基于PPO的移动平台自主导航
2022-11-30徐国艳熊绎维周彬陈冠宏
徐国艳,熊绎维,周彬,陈冠宏
(北京航空航天大学 交通科学与工程学院 特种车辆无人运输技术工业和信息化部重点实验室,北京 100191)
自主导航作为无人驾驶技术中的关键,可通过结合感知、决策和控制等功能[1],来解决“我在哪”“要去哪”及“怎么去”等主要问题[2]。预期实现的功能为:用户指定目的地后,智能体可在非碰撞条件下自行去往目的地。
传统实现自主导航功能的算法多为基于搜索的路径规划算法,如A*[3]、D*[4-5]、快速扩展随机树(rapidly exploring random tree,RRT)[6]等。此类算法的基本思想是:通过定位自身位置,根据目的点位置和障碍物位置,搜索出一条最优路径。此类算法的稳定性高,应用于实际场景时可以得到很好的效果,但存在无法进行自我学习、在复杂环境下适用性较低等问题。
强化学习的使用可以有效解决上述问题。强化学习的基本思想是:通过与环境交互得到奖励反馈,根据反馈自行更新模型参数。由于其独特的学习机制,模型可以在训练完成后迁移至无先验知识的场景中使用,且学习的场景越多,模型表现越好。
因此,近年来国内外众多专家学者开展了基于强化学习的自主导航研究。2017年,付雪建[7]以超声波和视觉作为环境感知器,构造了基于Q-learning的强化学习模型,将其应用在自主导航场景中,提高了移动机器人对未知环境的适应性。2019年,为了解决强化学习的输入维度灾难问题,杨宁博[8]使用即时定位与地图构建(simultaneous localization and mapping,SLAM)完成了室内自身定位,并使用基于深度Q学习网络(deep Q network,DQN)的强化学习算法,在无先验地图的情况下实现自主导航移动机器人。2020年,陶睿[9]研究了基于DQN及其改进Double DQN、Dueling DQN的强化学习算法,并分析和总结了强化学习算法在自主导航实际应用中各参数的选择方法。2021年,何聪[10]针对无地图环境下的导航任务,提出了基于智能体自我定位和深度预测辅助任务的深度强化学习模型,实现了无地图环境下的自主导航。
