基于相关修正的无偏排序学习方法
2022-12-16王奕婷兰艳艳郭嘉丰程学旗
王奕婷 兰艳艳 庞 亮 郭嘉丰 程学旗
1(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190)2(中国科学院大学 北京 100049)3(清华大学智能产业研究院 北京 100084)4(中国科学院计算技术研究所数据智能系统研究中心 北京 100190)(wangyiting211@mails.ucas.ac.cn)
排序学习是信息检索领域的关键技术,它运用机器学习方法训练模型并根据查询请求返回候选文档的预测得分.真实场景中的网络信息随时间更新变化,若采用传统的排序学习方法则需不断对新产生的数据进行人工标注,这需要消耗人力且不利于模型的实时更新.相较文档相关标签,用户浏览留下的点击数据规模大、易于获取[1]且更能反映用户偏好和兴趣[2].将点击数据作为标签能够有效降低标注成本[3].因此,面向点击数据训练模型具有重要意义.
用户点击[4]包含偏差和噪声[5-6],如位置靠前的文档更容易被用户点击,因此直接将是否点击作为文档相关的判据会导致次优的模型训练效果[7].目前主要有2类方法利用点击数据训练模型:一类为点击模型,它通过研究用户行为特点从用户点击推测文档相关性,从而得到去除偏差后的数据用于训练.这类方法将偏差去除和排序任务作为2个分开的任务.由于2步骤优化的目标不一致,往往不能达到很好的训练效果,且在长尾稀疏数据场景表现不佳.另一类为近年来提出的无偏排序学习方法,它的基本思路是利用逆倾向加权方法进行反事实因果推断,对不同文档进行点击倾向估计并对损失加权,最终得到无偏模型.这类方法需要较为准确的点击倾向估计,结果随机呈现是较常见的思路.它将候选文档打乱排列次序并呈现给用户,根据用户的实际点击情况估计点击倾向,但呈现给用户的文档顺序被打乱进而会导致用户体验不佳.
基于回归的期望最大化方法是通过极大似然估计计算点击概率和倾向概率,但该方法对初值敏感且每当有数据更新时都需重新执行算法,因此适用范围有限.
对偶学习方法是目前较为主流的无偏排序方法,适用范围较广且在多个数据集上表现较优[8].在已知用户点击的情况下,用户是否观察到文档以及文档是否与该项查询相关未知.对偶学习将这2个概率估计问题看作对偶任务,利用逆倾向加权和逆相关加权联合训练排序模型和倾向模型.但该方法仅当排序模型和倾向模型的损失函数均为凸函数时收敛到最优.实际神经网络包含多个隐藏层导致损失函数非凸,模型可能收敛得到次优解.
针对上述问题,本文提出一种新的无偏排序学习方法,利用现有小规模标注数据对排序模型预训练,并利用其对对偶去偏过程进行相关修正.由于对偶学习方法中越精准的排序模型会促使倾向模型输出的倾向得分越贴近真实用户点击倾向,而越准确的倾向模型会促使训练的排序模型更接近无偏模型,故本文方法利用现有的小规模样本训练排序模型能使得模型在联合训练前有较好的初始值从而避免训练中错误的累积,进而得到更优的无偏模型.模拟不同程度的点击偏差并在真实点击数据场景下测试,结果表明本文方案能够有效提升无偏排序方法表现.
1 相关工作
利用用户点击反馈训练模型有点击模型和无偏排序学习2类方法.
1.1 点击模型
点击模型从已知的用户点击中反向推断文档与查询的相关性,再将其结果用于训练.基于用户浏览行为特点,研究者提出了不同的点击模型[9-13],从带偏的点击数据中推测实际文档相关性.如位置模型(position based model, PBM)假设用户是否点击由文档吸引用户程度以及是否被用户检验所决定.在此基础上Craswell等人[10]作进一步假设,认为用户自上而下浏览网页、返回结果、并逐个判定是否点击该文档、直到需求被满足,构建了级联模型(cascade model, CM).级联模型在一次搜索过程中只出现一次点击,某位置文档被点击的概率与之前的文档是否被点击有关,而位置模型中各文档被点击的概率相互独立.用户浏览模型[11](user browsing model, UBM)可看作上述模型的拓展,它既考虑了用户对某一位置文档是否点击与该位置之前的文档是否被点击之间的关联关系;又考虑了文档排列的先后位置顺序与用户对该位置文档进行检验的概率之间的关联关系.
在上述不同假设条件下,可以通过用户点击来推测文档的相关性,从而训练排序模型.然而,这类方法要求每一查询-文档对多次呈现给用户,因此难以适用于稀疏数据场景.此外,由于点击模型去偏和训练排序模型2步骤的优化目标不一致,最终模型能够达到的效果有限.
