基于群体意志统一的无人机协同围捕策略
2022-11-30刘峰魏瑞轩周凯丁超
刘峰,魏瑞轩,*,周凯,2,丁超
(1.空军工程大学 航空工程学院,西安 710051; 2.空军航空大学,长春 130000)
多无人机协同围捕是研究如何指导一群具有自主决策能力的无人机通过相互合作对单一个体或群体实现围捕。由于这类问题有着重要的理论价值和广泛的应用前景,如应用于军事领域,可大幅度提高军队无人机的自动化程度,降低军事任务成本,提高战斗效率等,因此受到很多学者的关注[1-6]。
就协同围捕策略设计而言,蔡云飞等[7]设计出Cross-EKF定位算法,通过交叉计算目标位置的后验估计协方差,将对动态围捕点的收敛扩展到对动态围捕面的收敛,提高了协同围捕的收敛速度及稳定性。黄天云等[8]通过对围捕行为的分解,设计了每个个体自组织运动控制器,提出了基于松散偏好规则(loose-preference rule,LPRule)的自组织协作围捕策略,并从理论上分析了其稳定性。李瑞珍等[9]为使机器人有效地快速围捕移动目标,提出一种基于动态围捕点的多机器人协同围捕策略,采用协商法为围捕机器人分配最佳围捕点,建立目标函数并优化,实现了围捕机器人在线路径规划。裴惠琴等[10]主要针对围捕环境受限及双方的速度比率受限问题,设计基于动态虚拟势点的“切换式”围捕策略,在提高围捕效率的同时解决了由“夹角最小”原则带来的围捕者“死锁”问题。
以上对于协同围捕策略的研究仍是建立在获取目标位置后,预先依据围捕成功的条件进行任务分配与协同环节的基础上,并基于特定控制模式完成围捕。同时,需要指出的是,围捕策略对于环境的自适应性、策略体现出的智能性有待提高。
近年来,也有部分学者通过观察总结和强化学习来探索集群协同问题[11-12]。Muro等[11]通过观察、计算模拟北灰狼群围捕猎物行为的规则和主要特征,从狼群和猎物的4种简单行为中提出一个计算多智能体模型,总结出狼群的围捕策略。