基于内容发布订阅系统中高并发事件匹配算法
2022-12-30张志远
张志远,钱 玭
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
分布式发布订阅系统是一个多对多的异步消息(事件)传递模型,在时间、空间和同步上完全解耦,同时还具有易扩展和多对多的通讯特点[1],被广泛应用于各种大规模数据交换平台中,如在线广告[2]、信息过滤[3]、移动消息推送[4,5]、物联网传输[6,7]等。在整个发布订阅系统中,事件匹配算法作为核心组件,是保证系统匹配性能的关键因素。发布订阅系统按照消息类型可分为3类:基于主题的、基于类型的和基于内容的[8]。与基于主题和基于类型的系统相比,基于内容的发布订阅系统订阅信息的描述更加详细,表达能力也更强。
近年来,学术界提出的事件匹配机制按照索引结构大致可以分为两个方面:
(1)树形索引结构。Be-Tree[9]是一种动态树索引结构,采用了一种两相空间切割技术。通过属性来划分订阅区间,对属性和属性值约束,快速过滤不满足订阅来提高匹配效率。H-Tree[10]是哈希表和哈希链的结合。在每个索引属性的值域被分成几个部分重叠的单元格后,所有索引属性的哈希列表都链接到哈希树中。CBPS[11]提出了一种树匹配结构四叉树。将谓词匹配问题转化为查询问题,并对这个区间进行划分。
(2)线性索引结构。TAMA[12]使用分层索引表来存储订阅,将每个属性的范围从多层索引结构的顶部到底部分成多个单元格。REIN[13]将事件匹配问题转化为矩形相交问题,对于每个属性,构建两个桶列表。一个桶列表用于范围约束的低值,另一个用于范围约束的高值。PHSIH[14]通过水平分割数据结构的索引层次来实现并行化,以支持多个线程在公共数据结构上并行执行匹配任务。GEM[15]设计了一种基于解析几何的索引结构,将订阅的谓词映射到每个维度的三角形区域。
以上算法研究只关注单个事件与订阅之间的匹配,在高并发情形下多个事件批量到达时,对单个事件逐一进行匹配的速度可能落后于事件的到达速度,导致事件不能及时处理。为此,关注多个事件之间的匹配关系,在REIN算法的基础上,提出一种面向高并发事件的匹配算法HCEM,旨在解决传统算法并行能力上的缺陷。
1 相关概念及索引结构的构建
1.1 基本定义
定义1 事件
事件由发布者发布,通常也称之为消息、通知和发布。属性用attr表示,属性值用value表示,事件E是由多个attr=value的属性值对的连词,以及一个标识事件的事件号id组成,规定每个属性在事件中出现且仅只能出现一次。例如: E={id=1,temperature=25,humidity=50} 表示一个事件号为1的天气事件,温度等于25 ℃,湿度50%。定义A={a1,a2,a3,…,am} 为事件的属性集合。