以上研究虽然都实现了强化学习算法在自主导航中的应用,但依然存在着一个主要问题,即模型的输出动作离散问题,这将导致底盘的运动不流畅,使得部件损坏加速。为了解决上述问题,Tai等[11]将改进型的深度确定性策略梯度算法(deep deterministic policy gradient,DDPG)应用于自主导航场景中,该方法使用激光雷达作为传感器,完成了端到端的强化学习模型训练,并实现了机器人的连续性控制。但输出动作连续性的解决将引发动作采样空间增大的问题,这意味着模型与环境交互的可能性增多,进而导致模型训练次数增加,收敛困难。
基于以上研究背景,本文提出了一种基于近似策略优化(proximal policy optimization,PPO)算法的移动平台自主导航方法,可有效解决强化学习算法的输出动作连续性问题及模型收敛困难问题。首先,利用全球导航卫星系统(global navigation satellite system,GNSS)和激光雷达传感器获取环境信息,并根据环境数据设计了一种基于改进人工势场算法的自身位置评价方法,作为状态输入。其次,在PPO算法的基础上,设计了基于正态分布的动作策略函数,移动平台的整车线速度和横摆角速度在正态分布中采样,通过该方法解决了强化学习模型输出动作连续性的问题;并根据导航场景特点,设计了强化学习模型的网络框架和奖励函数。然后,搭建了基于Gazebo模拟器的仿真环境对模型进行训练,结果表明,在经过自主学习后模型可有效收敛,且引入自身位置评价后的模型收敛速度明显增快。最后,将该模型移植入真实环境中进行实车实验,实验结果说明,移动平台在真实环境中可有效完成自主导航任务,验证了本文方法的有效性。
1 PPO算法
1.1 强化学习算法
随着人工智能的兴起,强化学习算法也越来越多的应用在无人驾驶领域,其基本思想是:通过与环境交互来获取奖励,并以此进行自我学习。
强化学习算法包含5个主要部分:智能体、环境、状态、动作及奖励。智能体若在t时刻处于状态St,可根据当前的策略函数π选择动作At,该动作会影响环境,并在下一时刻返回奖励Rt+1,与环境交互的轨迹序列可表示为:{S0,A0,R1,S1,A1,R2,…,St,At,Rt+1}。其中,智能体训练的目的是最大化获取的回合奖励,即期望回报Gt。回报表示回合结束后的累计奖励加权值。Gt的定义如下:

式中:γ为值小于1的折扣因子。
为了评价某一个状态或者动作的好坏,引入状态价值函数Vπ(s)和动作价值函数Qπ(s,a),方程分别如下:
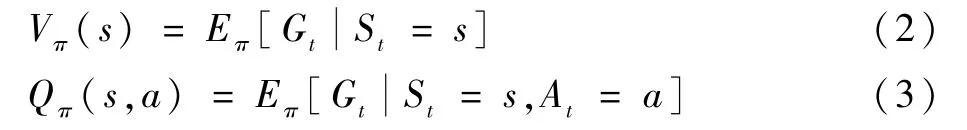
状态价值函数和动作价值函数反映了当前状态或动作可获取的回合平均期望回报值,因此可作为强化学习的决策指标。
1.2 基于策略的算法
现有许多强化学习算法都基于Q值,模型参数用于更新动作价值函数Qπ(s,a),策略即选择最大的Qπ(s,a)。

通过更新参数向量θt,可得到更优的策略函数。参数向量更新方程如下:
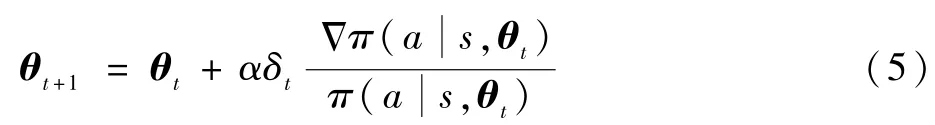
式中:α为学习率;δt为根据训练过程中求解出来的基准值。
参数向量更新的目的是使回报函数最大,回报函数定义如下:
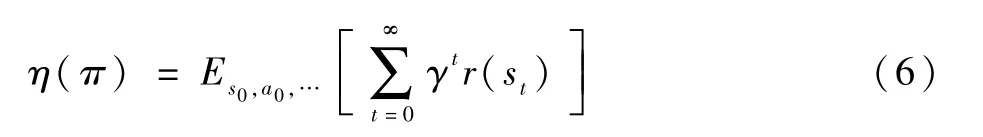
式中:r(st)表示在st状态下的奖励值。
但在实际训练过程中,可能会由于学习率α设置的不合适导致策略模型表现越来越差。为解决此问题,PPO算法定义了优势函数Aπ(st,at)[12]:
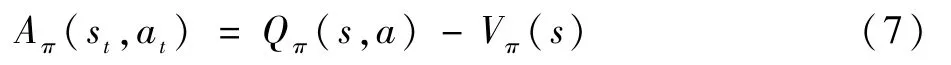
函数(7)表示动作a所获得的回合奖励与动作平均可获得的回合奖励差值。若Aπ(s,a)>0,则说明动作a优于平均表现。
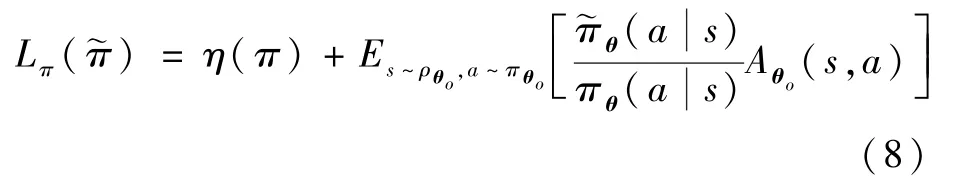
根据优势函数,构建了近似回报函数Lπ(~π):式中:Lπ(~π)表示更新后的策略~π所对应的近似回报函数;η(π)表示更新前策略π对应的回报函数;ρθo表示更新前策略参数为θo所对应的状态分布。
若式(8)中的优势函数项Aθo(s,a)≥0,则策略更新后的回报函数单调不减,即模型策略更优或不变,通过该方法可提高训练效率。
2 导航状态定义
在自主导航场景中,为定义强化学习算法中的状态St,需要获取自身位姿、速度和障碍物等多个数据。本文预设的场景为室外非结构化道路,因此,使用GNSS和激光雷达多传感器来获取环境信息。
2.1 环境感知方法
2.1.1 自身位置和速度信息感知
考虑到普通工业化的GNSS精度仅能达到米级别,无法满足小范围内的自主导航要求,因此,使用RTK技术对GNSS定位精度进行了提升,并将坐标从大地坐标系转换为站心坐标系[13-14],可获取坐标值(N,E,U),表示相对于站心点的东向、北向、天向距离。同时,通过在移动平台车头和车尾搭载2个GNSS天线,可根据其接收信号计算出移动平台底盘的航向角φ。
