结合粒子群优化与强化学习的攻击检测系统
2022-12-30郝武伟李俊吉
郝武伟,李俊吉
(1.山西工程科技职业大学 现代物流学院,山西 晋中 030619;2.太原科技大学 信息科学与技术学院,山西 太原 030024)
0 引 言
入侵检测系统(intrusion detection system,IDS)[1]是网络安全的第一道防线,对网络中传输的数据进行实时监测,若发现可疑流量则发出警报,及时降低恶意行为造成的损失。目前最有效的IDS大多对网络流量的特征进行建模,再通过各种分类器对流量进行分类[2]。为提高IDS的检测性能,各专家学者尝试将不同的机器学习模型应用于入侵检测系统,包括支持向量机[3]、决策树[4]、随机森林[5]等,但传统机器学习模型的特征学习能力较有限,难以大幅提升IDS的攻击检测率。
近年深度神经网络因其强大的非线性学习能力,在计算机视觉[6]、自然语言处理[7]、网络安全[8]等领域展现出明显的优势。文献[9]提出一种基于深度卷积神经网络的入侵检测的算法,在卷积神经网络基础上引入Inception模型和残差网络,采用深度学习技术提高模型的收敛速度。文献[10]提出一种基于误差逆向传播神经网络的攻击检测算法,该模型对中小型网站的传输数据能准确地识别出正常流量与攻击流量。文献[9]与文献[10]通过深度神经网络技术提取了丰富的网络数据特征,提高了网络攻击的识别性能,但此类技术均需在已有训练集上完成训练,再对测试集进行静态分类,因此上述基于深度神经网络的攻击检测算法仅支持静态数据集,无法识别新的攻击类型。
IDS作为第一道防线,应能主动发现可疑行为以保障网络的平稳运行,其中发现新型攻击是当前IDS面临的一大挑战。文献[11]采用Bagging策略独立训练多个极限学习机,引入一种基于批量样本增量学习的在线更新策略,实现入侵检测模型的在线更新,能适应复杂网络环境的变化。文献[12]先采用开集分类网络检测未知攻击,再采用语义嵌入聚类方法发现隐藏的未知攻击,最终使用增量最近质心法学习发现的未知攻击。虽然文献[11]与文献[12]通过增量学习可成功检测未知的攻击,但均通过机器学习模型检测可疑行为,导致对新型攻击的检测准确率仍有提升空间。针对上述问题,本文IDS采用深度自编码器提取网络数据的深度特征,将特征迁移至深度神经网络进行微调与分类,提出基于粒子群优化算法的深度神经网络自适应训练方法。此外,采用强化学习增强IDS对网络环境的动态感知能力与学习能力,以改善深度神经网络对新型攻击的识别能力。
