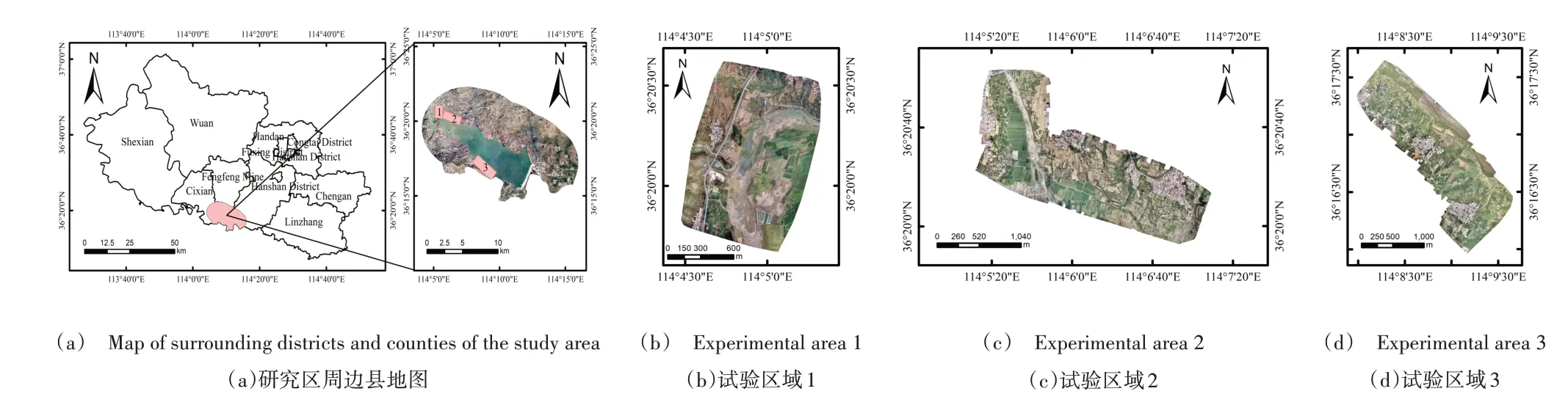
Fig.3 Schematic diagram of the study area图3 研究区域示意图
考虑到计算机负荷及训练时间,参考公共遥感数据集,对无人机影像进行重采样。为了快速制作出符合实验要求的切片,借助相关软件进行快速裁剪,将无人机影像裁剪为512 pixel×512 pixel,并将原始图像按7∶3 随机分为训练集和测试集。结合目视解译和实地调查,利用EISeg软件对无人机数据集进行标注,如图4 土地利用分类标注示例,制作成满足训练条件的岳城水库居民区土地利用分类信息数据集。数据集共包含建筑物、水体、道路、农业用地、林地、其他用地等6 种类型,各用地类型所占像素百分比分别为24%、1%、9%、31%、28%和7%。为了得到泛化能力更强的模型,提高分类精度,防止因数据集过小而导致的过拟合问题,本文模型及对比模型均采用五折交叉验证的方式,最后使用测试集对最优模型进行测试。采取随机旋转、平移、模糊、加噪等方法对训练集进行增强,增强后的图片共有1 521 张,其中训练集1 400 张,测试集121张。
2.2 实验过程
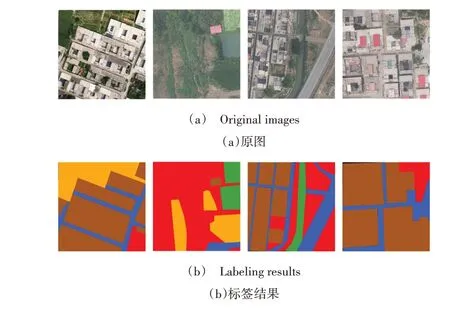
Fig.4 Schematic diagram of land use classification annotation图4 土地利用分类标注示示意图
实验环境为64 位Windows 操作系统,CPU 为Intel Core i7-9700K,内存为3.6GHz @128G,显卡为RTX 2080Ti 12G,硬盘为Samsung SSD 2TB,使用的深度学习框架为Pytorch。训练过程中设置批大小(batch_size)为6,迭代次数为300 个周期(epoch),学习率初始化为0.000 5,weight_decay 为0.000 1,使用Adam 优化器进行迭代更新参数,Adam可动态调节学习率,使学习率更贴近当前参数更新状态,从而让模型更好地收敛。
2.3 模型评价指标
