一种运用SVM分类的多源态势数据关联方法*
2022-12-30李川,黄威,孙伟,郝欢
李 川,黄 威,孙 伟,郝 欢
(中国人民解放军31101部队,南京 210014)
0 引 言
现代战争是信息化条件下的一体化联合作战,需要多维统一战场态势情报的支持,而这种统一态势形成的关键是多源战场态势数据目标融合,核心问题是目标关联[1]。当前已有的态势数据源数量很多,如不进行有效去重,一方面多源态势情报难以形成合力,另一方面对每个态势源守控将耗费大量人力物力。
本文对现有战场态势系统中多源态势数据进行实验分析研究。为了叙述方便,将两种态势源简称为A源和B源:A源态势精度较高,但是缺少目标属性数据;B源态势精度较差,但由于是被动侦收获得,属性数据可信度较高。对这两种态势数据的目标进行关联识别,形成战场目标属性和位置统一的目标态势。
针对上述两种的态势数据存在时空和属性等差异性,一般国内外常采用的算法是目标多源航迹关联,如最近邻[2]、模糊关联[3]、MKNN算法[4]、拓扑关联算法[5]和灰色关联算法[6]等,但难以将不同复杂场景下相同目标的多源航迹进行自适应门限适配关联。本文使用支持向量机(Support Vector Machine,SVM),利用核函数的非线性分类特点将其应用到大时空差异多源态势关联中,通过设计态势航迹比对分类器,利用模拟真实数据样本训练学习后,可自动实现大差异下的多源态势目标数据关联比对识别。该算法推广能力强,在任意态势源融合中均可使用。
1 多源态势数据关联
多源态势数据关联主要针对战场态势形成过程中多路来源的海空目标航迹进行去处重复,将相同一个目标的不同路来源的目标轨迹自动判别为一个目标。基本原理如下:
(1)假设存在m路态势来源,m×nm个目标进行接收,其中m≥2,nm是第m路来源的目标个数;
(2)假设nm的组成为为第1个目标的第k个时刻的轨迹为

(3)假设真实的目标个数为p,那么需要合并掉m×nm-p个目标,形成真实目标的有限集合为设为T;
(4)假设第m路来源的第1的目标的k时刻的目标为

第n路态势来源的第1个目标的k个时刻的轨迹为

那么如果这两路目标是同一个目标,则应将T1={tm1,tn1}合并为一个目标作为战场态势中的第T1真实目标,T1∈T,合并的原则按照每一路来源的每一个目标轨迹特征信息相似进行分类,最终形成