1.2 无偏排序学习
对点击数据去除偏差并得到文档的真实相关性的任务存在难以适用于稀疏长尾数据的真实场景以及前后任务优化目标不一致等诸多难点,因此近年来研究人员提出无偏排序学习这一新的研究方向,将点击数据作为标签训练无偏模型.Wang等人[14]和Joachims等人[15]提出采用逆倾向评分加权的方法来训练无偏排序学习模型,利用结果随机呈现的方法来估计点击倾向.然而上述方法需要将结果随机展示给用户,导致用户体验下降.因此,2018年Wang等人[16]探讨了结果随机呈现带来的不良影响并提出基于回归的期望最大化方法用于个性化搜索场景.该方法可以提升用户体验,并从一定程度上解决个性化搜索中的点击数据稀疏的问题,但每当有点击数据更新时都需要重新进行计算.
Ai等人[17]将排序学习模型和倾向模型的训练看作对偶任务,对2个模型同时训练.在此基础上,Hu等人[18]将逆倾向得分加权方法扩展为成对去偏方法,并结合LambdaMART实现位置偏差估计和排序模型的共同训练.这类方法用户体验相对较好,然而当相关性模型估计不准确时会引入新的偏差.由于倾向估计表现依赖于排序模型效果,因此需要构建较为准确的相关估计模型以提升效果.
2 问题描述
2.1 无偏排序任务
无偏排序旨在利用用户反馈数据训练模型,对给定查询q和文档d的特征信息给出对应的文档相关得分,按照从高到低将排序结果返回并呈现给用户,系统记录用户点击候选列表中的某一文档并更新模型,其流程如图1所示:
对于每一查询-文档对,无偏排序学习方法将点击数据作为标签,通过设计有效的损失函数尽可能消除点击数据偏差,使模型向相关标签训练的排序模型收敛.
为统一本文表达方式,列出本文使用符号参数及其含义如表1所示.令用户输入的查询集合为Q,查询q∈Q.系统针对查询q返回呈现给用户的文档列表πq,文档用d表示.>

Table 1 Symbols and Their Meanings表1 使用符号及其含义
2.2 对偶学习及问题
现有无偏排序学习算法中,对偶学习方法在多个数据集上表现较佳且适用范围较广,其流程如图2所示:
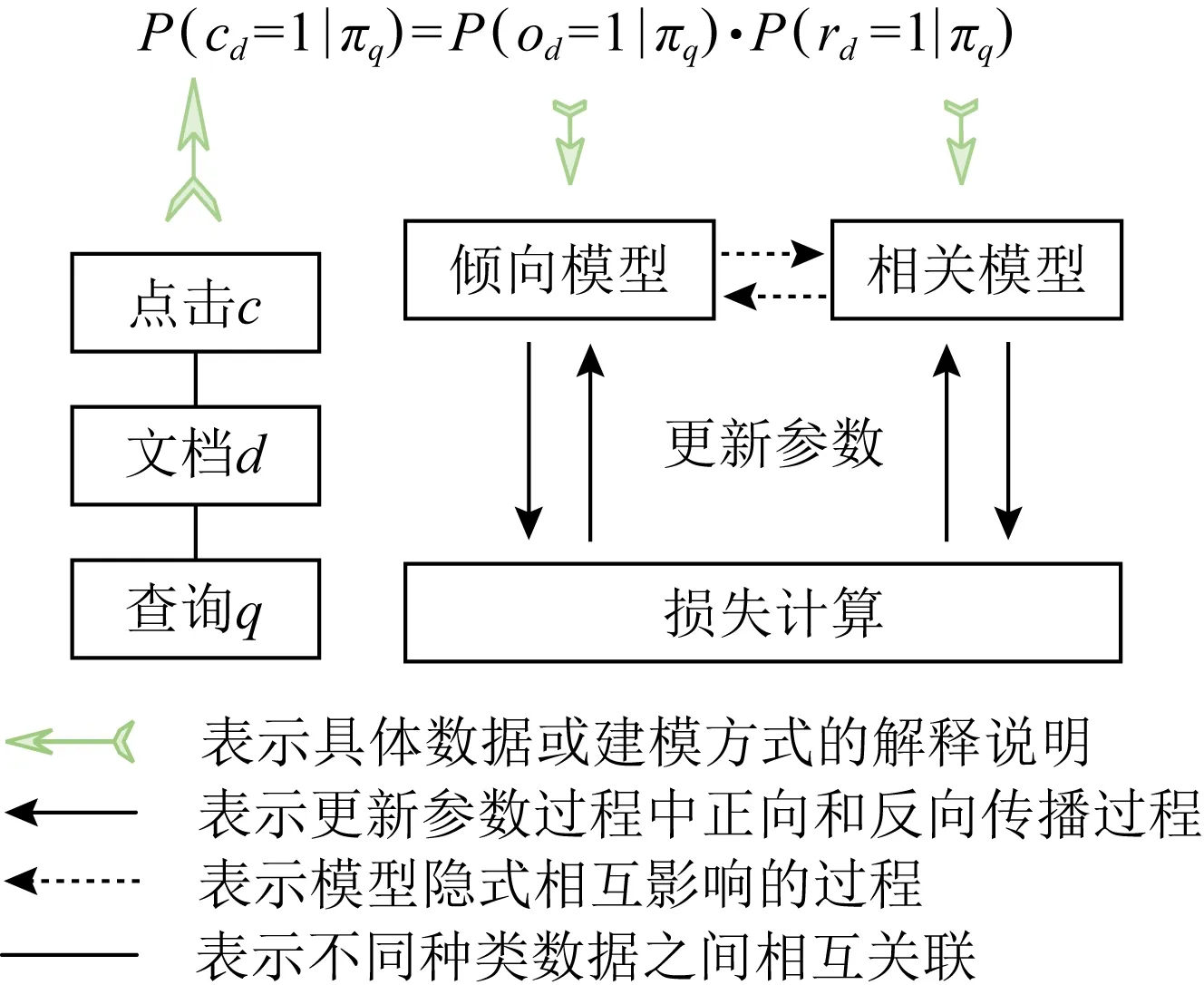
Fig. 2 Core ideas of dual learning algorithm图2 对偶学习核心思路
假设对每一文档d,用户点击某一文档当且仅当该文档被观察到且与查询相关,如式(1)所示:
P(cd=1)=P(od=1)×P(rd=1).
