基于Hadoop的动态网络异常节点智能检测方法
2022-12-24常伟鹏
常伟鹏,袁 泉
(中国药科大学图书与信息中心,江苏 南京 211198)
1 引言
网络流量急剧增加,导致网络系统的处理能力远低于网络数据的存储与传输要求[1,2]。然而随着网络规模的增加,分布式集群中[3]存在一些异常行为的节点,这些异常节点很有可能降低系统的运行效率,甚至导致系统运行崩溃[4,5]。为了应对网络安全问题,对异常节点进行检测与处理,降低异常节点造成的损失,成为保护网络安全的重要研究课题之一。
文献[6]通过Logstash工具对Hadoop集群点中的任务状态信息进行收集,结合Perf性能工具对收集信息的异常点进行分析,采用异常点诊断算法对集群中异常点进行诊断,构建出异常点实时监测模型,该方法对异常点监测的精度较高,但不适用于较复杂的场景。文献[7]通过Flume采集组件结合Spark集群框架对数据进行采集,并计算出采集数据的节点风险值,利用路由器节点数量对节点状况进行判断,通过定位算法完成对异常节点的定位,该方法误报率较低,但目前仅处于实验测试阶段。文献[8]在模型中引入图结构、图动态变化和图属性信息,对网络异常节点进行向量表示,并提出动态网络无监督算法对提取的异常特征进行向量学习,该方法不仅能够提升异常点的检测精度,还能够挖掘出网络中有实际意义的异常点,但系统的运行效率有待提高。
基于以上研究,提出基于Hadoop的动态网络异常节点智能检测方法。详细分析了Hadoop网络行为监测系统,对网络节点流量进行分析。针对初始聚类敏感问题,提出一种改进的均衡化评价函数对簇内节点差异准确的分析。
2 Hadoop分析
Hadoop是一种分布式计算框架,其核心包含HDFS和Map/Reduce两部分内容。Hadoop作为分布式软件框架具有可靠性高、扩展性高、效率性高、容错性高和成本低等5个突出性的优点。伴随着发展,Hadoop已经逐渐成为由数据分析层、编辑模型层、数据存储层、数据集成层和平台管理层组成的生态体系,每个层次间具有相应的功能,通过相互合作完成数据的存储与计算。Hadoop体系结构如图1所示。
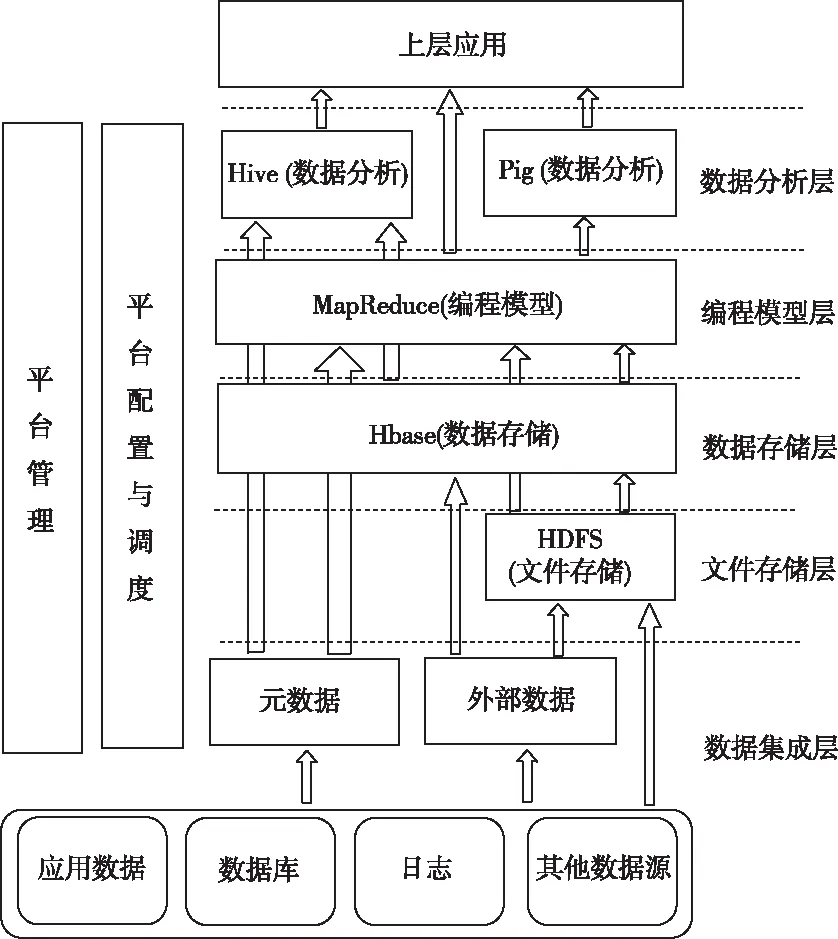
图1 Hadoop体系结构图
平台管理层对维持系统的稳定秩序起到决定性的作用,主要负责节点的故障分析、管理和性能优化等工作。数据集成层主要是将网络数据导入到HDFS上,对数据进行整理与统计。存储层主要是将导入到HDFS上的数据以64MB大小分块的形式分布式存储起来。模型层主要负责Map和Reduce的编程任务,是服务器分析数据的核心层次。数据分析层与用户直接关联,可通过特定的分析与建模等完成用户的特定需求。
HDFS采用Master/Slave架构,主要负责Hadoop集群数据的管理与存储,按照64MB大小将数据按分块的形式进行存储,可以进行多次的读写操作。
MapReduce为分布式编程框架,主要负责提供给用户简单接口,即使在用户不了解分布式程序的情况下,通过规则编写map和reduce函数就可以实现将程序运行到分布式集群上。由分治规则,MapReduce具有把单一节点上难以解决的问题划分成众多小问题处理的能力,可以极大程度地提高工作效率,减少对宽带的损耗。
NetBASS是一种实现网络检测、分析与处理的架构,主要功能是通过对网络流量数据的分析,对主机和网络节点的正常或异常行为以及恶意流量进行查找。
3 网络节点流量特征分析
网络节点是一种由协议、IP地址和目的端口组成的实体,每个节点代表一种网络业务。在一天中,少数节点产生的流量能占据网络节点的大部分,而大部分节点产生的流量反而占据网络节点小部分的特征,与幂律分布较为吻合。Zipf分布能够从大到小的对统计数据进行排序,是从幂律分布中演化来的。网络节点总流量服从Zipf排名分布,定义PDF为p(x)=Ax-α,网络节点排名公式可表示为

