自定义目标检测数据集的收集与半自动标注
2023-01-02邓庆昌
邓庆昌,程 科
(江苏科技大学计算机学院,江苏镇江 212000)
0 引言
目标检测是计算机视觉和数字图像处理领域的热门研究方向,其可在给定图像中精确定位属于特定类别的对象,并为每个对象分配相应的类别标签,采用边界框标识出其位置,目前已广泛应用于人脸检测[1-2]、安全帽佩戴检测[3-6]、口罩佩戴检测[7-8]、烟火检测[9]等领域。
目标检测研究中使用的数据集包括公共数据集、自定义数据集以及公共数据集与自定义数据集混合的数据集。例如,张达为等[10]使用长沙理工大学中国交通标志检测数据集CCTSDB 研究实时交通标志检测方法;候少麒等[11]建立了基于空洞卷积金字塔网络的目标检测算法,并采用公共数据集VOC2007 和VOC2012 进行了性能评价。公共数据集使用方便、效果好,但无法满足一些细化场景的需求,此时需要创建自定义数据集。例如徐涛等[12]研究机坪工作人员反光背心检测问题时尚未有对应的公开数据集,其通过拍摄得到图片数据并采用人工标注得到自定义数据集;张永亮等[13]在进行交通标志检测时通过相机实地拍摄大量真实道路场景和交通标志获取图片数据;马永刚等[14]通过车载视觉传感器采集了10 000 帧有轨电车运行视频中的图片数据用于有轨电车在途障碍物检测。在自定义目标检测数据集的构建过程中,数据的采集和标注多采用全人工方式,没有相似图片处理和无用图片清理等中间处理说明。
随着目标检测领域的逐渐细化,公共数据集已难以满足实际需要,制作符合个性化研究需求的数据集十分必要。然而,制作目标检测数据集一方面需要获取大量图片数据,另一方面需要对图片数据进行标注,表明相应位置是否含有物体并明确其类别,如果均采用人工实现将花费大量时间和精力。为此,本文以创建自定义安全帽佩戴检测数据集为例,设计一种自定义目标检测数据集的收集与半自动标注方法,通过Scrapy 爬取和OpenCV 库获取视频帧的方式得到图片数据,使用训练好的目标检测模型生成标注文件,并通过人工修正得到最终数据集,避免了大量人工过滤不良数据的操作。
1 基础技术