Lowe等[12]从多智能体深度强化学习的角度,构建智能体合作与竞争的场景,提出多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,MADDPG)算法,采用集中训练和分散执行的框架,实现了群体之间的协同策略,其鲁棒性远优于传统的强化学习算法,但是,随着智能体数量的增加,系统的稳定性降低,收敛速度变慢。
基于以上研究的不足,本文探索出一种智能化的多无人机协同围捕策略。在该策略中,借助图卷积网络模型对围捕无人机进行信息融合认知设计,实现参数共享,减少模型复杂度,有效减轻计算负载;更具魅力之处在于借鉴人类在协作任务中达成认知统一的规律[13],设计群体意志趋同学习的生成式模型使围捕无人机通过学习更倾向于产生协作策略,使无人机集群涌现出更加智能化的围捕行为。仿真结果验证了基于群体意志统一的围捕策略能够有效完成多无人机协同围捕任务。
1 问题描述
假设在一个无限大且无障碍的二维空间中,有N(N≥3)个围捕无人机对一个目标无人机进行围捕,如图1所示。
图1 N个无人机围捕单个目标Fig.1 N drones rounded up a single target
其中,U={U1,U2,…,UN}为N架围捕无人机的集合,VU={VU1,VU2,…,VUN}为N架围捕无人机速度的集合。T为单架目标无人机,VT为目标无人机的速度。为更好的体现所设计围捕策略的智能性,∀VUi∈VU,满足VUi<VT,其中,i=1,2,…,N。所有无人机均视为质点,且不具备攻击能力,围捕无人机仅通过协作形成封闭包围圈完成围捕。
围捕开始后,围捕无人机通过协作对目标无人机实施围捕,目标无人机则按照一定的逃逸策略进行逃离。当围捕无人机在目标无人机周围形成封闭的Apollonius圆域时,视为围捕成功。考虑到围捕无人机固定物理防守半径RUi,当目标无人机T与任意一架围捕无人机Ui距离小于相应的RUi时,也视为围捕成功。
2 模型构建
2.1 无人机运动模型
假设无人机当前时刻位置向量为[x,y]T,将无人机的运动模型表述如下:

式中:θ为航向角;v为速度;̇x为v的水平分量;̇y为v的竖直分量。
可以看出,忽略姿态变化后,无人机的横向、纵向速度都可以通过v和θ进行相应配置。为拓展无人机机动能力,航向角θ可变,但存在角速度上限,变化示意图如图2所示。
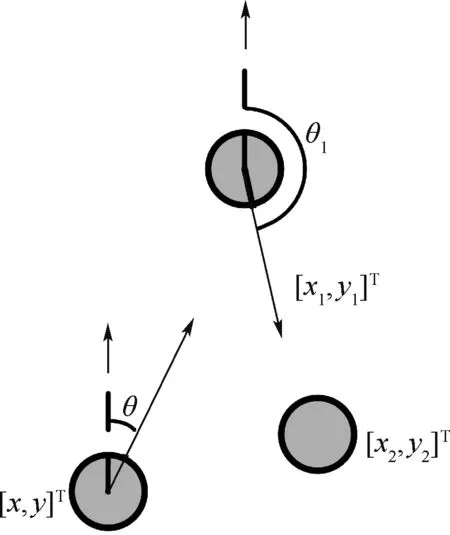
图2 无人机航向变化示意图Fig.2 Diagram of course change of UAV
2.2 基于Apollonius圆的围捕模型
Apollonius圆的定义为平面内到2个定点的距离之比为常数k(k≠1)的点的集合。针对围捕无人机与目标无人机而言,若二者速度之比为k,则双方同时到达Apollonius圆上,从而实现单一方向上的拦截。
围捕无人机借助与目标无人机到达Apollonius圆[14]上点的时间相等这一特点进行决策,其决策原则如图3所示。
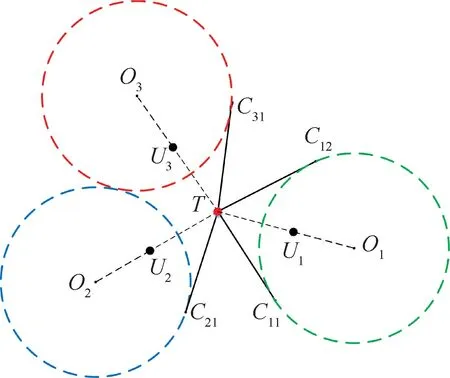
图3 围捕无人机决策静态示意图Fig.3 Static schematic of a roundup UAV decision making
图中绿色、蓝色、红色虚线圆分别为围捕无人机U1、U2、U3与目标无人机T之间构建的Apollonius圆,点O1、O2、O3分别为3个圆的圆心,点C11、C12、C21、C31分别为围捕无人机当前 位置与3个圆的切点。由于围捕无人机速度小于目标无人机速度,故目标无人机未被围捕前,可利用速度优势从C11以 左、C21以 右 或C12以 上、C31以 下 区域,进行逃离。若形成封闭Apollonius圆域,则围捕成功。
3 基于群体意志统一的协同围捕策略
3.1 双回路认知模型
当人类参与协作任务时,个体除获取自身信息外,通过观察、交流获得环境及其他个体信息,基于融合后的信息,一方面进行自我认知,形成指导自身的策略;另一方面能够进行协作认知,形成对于群体目标的认知,且群体目标会反过来影响个体的自我认知过程。本文将围捕无人机根据其获得信息形成关于协作任务的认知定义为群体意志。对于每个个体而言,群体意志是个体根据自身能获得的所有信息形成的对协作任务的认识。根据这种现象,构建了人类在协作任务中的双回路认知模型如图4所示。