(1)
其中,y表示排名小于x的网络节点。若网络节点的总数为Bnum个,预测节点数大于Bnum的概率用公式可表示为
Ppre=BnumAyα-1
(2)
1)与(2)式结合,计算得出

(3)
其中,β表示排名指数,一般情况下满足1≤β≤2。随着排名的增加,网络总流量呈现下降趋势。为了对网络节点的稳定性和离异程度进行描述,通过标准差系数对节点参数的稳定性进行评价。标准差系数是反映参数变化程度的相对指标,公式可表示为

(4)

K-means算法是一种经典的划分算法,通过K-means算法对网络数据集聚类处理。K-means算法依据输入的参数N,将网络数据划分成N个簇,并以N为参考点对相似度进行计算,经过不断的迭代更新,直到算法收敛为止。就网络节点检测而言,虽然K-means算法高效快速,但在初始簇中心的选择上具有缺陷性,其聚类结果会随着随机选取的初始聚类中心发生变化,极其不稳定。而且K-means算法中只对簇内的差距进行考虑,并没有对簇间的差距加以分析,导致聚类误差较大。因此本文对K-means算法的初始簇的选择过程与评价函数进行改进,使用新的均衡化函数作为数据的收敛函数,使聚类效果更加稳定。引入簇内与簇间的差异,簇内差异表示同一簇间的数据紧凑情况,公式可表示为
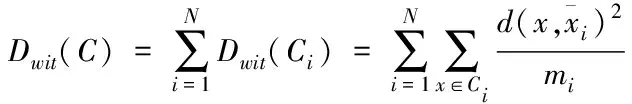
(5)
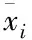
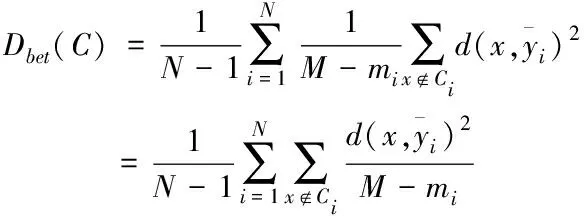
(6)
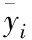
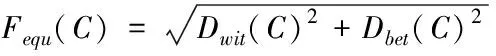
(7)
本文以簇内/簇间差异平方和的二次开方作为均衡化函数,与使用单一的簇内或簇间均方差相比,对收敛的考虑更加全面,更有利于样本的聚类。
4 Hadoop集群异常节点检测
网络异常节点检测主要由Hadoop集群异常点检测和异常定位两部分组成。诊断系统通过对Hadoop的运行日志进行实时检测,并将检测到的数据发送给指定的topic,同时各个节点把收集到的结构层数据也发送给指定的topic,进行逻辑的计算工作。异常检测系统框架如图2所示。
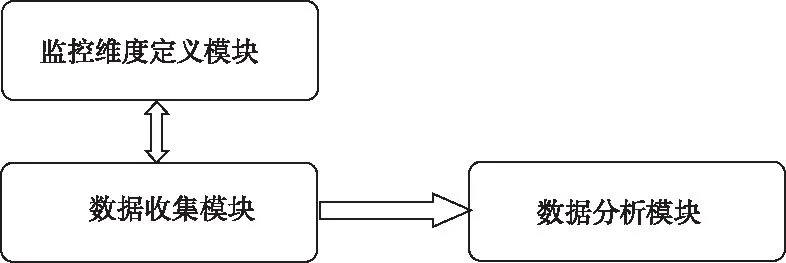
图2 异常检测系统框架图
异常检测系统由监控维度定义、数据收集和数据分析三个模块组成。监控维度定义模块主要起到分析系统层和体系指标层数据的作用,只需修改该模块的信息即可监控新的性能指标。数据收集模块主要采集集群点的性能指标,为了保证不同阶段采集的性能数据,该模块需要实时对执行阶段进行监控。数据分析模块主要对收集的性能指标进行分析,并定位出异常的节点,通过对多维度性能信息的利用,大大提高检测精度。
4.1 数据的收集