除此之外,还可根据底盘控制器域网(controller area network,CAN)返回的消息得到移动平台的整车线速度v及整车横摆角速度ω。
2.1.2 障碍物信息感知
在障碍物感知中,选用VLP-16线激光雷达作为障碍物感知传感器,但该激光雷达扫描出的点云数据量太大,无法直接输入给决策模块进行处理。因此,需要对激光雷达点云进行聚类分析。本文使用基于K-D树的欧氏距离聚类方法,通过对激光雷达点云进行聚类处理后即可得到障碍物相对自身的坐标信息(Xi,Yi,Zi)和长宽高信息(Li,Wi,Hi)。
2.2 状态空间定义
强化学习是根据某一时刻状态St进行动作选择的,在本文的自主导航场景中,状态St的定义如图1所示。
由图1可知,状态St中包含自身位姿信息(N,E,U)、航向角φ、底盘速度信息(v,ω)及障碍物信息(Xi,Yi,Zi,Li,Wi,Hi)。
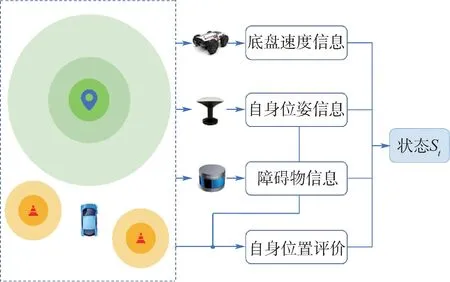
图1 状态空间构造示意图Fig.1 Schematic diagram of state space construction
除此之外,本文还设计了一种改进的人工势场算法,来评价自身完成任务的情况,并将其作为状态值。
2.2.1 人工势场算法
人工势场[15]作为移动平台的导航算法之一,其基本思想是:障碍物对自身产生排斥力,目的地对自身产生吸引力,势能为引力斥力之和,通过该方法在环境中构建人工势场。传统的引力势能和斥力势能如下:
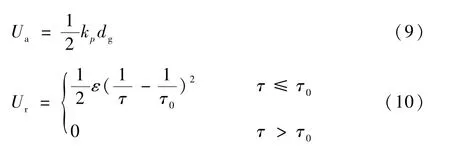
式中:Ua为引力势能;kp为引力因子;dg为自身与目的地的距离;Ur为斥力势能;ε为斥力因子;τ为自身与最近障碍物间的距离;τ0为自身与障碍物间的距离阈值。
2.2.2 自身位置评价
本文设计了一种改进的人工势场算法作为移动平台自身位置评价,可有效评估移动平台完成任务的情况。
传统人工势场的斥力势能取最近障碍物与自身的距离τ,但很多时候距离远的障碍物可能因为其体积大更有碰撞风险。因此,本文设计了一种危险因子用于判断障碍物的危险程度,危险因子定义如下:

式中:do为自身与障碍物的距离;L和W分别为障碍物的长度和宽度。