定义2 约束
约束是指A上的某个属性需满足的条件。简单约束通常表示为 {attr,operator,value,type} 的形式,其中operator是操作符,包括≥、≤、=,type表示属性的数据类型,和REIN算法一致本文仅考虑integer型。范围约束通常表示为 {attr,vlow,vhigh,type} 的四元组形式,其中vlow表示下界值,vhigh表示上界值,并且vlow始终小于等于vhigh。给定属性的取值范围,则简单约束可用范围约束定义,例如:数据类型为integer的温度值域为[0,100],那么简单约束 {temperature,≥,20,integer} 可转换为 {temperature,20,100,integer}。
定义3 订阅
订阅是用户对事件兴趣的表达,由多个合取的约束构成,即必须同时满足所有的约束条件。每个订阅由一个唯一的订阅号进行标识,订阅中的约束数量不大于m,其中m为事件中出现的属性个数。
定义4 事件匹配
给定一组n个订阅S={S1,S2,S3,…,Sn} 和事件E,从S中检索与事件E匹配的所有订阅的过程称为事件匹配。匹配订阅集Se是订阅集S的一个子集,Se⊆S

1.2 索引结构设计
为实现高效事件匹配,采取负搜索策略,即在事件匹配过程中及时删除所有不匹配订阅。本节对索引结构作详细介绍和说明。
索引结构由多个索引桶列表组成,每个索引桶里储存映射到该索引值的所有谓词值value和订阅号id。索引桶列表的个数为2 m,其中m为事件中出现的属性个数。对于每一个属性,都为其构建两个索引桶列表Llow和Lhigh,Llow用来存储所有订阅谓词的下界值,Lhigh用来存储所有订阅谓词的上界值。同时为每个事件创建一个bits集合,大小为订阅数量,用来标记不匹配订阅。
对于订阅Sj∈S中的任意维度属性ai∈A,采用离散化属性值方法将范围约束的谓词vi映射到相应的索引桶中(假设谓词的下界值为vilow,上界值为vihigh,属性ai的值域为 [Ui,Ri], 订阅Sj有唯一的标识符Sj·id),具体计算过程如下,其中T为索引桶个数
(1)
(2)
例如对于表1中的15条订阅,构建的索引结构如图1所示。为属性a1创建两个索引桶链表La1low和La1high,假设T=7,即为La1low和La1high分别划分7个索引储存桶,每个索引桶由唯一索引值标识,索引桶储存所有映射到索引值的谓词值value和订阅号id。