为了衡量网络性能,采用像素准确度(Pixel Accuracy,PA)、平均像素准确率(Mean Pixel Accuracy,MPA)、交并比(Intersection over Union,IoU)和平均交并比(mean Intersection over Union,mIoU)作为图像语义分割性能的评价指标。其中,PA 表示预测正确的像素点与总像素点的比值,MPA表示计算每个类被正确分类的像素总数与每个类别总数比率求和得到的均值,其计算公式分别为:
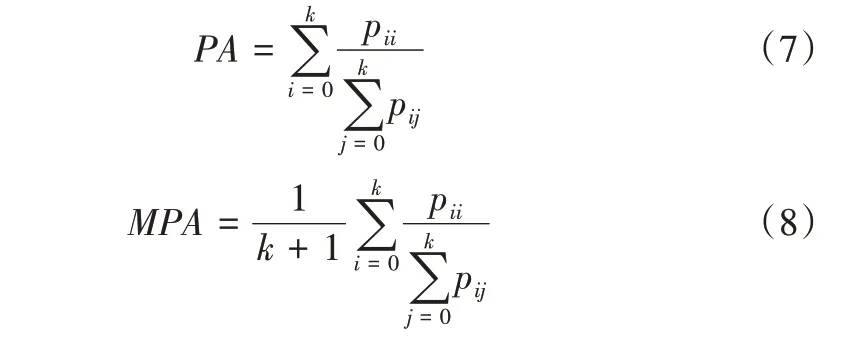
作为语义分割性能的评价指标,IoU 是衡量模型性能的常用评价指标,交并比用于计算某一类别真实值和预测值两个集合的交集与并集的比值;mIoU 是对IoU 的进一步提升,为计算得到的每个类别IoU 的平均值,其计算公式分别为:
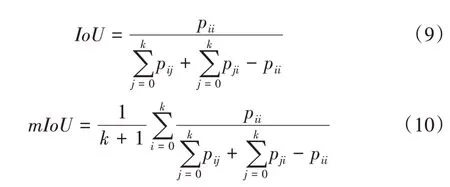
其中,k表示标签的类别;k+1 表示包含空类或背景的总类别;pij表示本属于i类但预测为j类的像素点总数;pii表示真正例,即模型预测为正例,实际为正例;pij表示假正例,即模型预测为正例,实际为反例;pji表示本属于j类但预测为i类的像素点总数。mIoU 的值越大,说明预测的分割结果越准确。
2.4 实验过程
2.4.1 网络验证实验
为了验证轻量级MobileNeV2 网络在DeeplabV3+模型中的匹配性和表现效果,分别采用ResNet101 和Mobile-NetV2 作为DeeplabV3+模型的特征骨干提取网络(MN_DeeplabV3+)在岳城水库数据集上进行比较实验,以mIoU、MPA、模型参数量作为评价指标,实验结果如表1 所示。采用ResNet101 作为DeeplabV3+模型的特征骨干提取网络,评价指标mIoU 为65.10%,MPA 为76.31%,参数量为226.38MB,而将DeeplabV3+的主干特征提取网络替换成MobileNetV2 后,mIoU 为66.31%,MPA 为78.28%,参数量为22.90MB。结果表明,替换主干特征提取网络后的模型,分割平均像素准确率和平均交并比均比采用Resnet101 网络略有提升,同时模型参数量相比于原始DeeplabV3+模型呈现大幅度减少。因此,使用MobileNetV2 作为主干特征提取网络具有一定优势,不仅提高了模型分割精度和速度,而且参数量仅为原始网络的1/10,降低203.48MB。