计算各障碍物的危险因子并取其最小值t*,将斥力势能替换如下:
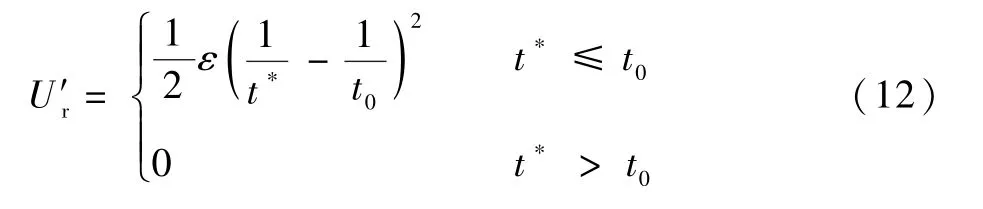
式中:t0为危险阈值。
除此之外,由于本文中的目的地并非某个点,而是一块区域,为更准确定义目的地区域的势能,将引力势能定义如下:
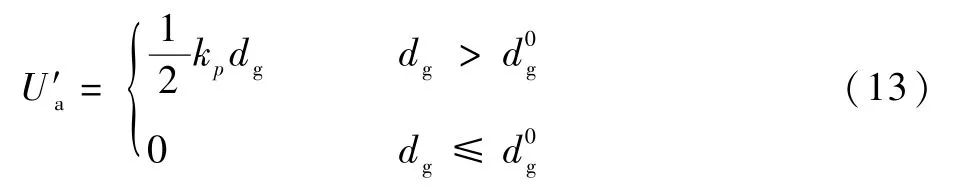
最终,取引力和斥力的势能和作为移动平台的自身位置评价指标:

U值越大,说明完成任务情况越差,U值越小,说明任务完成情况越好。
3 决策模型设计
3.1 动作策略函数
为解决在导航过程中移动平台输出动作的连续性问题,本文在PPO算法的基础上,根据式(4)的PPO动作策略函数,利用正态分布函数将策略函数重新定义如下:
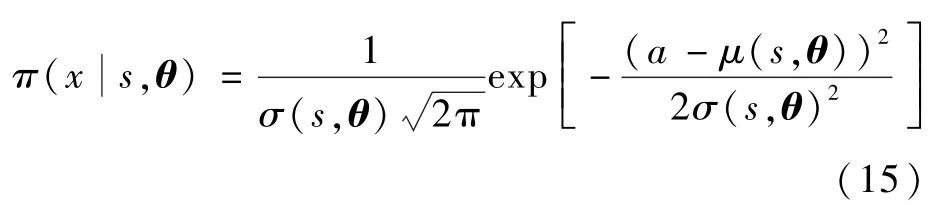
式中:σ(s,θ)和μ(s,θ)分布表示带有参数向量θ的策略分布方差和期望。
基于以上动作策略函数定义,整车线速度v和横摆角速度ω将从正态分布中进行采样。相比于离散性采样,在正态分布中进行采样可以使输出动作数值连续,由此可解决输出动作连续性问题,且通过式(5)更新参数θ,可改变正态分布的期望和方差,从而改变动作的采样概率,使好的动作采样概率更高,坏的动作采样概率更低,进而得到更优的决策模型。
但考虑到移动平台的整车线速度和横摆角速度有上限值,若不对正态分布期望进行限制,大多采样动作会超出其上限值,这意味着许多采样动作将对模型的更新起不到作用,进而导致模型收敛速度慢。因此,使用tanh激活函数对正态分布期望进行限制。由于tanh激活函数方程取值为(-1,1),将其乘以期望因子δμ可限制策略分布的期望,策略分布期望定义如下:

本文中的期望因子δμ取值为移动平台整车的线速度和横摆角速度上限值。
3.2 网络框架
根据上述策略定义,本文设计了决策模型的网络框架,如图2所示,包括1个输入层、演员网络和评论家网络。
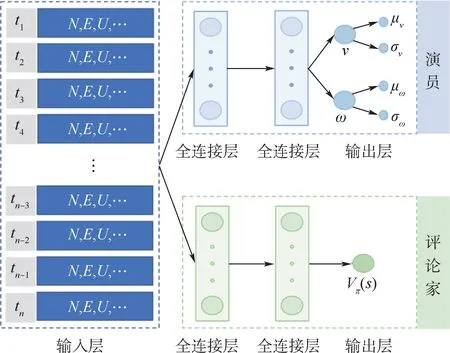
图2 模型网络框架示意图Fig.2 Schematic diagram of model network framework
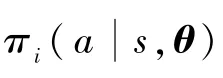
3.3 奖励函数
3.3.1 离散奖励
