基于改进RBF网络的铁路数据价值映射模型
2022-12-24廉小亲吴艳华程智博
廉小亲,刘 钰,吴艳华,程智博
(1.北京工商大学人工智能学院,北京 100048;2.国家铁路智能运输系统工程技术研究中心,北京 100081)
1 引言
随着新建高铁快速发展,铁路数字化、智能化建设逐步深入,中国新建铁路在建设阶段就已经积累了海量结构化、半结构化、非结构化数据,包括勘察设计数据、工程进度数据和自然灾害检测数据等。铁路建设期数据具有数据量大、数据类型多、数据增长快、业务价值大的特点[1],传统的数据存储方式管理复杂、成本较高、访问速度较低。因此,为了能够满足铁路建设期数据存储量大、存储方式多样的需求,选择分级存储的方式能够有效降低存储成本,提高系统性能。
数据分级存储是根据数据自身价值高低,选择与数据价值相匹配的存储设备来进行存储,将数据价值高、经常被访问以及重要程度高的数据存储在高性能的存储设备中,数据价值低、备份数据以及重要程度低的数据则存储在低性能的存储设备中,基于此就需要对数据价值进行准确判定才能保证数据分级存储有效性。江菲[2]等提出的数据价值评估模型从静态因素以及动态因素多指标考虑,相较于基于频率评估数据迁移结果准确率有明显提升,但该数据模型中未考虑到数据业务特性,无法满足不同业务类别、不同数据类型的铁路建设期数据业务存储需求;黄冬梅[3]等提出海洋数据价值迁移模型综合考虑了时间属性、文件大小和海洋数据的区域性等,但要素涉及范围不够全面,对数据价值判断准确性有影响;边根庆[4]等提出的海量数据价值评估模型通过多项参数加权求和实现数据价值精确判定,但简单的叠加求和方法所求得的结果是否准确难以判定。
为了改进上述问题,本文提出一种基于聚类-PSO-RBF神经网络的多维铁路数据价值映射模型。将数据量大小、数据访问时间重要性、数据访问频率重要性、访问用户相似度和数据业务价值共同作为判定数据价值高低因素,从数据自身属性以及业务特征、访问情况、未来被访问的可能性等方面进行多维度全面衡量数据价值,以改进RBF神经网络模型构建数据价值判定因素与数据价值等级之间的非线性映射关系模型,数据价值高低直接对应数据分级存储位置,使得数据分级结果更准确。
2 铁路数据多维分级模型
2.1 数据业务价值计算方法
2.1.1 铁路建设期数据业务价值指标评价体系
针对当前铁路建设期数据的业务特点以及存储需求[5],本文提出三级铁路建设期数据业务价值指标评价体系,如图1所示。
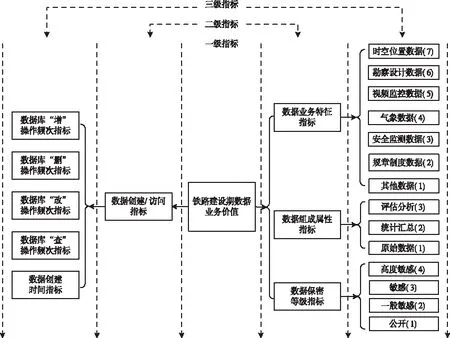
图1 铁路建设期数据业务价值指标评价体系