根据上述假设,可知多源态势数据关联可以转化为一个分类问题,将不同路来源的目标轨迹进行分类。SVM在分类任务中具有其独特优势,下面采用SVM的方法进行解决该问题。
2 基于SVM关联算法
SVM方法由Vapnik提出,从严格的数学理论出发,论证和实现了在小样本情况下能最大限度地提高预报可靠性的方法。核心内容包括下列四个方面:经验风险最小化原则下统计学习一致性的条件;在这些条件下关于统计学习方法推广性的界的结论;在这些界的基础上建立的小样本归纳推理原则;实现这些新的原则的实际方法。本文主要借助SVM的方法中的小样本的归纳学习,获得的主要算法流程如下:
Step 1计算两条比对航迹的有效时间是否有交集,即是否有同时有效的时段,如果有效时间没有交集则跳到下一条航迹比对。其次将地图按经线和纬线划分为网格,当两条航迹进行比对时计算出两条航迹同时存在的时段,并查看在时段的起点和终点时刻,两条航迹的位置是否为同一网格或相邻网格。如果不是,则认为两条航迹不可能是同一目标(现代侦测手段,误差基本不可能超过1°,也就是60 n mile超过100 km),继续选比对源的下一条航迹进行比对。
Step2分类器训练时,需匹配源有m条航迹,比对源有n条航迹,则首先逐一从匹配源取出一条航迹。该航迹同比对源的n条航迹进行筛选,可剔除h条有效时间没有交集或未通过网格筛选的航迹。对其余有效航迹逐个进行预处理,可得到一组共n-h个特征样本。目测比对源所有航迹,找出与匹配源的那条航迹可能是同一目标的航迹,并将其对应的样本标记为识别同类,该组其余样本标记为识别异类。
需要注意的是,分类器训练时,每组样本不能只将目测最佳的样本标记为识别同类,而应当将目测该组可能匹配的所有样本都标记为识别同类,其余标记为识别异类。同时,在不同组目测划分时也需要尽可能地保持一致的划分标准。
Step3SVM匹配算法处理每组样本后能够得到的识别同类往往是一条或几条航迹,如结果是多条航迹,还需要结合其他已识别航迹来综合判定。SVM匹配算法核函数中的C和gamma 是两个必选的常数,分别为惩罚系数参数和间隔,其取值好坏直接影响到分类精度。本文采用一种基于交叉验证的网格搜寻方法来确定C和gamma的取值。
本文算法流程如图1所示。
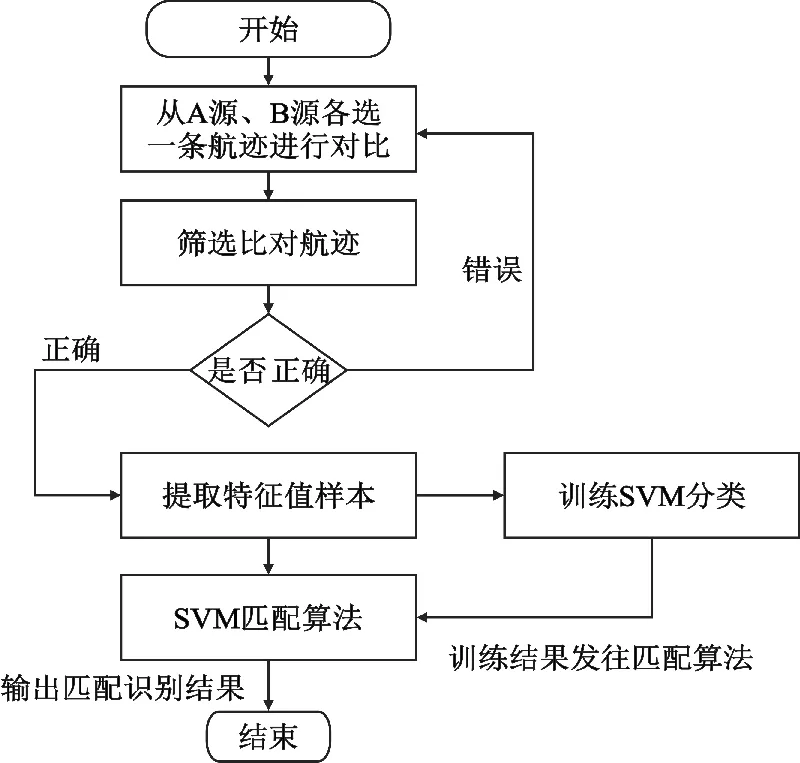
图1 运用SVM实现目标多源态势融合算法流程
算法核心步骤如下:
(1)比对航迹预处理
多源态势融合算法的核心是对于不同来源的态势航迹进行比对,寻找出属于同一目标的航迹。本文使用的方法是从某一源的态势里取出一条需要匹配航迹,用该航迹同其他源所有航迹进行逐一比对,选出有可能是同一条的航迹。
图2是两条不同态势源的航迹A和航迹B的经纬度图示。
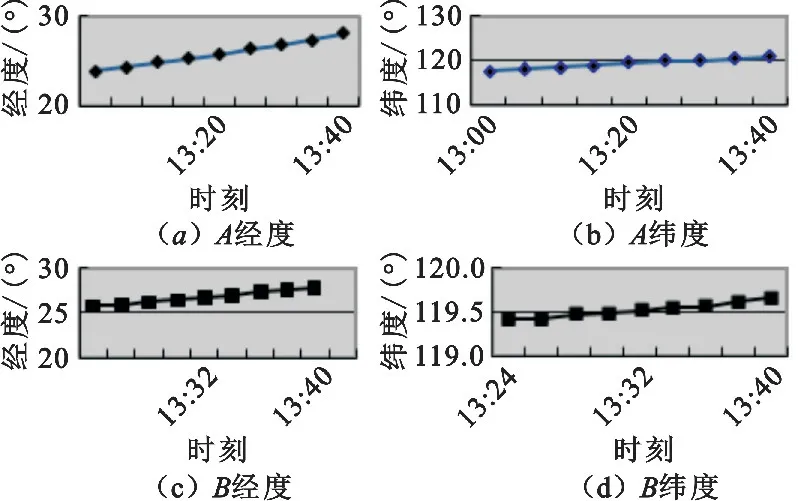
图2 航迹A、航迹B经纬度图示
由图可见,两条航迹进行比对时,只有两条航迹同时存在的时段才是有效的比对数据,两条航迹在同一时刻的比对点才是有效比对点,因此需要将航迹进行预处理。
根据已有的两条比对航迹的属性,计算出这两条航迹同时存在的时段,并近似计算出有效时段内每隔固定间隔(数据模型中使用30 s作为间隔,即使用每分钟的0 s和第30 s位置)态势目标所在的位置,最后以这些计算出的位置所组成的航迹作为比较航迹,如图3所示。
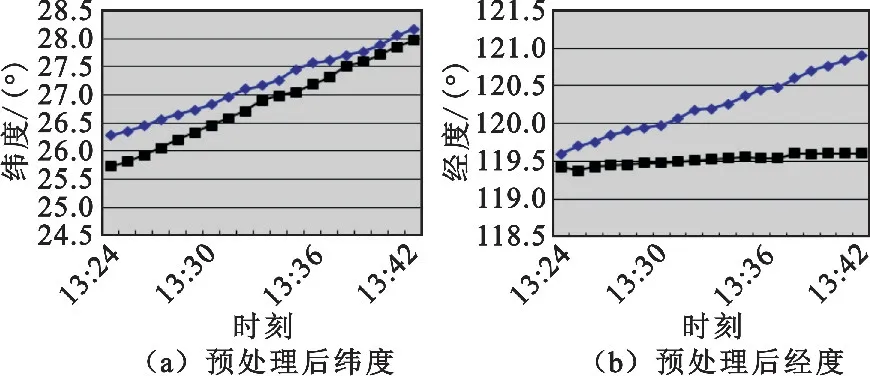
图3 航迹A和航迹B预处理后位置图示
当两条航迹所对应的比较航迹求出后,可进一步依据两点间距离公式计算比较航迹在每一间隔时刻对应的两点位置之间的距离。
图4为依据两条比较航迹在每一间隔时刻计算出对应的两点位置,所绘制的航迹点距离和时间关系图。至此,预处理工作完成。

