基于竞争双深度Q网络的动态频谱接入*
2022-12-30梁燕,惠莹
梁 燕,惠 莹
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.信号与信息处理重庆市重点实验室,重庆 400065)
0 引 言
动态频谱接入[1](Dynamic Spectrum Access,DSA)在同一频段内为不同制式的技术动态、灵活地分配频谱资源,使次要用户(Secondary User,SU)可以搜索和使用主要用户(Primary User,PU)未使用的空闲信道[2]。DSA可以提高无线网络的频谱利用率,有助于满足对更多频谱的需求。
关于DSA问题已有大量研究:文献[3-4]将问题描述为多臂老虎机(Multi-armed Bandit,MAB)模型,通过对信道的观察,选择有最佳回报的信道;而文献[5-8]将频谱接入问题描述为频谱拍卖和租赁过程,提出拍卖模型的多信道分配策略,通过分配空闲频谱,使信道得到充分利用。上述方案需要提前知道信道状态信息,实际中,如果没有中央控制器,通常很难获得信道状态信息。即使在有中央控制器的情况下,交换这些信道状态信息也可能给底层网络带来沉重的控制开销,使其难以在实践中应用。
深度强化学习(Deep Reinforcement Learning,DRL)作为一种在未知环境下学习的方法,可以使DSA设备实时获得信道状态信息和有用的预测信息。将深度学习与Q学习(Q-Learning)相结合,使用状态作为输入、估计Q值作为输出,通过在线学习找到信道访问策略。文献[9]提出了一种基于Q学习的多用户接入多信道的动态频谱访问策略,使SU通过Q函数获取和更新环境信息,并利用用户协作学习机制来克服局部最优问题。文献[10]针对Q学习不能解决的大状态空间和状态的部分可观测问题,采用深度强化学习的方法使信道吞吐量达到最大。文献[11]提出了一种分布式强化学习算法及分布式的信道访问策略,保证对碰撞概率的高精度控制。文献[12-13]分别使用深度Q学习和双深度Q学习解决了用户接入多信道的问题。文献[14]讨论了多用户接入问题。除此之外,文献[15-16]中还提到了频谱接入前对频谱进行感知时存在感知误差的问题。
综合分析上述文献中所提出的多用户多信道DSA模型,文献[10-11]关注了SU接入时的碰撞,文献[15-16]解决了频谱感知错误问题,但是缺乏对两个问题联立解决的考虑。另一方面,对于处理DSA模型的方法,文献[9]和文献[11]中使用的Q网络(Q-Network)存在频繁查找Q表格会消耗大量时间和空间的问题,文献[10-12]使用的深度Q网络(Deep Q-Network,DQN)存在对Q值的过估计使接入策略不能达到最优的问题,而文献[13]使用的双深度Q网络[17](Double DQN,DDQN)是解决过估计的良好方法。