1 基于强化学习的攻击检测框架设计
1.1 攻击检测框架
基于强化学习的攻击检测系统框架如图1所示。网络流量经过深度自编码器提取特征,将特征集传入深度神经网络进行微调与分类处理。攻击检测结果保存于安全数据库,安全专家对数据库进行分析,基于分析结果对前端部分进行奖赏。
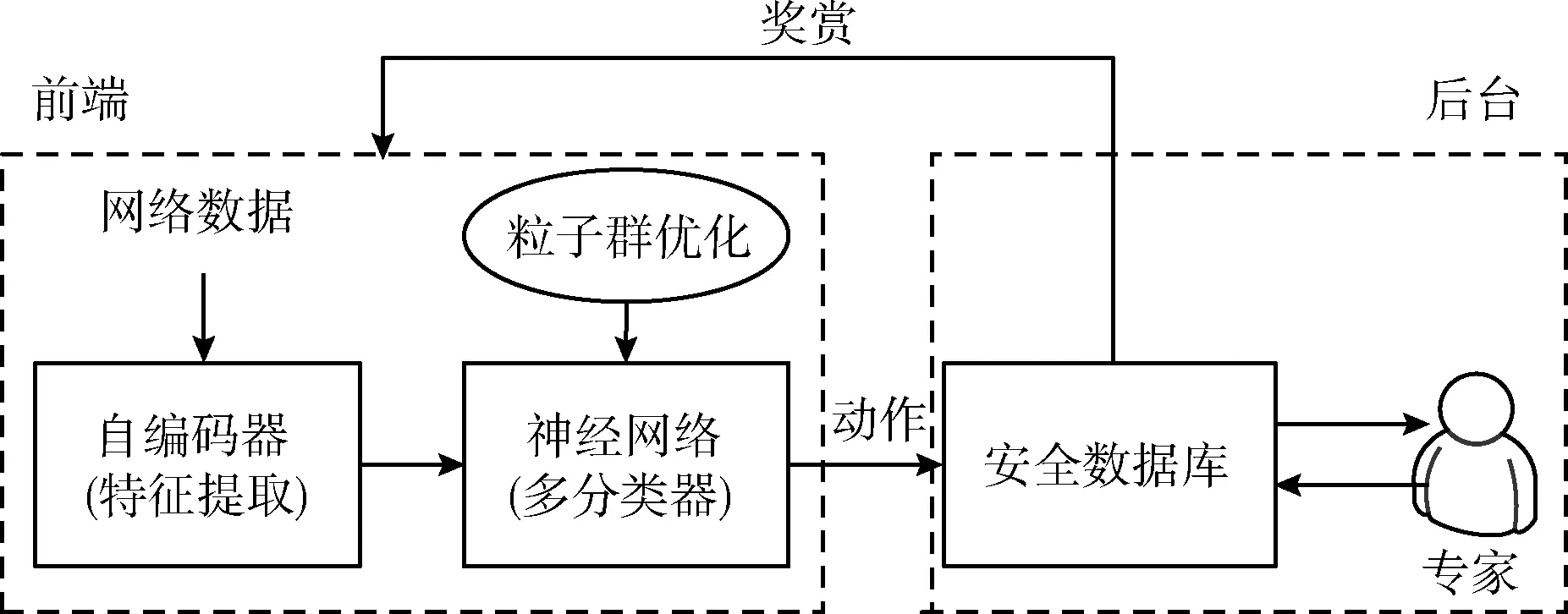
图1 强化学习框架
强化学习模型[13]可表示为ψ(Di,A,R), 其中A为攻击检测的动作,R为攻击检测的奖赏,奖赏值依赖于攻击检测成功率。强化学习的奖赏函数定义为
(1)
式中:x∈[0,1] 表示攻击检测率,y∈[0,1] 为攻击检测成本,z∈[0,1] 为攻击检测假正率与假负率之和,反映了检测器的有效性,m为攻击总数量。分析式(1)可知,奖赏函数的奖赏值随检测率x升高而升高,如果假正率与假负率之和z升高,即未被检测的攻击数增加,那么x降低,奖赏值也随之降低。将攻击检测成本y定义为深度神经网络的训练成本,成本y作为一个约束条件。
1.2 基于强化学习的攻击检测
若检测系统的前端部分识别出一个异常行为,触发一个警报,将可疑目标标识符ids、攻击特征列表Fk及动作A保存于安全数据库中。
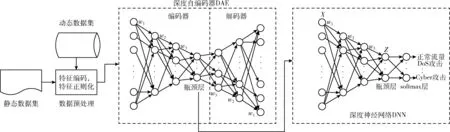
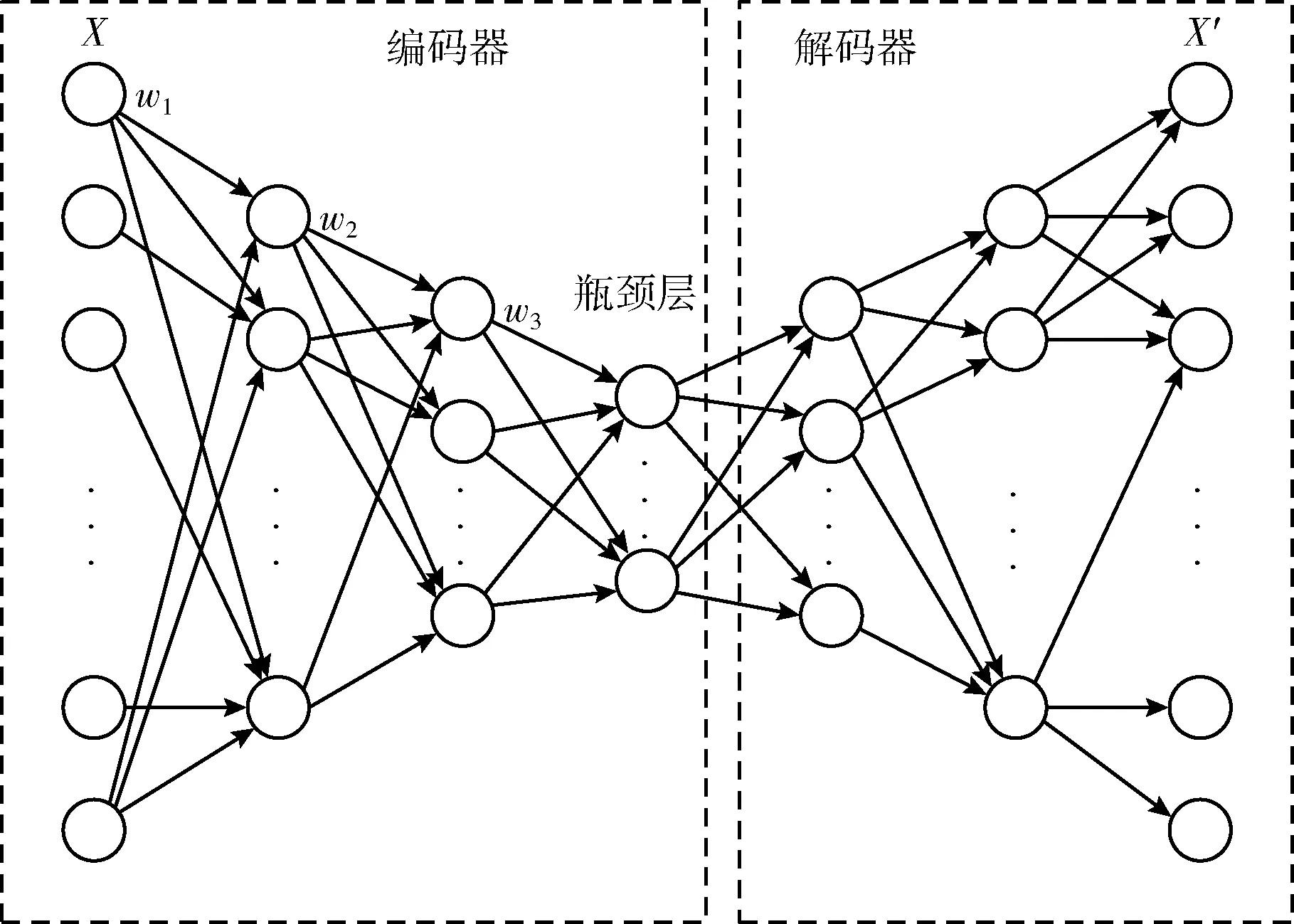
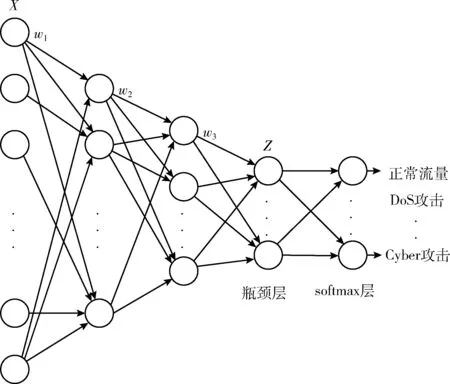
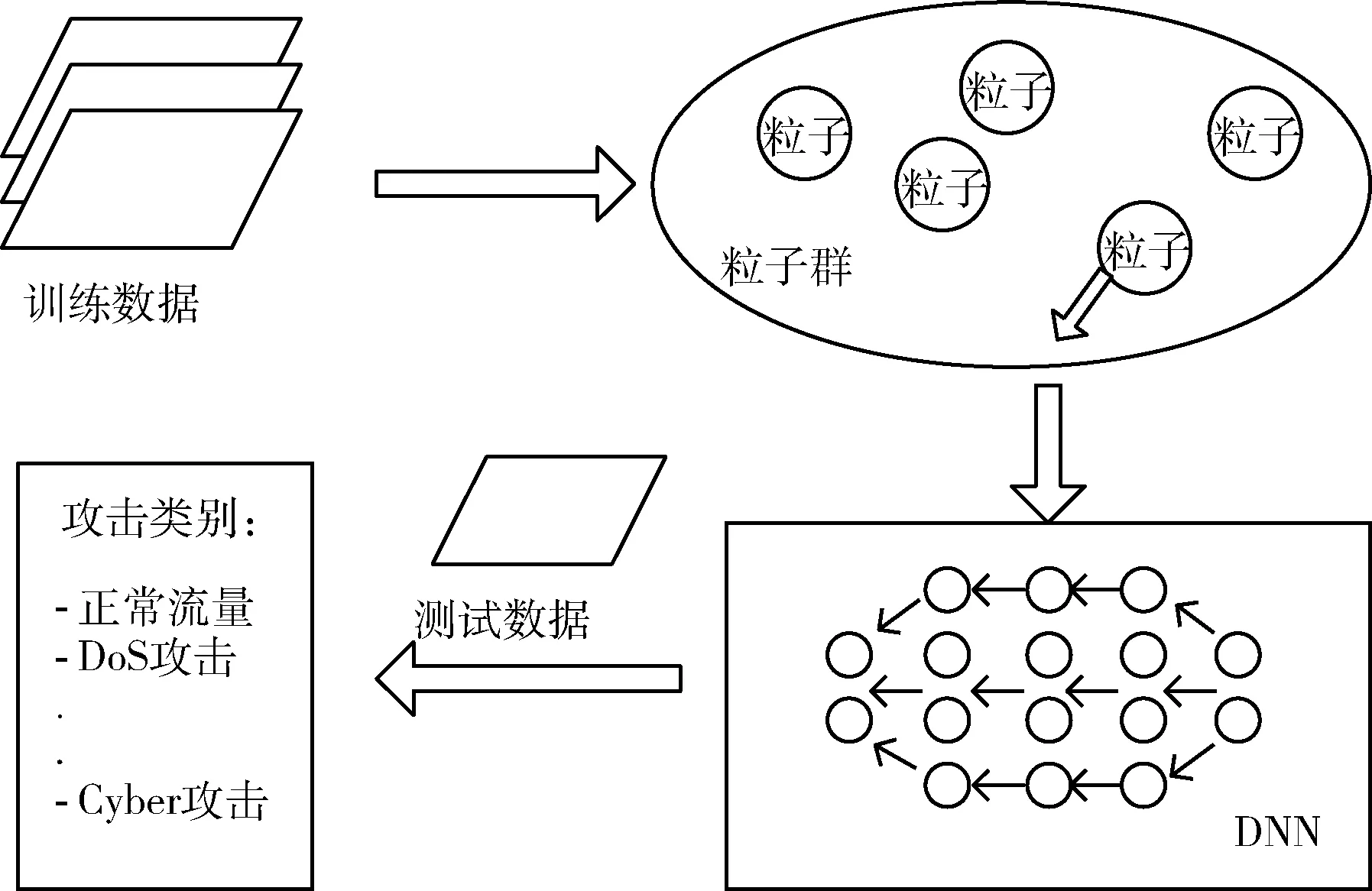
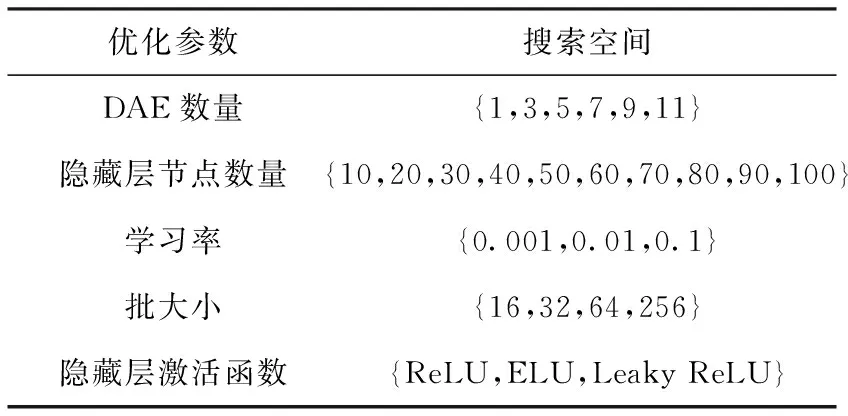
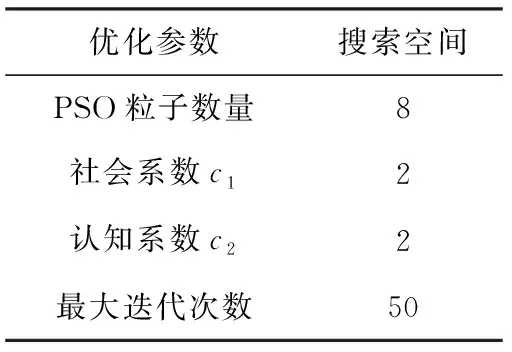
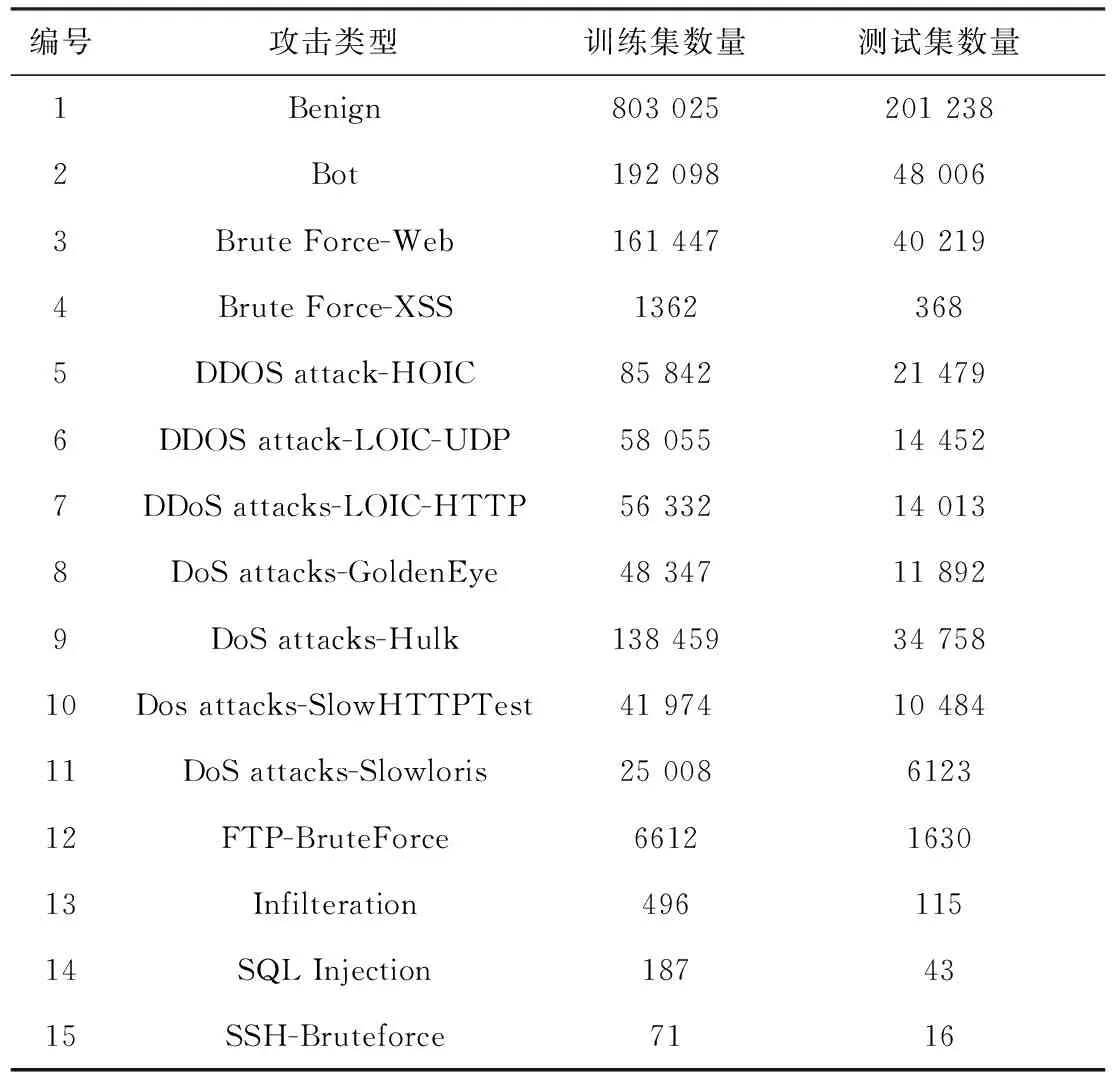
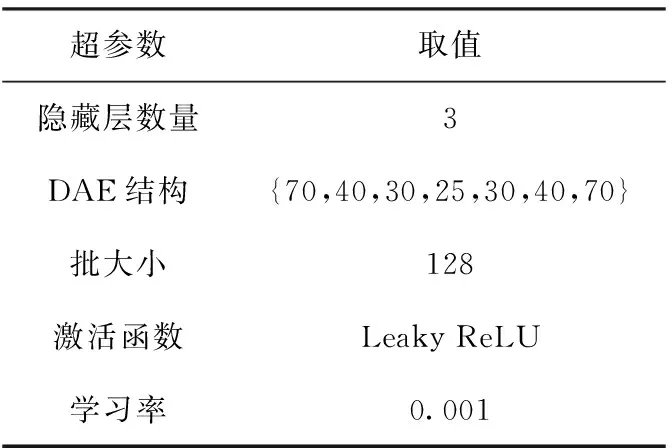
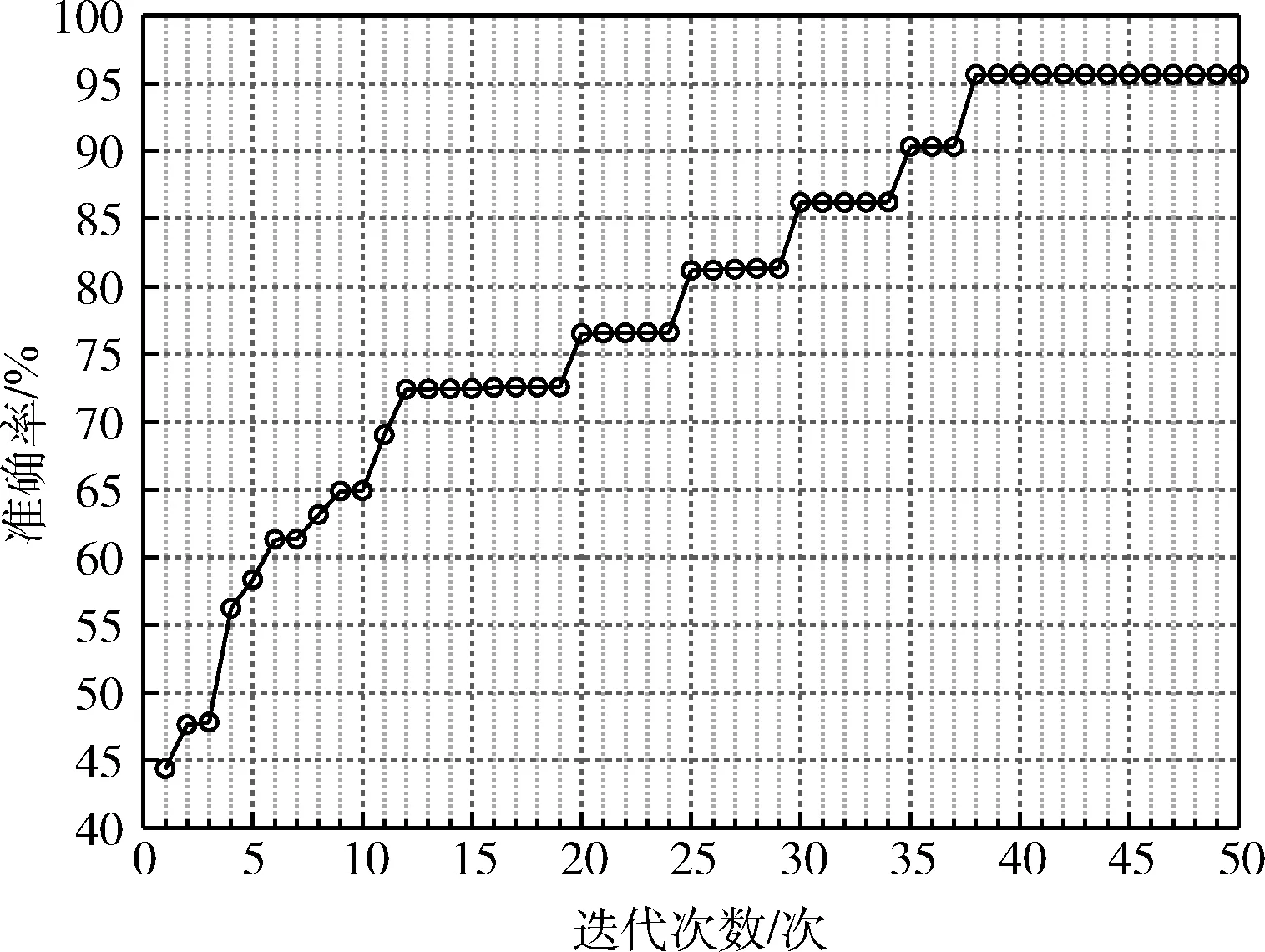
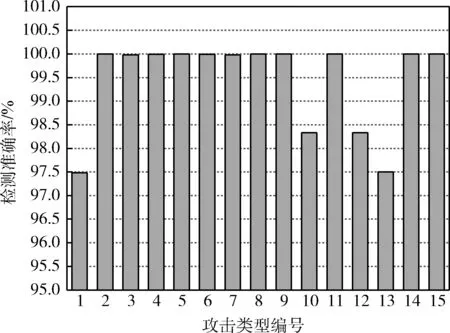
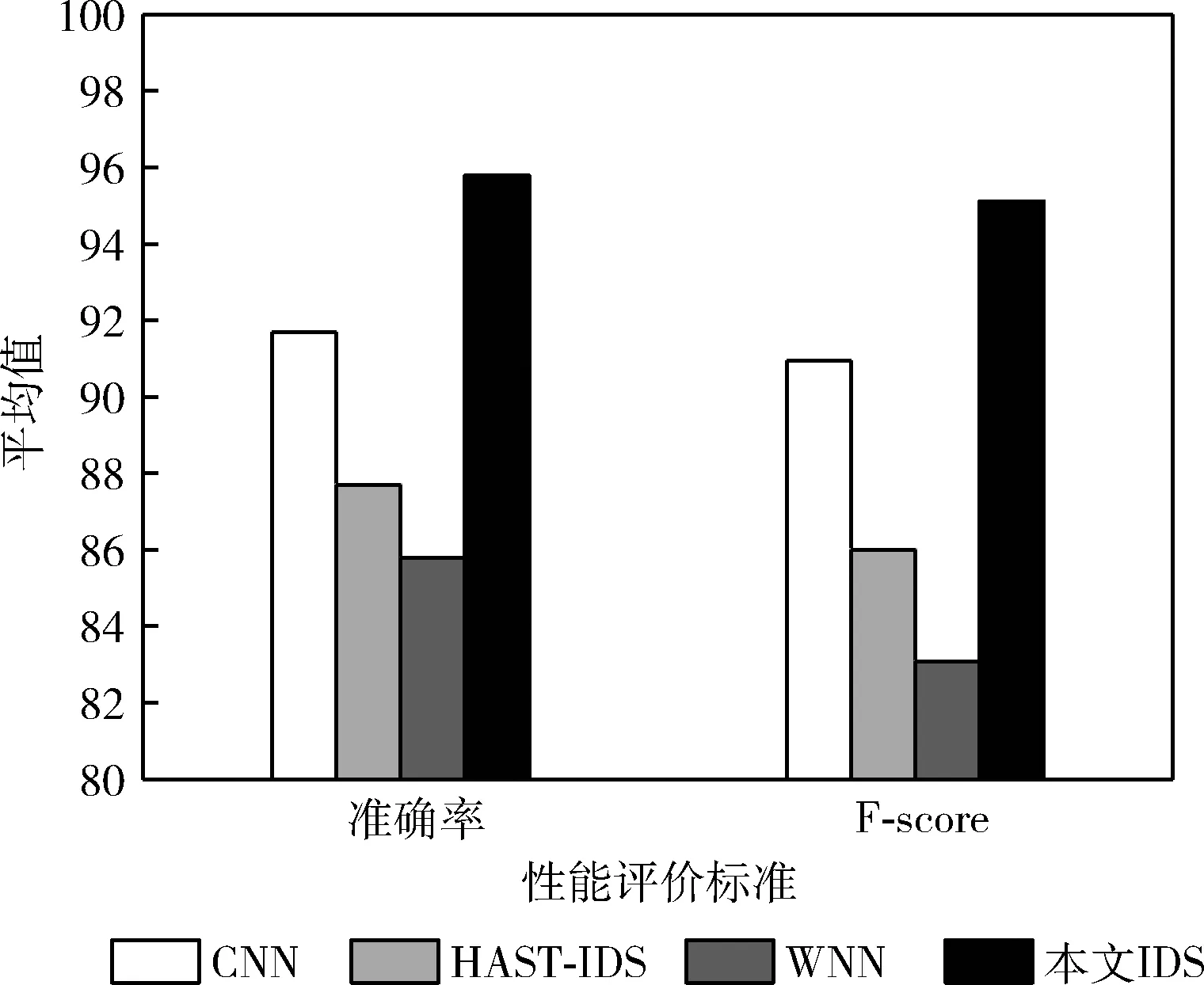
