基于层次匹配的维吾尔文关键词图像检索
2022-12-30宋志平朱亚俐吾尔尼沙买买提徐学斌库尔班吾布力
宋志平,朱亚俐,吾尔尼沙·买买提,徐学斌,2,库尔班·吾布力,2+
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆大学 多语种信息技术重点实验室,新疆 乌鲁木齐 830046)
0 引 言
文档图像检索方法分为基于光学字符识别[1](optical character recognition,OCR)的检索和基于图像特征的检索,基于OCR的检索方法高效快捷,但是检索系统复杂,对手写体文档图像及少数民族语言文档图像而言,目前无成熟的OCR系统,而基于关键字的检索方法它能快速确定所需信息的准确位置,无需进行字符识别、系统结构简单,能够带给用户与OCR检索几乎相同的检索体验,是OCR系统的一种非常有效的互补方法。白淑霞等[2]将语言模型与词袋模型(bag-of-visual-words,BoVW)的框架相结合,提出了一种基于LDA的主题模型,改进了蒙古文图像关键词检索框架。魏宏喜等[3]建立了基于词定位法的蒙古文图像检索系统,关键词图像通过文字轮廓、投影特征和笔画的交集来表达,最后将视觉特征集成到BOVW模型[4]中并用于检索任务。周文杰[5]采用形态学梯度算法对维吾尔文文档图像进行切割,使用切分后的单词图像LBP纹理特征实现检索。李静静等[6]在粗匹配阶段采取模板匹配,之后将HOG特征用于精细匹配,最后利用SVM分类器对关键词进行精确检索。
基于层次匹配的维吾尔文关键词检索方法,首先对预处理后的文档图像进行单词切分,生成单词数据库,并使用分块灰度共生矩阵算法对单词图像库进行浅层检索,过滤掉部分无关单词图像后形成候选单词库;其次利用预先训练好的VGG16网络特征提取器对浅层检索回的候选单词库进行深层精确检索,具体框架如图1所示。
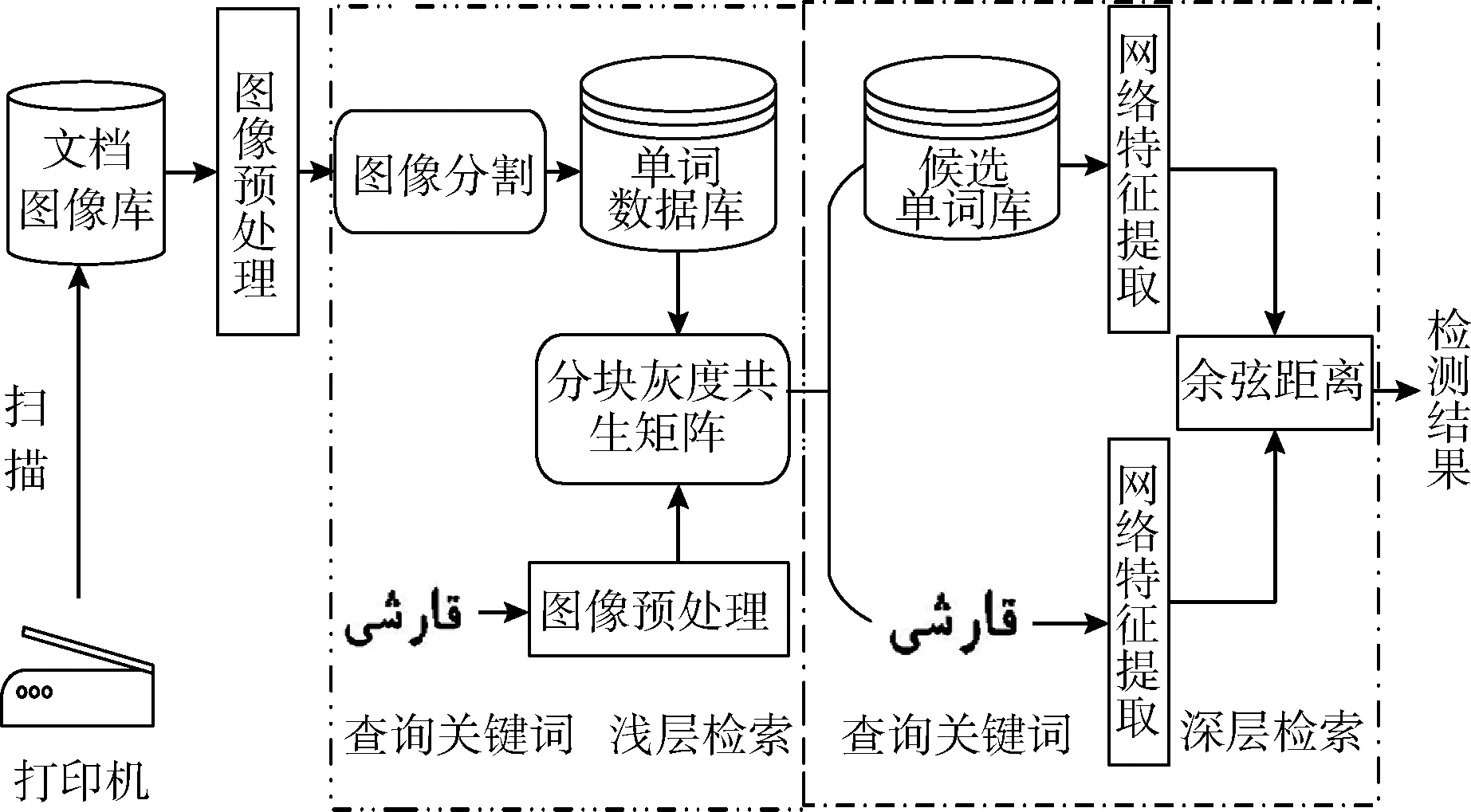