因此,本文针对多个SU接入多个信道的场景,建立一个同时考虑感知错误与避免碰撞的DSA模型。对于这个模型,提出双深度Q网络和竞争Q网络[18](Dueling DQN) 结合的竞争性DDQN网络(Dueling DDQN)学习框架。通过动态感知、接入和反馈的学习过程,解决碰撞避免和存在感知错误的DSA问题。DDQN将动作的选择和评估分别用不同值函数实现,解决了值函数的过估计问题,而竞争性DQN解决了神经网络结构的优化问题。两种方法结合得到的竞争性DDQN可以有效解决过估计和网络结构优化的问题。
1 系统模型及问题描述
建立一个DSA模型,由C={1,2,…,i,…,C}个PU和N={1,2,…,j,…,N}个SU组成。假设一共有和PU数相同的C个无线信道C={1,2,…,i,…,C},使得每个PU在一个唯一对应的信道上进行传输以避免PU之间的干扰。其中i,j分别表示第i个PU(第i个信道)和第j个SU。用户使用随机访问协议在信道上传输数据。假定每个信道有空闲或繁忙两种可能的状态,每个PU也有空闲或占用信道两种状态。PU状态与信道状态一一对应且状态转换模式相同。每个PU的状态可以在空闲和占用之间转换,转换过程遵循马尔科夫转移概率。动态频谱接入过程的系统模型如图1所示。为了成功传输数据,所有SU旨在尽可能频繁地选择空闲信道。由于信道切换模式和其他SU的选择未知,因此每个SU每次只能尝试感知和访问不同的信道,并根据自己的观测尽可能确定信道模式。通过这种方式,SU可以了解所选信道处于空闲还是占用状态,进而做出接入动作。SU接入后得到回报,回报将反映接入动作的好坏。上述过程重复执行,SU作为竞争性DDQN智能体,根据历史学习经验,SU会在需要选择信道的下一时间段内预测信道状态,并增加选择空闲信道的可能性。
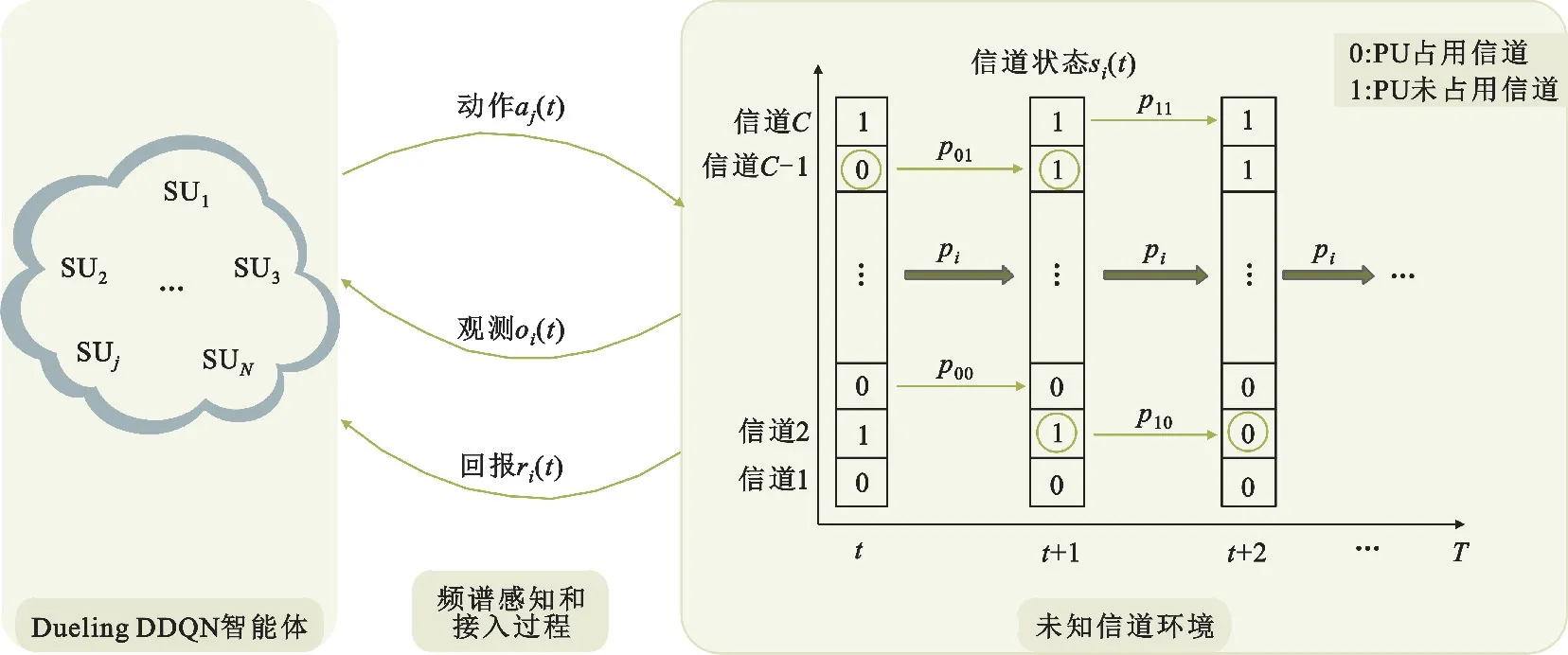
图1 动态频谱接入过程
由于每个SU只能学习所选信道的状态转换模式,即SU是对环境的部分观察,因此从C个信道中选择处于空闲状态的信道是部分可观测马尔科夫决策 过 程[19](Partially Observable Markov Decision Processes,POMDP)。也就是说,为了解决动态频谱接入问题,必须确定一种访问策略,该策略取决于每次感知之后SU得到的信道信息(即信道观测)、用户行为和回报。因此,在本节中将定义DSA模型用到的状态、观测、行为和回报,通过深度神经网络对这些数据的处理,找到最优的访问策略(即智能体根据信道状态执行动作后得到的累积回报的大小)。
1.1 信道状态
假设每个信道有两种可能的状态:空闲(用“1”表示)和繁忙(用“0”表示)。信道可能被PU占用,“空闲”表示信道被PU占用,SU无法访问该信道;“繁忙”表示PU未占用信道,SU可以访问该信道。信道状态的变化遵循马尔科夫转移概率,因此将每个信道的状态描述为如图2所示的两状态马尔科夫链。
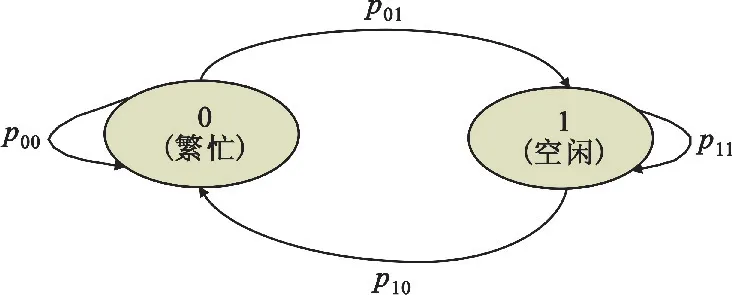
图2 两状态马尔科夫链
第i个信道的两状态马尔科夫转移概率表示为