每次迭代计算检测系统的效用u(t-1) 与u(t), 比较相邻时间点的效用值以更新奖赏R。如u(t)>u(t-1), 则R值升高;如u(t) (2) 式中:α∈[0,1] 为学习率,γ∈[0,1] 为折扣因子。 算法1描述了攻击检测系统的强化学习过程,强化学习算法周期地运行直至当前效用值大于预定的效用阈值,即大多数异常与攻击被成功检测。安全专家的目标是通过强化学习降低检测系统的假阳率,持续更新特征集F′k, 维持攻击检测的性能。 算法1:强化学习算法 (1)计算检测系统的效用u; (2)while (ut (3) if (ut>ut-1) (4)R++; (5) else (6)R- -; (7) endif (8) 向安全数据库发送报警消息 {ID,Fk,A}; (9) if (ut (10)R=R′-1; //如果效用下降,则降低奖赏。 (11) 安全数据库更新{Fk,A,R}; (12) else (13)R=R′+1; //如果效用上升,则增加奖赏。 (14) 专家估计期望值 {F′k,A′}; (15) endif (16) if (F′k≠∅,A′≠∅) (17) 计算ut-1; (18)endwhile 本文使用预训练的深度自编码器(deep auto-encoder,DAE)[14]提取网络流量特征,使用深度神经网络(deep neural network,DNN)[15]对特征集进行微调,如图2所示。DAE由编码器与解码器构成,其瓶颈层可对输入特征集进行降维处理,DAE提取的特征集结果包括特征编码、网络权重及网络偏置,再将特征集传入深度神经网络进行微调。假设DAE的输入数据为X,输出数据为X′,基于DAE的特征集训练DNN。在DNN的训练阶段采用PSO搜索DNN的超参数,提高网络攻击的检测率。 图2 基于深度自编码器的特征提取 DAE包含多个隐藏层,从输入层到隐藏层为编码阶段,隐藏层到输出层为解码阶段,DAE的结构如图3所示。 图3 深度自编码器的结构 假设DAE共有5个隐藏层,那么DAE包含3个编码器-解码器组,3个编码器分别记为E1、E2、E3,那么中间层的编码结果可表示为Z=E3(E2(E1(X)))。 第1个编码器的输出可表示为h=f(WX+b), 其中W为权重矩阵,b为偏置向量,X为输入向量。下一个编码器的输出可表示为 h(l+1)=f(W(l)·h(l)+b(l)) (3) 假设3个解码器分别为D1、D2、D3,解码器的输出结果可表示为X′=D1(D2(D3(E3(E2(E1(X))))))。 