Hadoop的作业由Map和Reduce两个阶段构成,在日志中不同的任务对应不同的标记,当作业提交时,通过shuffle阶段对不同的任务进行交换处理,并将信息记录到日志上。网络节点中的各个任务均由两条信息对其状态进行记录,通过记录信息确定该任务的执行情况。网络节点的体系结构信息反映节点的资源分配状况,通过整合运算可确定相应节点的利用率。若某一个指标有问题,那么相应的节点就会异常。为了方便对异常节点进行定位并分析出其异常的原因,采用该节点体系结构,检测出异常指标的方法。体系结构层数据主要分为CPU、内存和磁盘读写。其中CPU的性能和内存均可通过利用率进行测量,磁盘读写主要功能是进行数据的加载与存储,若该性能出现问题,会严重影响集群的性能。本文只对后期相关的数据进行收集与分析,利用perf对节点的性能指标进行周期性的计算,通过logstash对日志采取结构化分析,然后整理成对应格式的数据发送给指定话题,提供给spark streaming做后续分析。
4.2 异常点检测
随着Hadoop集群的扩大,其节点性能具有异构性,但在运行过程中节点间都是同构的,所有任务的逻辑和处理情况大致相同,正常节点行为也具有相似性,而异常行为的节点与正常节点不同于任务量上。一般情况下,异常节点的任务量较少,单个任务执行的时间相对较长。因此提出一种异常节点的检测算法,通过对作业中的节点表现情况分析,对异常节点在集群中的位置进行检测,结合性能指标分析出该节点异常的原因。
Hadoop集群作业的日志分解主要过程为:首先定义收集分析维度,本文主要包含节点完成map的个数,节点最近完成map的时间以及节点运行reduce的时间三方面;然后通过分析Hadoop集群作业日志获取正在做任务的节点信息;最后按照定义的维度进行节点信息的汇总。Hadoop执行任务时map和reduce两个阶段不是完全分开的,当map任务完成后,reduce任务才开始,且会占据一个任务槽。
为降低耦合性,采用将map与reduce任务一起考虑的方法,根据集群作业中任务执行时间,将reduce任务转换成同性能下的map任务。当作业数量较大时,未被分配reduce任务节点高于正在工作的reduce任务节点。为了避免错误,将逻辑完成数与节点平均值比较,若逻辑完成数大于平均值,那么节点是正常节点;若逻辑完成数小于平均值,那么节点是异常节点。采用t分布下的标准分数对节点的性能偏移进行衡量,用公式表示为
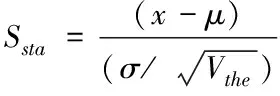
(8)
其中,μ表示逻辑完成数的均值;σ表示标准差;Vthe表示阈值。数值越大表示偏移较多。
5 仿真与结果分析
为了验证基于Hadoop网络异常节点检测方法的有效性,在Hadoop集群中使用5个运行节点,包含一个负责逻辑调度的主节点Nmain,四个负责逻辑计算的从节点N1from、N2from、N3from、N4from,每个节点配置逻辑CPU24个,内存32GB,硬盘1TB。选择CPU hog故障进行实验评估,在运行负载前和运行负载过程中对集群的某一个节点引入故障,判断其异常检测的准确性。
运行负载工作前,对第4个节点引入CPU hog故障,然后提交负载,通过测试,运行负载前引入故障的逻辑完成数与t分布下的标准分数如图3所示。

