Modeling of unsupervised knowledge graph of events based on mutual information among neighbor domains and sparse representation
2022-12-23JingTaoSunJingMingLiQiuYuZhang
Jing-Tao Sun ,Jing-Ming Li ,Qiu-Yu Zhang
a School of Computer Science and Technology,Xi'an University of Posts and Telecommunications,Xi'an,Shaanxi,710121,China
b Shaanxi Key Laboratory of Network Data Analysis and Intelligent Processing,Xi'an University of Posts and Telecommunications,Xi'an,Shaanxi,710121,China
c School of Management Science and Engineering,Anhui University of Finance and Economics,Bengbu,Anhui,230030,China
d School of Computer and Communication,Lanzhou University of Technology,Lanzhou,Gansu,730050,China
Keywords:
ABSTRACT Text event mining,as an indispensable method of text mining processing,has attracted the extensive attention of researchers.A modeling method for knowledge graph of events based on mutual information among neighbor domains and sparse representation is proposed in this paper,i.e.UKGE-MS.Specifically,UKGE-MS can improve the existing text mining technology's ability of understanding and discovering high-dimensional unmarked information,and solves the problems of traditional unsupervised feature selection methods,which only focus on selecting features from a global perspective and ignoring the impact of local connection of samples.Firstly,considering the influence of local information of samples in feature correlation evaluation,a feature clustering algorithm based on average neighborhood mutual information is proposed,and the feature clusters with certain event correlation are obtained;Secondly,an unsupervised feature selection method based on the high-order correlation of multi-dimensional statistical data is designed by combining the dimension reduction advantage of local linear embedding algorithm and the feature selection ability of sparse representation,so as to enhance the generalization ability of the selected feature items.Finally,the events knowledge graph is constructed by means of sparse representation and l1 norm.Extensive experiments are carried out on five real datasets and synthetic datasets,and the UKGE-MS are compared with five corresponding algorithms.The experimental results show that UKGE-MS is better than the traditional method in event clustering and feature selection,and has some advantages over other methods in text event recognition and discovery.
1.Introduction
With the rapid development of information technology,text information is growing explosively,which has made artificial marking of massive texts impossible.Thus,how to find useful information in texts accurately and efficiently has become an urgent problem to be solved.As a branch of the big data mining field,text mining technology is widely used in media evaluation,topic detection and tracking,emotion analysis,and many other fields,in which feature selection and text clustering technologies are two text data mining technologies used most commonly[1,2].
At present,relatively mature feature selection method is mainly the statistical method based on vector space mode under supervised environment[3-6],such as CHI statistical selection method(CHI for short)[7,8],information gain(IG for short)[9,10],and mutual information(MI for short)[11,12].These kinds of method have two problems in practical applications.
First of all,the research of such method is based on the summary of labeled samples,which requires marking a lot of samples artificially,with time of a lot of experts being wasted,and meanwhile,it is almost impossible to mark enough samples in the face of big data.
Secondly,these methods do not take into account influences of sample distribution and relevance on representation of events,which causes the problem that the most distinguishable selected feature subset cannot accurately reflect the true information of the sample space,and thus impairs the performance of the text mining technology in practice.In addition,due to the introduction of sample category information,these methods are not suitable for unsupervised feature selection.
Clustering,as an unsupervised data analysis method,discovers the“underlying concept”[13]of unstructured data by analyzing the dependencies between data.Generally,current clustering methods fall into two categories:feature clustering and sample clustering.
The feature clustering method,also known as subspace clustering method,is an effective way to achieve high-dimensional data clustering,the idea of which is to find clustering in different subspaces of the same dataset[14].The sample clustering method is to obtain data category labels by clustering data sample sets without category labels and then select features according to the contribution degree shown by features in the clustering process[15].Compared with feature selection in the supervised environment,studies on the feature selection in the unsupervised environment is not comprehensive enough.The main reasons are as follows:firstly,the research on unsupervised feature selection lacks the guidance of prior knowledge,which is not conducive to the evaluation of feature values;Secondly,studies on unsupervised feature selection are full of uncertainties,and the results are often difficult to explain and verify.Considering the fact that the current text mining techniques have the above problems when processing texts of high dimensional unmarked data,this paper makes an in-depth study of the technical details involved in text event mining modeling,and gives a detailed description by the following.
Aiming at the above problems of existing text event mining technology in dealing with high-dimensional,big data,unmarked text,we propose a method for modeling the unsupervised knowledge graph of events based on mutual information among neighbor domains and sparse representation(UKGE-MS).In the proposed model,the definition of feature correlation is introduced into the mutual information between adjacent domains,and the vector of the relationship between sample features and newly emerged samples is established to minimize the uncertainty of features.Neighborhood mutual information is an information measurement method that integrates neighborhood concept into mutual information.With the idea of k-means clustering algorithm[16,17],the features are clustered into a cluster.According to the local structure of high-dimensional feature data,local linear embedding algorithm is adopted to obtain the low-dimensional manifold space of the cluster.In an unsupervised environment,the model constructs a more generalized knowledge graph of events,with better dimensionality reduction being achieved,the event representation ability of features being enhanced,and the effects of event discovery and recognition being improved.Then an unsupervised knowledge graph of events is constructed using the reconstruction coefficients of data and based on the sparse representation theory.
The rest of this paper is organized as follows:Section 2 discusses work related to the study methods used in the paper;Section 3 details the modeling of unsupervised knowledge graph from two aspects,namely the feature clustering algorithm based on the average mutual information between neighbors and the unsupervised feature selection method based on local linear embedding and sparse representation;Section 4 introduces the experimental process and results analysis;and Section 5 summarize our work with future work.
2.Relevant work
