深度学习的目标检测算法综述
2022-12-21柴立臣冯中营
宁 健,马 淼,柴立臣,冯中营
(太原工业学院理学系 山西 太原 030008)
0 引言
深度学习是对人工神经网络进行改进形成的,为一种常用的人工智能技术,其中含多个隐藏层。这种技术主要是对低层特征进行一定模式的组合而形成高层次的特征,为数据分析提供支持[1]。在这场深度学习中,这种神经网络有很高应用价值,目前人工智能中有着非常重要的地位。
目标检测,主要是根据目标的相关特征对图像进行分割,从而实现目标识别目的。基于深度学习的目标检测算法在步骤上包括双阶段(two-stage)和单阶段(onestage)两种目标检测框架。前一种框架在处理过程中先确定出样本的候选框,接着对样本通过CNN网络分类;后一种框架在处理时不产生候选框,直接在一定回归分析基础上实现目标检测。对比分析可知这两种方法的特性明显不同,前者所得结果更准确,不过实时性差,后者速度上占优。各经典算法及主流特征提取网络出现的时间[2],如图1所示。

图1 各经典算法及主流特征提取网络出现的时间
1 基于区域提取目标检测框架
区域提取算法的核心框架是卷积神经网络CNN,对这种网络的研究可追溯至神经认知机,神经认知机的主要特征表现为具有深度结构,属于一种研究相对深入的深度学习算法。根据相关资料可知这种网络中,隐含层是S层和C层组合形成的,在运行过程中二者分别用于提取和接收图像特征的功能。20世纪80年代 LECUN等[3]对这种模型进行改进和优化,建立起功能更强大的LeNet-5网络,然后通过其识别手写数字,结果发现其可以很好地满足应用要求。LeNet-5的主要特征为引入了池化层来筛选输入特征,这样可以显著提高网络的性能。LeNet-5对CNN网络发展起到很大促进作用,并决定了其基本结构,通过这种网络进行图像处理时,可获得其平移不变特征。卷积神经网络主要由两部分组成,一部分是特征提取(卷积、激活函数、池化),另一部分是分类识别(全连接层),图2便是手写文字识别卷积神经网络结构图。

图2 手写文字识别卷积神经网络结构图
1.1 R-CNN
采用滑动窗口策略对图片进行反复特征提取,虽然能够尽量提取图片信息,但是穷举法导致识别结果多了很多其他信息,效率太低。GIRSHICK等[4]提出区域卷积神经网络R-CNN(Region CNN),如图3所示。R-CNN算法和改进前网络相比取得了50%的性能提升,但其也有缺陷存在:基于传统方法确定出候选区,这样降低了其处理实时性;卷积神经网络需要分别对各候选区来特征提取处理,实际存在大量的重复运算,也显著降低算法效率。

图3 R-CNN目标检测算法步骤
1.2 Fast R-CNN
GIRSHICK等[5]在研究过程中提出一种优化的Fast R-CNN模型,如图4所示。Fast R-CNN和R-CNN相比,训练时间从84 h减少到9.5 h,测试时间从47 s减少到0.32 s,并且在PASCAL平台上测试的准确率提高到66%~67%之间。且在学习训练过程中,综合了分类损失和回归损失,这样可显著改善学习效果。然后根据要求输出相关分类和定位信息,对中间层信息不需要特定性的保存,有利于节约存储资源。梯度可利用池化层来高效的传播。Fast R-CNN使人意识到了候选区域+卷积神经网络在提高检测实时性方面的优势,对比分析可知多类检测可在改善处理实时性基础上,也提高了处理准确性,不过其依然存在局限性,如处理过程中基于传统方法生成候选区。

图4 Fast R-CNN目标检测步骤
1.3 Faster R-CNN
为了解决上述算法的问题,2015年微软研究院的REN等[6]以及Ross团队推出快速R-CNN,如图5所示,在处理过程中简单网络目标识别速度为17 fps,在PASCAL VOC上准确率为59.9%,复杂网络的为5 fps,准确率也达到78.8%。在这种模型中加入边缘提取网络,这样使得生成候选区域,特征提取,分类以及定位相关的环节被纳入到整体框架中,有利于提高模型的标准性水平。在对此网络进行改进时,应用区域生成网络(RPN)取代其中的搜索方法。设计辅助生成样本的RPN网络,算法在目标检测时的流程为,先由RPN对候选框进行判断,确定出其是否为目标,接着判断目标的类型。在各环节都可以共享提取的特征信息,因而有利于提高处理效率,同时占据的空间减小,可以更快地生成候选框,而算法的精度并不受到影响。不过进一步分析可知RPN网在处理时可获得多尺寸的候选框,这样在处理时感受野和目标尺寸会产生不匹配问题,在目标平移变化情况下无法实现检测目的。

图5 Faster R-CNN目标检测算法步骤(左)和RPN基本结构(右)
1.4 Mask R-CNN
为了处理two stage算法应用中存在的问题,HE等[7]对上述问题进行分析,建立了Mask R-CNN模型,取得了很好地识别效果。处理时面临的任务为3个,包括分类+回归+分割,如图6所示。基于全卷积网络预测候选框的掩膜,可使得目标空间结构相关的信息都很好的保留,实现目标像素级分割定位。