自编码器的各隐藏层运算可表示为X′=f(WT×h+b′), 解码函数可表示为D3=f((W(3))T×Z+b(3)′),D2=f((W(2))T×D3+b(2)′),X′=f((W(1))T×D2+b(1)′), 其中f() 为隐藏层的激活函数。 DAE的损失函数评估了输入X与重建X′间的距离,其数学模型可表示为 (4) 假设输入数据的样本数量为m,可将DAE的损失函数重写为 (5) 式中:x表示将输入数据映射到[0,1]区间的结果。采用非线性sigmoid函数作为DAE隐藏层的激活函数。 通过反向传播更新神经网络每个节点的权重与偏置,损失函数的最优值接近零,此时DAE瓶颈层Z的输出即为输入数据的低维特征集,将Z的输出传入DNN分类器,该处理机制也称为迁移学习。通过迁移学习将自编码器的编码结果、权重与偏置迁移至DNN进行特征微调与分类。 采用深度神经网络根据输入特征检测流量的攻击类别,深度神经网络的结构如图4所示。 图4 深度神经网络分类器的结构 深度神经网络的输入数据是由DAE迁移过来的特征集、DAE权重与偏置。深度神经网络DNN的输出y′可表示为 y′=f(W(l)·h(l)+b(l))=f(z(l+1)) (6) 式中:l+1为深度神经网络的最后一层。 DNN的输出层采用softmax函数对数据进行分类。假设由DAE迁移至DNN的权重为W(1),W(2),W(3),偏置为b(1),b(2),b(3)。DNN的损失函数为多分类交叉熵函数,输出层节点采用softmax函数。 2.3.1 粒子群优化算法 粒子群优化算法(particle swarm optimization,PSO)[16]是由Eberhart和Kennedy提出一种基于种群的随机优化技术。PSO模仿自然界群体合作寻找食物的过程,PSO各粒子通过学习其自身经验与社会经验来不断改变其搜索过程。PSO算法的运行流程可参考文献[17]。 PSO第i个粒子在第k次迭代的速度更新模型可表示为 (7) 第i个粒子在第k次迭代的位置可表示为 xi(k)=xi(k-1)+vi(k) (8) 2.3.2 基于PSO的深度神经网络训练方法 图5是基于PSO的深度神经网络训练基本流程。PSO对DNN结构参数与超参数进行优化,每个粒子对应一个可能解,DNN最后一层softmax层计算每个数据样本的分类概率,将DNN的分类准确率作为PSO粒子的适应度。PSO迭代地优化DNN的超参数,最终收敛于最优适应度,该最优解为最佳的DNN网络结构。 图5 基于PSO的DNN训练过程 2.3.3 PSO种群初始化 将PSO的解表示为向量形式,如图6所示。 