(1)
对于查询集合Q,倾向估计的目标是找到倾向模型P,使得损失函数达到最小:
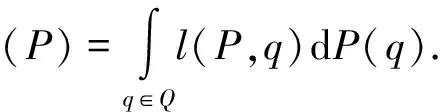
(2)
类似地,对文档进行正确排序的方法是找到排序模型R使得损失函数达到最小:
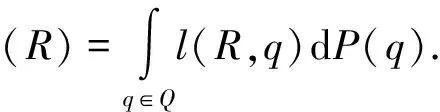
(3)
对偶学习方法将倾向估计和相关估计看作对偶问题,联合训练倾向模型和相关模型并得到最终模型参数.对于点击倾向模型,对检索记录被观察到的概率估计问题定义逆相关加权(inverse relevance weighting, IRW)损失函数lIRW(P,c)如式(4)所示:
(4)
其中Δ(P,cd|πq)代表文档序列πq中文档d的损失.可以证明逆相关加权后lIRW(P,c)是倾向模型的无偏估计,如式(5)所示.类似也可证明逆倾向加权后lIPW(P,c)是排序模型的无偏估计.
(5)
训练过程中,倾向模型对每一位置的文档输出其估计的用户点击倾向;相关模型对每一文档输出其计算出的相关概率;对用户点击分别乘以逆倾向权重和逆相关权重来计算相关模型和倾向模型的损失值并更新参数.经过多轮迭代直到模型收敛并得到最终的模型参数.
该方法的收敛条件是排序模型和倾向模型的目标函数为凸函数,但实际神经网络含有多个隐藏层,导致其损失函数非凸不能保证结果最优.
3 基于相关修正的对偶去偏方法
3.1 模型架构
针对上述模型收敛得到次优解的问题,本文设计一种基于相关修正的无偏排序学习方法,利用现有小规模相关标签训练模型并利用其对对偶学习进行调整和修正,从而得到更优的无偏排序模型.方案流程如图3所示:
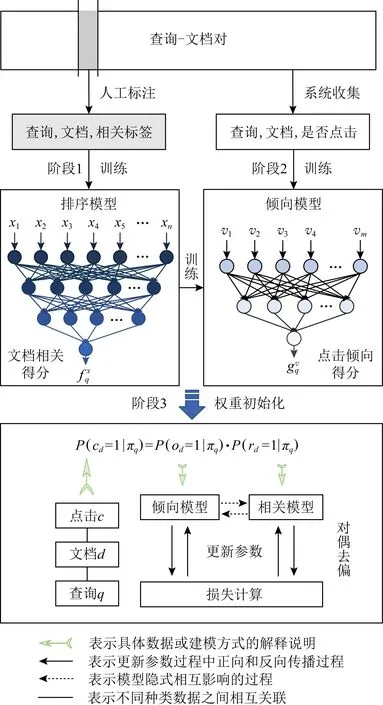
Fig. 3 Unbiased learning to rank based on relevance correction图3 基于相关修正的无偏排序学习方法
在小规模标签上预先排序模型可以对对偶去偏过程赋予更优的初始参数,因此在训练过程中,尤其是训练初期,排序模型和倾向模型输出的文档相关得分和点击倾向得分更加准确.这防止了对偶训练过程中文档相关得分和点击倾向得分在相互输出并计算损失时由于相关得分和倾向得分估计不准确导致迭代过程中错误的累积,从而促使最终模型收敛得到更优结果.