1.1 Scrapy
Scrapy 是适用于Python 语言的一个快速、高层次的屏幕抓取和Web 抓取框架,用于抓取Web 站点并从页面中提取结构化数据[15-18]。Scrapy 集成了网页请求、下载机制和重试机制等内容,使爬虫工作者从大量重复操作中解放出来,专注于网页爬取规则的编写,用户只需定制开发若干个模块便可轻松实现爬虫操作,通过少量代码完成大量工作。
Scrapy 的框架如图1 所示,包含引擎(Engine)、物品(Item)、管道(Pipeline)、下载器(Downloader)、爬虫(Spider)和调度器(Scheduler)等组件。其中Engine 负责除Item外其他模块的通讯和数据传递等;Item 为数据存储的对象,可以定义不同属性;Pipeline 负责处理Spider 返回的Item 对象,并可以对Item 对象进行进一步处理;Downloader负责下载Engine 发送的所有Requests 请求结果,并将获取到的响应交还给Engine;Spider 负责发起Request 请求,接受Engine 返回的响应并对其进行解析,提取所需信息并交给Item 对象,还可以获取下一页的链接进行递归爬取;Scheduler 负责接收Engine 发送过来的Request 请求,并按照一定的方式进行整理排列,当Engine 需要使用Request请求时返还给Engine。
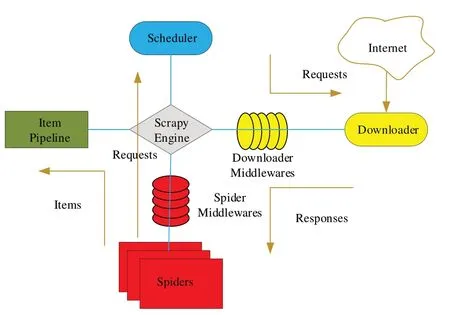
Fig.1 Framework of Scrapy图1 Scrapy框架
1.2 JSON
JSON(JavaScript Object Notation)是一种轻量级数据交换格式,便于人们阅读和编写,同时也易于机器解析和生成。JSON 采用完全独立于语言的文本格式,但也延续了类似于C 语言家族(包括C、C++、C#、Java、JavaScript、Perl,Python 等)的习惯,这些特性使得JSON 成为理想的数据交换语言。在网页中使用JSON 作为数据包传输格式时效率很高,相较于XML 数据格式拥有更高的有效数据量[19]。