图6 PSO的解表示 表1是每个超参数的搜索空间,采用PSO搜索深度神经网络的5个超参数,分别为:DAE数量、隐藏层节点数量、学习率、批大小、隐藏层激活函数。 表1 PSO的搜索空间 2.3.4 PSO参数设置 表2是PSO的参数设置。PSO种群的总维度为5×8=40,最大迭代次数为50。 表2 PSO参数设置 PSO的惯性权重采用sigmoid函数,该函数能够在全局搜索与局部开发之间取得较好的平衡,并能防止早熟收敛。惯性权重函数定义为 (9) 式中:t为当前的迭代次数,tmax为最大迭代次数,α参数设为0.2。 2.3.5 PSO适应度评价 DNN最后一层softmax层输出每个样本的分类准确率,准确率越高则粒子的适应度越高。PSO的适应度函数可表示为 fit(pj)=DNN(dc,hc,lr,ps,af) (10) 式中:dc为DAE数量,hc为隐藏层节点数量,lr为学习率,ps为批大小,af为激活函数。 2.3.6 PSO搜索流程 图7是PSO搜索DNN超参数的运行流程。 算法2是基于PSO的DNN优化算法伪代码。PSO种群初始化成表1中的随机值,然后评价每个粒子的适应度,更新每个粒子的速度与位置,每次迭代结束更新全局最优粒子。 算法2:基于PSO的DNN优化算法 输入:最大迭代次数,超参数搜索空间 输出:最佳DNN超参数。 (1)随机初始化粒子群的各个粒子; (2)while (未达到最大迭代次数) do (3) 计算ω; (4) foreachpifromp1topmdo (5) 评价pi的适应度; (6) 更新个体最优pbesti; (7) 更新粒子速度vi与位置pi (8) endfor (9) 更新全局最优gbest; (10)end while; (11)returngbest; 本文的仿真环境是Windows 10操作系统,处理器为Intel Core i7-10700,主频为2.9 GHz,内存为32 GB。神经网络的编程语言是Python,神经网络搭建环境为谷歌开发的TensorFlow version 2.1.0[18],另外采用了Keras神经网络库[19]。 采用CSE-CIC-IDS2018作为IDS的实验数据集,该数据集是通信安全机构与加拿大网络安全研究所的合作项目,其数据样本来源于真实网络,下载地址为(https://registry.opendata.aws/cse-cic-ids2018/)。