该方案包括以下步骤:阶段1.先在少量标注的相关标签上进行排序模型预训练;阶段2.利用排序模型输出的相关得分训练点击倾向模型;阶段3.利用训练好的模型对对偶去偏过程赋予初值并联合训练.
3.1.1 排序模型预训练
为统一输入的候选文档维度并减少计算量,在预训练数据输入之前先进行粗排.选用少量的训练数据训练模型并利用其返回排在前k位的文档,作为预训练排序模型的训练数据.
利用带有相关标签的训练数据,找到能够使得指定损失函数L(y,f(x))最小的函数f*:
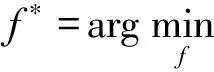
(6)
其中,f(x)代表排序模型输出得分,y代表对应的相关标签.理论上任何可以输出候选文档分值的排序模型都可以作为该模型的实现方式.
对每一查询q的候选文档列表,按照式(7)计算损失:
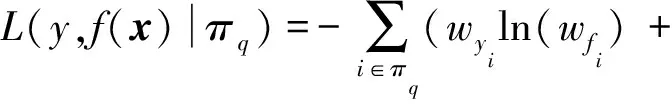
(7)
其中,i表示候选列表πq中第i个文档,yi为第i个文档的相关标签值,wyi为对每一文档分配的权重,其计算公式如式(8)所示:
(8)
文档与查询的相关程度越大,对应的权重wyi越高,该文档占损失的比重越大.在小规模相关标签上训练完成后,返回预训练得到的排序模型参数θ0.
3.1.2 对偶去偏
在执行对偶学习去偏过程之前,利用训练好的排序模型对每一查询-文档对输出文档相关得分.利用点击数据和相关得分,采用逆相关加权方法训练倾向模型P,返回其参数γ0.
将排序模型的参数θ0和倾向模型的参数γ0作为对偶去偏过程的初始值,并面向点击数据联合训练实现对偶模型的参数更新,得到收敛程度更好的最终模型.
能够有效利用经偏差校正后的损失函数均可用于本文提出的方案.为便于方法有效性验证和效果对比,选用与文献[17]相同的基于softmax交叉熵的损失函数如式(9)(10)所示:
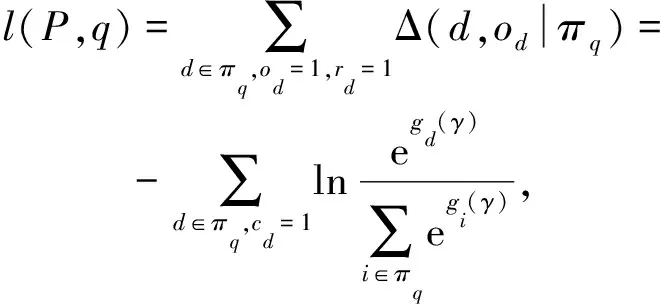
(9)
(10)
用户点击倾向概率和文档相关概率是通过倾向模型和排序模型对每一查询-文档对输出的分值gd(γ)和fd(θ)经过softmax变换后得到.
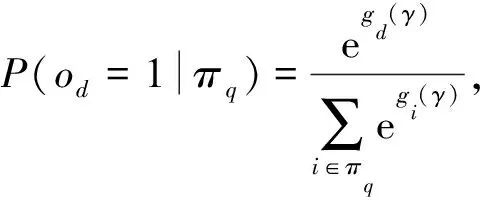
(11)
(12)
因此,经过逆倾向加权和逆相关加权后的损失函数如式(13)(14)所示.式中rk代表第k个位置的文档是否相关,ok代表第k个位置的文档是否被观察到.
(13)
(14)
对数据集中的查询集合Q,按照式(15)(16)计算倾向模型P和排序模型R的损失:
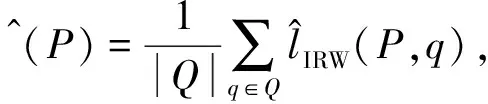
(15)
(16)
综上,本文提出的基于相关修正的对偶去偏方法如算法1.
算法1.基于相关修正的对偶去偏方法.
输入:查询集合Q,对q∈Q有集合{q,πq,cq};
输出:排序模型R的参数θ,倾向模型P的参数γ.
① 利用预训练的排序模型f*,对排序模型R的参数θ进行初始化赋值;
② 固定排序模型R的参数θ0,利用用户点击数据训练倾向模型P,得到参数γ0;
③ 随机抽取部分查询样本,利用式(11)(12)对每一查询计算展示列表中每个文档被观察到和被点击的概率;
④ 按照式(15)(16)计算倾向模型和相关模型的损失;
⑤ 根据损失计算梯度并更新模型参数θ和γ;
⑥ 重复步骤③~⑤,直到收敛.
3.2 有效性验证
令fi代表文档列表πq中第i个文档的相关性得分,将排序模型的参数固定,当满足式(17)时,基于相关修正的对偶去偏模型收敛.