1.3 OpenCV
OpenCV 是一个基于BSD(Berkly Software Distribution)许可发行的跨平台计算机视觉和机器学习软件库,实现了计算机视觉和图像处理方面的很多通用算法。OpenCV 的应用领域非常广泛,包括图像拼接、图像降噪、产品质检、人机交互、人脸识别、动作识别、动作跟踪等[20-21]。OpenCV 还提供了机器学习模块,用户可以使用正态贝叶斯、K 最近邻、支持向量机、决策树、随机森林、人工神经网络等机器学习算法。
2 总体设计
目标检测数据集的收集与半自动标注方法总体设计流程见图2。该流程适用于大多数目标检测任务,本文以创建安全帽佩戴检测数据集为例实现整个流程。
2.1 图片数据收集
自定义目标检测数据集的一个来源是网络爬虫爬取,通常可以通过搜索引擎(如百度、必应和谷歌)搜索相应的关键词,然后分析页面,确定一定规则以爬取图片链接并进行下载;另一个来源是通过视频获取,如对现场拍摄或网络下载的视频进行逐帧处理可得到所需图片数据。爬虫爬取的文件可能存在相同和相似图片,且视频获取的相邻帧图片之间相似度极大,因此设计去重模块检测图片之间的相似度,仅保留相似图片中的一张。
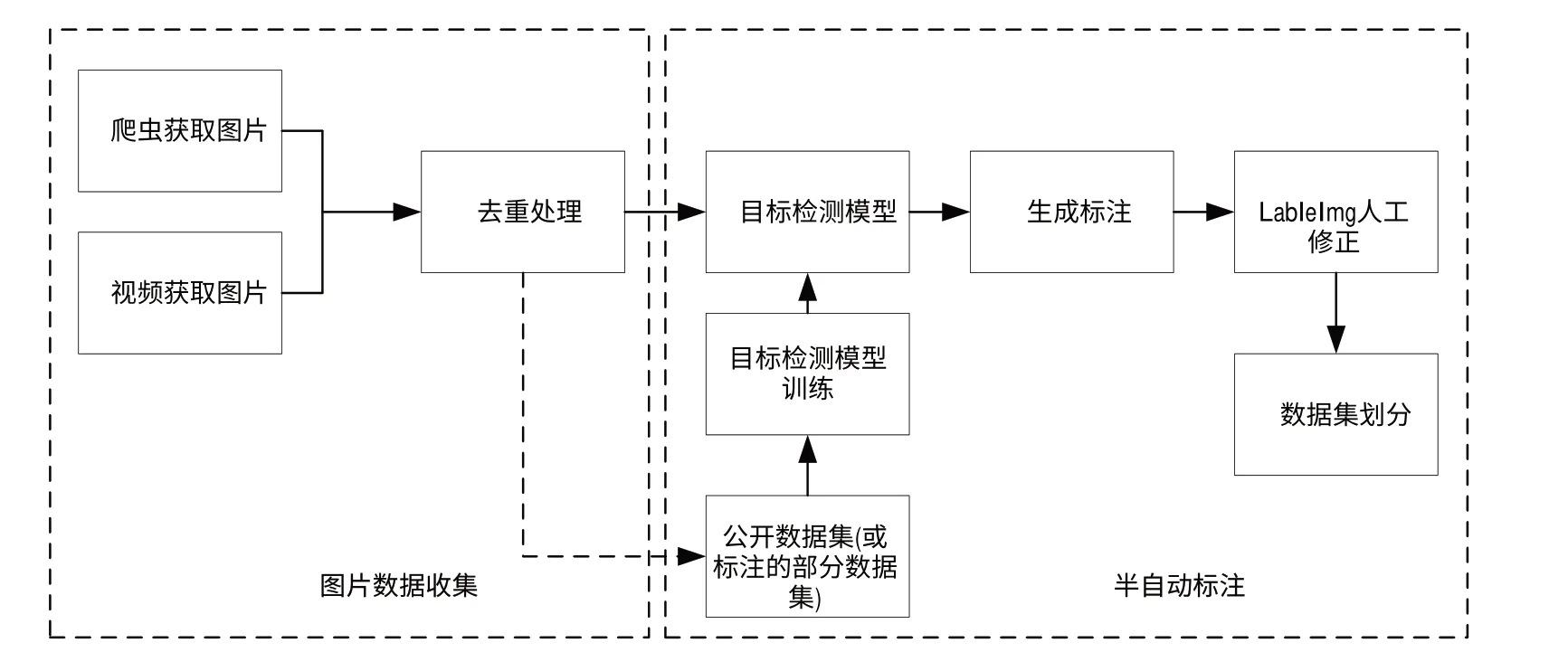
Fig.2 Overall design process图2 总体设计流程
2.2 半自动标注
收集到的图片数据需要经过标注后才可以在目标检测模型中进行训练,然而图片数量庞大,纯人工标注将耗费大量时间,因此本文设计了半自动标注方法。半自动标注主要通过某个目标检测网络训练部分已经标注好的数据集,如果有相符的公共数据集可直接用于模型训练,否则就要先对收集到的部分图片进行标注,然后通过训练好的模型预测自行收集的图片数据,得到预测的标注框和类别信息,并使用这些信息生成对应的标注文件。生成的标注文件会存在误标注的情况,需要人工进行更正和排除,因此称为半自动标注方法。
3 实现方法
3.1 基于Scrapy爬取图片
3.1.1 Item数据定义