图1 基于关键词的文档图像检索系统框架
1 基于维吾尔文单词图像检索研究
1.1 图像采集与预处理
由于在将纸质书文本扫描成电子文档图像的过程中,由于环境设备等因素的影响,阻碍了图像有效信息的提取。因此本文通过图像预处理方法来增强图像质量,其中预处理操作包括灰度化(加权平均法)、噪声去除(中值滤波)及倾斜校正(Hough)。预处理前后效果如图2(a)、图2(b)所示,经过预处理后的图像笔迹较之前更清楚,内容结构更易于识别,这说明经过预处理后的图像特征比灰度图片更明显。由于本文使用的数据集是纯文本版面,因此采用徐学斌等[7]提出的基于聚类+连体段判别法完成对维吾尔文印刷体文档图像的单词切分,效果如图2(c)所示。

图2 文档图像预处理
1.2 单词图像增广
基于深度学习的探究需要大量的数据样本来训练网络[8,9]。但多数情况下是没办法得到足够的数据,因此数据增广技术有利于深度学习模型的训练,同时数据增广技术可以从已有的数据中获得新的样本,从而有效改善模型的表达能力[10]。维吾尔文单词图像方面的样本数据较少,除了字体字号的变化外,没有其它的数据样本,因此本文采取数据增广的方法,来提升单词图像样本的多样性。
本文通过对115张纯文本维吾尔文文档图像进行单词切分,形成单词图像总数为24 460张单词数据库,其词汇量为1233,选取了其中词频最高的200个类,之后分别从每个类中选取10张单词图像对其采用旋转、剪切、遮挡、加噪、模糊等几何图像变换方法,将其扩充为原来的10倍,并用于网络模型的训练。之后在网络训练中采用概率p=0.5进行在线数据增广方法,来增加训练数据集样本的多样性,离线增广部分效果如图3所示。

图3 单词图像增广
2 特征提取
2.1 灰度共生矩阵
