改进多尺度特征融合的工业现场目标检测算法
2022-12-01刘瑞昊于振中
刘瑞昊,于振中,孙 强
(1.江南大学物联网工程学院,江苏 无锡 214122;2.哈工大机器人国际创新研究院人工智能研究所,安徽 合肥 230601)
0 引言
随着深度学习技术推广,目标检测技术在工业现场等场景中应用广泛[1],人员在工地、工厂等复杂的危险区域进行安全生产活动时,安全帽、安全绳等目标的实时检测越发重要[2]。从Alexnet[3]开启了计算机视觉新方向后,不断出现如ResNet[4]、GoogLeNet[5]等网络。在目标检测方面,依次出现了卷积神经网络[6](R-CNN)、空间金字塔池化网络[7]和加速区域卷积神经网络[8]。2015年之后,Faster R-CNN[9]、YOLO 算法[10]崭露头角,随后出现各种改进版本,如SSD[11]、YOLOv2[12]和 YOLOv3[13]。YOLOv3融合了多尺度的特征,在工程应用上更适合用于多种不同目标的同时检测[14-15]。
在安全检测[16]方面,冯国臣等[17]采用机器视觉的方法对安全帽进行检测;刘晓慧等[18]采用先定位人脸,再用支持向量机(SVM)对安全帽进行检测;Sun等[19]提出了一种多特征融合和SVM相结合的头盔检测方法;王雨生等[20]通过肤色特征识别和头部检测,交叉验证是否佩戴安全帽。
本文提出一种改进多尺度特征融合的工业现场目标检测算法,可在工业现场的安全生产检测中发挥重要作用。
1 相关原理
1.1 YOLOv3算法模型
YOLOv3 模型的框架主要由2部分组成,前75层网络使用 Darknet-53 网络作为特征提取层,后面的76~105层网络,利用了特征融合金字塔结构,组成了大、中、小3种不同尺寸的卷积网络的预测层。YOLOv3 也借鉴了残差网络的优秀结构,在某些层之间增加了快捷结构 shortcut。YOLOv3具体结构如图1所示。
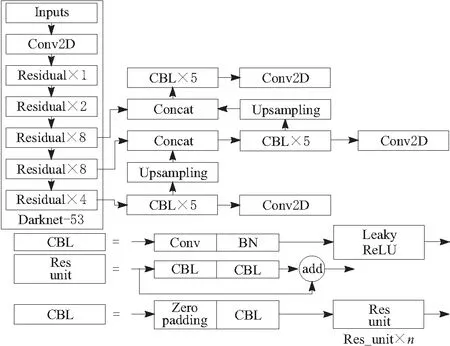
图1 YOLOv3算法结构
1.2 PANet结构
PANet的多尺度特征融合方法,是基于FPN[21]的特征金字塔方法的改进版本。一般的FPN是自上而下、由深至浅,将深层的特征信息向浅传送,对整个特征信息传播的网络进一步强化,虽然目标的类别特征得到加强,但是位置的特征信息却没有得到传送,如图2a所示。PANet在自上而下,由深至浅的特征金字塔基础上,又增加一个特征信息方向为自下而上、由浅至深的特征金字塔,在增强多尺度目标特征多样性的同时,也传送了目标特征图的位置信息,如图2b所示。PANet的特征融合方式,增加了特征图多样性,也实现了多尺度检测,提高了模型检测识别精度,这对YOLOv3 结构改进有很好的启发。

图2 PANet 特征融合
2 实验方法
2.1 k-means聚类
本文以工业现场监控视频的数据为基础,制作成工业现场安全生产的数据集FHPD(factory helmet and person detection)和FSRPD(factory safety rope and person detection)。原始YOLOv3确定的9组先验框维度分别是(373,326)、(156,198)、(116,90)、(59,119)、(62,45)、(30,61)、(33,23)、(16,30)和(10,13),但是原始的框并不适合实际采集的安全生产的数据集这一研究对象。工业现场安全生产数据集的目标框尺寸分布如图3和图4所示。由于采集的图片尺寸和检测目标的大小不同,因此需要利用k-means算法对数据重新进行聚类分析。