表1 订阅清单

图1 HCEM索引结构
1.3 订阅插入
步骤1 输入订阅s;
步骤2 判断订阅中谓词约束属于简单约束还是范围约束,简单约束转步骤3,范围约束转步骤4;
步骤3 若约束操作符operator为“≥”,令vlow=va-lue,vhigh=Ri;若约束操作符operator为“≤”,令vlow=Ui,vhigh=value;若约束操作符operator为“=”,令vlow=vhigh=value;
步骤4 把上下界值vhigh和vlow代入式(1)和式(2),分别计算谓词映射到维度ai上下界索引结构中的位置Tihigh和Tilow;
步骤5 把约束值vi和订阅号id插入到索引值相对应的储存桶中。
例如,假设表1中属性a1的值域为[0,70],则对于约束S1,下界值vlow=8映射到La1low索引桶0中储存,上界值vhigh=24映射到La1high索引桶2中存储。
2 HCEM
HCEM(high concurrency event matching)模型设计有两个重要指标。首先,匹配速度对发布订阅系统的影响至关重要,因此模型的首要目标是追求高匹配速度;其次,匹配性能必须稳定,匹配时间不会随着订阅数量、属性数量等因素的增加而急剧上升[16]。为了追求高匹配速度和减轻订阅匹配的影响,模型采用了负搜索策略[17]。其基本思想是从订阅集中快速检索出不匹配订阅并将其从搜索空间中剔除,最后剩下的即为匹配订阅。
2.1 动态调整机制
为提高系统在事件高并发情形下的处理能力,设计了动态调整机制。针对某时刻内同时到达的多个事件,考虑事件之间的内在特性,动态调整事件进入搜索空间的顺序。随着搜索的不断深入搜索空间不断减小,从而减少不必要的遍历,提高事件匹配效率。
当事件同时到达时,事件匹配按照属性维度进行。依次在属性ai(i=0,1,…,m)上对事件值进行排序,确定事件进入属性ai搜索空间的顺序。根据负搜索策略,找出与事件不匹配的订阅,所以,在下界值索引结构中找出大于事件值的订阅,在上界值索引结构中找出小于事件值的订阅。若存在事件ej>ek,那么在下界值索引结构中满足ej的订阅必定也满足ek,在上界值索引结构中满足ek的订阅必定满足ej。故而确定在下界值索引结构中,事件值越大,越优先进入搜索空间。相反,在上界值索引结构中,事件值越小,事件就越先进入搜索空间。