Scrapy 框架爬取图片需要Item 对象具有image_urls 属性,如果另行设置images 属性,图片下载得到的信息便会保存到这个属性中,包括是否下载成功和下载位置等信息。本文使用的Item 定义为:

3.1.2 数据爬取
通过百度图片搜索关键词的方法获取图片url,通过百度图片搜索的JSON 接口(https://image.baidu.com/search/acjson)发起请求,请求url实例如下:

其中,word 表示搜索的关键词;pn 表示从第几张图片
开始;rn表示搜索返回的图片数量。
返回的JSON 数据示例为:

可以从返回的JSON 数据中获取所有的middleURL 作为Item 对象的image_urls,解析获取的JSON 数据流程为:

3.1.3 配置图片下载和存储
通过配置settings.py 的ITEM_PIPELINES 可指定使用ImagebaiduspiderPipeline 作为图片的下载通道,并设置IMAGES_STORE 指定图片下载的文件夹全路径,设置RETRY_TIMES 指定下载失败的重试次数。本文实验使用的部分配置为:


3.2 视频逐帧获取图片
通过Python 和OpenCV 可以获取视频的逐帧图片,流程如图3 所示。一个视频通过OpenCV 读取后可以循环获取每一帧图片,由于视频帧数量大,且相邻帧一般变化不大,因此设置skip 参数,代表每隔skip 数量的视频帧取一帧保存。获取视频帧的部分代码如下:



Fig.3 Flow of getting pictures frame by frame from video图3 视频逐帧获取图片流程
3.3 图片去重
通过比较图片之间的相似度可以排除一些重复和相似的图片。遍历两张图片的所有像素并作差以判断图片是否相同的方法虽然速度快,但太过严格,一旦仅有一个像素不同便会判断图片不相同,因此只能用于排除重复图片,不能用于排除相似图片。本文通过直方图比较的方式判别图片的相似度,原理是获取被比较图片的直方图数据并进行归一化,比较归一化后的数据得到相似指数,通过设定相似指数阈值判断两张图片是否相似。
通过Python 和OpenCV 计算相似度的代码为:

本文实验相似指数阈值设置为0.99,去重前后图片数量比较见图4(彩图扫OSID 码可见,下同)。通过Scrapy 爬取1 477 张图片,通过24 个视频逐帧获取21 069 张图片,共收集到22 546 张图,去重后得到17 493 张图片,保存于文件夹D:/predata/helmet_img 下。
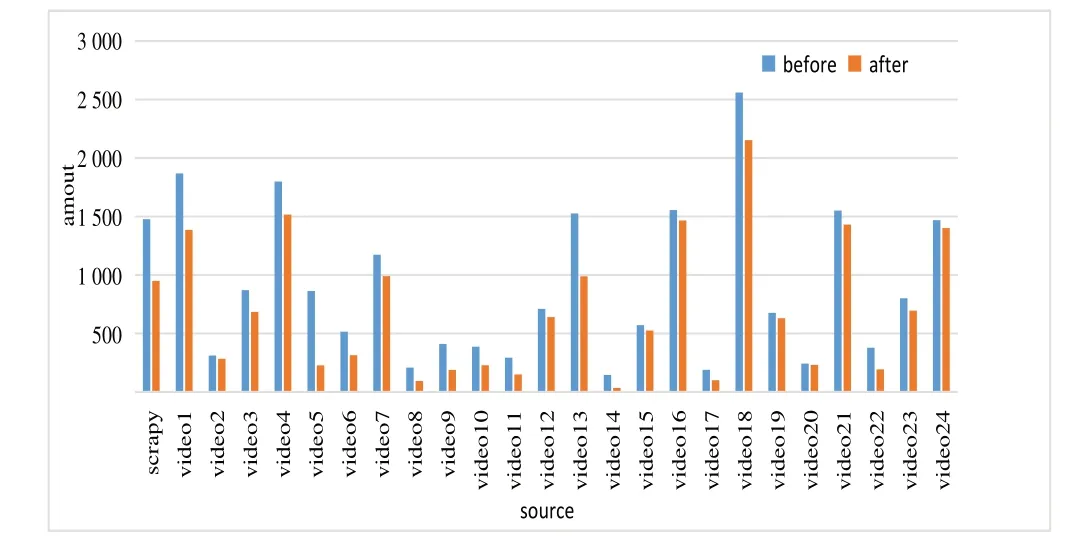
Fig.4 Comparison of the number of pictures before and after deduplication图4 去重前后图片数量比较
3.4 YOLOv5模型训练
通过训练目标检测模型实现对图片数据的自动标注。本文选择YOLOv5 模型,训练数据集为开源的SHWD(Safety-Helmet-Wearing-Dataset)安全帽佩戴数据集,包括7 581 张图像,其中有9 044 个佩戴安全帽对象和111 514个未佩戴安全帽对象。数据集的标注方法见图5,佩戴安全帽的头部标注为hat,未佩戴安全帽的头部标注为person。
模型训练命令如下:

其中,--data 表示配置训练使用的数据源,本文使用的数据源为YOLO 标注格式的SHWD 数据集;--hyp 表示指定超参数配置文件,本文使用默认的hyp.scratch.yaml;--name 表示保存训练结果的文件名。

Fig.5 Example of data set annotation图5 数据集标注示例
训练结束后可使用得到的best.pt(runs/train/helmet/weights/best.pt)预测自行收集到的图片数据。
3.5 生成标注
使用训练好的YOLOv5模型对收集到的图片数据生成对应的标注,执行命令为:

其中,--weights 表示预测使用的模型权重文件,本文设置为前面训练结果的best.pt 文件;--source 表示预测的源,本文设置为自行收集图片所在的文件夹;--conf-thres表示置信度阈值,只有预测框的置信度大于阈值才会生成标注,可按需设置;--nosave 表示不保存预测结果图片,因为仅需要标注文件;--save-txt 表示保存预测的标注文件。