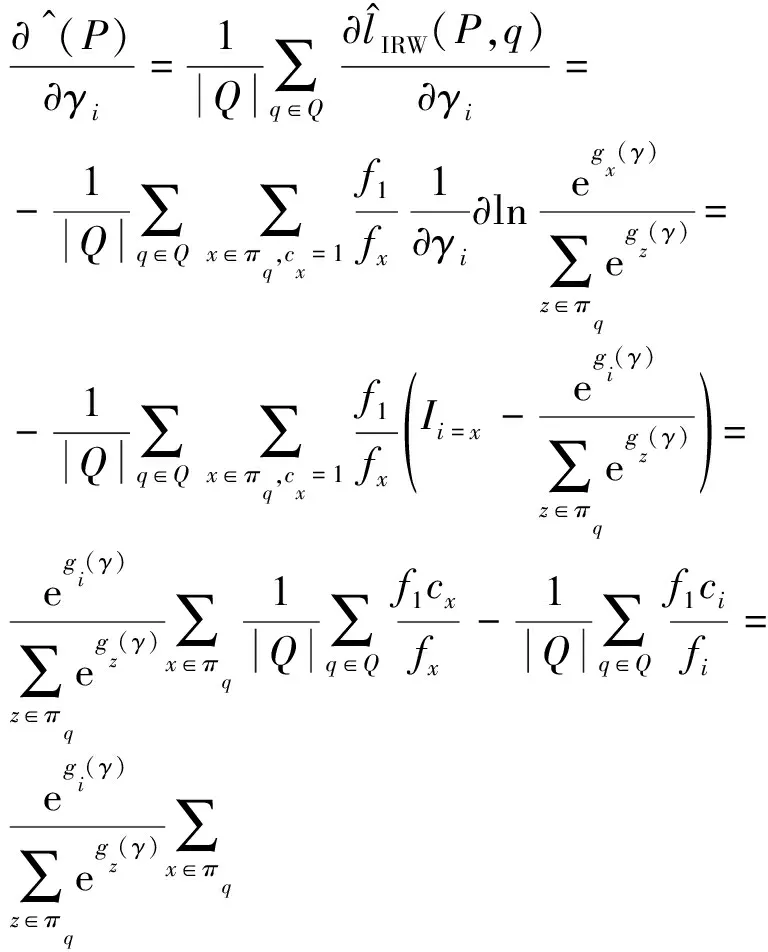
(17)
模型收敛时,最终得到
P(od=1|πq)=
(18)
此时,位置i处的逆倾向权重为
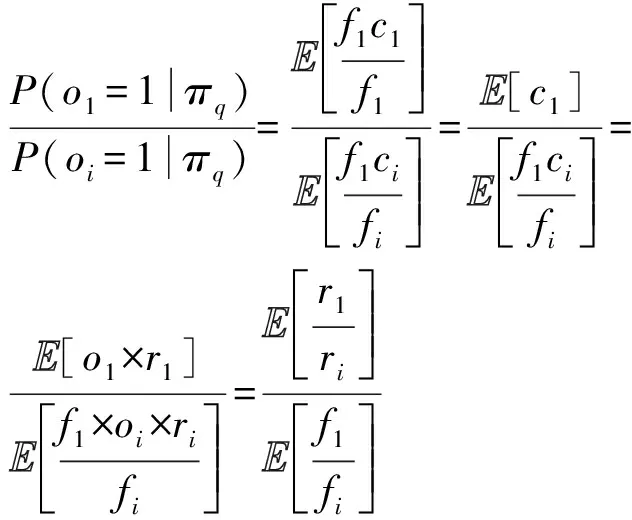
(19)
由上可知,通过赋予较好的参数初始值可以避免迭代过程中错误的累积,从而得到更优的无偏排序学习模型.因此,本文提出的无偏排序学习方法能够有效促进系统的性能提升.
3.3 计算速度
在线计算速度方面,由于本文提出的基于相关修正的对偶去偏方法通过预训练的排序模型和倾向模型对对偶去偏过程赋予较好的初始值,并未改变部署的对偶去偏模型的参数量,因此在模型上线部署后,计算速度与原有对偶学习方法一致.
离线训练时间方面,由于本文使用小规模的人工标注相关标签预训练排序模型,因此需在原有基础上会增加排序模型预训练的时间.然而实际场景下,系统往往已有预先训练好的表现较优的排序模型可直接用于参数赋值,且离线训练时间不影响用户体验与模型上线效果,故该因素可以忽略.
因此本文提出方法不影响模型的上线计算速度,能够应用于在线学习场景.