从铁路建设期数据属性特征业务特征以及属性特征业务特征两方面设置“数据创建/访问指标”定量二级指标以及“数据业务特征指标”、“数据组成属性指标”以及“数据保密等级指标”定性二级指标。定性二级指标分别通过专家评价方式法判定数据符合的下一级三级指标内容,根据数据类别重要程度对同一二级指标下的各项三级指标赋权值,重要程度越高,权值越大,判定符合的三级指标权值则为相应二级指标结果。
“数据创建/访问指标”下的三级指标,通过访问日志计算某一时间周期内数据所存储数据库内所有数据执行“增”、“删”、“改”、“查”操作行为频次作为相应的指标结果;“数据创建时间指标”计算数据创建时间截止到当前时间的时间范围,分为五个区间,“5年以上”、“4-5年”、“3-4年”、“2-3年”和“2年以内”,“数据库创建时间指标”根据区间范围设定对应为1-5权值,5年以上权值为“1”,权值越大创建时间截止到当前时间越短,根据时间范围计算结果确定的权值作为该项指标结果。
2.1.2 铁路建设期数据业务价值计算方法
在计算铁路建设期数据业务价值的过程中,得到铁路建设期数据业务价值指标评价体系中的各项指标结果后,需要建立各个指标间的关系,确定“数据创建/访问指标”下五项三级指标之间的权重W1,“数据创建/访问指标”、“数据业务特征指标”、“数据组成属性指标”以及“数据保密等级指标”四项二级指标之间的权重W2,通过指标所赋权值大小来体现不同指标之间的重要程度差异,同时,将多个指标的综合评价结果作为最终的铁路建设期数据业务价值结果,铁路建设期数据业务价值计算方法的逻辑架构如图2所示。
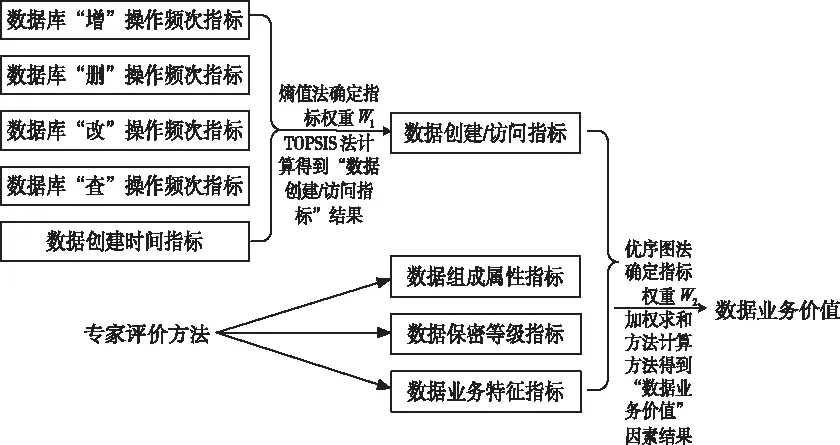
图2 数据业务价值计算方法逻辑架构
1)指标间权重确定方法
“数据创建/访问指标”下的三级指标值均为统计结果,“数据业务特征指标”、“数据组成属性指标”以及“数据保密等级指标”值为专家评价结果,针对指标结果性质,本文在确定指标间权重时平衡主观性与客观性之间的影响,选用熵值法-优序图组合方式确定铁路建设期数据业务价值指标评价体系中两组指标权重,能很好地解决单一权重确定方法主客观性不能兼顾的问题,结果可靠。
“数据创建/访问指标”下五项三级指标权重W1通过熵值法确定,熵值法[6]根据指标结果的信息熵确定指标间的权重值,以量化特征的方式保留指标结果数据本身的客观性,能够更好地体现铁路建设期数据业务价值指标评价体系中定量指标结果的数字特征;“数据创建/访问指标”、“数据业务特征指标”、“数据组成属性指标”以及“数据保密等级指标”四项二级指标间权重通W2过优序图法确定,优序图法[7]通过指标重要性专家评价矩阵计算指标权重,适用于通过专家评价方法获取的数据,能较好体现评价对象所处的背景条件和评价者意图。
2)计算铁路建设期数据业务价值方法
铁路建设期数据业务价值结果是铁路建设期数据业务价值指标评价体系各项指标结果结合指标权重的综合评价结果,在本文中提出的三级铁路建设期数据业务价值指标评价体系中需要两次计算。