该数据集共有16 232 943个数据样本,训练集共有1 619 315个数据样本,测试集共有404 836个数据样本。表3总结了CSE-CIC-IDS2018数据集的分布情况,共包含15种攻击。 表3 CSE-CIC-IDS2018数据集的分布情况 采用以下性能指标对IDS进行评估: 准确率 (11) 式中:TN与FN分别为真负样本与假负样本的数量,TP与FP分别为真正样本与假正样本的数量。 F-score (12) CSE-CIC-IDS2018数据集的数据量较大,每次迭代训练深度神经网络的时间较长,为减少训练时间,将神经网络的学习率设为较大值{0.001,0.01,0.1}。图8总结了粒子群每次迭代中DNN模型训练的检测准确率,由图中可知,由于限定了DNN各超参数的搜索空间,因此DNN可在第35~40次迭代达到收敛。PSO搜索的最优超参数集见表4。 表4 CSE-CIC-IDS2018数据集的训练结果 图8 DNN训练的收敛曲线 在测试集上对所训练IDS进行攻击检测实验,分别统计15种攻击的检测准确率,结果如图9所示。由图中可知, 图9 测试集不同攻击的平均检测率 本文IDS对Bot、DDOS attack-HOIC、DoS attacks-GoldenEye、DoS attacks-Slowloris、SQL Injection、SSH-Bruteforce的检测准确率为100%,对Brute Force-Web、Brute Force-XSS、DDOS attack-LOIC-UDP、DDoS attacks-LOIC-HTTP、Dos attacks-SlowHTTPTest、FTP-BruteForce的检测准确率也较高,但对Benign与Infilteration的攻击检测率低于98%。 为评价本文IDS对静态网络数据的检测性能,选择卷积神经网络(convolutional neural network,CNN)[20]、时空神经网络(hierarchical spatial-temporal features using deep neural networks,HAST-IDS)[21]以及小波神经网络(wavelet neural network,WNN)[22]共3个静态IDS与本文系统进行对比实验。文献[20]采用卷积神经网络提取网络传输数据的特征,并在最后一层采用softmax层对输入样本进行分类;文献[21]采用深度神经网络学习网络传输数据的时域特征,所提取的特征考虑了数据的时域相关性与空间相关性;文献[22]采用小波神经网络学习网络传输数据的非线性关系,再传入分类器对输入样本进行分类。