Text mining is to analyze semi-structured or unstructured texts in natural languages and retrieve interesting patterns or extract useful implicit information from them[18].The current studies are focused on such directions as text mining models[19],text information extraction[20](supervised,semi-supervised and unsupervised),text mining algorithms[21](such as mining of semantic relationship,classification and clustering of texts,analysis of text orientation,and topic discovery and tracking),and tools for text mining[22].In these directions,the topic discovery and tracking technology is similar to the idea of constructing knowledge graph of events proposed in this paper,which is to mine structured or hierarchical complex information from unstructured text of natural language description.In recent years,the major studies in this field are to reduce the workload of manual marking,and unsupervised clustering learning is a better method.Xu G et al.[23]build a detection and tracking system without manual marking.
The main idea of unsupervised learning[24](also called nonsupervised learning)is to learn the abstract form of data autonomously with the samples not being labeled,which is consistent with the fact that majority of samples are not marked in practical cases.Therefore,unsupervised learning is more widely applied than supervised learning.Current methods for processing unsupervised data can be roughly divided into:clustering and dimensionality reduction[25].The traditional clustering methods mainly include partition clustering,hierarchical clustering,and densitybased clustering.Zhu Lizhi[26]proposes an improved weighted Euclidean distance clustering algorithm to determine whether the weight corresponding to the attribute is the key weight by calculating the similarity of the attribute of the clustering object.Masdari et al.[27]proposes the heuristic hierarchical clustering algorithm of sensor nodes data based on chaotic discrete version of the ABC algorithm(CDABC),which selects the clustering level automatically using clustering protocol that can be used to organize WSNs into multiple levels of clusters to reduce their energy consumption.Liu et al.[28]proposes a density-based statistical mergence clustering algorithm(DSMC).According to the density information of data points,each feature on the data points was taken as an independent set of random variables,and the density sequence was taken as the fusion sequence of the information of the data point aggregation process.
With the advent of the era of big data application,in order to adapt to the problems related to clustering in high-dimensional space,new methods such as attribute reduction and subspace clustering are proposed on the basis of improving the traditional methods.The method based on attribute reduction is to reduce dimensionality through transformation or selection of attribute features,and then cluster in low dimensional spaces by using traditional clustering algorithms.Xu S L et al.[29]put forward with a data stream classification algorithm combined with unsupervised learning,introducing attribute reduction in the classification process and using clustering algorithms to cluster the data stream.Yiu-Ming et al.[30]bring about a feature selection method based on feature clustering,which employs the clustering algorithm to search for clusters in different subspaces,classified the features with strong correlation(redundancy)into a cluster,and then selected a representative subset from each cluster to form the feature subset.Alex Rodriguez et al.[31]proposes a fast search density peak(DPC)clustering algorithm,which can quickly find the density peak points of samples and discover patterns of any dimensions and distribution shapes.
As for dimension reduction method,feature extraction and selection are the primary method of data dimension reduction.Mainstream methods of dimension reduction method include principal component analysis(PCA)mutual information(MI)method,the method of multidimensional scaling(MDS),isometric mapping algorithm(ISOMAP),and the method based on manifold(locally linear embedding(LLE)algorithm,the Laplace feature mapping algorithm(LE),local projection(LPP),neighborhood be embedded(NPE),and so on).Lin Y E et al.[32]propose a direct unsupervised orthogonal local preserving algorithm.In this algorithm,Laplace matrix is used for matrix decomposition,and projection matrix can be directly extracted from the original space of high-dimensional samples to solve the problems related to small samples in unsupervised discriminant analysis.Xu J L et al.[33]propose an unsupervised feature selection method(UFS-MI)based on mutual information,in which a feature selection criterion taking into account relevancy and redundancy comprehensively.Deng Cai et al.[34]propose a multiple clustering feature selection method,which uses the spectral embedding approach to reduce the dimension of data,then obtains low dimensional linear dependence of high dimensional features by solving l1norm regularization regression problems,with the largest coefficient values in sparse representation being taken as the optimal features to be selected.Zhu P F et al.[35]proposes an unsupervised feature selection mode of regularized self-representation(RSR),which allows each feature to be represented as a linear combination of relevant attributes in a low dimensional space by using l2norm regularization.Zhu Y et al.[36]proposed an embedded unsupervised feature selection method(EUFS),which embeds feature selection into the clustering algorithm through sparse learning.Tang C et al.[37]propose a strongly robust unsupervised feature selection algorithm(RUFS),which processes redundancy and noise features effectively by means of l2,1norm minimization in the process of label learning and feature selection.
3.Method of modeling unsupervised knowledge graphs of events
3.1.Methodology and basic framework
In the unsupervised environment,it is necessary to overcome the following difficulties in analyzing massive information and extracting implicit event information:1)How to model unlabeled high-dimensional data;2)How to effectively measure the similarity of features;3)How to effectively reduce the dimension of features and eliminate redundancy;4)How to ensure fast acquisition of the optimal feature subsets.
Therefore,the knowledge graph of events modeling process consists of three phases in this study.Firstly,the features with strong correlation are classified into a cluster according to the influence of sample neighborhood on feature similarity and the correlation between features measured by mutual information between neighboring areas.Then,a similarity matrix is constructed for the sample set to which the cluster belongs,and a local linear embedding algorithm(LLE)is used to construct a low-dimensional embedding space and keep the manifold structure of the original sample.Finally,the events knowledge graph is constructed by means of sparse representation and l1norm.The frame of UKGE-MS method is shown in Fig.1.The three phases of modeling a knowledge graph of events are described in the following.
3.2.Feature clustering algorithm based on the average mutual information among neighbor domains
In this section,six definitions related to feature clustering algorithm are given.Secondly,referring to the idea of K-means clustering algorithm,the algorithm steps of feature clustering based on the average mutual information between neighbors are descripted.Finally,the time and space complexity of clustering algorithm are analyzed.
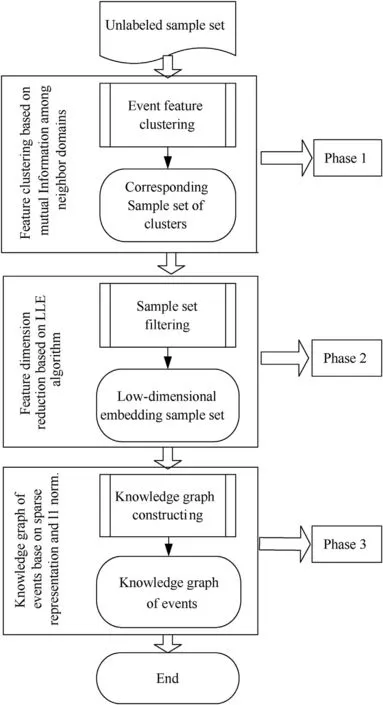
Fig.1.Diagram of UKGE-MS method.
3.2.1.Definitions
In order to introduce the neighborhood mutual information into the calculation of feature correlation,the concepts involved need to be defined as follows:
Definition 1.Given a random sample xi,xi∊U in a non-empty finite set{x1,x2,…,xn}in the sample space U,its neighbor domain is defined as ζ(xi)={x|x∊U,Δ(x,xi)≤ω},ω≥0.
Definition 2.For a feature set Y in the sample space U,the feature subset B,D⊆Y exists,and thus its average mutual information among neighbor domains is defined as:

where,ζB(xi)and ζD(xi)are ζ neighbor domains of xion feature subsets B and D,respectively.
Definition 3.For∀B,D⊆Y,its joint information entropy among neighbor domains is defined as:

Definition 4.For the features Tiand Tj,i,j∊{1,2,…,p},i≠j,their relevance is defined as:

where,Iζ(Ti;Tj)is the average mutual information among neighbor domains of features Tiand Tj,and Hζ(Ti;Tj)is the joint information entropy of features Tiand Tj.
Definition 5.For feature Ti,i∊{1,2,…,p},its average relevance degree is defined as:

Definition 6.If feature Tibelongs to cluster Cv,v=1,2,…,k,the relevance of the two features is defined as:

3.2.2.Description of algorithms
There are always some specific problems when event descriptions are being extracted by supervised learning method.For example,in a real-world situation,a valid event label cannot be provided because a large amount of information content is usually not processed or sorted.For this reason,unsupervised learning clustering method is adopted for analysis to avoid the problem that events cannot be accurately described in unsupervised learning environment.In addition,some studies have found that the features of a certain event tend to appear in the documents related to the event,and through clustering the features,a subset of the features related to the event can be obtained,which means that a set of relevant features can mark an event.Because of the simplicity and efficiency of neighborhood algorithm,the advantage of mutual information and the correlation of information entropy measurement,this study proposes a feature clustering algorithm based on the average mutual information between neighborhood,where samples are regarded as characteristics and vectors are set as the relationship between sample characteristics and emerging samples.This method can minimize the uncertainty of features and avoid the influence of artificial supervision and prior knowledge on the performance of the algorithm.Based on the idea of k-means clustering algorithm,features are clustered into one cluster,which provides a possibility for constructing knowledge graph of events.Specific steps of the algorithm are as follows:
Step 1.Initialization.The initial number of clusters is k=1,a new set of features T*is constructed,and T*is an order of features arranged in an ascending order of
Step 2.Calculation of the clustering threshold.θ=
Step 3.A center table of clusters c-table is constructed,and T*is divided equally into k+1 parts,with the feature of each right endpoint being added in c-table as a cluster center point;
Step 4.Each feature Tiin T*and the feature cvin c-table,as well as the relevance SIHζ(Ti;cv),v∊{1,2,…k}of the two,is calculated according to the definition,with Tibeing classified into the cluster containing the largest value of SIHζ(Ti;cv).
Step 5.The relevance SMIHζ(Ti;Cv)of feature Tiin cluster Cvis calculated according to the definition,with c-table being updated,and the feature with the largest value SMIHζ(Ti;Cv)in the cluster Cvbeing classified as the cluster center.
Step 6.The relevance SIHζ(Ti;Tj)of two features within the cluster Cvis calculated according to the definition.of the cluster Cvis calculated.
Step 8.k=k+1 is increased gradually.
Step 9.Steps 3-8 will continue until max{D(Cv)}≤θ.
Step 10.The algorithm ends.
The time complexity of the algorithm is O(k2×n×p)(n is the number of samples,p is the number of features,and k is the number of clusters).In addition,according to the specific steps of the algorithm,the space complexity of the algorithm is O(n×p).
Step 7.Variance
3.3.Feature dimensionality reduction method based on locally linear embedding
In an unsupervised environment,the clustering algorithm proposed in section 3.2 is used to obtain multiple feature clusters and realize feature granulation in the sample space.Then,the local linear embedding algorithm is employed to maintain the local linear features of samples and realize low-dimensional embedding of high-dimensional data.
Local linear embedding(LLE)is a manifold learning algorithm[38-40],which can obtain low-dimensional embedding of highdimensional data by keeping the local linear characteristics of samples,so as to achieve the purpose of dimension reduction.The algorithm described in Section 3.2 is used to obtain the feature cluster of the samples Cv,on which the sample set Xvcontaining this cluster of features is generated.Due to the low amount of information contained in some typical samples,before dimensionality reduction using low dimensional embedding(LLE),it is necessary to deal with Xvto a certain degree,so as to reduce the number of sample points and improve the performance of the algorithm.As for the selection of samples in Xv,the simple and intuitive method of document frequency selection(DF)is referenced,and the significance of feature samples(SOF)is determined based on how many features are contained in Cv.Usually samples below a certain threshold contain only a small amount of information and are not very representative.So the implementation description of dimension reduction of event features are as follows:
①Given neighborhood sample set X*v.A sample set X*vof|Cv|dimensions is obtained using feature clustering algorithm mentioned in Section 3.1.2 and the above sample selection rules,with X*vbeing used as the number of samples in the set.