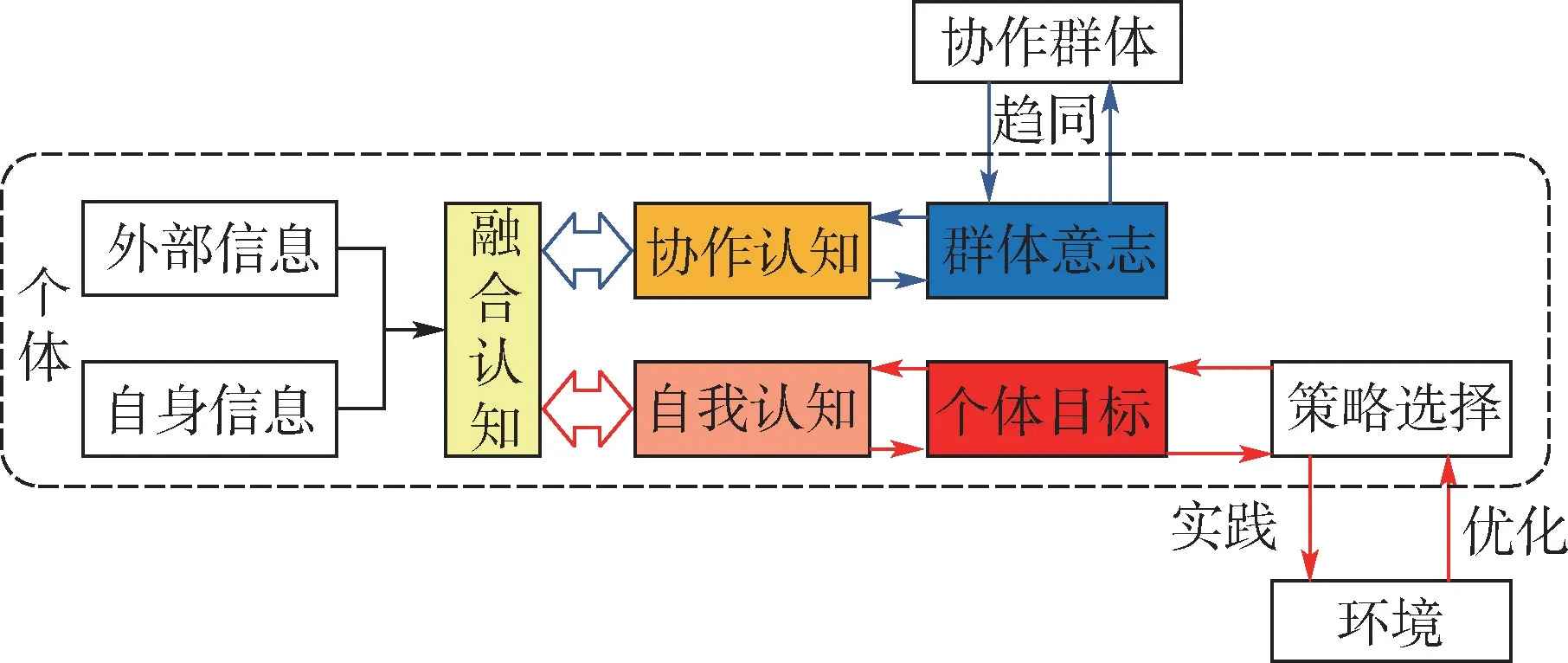
图4 双回路认知模型示意图Fig.4 Schematic diagram of double-loop cognitive model
在协作任务中,人类的认知活动分为两部分。其中,第1部分如图4红色箭头表示的实践学习认知回路,个体根据自我认知形成决策,并通过观察环境反馈的信息不断学习优化,以保证个体策略的最优性;第2部分如图4蓝色箭头表示的回路,个体将自身得到的群体意志与群体中其他个体获得的群体意志进行对比,存在差异时,试图与其他个体实现统一,此过程反过来会改变信息融合时的侧重点和对信息的认知理解,从而改变自身对能够获得的信息的融合过程,将这一过程称为群体意志趋同认知回路。
3.2 无人机融合认知方法设计
在协同围捕过程中,围捕无人机之间存在不完全联系,为有效形成个体对于整体的认识,需要构造一个能够实现信息交联,并进行融合认知的模型。
3.2.1 基于图论的信息交联关系
采用图G=(V,E,H)描述N架围捕无人机的信息交联关系,其中,V={1,2,…,N}为各围捕无人机节点集合,E为边集。当围捕无人机j能获得围捕无人机i的信息,则有(i,j)∈E,且将围捕无人机i称为围捕无人机j的邻居(Neighbor)。H为N×N的邻接矩阵,建立式(2)模型描述围捕无人机之间的连通性。


3.2.2 基于图卷积网络的融合认知模型
借助空间域和谱域融合的图卷积网络[15](graph convolutional network,GCN)在拓扑结构数据上强大的特征提取能力和分类能力,设计了基于GCN的融合认知模型,如图5所示。