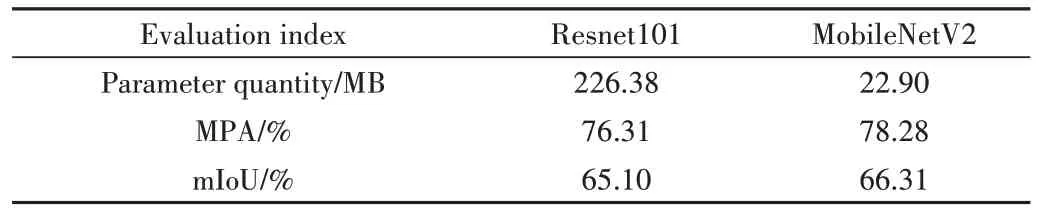
Table 1 Comparison results of different trunk feature extraction networks表1 不同主干特征提取网络比较结果
2.4.2 模型比较实验与分析
为了验证CA 注意力机制的有效性,在保持实验环境和数据集不变的条件下,将加入CA 注意力机制的MN_DeeplabV3+模型(MNCA_DeeplabV3+)与DeeplabV3+、SE_DeeplabV3+、MN_DeeplabV3+进行实验比较。由表2 可知,在平均交并比方面(mIoU),传统DeeplabV3+模型的平均交并比为65.10%,SE_DeeplabV3+的平均交并比为66.46%,MN_DeeplabV3+的平均交并比为66.31%,而MNCA_DeeplabV3+的平均交并比为70.36%,较传统的DeeplabV3+算法、SE_DeeplabV3+、MN_DeeplabV3+模型分别提高5.26 个百分点、3.9 个百分点、4.05 个百分点;在平均像素准确度方面(MPA),传统DeeplabV3+模型的平均像素准确度为76.31%,SE_DeeplabV3+的平均像素准确度为77.45%,MN_DeeplabV3+的平均像素准确度为78.28%,而MNCA_DeeplabV3+的平均像素准确度为80.41%,较传统的DeeplabV3+模型、MN_DeeplabV3+模型分别提高4.10 个百分点、2.96 个百分点、2.13 个百分点。此外,从不同用地类别的分割精度看(见表2),4 种网络对于建筑物、农业用地、林地等用地类型均具有较高的分割精度。原因在于,这几种用地类型目标在数据集中所占像素比例较高,能够取得较好的分割精度,而其他用地类型,所占像素比例较小,且语义特征不明显,分割精度相对较低。实验数据表明,在MNCA_DeeplabV3+加入CA 注意力机制提高了模型的特征提取能力,对地物的分割精度更高。

Table 2 IoU and PA results of different land use classification表2 不同用地类别的IoU和PA结果
