基于序列帧的三维人体重建*
2022-12-10郑承绪姚剑敏林志贤
郑承绪, 姚剑敏,2, 严 群,2, 林志贤
(1.福州大学 物理与信息工程学院,福建 福州 350108;2.晋江市博感电子科技有限公司,福建 晋江 362200)
0 引 言
计算机技术和信息技术飞速发展,使得对使用三维技术的需求也与日俱增。三维建模的相关项目逐渐进入到了社会的各行各业,包括机械、医学、影视娱乐甚至教育领域,三维技术都扮演着越来越重要的角色,成为计算机领域的重要课题之一。传统意义上的三维人体模型的制作仍然是基于专业人员通过相应的建模软件将模型从无到有一步一步制作出来,其中所需要消耗的时间和精力是十分巨大的。或是使用三维捕捉技术、三维扫描技术等进行人体建模,但这需要在模特身上装配大量定位设备、在环境中配置多个多功能摄像头,专业度极高、器件价格也非常昂贵,难以在大众领域应用。
近年来,深度学习算法广泛发展,大量研究者开始通过多种方法训练神经网络以进行三维重建工作。在人体建模方面,Danerek R等人[1]提出了通过利用动作捕捉器获得的人体和姿势训练神经网络来估计三维顶点位移重建人所穿着的三维衣物。Kanazawa A等人[2]提出了不需要2D与3D配对监督的三维人体重建,运用三维回归迭代和求解先验姿势来对图像中的人物进行三维重建。Alldieck T等人[3]实现了只通过单目相机拍摄序列帧就能进行的重建。在图上标注人体关键点,利用镜头至人物轮廓的射线集视椎体的变换获取数据并使用SMPL(skinned multi-person linear)[4]进行重建。之后,Alldieck T等人又提出了一种基于深度学习的网络模型[5]。能较之前使用更少的输入图像重建,并且提升了重建的速度和精度。Zheng Z等人[6]运用卷积神经网络(convolutional neural network,CNN)以及多尺度特征转换法,利用从SMPL模型、RGB图像中重建人体及衣服。在面部重建与训练方面。刘成攀等人[7]提出了一种脸部三维重建方法,使用了自监督的表征法映射特征实现三维人脸重建。Chen A等人[8]的方法回归运算单个输入视图的几何残差,来重建出较为精细的面部结构。而Wu F等人[9]的方法基于多个输入图像,回归运算了可变形的面部模型。
本文受此启发,将端到端可学习的多视图三维面部重建[10]与基于序列帧的三维人体重建[5]方法相结合,使用特征图金字塔[11]和多损失函数,结合了基于学习的方法的稳定性以及几何推断方法的通用性,有效提升了重建精度。
1 方 法
阐述三维人体模型的生成与优化。首先,介绍三维人体模型生成架构,包括编码器和解码器两个模块;接着,描述生成高精度面部模型的算法与内部结构;最后,介绍模型训练时引入的损失函数。
1.1 三维人体模型的生成
图1所示为三维人体重建网络模型框架。该网络的作用是从单目RGB 相机拍摄的人物获取输入序列图像,以创建一个与人物对应的三维人体模型。该模型能够一定程度地还原被拍摄者的身材外型,头发以及衣服等内容。由于人体是一个复杂的非刚性物体,为了尽量减小非刚性形变,需要拍摄保持一个大致的“A形姿势”并旋转一周的人物来进行三维重建。为此而训练的CNN,能够从数张输入帧推断出一个三维网格模型,并且能利用该网络的解码器部分来细化身体形状以尽量还原被拍摄者的身材体型以及外观。

图1 三维人体重建网络模型框架
该网络使用了一种参数化的人体模型SMPL[4],能够以调节参数以及调整偏移量的方式来体现人物的特定体型、衣着与头发等特征。是将姿势θ和形状β映射到其总共6 890个顶点上来表示人体特征的函数。通过修改θ和β的值,以及在标准模型项T上加入偏移量D,就能通过如下函数获得一个具有特定体型与姿态的人体模型
M(β,θ,D)=W(T(β,θ,D),J(β),θ,W)
(1)
式中W为具有权重W的线性混合函数,J为骨骼关节点集。
尽管该模型能够在一定程度上还原对象的体型和衣着外观,并且只需要使用简单拍摄的单目RGB图像序列就能生成,但也因此,重建出的模型肯定具有一定的误差,尤其在于该模型对于脸部形状细节的提取程度很低,但脸部是辨识一个人物的重要标志之一,要实现更高精度的人体重建,更细致的脸部建模是一个关键。由此引入非刚体三维脸部建模方法[10]以提升重建的精确度。重建效果对比如图2。