4 实验分析
4.1 基准数据集实验
实验选用公开数据集Yahoo! Learn to Rank Challenge[19]version 2.0 set1,该数据集总共包含29 921个查询和其对应的709 877个文档,每一查询文档对有700维度的特征向量及其对应的5分类水平(0~4)的相关标签.其数据特征如表2所示:
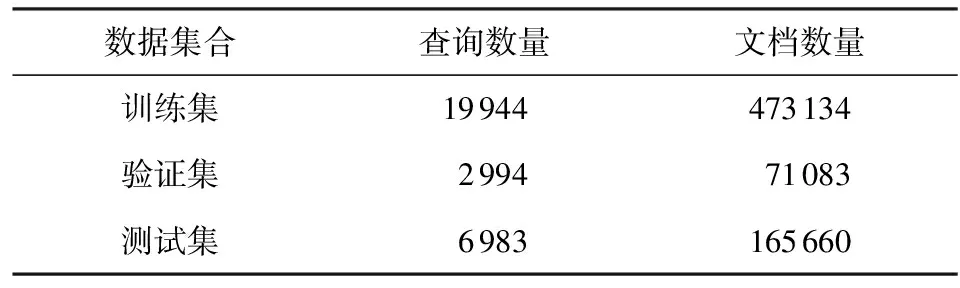
Table 2 Data Characteristics of Yahoo Dataset表2 Yahoo数据集数据特征
仿照文献[15,17]的方法,采用以下方法生成用户点击数据.首先,随机选取1%的训练数据和相关性标签训练Ranking SVM模型[20],得到对每一查询q的初始的结果序列πq,将该模型称作初始排序模型,设置参数c=200.然后模拟用户浏览检索结果的过程,引入参数控制偏差和噪声,计算点击概率并生成点击数据,步骤如下:假设用户在仅当文档被观察到并且与查询相关时点击该文档.按照式(20)通过文献[9]基于眼动追踪实验估计的展示偏差ρ计算观察倾向概率.
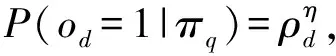
(20)
其中,η∈[0,+∞]是控制展示偏差程度的超参数,本文设置η的默认值为1.仿照文献[21]按照式(21)的方法计算文档相关概率.
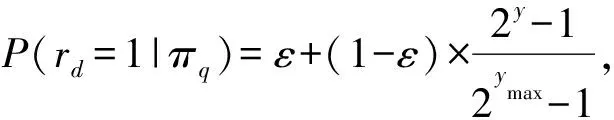
(21)
其中,y为文档的相关标签,ymax是数据集中相关标签的最大值,参数ε引入噪声故而不相关文档(yd=0)有一定概率被点击.实验设置ε=0.1.本文选用数据集的标签是5分类,因此ymax=4.对于每一查询,按照Ranking SVM模型输出的得分对文档进行排序,设置截止文档个数为10.
对偶学习方法的实现仿照论文设置学习率为0.05,批量大小(batch size)设置为256,网络迭代13 000次后结束训练.本文方法中倾向模型的迭代次数设置为3 000,学习率为0.05,批量大小设为256,对偶去偏网络迭代10 000次结束.不同比例的查询数据实验设置参数值如表3所示:

Table 3 Parameter Settings of the Pre-trained Ranking Model表3 预训练排序模型参数设置
4.1.1 可行性验证
为验证本文提出方法的可行性,对上述Yahoo数据集进行划分和构造.将训练集分成2部分:一部分通过随机抽取少量数据作为排序模型预训练的集合;另一部分查询-文档对通过模拟用户行为生成用户点击并用于无偏排序模型的训练,2集合的划分比例为2∶8.实验选用的验证集和测试集与Yahoo原始数据集相同.
由于相关标签有5个等级,因此选用多分类等级评估指标NDCG(normalized discounted cumulative gain)和ERR(expected reciprocal rank)展示其在第1,3,5,10位置上的结果,实验结果如表4所示.另外选用较常用的AUC(area under curve)和MAP(mean average precision)指标进行评估.表4中数据显示本文提出方法在各项指标上均优于对比方法,说明该方法能够有效提升现有方法的表现.