在常见的图像语义分割模型中,一般模型层数越多,模型涉及参数量越大,模型越复杂,模型训练难度就越大。由表3 可知,相较于传统DeeplabV3+模型,MNCA_DeeplabV3+模型参数量降低202.5MB,仅为传统模型的1/10;相较于SE_DeeplabV3+模型降低185.42MB;相较于MN_DeeplabV3+模型虽然有所增加,但仅为0.98MB,这是由于加入CA 注意力,分割效率受到影响。综合分析可知,同时兼顾分割精度和分割效率的模型改进难度较大,MNCA_DeeplabV3+模型以较小的检测速度为代价,换来分割精度的显著提升,较好地平衡了分割精度和效率,体现了该模型的优越性。
为了验证改进模型的优越性,将相同的测试图片传入到训练好的不同模型中,得到各模型分割结果如图5所示。
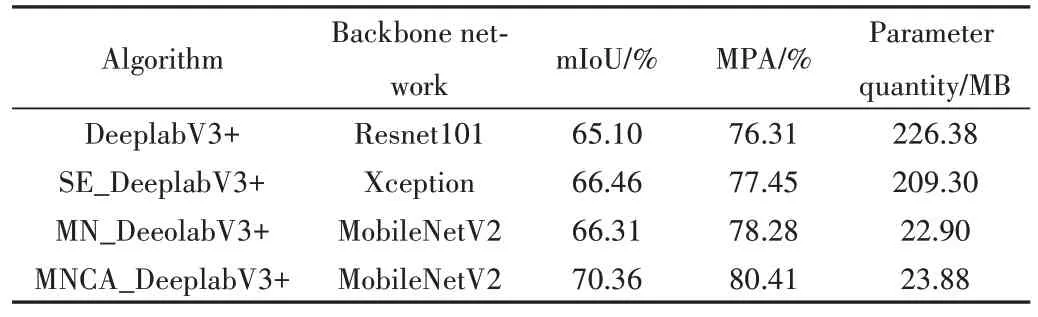
Table 3 Comparative experimental results of different models表3 不同模型比较实验结果
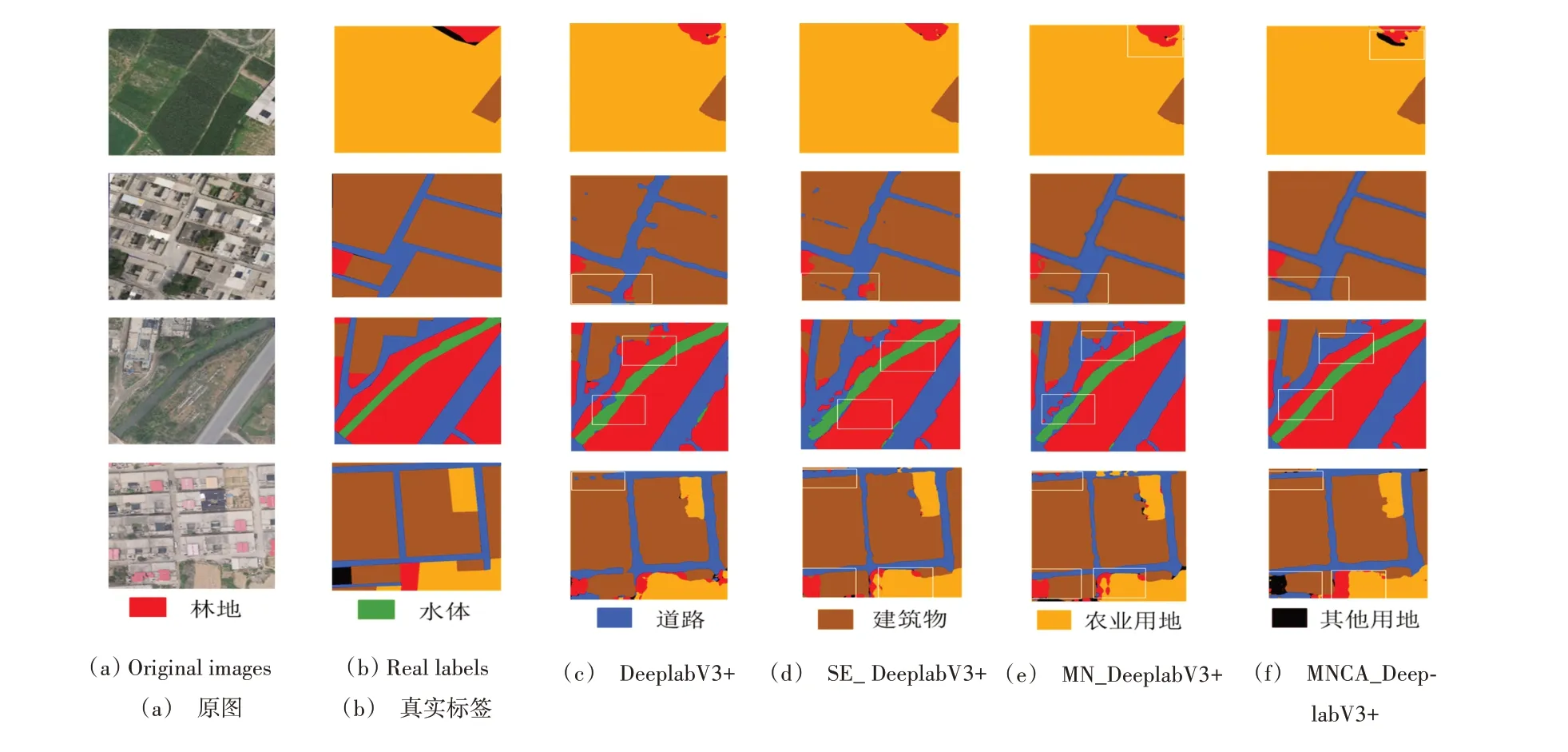
Fig.5 Segmentation and comparison of different network models图5 不同网络模型分割比较
比较第一行和第四行图片,DeeplabV3+、SE_ DeeplabV3+和MN_DeeplabV3+对林地和其他用地分割效果较差,不能真实地反映地物类型,其他用地被错分为林地,林地被错分为农业用地;相比较而言,MNCA_DeeplabV3+模型分割结果未出现上述不足,分割效果有所提高,预测结果更加准确。对于用地类别较少的图像(第1 行),4 种网络分割效果差异较小,但对于含有地物类别比较丰富的图像,以上4 种网络差异比较明显。对比第2、3、4 行发现,对于地物类别比较丰富的图像,DeeplabV3+模型分割结果最差,道路和建筑物误分现象严重,存在严重的道路分割不连续现象,林地和水体也出现少数错分现象;MC_DeeplabV3+、SE_ DeeplabV3+模型虽然提高了模型分割精度,改善了错分及道路分割不连续问题,但效果并不理想,农业用地和林地仍存在误分或分割不完全现象且有明显毛边问题;MNCA_DeeplabV3+网络的分割效果明显优于其他3 个网络,该网络对土地利用类型的分割更加精确,能准确识别出图像细节信息,边缘预测更为清晰,主要表现在道路不连续现象较少,建筑物轮廓相对规则,误分和不完全分割现象相对较少。