基于位置辅助标记的实体关系抽取方法
2022-12-03欧阳康朱艳辉孔令巍黄雅淋金书川沈加锐
欧阳康 ,朱艳辉 ,张 旭 ,孔令巍,黄雅淋,金书川,沈加锐
(1.湖南工业大学 计算机学院,湖南 株洲 412007;2.湖南省智能信息感知及处理技术重点实验室,湖南 株洲 412007)
1 研究背景
近年来,各大网络社交及传媒平台带来的信息数不胜数,如何快速、精准地获取其中的关键信息是一个巨大的挑战。信息抽取随之诞生,关系抽取(relation extraction,RE)作为信息抽取的子任务,通过二分类方法判定语句中是否存在关系,并通过多分类的形式判定该语句存在何种类型的关系。在关系分类任务中,往往需要事先定义关系类型,然后判断文本中实体间是否可能存在某种关系类型。该形式可描述为三元组
随着时代发展,信息抽取技术在文本信息化工作中起着越来越不可忽视的作用,也吸引了国内外学者对前沿技术的探索。传统的关系抽取方式大多采用流水线的方式进行,流水线方式抽取包含两个子任务:命名实体识别(named entity recognition,NER)和关系分类[1-2]。流水线方法指将实体关系抽取以流水线方式进行,即第一步是进行实体识别,在实体识别完成之后,再进行关系抽取。早期工作中,D.Zelenko[3]、Chan Y.S.等[4]以流水线的方式处理关系抽取任务,他们通过两个独立的步骤提取关系三元组:首先,在输入句子上通过命名实体识别的方式识别出文本中所有实体;提取出实体对后,在该基础上进行关系分类。流水线方法通常存在错误传播问题,而且会忽略两个步骤之间的相关性,为了缓解这些问题,现有研究已经提出许多旨在共同学习实体和关系的联合模型。
联合抽取方法的出现,较好地解决了流水线方法中存在的误差传播问题,能够更好地利用子任务之间的关联性。该方法选择对命名实体识别和关系分类采用联合建模,能够较好地利用实体和关系之间的交互信息,同时抽取实体并分类实体对的关系。联合抽取通常是先提取实体对,然后再对关系进行分类或采用统一标注的方式来解决实体关系抽取问题。早期Yu X.F.[5]、Li Q.[6]、Ren X.等[7]提出的基于特征的联合模型需要复杂的特征工程过程,严重依赖各种NLP(natural language processing)工具且需手动操作,操作繁琐。为了减少这种手工操作,最近的研究着重于基于神经网络的方法来解决问题。M.Miwa 等[8]提出一种端到端的神经网络模型,该方法首次将深度网络和依存树进行结合,通过该方式来进行实体和关系抽取,该论文的成果为后续实体关系联合抽取的研究奠定了基础。Zheng S.C.等[9]通过序列标注的方式解决实体关系联合抽取,该方案可以获得实体信息和它们所持有的关系,摆脱了复杂的特征工程,且该方法可以直接将关系三元组作为一个整体进行建模,但该方法并未解决关系重叠问题。
关系往往指两个实体之间存在的某种联系,关系重叠即某实体和其他实体可能存在一种或多种关系,将这种情况分为单实体多关系(single entity overlap,SEO)和同实体对存在多关系(entity pair overlap,EPO),如图1,实体“战狼2”与“吴京”和“卢靖姗”3 个实体之间分别拥有“导演”、“主演”的关系,称之为SEO 问题;实体“吴京”和实体“战狼2”分别拥有“导演”和“编剧”两对关系,称之为EPO 问题。
针对关系重叠问题,Wei Z.P.等[10]提出了CASREL 模型,通过一种新的级联二进制框架先预测出文本中所有可能是主体的实体后,下一步通过预测出的主体预测与其相关联的客体。Wang Y.C.等[11]提出了一种TPLinker 思路,并在英文数据集NYT和WebNLG 上进行实验,通过3 个握手矩阵将实体与关系进行规则抽取,取得了较好结果。陈仁杰等[12]将该两类方法应用在英文数据集NYT和WebNLG上,都取得了很好的结果,但对关系重叠,还在探索和研究之中。陈仁杰等[12]提出了一种融合实体类别信息的实体关系联合抽取方法,该方法在解码阶段融合了头尾实体类别信息的预测,在中文数据集DuIE 上进行试验,但最终实验结果还有一定的提升空间。为了更有效地抽取出文本中的实体与关系,且能较好地解决实体关系重叠问题,本文做了如下工作:1)针对关系重叠问题提出了位置辅助标记方法;2)运用位置辅助标记方法在中文数据集DuIE 上进行对比实验证明了该方法的有效性。