灰度共生矩阵(gray level co-occurrence matrix,GLCM)[11]是一种具有方向选择性的特征统计方法。通过灰度空间特征对图像在方向、相邻区间、变化幅度等信息进行描述。其一般表示量是:能量、熵、对比度、相关性、纹理方差等6个主要特征量,对图像灰度空间变化信息进行描述。本文主要采用能量、熵、对比度和相关性4个最具有代表性的纹理参数作为本文的纹理特征,具体计算如下:
(1)对比度,又称惯性矩,它能测量图片中的矩阵分布和局部变化,反应图中局部的纹理信息
(1)
(2)角二阶矩,又称能量,它能反映图像灰度分布和纹理厚度
(2)
(3)熵,它表示了图像的信息测度,图像内容的随机性和图像纹理的复杂性
(3)
(4)相关性,也称为同质性它被用于衡量灰度级在行或列方向上的相似性,因此该值反映了局部的灰度关联值
(4)
其中,i为矩阵行数,j为矩阵的列数,P(i,j) 表示矩阵在i行j列处的值。μx,μy,σx,σy分别是Px和Py的均值和方差,Px是共生矩阵中每列元素之和,Py是共生矩阵每行元素之和。
2.2 改进的灰度共生矩阵
在图像检索中使用灰度共生矩阵特征参数时,通常选择一个或多个特征参数来度量图片的相似性。其次GLCM在进行纹理提取时,往往不考虑基元的形状,不适合由大基元组成的纹理,会导致很多有价值的纹理信息被忽略。
为了突出图像的中心位置,从而提高图像检索效率,本文在原有算法的基础上改进了灰度共生矩阵算法[12]。首先将M×N大小的单词图像调整到N×N大小的图像,然后再将图像分成3×3共9个相同大小的子块,之后计算每个子块00、450、900、1350,4个方向的GLCM特征参数作为子块的纹理特征,将提取到的各个子块纹理特征进行串联得到3×3×16=144维纹理特征代替原始的GLCM特征去表达图像纹理信息,这样能够把较大的共生矩阵数组化为较小的共生矩阵数组,同时还可以避免出现过多的纹理特征被忽略的情况,能够对图像有效区域的纹理信息进行细致描述。
2.3 VGG16网络