例如,假设在属性a1上同时到达3个事件 {e1(a1=57), e2(a1=15), e3(a1=32)}。 根据动态调整机制,在下界值索引结构中事件进入搜索空间的顺序为e1→e3→e2。如图2(a)所示,因为区间X1的值始终大于区间X2的值,符合事件e1的订阅必定也符合事件e3,所以,事件e3的遍历空间为X2,同理,事件e2的搜索空间为X3。在上界值索引结构中,事件进入搜索空间的顺序为e2→e3→e1。如图2(b)所示,因为区间X1的值始终小于区间X2的值,符合事件e2的订阅必定也满足事件e3,所以事件e3的遍历空间为X2。同理,事件e1的搜索空间为X3。如此,在上下界索引的遍历过程中,排序后只需从头到尾扫描一遍索引结构,因此大大缩减了遍历空间,减少不必要的搜索,从而提高事件匹配效率。

图2 动态调整机制
2.2 事件匹配
给定同时到达事件集合 E={e1,e2,…,en}, 其中事件e={a1=v1,a2=v2,…,am=vm}, 对每个约束(含下界和上界)的谓词与事件值进行比较,发现和标记所有与事件不匹配的订阅。具体事件匹配算法见表2。

表2 事件匹配算法
例如,同时到达事件为E={e1(a1=57),e2(a1=15),e3(a1=32)}, 查找图2中与事件匹配的订阅。根据事件匹配规则,先为每个事件建立bits集,并初始化为0。然后根据动态调整机制,确定事件进入下界值索引结构顺序为e1→e3→e2。首先事件e1进入,先在索引桶b5中查找,没有找到不匹配订阅,然后遍历X1区间所有订阅S10,并在事件e1、e2、e3的bits集中标记为1。其次事件e3进入,先在索引桶b3找到不匹配订阅S8、S13并在bitse3集中标记为1,然后遍历X2区间所有订阅S6、S7、S12、S14,并在事件e3、e2的bits集中标记为1。最后事件e2进入,在索引桶b1找到不匹配订阅S3并在bitse2集中标记为1,然后遍历X3区间的所有订阅S2、S4、S5、S8、S9、S13,并在事件e2的bits集中标记为1。上界值索引结构中匹配同理。最终结果如图3所示,bits集中值为0的即为每个事件的匹配订阅。

图3 事件匹配bits集
2.3 事件匹配性能分析
为分析事件匹配性能,设同时到达的事件数为h,每个事件中的属性数为m,订阅数为n,每个订阅中的谓词数为k,储存桶个数为b。为每个属性创建两个由b个索引桶组成的索引结构。储存桶的总数为m*b,订阅的谓词总数为n*k,假设谓词被均匀的插入到储存桶中,则每个储存桶里的谓词数量为
事件匹配成本主要由两部分组成,第一部分是在不完全匹配的索引桶中依次比较找出不匹配订阅的比较成本,第二部分是在完全不匹配的索引桶中遍历所有订阅的遍历成本。设比较一个谓词(不完全匹配时)的单位时间为α,遍历一个谓词(完全不匹配时)的单位时间为β。在最坏情况下,HCEM的匹配时间为