以围捕无人机i为例,将状态信息si=[xi,yi]T和动作信息ai=θi,记为xi={si,ai},利用一个隐藏层为2层,每层64个节点,激活函数为tanh函数的多层感知器(multi-layer perceptron,MLP)对xi进行池归一化[16]等预处理,记处理后的信息为x′i={s′i,a′i}。将x′i输入图卷积网络,利用GCN的特征提取能力获得融合信息。融合认知过程中信息的传递过程可以表示为

图5 融合认知模型结构示意图Fig.5 Schematic diagram of fusion cognitive model

相较于已有结果,融合认知模型的优势在于:①鲁棒性强。由于将各围捕无人机之间存在差异的连接关系作为GCN网络的输入,因此,不需要针对每架围捕无人机设计特定的信息提取模型。②模型复杂度低。使用单层卷积即能够实现所有相邻围捕无人机信息的融合,若增加一层则可实现与当前围捕无人机有二跳连接关系的围捕无人机信息融合。
同时,图卷积网络的层数也不宜过多,连接关系较远的围捕无人机对当前个体认知的影响较小,层数增加会出现过度平滑的问题[17],失去了利用局部信息实现群体意志统一的意义。
3.3 群体意志的趋同学习原理
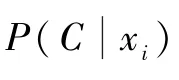
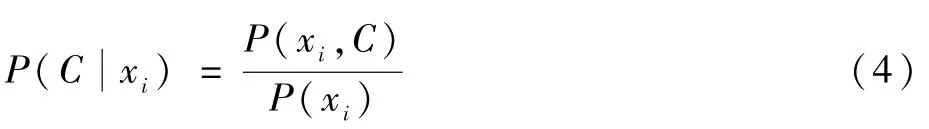
式中:P(xi,C)为xi与C的联合分布;P(xi)为无人机i获得的信息的分布。对于围捕无人机协作问题而言,式(4)很难执行,因为围捕无人机获得的信息相对复杂,联合分布P(xi,C)难以获得,并且,达成统一后的群体意志C的分布P(C)也是后续求解得到的。

式中:DKL(·)为2个分布之间的KL散度(也称为交叉熵或相对熵),表示2个分布之间的距离。根据变分推断理论[18],式(5)等价于
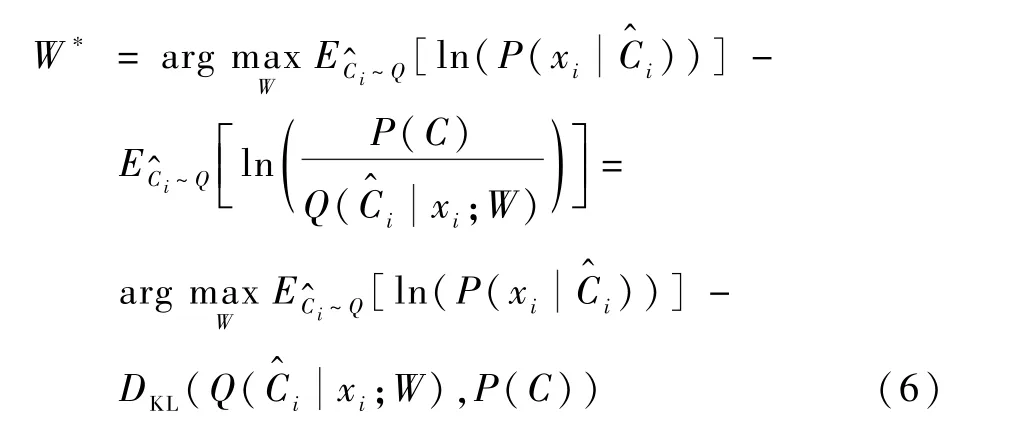
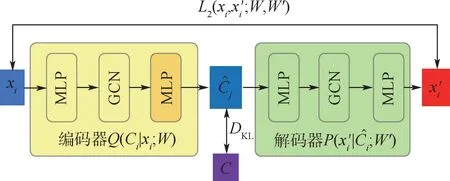