2 基于位置辅助标记的实体关系抽取方法原理
本文提出一种基于位置辅助标记的方法来抽取实体关系三元组,整体模型结构如图2 所示。将实体关系三元组定义为
在整个实体关系的抽取过程中,有可能存在
2.1 BERT 预训练语言模型
BERT(bidirectional encoder representation from transformers),2018 年由Google 首次提出,是一种预训练语言模型。BERT 采用双向Transformer 的Encoder,通过新的遮蔽语言模型(masked language modeling,MLM)来生成深度的双向语言表征,这不同于以往采用单向语言模型或将两个单向语言模型进行浅层拼接,且BERT 在预训练完成之后,只需要一个额外的输出层进行fine-tune,就能在各种下游任务中取得state-of-the-art 的表现。基于此,本文采用BERT来作为embedding层,以较好地获取上下文信息,将BERT 对应输入文本使用词向量的方式进行表示。
式中:S为模型文本;(w1,w2,…,wn)为S的每个字;V为文本S经过BERT 预训练语言模型后的字向量表现形式;(v1,v2,…,vn)为(w1,w2,…,wn)经过BERT预训练语言模型后的每个字对应的字向量表现形式。
2.2 位置辅助标记
通过位置辅助标记矩阵,可以通过索引标记将实体对之间建立关系,如图3 所示。
输入语句S:“在吴京自导自演的电影《战狼2》里,卢靖姗作为女主角在电影中扮演援非医生瑞秋。”在该例句中,以三元组<吴京,导演,战狼2>为例,实体矩阵中,“吴京”实体索引位置为<1,2>,“战狼2”实体索引位置为<11,13>;关系矩阵中分为关系头部矩阵和关系尾部矩阵,关系头部矩阵中,“吴京”实体中的第一个字“吴”与“战狼2”实体中第一个字“战”索引位置为<1,11>,关系尾部矩阵中,“吴京”实体的最后一个字“京”与“战狼2”实体最后一个字“2”索引位置为<2,13>。解码时,实体矩阵中存在索引<1,2>与<11,13>,通过关系矩阵中存在<1,11>与<2,13>可以得到索引<1,2>与<11,13>,故实体“吴京”和“战狼2”存在关系,能够构成三元组<吴京,导演,战狼2>。此外,对于实体矩阵而言,因为实体尾部索引必然大于实体头部索引,矩阵存储的方式采用上三角矩阵的方式进行存储,即对于句子S,设句长为n,则位置辅助矩阵的长度为n(n+1)/2,通过该方式,可以更好地利用空间。该模块的操作流程通过以下公式表示:
式中:Wh为参数矩阵;[hi,hj]为在位置辅助矩阵中的索引位置;bh为可在训练中进行更新的偏差向量。
2.3 实体抽取器
本文针对每一种实体类型设置一个实体抽取器,对于N个预定义的实体类型,共有N个实体抽取器。实体抽取器内使用一个全连接层加softmax 的方式,标签采用1/0 的方式,若在文本中某一位置上被判定为某一类型实体的可能性大于0,那么就将该值标记为1,否则标记为0。得到标记结果的情况下,会根据位置辅助上三角矩阵来获取每个实体抽取器中的所有实体。操作流程如公式(3)(4)所示。
式(3)(4)中:We为参数矩阵;hi,j为位置向量;be为可以在训练中进行更新的偏差向量;P(yi,j=m)为在[i,j]位置链接实体类型为m的概率;Link(wi,wj)为[i,j]位置链接概率最大的实体类型。
2.4 关系抽取器
与实体抽取器相似,根据预定义关系种类设立关系抽取通道,但本文针对每个关系设置4 个关系抽取器。以导演为例,将会设置导演SH2OH(主实体头部与客实体头部),导演ST2OT(主实体尾部与客实体尾部),导演OH2SH(客实体头部与主实体头部),导演OT2ST(客实体尾部与客实体头部),因为在位置辅助标记中,统一采用了上三角矩阵进行存储。这样,对于某些输入语句而言,可能会存在客实体在主实体之前,那么,上三角矩阵就无法标记出所有的实体对,无法确认主实体与客实体,故设置了OH2SH 和OT2ST 通道,将其设置为输出种类,操作流程与实体抽取流程一样。