图3 FHPD数据集中目标框尺寸

图4 FSRPD数据集中目标框尺寸
在实际工业现场安全生产的场景下,使用k-means 算法对安全帽佩戴、安全绳等数据集进行聚类分析,将图片缩放到416×416后,聚类得到9组新的anchor box,具体数值如表1所示。
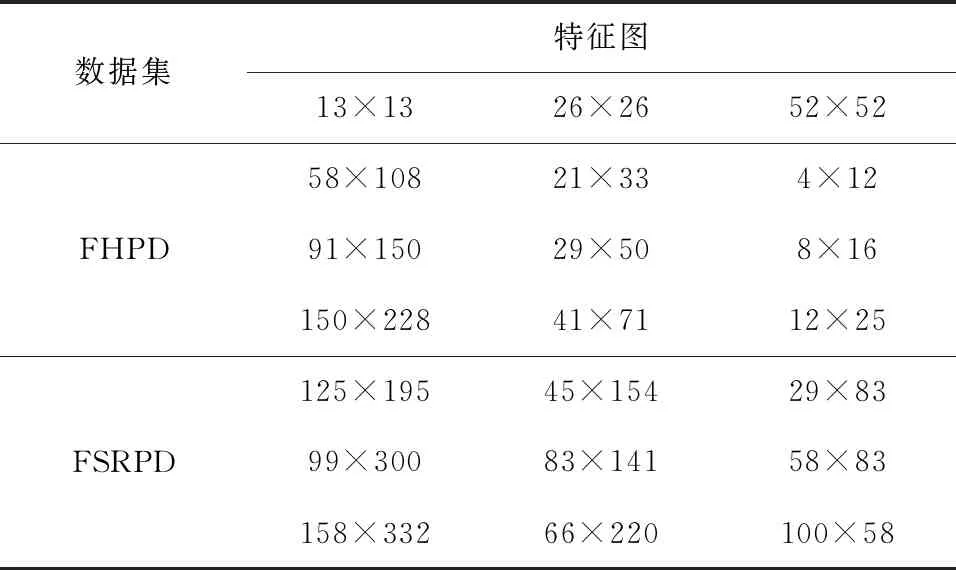
表1 安全生产数据集的anchor box分配
2.2 基于YOLOv3的特征融合改进
2.2.1 增加Inception_shortcut结构
为了增强网络的特征提取能力,特别是浅层特征,受空间金字塔SPP(spatial pyramid pooling)和GoogLeNet的启发,创建了Inception_shortcut模块,在增加少量参数的基础上,对主干网络特征输出的浅层信息进行网络宽度的扩大,将浅层不同尺度的特征图进行融合,提高浅层小目标信息的感受野,获取更加丰富的细节特征信息,加强对安全帽等小目标的检测能力。使用的Inception_shortcut模块如图5所示。

图5 Inception_shortcut模块
2.2.2 改进YOLOv3的整体结构
原始的YOLOv3网络使用8倍下采样输出的特征图对小目标进行检测,当目标太小时,网络对小目标的预测就会出现困难。工业现场使用的监控摄像头,其拍摄图片中安全帽等目标相对较小,会造成检测精度较低。引入Inception_shortcut模块后,浅层融合输出多尺度的特征图,使模型能够检测到更多的目标信息;此外通过PANet相似的结构改进YOLOv3的特征金字塔,加深了网络的深度;同时为避免梯度消失,特征检测层适当减少层数,最后建立新的特征融合目标检测层,能对多尺度目标进行检测,可以提高对安全帽、安全绳等目标的检测率。改进的YOLOv3详细的整体模型如图6所示。
通过这件事,我对她的印象好多了,且不管她说话算不算数,学习总是应该的。从那以后,我们都不再荒废时间了。我虽不相信她能真来,但倘若将来见面了,总不能让她看低了。

图6 改进的YOLOv3模型
2.3 评估标准
目标检测的效果由预测框的定位精度和分类精度共同决定,目标检测算法的综合评价指标通常是平均精确率。平均精确度A被定义为准确率(P)-召回率(R)曲线下的面积,用来衡量数据集中一类的平均分类精确率,计算式为
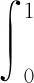
(1)
但是对于多分类问题,需要对N个类别的精确度求均值,即平均精确度均值J,用来衡量分类器对所有类别的分类精度,也是目标检测算法最重要的指标,计算式为
(2)
M为N个类别的精确度A的累加值。
运行速度的评价指标采用的是每秒检测图片的帧数,即帧/s。
3 对比实验
3.1 实验环境
使用的计算机为Windows10,64位操作系统,处理器为Inter Core i7-7700 CPU @3.60 GHz,16 GB RAM。
后续的深度学习算法的改进与运行主要是在服务器上进行,本文实验在 Ubuntu18.04 操作系统下进行,模型搭建采用PyTorch 深度学习框架,服务器使用的是Intel Xeon E5-2680 v3,CPU运行内存64 GB,GPU(RTX2080Ti)显存11 GB。在模型训练中 batch size 设置为8,优化器选择SGD(stochastic gradient descent),动量参数 momentum设置为0.9,迭代次数设置为5 000,初始学习率设置为0.000 1。NMS设置为0.5,权重衰减0.000 5。
3.2 实验1
以实际工业现场为实验场景,使用安全帽数据集FHPD数据19 148张图片进行网络训练和验证。如图7所示,在训练过程中,改进版本的训练损失数值迅速下降,且最后稳定在较小的数值,说明改进的网络收敛性较好。

图7 改进YOLOv3的训练损失

图8 优化前后安全帽检测对比
通过表2具体数据也可以看出,改进后的网络在复杂工业环境下的安全帽检测精确率得到了提高。

表2 YOLOv3和改进方法对比结果
3.3 实验2
在实际工业现场获取监控图片,制作成安全绳数据集FSRPD数据,对3 532张图片进行网络训练和验证。2种模型检测结果的对比如图9所示,左列是原始YOLOv3模型预测结果,右列是改进的YOLOv3预测结果。根据左右两侧预测框的数量和预测精确度的数值,可见改进后的目标检测精确率得到了提高。

