融合实体外部知识的远程监督关系抽取方法
2022-12-16高建伟万怀宇林友芳
高建伟 万怀宇 林友芳
(北京交通大学计算机与信息技术学院 北京 100044)(gaojianwei@bjtu.edu.cn)
作为自然语言处理领域中一个重要的基础研究课题,关系抽取旨在从无结构化的文本当中预测出给定实体对之间的关系事实.例如,从表1的第1行句子中,我们可以抽取出实体对Apple和Steve Jobs之间的关系是创始人.

Table 1 An Example of Sentences in a Bag Labeled by Distant Supervision
通常,大多数传统的关系抽取模型[1-3]都采用有监督学习的方法来进行训练,然而这一过程往往需要大量的高质量标注样本来进行支撑,非常的耗费人力.Mintz等人[4]提出使用远程监督的方法来缓解缺乏训练数据的问题,该方法可以通过将知识图谱(knowledge graph, KG)中的实体对与文本中相应的实体对进行对齐来自动生成带标签的训练样本.关系抽取中的远程监督是基于这样的假设来定义的:若在给定KG中的2个实体之间存在关系事实,那么我们认为所有包含该相同实体对的句子都表达了对应的关系.因此,远程监督方法所具有的这种强有力的假设不可避免地会伴随着错误标记的问题,从而导致了噪声数据的产生.
因此,Riedel等人[5]提出了一个使用多示例学习(multi-instance learning, MIL)框架的方法来缓解噪声数据的问题,这一方法提出了一种叫作“expressed-at-least-once”的假设来缓解先前约束较强的假设条件.该方法假设,在所有包含相同实体对的句子当中,至少有1个确实表达了它们的关系.在多示例学习框架当中,关系抽取的目标从句子级别变成了为包级别,其中每个包是由一组包含相同实体对的句子所组成的集合.此后,有许多研究者都受到该工作的启发,基于MIL框架开展了一系列的研究工作来提高模型选择有效句子的能力[6-9].其中,Lin等人[9]提出的选择性注意力框架使用注意力机制来为句子分配权重,从而能够充分地利用所有句子中所包含的信息.近些年来,基于选择性注意力框架,提出了一系列新的关系抽取模型[10-13],它们大多使用卷积神经网络(convolutional neural network, CNN)来作为句子编码器,证明了这一结构的稳定性和有效性.
然而,尽管上述框架结构被广泛使用在远程监督关系抽取领域,但是传统特征抽取器却忽略了广泛存在于实体之间的知识信息,这导致所捕获的特征有可能会误导选择有效句子的过程.例如,表1中句子“Steve Jobs was the co-founder and CEO of Apple.”和“Steve Jobs argued with Wozniak,the co-founder of Apple.”在句式结构上非常相似.因此先前的模型会从这2个句子当中捕获到相似的特征(即认为它们都表达了Steve Jobs和Apple是创始人的关系).在这样的情况下,如果缺乏实体知识信息,模型就无法很好地辨别出正确的信息来生成有效的包级别的特征表示.
为了解决上述提到的问题,本文通过探索额外的实体知识提出了一种实体知识增强的神经网络结构(entity knowledge enhanced neural network, EKNN).EKNN模型通过动态地将实体知识与词嵌入融合在一起,从而能够使模型将更多的注意力集中在与句子中给定实体对有关的信息上,提高了模型在句子级别的表达能力.本文的主要贡献有3个方面:
1) 提出了一种知识感知的词嵌入方法,将实体中的2种知识,即来自语料库的语义知识和来自外部KG的结构知识动态地注入到词嵌入中.
2) 在广泛使用的“纽约时报”(New York Times, NYT)数据集[5]上评估了EKNN模型.实验结果表明,本文提出的模型在2个版本的NYT数据集上的表现明显优于其他最新模型.此外,通过额外的对比实验确认了2个版本的数据集之间存在的差异.
3) 通过进一步的消融实验,分别探究了2种不同的知识在关系抽取任务当中的有效性.
1 相关工作
大多数有监督的关系抽取模型[1-3]都会遇到标注数据不足的问题,而手动标记大规模的训练数据既费时又费力.因此,有研究者提出了使用远程监督的方法来自动完成标记训练数据的工作[4].尽管远程监督在一定程度上缓解了人工标注数据的困难,但仍然会伴随着噪声数据的问题.Riedel等人[5]和Hoffmann等人[6]都提出利用多示例学习的方法来缓解噪声数据的问题,该方法不再使用单个句子作为样本,而是将包含相同实体对的句子所组成的集合看作一个整体来作为样本.