图3 运行负载前引入CPU hog图
从图中可以看出,各个节点的逻辑完成数分别为(N1from,12)、(N2from,11)、(N3from,11)、(N4from,2),t分布下的标准分数分别为(N1from,0.67)、(N2from,0.40)、(N3from,0.40)、(N4from,1.87),计算节点N4from的标准分数高于t分布的阈值1.85,而其它计算节点均比阈值低,因此除了计算节点N4from存在异常外,其它计算节点没有报警生成,实验结果与引入故障的节点具有一致性,验证了本文方法的有效性。
为了对运行负载引入故障时CPU的利用率进行检测,同样在计算节点N4from引入CPU hog故障,通过测试,运行负载前引入故障的CPU利用率如图4所示。

图4 运行负载前引入故障CPU利用率
从图中可以看出,4个节点的利用率比所有节点数的80%大时,节点应排在第一位,利用率比所有节点数的20%小时,节点应排在第五。由于N4from节点的CPU利用率排名第一,内存利用率排名第二,I/O利用率排名第四,说明N4from节点的CPU利用率比所有节点数的80%大,于是可以判断出该节点CPU存在异常,验证了本文方法对异常点判断的准确性。
运行负载时,同样对N4from节点引入CPU hog故障,但需要通过不同的时间段进行故障的引入,本文分别在map完成任务的10%、50%和90%时逐一引入的。Hadoop集群运行负载时CPU hog故障引入后运行的准确率如表1所示。

表1 引入CPU hog故障测试结果
从表中可以看出,Hadoop集群运行负载时,map任务完成10%和50%时引入CPU hog故障,准确率均能达到95%,召回率为1;虽然map任务完成90%时准确率为89%,召回率为0.87左右,但完全满足异常点检测要求。
6 结束语
为了降低运维成本,对网络中异常节点性能问题进行及时的定位与检测,提出一种基于Hadoop的动态网络异常节点智能检测方法。从Hadoop日志中获取相关任务状态信息,对map和reduce任务个数加以综合考虑,通过统计学分析节点的异常情况,一旦出现网络异常节点,通过收集系统及性能指标对异常点进行定位。在Hadoop集群中使用5个运行节点,对计算节点中的第4个节点分别在运行负载前和运行负载时引入CPU hog故障。实验结果表明,只有引入故障的节点才会有报警生成,其余节点均为正常节点。并且当map任务完成10%和50%时,准确率均能达到95%,召回率均为1,充分证明本文方法的有效性和准确性。