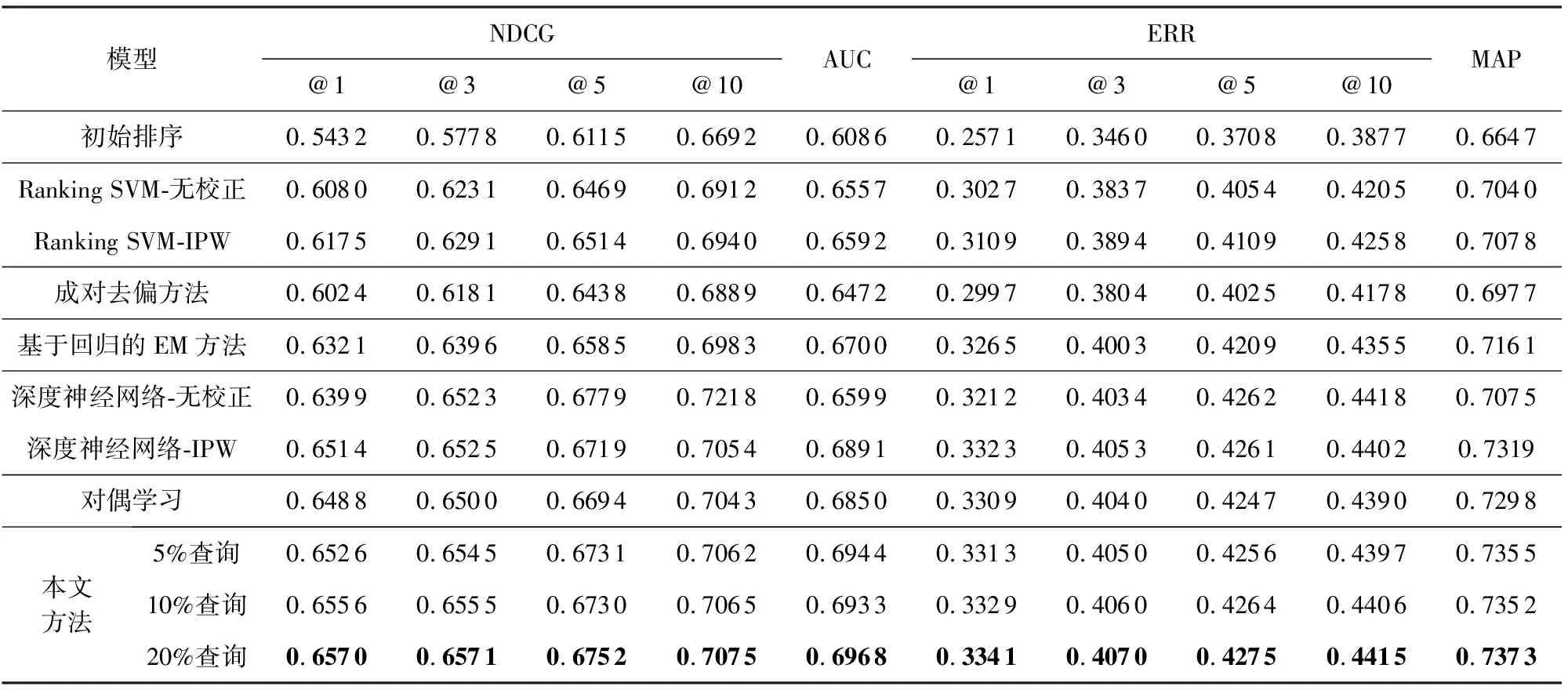
Table 4 Experimental Results on the Yahoo Dataset表4 在Yahoo数据集上的实验结果
4.1.2 偏差程度影响
表4结果表明点击数据偏差一定时,本文提出方法优于基准方法.然而真实情况下用户行为不断变化.选用不同的η值模拟不同程度的点击偏差,η值越大代表生成点击数据的偏差越严重,比较对偶学习方法和本文方法训练结果如图4所示.图中展示的本文方法是随机抽取20%查询训练排序模型并进行相关修正的结果,令η值分别为0.5,1.0,1.5,2.0并绘制NDCG和ERR在第1,3,5,10位置的结果.

Fig. 4 Results of different degrees of bias图4 不同偏差程度结果
图4中可以看到,在不同η值模拟的用户点击偏差场景下,本文提出方法效果均优于对偶学习方法.因此在不同程度的用户点击偏差场景下,本文方案能够有效去除偏差.
4.1.3 抗噪性能分析
为进一步验证方法的鲁棒性,在不同噪声场景下对比分析本文方法的性能,如图5所示.通过控制ε值的大小来模拟不同程度的噪声,其中ε值越大代表噪声程度越大.ε=0.3时表明用户有59.8%的概率点击不相关的文档.图5中结果说明在不同噪声程度下本文方法均有优越的表现.