由于收集到的图片中含有大量非目标图片,有必要进行过滤。读取生成的标注文件,只保留含有hat标注和person 标注的文件及其对应图片,如此可过滤大量无用数据,免去人工过滤步骤,最后得到质量较好的数据。数据过滤流程见图6。
过滤后得到含有hat 标注(可能有person 标注)的数据10 951个,仅含有person 标注的数据1 563个。有标签数据的分组主要是为了加快人工修正速率,因为多目标标注需要经常转换标签,会花费一定时间。过滤掉没有标注的数据共4 979 个,主要包含没有人体、有部分人体却没有头部、有头部但没有被识别出来的图片等。未标注的图片示例见图7。
3.6 人工修正标注
经过以上操作得到的数据集已经包含图片文件及其对应的标注文件,然而通过YOLOv5 生成的标注文件并不会100%正确,还需要进行人工修正。LableImg 软件可以通过Open Dir 指定图片文件目录,通过Change Save Dir 指定标注的文件目录,标注的格式指定为YOLO,具体示例见图8。
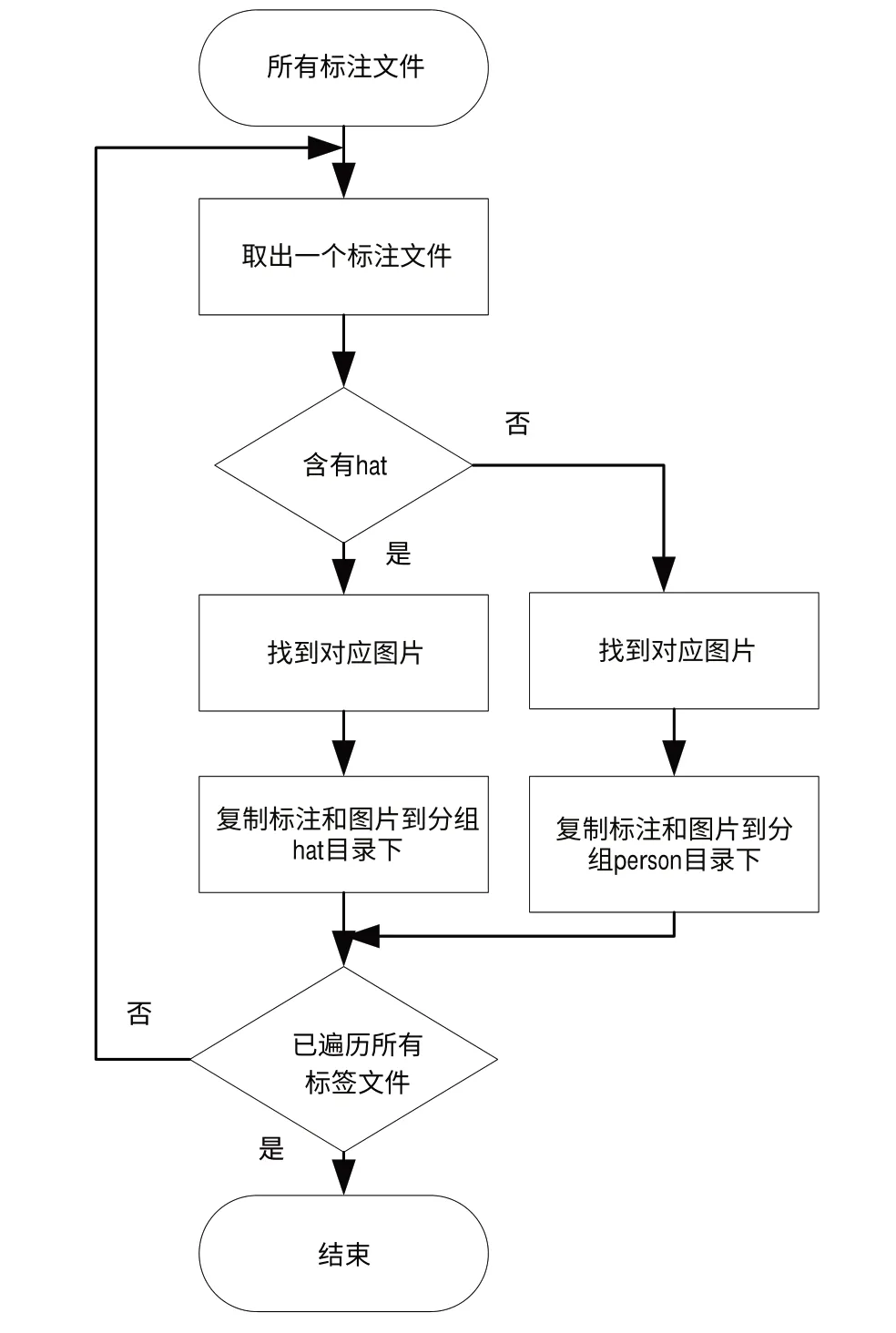
Fig.6 Process of filtering data图6 数据过滤流程

Fig.7 Examples of unlabeled pictures图7 未标注的图片示例
LableImg 软件可以非常方便地实现标注文件的可视化和修改,修改项目包括有目标而未正确标注、标注框位置错误、标注框类别错误和标注框大小不合适等,示例见图9。
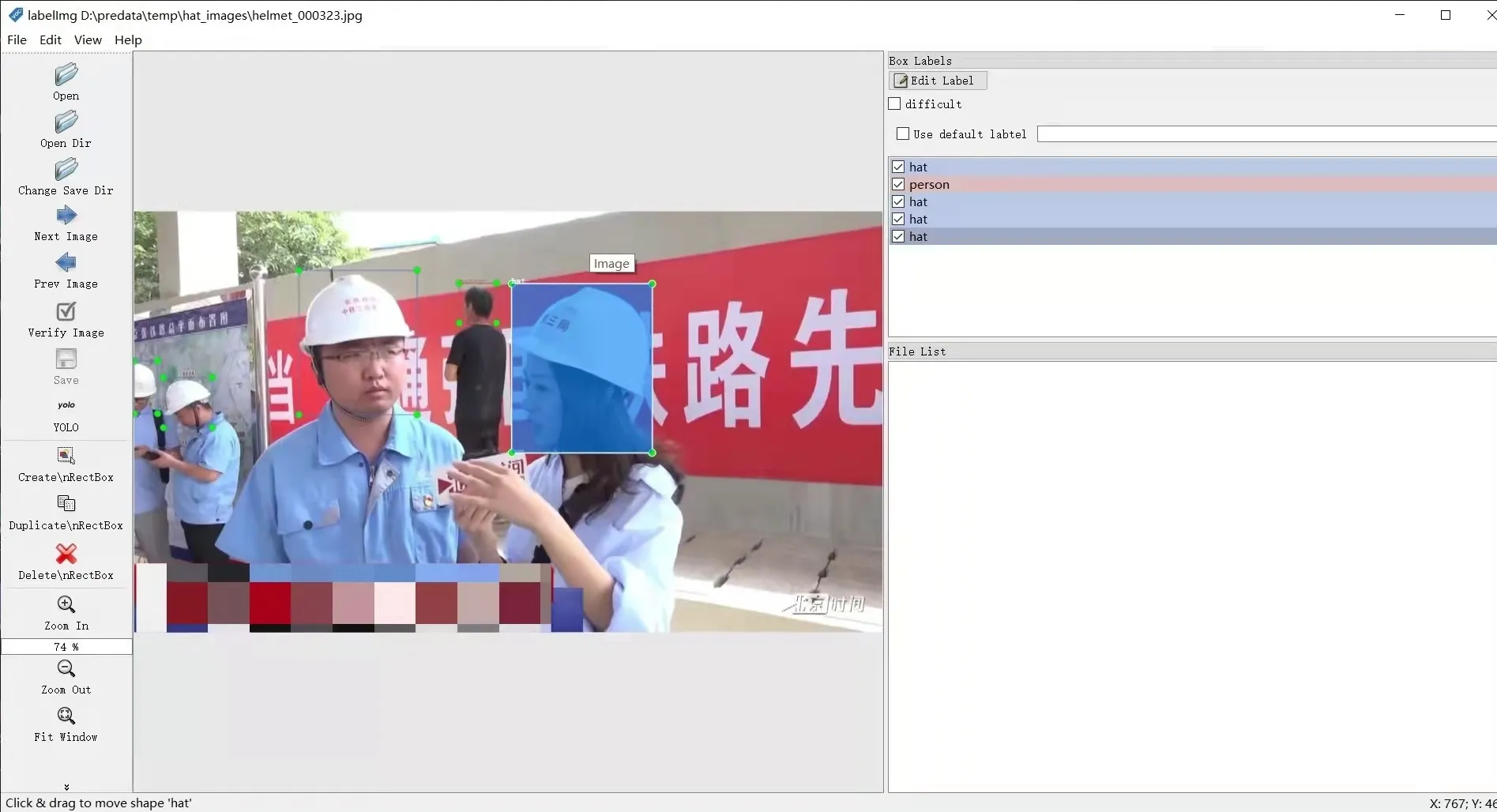
Fig.8 Example of using LabelImg图8 LabelImg使用示例

Fig.9 Examples of annotations that need to be modified图9 需要修改标注的示例