THCEM=2qαmh+2bqβm
其中,前一部分为比较时间,因为比较操作只在上下界索引结构各一个索引桶中完成,所以单个事件在单个属性上的比较时间为2qα,总的比较时间为2qαmh。后一部分为遍历时间,最坏情况下,遍历索引结构中的所有订阅,所以总遍历时间为2bqβm。相比之下,REIN算法的匹配时间为
TREIN=2qαmh+bqβmh
与REIN算法相比,HCEM与REIN有着相同的比较时间,但HCEM算法的遍历时间仅为REIN的2/h,即当同时到达的事件越多时,HCEM的匹配时间相对于REIN就越短,匹配性能更具优势。原因在于HCEM算法大大减小了遍历空间,从而减少大量不必要的遍历,事件匹配速度也得到很大程度提高。
3 实 验
3.1 实验设置
为全面评价HCEM的匹配性能,我们在不同实验场景下对HCEM和其它算法进行了大量对比测试。实验环境为:CPU AMD Ryzen7 4800H 2.90 GHz,RAM 16 GB,Windows10 64位。所有代码均用C++编写。
本文选择TAMA、H-Tree、REIN这3种匹配算法与HCEM进行比较。TAMA是一种近似匹配和转发引擎,使用层次索引表来转发订阅。H-Tree是一个由多个哈希列表组成的组合,通过对属性进行新的划分来建立哈希列表。REIN为每个属性构建高低两个约束储存链表,将事件匹配问题转化为矩形相交问题。这些算法的设置如下:TAMA中的离散化水平设置为γ=13;H-Tree中单元格数和索引属性数设置为τ=δ=6;REIN中索引桶数量设置为b=1000。
实验的3个重要指标是事件匹配时间、订阅插入时间和订阅删除时间,在这个3个指标中,事件匹配时间是评估事件匹配算法最重要的因素。HCEM算法与REIN算法索引结构基本一致,订阅的插入和删除也基本一致,本文只改变了其中的匹配算法,所以HCEM与REIN的订阅插入时间和订阅删除时间基本一致。
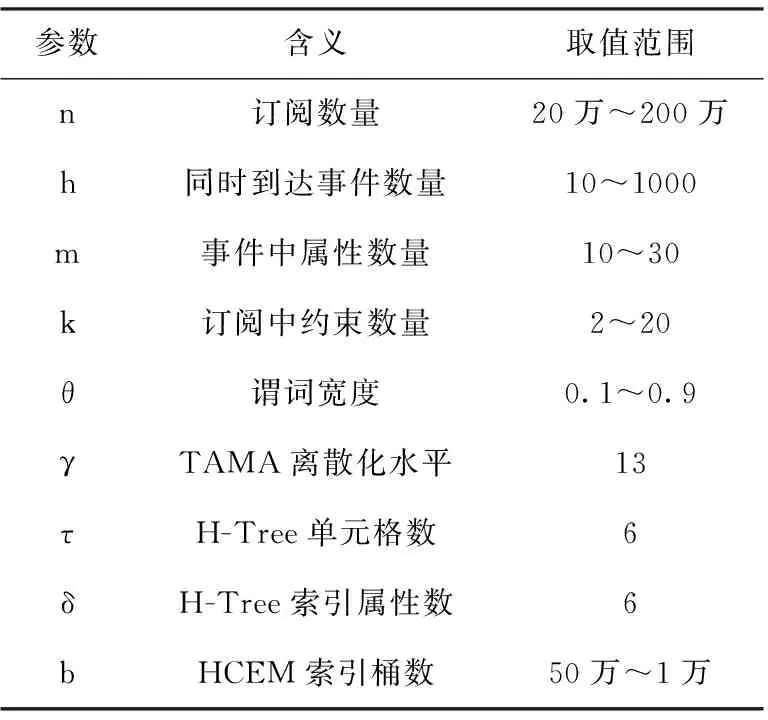
表3 实验参数设置
HCEM的匹配时间受多个参数的影响,包括订阅的数量、订阅中包含的约束数量、谓词宽度、输入的事件数和索引桶数量等。在实验部分,我们进行了大量实验来观测这些参数在不同设置下对事件匹配算法的影响。如无特殊说明,设置同时到达500个事件来测量每个实验中的事件平均匹配时间。实验中,除非有明确说明,否则事件属性、事件值、约束属性、约束值都随机生成。