图9 优化前后人员和安全绳检测对比
由于人员及安全绳的监控摄像头拍摄图片较大,目标尺寸也较大,可以进一步验证提出的算法在多尺度目标情况下也能取得很好的效果。实际安全绳的检测环境比较困难,人员身体及环境遮挡较多,在实际工程应用时,可以用多角度的相机或者在每段时间内进行人员安全绳检测,只要1个相机拍摄到或者在这段时间内检测到悬挂安全绳即可认为佩戴了安全绳。
详细的数据对比如表3所示,改进的网络在416×416上mAP是82.72%。比原始的YOLOv3的mAP提高了2.07个百分点。由于相机拍摄的未佩戴安全绳数也较少,数据分布不均,以及工业现场环境恶劣,未系安全绳检测的精确率并不高,但相对于原始模型仍有较大的提升。
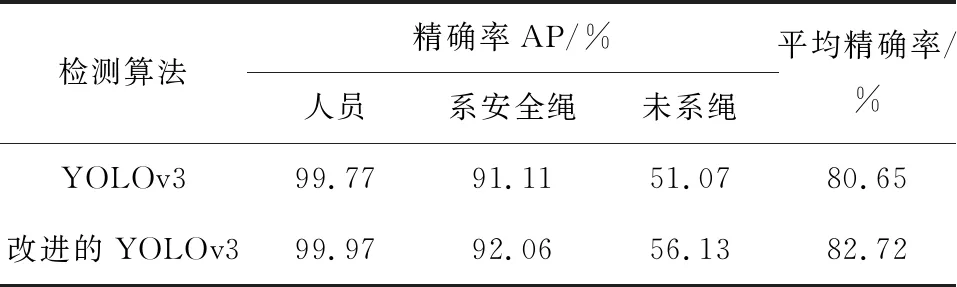
表3 YOLOv3和改进方法对比结果
3.4 实验3
为了进一步验证所设计模型的鲁棒性,在公开的数据集PASCAL VOC2007和PACSCAL VOC2012上进行了类似的对比实验验证。不同目标检测算法的测试结果如表4所示。在训练阶段,将网络模型的图像输入尺寸设置为416×416 后,不再对图像尺寸进行缩放和填充。本文提出的网络在416×416上mAP是80.9%。与其他目标检测算法相比,改进后的网络使mAP得到了明显的增强。

表4 不同目标检测算法在PASCAL VOC上结果
4 结果分析
从工业现场数据集FHPD、FSRPD以及公开数据集PASCAL VOC的实验结果和详细数据可以看出,YOLOv3有许多的目标漏检和误检,特别是复杂工业场景下的小目标检测,改进后的网络可以避免这些问题。如图8的右列图所示,改进后的网络表现更好,更加适用于工业现场的安全生产检测。因为所设计网络采用多尺度融合来检测目标,增加了主干网络的输出的网络宽度,并提高了网络对多尺度目标检测的鲁棒性,这样的特征融合目标检测层有助于检测小目标,引入了PANet类似的金字塔结构,在加深网络的同时也获取更丰富的多层次信息,同时为了消除网络过深造成梯度消失,简化了检测网络的输出结构。
同时,对提出算法的计算复杂度和运行的速度进行了统计,为使数据更有说服力,在公开数据集PASCAL VOC上进行对比,详细结果如表5所示。

表5 不同算法在PASCAL VOC上性能对比
改进后的模型由于添加了PANet结构以及增加了Inception_shortcut结构,模型增大是必然的,但是改进后的模型FPS和原始的相差不多,且改进后的模型目标检测精确率得到很大的提高,说明改进算法对工业现场的目标检测是适用的,可以进一步提高和推广。
综合实验可得,对于工业现场复杂的情况,如安全帽、安全绳和人员检测,本文算法更加适合此类多尺度目标的检测。此外,使用k-means算法对目标数据集框的重新计算,能够使检测的精确度得到了提高。
5 结束语
本文提出了一种改进的YOLOv3工业现场中安全生产检测的算法,主要应用于工业现场安全帽、安全绳及人员等多尺度目标的检测。通过对工业现场的监控视频进行处理,整合数据集对安全帽、安全绳的检测进行实验,将主干网络的输出网络宽度变宽,同时引入PANet多尺度特征增强结构方法优化YOLOv3,也降低了网络的梯度消失的风险,简化了检测的结构。改进YOLOv3在工业现场安全帽检测的mAP达到91.54%,比原始YOLOv3的平均精确率提高了2.69个百分点;在工业现场安全绳检测中mAP达到82.72%,比原始YOLOv3的平均精确率提高了2.07个百分点。此外,为进一步验证提出模型的鲁棒性,在公开数据集PASCAL 2007和PASCAL 2012上,改进YOLOv3的mAP为80.9%,比原始的算法的平均精确率提高了2.2个百分点。由于算法的网络层增加,改进的检测速度为33帧/s,和原始的算法速度相差不多,也满足实时性要求。下一步将在完善所做工作的基础上,进一步降低模型的复杂度,加快网络的检测速度,达到工业安全生产监控视频中的多种安全目标的检测要求。