在本文的自主导航场景中,设置离散奖励如下:碰撞障碍物会得到负奖励,到达目的地会得到正奖励。除此之外,还定义了可行驶区域,超出该区域也会得到负奖励。具体的离散奖励值re设置如下:
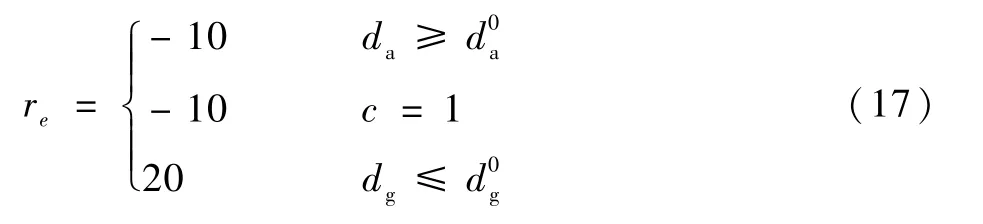
式中:da为移动平台中心到目的地中心的距离;为可行驶区域阈值;c为碰撞检测因子,若发生碰撞则为1,不发生碰撞为0。
3.3.2 基于自身位置评价的过程奖励
自主导航场景可采样的行为序列过多,可产生到达目的地的回合次数很少,因此只采用离散奖励训练效率较低。为提高模型收敛速度,本文使用自身位置评价作为过程奖励对该模型进行引导。
引导方法为:在每一步计算自身位置评价奖励,而非仅在回合结束时计算离散奖励。根据改进的人工势场(式(14)),计算出当前时刻的人工势能,并取前后2步的人工势能差值ΔUt作为奖励值,如下:

式中:Ut-1和Ut分别为上一时刻和这一时刻移动平台的人工势能值。
考虑到移动平台有可能为赚取更多离散奖励值而不结束回合,因此,为了突出结果对移动平台的指导性,将过程奖励的值设置为比离散奖励小一个量级。上文中已对离散奖励设值,取值分别为-10和20,因此将过程奖励归一化至(-1,1)之间。过程奖励具体的计算步骤如下:
步骤1初始化列表lU=[0,1],计算在初始位置时移动平台的人工势能U0。
步骤2回合未结束时做如下循环:
步骤2.1移动平台采取动作At,计算移动平台人工势能值Ut。
步骤2.2计算移动平台前后2步的人工势能差值:ΔUt=Ut-1-Ut。
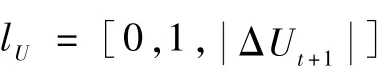
步骤2.4计算过程奖励值:ru=(ΔUt+1-min(list))/(max(list)-min(list))。
某个时刻的单步整体奖励值r为

4 仿真环境实验和实车实验
4.1 仿真环境实验
考虑到直接在真实环境中训练模型的成本太高,因此,搭建仿真环境对模型进行训练。本文的仿真环境基于Gazebo模拟器,并在该环境中搭建了移动平台物理模型和激光雷达传感器模型。模型搭建完毕后,将点云聚类算法应用在仿真环境中可得障碍物感知效果如图3所示。
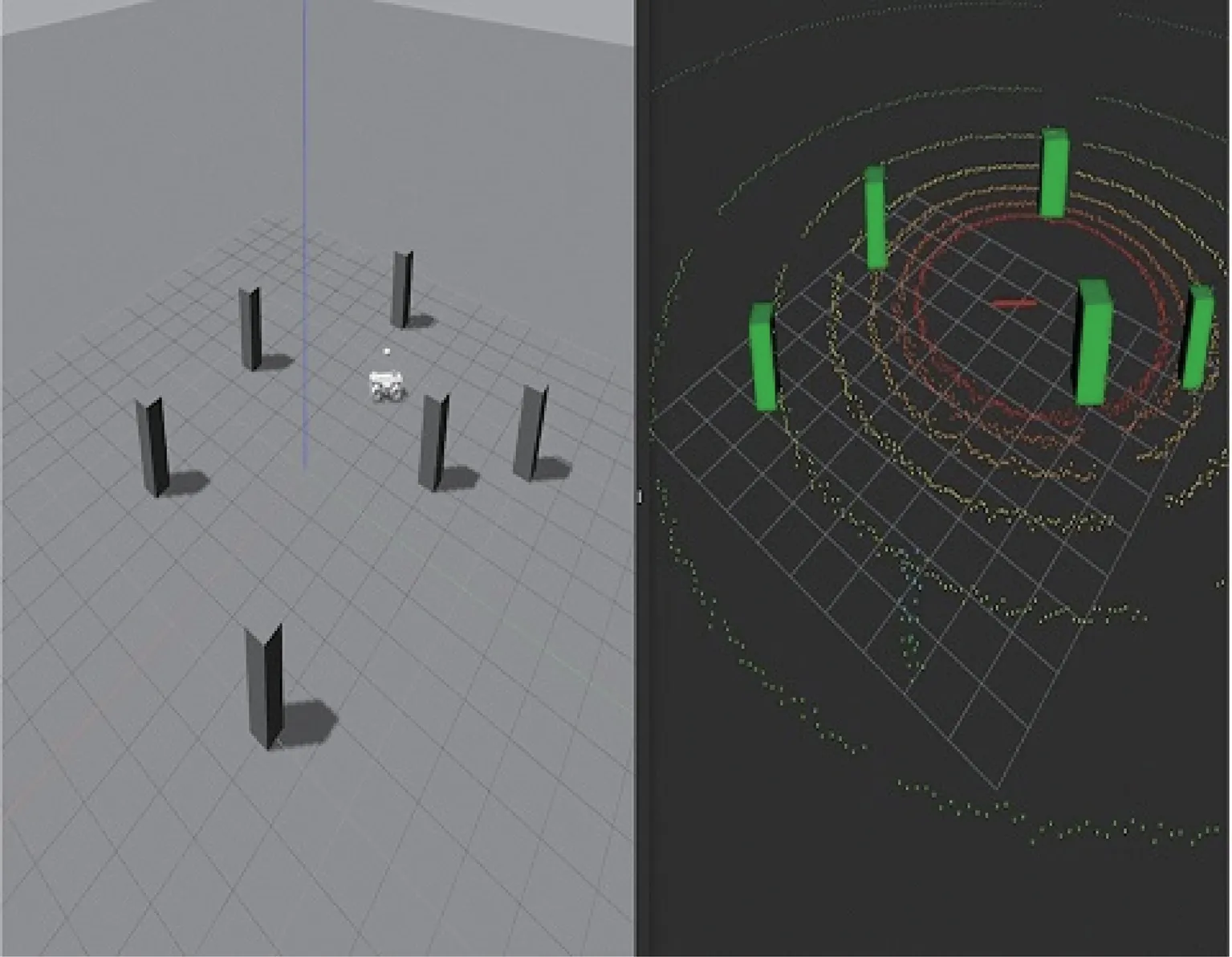
图3 Gazebo环境中的障碍物感知效果Fig.3 Obstacle detection in Gazebo environment