目前常用的深度网络有AlexNet[13]、VGGNet[14]、GoogleNet[15]、ResNet[16];VGG16[17]网络由13个卷积层5个池化层和3个全连接层构成,3×3卷积核取代5×5卷积核提取更细致的图像特征,其模型参数较少而且结构简单规整,并能更好进行特征提取;因此本文选取了VGG16作为特征提取网络VGG16网络结构如图4所示。

图4 VGG16网络结构
2.4 网络迁移
迁移学习是指将模型通过源域学习的知识迁移运用到目标域中,即将以往的知识迁移到另一个新的领域中。刘诗琪[18]通过将深度学习与迁移学习结合提出tr-RCNN模型
结合RBM与CNN两种模型有效解决了小样本航拍图像分类问题。刘嘉政[19]结合CNN和迁移学习用于花卉图像识别,取得了很好的效果。由于维吾尔文单词数据集属于小样本数据集,因此本文首先在源域Kannada语手写体数据集上对VGG16网络模型进行预训练至参数收敛,之后将训练参数作为目标域维吾尔文单词数据集的初始化参数,并对网络模型参数进行微调(Finetune)至充分拟合,最后将全连接层的输出作为单词图像的特征表示,如图5所示。
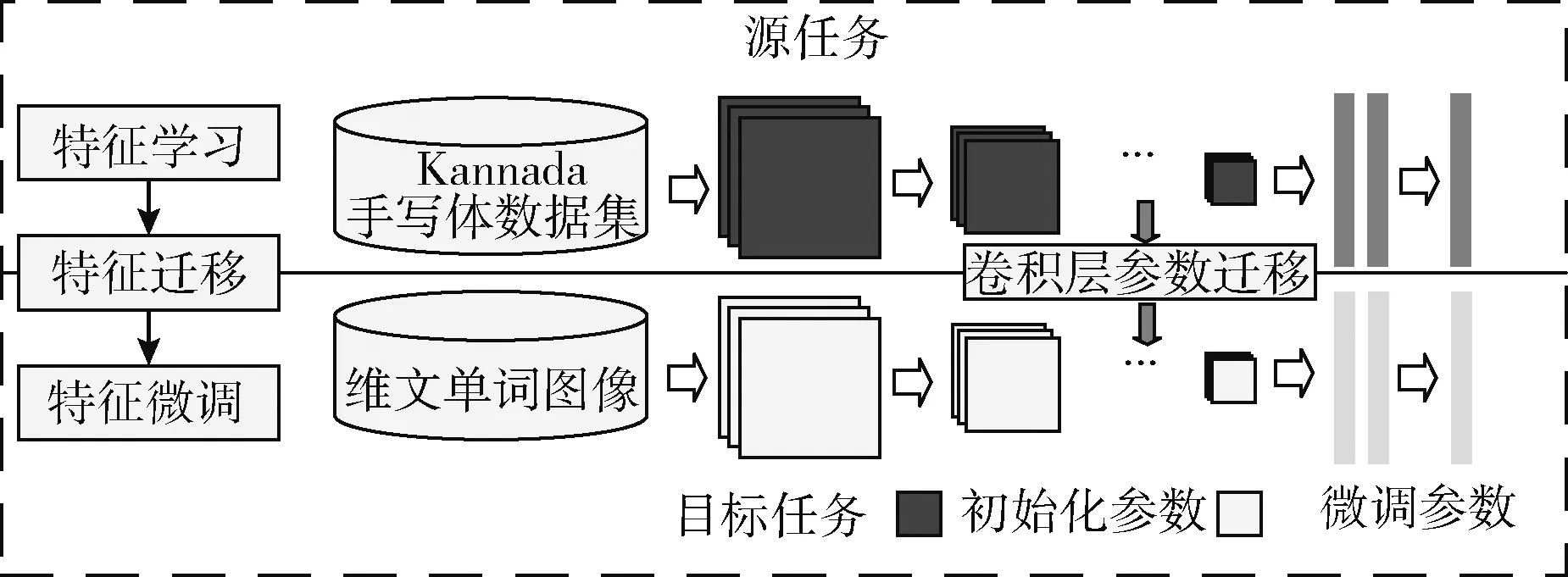
图5 VGG16网络微调
2.5 相似性度量
本文采用余弦相似性算法来对图像检索的结果进行评估。余弦距离也称为平行倾斜率。它计算俩矢量间的空间余弦,以测定俩矢量间的大小差。它的应用范围比较广阔,能解决任意维度向量比较的问题。而对于图像来说,图像本身就是一个一个富含大量特征的载体,同时这些特征又有着很高很复杂的维度空间,和别的算法不同的是,余弦相似性算法[20]将数据映射为高维空间中的向量从方向上区分差异性,而不考虑空间位置等因素,图6为余弦距离。
图6 余弦距离
假设向量a1=[A11,A22,……,Ann] 和向量a2=[B11,B22,……,Bnn] 是两个n维向量,那么向量a1与a2的夹角θ
的余弦计算公式为
(5)
3 实验结果与分析