“数据创建/访问指标”下五项三级指标结果与指标权重W1的综合评价结果是“数据创建/访问指标”结果,结合建设期铁路数据量大、评价指标复杂的特点,选用TOPSIS方法[8]。TOPSIS方法可在具有多个评价指标情况下对不同方案进行综合评估比较,在指标多少、样本含量和数据分布等方面都没有严格的限制和要求,且能够实现不同评价指标在同一方案之间横向比较和同一评价指标在不同方案间纵向比较;四项二级特征指标结果与指标权重W2通过加权求和综合评价法计算得到最终数据业务价值结果。
2.2 数据价值判定因素
为了更精准地判定铁路建设期数据价值,从数据被访问情况、被访问可能性以及自身业务特征角度,本文提出从数据量大小、数据访问时间重要性、数据访问频率重要性、数据访问用户相似度和数据业务价值五个方面判定铁路建设期数据价值[9]。
1)数据量大小因素S(X)
对于数据分级存储系统,为节约存储成本,高性能存储设备容量相对于其它存储设备来说是最小的,若将数据量较大的数据存储在高性能存储设备中,占用存储空间较大同时存储成本较高,将有可能导致数据量较小而且重要的数据无法及时被访问,造成高性能存储设备资源浪费。将数据量大小S(X)作为数据综合价值判定因素之一。数据量较小的数据价值相对较高,应优先考虑将数据量较小的数据存储在高性能存储设备,数据量较大的数据更适合存储在存储容量充足的低性能存储设备。
2)数据访问时间重要性因素T(X)
用户对于数据的访问情况从访问时间的角度考虑具有一定规律,一般最新创建或最近被频繁访问过的数据在未来短时间内再次被访问的可能性更大,数据在这段时间内重要程度比较高,该数据的数据价值也会随之提高,应优先考虑将此类数据存储在高性能存储设备;相反,数据在被访问过后未被访问的时间间隔逐渐拉长,数据被重新访问的可能性也会随之降低,数据价值以及重要程度就会随之降低,在这种情况下就需要将数据存储到低性能的存储设备。因此,数据被访问的时间间隔可作为数据综合价值判定因素之一。
在某一特定周期下,数据每次被访问和修改的时间集合为{t1,t2,…,tn},当前时间是t,时间集合内的时间点距离当前时间的间隔为{t-t1,t-t2,…,t-tn},设以上时间段为{T1,T2,…,Tn},则计算数据X的访问时间重要性因素T(X)如式(1)所示。
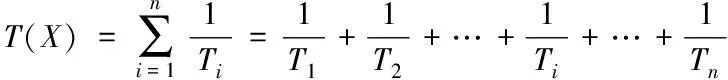
(1)
3)数据访问频率重要性因素F(X)
数据访问频率可以理解为横坐标为时间、纵坐标为数据访问次数的二维坐标图的斜率,斜率在一定程度上能够预示图形未来短时间内的变化趋势。在一段时间内,数据访问频率变化成正相关,则该数据在未来短时间内访问次数依旧持续增加的可能性比较大,数据综合价值及重要性也相对提高,这样的数据应优先考虑存储在高性能存储设备。因此,可将数据访问频率重要性作为判定数据综合价值高低的因素之一。计算数据X的访问频率重要性因素F(X)如式(2)所示。在某一特定时间周期内包含N个Tk时间段,每个Tk时间段内数据访问频率为fk,在Tk-Tk-1时间段内数据访问频率的变化趋势为fk-fk-1,N个时间段数据访问频率变化的代数和即数据访问频率重要性因素。