图7 用于群体意志趋同学习的生成式自动编码器结构Fig.7 Generative autoencoder for group will convergence learning
图7中,黄色部分为编码器,根据信息xi构造群体意志,即图6中的群体意志构造模块。绿色部分为解码器,根据编码器生成的试图恢复信息xi,其输出为xi的近似值将其写成条件概率分布形式即为,其中W′表示解码器部分神经网络的参数。图中与C之间的KL散度对应式(6)中的第2项,P(C)),能够使围捕无人机学习到的群体意志分布尽可能接近统一的群体意志的先验分布P(C)。L2(xi,;W,W′)为原始信息xi与重构信息之间的重构误差,是式(6)中第1项的最小二乘距离表达形式。通过两方面的误差传播,上述生成式自动编码器能够不断优化神经网络参数,从而实现群体意志的趋同逼近。需要指出的是,,P(C))计算的是2个分布之间的距离,生成式自动编码器不像传统的自动编码器那样输出实数向量,而是输出一个分布模型。
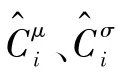
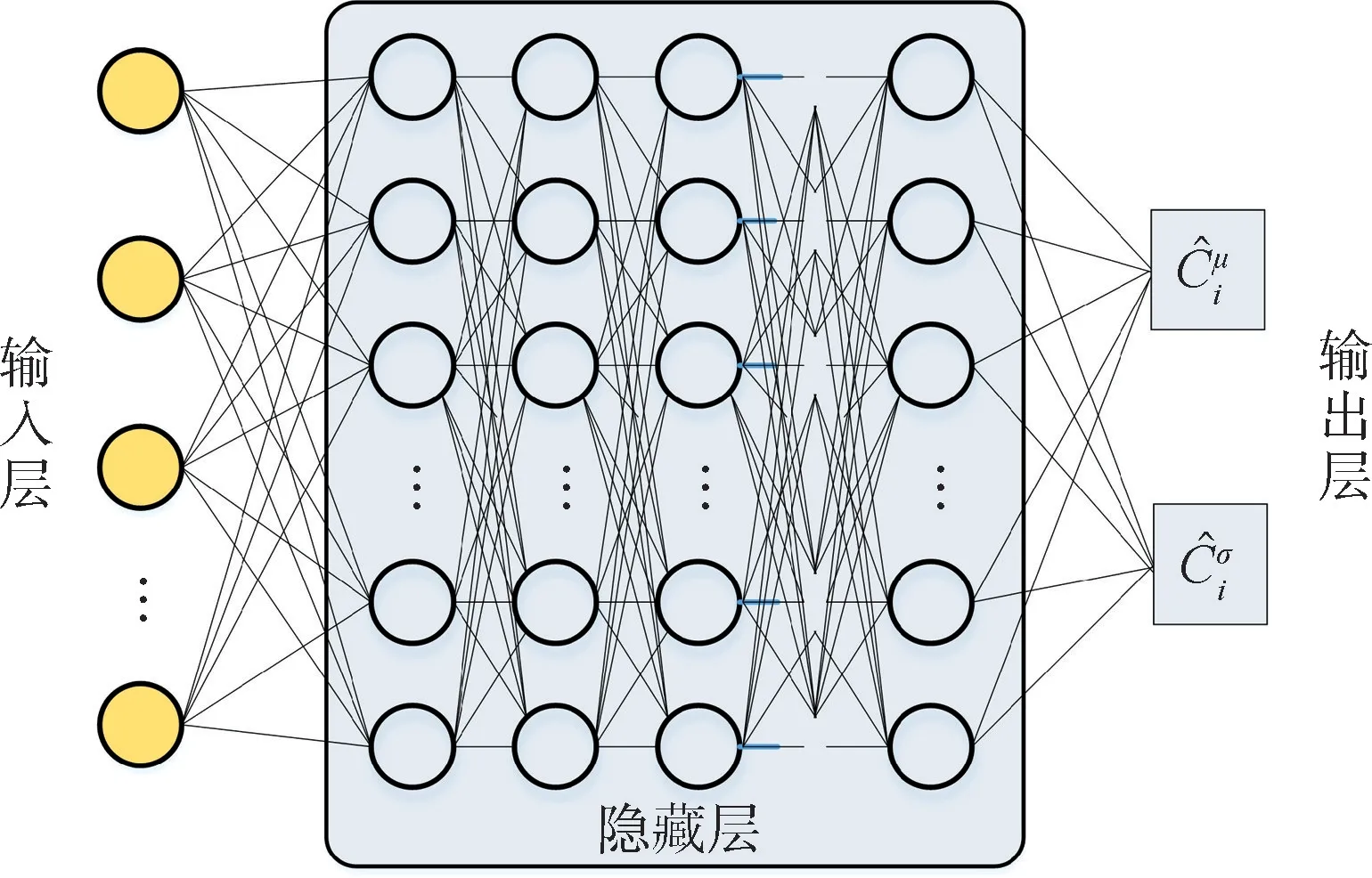
图8 协作认知模块的神经网络结构Fig.8 Neural network structure of cooperative cognition module
综上,群体意志趋同学习的训练过程表示为

4 仿真及分析
4.1 训练集参数设定
为验证所设计策略的有效性,取围捕无人机数目N=4进行仿真实验,初始位置随机生成,大致散布在目标无人机周围,最远不超过150km,具体参数如表1所示。
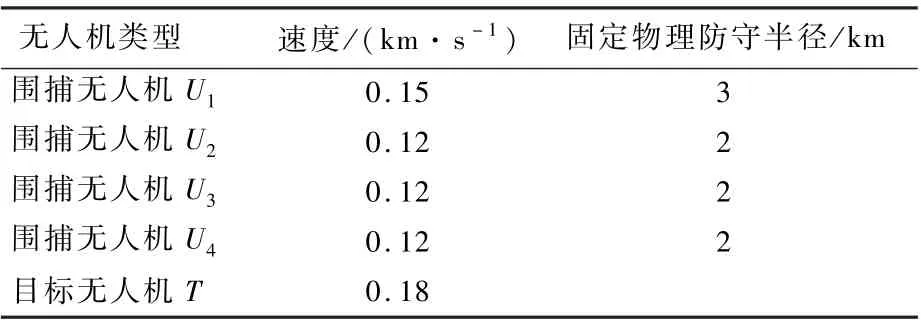
表1 无人机参数设定Table1 UAV parameter setting
设定t时刻奖励函数如下:

式中:DIDi(t)表示t时刻第i个围捕无人机与目标无人机的距离,为便于处理数据及突出奖励,对距离和乘以10。训练开始时,记初始时刻奖励r0=0。flag定义为