本文实验在Windows10环境下展开,处理器型号为Intel Core I5-8300,运行内存8 GB,具体程序是在python3.7开发环境下编程调试,并借助OpenCV-3.4.2.16开发平台实现。文档图像数据库源于《马列主义经典著作选编》维吾尔语版,为模拟不同的办公环境,采用不同的打印机将纸质书籍扫成文档图像,建立了1000张文档图像,随机选取了115张文档图像并切分成24 460张单词图像库,并在其中选取10个具有丰富意义的关键词图像作为查询关键词图像,并在数据库中进行检索实验。检索性能的评价指标有准确率(precision)、召回率(recall)、F值,指标计算公式如下:
TP(true positive):检索为关键词;实际也为关键词;
FP(false positive):检索为关键词;实际是非关键词;
TN(true negative):未被检索到的关键词;实际是非关键词;
FN(false negative):未被检索到的关键词;实际是关键词
precision=TP/(TP+FP)*100%
(6)
recall=TP/(TP+FN)*100%
(7)
F=precision*recall*2/(precision+recall)
(8)
3.1 基于灰度共生矩阵的浅层检索实验
本文首先在维吾尔文单词数据集上,评估了灰度共生矩阵算法在维吾尔文文档数据集上的性能。表1展示了原始灰度共生矩阵算法的检索性能,其中准确率平均值为39.04%,召回率的平均值为48.29%,F值平均值为42.27%。第5个查询关键词的检索准确率在这10个关键词图像中效果最好为55.81%。表示共检索到43个单词图像其中目标关键词包含24个。准确率最差的是第1个查询关键词,为25.39%,即共检索回63个单词图像,其中正确单词图像为16个。而第9个单词图像召回率在这10个查询词中最好,为66.00%,表示共标注50个关键词图像,其中33个被召回。第3个查询关键词图像召回率最低,为32.14%。即共标记56处关键词图像,其中召回18处。
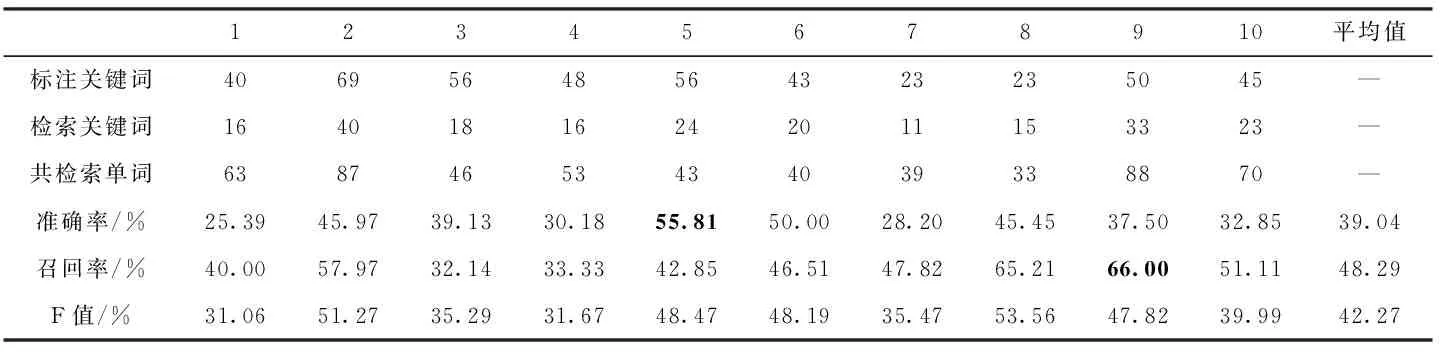