CNN[20]设为5层网络,各层的filter数量分别为256、128、64、32与16,各层的核大小分别为16、8与3。HAST-IDS[21]与WNN[22]的超参数采用各文献所推荐的值。 图10是4个IDS在静态CSE-CIC-IDS2018数据集上的测试实验结果,分别统计了平均检测准确率与平均F-score值。由于HAST-IDS与WNN均为一个隐藏层,HAST-IDS通过时空相关性来学习数据的非线性关系,而WNN通过小波函数来学习数据的非线性关系,这两个网络的非线性拟合能力不足。由于DDOS attack-HOIC、DDOS attack-LOIC-UDP、DDoS attacks-LOIC-HTTP、DoS attacks-GoldenEye、DoS attacks-Hulk、Dos attacks-SlowHTTPTest、DoS attacks-Slowloris均属于DDOS攻击,这些攻击类别之间的相似性较高,因此HAST-IDS与WNN对此类攻击的检测准确率较低。CNN网络共有5层卷积层,其卷积运算能够拟合网络传输数据的非线性关系,因此对CSE-CIC-IDS2018数据集的检测性能明显优于HAST-IDS、WNN。本文IDS采用深度自编码器提取网络传输数据的特征,再将自编码器的特征集、DAE权重与偏置迁移至深度神经网络对特征进行微调处理,有效利用了深度自编码器的特征学习能力以及深度神经网络的数据处理能力,使本文IDS的攻击检测性能优于CNN网络。 图10 IDS的对比实验结果 为评价本文IDS对未知攻击的检测能力,本文将攻击编号1-10的训练集作为训练数据,将全部15个攻击的测试集作为测试数据,评估IDS对未知攻击的检测性能。选取Scalable Network[12]与Zero-Shot Learning[23]两个IDS系统与本文IDS进行对比实验,Scalable Network通过异常检测触发神经网络的扩展与更新,从而支持对未知攻击的检测;Zero-Shot Learning通过零次学习使IDS能够对未知数据类别进行分类,为IDS引入了推理能力。本文IDS强化学习的效用阈值设为训练阶段检测性能的80%。 图11是3个IDS对未知攻击检测的平均性能,图11(a)与图11(b)分别统计了对5个未知攻击类型的平均检测准确率与F-score值。