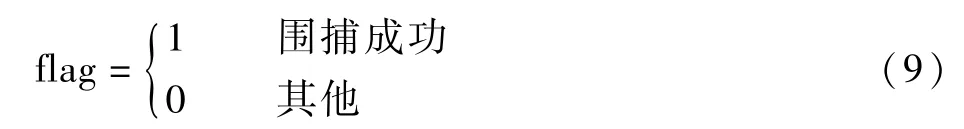
式(8)第①部分促使围捕无人机接近目标无人机进行围捕,第②部分为围捕成功后反馈奖励值10。当∀i∈{1,2,…,N},D(t-1)-D(t)<0成立时,判定围捕任务失败。
仿真流程如图9所示。其中,M为所设置的训练片段数量上限,t为常数。

图9 仿真流程Fig.9 Simulation flow chart
4.2 仿真结果
通过对比实验分析群体意志统一对无人机协作围捕学习的影响,实验组采用基于群体意志统一的策略训练围捕无人机,对照组采用与实验组相同的网络结构,但采用传统的分布式优化策略,只进行基于实践的学习,而不进行趋同学习。
记录下实验后期某片段围捕无人机获得的实时奖励,如图10所示。
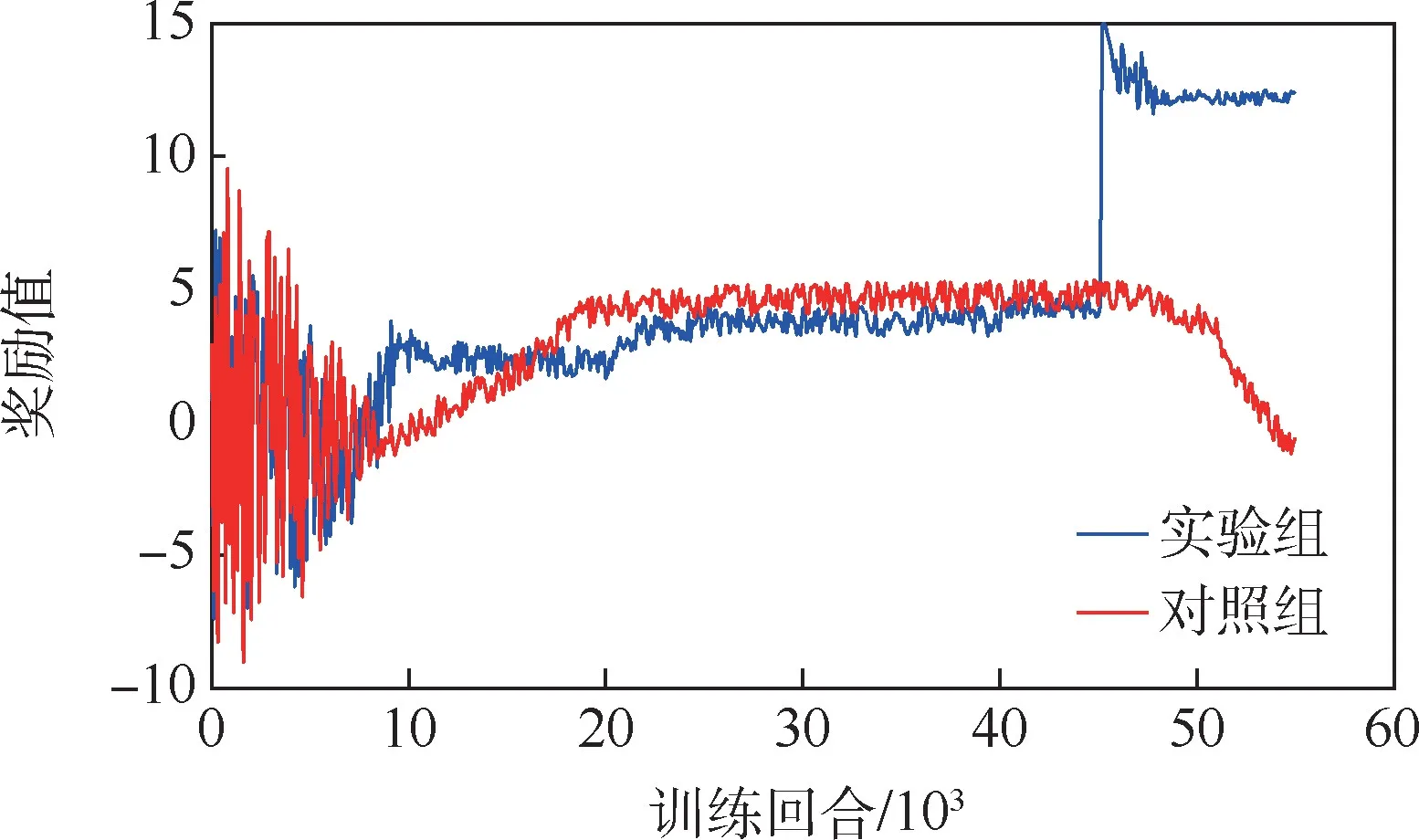
图10 训练实时奖励Fig.10 Training real-time rewards
从图10中可以看出,实验组与对照组的学习效果大约在第6500回合出现差别。进行趋同学习的实验组获得的初始奖励较低,但围捕无人机系统经过基于群体意志统一的学习,能够在较短回合内提升奖励值,并经过大约45000回合的训练后,通过协作实现了对目标无人机的围捕。而采用传统的分布式优化策略,只进行实践学习的对照组能够更快的获得较高的初始奖励,随后奖励值的增长速度较慢,远小于实验组。同时,由于对照组个体更倾向于接近目标无人机,扩大自身收益,在局部回合较实验组能够获得更高的实时奖励,但从任务整体的收益来看,最终并未完成围捕任务。
为了更直观地说明问题,将训练48000回合的围捕无人机系统接入训练环境,获取实验组和对照组的拦截过程截图。
如图11和图12所示,红色实心点为目标无人机的当前位置,红、绿、蓝、黑4条虚线弧分别为围捕无人机U1、U2、U3、U4与目标无人机形成的Apollonius圆弧。