表1 基于灰度共生矩阵的关键词图像检索实验
表2中数据为分块后的灰度共生矩阵算法的检索结果,其检索平均准确率为39.90%,而这些正确的关键词图像,占所标注关键词图像总个数的87.72%,F值平均值为52.49%。其中第5个关键词准确率在这10个查询关键词中最高,为60.00%,即表示共检索回70个单词图像,其中目标关键词包含42个。相反也有准确率较差的关键词,第6个关键词准确率在这10个词中最差,为12.82%,即共检索到312个单词图像,其中目标关键词图像包含40个。召回率效果最好的是第2个关键词,为100%,代表标注关键词图像全部召回,而召回率最差的是第5个关键词,为75.00%,即标注56个目标关键词图像其中成功召回42个目标关键词图像。
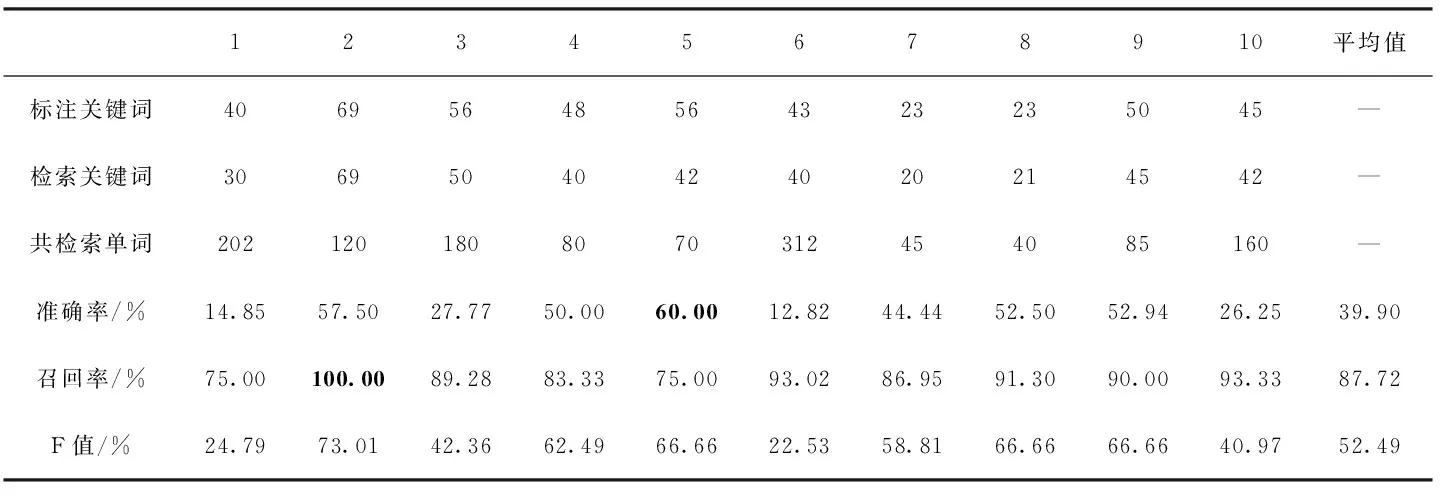
表2 基于改进的灰度共生矩阵浅层检索结果
由表1和表2结果可以得出,采用分块后的灰度共生矩阵算法相较于原始的灰度共生矩阵算法在准确率和召回率上都有大幅提升。但无论是改进前还是改进后的特征,其准确率都普遍偏低且其波动较大,召回率都偏高且波动较小。经分析得出灰度共生矩阵算法中仅简单利用了图像的像素纹理信息对单词图像进行快速筛选, 以保证尽可能多的目标关键词被召回。然而并未提取到图像更深层次特征去表征图像间细微的差别,仅仅对数据库中一些不相关的单词图像和切分错误的单词图像进行过滤,以保证尽可能多的召回目标单词图像。
3.2 基于VGG16网络的深层检索实验
本节第一组实验是在没有浅层检索的基础上,只用VGG16卷积神经网络特征在维吾尔文关键词图像数据库进行检索。其结果见表3:准确率平均值为70.29%,召回率平均值为57.98%,F值平均值为60.37%。第5个关键词的准确率最好达到92.85%,即表示共检索回28个单词图像其中26个检索正确,而第10个关键词准确率最低,为40.00%,表示共检索回100个单词图像其中正确检索回40个关键词图像;对于召回率而言第9、第10这2个关键词效果最好均达到80%以上,即代表标注关键词图像大部分都被召回。