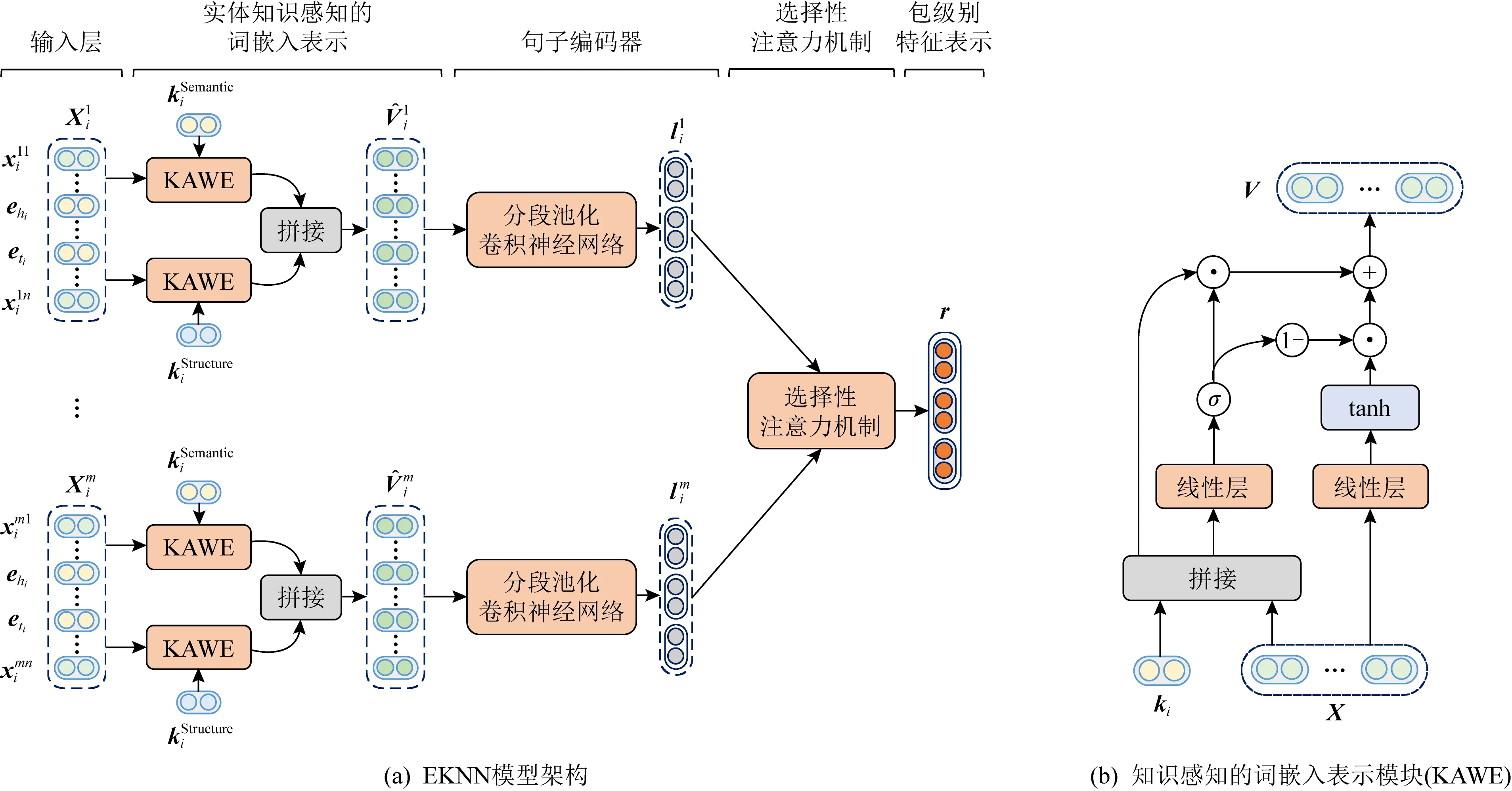
Fig. 1 The framework of our proposed neural architecture EKNN图1 本文提出的EKNN模型架构图
传统的关系抽取方法主要是基于人工设计的特征进行的.近年来,随着深度学习的发展,神经网络模型已经被证明可以有效地捕获句子中的语义特征,并且还避免了由人工特征所引起的误差传递[14-16].Zeng等人[8]提出了分段池化卷积神经网络(piecewise convolutional neural network, PCNN)从句子中更充分地提取实体之间的文本特征,并选择可能性最大的句子来作为包级别的表示.Lin等人[9]提出了一个选择性注意力框架,该框架通过对集合内的所有句子进行加权求和来生成包级别的特征表示,这一框架也被之后的许多研究工作所广泛地采用[11-13].Shang等人[17]则提出了一种基于深度聚类方法的关系抽取模型,通过无监督的深度聚类方法来为噪声句子重新生成可靠的标签,进而缓解噪声问题.此外,也有许多的工作尝试利用实体相关的外部信息来改善模型性能.Han等人[18]提出了一种用于降噪的联合学习框架,该框架能够在知识图谱和文本之间的相互指导下进行学习.Hu等人[19]利用知识图谱的结构信息和实体的描述文本来选择有效的句子进行关系提取.然而,这些方法大多数都仅仅考虑将知识信息用于降噪,并没有充分地利用实体知识中所蕴含的丰富的信息.
因此,在本文中同时引入了结构知识和语义知识来生成知识感知的词嵌入向量.通过这样的方法,知识信息可以更加深入地融合到模型中.
2 实体知识感知的神经网络模型
在本节中将介绍本文用于远程监督关系抽取的EKNN模型的整体框架和细节描述.
2.1 符号定义
2.2 模型框架
给定一个实体对(hi,ti)及其实体对包Si,关系抽取的目的是预测实体对之间的关系ri.模型的总体框架如图1(a)所示,主要有3个部分:
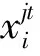
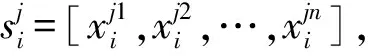
3) 选择性注意力机制.给定实体对包Si中所有句子的语义上下文嵌入表示,包级别的特征表示通过注意力机制计算得到,最终用于预测关系类型.
2.3 知识感知的词嵌入模块
关系抽取的目标是预测2个实体之间的关系.因此,实体对中所包含的信息是非常重要的.在当前的研究当中,实体对中仍然还有很多隐含的信息尚未得到充分的利用.受这一想法的启发,本文引入了语义信息和结构信息作为实体对的外部知识,以此来丰富传统的词嵌入表示.
2.3.1 语义知识嵌入
词嵌入技术由Hinton等人[20]首次提出,其目的是为了将词语转换为向量空间当中的分布式向量表示,以捕获词语间的句法和语义特征.因此,本文采用词嵌入作为语义信息的来源.给定一个实体对(hi,ti)及其词嵌入(ehi,eti),将实体对的语义知识嵌入定义为

(1)
其中,ehi,eti∈2dw.
2.3.2 结构知识嵌入
典型的知识图谱通常是一个具有多种关系类型的有向图,可以将其表示为一系列关系三元组(h,r,t)的集合[12].因此,知识图谱通常会包含有丰富的结构信息,可以将其看作本文结构知识的来源.本文使用TransE[21]作为知识图谱嵌入模型,以此来得到实体和关系的预训练嵌入向量.给定一个三元组(h,r,t)及其嵌入表示(h,r,t),TransE将关系r看作是从头实体h到尾实体t的一种翻译操作,如果(h,r,t)存在,则可以假设嵌入向量t应该接近于h+r.因此,将实体对的结构知识嵌入定义为

(2)
其中,hi,ti∈ds.
2.3.3 门控融合
为了能够动态地将实体对的知识与原始的词嵌入融合在一起,本文使用门控机制来生成知识感知的词嵌入表示.