3.2 索引桶数量对事件匹配的影响
对于HCEM,比较操作在每个属性的两个索引桶中进行,桶的大小势必会对事件匹配性能造成影响,为此我们设计实验验证最佳索引桶的个数。设置订阅数量n=200万,事件中属性数量m=20,订阅中约束数量k=10,谓词宽度θ=0.5,只改变索引桶b的数量。结果如图4所示,当订阅为200万时,最佳的索引桶数为1000。当桶数大于1000时,匹配事件不再随着桶数的增加而减少,匹配性能反而下降。原因为当订阅数量较大时,需要更多的索引桶来提高匹配效率,但随着桶的增加,桶之间的切换成本就会增加,抵消减少比较操作所获取的好处。所以,当桶的数量达到一个临界值时,匹配性能就会下降。
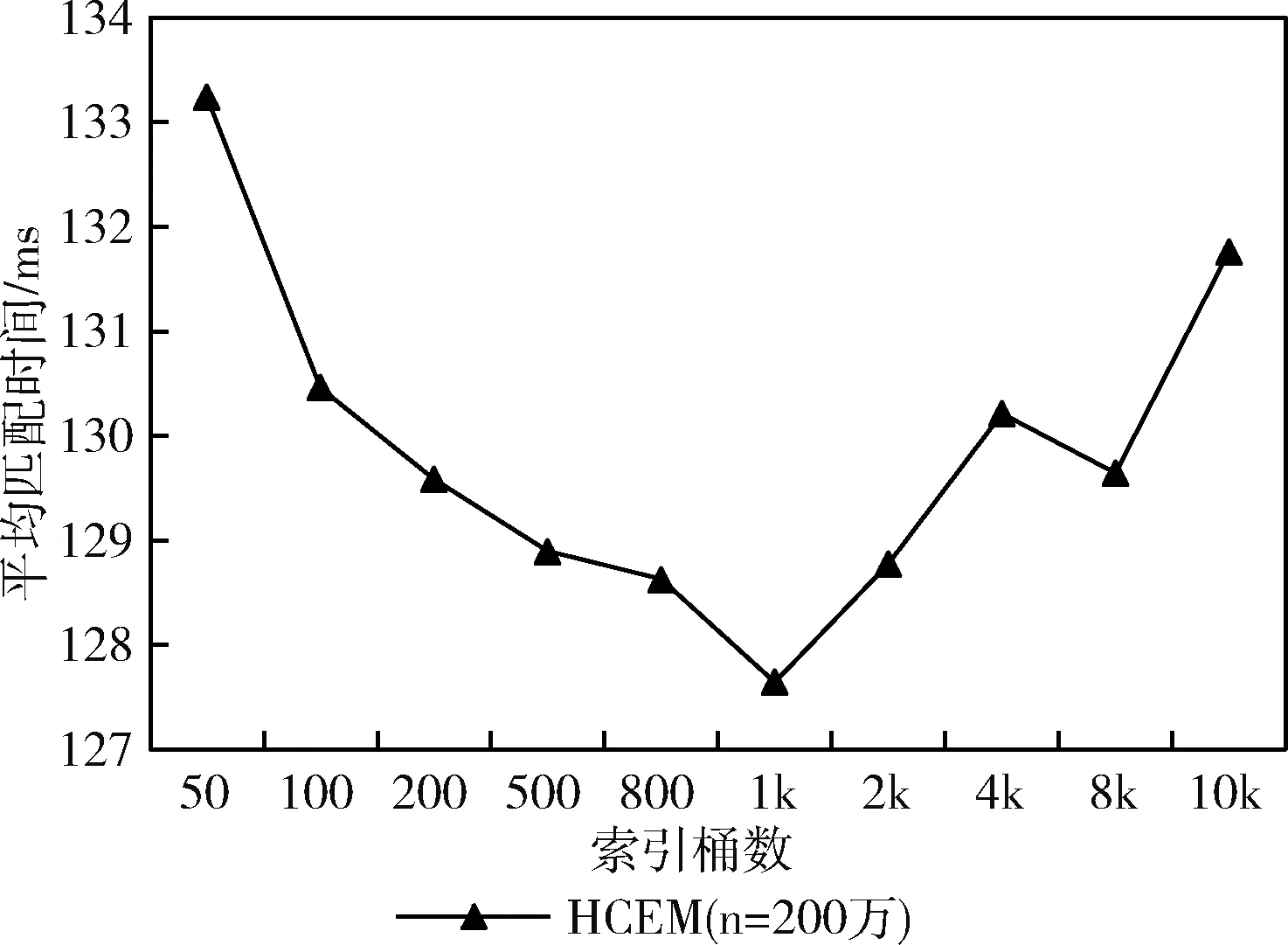
图4 索引桶数量的影响
3.3 事件批处理能力
HCEM利用动态调整机制确定事件进入搜索空间的优先级,相对于其它算法来说,最大的优势在于其批处理能力。本节通过实验研究4种算法的批处理能力,设置事件中属性数量m=20,订阅中约束数量k=10,谓词宽度θ=0.5,索引桶数b=1000,订阅数量n=100万,只改变同时处理的事件数量。实验结果如图5所示,4种算法的匹配时间都随着事件数的增多而增加。当同时到达的事件越少时,HCEM与REIN的匹配时间差距越小,当事件为1时,退化为REIN。当同时处理1000个事件时,相比于TAMA、H-Tree和REIN,HCEM匹配时间分别是这3种算法的12.1倍、6.4倍和2.2倍。由此可见,HCEM对事件批处理的能力大大优于其它算法。
图5 批处理性能
3.4 订阅数对事件匹配时间的影响
在本实验中,我们设置事件中属性数量m=20,订阅中约束数量k=10,谓词宽度θ=0.5,索引桶数b=1000,只改变订阅数量,观察订阅数对事件匹配算法性能的影响。给定谓词宽度,为保证下界值的分布和上界值分布相同,范围约束的下界值从[0,1-θ]中随机生成,上界值从[θ,1]中随机生成。
结果如图6所示,总体而言,所有匹配算法的事件匹配时间都随着订阅数量的增加而增加。与其它3种匹配算法相比,HCEM算法的性能受订阅次数的影响最小。当订阅为200万时,HCEM相比于TAMA、H-Tree、REIN的事件匹配时间分别下降91.04%、83.17%和47.02%,平均下降89.59%、81.75%和47.11%。

图6 订阅数量对匹配时间的影响