在这一部分,使用VGG16网络特征进行关键词检索,准确率普遍较高,其原因是由于网络根据大量的数据样本可以学习到更深层的内在特征表示,对图像内容的表达更准确,而其召回率普遍较低,经分析发现,虽然我们通过了数据增广来增加图像数据的多样性,但只是对原有数据集进行改变,本质上对数据特征多样性变化不够,从而导致网络模型不能很好学习到维吾尔文单词特有的纹理轮廓等特征信息,难免会检索回与目标查询词无关的图片。由此可以看出单一特征的检索效果都不尽如人意,无法从不同角度衡量图像;但对不同特征进行融合可以很好的解决这一问题,因此本文在灰度共生矩阵浅层检索的基础上,采用VGG16网络特征对浅层检索回的候选单词图像库进行二次精确检索,实验效果见表4。表4中的数据是在结合分块灰度共生矩阵,与卷积神经网络在维吾尔文关键词图像二次检索的结果。其中准确率平均值为94.15%,召回率平均值为82.03%,F值平均值为86.80%。从表4结果中可以看出第5、第9、第10这3个查询关键词的准确率均达到100%,即表示检索回的单词图像均为目标关键词图像;对于召回率而言,第2个关键词召回率为100%,表示标注关键词图像全部召回;与表2浅层检索结果相比其准确率平均值提升了54.25%,召回率方面降低5.69%,与表3结果相比平均准确率和召回率分别提高23.86%和24.05%。
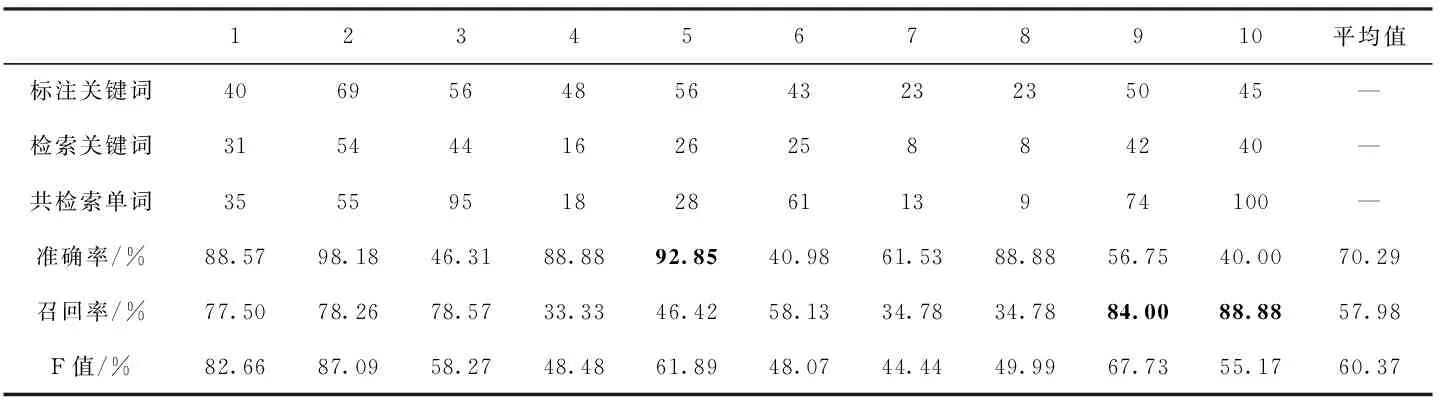
表3 基于VGG16的关键词检索结果
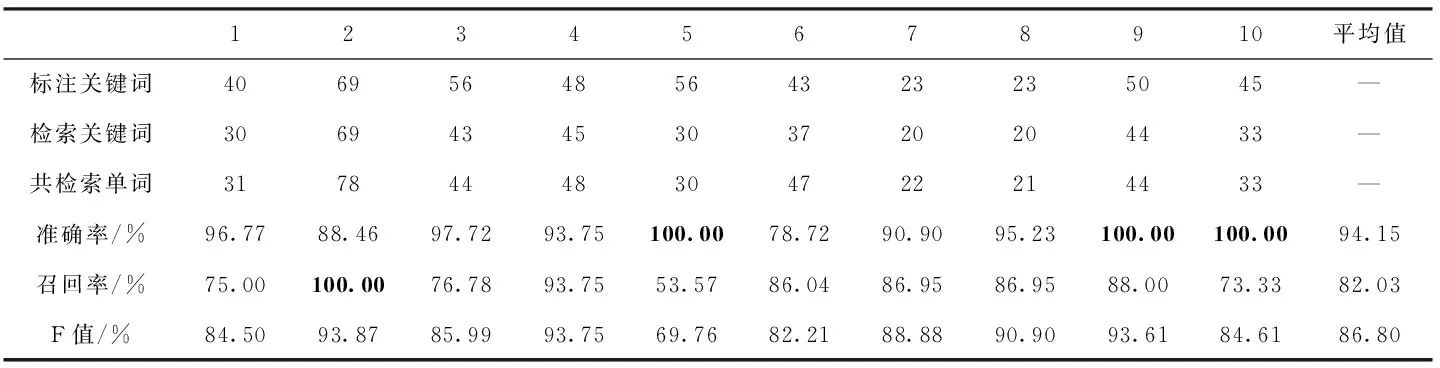
表4 基于分块灰度共生矩阵+VGG16的关键词深层检索结果