图6 Mask R-CNN目标检测算法步骤
1.5 其他Two-Stage检测算法
2017年卡内基梅隆大学提出A-Fast-RCNN算法[8],其引入了对抗学习策略,据此获得一个遮挡和变形样本对网络进行训练,从而更好地对遮挡和变形情况下的目标进行识别。2017年12月,Face++提出一种大mini-batch的目标检测算法MegDet,可以高效地利用多块GPU联合训练,大大缩短训练时间,同时解决了批标准化统计不准确的问题,达到更高的准确率。2017年12月Face++提出检测算法LI等[9],应用了大内核而获得符合要求的特征图,可使得ROI子网络处理过程中占用的资源显著减少,平衡物体检测中的精确度和速度。R-CNN相关的两阶段算法由于RPN结构的存在,虽然检测精度不断提高,但是其速度却遇到瓶颈,比较难于满足特定条件下的实时性需求。
2 基于回归的目标检测框架
为了进一步提高目标检测的实时性,出现了YOLO(you only look once)和SSD(single shot multibox detector)等基于回归的目标检测框架,这样不仅可以确保算法的可靠性,还能最大程度上提高其运算速度。
2.1 YOLO
2015年美国计算机研究者REDMON等[10]建立YOLO算法,通过这种算法进行处理时,对应的流程情况如图7,其在预测过程中主要运用到图形全局信息,因而相应的处理过程显著简化。将输入图像尺寸进行还原,设置了7×7网格单元。通过CNN提取的特征进行学习训练,输出结果为目标的类别信息。然而该方法也存在一定的局限性,具体体现在定位不准、召回率不甚理想,尤其是在近距离的物体检测中不十分适用,从总体来看此方法的泛化能力相对弱。
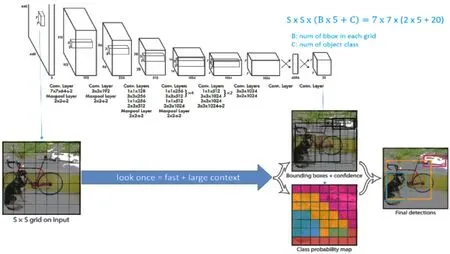
图7 YOLO流程
2.2 YOLOv2和YOLO9000
基于YOLO有2个改进版,YOLOv2和YOLO9000,它们有效弥补了以往方法的不足,可以减小召回率和定位误差。前者(如图8所示)主要是运用了Faster R-CNN的思想,在具体应用过程中采用锚框机制,同时还使用了典型的K-Means聚类方式获得更为理想的锚框模板。这种算法的特殊性还体现在通过增加候选框的预测,引入更为科学的定位方法,从而有效弥补了以往算法召回率低的问题,现阶段这种方法已经在实践中得到大量应用。YOLO9000是基于YOLOv2形成的一种算法,该算法的最大优势体现在能够检测超过9 000个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。

图8 YOLOv2训练过程及流程
2.3 YOLOv4
YOLOv4(如图9所示)算法是也是基于YOLO形成的一种新方法,相对来说,前者更具先进性。其采用了近些年卷积神经网络领域中最优秀的优化策略,因此在很多场合中都非常适用,比如在数据处理、主干网络等场合中均有不同程度的优化。在YOLOv4中,借鉴了跨阶段局部网络CSPNet(cross stage partial networks),对Darknet53做了一点改进。CSPNet解决了其他大型神经网络框架梯度信息重复这一瓶颈,其采用特殊的方式将梯度完全集成到特征图中,故而采用这种方法能够有效减少模型的参数量和FLOPS数值。因此与其他的算法相比,其有更高可靠性,推理速度也非常理想;同时显著减小了模型尺寸。

图9 YOLOv4流程
2.4 SSD
LIU等[11]建立此算法,如图10所示。SSD的主要特征表现为融合了以上两种算法的回归和锚盒机制,在各卷积层的特征图上进行定位预测,输出的为统一的boxes坐标,对对应的类别置信度主要是通过小卷积核进行预测分析。进行整体多尺度的边框回归分析,这样可以提高算法的处理速度,而定位准确性不受到明显影响。然而其利用多层次特征分类,因此在应用中也存在一定不足,比如对于小目标检测困难。

图10 SSD和YOLO网络结构对比
2.5 其他One-Stage检测算法
RetinaNet网络架构采用FPN网络的结构,其主要创新点在于提出了一个新的损失函数Focal Loss,主要用于解决正负样本极不平衡这一不足。在网络预测中,正负样本比相差大,并且负样本大多为简单样本,大量的简单样本损失累积会导致训练缓慢,所以对预测错误的样本添加权重,从而使简单样本损失降得更大,从而优化了训练。
M2Det使用主干网络加多级金字塔网络MLFPN(multilevel feature pyramid network)来提取图像特征,接着采用特定的方法预测密集的包围框,通过NMS得到最后的检测结果。
3 结论
深度学习目标检测有多方面性能优势和很广阔的应用场景,同时也面临着很多困难与挑战。本文以具有代表性的目标检测算法为主线,综述了这种检测技术的进展和思考。参考上下文特征的多特征融合,在此基础上,结合RNN展开更为深入的探讨。当前这种目标检测算法虽然应用非常广泛,然而同样存在诸多局限性,如何减少复杂背景干扰以提高检测的准确性,基于深度学习目标检测技术的研究值得更深层次的研究。