实验结果表明,以上4 种模型在分割水体和建筑物方面均表现出优越的性能,并且对于类别越少的影像其性能越突出;但对于用地类型较多的影像,MNCA_DeeplabV3+网络更具有优越性和有效性,能较好地识别真实的用地类型。此外,MNCA_DeeplabV3+模型在降低模型参数量的同时有效解决了道路断连和分割不完全等问题,细化了目标地物的边界,提高了目标地物的分割精度,具有更好的地物辨别能力。
3 研究结论
为了降低模型的参数量、提高地物分类精度和提取效果,本文以DeeplabV3+模型为基础,提出了一种改进的轻量级网络模型MNCA_DeeplabV3+,并在自制无人机数据集上进行对比实验,结果表明:
(1)MNCA_DeeplabV3+模型采用MobilenetV2 作为主干特征提取网络,在很大程度上降低模型参数量,提高了模型计算速度;CA 注意力机制加入MobilenetV2 网络提升了捕获空间位置信息能力。通过模型比较实验表明,注意力机制可以改善模型中存在的分割不完全、道路断连、边缘细节丢失等问题,进一步验证了MNCA_DeeplabV3+模型优越性。
(2)与原始网络相比,MNCA_DeeplabV3+在选定区域无人机数据信息提取方面表现良好,mIoU、MPA 分别达到70.36%,80.41%,且模型参数量降至原始网络的1/10。实验结果证实,改进后的MNCA_DeeplabV3+模型对该数据集具有一定的适用性。
语义分割被广泛应用于国土监测、精准农业等多个领域,进行诸如建筑物、道路提取、土地利用分类等工作。从实验流程和实验结果看,本文仍存在以下问题需深入研究:①无人机数据集标注工作量大,耗时耗力,后续将研究采用无监督学习等方法解决数据集标注问题;②本文实验区为高密度人类活动区,考虑人工标注成本和无人机航线多等问题,实验时仅选取地物类型较丰富的3 块实验区进行土地利用分类研究,代表性不足,未来将进一步丰富无人机影像数据集,测试MNCA_DeeplabV3+模型在完整区域的土地利用分类结果。