在上述仿真环境的基础上,本文设定了2类训练场景,包含不同的障碍物分布和目的地区域,如图4所示。图中:红色物体表示障碍物,绿色区域表示目的地区域,紫色区域表示可行驶区域。
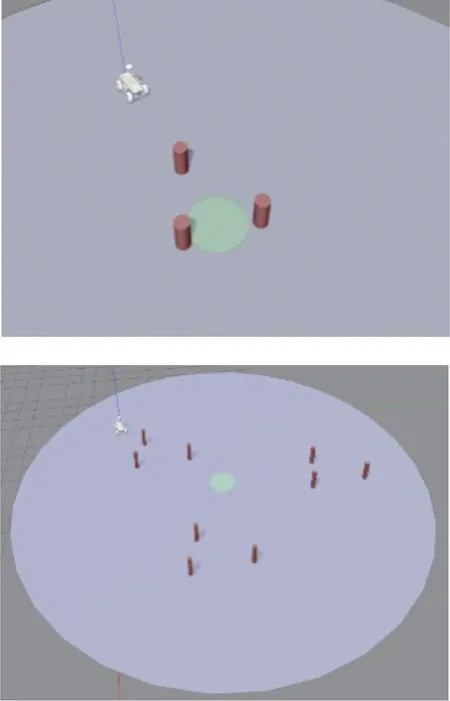
图4 仿真环境训练场景Fig.4 Training scenario in simulation environment
根据上述训练场景,设定以下训练策略:①训练回合步长设定为160步,每32步进行模型参数更新,若回合结束,则更新模型并初始环境,开始下一回合训练;②若移动平台发生碰撞、超出行驶范围及到达目的地,则返回奖励,更新模型参数并初始环境,开始下一回合训练。
为对比自身位置评价对导航模型的影响,本文分别对引入自身位置评价的模型和未引入自身位置评价的模型进行训练。其中,未引入自身位置评价的模型奖励值仅为离散奖励,训练结果如图5所示。
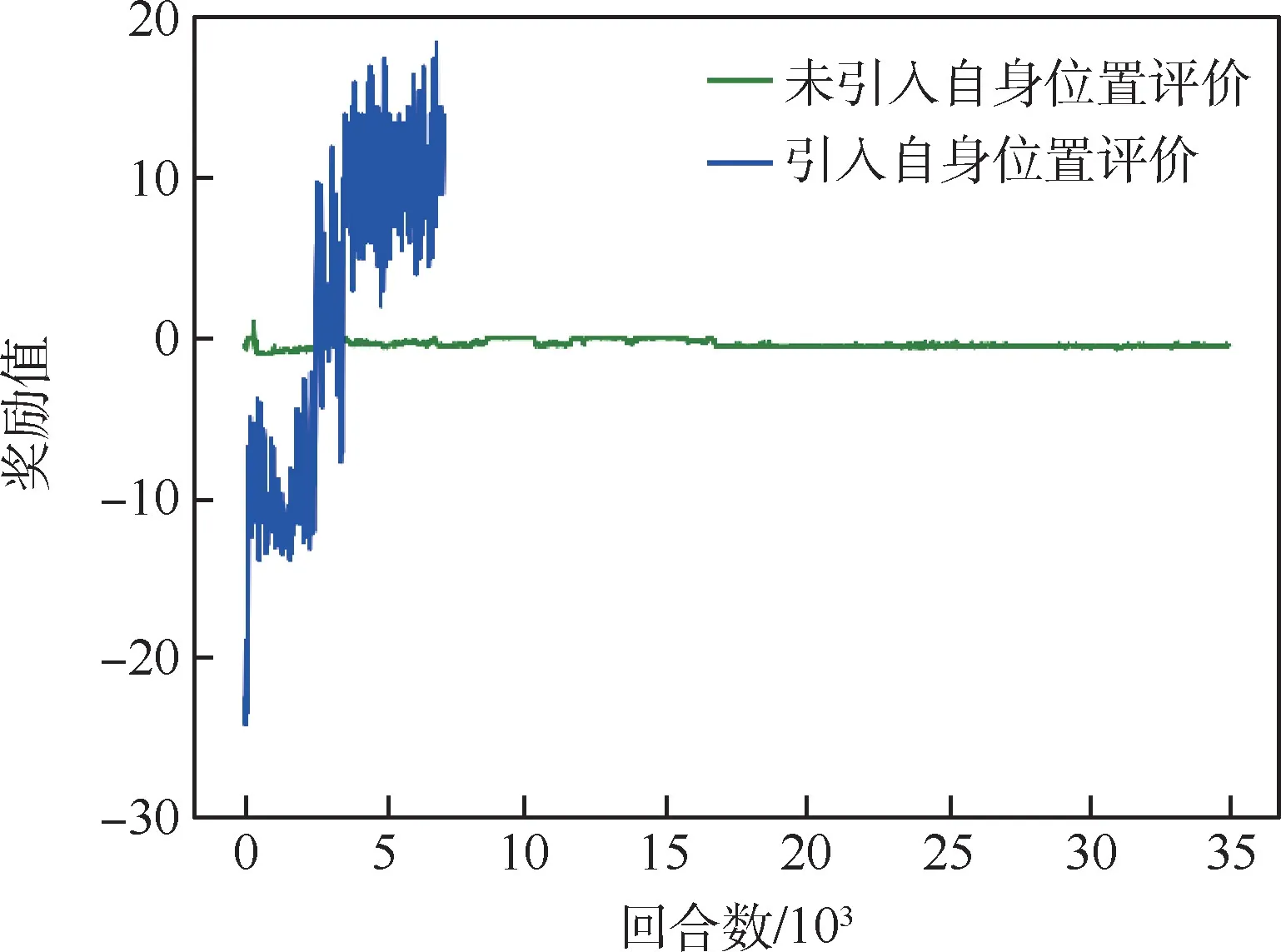
图5 导航模型训练结果Fig.5 Training results of navigation model
由图5可以看出,未引入自身位置评价的模型训练35000个回合依然无法收敛,而引入自身位置评价的模型在训练近5000个回合时就可以达到收敛。训练结果表明,引入自身位置评价后模型收敛速度明显提高。
需要说明的是,由于引入自身位置评价,奖励会根据步数产生累计,在模型收敛后奖励依然波动较大,但整体不影响其完成到达目的地的任务。
模型经过自主学习后,可搜索到去往目的地的有效路径,并完成导航任务。其中,模型在训练场景中所习得路径如图6所示。
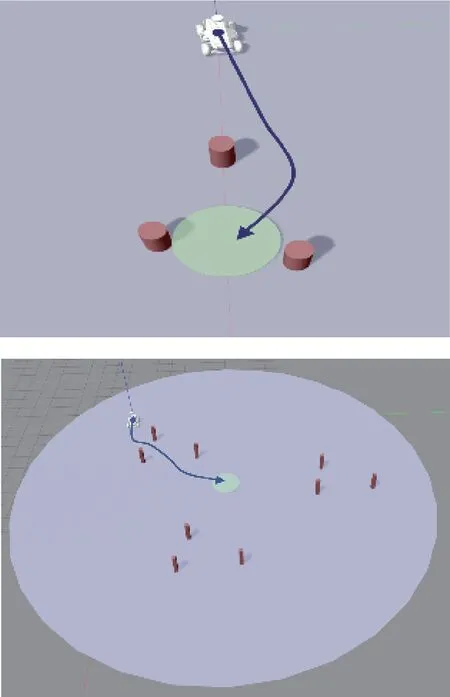
图6 仿真环境中导航模型所习得路径Fig.6 Learned path of navigation model in simulation environment
4.2 实车实验
为验证所提出的自主导航模型在真实环境中是否有效,本文搭建了一套移动平台硬件如图7所示。基于以上硬件设施,完成了真实环境中的感知、决策和驱动3个功能的测试。

图7 真实环境下搭建的移动平台Fig.7 Mobile platform built in real environment