图2 三维人体重建(左),使用面部优化重建(中),模特(右)
1.2 非刚体三维面部建模
本文引入非刚体三维面部建模来改善模型面部的精度。这是一个通过输入的图像序列之间的外观一致性关系来建立面部三维模型的深度神经网络。该框架主要由:特征提取、生成自适应性人脸模型和非刚体多图像重建3个部分组成。在本节中,首先介绍非刚体多视图重建部分是如何通过深度学习与求解器集成的,然后介绍自适应性面部模型的原理,最后介绍多级重建方法和损失函数。
1.2.1 非刚体多输入视图的重建
给定同一个人物的M个不同表情与视角的面部图像组{Ii}M,面部三维几何估计Vi,和对应的六自由度头部姿势pi,就可以通过在训练中尽可能降低外观连续性的误差与界标拟合误差来建立公式,命名为非刚体多视图优化。该方法能够重建出高度还原被拍摄者样貌的面部模型。本文将该模型应用于文献[5]的方法模型上,能够显著提升脸部模型的精细度。图3显示了非刚体多视图建模方法的网络框架。

图3 非刚体多视图重建网络的框架
参数化:该结构使用弱透视的相机将头部姿势模型参数化为p=(s,R,t)。其中,s为尺度因子,R为三维旋转矩阵SO(3),t为二维空间坐标,表示p在二维图像平面上的平移量。接着构建三维到二维的投影函数∏,将三维空间的点v映射到二维图像平面
(2)
然后参数化脸部形状V=f(x)。其中,f(x)为生成器函数,V为三维空间的参数。f(x)将低维度的参数向量x映射至含有所有顶点的三维坐标向量上。因此,非刚体多视图重建的参数就可以表示为X=(s,R,t,x)。
目标函数
E=λαEα+λlEl
(3)
式中Eα为每一个输入图像之间的外观一致性误差,而El为脸部标记的对齐误差。两个λ参数是用于平衡两个目标的权重。
通常来说,Eα的计算都是以图像序列之间的图像强度值变化为指标的。可以通过使用式(2)将每一张视图的三维重建结果(Vi,pi)投影至二维图像Ii上,并使用双线性插值法获取它们的图像强度采样。这样就获得了每一个顶点上对应的图像强度I(vi)。然后计算每一对不同的视图(i和j)中对应顶点之间的图像强度之差,再对所有视图中的所有该差值综合取平均值。总结获得如下公式
(4)

(5)
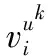
(6)
1.2.2 目标和求解器
极度非凸的强度空间可能会使得求解模型优化变得非常困难,受到刚体三维重建[12]和动作评估方法[13]的启发,引入了与此两个方面相关的深度学习内容。
(7)
步长的预测:为了保证训练效果的稳定与可靠,需要严格控制梯度下降的步长α。但是该方法能够根据所有的顶点和视图的平均值和输入图像序列之间的绝对残差来学习预测步长α。
1.2.3 适应性的脸部模型
为了能够更好地利用现有的三维可变形模型而不受制于其表现能力,要使用含有2个线性子空间的适应性人脸模型参数x=(xbfm,xadap)。脸部的形状V如式(8)所示
(8)