②The matrix of weight coefficients W=[wij].wijrepresents the weight coefficient of the linear relationship between sample xiand its neighborhood sample xj,with the mean square error being used to define the error and functionLagrange multiplication is used to get the optimal weight wij.
③Calculate the low dimensional embedding Yv.Given that the neighborhood sample set is X*v={x1,x2,…,x|X*v|},xi∊R|Cv|,and the corresponding projection of xi∊R|Cv|in low dimension is Yv={y1,y2,…,y|X*v|},yi∊Rd,and J(Yv)=shall be minimized so as to maintain the linear relationship of the high dimension space.
In order to obtain standardized low dimensional data,the following constraints need to beAccording to the constraints,the formula can be converted into:J(Yv)=tr(YTv(I-W)T(I-W)Yv),tr is the trace function.The corresponding Yvof J(Yv)is minimized,which is the matrix composed of d corresponding feature vectors of d non-zero feature values containing the smallest(I-W)T(I-W).Since the smallest feature value of(I-W)T(I-W)is 0,which cannot reflect the data features,the corresponding feature vectors of the smallest feature values of(I-W)T(I-W)from the second one to number d+1 are selected to construct the final Yv={y2,…,yd+1}.
3.4.Construction of knowledge graph of events
Sparse representation is a new method that has emerged in the field of machine learning in recent years,which obtains sparse vectors with over complete dictionary features by minimizing the norm optimization method,and currently,it has become an effective tool for acquiring,representing and compressing high dimensional data.However,most of the current studies focus on the high-dimensional data of images and pay little attention to other types of high-dimensional data.Moreover,in the supervised environment,this method can only achieve better performance than the traditional method,while the research on unsupervised learning is not mature.According to the basic idea of sparse representation,high-dimensional information can be represented completely or approximately by a small group of linear combinations of data objects.Therefore,in order to make the selected feature words describe events more accurately,on the basis of the dimension reduction of LLE algorithm in Section 3.3,a knowledge graph of events is constructed by selecting a small number of features from the event feature space that have high discrimination and can well represent the features of the events in the data set.
Given dataset X*v,the response variable is Yv,the mathematical model of sparse representation is as shown in formula(6):

where,xiis the feature of number i in X*v,a is the coefficient vector of the sparse representation,is the norm of l0,that is,the number of non-zero elements in the vector.Solution in formula(7)is an NP-hard problem,which converts the minimization of the norm of l0into the minimization of the norm of l1,that is:

4.Experiment and result analysis
In this section,the effectiveness and correctness of the model proposed in this paper is verified through simulation experiment,with comparison being made with the performance of LDA model[41],clustering algorithm searching density peaks fast(DPC)[31],feature selection based on feature clustering(FSFC)[30],unsupervised feature selection method based on mutual information(UFSMI)[33],and strongly robust unsupervised feature selection algorithm(RUFS)[37].
4.1.Experimental design and data
All codes employed in the experiment are written by Matlab R2013a software platform,and the PC parameters compiled and run are:Lenovo YOGA,Intel i5-7200U,8.00 GB RAM,and Win10 64-bit operating system.In order to verify the differences in performance of various methods for different data environments.Three datasets from different sources for evaluation and test are selected in this study.
Dataset 1 contains microblogs related to 12 hot topics on Sina Weibo collected from January 1 to January 10,2017.Because the popularity of subject items varies greatly,an equal proportion sampling method is used,with artificial marking being done after the sampling so as to validate the results.Dataset 1 contains 2996 pieces of relevant messages and 500 pieces of noisy data for the 12 topics.The topics and quantities are distributed as shown in Table 1.
Dataset 2,i.e.(SogouCS)20151022 corpora,is employed as the experimental data set,with a total of 10902 articles in 12 categories.In order to test the effect of each method,the corpus is supplemented and optimized to some extent.For example,some types of texts are added,some incomplete texts are removed,and 6 categories are selected from the processed corpus,namely,video games,entertainment,sports and leisure,medicine,natural sciences,and art,which are 5493 texts in total,and the specific data structure is shown in Table 2.
Dataset 3 contains two datasets of the sonar and ionosphere from UCI,a public database,which are shown in Table 3.
Dataset 4 is the user comment information of some products obtained from online platforms including JD,Amazon and Dianping by crawler technology.Refer to the distribution of related categories and information quantity in Table 4.