从表4结果可以总结出,采用层次匹配的检索方法将分块灰度共生矩阵与卷积神经网络特征进行分层次融合,在提取到图像更深层次空间域特征的同时,兼顾到图像底层纹理信息。与表2浅层检索结果相比通过损失较小的召回率的情况下极大提高了检索的准确率,其结果明显优于表2和表3单一特征的检索效果。显然通过将图像底层特征与高层空间域特征有效的结合可以更全面地表达关键词图像信息进一步提高了检索性能;同时验证了本文方法在维吾尔文文档图像检索中的有效性。
3.3 与现有方法对比
为进一步验证本文提出方法的性能,和已有的Hu+MBLBP+OSVM[5]和模板匹配+HOG+OSVM[6]维吾尔文关键词检索方法作比较,3种方法的准确率、召回率和F值等对比情况见表5。由表5可知本文方法检索平均准确率为94.15%,平均召回率为82.03%。相较于Hu+MBLBP+OSVM关键词检索方法,本文方法在准确率上提升了7.45%,召回率提升了3.73%,而相较于模板匹配+HOG+OSVM关键词检索方法,本文方法在准确率上提高了2.41%,在召回率上提升了2.72%。可以看出相较于前两种基于经典特征与SVM的检索方法,本文方法在准确率、召回率上均有明显提升。

表5 基于维吾尔文关键词图像检索结果对比
4 结束语
本文针对传统图像特征在维吾尔文文档图像上检索效果不理想等问题,提出结合灰度共生矩阵与卷积神经网络的维吾尔文关键词图像层次检索方法,通过将传统手工特征与深层空间域特征进行分层次融合,在浅层检索召回率略有损失的情况下极大提高关键词图像检索的准确率,同时随着对关键词检索研究的深入,基于关键词的维吾尔文文档图像检索已然成为一个极具挑战的研究热点,尤其是关键词图像特征选取的研究,因此下一步工作将更加深入分析维吾尔文单词图像特点,寻找新的特征进行融合进而提高系统检索性能。
其次,本文的研究主要是建立在印刷体的维吾尔文纯文本文档图像上,而现实中的文档图像还包含表格、图片等信息,因此,需增加具有复杂布局的文档图像以及手写体的文档图像,同时单词切分方法也有待改进,实验中的测试关键词数目以及文档图像规模还会继续扩大,降低偶然因素对检索结果的影响。