其中,pxy={下一状态是x|当前状态是y},x,y∈{0,1}。
将第i个信道的状态表示为

那么所有信道的状态集合表示为
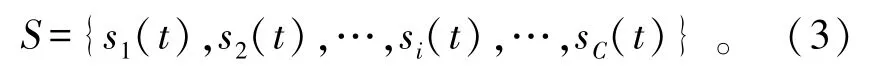
1.2 信道观测
为了成功传输数据,SU必须从对信道状态的观察中推断出信道转换模式。但是,由于频谱检测器并不完美,感知信道状态的结果可能存在误差。定义第i个信道上第j个SU的感知错误概率为Pji,所以感知正确的概率为
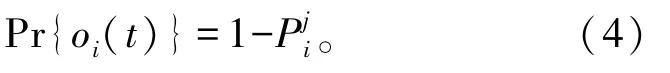
式中:oi(t)表示用户对每个信道的观测,定义为

由于SU不知道是否会发生感知错误,可以认为观测是对信道状态(1-Pji)的正确反应,因此在本文中,主要使用观测结果作为历史信道状态数据。将SU在t时进行感知的得到的可能存在感知误差的结果表示为
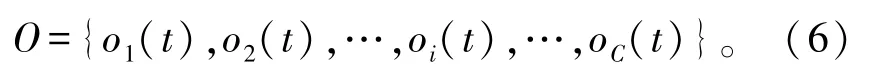
1.3 用户动作
执行完频谱感知后,每个SU根据感知结果决定保持空闲状态还是接入信道,有以下几种情况:
情况1:SU所选信道是空闲状态,并且没有其他SU选择该信道,说明SU之间没有碰撞,可以接入信道,这是DSA最想要达到的状态。
情况2:SU所选信道被PU占用,此时,由于SU感知到的信道是繁忙状态,因此SU不接入信道。
情况3:多个SU选择同一信道,可能发生SU之间的碰撞,此时让多个SU都不接入信道,以此来避免可能发生的碰撞情况。
用aj(t)=i表示在t时用户j选择接入信道i发送数据(对应情况1),aj(t)=0表示不能接入信道发送数据(对应情况2和情况3),从而将每个SU的动作表示为

1.4 回报
执行动作后,将根据动作情况获得回报。如果SU选择的信道是空闲状态,则传输成功,分配正奖励。如果SU选择的信道被占用或者SU之间发生碰撞,则传输失败,奖励为零。因此,将接入信道得到的回报表示为

得到回报的反馈后,每个信道的状态将根据马尔科夫链改变。在下一时隙SU将感知新的信道状态进行频谱接入。
1.5 策略
DSA的目标是提高频谱利用率,而利用率与选择空闲信道的频率相关,因此将DSA的目标转变为最大程度地增加选择空闲信道的频率。定义Mi(t)为在时间T内选择空闲信道的总次数:

因此,在时间T内每次选择空闲信道对总次数的贡献为1/Mi(t),所以将回报函数定义为

有限时间T内平均累积回报定义为
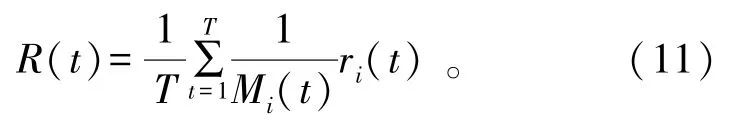
综上所述,DSA的最终目标转化为最大化式(11)中的回报。找到最优策略π*:O→A就能在任何状态下最大化回报。在POMDP中可以通过计算最佳Q值函数来找出π*:

将POMDP问题与深度强化学习结合后,找到π*的一种常见方法是Q学习,但是Q学习很难处理动作空间很大的DSA问题。幸运的是,DRL通过将强化学习与深度神经网络相结合的方法可以解决此问题。
2 竞争性DDQN框架
标准的Q学习和DQN中的最大运算符使用相同的Q值来选择和评估动作,它们倾向于选择过高的值,使性能有偏差。在此基础上,加入竞争Q网络,通过优化神经网络的结构保证算法的稳定性,使智能体学到更加真实的值。将两者结合得到的竞争性DDQN网络结构如图3所示。

图3 竞争性DDQN网络结构
将DSA和竞争性DDQN结合进行频谱接入的具体过程如下:
1 初始化 经验回放池D,存储经验样本的最大值为M
2 初始化 当前Q网络和目标Q网络的所有参数
3 重复 经验轨迹,从1到M:
4 初始化信道状态和信道观测
5 重复 经验轨迹中的时间步,从t=1到T:
6 以概率ε选择随机动作aj
7 执行动作aj,获得奖励rj
8 设oj+1=oj,并计算下一时间步的输入
9 存储经验样本(oj,aj,rj,oj+1)到经验池D中
10 从经验池D中随机采样小批量的存储样本(oj,aj,rj,oj+1)
11计算当前目标Q值aj;θ);θ-))
12 使用梯度下降算法更新损失函数中的网络模型参数(yj-Q(oj,aj,θ))2
13 每隔一定时间步重置Q'=Q
14 结束重复
15 结束重复
3 仿真与分析
3.1 参数设置
在一个无线网络中,包含多个SU和PU。由于大多数许可频带的利用率低,即信道处于空闲状态的概率大,因此p11的可能值应该高,而p00的可能值应该低。所以分别从[0.7,1]和[0,0.3]上的均匀分布中随机选择每个信道的状态转移概率p11和p00,然后计算出相应的p10=1-p11和p01=1-p00。系统模型的详细参数如表1所示。

表1 系统模型详细参数
参考文献[10]产生信道状态数据的方法,首先随机初始化信道状态数据为0或1,根据状态转移概率p11和p00计算信道下一时隙的状态并更新。信道在不同时隙的部分状态变化如图4所示,该像素图可视化多个信道的状态变化情况,白色表示信道在相应时间上是空闲的,黑色表示信道被占用。
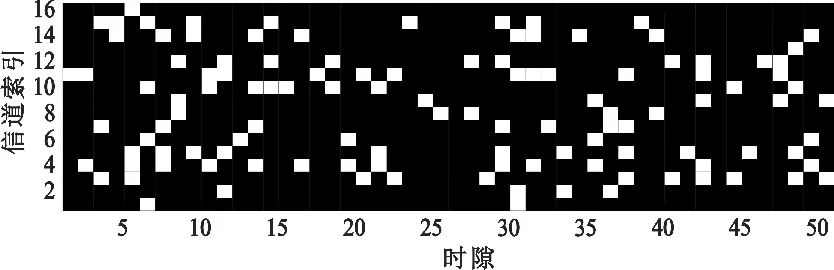
图4 信道状态变化情况
经验回放[20](Experience Replay)可以存储先前的观测数据,并打破数据样本间的相关性,使训练稳定收敛。因此,将经验回放技术应用于竞争性DDQN,并在TensorFlow[21]中实现。竞争性DDQN的最终参数确定为:一个全连接的神经网络,其中两个隐藏层包含200个神经元。每个神经元的激活函数采用线性整流函数(Rectified Linear Unit,ReLU),它的计算公式为f(x)=max(x,0)。竞争性 DDQN的输入为32个时隙上的动作和观测结果的组合,输出为选择信道的决策。应用贪婪策略(ε-greedy)将随机动作探索概率设置为0.1。当更新竞争性 DDQN的权重时,从经验回放池中随机选择32个样本的小批量来计算损失函数,并使用Adma算法[22]更新权重。有关超参数的详细信息见表2。

表2 超参数详细信息
3.2 与深度强化学习方案对比
本小节主要对比了竞争性DDQN和两种深度强化学习方案,即文献[10]中使用的DQN方法和文献[13]中提到的对Q值计算的改进方法DDQN。
图5给出了DQN和竞争性DDQN的Q值大小比较,验证Q值的过估计问题。由于DDQN和竞争性DDQN用到的Q值计算方式相同,所以图5未对比 DDQN的Q值。图5所示竞争性DDQN的Q值始终比DQN的Q值小,这是因为DQN中使用max函数虽然可以快速让Q值向最优目标靠近,但是每次都选择最大的Q值容易导致过估计问题。而竞争性DDQN通过将目标Q值动作的选择和计算解耦,解决了该问题。这里需要注意的是,Q值就是评估动作的价值,即在某个状态下执行某个动作时得到的平均奖励。根据ε-贪婪算法选择动作,以小概率选择一个随机动作,以大概率选择奖励最高的动作。因此,图中大部分Q值是较大的,而Q值突然变小是因为随机选择的动作得到的奖励值较小。