Table 1 Composition of topics involved in dataset 1.

Table 2 Data composition in dataset 2.

Table 3 Descriptions of UCI datasets.
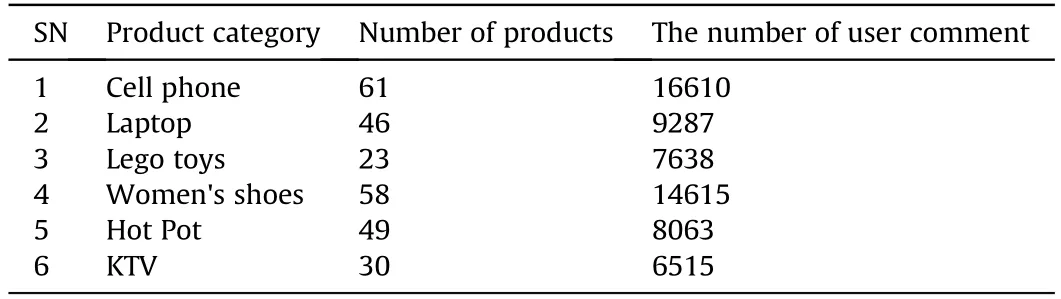
Table 4 Product categories and number of comments in dataset 4.
Dataset 5 uses Reuter-21578 corpus,testing sample set consisting of 10 classes of 7549 files with an unbalanced distribution.The greatest set included 2877 files constituting 38.11%of the files in the sample set,while the smallest set included 101 files(1.34%of the sample set).
ICTCLAS,a Chinese word segmentation tool of Chinese Academy of Sciences,is used in text preprocessing.Support vector machine with superior performance is employed in the sorting algorithm,and the specific realization is done with LIBSVM toolkit of Taiwan University,with the radial basis function being adopted as the kernel function.In the comparison algorithm,the neighborhood parameter is set to 5,and cosine similarity is used for the similarity between vectors.
4.2.Evaluation indicators
The missing rate,false detection rate and clustering accuracy(AC)are used to evaluate the performance of the algorithm.The macro average recall rate,macro average accuracy rate and macro average F1 value are used to evaluate the overall performance of the system.
The computational formula of evaluation indicators is shown in Table 5.
In Table 5,a and b represent the number of correct events and incorrect events among the results respectively,c and d denote correct events and incorrect events not detected among the results,and|C|represents the number of categories.N represents the number of datasetsrepresents a permutation mapping function that maps the clustering tag to the corresponding real tag[42].

Table 5 Computational formula of evaluation indicators.
4.3.Experiment test and analysis
To obtain experiment results of more statistical significance,5-fold cross check method is adopted to evaluate the effectiveness in this study.First,for dataset 1,UKGE-MS,LDA model,clustering algorithm searching density peaks fast(DPC),and the feature selection method based on feature clustering(FSFC)are adopted to evaluate the topics discovery.LDA requires presetting the number of topics,which is set as 12 in this paper,and the specific experiment results are shown in Table 6.Compared with the manual marking of the subject words,the macro average accuracy and recall rate of the subject words in the knowledge graph of events are obtained,in which the DPC selects the subject words with features at the peak of their density.The experiment results are shown in Fig.2 and Fig.3.
It can be observed from Table 6 that UKGE-MS and LDA can correctly identify the same number of topics,both of which are the highest among the four methods,but the false alarm rate of LDA is one time higher than that of UKGE-MS,and meanwhile,the method requires presetting the number of clusters,while UKGE-MS canautomatically identify the number of topics.FSFC is superior to LDA and DPC on false alarm rate,but its omission rate is higher,which is mainly related to the method for setting its clustering threshold.