通过训练好的YOLOv5模型预测得到的标注仅可作为人工标注的参考,在进行人工修正时,不仅需要修改明显错误的标注,必要时还可以拉升标注框的长宽比例,对标注正确的标注框进行微调。更正过程会删除部分不合理数据,最后共得到10 967 张图片及其对应的标签。对更正后的数据集进行训练集、验证集和测试集划分便可用于YOLO 模型的训练,也可以通过编写脚本转化为其他格式(如VOC 和COCO 格式等)用于其他目标检测模型的训练。格式之间的不同主要体现在标注框上,YOLO 标签的格式包含标注框的归一化中心坐标(x_center,y_center)和宽高(w,h),而VOC 格式的标注框格式包含标注框左上角的坐标(xmin,ymin)和右上角的坐标(xmax,ymax)。设图片实际宽高分别为width 和height,YOLO 格式的标注框转换为VOC 格式的公式为:
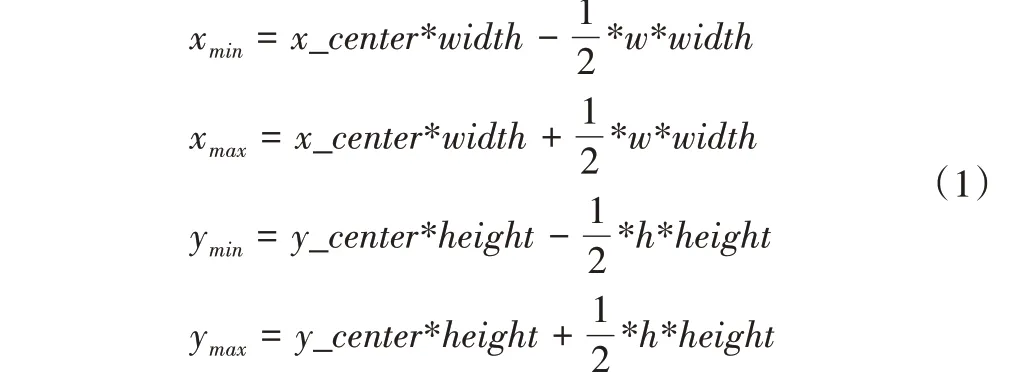
3.7 数据集的使用
由于收集得到的数据集由自动检测结果和人工标注结果混合而成,这样的数据集不利于模型进一步学习。本文使用YOLOv5 模型进行半自动人工标注,如果再使用修正后的数据集训练YOLOv5 模型是不合适的,因此得到的数据集可以应用于除YOLOv5模型以外的其他目标检测网络的训练或不需要进行深层次改进的目标检测任务中。当希望获得更好的目标检测模型而对数据集要求更高时,可以通过生成的标注获取所需图片后不使用自动生成标注方法,而使用人工方式对全部数据进行标注。
4 结语
本文设计的自定义目标检测数据集的收集与半自动标注方法通过爬虫技术和视频取帧获得了大量目标检测图片数据,通过训练好的目标检测模型和人工修正方便快速地创建了数据量巨大的数据集,且在制作过程中便可以通过算法过滤大量无用数据,大大减少了人工过滤时间。然而该方法还有很多需要优化之处,如处理大量图片时设计的去重算法会花费大量时间;需要训练某个目标检测算法时需要熟悉该算法并搭建训练环境,如果没有公共数据集用于训练,则需要从收集的数据中先标注部分数据用于训练。本文方法虽然实现了半人工标注,但人工修正仍然需要花费一定时间,选择预测准确度高的模型可以大大降低人工修正难度。