为了测试匹配算法性能的稳定性,我们对匹配时间的最小值、最大值和标准差进行分析,结果见表4,相比于TAMA、H-Tree、REIN,HCEM的标准差小了11.3倍、6.1倍和1.9倍。此外TAMA、H-Tree、REIN和FEMA在匹配时间的最大值和最小值的差上。因此,HCEM可以为事件匹配提供更稳定的匹配性能,保证事件匹配的稳定性。

表4 事件匹配算法的性能
3.5 约束个数对事件匹配的影响
本节进行实验来评估约束个数对事件匹配性能的影响。实验中,设置谓词宽度θ=0.5,订阅数量n=100万,索引桶数b=1000,只改变事件属性m和约束属性k的数量,并保证k为m的一半。实验结果如图7所示,当订阅约束数量增加时,订阅的选择性降低[10],因此H-Tree的匹配时间首先随着约束数量的增加而迅速下降。一般情况下,4种算法的匹配时间都随着约束数量的增长而增长。当约束数量k=20时,HCEM分别是TAMA、H-Tree、REIN的9.8倍、4.3倍、2.0倍。

图7 约束数量对匹配时间的影响
3.6 谓词宽度对事件匹配的影响
给定事件值的分布,谓词宽度决定了订阅的匹配性,一般来说,宽度越大,订阅匹配性越高。本节通过实验研究谓词宽度对事件匹配的影响,设置事件中属性数量m=20,订阅中约束数量k=10,索引桶数b=1000,订阅数量n=100万,改变谓词宽度θ,结果如图8所示。TAMA的事件匹配时间随着θ的增长呈现线性增加;H-Tree的性能随着θ的增长呈指数级恶化,因为θ越大,越多的谓词落在相对少的单元格中,需要遍历的单元数呈指数级增加。当θ≥0.8时,内存被消耗完,因此图中没有结果。REIN和HCEM的匹配时间随着θ的增加而减少,因为不匹配订阅随着谓词宽度θ的增长而减少,需要遍历和被排除的订阅也就减少。当谓词宽度越大时,HCEM与REIN的匹配时间越接近。因为θ越大,谓词越集中分布在少量的索引桶中,动态调整机制作用越小。总体来说,HCEM相比于其它3种算法,谓词宽度对事件匹配时间的影响都是最小的。
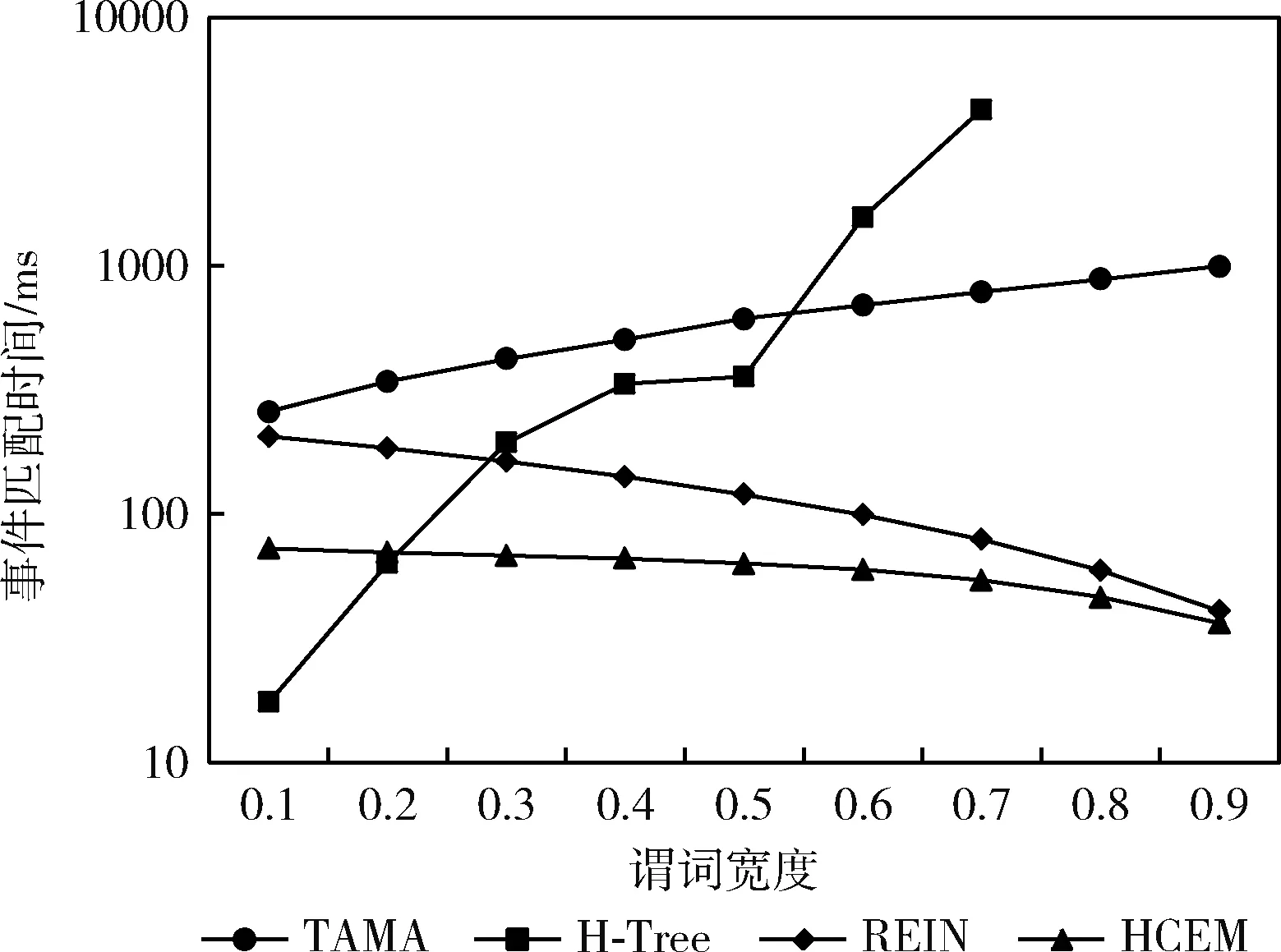
图8 谓词宽度对匹配时间的影响
4 结束语
本文提出了一种基于内容的发布订阅系统中高并发事件匹配方法HCEM。以往的算法中,事件之间是独立的,只考虑每个事件的匹配流程,忽略了事件之间的联系,系统的并行能力不能满足高并发事件的需求。为此,本文考虑事件高并发情况,设计动态调整机制对事件优先级进行处理,并采用负搜索策略进行事件匹配。为了评估HCEM的性能,进行了一系列综合实验。实验结果表明,该算法在匹配速度、性能稳定和批处理能力等方面均优于其它同类算法。同时也表明了HCEM具有快速性、稳定性和动态性等特征。