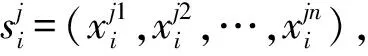

(6)
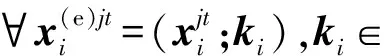
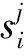
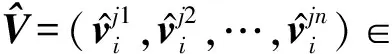
(7)
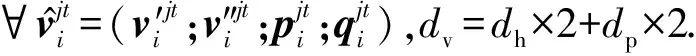
2.4 句子语义特征编码


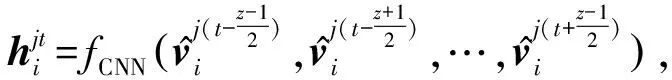
(8)
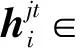
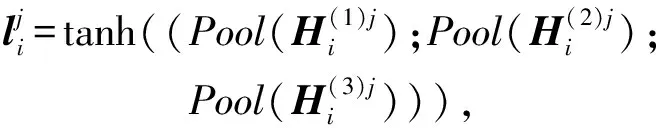
(9)

2.5 选择性注意力机制

(10)
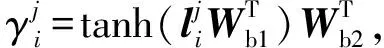
(11)
其中,Wb1∈db×3dc,Wb2∈1×db是可学习参数,db是超参数.之后,可以通过上述注意力分数来得到包级别的特征表示用于关系分类,其定义为
(12)
最终,特征r在经过线性变换后被送入到Softmax分类器当中.其计算公式定义为
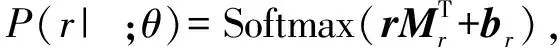
(13)
其中,Mr是变换矩阵,br是偏置项.同时,与Lin等人[9]相同,本文在包级别的特征表示r上使用了dropout[22]来防止过拟合.
2.6 模型学习
在训练阶段,本文尝试最小化交叉熵损失函数:
(14)
其中,θ表示模型中的所有参数,B=[S1,S2,…,S|B|]表示实体对包的集合,而[r1,r2,…,r|B|]则表示对应的关系标签.本文中所有模型均使用随机梯度下降(stochastic gradient descent, SGD)作为优化算法.
3 实验及结果分析
3.1 数据集
在Riedel等人[5]公开的“纽约时报”NYT数据集上对本文的模型进行了评估,该数据集是通过将Freebase中的关系与NYT语料库进行自动地对齐而生成的,它在目前许多最新的远程监督关系抽取研究工作当中被广泛使用.该数据集共包含53类关系和一个无关系NA标签,无关系标签表示2个实体之间没有任何关系.值得一提的是,在当前的许多研究工作当中存在2个不同版本的NYT数据集,这是由于一次错误的数据集发布所造成的(1)https://github.com/thunlp/NRE/commit/77025e5cc6b42bc1adf3ec46835101d162013659.这2个版本数据集之间的主要区别在于训练集部分不同,它们的测试集是相同的.具体而言,表2中列出了这2个数据集的一些数据统计情况.本文将这2个不同的训练集分别称为train-570K和train-520K.从表2中可以看出,train-570K和测试集在实体对而非句子上存在交集,而train-520K是比较干净的训练集,不存在交集.在交集部分,大多数实体对的标签为NA,这使得模型更容易区分标签为NA的样本.因此可以推断出,对于同一模型,使用train-570K数据集进行训练的效果会高于train-520K数据集.
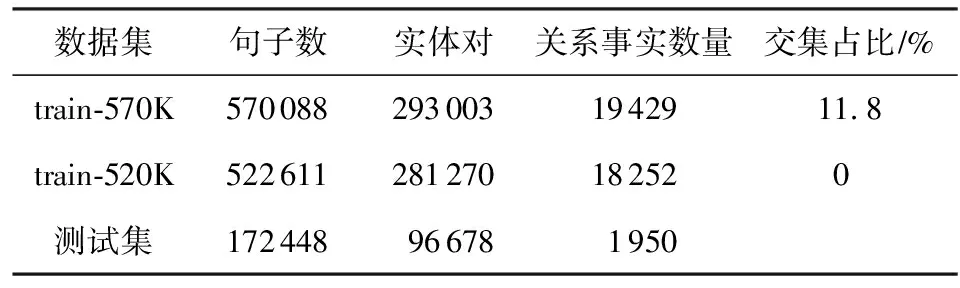
Table 2 Statistics of the NYT Dataset表2 NYT数据集统计情况
在评价指标方面,本文遵循了目前主流的研究工作[4,9,13],在NYT测试集上使用精确率-召回率(P-R)曲线以及该曲线下面积(AUC)和Top-N精确度(P@N)来作为评估指标.