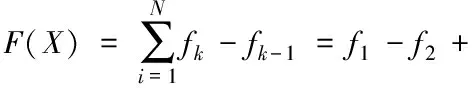
(2)
4)数据访问用户相似度因素H(X)
通过计算所有访问过数据X用户的相似用户个数之和能够预测数据在未来短时间内被更多用户访问的可能性以及可增加的数据访问量,相似性较高的用户,具有较为相似的用户习惯和兴趣,访问过数据X用户的相似用户越多,则数据被更多用户访问的可能性也就越高,可增加的数据潜在访问量也就越多,则数据价值以及重要性就越高,应优先考虑存储在高性能存储设备。
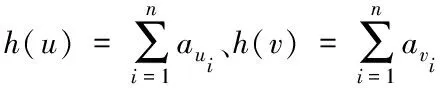
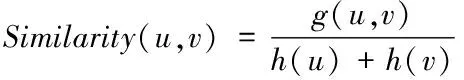
(3)
计算数据X的访问用户相似度因素H(X)需要遍历访问过数据X的用户以及没有访问过数据X的用户,多次重复计算一个访问过数据X用户与一个未访问过数据X的用户之间的相似度,计算数据X的访问用户相似度因素H(X)具体计算步骤如下所示:
1)设访问过数据X的用户集合用U来表示,未访问过数据X的用户集合用V来表示,则有U={u1,u2,…,ui,…,un},V={v1,v2,…,vj,…,vm},式中:n和m为各自集合内用户的数量。
2)循环逐一取出用户集合U、V中的用户,通过式(3)分别计算计算一个集合U中用户和一个集合V中用户两两之间的相似度S,最终得到相似矩阵如式(4)所示。
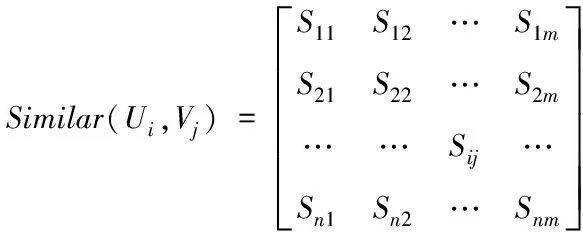
(4)
式中:i∈[1,n],j∈[1,m]。
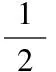
4)避免访问过数据X用户集的相似用户集合可能包含有相同的用户,重复的用户应只计算一次,则计算数据X的访问用户相似度因素H(X)如式(5)所示。
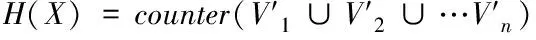
(5)
5)数据业务价值因素P(X)
铁路建设期数据的业务价值体现了数据在业务方面的重要程度,同时数据业务特征对数据存储有特殊的存储需求,在一定程度上也影响了数据存储级别的选择。因此,将数据业务价值作为判定数据综合价值的一项因素,铁路数据业务价值计算方法如1.1.2节所示。
2.3 RBF神经网络