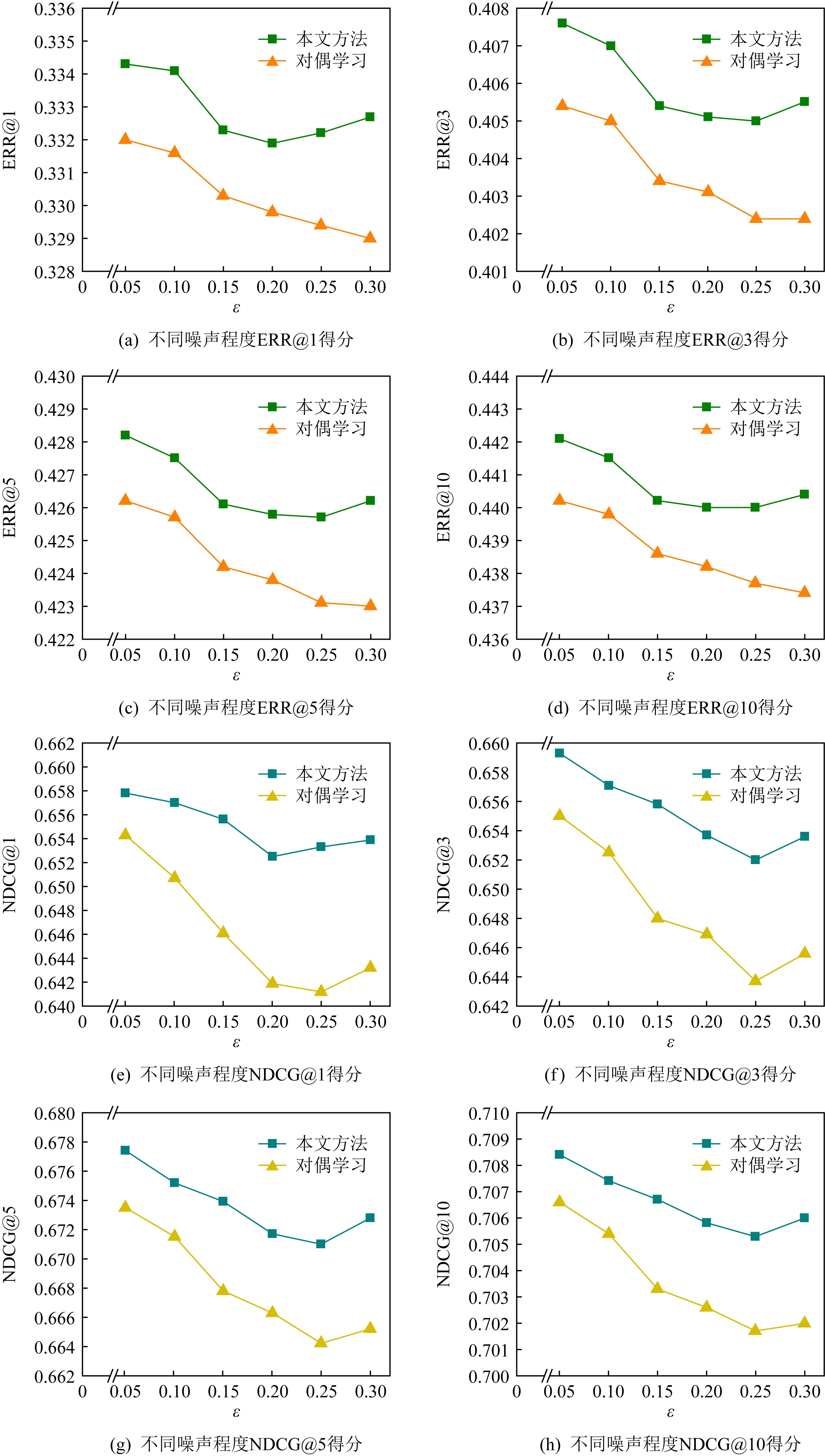
Fig. 5 Results of different degrees of noise图5 不同噪声程度结果
4.2 真实点击实验
为验证真实用户点击数据场景下本文提出方法的有效性,选用Tiangong-ULTR[17,22]数据集进行实验.该训练集包含3 449个查询、333 813个文档及其对应的真实用户点击数据;测试集包含100个查询和10 000个文档.按照2∶8对测试集进行划分,其中20%含有相关标签的数据作为排序模型预训练的数据,另外的数据用于模型评估与比较.
与现有点击模型方法级联模型CM、用户浏览模型UBM、位置模型PBM和对偶学习方法进行比较,结果如图6所示.可以看到,图6中展示的各指标表明本文方法均优于基准方法,证明了真实点击数据场景下该方案具有优异的性能表现.

Fig. 6 Results of the real click experiment图6 真实点击实验结果
5 总结展望
针对对偶学习方法存在的问题,本文提出一种新的通用无偏排序学习方法.利用现有小规模标注数据训练排序模型,对候选文档进行较精准的相关性判定,并对对偶去偏过程进行相关修正.通过预先训练的排序模型参数赋值操作避免损失函数非凸造成的次优解.该方法将无偏排序问题转化为在小规模标注数据上的排序学习问题,使得以往的排序模型能够应用于大规模点击数据.在模拟和真实用户点击场景下测试结果表明:本文方法能够有效提升现有方法表现.
未来可以将本文提出方法应用于大规模真实用户点击数据场景,并尝试不同种类的排序学习方法作为预训练模型以进一步提升无偏排序模型的性能表现.
作者贡献声明:王奕婷为论文主要完成人,负责实验设计与实施、文章撰写;兰艳艳对文稿提出针对性修改意见,完善课题思路和实验设计,负责文章审校;庞亮提供专业知识等方面帮助,负责文章实验部分的技术性指导;郭嘉丰对文章的知识性内容作批评性审阅并提出意见,提供工作支持;程学旗对所用方法缺陷提出改进意见.