图4 航迹点距离和时间关系图
(2)特征向量提取
依据预处理得到的数据结果,可进一步提取出比对的特征值,组成了一个特征向量,用于SVM的训练和分类。
①特征值1:平均距离R
两条比较航迹在同时有效的时段内,所有的固定间隔比较点的平均值就是平均距离。平均值越小,两条航迹为同一目标的可能性越大。采用欧氏距离,求出R公式如下:

式中:P(A)为A路源一个目标一段时间的轨迹点数;P(B)为与A路源相同的一段时间B路源一个目标的轨迹点数。
②特征值2:直线拟合灵敏度k
使用航迹点距离和时间关系图的数据,使用斜率k作为灵敏度特征值。当斜率k趋近于0时,拟合直线趋近于平行X轴,此时各个间隔两条比较航迹的距离接近相同,是同一航迹的可能大。
③特征值3:直线拟合误差的相关系数r
使用航迹点距离和时间关系图的数据 ,r表示两变量之间的函数关系与线性的符合程度,r∈[-1,1],r绝对值越接近于1,x和y的线性关系越好;如果r接近于0,可以认为x和y之间不存在线性关系。在航迹比较实验中r绝对值越高(如能达到0.999以上)说明航迹点距离和时间关系同拟合直线的线性相关越好,如此时拟合直线斜率趋近于0,则是同一航迹的可能越大。
④特征值4:两条航迹比较时段的起始和结束位置之间距离的比值c
依照两点距离公式,可分别求出需匹配航迹和选取比对航迹在比较时段内起始和结束位置之间的长度。通过计算可得到比值c越趋近于1,则同一航迹的可能越大。通过比值c这一特征值,可避免出现一条航迹是一个点而另一条航迹为以该点为圆心的圆弧,却又能较好满足前几个特征值这种情况。
3 实验结果与分析
实验数据选取某日A源态势和B源态势全天的模拟航迹数据来做比较。其中A源态势共有2 800条航迹,B源态势有569条航迹,排除只有一两个航迹点的航迹后,A源态势有效航迹为2 643条,B源态势有效航迹为479条。
实验中,从B源态势里依次取出一条需要匹配航迹,该条航迹同A源态势所有有效航迹进行逐一比对,可得到一组比对样本。比对样本总共可得到479组,实验随机选取88组样本作为训练用,剩下239组样本作匹配测试用。
SVM类型采用C_SVC,核函数采用RBF,通过交叉验证得到的C为512,gamma为0.5。
定义TP为判为同一目标正确的航迹关联个数(关联正确数),FP为不是同一个目标航迹的判为同一个航迹个数(关联错误数),TF为同一个目标航迹没有关联的个数(漏关联数),那么查准率公式为

查全率公式为

根据表1的实验结果,在239组样本测试集中,有153组目测有匹配目标中,有69组未能识别航迹,其中超过半数的航迹组是在同一个时段识别出错,初步分析原因是由于该时段数据质量不好或存在较大的时延,如忽略该时段,查全率预计超过90%。目测无匹配目标有部分匹配源航迹属于固定点目标,有部分轨迹由于航迹偏移较大,目测无法确认,还有部分无法在A源航迹中找到对应航迹。

表1 匹配数据测试实验结果
经实验测试,该匹配算法效果较好,具有较好的实用价值。
4 结束语
本文通过对战场多源态势目标航迹进行研究分析,提出了一种提取态势航迹比对特征并利用SVM进行分类比对识别相同目标航迹的方法。该方法首先对比对目标航迹进行预处理,再利用直线拟合等算法提取航迹点距离和时间关系特征,最后通过SVM对态势航迹比对特征进行分类,进而较为准确地识别出相同目标的航迹,形成战场态势一张图。通过实验分析验证,该方法融合效果较好,具有较强的实用价值。但算法不适用三维空间和复杂场景下的模型自适应训练和学习等问题,需要继续开展研究。