RBF神经网络包含输入层、隐含层和输出层三层结构,对于非线性函数具有较强的逼近能力,且具有结构简单、收敛速度快的特点。利用RBF神经网络的自学习功能,在提供神经网络输入、输出的前提下,确定数据价值判定因素与数据价值高低等级之间的非线性映射关系,构建多维铁路建设期数据综合价值映射模型,拓扑结构如图3所示。以5个数据价值判定因素作为网络的输入向量,以数据价值等级作为RBF神经网络的输出,设置数据价值高等级标签为“1”、中等级标签为“2”、低等级标签为“3”。
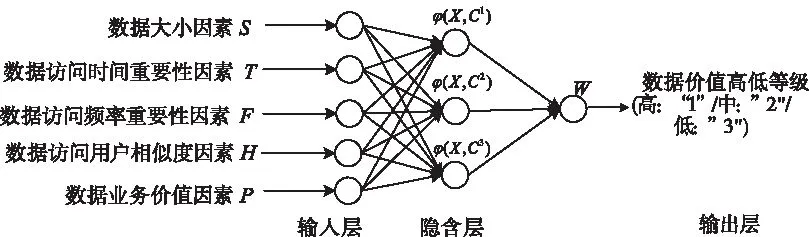
图3 RBF网络拓扑结构
网络隐含层为高斯径向基层,隐含层神经元的激活函数φ(X,Cj)如式(6)所示[10]。
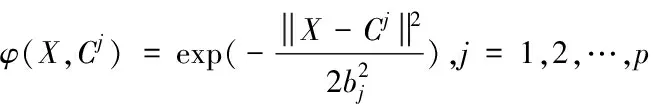
(6)
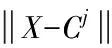
网络隐含层与输出层以权值矩阵W连接,在RBF神经网络训练过程中采取梯度下降法调节C、b和W,但此算法易陷入局部最小值[11]。为提高RBF神经网络收敛性,保证神经网络输出结果的准确性,本文引入粒子群算法(PSO)以及聚类方法,通过聚类方法确定RBF的隐层神经元径向基函数中心向量C以及扩展常数b,利用PSO算法选择隐含层到输出层之间的最佳权值矩阵W,以获得最优神经网络模型。
2.4 聚类-PSO-RBF神经网络映射模型
粒子群优化算法(PSO)具有全局收敛性,在RBF神经网络发挥泛化映射性的基础上,能够提高网络的自学能力以及有效性。
PSO算法是在D维空间下n个粒子寻找最优解的过程,在每次迭代中更新粒子适应度函数个体最优值Pbest和全局最优值Gbest追踪当前最优粒子,根据式(7)和式(8)来更新粒子的速度和位置。
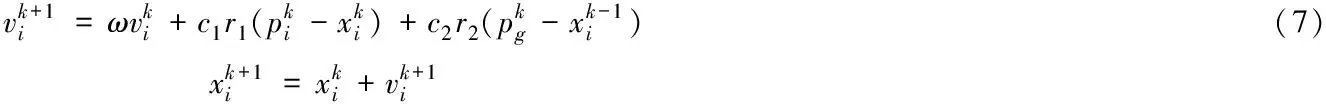
(8)
通过PSO算法确定RBF神经网络隐含层到输出层之间的权值矩阵W,PSO算法的评价函数如式(9)所示。
(9)

图4 基于聚类-PSO-RBF神经网络的铁路数据价值映射模型算法流程
3 分析与讨论
3.1 试验结果设计
本文设计了验证聚类-PSO-RBF神经网络模型结果的准确性实验,以当前真实存储的铁路建设期结构化数据作为实验数据,包含了28个铁路建设期数据相关业务系统的数据库以及其中的721张数据表,以一张数据表作为一个数据单位,模拟数据表访问记录、构造RBF神经网络模型数据集、分析聚类-PSO-RBF神经网络映射模型结果。
3.1.1 模拟数据表访问记录
参考数据存储系统的数据访问日志内容,针对721张数据表模拟生成随机数量的访问记录,构成原始数据集如表1所示。
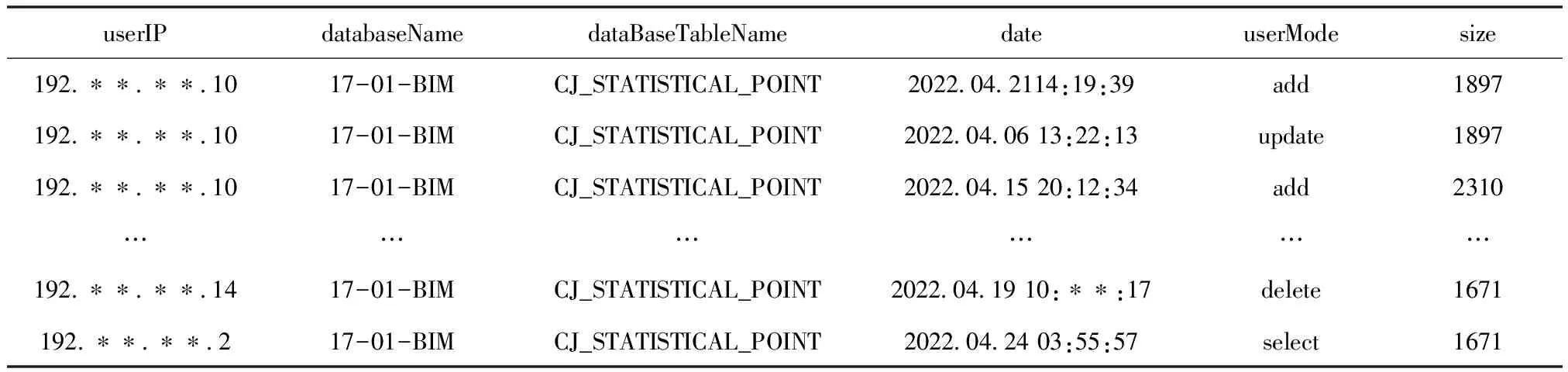
表1 访问记录原始数据集