3.2 实验设置
3.2.1 知识图谱嵌入
本文使用FB40K[23]来作为我们的外部知识图谱,它包含大约40 000个实体和1 318种关系类型.为了生成预训练的知识图谱嵌入,使用OpenKE Toolkit[24]进行训练,其中嵌入向量的大小ds=100,超参数margin=5,学习率设置为1,迭代轮数为500轮.值得注意的是,FB40K和测试集在实体对上没有的任何交集.因此,在外部知识图谱FB40K中不会包含任何出现在测试集中的实体对.
3.2.2 参数设置
在实验中,通过网格法对超参数进行了选择,其中批量大小B∈{50,120,160},CNN卷积核个数dc∈{64,128,230,256},隐藏层db∈{256,512,690},平滑参数λ∈{30,35,40,45,50},其余参数则与前人工作[9,12-13]保持一致.同时采用了Lin等人[9]发布的50维的词向量用于初始化设置.表3列出了在2个版本的训练集上进行实验使用的所有超参数情况.此外,对于优化算法,在train-570K和train-520K上分别使用学习率为0.1和0.2的mini-batch SGD算法进行训练.
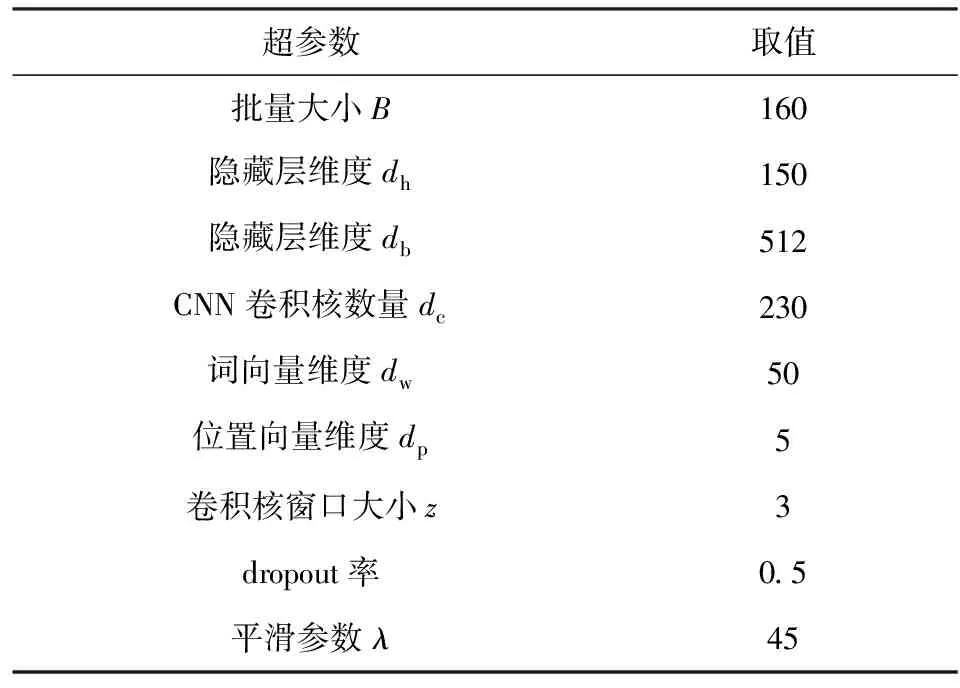
Table 3 Hyper-parameter Settings in Our Experiments表3 本实验中的超参数设置
3.2.3 基准模型
为了对本文所提出的EKNN模型进行评估,将其与当前最新的基准模型进行了比较:PCNN+ATT[9]是最基础的选择性注意力模型;+HATT[12]采用层次注意力机制,在长尾关系抽取上的效果有很大的提升;+BAG-ATT[13]分别使用包内和包之间的注意力机制来缓解句子级别和包级别的噪声;JointD+KATT[18]设计了一个联合学习框架,通过知识图谱和文本之间的相互指导学习来进行降噪;RELE[19]通过知识图谱的结构化信息来指导标签嵌入(label embedding)的学习从而进行降噪,提高了关系抽取的性能.此外,本文还与传统的基于特征的模型进行了对比,包括Mintz[4],MultiR[6],MIML[7]等.