Table 6 Comparison of event discovery performance of testing methods adopted.
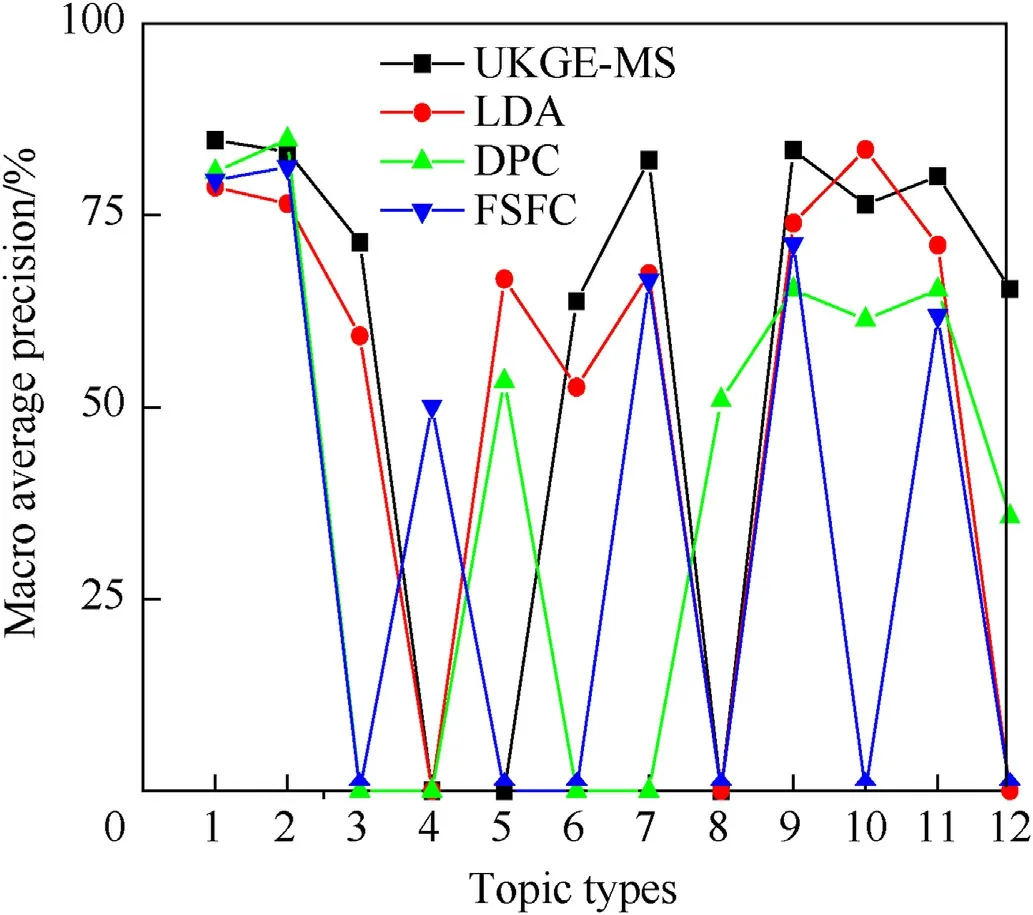
Fig.2.Precision rate of subject terms.
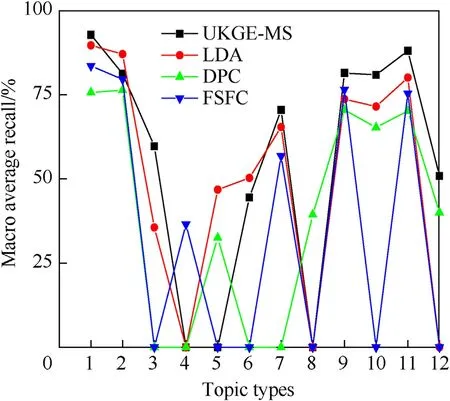
Fig.3.Recall rate of subject terms.
As shown in Figs.2 and 3,UKGE-MS has higher precision rate and recall rate in most topic categories.LDA has a higher precision rate than that of DPC and FSFC.Due to FSFC's poor performance on topic identification,it is difficult to achieve good results in recall rate and precision rate.From the comparison of the four methods,UKGE-MS is superior on performance than the others.
Second,in order to further verify the clustering performance of UKGE-MS,under different data sets(dataset 4,dataset 5),the clustering accuracy(AC)of UKGE-MS is compared with the standard LDA model,K-means algorithm and DPC algorithm.The experimental results are shown in Fig.4.
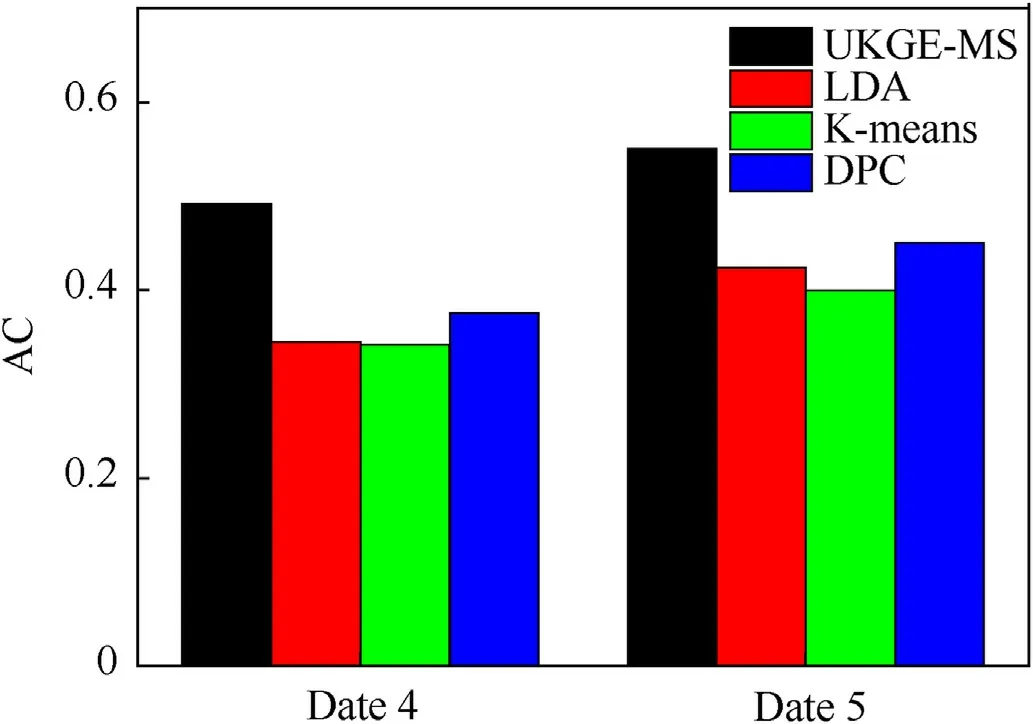
Fig.4.AC values of each algorithm in different datasets.
It can be seen from Fig.4 that the UKGE-MS proposed in this paper achieves high clustering accuracy on two different text data sets.Further comparison results show that the clustering results of each algorithm on dataset 4 are not very well.The reason is that it is closely related to the spatial structure of the dataset itself.Data set 4 is a short text information set for users,which is short in length,sparse in data and ambiguous in meaning.This is further manifested in the complexity of spatial structure and fuzzy cluster boundary.It will inevitably lead to the increase of clustering difficulty and the decline of clustering quality.However,UKGE-MS still achieves relatively good clustering results,which reflects the strong robustness of UKGE-MS.
Thirdly,for the dataset 2,the text classification performance of the selected feature collection is evaluated.Since there is no standard for the optimal number of features in this dataset,the validity of the algorithm is evaluated by artificially setting the number of features to be selected in the test.Table 7 lists the experiment results of UKGE-MS,feature selection method based on feature