每条记录包含了被访问数据的数据库名称、数据表名称、访问用户IP地址、访问时间、访问操作以及执行访问操作后的数据表大小,设定访问IP地址范围从“192.**.**.1”-“192.**.**.20”,访问时间为“2022.04.01”-“2022.04.30”这一周期内任一时刻,访问操作存在“add”、“delete”、“select”和“update”四种操作,执行访问操作后的数据表大小以MB为单位。每一张数据表的访问记录均大于10条,共生成了7583条访问记录,
3.1.2 构造RBF神经网络模型数据集
基于铁路建设期数据模拟生成的数据表访问记录,根据各数据价值判定因素计算公式,计算出每张数据表2022年4月这一周期内的数据量大小、数据访问时间重要性、数据访问频率重要性因和数据访问用户相似度五项因素结果,通过三级指标体系专家评价结果计算数据表业务价值,将数据价值判定因素结果作为RBF神经网络模型的输入;同时将每张数据表专家评价数据价值等级作为RBF神经网络模型的输出,构成铁路建设期数据价值映射模型训练数据集。
3.2 试验结果分析
本文设计了四组对比实验,梯度下降-RBF神经网络、聚类-RBF神经网络、RBF工具箱神经网络以及聚类-PSO-RBF神经网络分别作为铁路建设期数据价值映射模型,721组样本数据中,随机选择其中500组数据为训练集,剩下的221组为测试集,验证训练模型的有效性。聚类-PSO-RBF神经网络作为铁路建设期数据价值映射模型多次测试集分级准确率平均能达到95%以上,最优分级准确率能达到99%以上,四组对比实验判定数据各存储级别准确率如表2所示。

表2 四组对比试验数据分级结果准确率
四组对比实验测试集数据标签结果以及实际网络输出结果散点图如图5-图8所示。
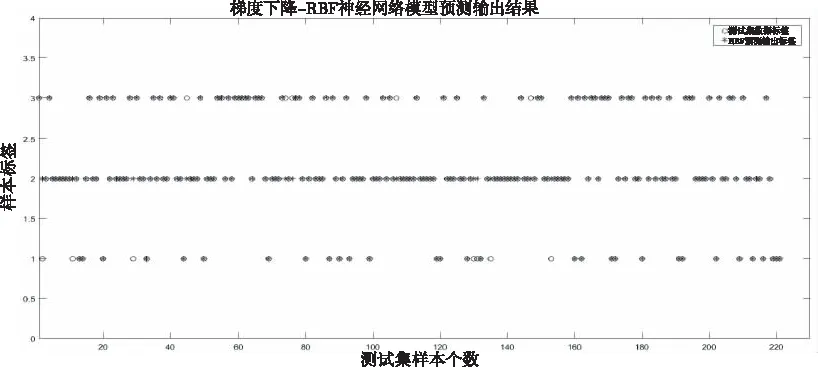
图5 梯度下降-RBF神经网络模型输出结果
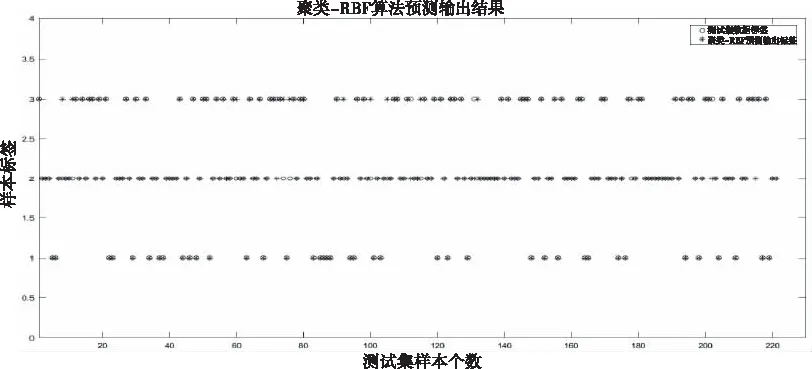
图6 聚类-RBF神经网络模型输出结果
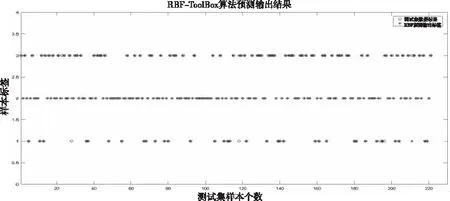
图7 ToolBox-RBF神经网络模型输出结果
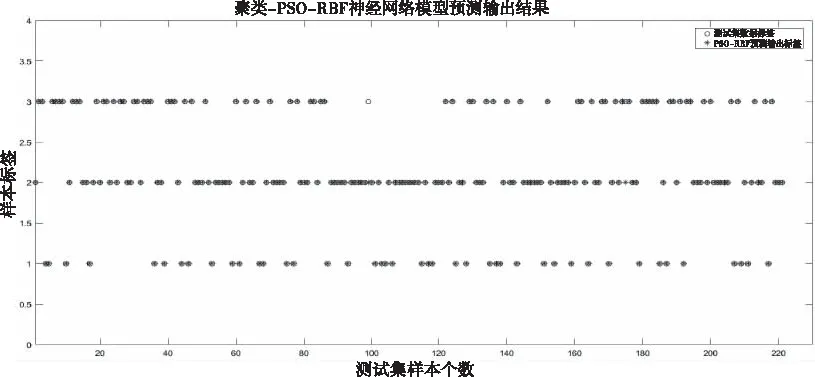
图8 聚类-PSO-RBF神经网络模型输出结果
4 结论
针对当前基于数据价值的数据分级存储模型存储模型简化、因素不全面等问题,本文提出了一种基于聚类-PSO-RBF神经网络的多维铁路数据价值映射模型。从数据量大小、数据访问时间重要性、数据访问频率重要性、数据访问用户相似度和数据业务价多维度衡量数据价值,选用RBF神经网络、引入聚类方法、PSO算法优化RBF神经网络模型参数选择,构建数据价值判定因素与数据价值高低等级之间的映射关系模型。实验结果表明,基于聚类-PSO-RBF神经网络的多维数据价值映射模型能准确判定数据价值高低,对实现铁路建设期数据分级存储十分有意义。