3.3 对比实验结果与分析
从表4中所列出的P@N值结果中可以看出,对于CNN+ATT和PCNN+ATT,使用train-520K进行训练的P@N要明显低于使用train-570K进行训练的P@N.这一实验结果与数据集上(表2)所观察到的现象是一致的,即训练集和测试集之间的实体对存在交集可以在一定程度上提高模型在关系抽取任务上的性能.而对于当前最先进的研究方法,也使用train-520K重新进行了训练.与上述实验结果相似,这些模型的结果在train-520K也出现了显著的性能下降.而所提出的EKNN模型在2个训练集上进行训练的结果也有所不同.但是与其他基准方法相比,在train-570K和train-520K上分别进行训练时,本文的方法在P@N指标上仍然要明显地优于其他方法.具体而言,在P@N均值这一指标上,相比PCNN+ATT模型在2个训练集上分别提升了11.6%和5.0%.此外,与最优的基准模型+BAG-ATT相比,本文所提出的模型在2个训练集上也有着显著的性能提升.上述结果证明了本文所提出的远程监督关系抽取方法的有效性.

Table 4 P@N Values of Different Models on the Two Training Sets表4 各模型在2个训练集上的P@N值 %
此外,图2和表5也分别展示了精确率-召回率(P-R)曲线和AUC的结果.从图2中的P-R曲线可以看出,随着召回率的提升,各模型的精确率出现了急剧的下降,这是由于远程监督数据集中的噪声问题所导致的.而从表5中的AUC值还可以看出,对比train-570K上的结果,包括本文模型在内的所有模型在train-520K下进行训练都有不同程度的性能下降,这与表4中的P@N指标的结果是一致的,也同样验证了在3.1节中所作的分析.但是,对比最优的基准模型+BAG-ATT,本文的方法在train-520K上仍然有显著提升,这进一步证明了本文所提出模型的性能提升是稳定且有效的.具体而言,本文在2个数据集上,+BAG-ATT的AUC指标分别提高了0.12和0.05.

Fig. 2 Precision-recall curves of the proposed model and other baseline models图2 本文模型与其他模型的精确率-召回率曲线
3.4 消融实验结果与分析
为了进一步验证本文所提出的方法中不同模块的有效性,本文进行了充分的消融实验,旨在探索什么样的实体知识对于关系抽取任务更有价值.消融实验的P@N指标结果在表4的6~8行列出,而精确率-召回率曲线和及其相应的AUC值在图3和表5的部分区域进行展示.其中,w/o All表示去掉本文中设计的所有新模块,相当于最基础的选择性注意力模型[9].在接下来的分析当中,可以将其作为基准和其它模型进行对比.