图5 Q值对比
图6给出了几种方案损失值对比情况。DQN、DDQN和竞争性DDQN在迭代到第20次时损失均达到稳定,其中DQN的损失值最大,DDQN次之,竞争性DDQN损失值最小,说明竞争性DDQN相比于DDQN和DQN预测模型更好。
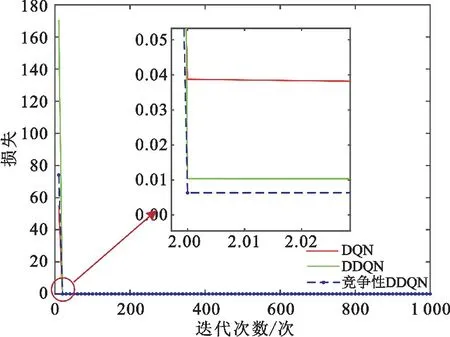
图6 不同网络的损失对比
图7以随机接入策略为参考基线,对比了解决DSA问题时不同接入策略的回报值。其中随机接入策略指没有学习过程,SU在每个时隙开始随机选择信道,所有信道的访问概率均相同。如图所示,平均累积回报分别为0.81(随机接入)、0.88(DQN)、0.89(DDQN)和0.92(竞争性DDQN)。随机接入策略只是对信道的随机选择,并没有关于信道状态的预测,因此获得的回报最差。相比于DQN和DDQN,竞争性DDQN具有较好的损失预测模型,其回报最好且最稳定。

图7 平均累积回报
对上述三种方法从时间和空间两个维度进行复杂度的计算:本文提到的三种深度强化学习方法由于它们的计算流程基本相同,只是对Q值的处理方式不同,因此三者的时间复杂度相同,均为O(MT);空间复杂度也相同,均为O(D)。
3.3 与传统方案对比
本文在解决动态频谱接入时,将问题描述为智能体学习信道状态变化的深度强化学习过程。本小节主要对比了所提竞争性DDQN和两种其他非深度强化学习方案。
多臂老虎机[3](MAB):目标是最小化遗忘函数。根据公式的推导可知,最小化遗忘函数等同于最大化期望回报。进而,计算每个用户的累积回报值,与本文所用深度强化学习得到的期望回报作对比。
竞争双拍卖[8]:目标是最大化频谱利用率,计算选择空闲信道的次数作为信道利用率,与本文提到的选择空闲信道的次数进行对比。
为了保证对比的公平性,上述两种方法的环境参数和本文的系统模型参数一致,并保证有2个SU和16个PU。上述两种方法主要结合数学推导和仿真结果得到一个衡量标准,由于衡量参数不同,因此,这里将对比结果以表3的数据呈现。可以看到,竞争性DDQN在累积回报或信道利用率上都比MAB和竞争双拍卖方法的结果好。对于MAB和竞争性DDQN,两种方法时间复杂度相同,但是竞争性DDQN的累积回报更高;而竞争双拍卖方法时间复杂度虽然低,但是它需要信道环境的先验知识,而且信道利用率也没有竞争性DDQN高,所以综合对比得到竞争性DDQN是MAB和竞争双拍卖中最优方法的结论。

表3 两种方案对比结果
4 结束语
对于动态频谱接入问题,本文建立了较真实的复杂信道场景。在多PU与多SU情况下,考虑频谱感知误差和多个SU接入时的碰撞情况,所提的基于竞争双深度Q学习的动态频谱接入算法(竞争性DDQN)帮助每个SU根据频谱感知结果以及学习结果做出较优的频谱访问决策。实验结果表明,基于深度强化学习方法比传统方案更适合该复杂场景。与随机接入算法相比,竞争性DDQN学习方法可以提供更高的回报;与DQN和DDQN相比,竞争性DDQN回报更高更稳定,且没有过估计问题。
对于未来的研究,将考虑扩展现有的深度强化学习网络综合解决频谱感知和接入问题,通过优化网络结构减小感知错误概率,进一步提高接入回报值。另外,算法的实用效果还需要在公共数据集上进行进一步的验证。