clustering(FSFC),unsupervised feature selection method based on mutual information(UFS-MI),and robust unsupervised feature selection algorithm(RUFS)using LIBSVM classifier(using radial basis function)in(SogouCS)20151022 corpus,in which the black and bold part indicates the number of fixed features,with the highest macro average precision rate and macro average F1 value.As shown in Table 7,when the number of features to be selected is 500 and 2000,the macro average F1 value of UKGE-MS is slightly lower than UFS-MI.When the number of features to be selected is 100,all the precision rates of classification of FSFC,UFS-MI and RUFS are less than 65%,while UKGE-MS can obtain an average macro precision rate of 71.55% in this study.
Table 8 lists the experiment results of the UKGE-MS,FSFC,UFSMI,and RUFS using LIBSVM classifier(using radial basis function,with the number of dimensions of feature spatial vectors being set as 1500)in(SogouCS)20151022 corpus.According to Table 8,the macro average recall rate and macro average F1 value of UKGE-MS in this study are significantly higher than those of the other three.Compared with the FSFC,the computation time of SVM classifier in this method is nearly doubled,and the running time is also shortened to some extent compared with the other two methods.
According to the experimental results in Tables 7 and 8,UKGEMS is superior to the other three on performance of classification of feature subsets selected from(SogouCS)20151022 corpus.At last,on dataset 3,comparison is made on the performance of classification of feature subsets selected by the UKGE-MS,the FSFC,the UFS-MI,and the RUFS,as well as on the corresponding number offeatures of the method boasting the best classification performance,so as to verify the effectiveness of the modeling methods in this study.Fig.5 and Fig.6 show the average classification precision rate of each method in different feature subsets.Table 9 shows the corresponding number of features to the optimal average precision rate of each method,in which,the bold part indicates the part with the least number of features or the highest classification precision rate.