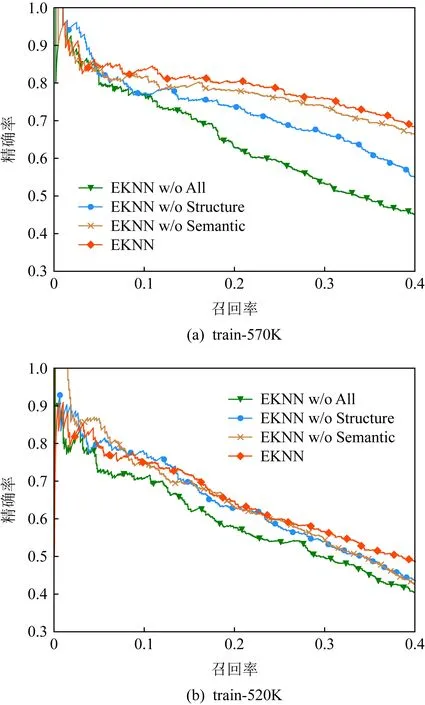
Fig. 3 Precision-recall curves for the ablation study图3 消融实验的精确率-召回率曲线
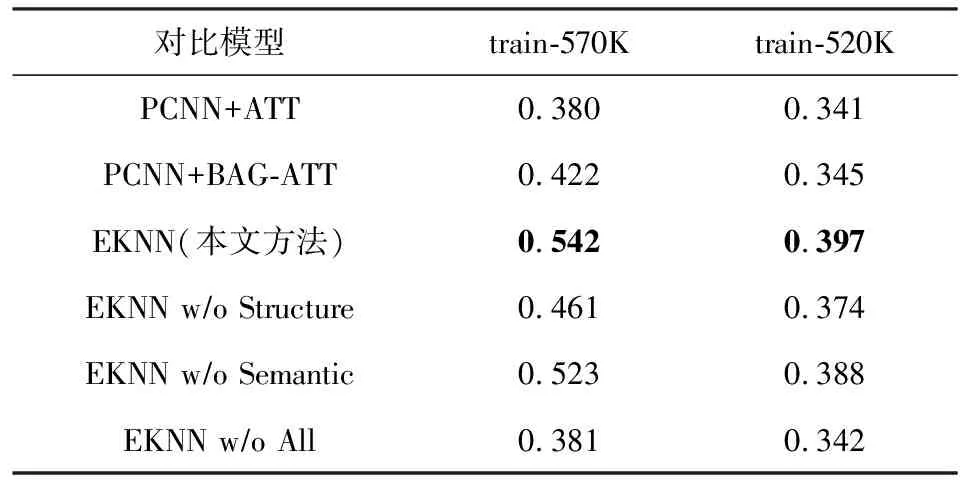
Table 5 AUC Values of Different Models on the Two Training Sets
在本文提出的EKNN模型中,引入了2类实体知识,分别为模型提供语义信息和结构化信息.为了验证它们的有效性,设计了2个变种模型.具体而言,w/o Semantic和w/o Structure都表示丢弃其中一类知识而保留另一类.从结果当中可以发现,2类实体知识都可以丰富模型的表达能力,并显著提高模型性能.以train-520K为例,假如去掉整个知识感知词嵌入模块(w/o All),P@N值和AUC指标分别下降了4.8%和0.055.此外,通过对比w/o Semantic和w/o Structure这2个变种模型,可以了解到在关系抽取任务当中结构化信息比语义信息具有更大的价值,这是由于模型从结构化数据中所学到的隐式嵌入具有更强的推理能力.
3.5 不同知识融合方式的对比实验分析
为了验证本文知识融合方法的有效性,本文与当前主流的融合知识的远程监督关系抽取方法进行了对比,实验结果如表6所示:
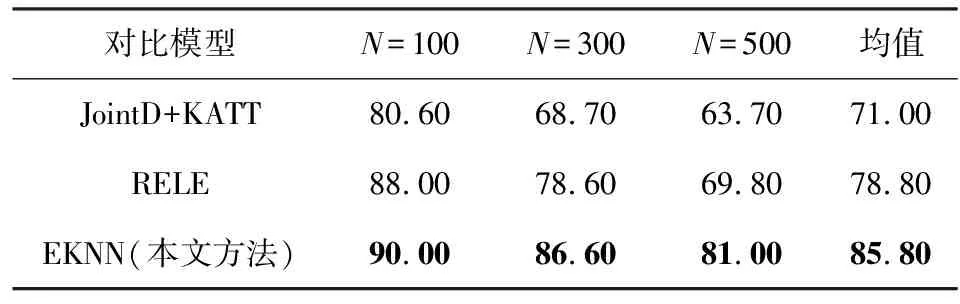
Table 6 P@N Values of Different Knowledge Integration Methods
从实验结果中可以看出,所提出的实体知识感知的词嵌入模块拥有更加优越的性能提升.这是由于JointD+KATT和RELE仅仅考虑了将知识信息用于模型训练和指导降噪的过程,而忽略了实体知识中所蕴含的丰富表示.EKNN模型通过知识信息和词嵌入表示融合的方式,更加深层次地将知识整合进了模型,对实体知识进行了更充分地利用,因而获得了更好的性能表现.
3.6 平滑参数λ对模型性能的影响
在实体知识感知的词嵌入表示模块当中,超参数λ用于对知识融合的过程进行平滑控制,图4给出了不同的λ值对于模型性能的影响.从图4中可以看出,当λ值在40~45之间时,模型中的实体知识和词嵌入可以实现相对较好的融合效果,从而提升模型性能.