式(5)(6)中:Wr为参数矩阵;br为训练中进行更新的偏差向量;P(yi,j=n)为在[i,j]位置链接关系n的概率;Link(wi,wj)为[i,j]位置链接概率最大的关系类型。
2.5 损失函数
由于该任务用于多分类任务,所以选择了多分类交叉熵损失函数作为损失函数,公式定义如下:
式中:N为实体类型数加上4 倍的关系类型数;m为实体类型集合;n为关系类型集合。
3 实验结果
3.1 数据集介绍
实验数据集来自百度提供的数据集DuIE[13]。DuIE 是一个大规模的高质量数据集,该数据集采用从粗到精的过程,结合远程监控和众包标注。本文使用的是DuIE 中的训练集和验证集,由于实验设备受限,且所提出模型复杂程度与句长呈指数级关系,故将文本长度大于130 的句子全部舍弃,最终实验所用数据情况如表1 所示。

表1 实验数据集Table 1 Experimental dataset
3.2 评价指标
基于位置辅助标记方法的实体关系抽取模型评价指标通过精准率(P,precision),召回率(R,recall)和F1值来进行衡量,具体计算方式如下:
式(8)(9)中:TP为预测出的三元组与原文本中存在三元组一致的个数;FP为预测出来的三元组与原文本中存在三元组不一致的个数;FN为原文本中存在的三元组但预测结果没有该三元组的个数。
3.3 实验环境
实体关系抽取模型实验环境如表2 所示。

表2 实验环境Table 2 Experimental environment
3.4 实验参数设计
本文进行了一系列实验,各实验参数设置如表3所示。

表3 各模型参数设置Table 3 Parameter settings of each model
3.5 实验结果分析
为了验证本文提出模型的有效性,利用上述模型按照上述参数进行了对比实验,结果如表4 所示。
如表4 所示,本文提出的方法与基于BERT 的模型相比,F1值提高了0.107;与FETI(融合实体类型信息)的实体关系联合抽取方法相比,本文提出的方法F1值提高了约0.079;相较于序列标注的方法,本方法F1值提高了约0.027。采用BERT+sigmoid 先识别实体再关系分类,使用该方式很难获取到实体和关系之间的相互依赖性。相比之下,本文提出的模型,实体和关系共享编码层参数,可以较好地利用实体和关系之间的交互信息。FETI 融合了实体类别信息进行关系抽取,将实体类别信息作为辅助信息做实体关系联合抽取,使用该方式,会给联合抽取任务提供大量的背景知识,同时也会引入更多噪声。本文提出的方法不会引入与抽取出的三元组无关的噪声,可以有效提高抽取的准确率。BERT+CNN+CRF 采用了序列标注的方法进行学习,通过该类方法模型需要额外学习复杂的BIEOS(B-beginner,I-inside,E-end,O-outsde,S-single)对性能有一定影响。而采用多个二分类器的方法进行实体关系联合抽取过程较为简单,在解码阶段引入相应位置辅助信息,而且能解决SEO 和EPO 问题。
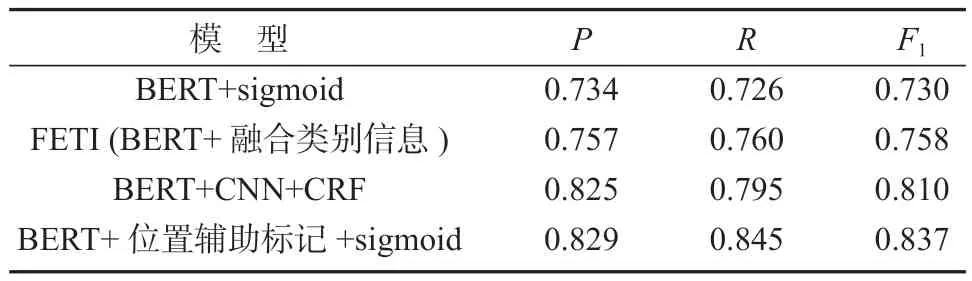
表4 各模型实验结果Table 4 Experimental results of each model
综上所述,本研究提出的BERT 结合位置辅助标记和sigmoid 模型的总体性能最好,优于其他模型。
4 结语
为了解决实体关系抽取任务中的关系重叠问题,本文采用了基于位置辅助标记[14-16]的方法进行实体关系抽取,可以更准确地抽取出实体关系三元组。该方法使用了BERT 来获取文本中的上下文语义,位置辅助信息可以更好地定义规则,为后续学习建立一个更明确的目标,解决了关系重叠问题。经过实验论证,本文在中文数据集DuIE 上表现良好,取得了不错的效果。在后续研究中,由于位置辅助矩阵引入参数过多,模型花费时间会较长,因而将对模型进行改进,以减少参数,提高效率。