从实验组和对照组围捕过程中可以看出,采用基于统一群体意志的协作围捕策略,围捕无人机更倾向于互相配合,尽快形成封闭Apollonius圆域完成围捕,实验组相比于对照组而言,尽管获得的奖励函数式(8)第①部分值较低,但是获得奖励函数整体值较高。对照组中围捕无人机更倾向于扩大自身收益,利用其他个体的Apollonius圆,尽快接近目标无人机,以固定物理防守半径完成围捕,却被目标无人机利用速度优势获得更好的局部态势。正如图11和图12所示,对照组与实验组拥有相同的初始条件,如图12(a)和图11(a)所示;在2组相应的围捕策略指导下,经过一段时间的运动后,对照组较实验组有更好的围捕态势,如图12(b)所示;在目标无人机向下运动压缩围捕无人机U3的Apollonius圆时,对照组围捕无人机U1和U4并没有像实验组及时保护U3的弱侧,却径直接近目标无人机,反被目标无人机利用速度冲击U1和U3空档,没有及时完成合围,如图12(c)和图12(d)所示。

图11 实验组围捕过程Fig.11 Experimental group round up process
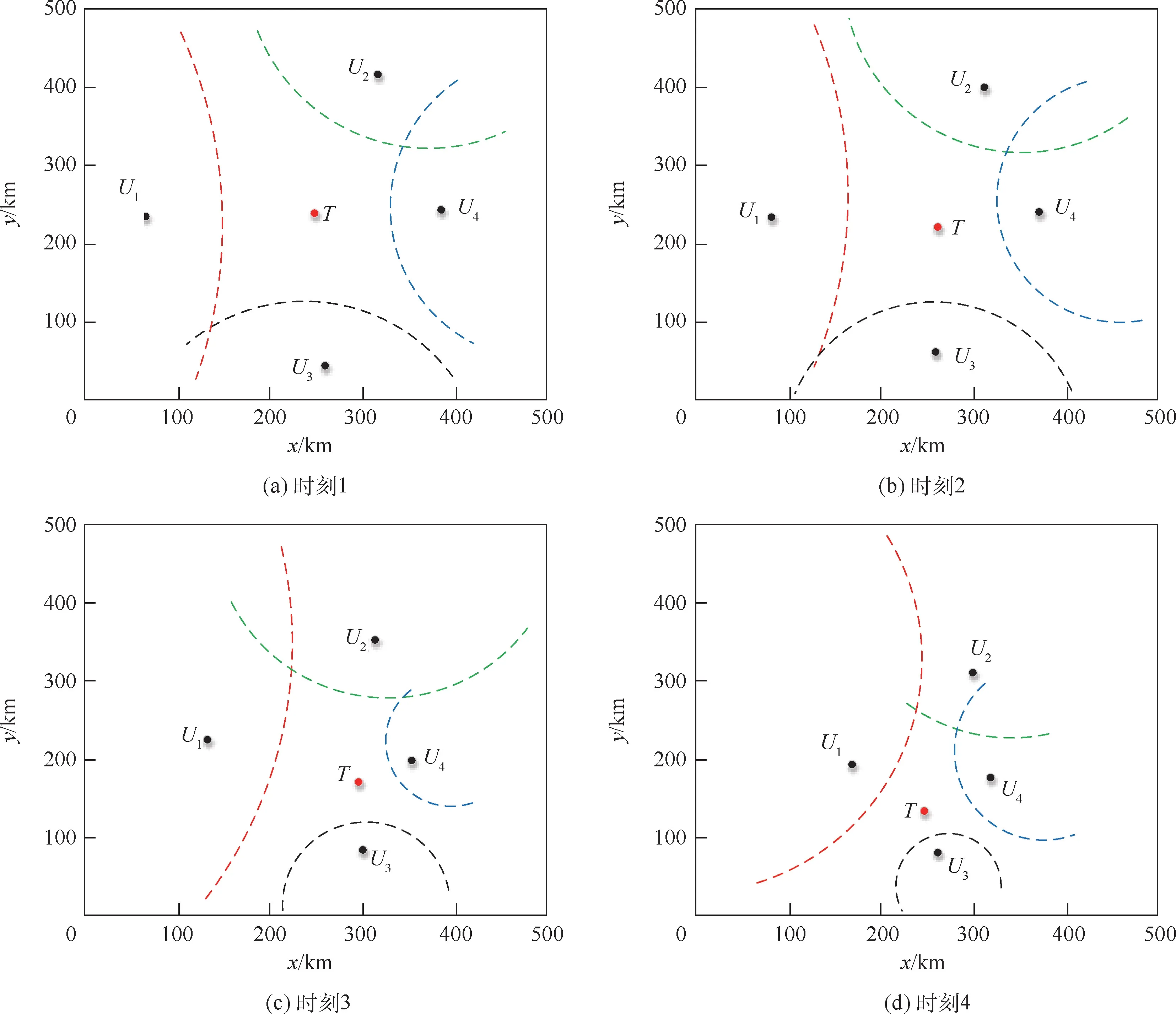
图12 对照组围捕过程Fig.12 Control group round up process
5 结 论
本文所设计的基于群体意志统一的多无人机协同围捕策略能够有效解决不同数量的无人机集群在固定环境下的围捕问题。设定围捕无人机集群速度小于目标无人机速度,同时摆脱复杂、精确的模型控制,提出群体意志趋同学习原理,在保证全局有解的情况下,使整个围捕无人机系统涌现出的智能化得到充分发挥。较采用传统的分布式优化策略,仅进行实践学习的围捕无人机能够更快的完成围捕,提高围捕成功率。
同时,本文只考虑了无约束的二维空间环境,仅能将所设计围捕策略简单适用于在指定高度层下,定速无人机协同围捕单架定速目标无人机的工程应用中,具有一定的局限性。下一步将针对有障碍物约束的二维场景及无障碍约束的三维空间环境,逐步进行深入扩展研究,并结合三维空间下的多无人机协同围捕工程应用,以增强该围捕策略在复杂环境下的鲁棒性。