Scalable Network通过异常检测触发神经网络的扩展与更新,由于5种未知攻击与训练集中攻击的相似性较高,未能及时触发Scalable Network进行网络更新,导致Scalable Network对未知攻击的判别能力较弱。Zero-Shot Learning所采用的零次学习属于一种迁移学习技术,将训练集上学习的映射关系迁移至其它攻击类型的识别。由图11可知,Zero-Shot Learning对未知攻击的识别效果优于Scalable Network技术。本文IDS利用强化学习技术感知环境的变化,在运行过程中因出现未知攻击导致检测准确率下降,此时强化学习的效用下降,后台安全专家降低对前端的奖赏,当效用值小于预定的效用阈值时,启动深度自编码器与深度神经网络重新训练DAE与DNN,使IDS具备检测未知攻击类型的能力。综合图11的结果可知,本文IDS对未知攻击类型的检测准确率与F-score值均优于Scalable Network与Zero-Shot Learning。 图11 IDS对未知攻击的检测性能 IDS作为第一道防线,应能主动发现可疑行为以保障网络的平稳运行,其中发现新型攻击是当前IDS面临的一大挑战。为应对网络攻击不断升级演变的问题,结合粒子群优化算法与强化学习提出一种半监督学习的攻击检测系统。该IDS系统的优势在于: (1)在网络传输数据的特征提取方面,利用了DAE的特征提取能力,DAE对网络传输数据的泛化能力强于CNN与RNN等模型。 (2)在网络传输数据的分类器方面,利用深度神经网络对DAE输出特征进行微调与分类,增强了特征的判别力。 (3)在对未知攻击的检测方面,利用强化学习技术感知环境的变化,在运行过程中因出现未知攻击导致检测准确率下降,后台安全专家降低对前端的奖赏,当系统效用值小于预定的效用阈值时启动深度自编码器与深度神经网络重新训练DAE与DNN,使IDS具备检测未知攻击类型的能力。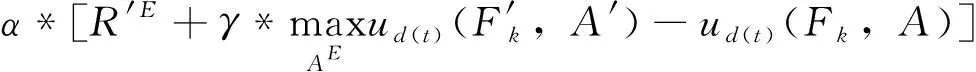
2 神经网络的方法与设计
2.1 基于深度自编码器的特征提取
2.2 基于深度神经网络的攻击识别
2.3 基于粒子群优化算法的网络训练方法
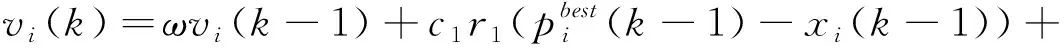

3 仿真实验与结果分析
3.1 仿真环境与数据集
3.2 IDS评价标准
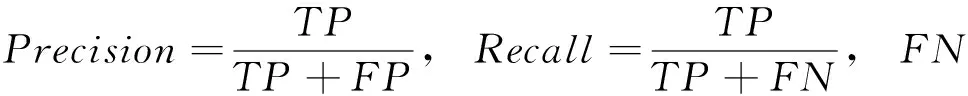
3.3 已知攻击实验
3.4 未知攻击实验

4 结束语