Table 7 Comparison of performance of feature selection method(Ascending of features).

Table 8 Comparison of overall performance of four methods.
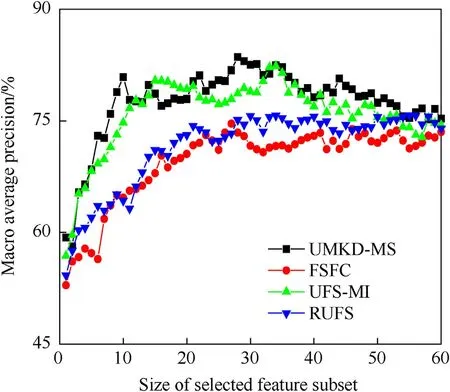
Fig.5.Sonar dataset.
According to the results of 5-fold cross check in Table 9,UKGEMS has a smaller subset of features selected in the ionosphere dataset as well as a higher classification precision rate than the other three.As far as sonar data sets are concerned,UKGE-MS has the highest classification precision rate,but the scale of its feature subset is not the smallest,while FSFC has the smallest classification precision rate.For ionospheric data sets,the classification precision rate of UKGE-MS and UFS-MI is close to each other.However,UKGEMS has a little advantage in feature subset and precision rate,FSFC and RUF are closer in performance,and the size of feature subset selected by FSFC is significantly smaller than RUF,but the classification precision rate of FSFC is slightly lower,which is the lowest in this data set.
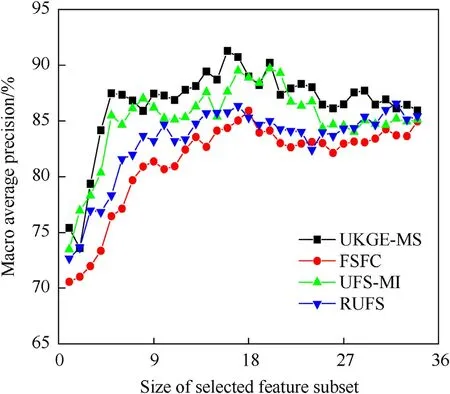
Fig.6.Ionosphere dataset.
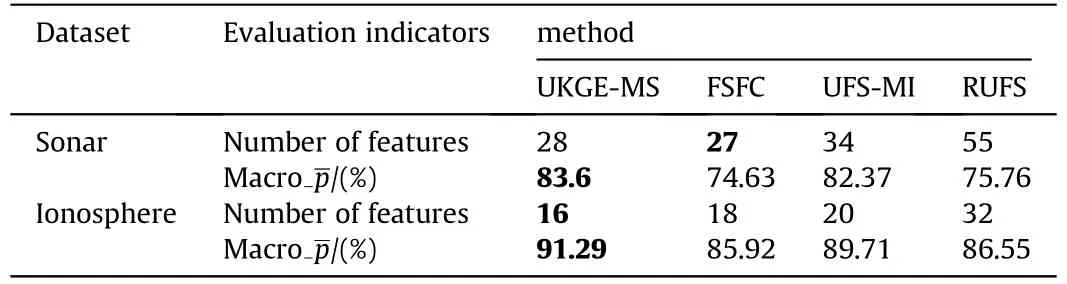
Table 9 Comparison of the highest macro average precision rate and the corresponding number of features of each method.
From Figs.5 and 6,it can be seen that UKGE-MS delivers a macro average precision rate much higher than that of the other three methods in both sonar dataset and ionosphere dataset.As shown in Fig.5,when the feature number in sonar dataset is 2,12,15,20,33,and 58,UKGE-MS has lower classification performance than that of UFS-MI.In other cases,UKGE-MS has classification performance better than or equal to the other three methods.As shown in Figs.5 and 6,FSFC has the lowest classification precision rate among the four methods,and RUFS algorithm is slightly better than FSFC.UFSMI,and UKGE-MS are close to each other on some feature numbers.In summary,according to the experimental results of Figs.5 and 6 and Table 9,UKGE-MS proposed in this study has better performance than the other three methods in feature subset classification of UCI data set.
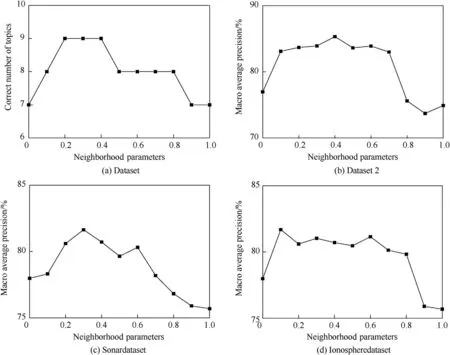
Fig.7.Influence of the value of neighborhood parameter ω on UKGE-MS.
4.4.Parameter analysis
As the domain parameter ω has a great influence on the performance of UKGE-MS algorithm,the following analysis is made on its value range.Given the value of the neighborhood parameter ω is{0,0.1,0.2,0.3,…,1.0},the changes in the number of topics identified in dataset 1 by UKGE-MS is as shown in Fig.7(a).The changes in classification performance of datasets 2 and 3 are shown in Fig.7(b-d).From Fig.7(a-d),it can be seen that neighborhood parameter ω has a significant influence on the performance of UKGE-MS,especially when ω is 0.2-0.4,the performance of UKGEMS is relatively stable and on a high level.
5.Conclusion
Aiming at the practical application requirements of text event mining in unsupervised environment,an unsupervised knowledge graph of events modeling method based on mutual information among neighbor domains and sparse representation(UKGE-MS)is proposed in this paper.This method does not need marking largescale sample for training,avoids predefined category relations and related features,and realizes the extraction of hidden information from multidimensional statistical data.Firstly,the correlation of features is defined by the mutual information of neighborhood and joint entropy of neighborhood to improve the event discovery ability of K-means clustering algorithm.Then,the local linear embedding(LLE)method is adopted to reflect the low dimensional embedding of local information in the cluster sample set.Finally,the sparse representation algorithm is used to deeply select the features in the clustering sample set,based on which the knowledge graph of events is constructed.This method raises the rationality of event graphs,improves the validity of event similarity calculation to some extent,and provides a new method for establishing precise and credible event identification in an unsupervised environment.According to the experiment results,UKGE-MS in this paper can further improve the efficiency and precision rate of finding short text events.In addition,the modeling of unsupervised knowledge graph of events is only the basic research of deep text data mining.The research results and ideas are conducive to the realization of text mining behaviors such as theme discovery,trend analysis and knowledge discovery,which provides new means and functions for the field of public opinion analysis.For future work,we will continue to focus on application research of events text mining.
Compliance with ethical standards
This study was funded by the International Science and Technology Cooperation Program of the Science and Technology Department of Shaanxi Province,China(No.2021KW-16),the Science and Technology Project in Xi’an (No.2019218114GXRC017CG018-GXYD17.11),Thesis work was supported by the special fund construction project of Key Disciplines in Ordinary Colleges and Universities in Shaanxi Province,the authors would like to thank the anonymous reviewers for their helpful comments and suggestions.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
杂志排行

Defence Technology的其它文章
- Influence of local stiffeners and cutout shapes on the vibration and stability characteristics of quasi-isotropic laminates under hygrothermo-mechanical loadings
- General design principle of artillery for firing accuracy
- Data-driven prediction of plate velocities and plate deformation of explosive reactive armor
- Analysis of the effect of bore centerline on projectile exit conditions in small arms
- Adaptive sliding mode control of modular self-reconfigurable spacecraft with time-delay estimation
- Prediction of concentration of toxic gases produced by detonation of commercial explosives by thermochemical equilibrium calculations