在自身位姿感知测试中,在室外环境下使用RTK技术获取移动平台的经纬高度。随后,将其转换至站心坐标系下获得移动平台的自身位姿状态。
在障碍物感知测试中,使用VLP-16线激光雷达获取环境点云,并对其进行去除噪点处理和感知区域设置,最终使用聚类算法对点云数据进行聚类,获取障碍物的位置和大小数据。聚类效果以包围框方式显示,如图8所示。

图8 真实环境下激光雷达点云聚类效果Fig.8 Clustering of LIDAR point cloud in real environment
将仿真环境中训练好的强化学习模型移植入真实平台中进行测试。测试环境中使用3个圆锥桶作为障碍物,并设定指定目的地进行移动平台自主导航的真实环境测试,测试场景布置如图9所示。

图9 真实环境下自主导航场景Fig.9 Autonomous navigation scene in real environment
测试过程中,以工控机为计算硬件平台的条件下,从感知到驱动平均花费时长为0.025s,即平均每秒可以进行40次决策。
在测试场景中,本文提出的导航模型根据感知输入的障碍物信息、自身位置信息及人为指定的目的地信息,生成了如图10所示的导航轨迹曲线,证明了该模型可自主绕过障碍物并完成导航任务,验证了其有效性。
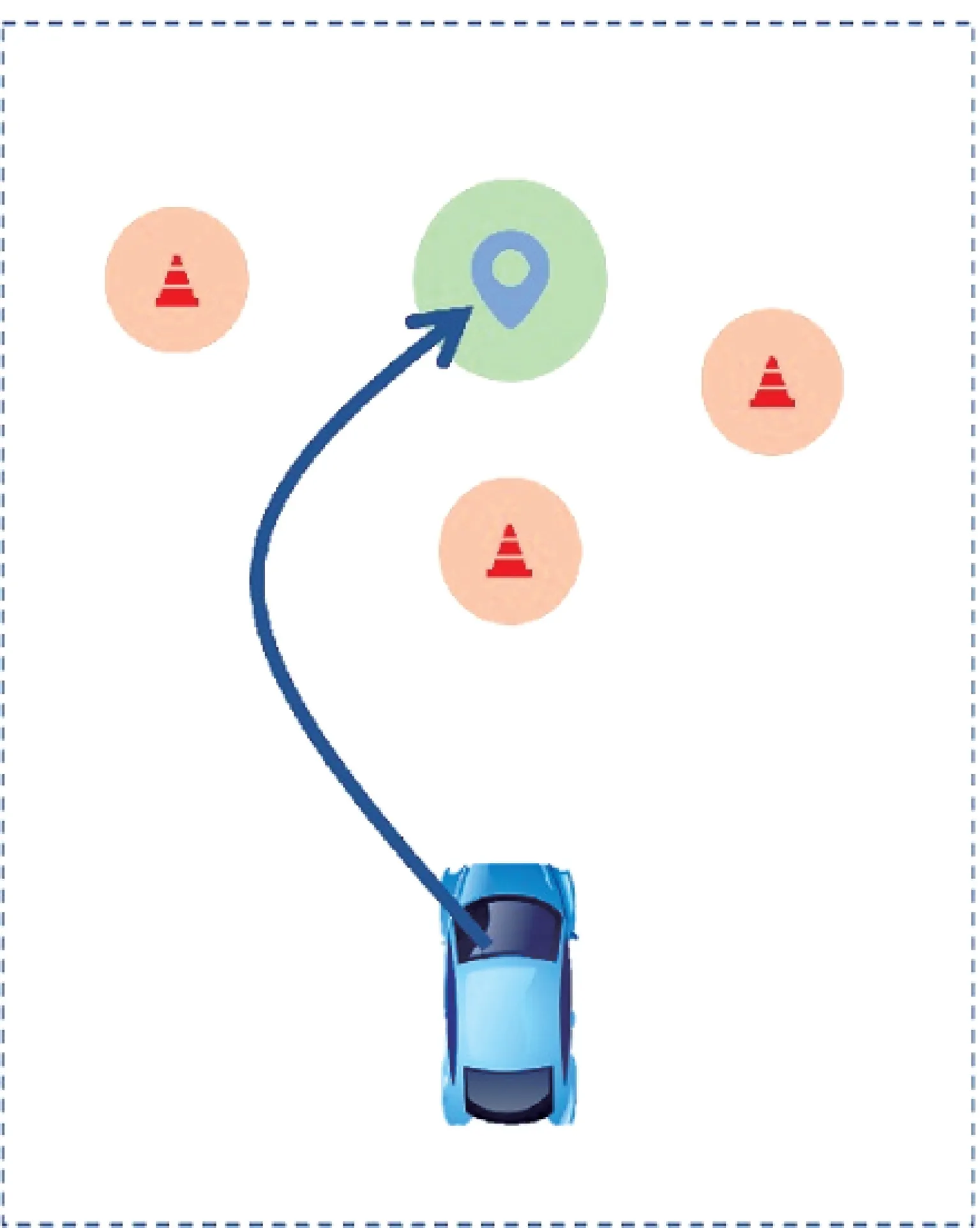
图10 真实环境下生成的导航轨迹曲线Fig.10 Navigation trajectory curve in real environment
5 结 论
针对移动平台的自主导航场景,本文提出了一种基于PPO算法的导航模型,并完成了模型训练和实景测试,主要结论如下:
1)在PPO算法的基础上,设计了基于正态分布的动作策略函数,移动平台整车线速度和横摆角速度在策略函数中采样,该方法可解决强化学习模型输出动作连续性问题。
2)设计了基于改进人工势场的自身位置评价方法,并将其作为过程奖励函数加入模型训练,该方法可大幅度加快导航模型的训练速度。训练结果表明,引入自身位置评价指标的模型训练5000次即可收敛,未引入自身位置评价指标的模型训练35000次以上还未完成收敛。
3)在仿真环境和真实环境中均完成了模型测试,测试结果说明,该模型可有效绕过障碍物并到达目的地,验证了其有效性。