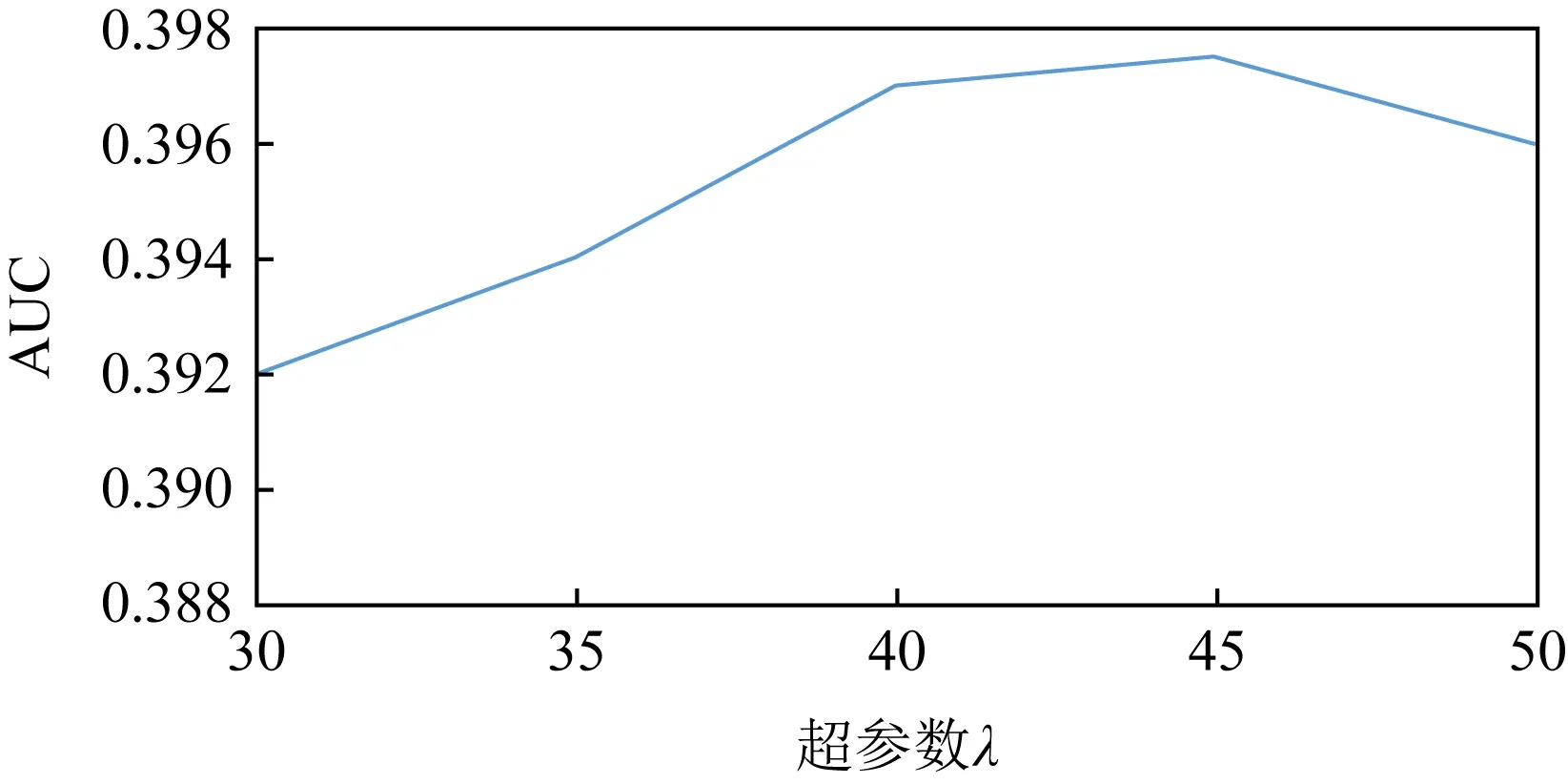
Fig. 4 The effect of hyperparameter λ on model performance图4 超参数λ对模型性能的影响
4 总 结
本文提出了一种用于远程监督关系抽取的神经网络模型EKNN.为了提高模型的表达能力,引入了2类实体知识(即语义知识和结构知识)来动态地生成知识感知的词嵌入.通过丰富的对比实验,证明了本文的模型性能显著优于当前最优的方法.此外,本文还通过对比实验探究了“纽约时报”数据集上2个版本的训练数据之间的差异,结果表明,由于排除了数据集间的实体对交集,train-520K数据集比train-570K数据能够更有效的反映模型性能.
作者贡献声明:高建伟负责模型设计以及文章的撰写;万怀宇负责方法概念的提出文章的润色和审阅校对;林友芳负责实验数据的管理、文章的润色和审阅校对.