F′i=F′fpn(Ii)
(9)
这样就获取了M个特征图。接下来就能通过将这些特征图和初步重建结果送入基准网络Fbasis以构建出适应性基准Badap
(10)
1.2.4 多级重建
使用多级重建的方法以构建出更加具有细节的三维人脸模型。具体而言,即将整个重建模型的过程划分为3个等级l(l=1,2,3)逐步优化
(11)
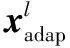
1.3 损失函数
给定网格真实值,FPN的步长预测和基准网络Fbasis,在计算过模型之间的深度对齐与密集对齐之后,就能计算在每一次迭代、优化时的每一个重建顶点和顶点真实值之间的距离L2。对于深度对齐项,需要计算
(12)
(13)
其中,深度对齐损失Lv_dep也会对姿态进行计算,而密集对齐损失Lv_den只计算模型之间的几何误差。
同时,为了确保表面的方向正确,需要运用余弦相似度来监督每个顶点的法线
Lnorm=∑(1-cos(ngt,nalign))
(14)
为了在提高表面平滑度的同时保留细节,还需要引入边缘损失
(15)
式中E为预定义的标准模板边缘。最后,还需要一个脸部标记损失式Lland,和式(5)较为相似。综上所述,得出综合损失函数
L=λ1Lv_den+λ2Lv_den+λ3Lnorm+λ4Ledge+λ5Lland
(16)
式中λ1~5均为超参数,用以调节不同损失项的权重。
2 实验与结果分析
2.1 数据集
本文采用ESRC三维脸部数据集进行训练。该数据集包含超过130个不同年龄、不同肤色的人物的照片和对应的高质量三维扫描模型。其中大多数人物都含有8组不同表情的模型,每一组的扫描模型都带有各个不同头部偏航角的RGB图像。
2.2 数据扩充
由于这批数据的数量还不足以训练神经网络,为了减少工作量,本文方法对图像进行了诸如曝光、压暗等渲染处理,提高数据的多样性,最终扩充到大约7 000张。
2.3 实验配置
本文设计使用TensorFlow深度学习框架,通过Pytorch实现;使用Nvidia-1080Ti设备来训练网络;计算机配置为Windows10操作系统,8 G内存。在多级优化重建过程中,所使用特征图的分辨率分别是32×32,64×64,128×128。这个过程还会在每级的运算中对参数进行3次的迭代更新。
2.4 结果分析
首先评估输入视图数量对该方法的影响。本文方法从数据集中被拍摄者的图像中随机选取4个图像,并按照头部偏角由小到大的顺序进行排序,分别测试输入图像数为2张、3张、4张时的重建效果。由于输入2张图像是使用的是首尾2张图,故最后只计算第一张图像和第四张图像的误差更为合理。结果如表1所示,通过引入更多的序列视图,该方法的平均几何误差将会减少,证明了多视图输入对于降低误差的有效性。最后一行是三维人体重建的平均顶点误差对比。经过实验得出,非刚性面部重建的顶点误差在输入4张以上图像时达到收敛,误差值为1.18 mm。而三维人体重建的顶点误差在输入8张以上图像时达到收敛,脸部平均顶点误差约为3.20 mm,明显大于该方法的误差,证明了使用非刚体脸部三维重建优化的有效性,能够显著提升对象的面部辨识度。

表1 不同视图输入数的平均几何误差
此外,还需研究多级重建对于减小误差的有效性。表2为使用BU3DFE数据集下的定量分析结果。

表2 多级重建下的误差
可见,几何误差和标准差随着每一级优化而逐级降低,证明多级了优化的有效性。图4为三维人体重建结合了非刚体面部重建模型的效果对比。

图4 (a)输入图集;(b)三维人体重建;(c)非刚体多视图面部三维重建;(d)面部效果对比
表3为引入FPN的本文方法的面部重建与其他文献[15,16]2种方法的误差对比,证明了本文方法的有效性。表4为了验证本文方法在实际应用时的有效性而进行了一项调查。拍摄并生成了6组本文方法与文献[5]的方法的三维重建模型,并向每个参与调查者展示和随机询问:“哪个重建模型更加能辨认出是图像中的人(辨识度)、哪个模型具有更多的细节(细节)”。

表3 与其他方法的误差对比

表4 调查的结果 %
调查结果如表3所示,分别有超过96 %和超过97 %的参与调查者认为本文方法所重建出的模型具有更高的辨识度和细节,证明了本文方法的有效性。
3 结束语
本文详细介绍了非刚性面部多视图重建网络,这是为重建出高精度人脸三维模型而设计的。本实验在原有的通过单目RGB相机拍摄序列图像以重建三维人体的模型中引入非刚性面部重建模型,添加FPN,能够帮助重建出更高精度的面部模型。应用于重建三维人体的面部时,能够显著提升人物的辨识度。实验结果证明:面部顶点误差能够显著降低,达到1 mm级别的误差水平。以及在调查中超过96 %的参与者认为本文方法具有更好的效果,证明了该方法对于大众领域使用普通非专业设备就能获得个性化的、识别度更高的三维模型有一定帮助。
